数据一致性的根本挑战
在数据库系统中,内存(Buffer Pool)与磁盘数据的一致性 是确保数据可靠性、完整性的核心命题。这个问题的本质源于计算机体系结构中的一个根本矛盾:内存的易失性与磁盘的非易失性,以及二者之间巨大的性能差距(内存访问比磁盘I/O快3-5个数量级)。
InnoDB存储引擎通过一套精密的协同机制,优雅地解决了这一矛盾,其核心由三大支柱构成:
- Write-Ahead Logging (WAL) - 解决"如何安全地延迟写盘"问题
- Double Write Buffer - 解决"如何防止部分写(Partial Write)"问题
- CheckPoint机制 - 解决"如何高效恢复并管理日志空间"问题
本文将深入剖析这三大机制的工作原理、协同关系及其在保障数据一致性中的关键作用。
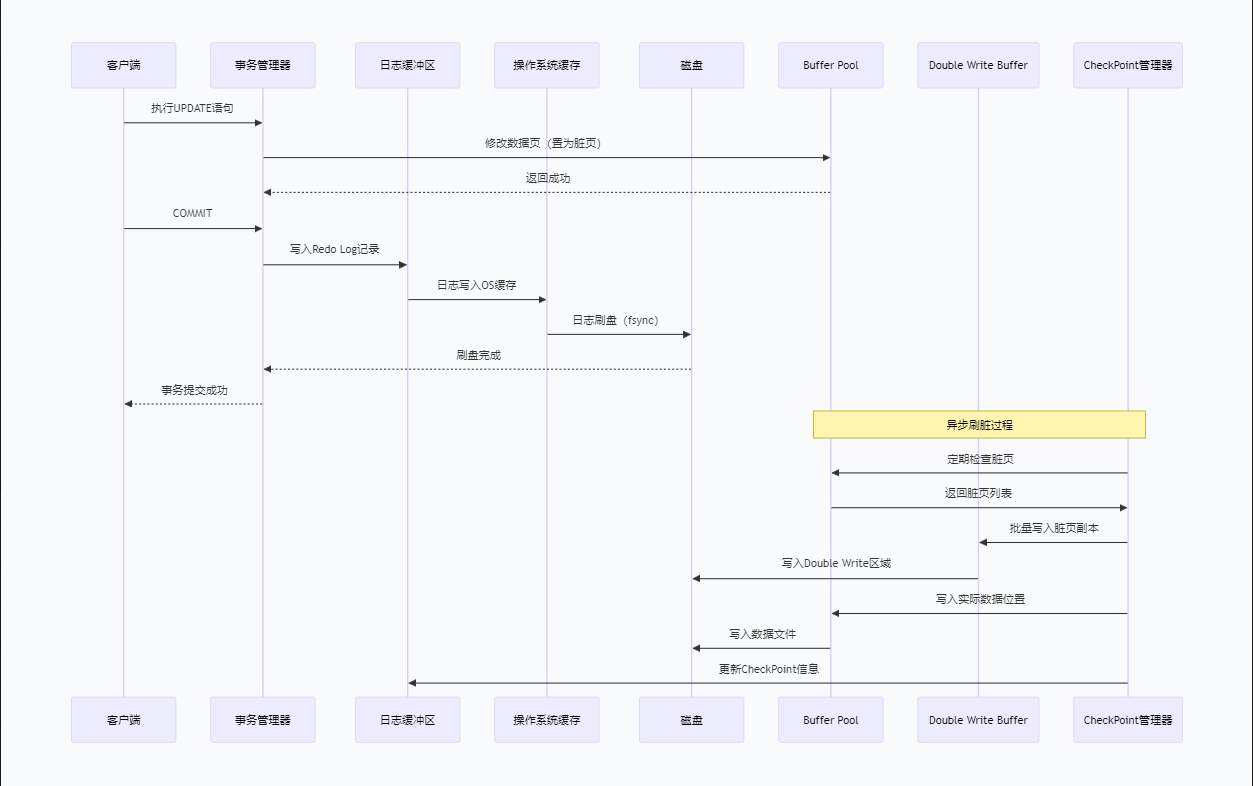
Write-Ahead Logging(WAL)------ 一切一致性的基石
WAL的核心思想与设计哲学
WAL的基本原理可以概括为:任何对数据页的修改,在应用到内存中的Buffer Pool之前,必须先将其对应的重做日志(Redo Log)持久化到磁盘。这一看似简单的规则,实则是数据库系统设计的重大突破,它解决了数据库系统中的"写放大"问题。
为什么需要WAL?
- 性能考量:如果每次事务提交都必须等待数据页刷盘,系统的吞吐量将受限于磁盘的随机I/O性能
- 原子性保证:事务要么完全提交,要么完全回滚,需要可靠的恢复机制
- 持久性保证:即使系统崩溃,已提交事务的数据不能丢失
Redo Log的物理与逻辑结构
物理结构
InnoDB的Redo Log在物理上由两个或多个预分配的文件组成(通常为ib_logfile0和ib_logfile1),以循环方式使用。每个文件被划分为固定大小的日志块(通常为512字节),这与磁盘扇区大小对齐,确保写入的原子性。
+------------------+------------------+------------------+
| 日志块头(12字节) | 日志记录体 | 日志块尾(4字节) |
+------------------+------------------+------------------+
| 块号 | 数据长度 | 第一个记录偏移 | ... 日志数据 ... | 校验和 |
+------+----------+----------------+-------------------+--------+逻辑结构:Log Sequence Number (LSN)
LSN是理解InnoDB一致性的关键概念,它是一个单调递增的64位整数,具有三重含义:
- 日志序列号:标识Redo Log中的位置
- 数据页版本号 :每个数据页头都有
FIL_PAGE_LSN字段,记录最后修改该页的LSN - 检查点位置:记录崩溃恢复的起始点
LSN构成了整个系统的一致性坐标轴,所有数据修改都在这条时间线上有序排列。
Redo Log的写入流程与性能优化
基本写入流程
c
// 概念化的写入流程
void write_redo_log(trx_t* transaction, redo_record_t* record) {
// 1. 获取下一个可用的LSN
lsn_t new_lsn = log_sys->next_lsn;
// 2. 构建日志记录,包含表空间ID、页号、页内偏移、修改数据等
build_log_record(record, new_lsn);
// 3. 将日志记录写入日志缓冲区(log buffer)
log_buffer_append(record);
// 4. 更新全局LSN
log_sys->next_lsn += record->length;
// 5. 事务提交时,确保日志刷盘(通过fsync或配置策略)
if (transaction->commit) {
log_write_up_to(new_lsn);
}
}关键优化技术
-
组提交(Group Commit)
-
问题 :频繁的
fsync()调用导致性能瓶颈 -
解决方案 :将多个事务的日志刷盘请求合并为一次
fsync -
实现机制 :
c// 简化版的组提交逻辑 void log_group_commit() { // 阶段1:将log buffer中的内容写入OS缓存 write_log_to_os_cache(); // 阶段2:收集当前等待提交的所有事务 trx_list_t waiting_trxs = collect_committing_transactions(); // 阶段3:执行一次fsync(最耗时的操作) fsync(log_file); // 阶段4:唤醒所有等待的事务 wakeup_all_trxs(waiting_trxs); }
-
-
日志缓冲区(Log Buffer)
- 内存中的缓冲区,用于缓存未刷盘的日志记录
- 大小由
innodb_log_buffer_size控制(默认16MB) - 写入时机:
- 事务提交时
- 日志缓冲区空间不足时
- 每秒一次的后台刷写
-
并行日志写入
- MySQL 8.0引入了并行日志写入,多个用户线程可以并发写入日志缓冲区
- 通过无锁数据结构(如CAS操作)减少竞争
WAL如何保障一致性
故障恢复流程
当数据库异常崩溃后重启时,恢复过程如下:
c
// 简化的崩溃恢复流程
void crash_recovery() {
// 1. 定位检查点(最后一个完成的检查点)
checkpoint_lsn = find_last_checkpoint();
// 2. 从检查点开始扫描Redo Log
current_lsn = checkpoint_lsn;
while (current_lsn < log_end_lsn) {
redo_record = read_log_record(current_lsn);
// 3. 判断是否需要重放:比较日志LSN和页面的LSN
page = get_page_from_buffer_pool(redo_record->space_id,
redo_record->page_no);
if (page->lsn < redo_record->lsn) {
// 页面版本较旧,需要应用重做日志
apply_redo_to_page(page, redo_record);
page->lsn = redo_record->lsn;
}
current_lsn += redo_record->length;
}
// 4. 处理未完成的事务(Undo Log回滚)
rollback_uncommitted_transactions();
}持久性保证的边界条件
事务提交成功 = Redo Log落盘,这一等式需要仔细理解其边界:
-
写缓存问题 :如果磁盘控制器或操作系统有写缓存且未启用断电保护,
fsync()返回成功并不保证数据真正落盘- 解决方案:启用写缓存策略(
O_DIRECT或innodb_flush_method)
- 解决方案:启用写缓存策略(
-
半写(Half-Write)问题:电源故障可能导致只写入部分扇区
- 这正是Double Write Buffer要解决的问题
Double Write Buffer ------ 防范部分写故障的守护神
部分写(Partial Write)问题的本质
部分写是指:当数据库将一个数据页(通常16KB)写入磁盘时,由于操作系统或存储设备的故障(如电源中断),只完成了部分扇区(如8KB)的写入。这种故障模式尤其危险,因为:
- 破坏页面完整性:数据页内部校验和不匹配
- 无法通过Redo Log恢复:Redo Log假设页面本身是完整的,只记录增量修改
- 可能导致数据文件永久损坏
Double Write Buffer的工作原理
双层写入架构
Double Write Buffer的实现采用经典的"先写副本,再写实际位置"策略:
+----------------+ 步骤1 +-------------------+ 步骤2 +---------------+
| | -------------> | | -------------> | |
| Buffer Pool | 写入副本 | Double Write Buffer | 写入实际位置 | 数据文件 |
| (内存中的脏页) | | (系统表空间区域) | | (用户表空间) |
| | | | | |
+----------------+ +-------------------+ +---------------+
| | |
| | |
+------ 步骤3:定期批量刷写 --------+ |
(顺序写,性能优化) |详细工作流程
c
// 简化的Double Write流程
void double_write_page(page_t* dirty_page) {
// 阶段1:写入Double Write Buffer(系统表空间)
// Double Write Buffer分为两个部分:内存缓冲区和磁盘保留区
// 1a. 将脏页复制到Double Write内存缓冲区
memcpy(double_write_buffer + offset, dirty_page, PAGE_SIZE);
// 1b. 当缓冲区积累一定数量(如120个页)或需要刷脏页时,批量写入磁盘
if (double_write_buffer_is_full() || need_flush_dirty_pages()) {
// 顺序写入Double Write磁盘区域(连续空间,性能好)
write_blocks_to_double_write_area(double_write_buffer,
num_pages_in_buffer);
// 确保写入完成(fsync)
fsync(double_write_file);
}
// 阶段2:写入实际数据文件位置
// 2a. 从Double Write缓冲区读取页面,写入实际表空间位置
write_page_to_actual_location(dirty_page->space_id,
dirty_page->page_no,
dirty_page);
// 2b. 写入完成后,标记Double Write Buffer中的副本为可覆盖
mark_double_write_slot_free(offset);
}Double Write Buffer的磁盘布局
Double Write Buffer在系统表空间(ibdata1)中有固定的存储区域:
-
位置:系统表空间的第7个区(extent),共128个页(2MB)
-
结构 :
第1个区:Double Write Buffer第一部分(64页,1MB) 第2个区:Double Write Buffer第二部分(64页,1MB) -
双缓冲区设计目的:允许在一个缓冲区刷盘时,另一个缓冲区继续接收新脏页
Double Write的崩溃恢复机制
当数据库崩溃重启时,恢复过程会检查并利用Double Write Buffer:
c
// 简化的Double Write恢复流程
void double_write_recovery() {
// 1. 扫描Double Write Buffer区域
for each page in double_write_area {
// 2. 读取Double Write中的页副本
dw_page = read_page_from_double_write(slot);
// 3. 读取实际数据文件中的对应页
data_file_page = read_page_from_data_file(dw_page->space_id,
dw_page->page_no);
// 4. 比较校验和或LSN
if (is_page_corrupted(data_file_page)) {
// 5. 如果数据文件中的页损坏,使用Double Write副本修复
write_page_to_data_file(dw_page->space_id,
dw_page->page_no,
dw_page);
log_recovery_action("修复损坏页", dw_page->space_id,
dw_page->page_no);
}
}
// 6. 完成修复后,继续正常的Redo Log恢复
apply_redo_log_from_checkpoint();
}Double Write的性能影响与优化
性能开销分析
Double Write的主要开销来自:
- 额外的写操作:每个脏页需要写两次(Double Write区域 + 实际位置)
- 额外的fsync:需要确保Double Write区域的持久化
实际测试表明,Double Write通常带来5%-10%的性能下降,但在现代SSD上这个开销更小。
优化策略
-
批量写入:积累多个脏页后一次性写入Double Write区域,将随机I/O转为顺序I/O
-
并行写入:MySQL 8.0支持并行Double Write
-
自适应刷新:根据系统负载动态调整刷新策略
-
SSD优化 :对于支持原子写的SSD,可以跳过Double Write
sql-- 如果SSD支持原子写,可以禁用Double Write以提升性能 SET GLOBAL innodb_doublewrite = 0; -- 注意:必须确保存储设备真正支持原子写,否则有数据损坏风险
Double Write的配置与监控
相关参数
sql
-- 查看Double Write状态
SHOW VARIABLES LIKE 'innodb_doublewrite%';
-- 主要参数:
-- innodb_doublewrite: 是否启用Double Write(默认ON)
-- innodb_doublewrite_files: Double Write文件数量(默认2)
-- innodb_doublewrite_dir: Double Write文件目录(默认数据目录)
-- innodb_doublewrite_batch_size: 批量写入大小监控指标
sql
-- 通过Performance Schema监控
SELECT * FROM performance_schema.file_summary_by_event_name
WHERE EVENT_NAME LIKE '%doublewrite%';
-- 通过InnoDB状态监控
SHOW ENGINE INNODB STATUS\G
-- 在输出中查找"DOUBLEWRITE"部分CheckPoint机制 ------ 平衡恢复时间与性能的艺术
CheckPoint的核心作用
CheckPoint机制解决了WAL带来的两个衍生问题:
- 恢复时间问题:如果不加控制,崩溃恢复需要重放所有Redo Log,耗时过长
- 日志空间问题:Redo Log文件是循环使用的,需要标记哪些日志可以安全覆盖
CheckPoint的类型与触发条件
InnoDB实现了多种CheckPoint,各有不同的触发条件和目的:
Sharp CheckPoint(尖锐检查点)
- 触发条件:数据库关闭时、手动执行检查点
- 特点:刷写所有脏页到磁盘,完全同步Buffer Pool和磁盘
- 影响:I/O压力大,影响性能,只用于关闭或维护场景
Fuzzy CheckPoint(模糊检查点)
- 触发条件:定期触发,是InnoDB的主要检查点类型
- 特点:只刷写部分脏页,异步进行,不影响正常业务
- 子类型 :
a. 异步检查点 :由后台线程定期触发
b. 增量检查点:只刷写最近修改的脏页
FLUSH_LSN CheckPoint(刷新LSN检查点)
-
触发机制:当Redo Log空间不足时触发
-
目的:释放旧的Redo Log空间以便重用
-
算法 :
1. 计算可覆盖的Redo Log起始位置 = 最旧未刷脏页的LSN 2. 触发刷脏,推进最旧未刷脏页的LSN 3. 更新Redo Log的可覆盖起始位置
CheckPoint的详细实现
关键数据结构
c
// 简化的CheckPoint相关数据结构
typedef struct {
lsn_t checkpoint_lsn; // 检查点LSN
lsn_t oldest_modification_lsn; // 最旧未刷脏页的LSN
lsn_t flushed_to_disk_lsn; // 已刷到磁盘的LSN
lsn_t write_lsn; // 已写入日志文件的LSN
lsn_t current_lsn; // 当前LSN
// 脏页管理
page_list_t flush_list; // 按修改时间排序的脏页列表
hash_table_t page_hash; // 快速查找脏页
// 检查点信息持久化存储
checkpoint_info_t checkpoint_block[2]; // 双重存储,防止损坏
} checkpoint_system_t;异步检查点的实现
c
// 后台检查点线程的主循环(简化)
void* checkpoint_thread_main(void* arg) {
while (!shutdown_requested) {
// 1. 睡眠,等待下次检查点时机
sleep(checkpoint_interval);
// 2. 计算需要刷新的脏页数量
// 基于多个因素:Redo Log空间使用率、脏页比例、上次检查点时间等
n_pages_to_flush = calculate_pages_to_flush();
// 3. 从Flush List尾部(最旧的脏页)开始刷新
for (i = 0; i < n_pages_to_flush; i++) {
page = get_oldest_dirty_page_from_flush_list();
// 4. 刷脏页到磁盘(通过Double Write)
buf_flush_page(page);
// 5. 更新统计信息
update_flush_statistics();
}
// 6. 写入检查点标记到Redo Log头
write_checkpoint_marker();
// 7. 更新可覆盖的Redo Log起始位置
advance_reclaimable_redo_log_start();
}
return NULL;
}自适应刷脏算法
InnoDB采用自适应算法动态调整刷脏速率:
c
// 自适应刷脏算法概念
void adaptive_flush_algorithm() {
// 因素1:Redo Log空间使用率
redo_log_usage = calculate_redo_log_usage();
// 因素2:脏页比例
dirty_page_ratio = calculate_dirty_page_ratio();
// 因素3:I/O能力
io_capacity = estimate_io_capacity();
// 因素4:用户活动
user_activity_level = monitor_user_activity();
// 综合计算目标刷脏速率
target_flush_rate =
base_rate *
(1 + redo_log_usage * 0.5) *
(1 + dirty_page_ratio * 0.3) *
(io_capacity_factor) *
(1 - user_activity_level * 0.2);
// 应用目标速率
set_flush_rate(target_flush_rate);
}CheckPoint与崩溃恢复的协同
检查点信息的持久化
检查点信息存储在Redo Log文件的头部,采用双重写入防止损坏:
Redo Log文件头结构:
+----------------+----------------+----------------+----------------+
| Log Group 0 | Log Group 1 | Checkpoint1 | Checkpoint2 |
| Header 0 | Header 1 | (主) | (备) |
+----------------+----------------+----------------+----------------+
| LOG_FILE_MAGIC | LOG_FILE_START | checkpoint_no | checkpoint_lsn |
| format | LSN | buffer_size | archived_lsn |
| ... | ... | ... | ... |
+----------------+----------------+----------------+----------------+崩溃恢复的起点确定
当数据库异常重启时,恢复过程首先定位检查点:
c
// 查找最新有效检查点
checkpoint_info_t* find_valid_checkpoint() {
// 尝试读取第一个检查点
checkpoint1 = read_checkpoint_block(LOG_CHECKPOINT_1_OFFSET);
// 尝试读取第二个检查点
checkpoint2 = read_checkpoint_block(LOG_CHECKPOINT_2_OFFSET);
// 选择checkpoint_no更大的那个(表示更新)
if (checkpoint1->checkpoint_no >= checkpoint2->checkpoint_no) {
if (validate_checkpoint(checkpoint1)) {
return checkpoint1;
} else if (validate_checkpoint(checkpoint2)) {
return checkpoint2;
}
} else {
if (validate_checkpoint(checkpoint2)) {
return checkpoint2;
} else if (validate_checkpoint(checkpoint1)) {
return checkpoint1;
}
}
// 没有有效检查点,需要从日志开头恢复
return NULL;
}CheckPoint的配置优化
关键参数
sql
-- CheckPoint相关参数
SHOW VARIABLES LIKE 'innodb_checkpoint%';
-- 主要参数:
-- innodb_fast_shutdown: 快速关闭模式(默认1)
-- innodb_max_dirty_pages_pct: 最大脏页比例(默认90%)
-- innodb_max_dirty_pages_pct_lwm: 低水位线(默认10%)
-- innodb_io_capacity: I/O能力基准值(默认200)
-- innodb_io_capacity_max: 最大I/O能力(默认2000)
-- innodb_flush_neighbors: 是否刷新相邻页(默认0,SSD建议禁用)
-- innodb_adaptive_flushing: 是否启用自适应刷脏(默认ON)
-- innodb_adaptive_flushing_lwm: 自适应刷脏低水位线(默认10%)性能调优建议
-
SSD环境优化:
sql-- 增加I/O能力设置 SET GLOBAL innodb_io_capacity = 1000; SET GLOBAL innodb_io_capacity_max = 2000; -- 禁用相邻页刷新 SET GLOBAL innodb_flush_neighbors = 0; -- 降低检查点频率,增加每次刷脏量 SET GLOBAL innodb_max_dirty_pages_pct = 75; -
机械硬盘环境优化:
sql-- 启用相邻页刷新,利用顺序I/O SET GLOBAL innodb_flush_neighbors = 1; -- 保守的I/O设置 SET GLOBAL innodb_io_capacity = 200; SET GLOBAL innodb_io_capacity_max = 400; -- 降低脏页比例阈值 SET GLOBAL innodb_max_dirty_pages_pct = 50; -
高写入负载场景:
sql-- 增加Redo Log大小,减少检查点频率 SET GLOBAL innodb_log_file_size = 4G; -- 通常需要重启 SET GLOBAL innodb_log_files_in_group = 3; -- 增加日志缓冲区 SET GLOBAL innodb_log_buffer_size = 64M; -- 更激进的自适应刷脏 SET GLOBAL innodb_adaptive_flushing_lwm = 20;
三大机制的协同工作与系统级一致性保障
整体协同架构
WAL、Double Write和CheckPoint不是孤立工作的,它们形成一个精密的协同系统:
+------------------------------------------------------------------------+
| InnoDB存储引擎一致性保障体系 |
+------------------------------------------------------------------------+
| |
| +----------------+ +----------------+ +----------------+ |
| | WAL机制 | | Double Write | | CheckPoint机制 | |
| | | | | | | |
| | • 提供原子性 | | • 防止部分写 | | • 控制恢复时间 | |
| | • 提供持久性 |<-->| • 页面完整性 |<-->| • 管理日志空间 | |
| | • 顺序日志写入 | | • 崩溃修复 | | • 异步刷脏 | |
| +----------------+ +----------------+ +----------------+ |
| | | | |
| | | | |
| v v v |
| +----------------+ +----------------+ +----------------+ |
| | Redo Log | | 数据文件 | | 缓冲池管理 | |
| | (ib_logfile) | | (.ibd文件) | | (Buffer Pool) | |
| +----------------+ +----------------+ +----------------+ |
| |
+------------------------------------------------------------------------+正常操作流程中的协同
以一个事务的提交和后续处理为例:
c
// 事务提交与数据刷写的完整协同流程
void transaction_commit_and_flush(trx_t* trx) {
// 阶段1:WAL保证 - 先写日志
// 1.1 生成Redo Log记录
redo_record = generate_redo_record(trx->modifications);
// 1.2 写入日志缓冲区
log_buffer_append(redo_record);
// 1.3 事务提交:确保Redo Log落盘(可能通过组提交)
log_write_up_to(trx->commit_lsn);
// 1.4 返回事务提交成功(此时数据页可能在内存中)
trx->state = TRX_COMMITTED;
// 阶段2:异步刷脏(由后台线程处理)
// 2.1 脏页被加入到Flush List,按LSN排序
add_dirty_pages_to_flush_list(trx->modified_pages);
// 2.2 CheckPoint机制监控刷脏进度
monitor_flush_progress();
// 2.3 当需要刷脏时(检查点触发或脏页过多)
if (need_flush_dirty_pages()) {
for each dirty_page in flush_list {
// 阶段3:Double Write保护
// 3.1 先写入Double Write缓冲区
write_to_double_write_buffer(dirty_page);
// 3.2 再写入实际数据文件位置
write_to_actual_data_file(dirty_page);
// 3.3 更新页面的LSN和清除脏页标记
dirty_page->lsn = get_current_lsn();
dirty_page->is_dirty = false;
// 3.4 从Flush List移除
remove_from_flush_list(dirty_page);
}
// 阶段4:CheckPoint更新
// 4.1 更新检查点信息
update_checkpoint_info();
// 4.2 推进可覆盖的Redo Log起始位置
advance_redo_log_reclaim_position();
}
}崩溃恢复的完整流程
当系统崩溃后重启时,三大机制协同工作确保数据一致性:
崩溃恢复流程:
+------------------------------------------------------------------------+
| 步骤 | 操作 | 使用的机制 | 目的 |
|------|-------------------------|-------------------|-------------------|
| 1 | 读取Redo Log文件头 | CheckPoint | 定位最新检查点 |
| 2 | 加载Double Write缓冲区 | Double Write | 获取页面的完好副本 |
| 3 | 验证数据页完整性 | Double Write | 检测部分写损坏 |
| 4 | 修复损坏页 | Double Write | 使用副本恢复损坏页 |
| 5 | 从检查点开始扫描Redo Log | WAL + CheckPoint | 确定恢复起点 |
| 6 | 应用Redo Log记录 | WAL | 重放已提交的修改 |
| 7 | 回滚未完成事务 | Undo Log | 保证原子性 |
| 8 | 系统恢复完成 | 所有机制 | 数据回到一致状态 |
+------------------------------------------------------------------------+性能与可靠性的平衡艺术
数据库系统设计本质上是性能与可靠性之间的权衡。InnoDB的三大机制体现了精妙的平衡:
-
WAL的平衡:
- 性能侧:将随机写转为顺序写,允许延迟刷脏
- 可靠性侧:确保事务提交前日志落盘
-
Double Write的平衡:
- 性能侧:批量顺序写入,SSD可禁用
- 可靠性侧:防止部分写导致的永久数据损坏
-
CheckPoint的平衡:
- 性能侧:异步刷脏,避免影响用户事务
- 可靠性侧:控制恢复时间在可接受范围内
现代硬件带来的挑战与演进
新型存储硬件的出现对传统一致性机制提出了新挑战:
-
NVMe SSD与持久内存(PMEM):
- 更低的延迟,更高的带宽
- 对WAL的组提交、日志缓冲区大小提出了新要求
- PMEM可能改变整个日志体系结构
-
原子写支持:
- 部分SSD支持原子写,可能绕过Double Write
- 需要精确检测硬件能力,防止数据损坏
-
分布式存储:
- 云数据库的多副本、分布式一致性
- Raft/Paxos协议与传统WAL的集成
-
机器学习优化:
- 预测性刷脏:基于历史模式预测最佳刷脏时机
- 自适应参数调整:根据负载模式动态调整机制参数
实战应用与故障处理
一致性保障机制的最佳实践
配置建议
ini
# InnoDB一致性相关配置示例(my.cnf)
[mysqld]
# 基础配置
innodb_buffer_pool_size = 系统内存的70-80%
innodb_log_file_size = 4G # 大值减少检查点频率
innodb_log_files_in_group = 3 # 足够的日志文件
# WAL优化
innodb_log_buffer_size = 64M
innodb_flush_log_at_trx_commit = 1 # 最高持久性级别
# 可选:innodb_flush_log_at_trx_commit = 2(OS缓存级别,性能更好)
# Double Write配置
innodb_doublewrite = ON # 默认开启,除非确认SSD支持原子写
innodb_doublewrite_files = 2
innodb_doublewrite_batch_size = 0 # 0表示自动调整
# CheckPoint优化
innodb_io_capacity = 1000 # SSD环境
innodb_io_capacity_max = 2000
innodb_max_dirty_pages_pct = 75
innodb_max_dirty_pages_pct_lwm = 10
innodb_adaptive_flushing = ON
innodb_adaptive_flushing_lwm = 10
# 高级优化
innodb_flush_method = O_DIRECT # 避免双缓冲
innodb_checksum_algorithm = crc32 # 更快的校验和监控与诊断
sql
-- 全面的InnoDB一致性监控
SELECT
-- Buffer Pool状态
(SELECT VARIABLE_VALUE
FROM performance_schema.global_status
WHERE VARIABLE_NAME = 'Innodb_buffer_pool_pages_dirty') * 16 / 1024 AS dirty_MB,
(SELECT VARIABLE_VALUE
FROM performance_schema.global_status
WHERE VARIABLE_NAME = 'Innodb_buffer_pool_pages_total') * 16 / 1024 AS total_buffer_MB,
-- Redo Log状态
(SELECT VARIABLE_VALUE
FROM performance_schema.global_status
WHERE VARIABLE_NAME = 'Innodb_os_log_written') / 1024 / 1024 AS redo_written_MB,
-- Double Write状态
(SELECT VARIABLE_VALUE
FROM performance_schema.global_status
WHERE VARIABLE_NAME = 'Innodb_dblwr_pages_written') AS dblwr_pages_written,
-- CheckPoint信息
(SELECT VARIABLE_VALUE
FROM performance_schema.global_status
WHERE VARIABLE_NAME = 'Innodb_last_checkpoint_lsn') AS last_checkpoint_lsn,
-- 恢复时间估计
(CAST((SELECT VARIABLE_VALUE
FROM performance_schema.global_status
WHERE VARIABLE_NAME = 'Innodb_checkpoint_age') AS UNSIGNED)
/ CAST((SELECT VARIABLE_VALUE
FROM performance_schema.global_status
WHERE VARIABLE_NAME = 'Innodb_ibuf_merges_per_sec') AS UNSIGNED + 1)
) / 1000 AS estimated_recovery_time_sec;常见故障场景与处理
电源故障恢复
场景 :服务器意外断电,重启后数据库恢复
处理流程:
- InnoDB自动进入崩溃恢复模式
- 读取Redo Log头部的检查点信息
- 使用Double Write缓冲区修复可能损坏的页
- 从检查点开始重放Redo Log
- 使用Undo Log回滚未提交事务
- 恢复完成后正常提供服务
优化 :通过增大innodb_log_file_size减少恢复时间
磁盘损坏处理
场景 :数据文件部分损坏,但Double Write缓冲区完好
处理流程:
sql
-- 1. 启动数据库,InnoDB会自动尝试从Double Write恢复
-- 2. 如果自动恢复失败,手动恢复
-- 步骤1:进入安全模式
SET GLOBAL innodb_force_recovery = 1; -- 尝试级别1-6
-- 步骤2:导出数据
mysqldump -u root -p --all-databases > backup.sql
-- 步骤3:重建数据库
-- 停止MySQL,删除所有ibdata和ib_logfile文件
-- 重新初始化数据目录
-- 导入备份
-- 步骤4:恢复正常配置
SET GLOBAL innodb_force_recovery = 0;性能问题诊断
场景 :写密集型负载下性能下降
诊断步骤:
-
检查Redo Log配置是否合理
sql-- 监控Redo Log空间使用 SHOW ENGINE INNODB STATUS\G -- 查看LOG部分,关注Log sequence number和Log flushed up to的差值 -
检查脏页比例和刷脏速度
sql-- 监控脏页情况 SELECT VARIABLE_VALUE AS dirty_pages FROM performance_schema.global_status WHERE VARIABLE_NAME = 'Innodb_buffer_pool_pages_dirty'; -
调整CheckPoint参数
sql-- 增加I/O能力设置 SET GLOBAL innodb_io_capacity = 2000; SET GLOBAL innodb_io_capacity_max = 4000; -- 调整脏页比例阈值 SET GLOBAL innodb_max_dirty_pages_pct = 80;
数据库系统的数据一致性保障是一个永恒的主题。随着技术的演进,底层机制会不断优化,但WAL所代表的"先日志,后数据"的核心思想,以及在此基础上的分层防御策略,仍将是保障数据可靠性的基石。理解这些机制不仅有助于更好地使用数据库,也为设计其他需要持久化保证的系统提供了宝贵借鉴。