精彩专栏推荐订阅:在下方主页👇🏻👇🏻👇🏻👇🏻
💖🔥作者主页 :计算机毕设木哥🔥 💖
文章目录
- 一、项目介绍
- 二、背景意义
- 三、开发环境
- 四、系统展示
- 五、代码展示
- 六、项目文档展示
- 七、项目总结
- [<font color=#fe2c24 >大家可以帮忙点赞、收藏、关注、评论啦 👇🏻](#fe2c24 >大家可以帮忙点赞、收藏、关注、评论啦 👇🏻)
一、项目介绍
系统介绍:本系统是一套基于大数据技术的车辆二氧化碳排放量可视化分析平台,旨在通过深度挖掘车辆排放数据,为环保决策提供直观依据。系统核心采用了SparkSession.builder构建的大数据环境,能够高效处理海量车辆信息,涵盖品牌、车型、发动机技术、燃料类型及油耗等多个维度的数据。通过六大维度的详细分析,系统实现了对各品牌平均排放量的统计、不同车辆类别的排放对比、发动机技术与排放的关联性分析,以及燃料类型的环保性能评估。同时,系统利用聚类算法等大数据技术,建立了综合环保评分体系,识别高排放与低排放车辆的特征画像,并通过可视化图表直观展示分析结果,帮助用户快速理解复杂的排放数据,为制定针对性的减排政策和技术改进方向提供科学的数据支撑。
二、背景意义
选题背景:随着全球气候变化问题日益严峻,汽车尾气排放作为主要的空气污染源之一,引起了社会各界的广泛关注。在"双碳"目标的背景下,如何有效监测和控制车辆碳排放成为了亟待解决的重要课题。传统的车辆排放研究往往依赖于小规模的抽样调查或简单的统计报表,难以全面反映真实路况下的排放水平。目前,虽然积累了大量的车辆技术参数和排放数据,但缺乏有效的工具对这些数据进行深度整合与多维度分析。现有的管理系统大多侧重于基础信息的录入,缺乏对排放规律、燃油经济性以及不同技术组合对环境影响的分析能力,导致数据价值未被充分挖掘,无法为环保部门制定精准政策提供强有力的科学依据。
选题意义:开发这个系统主要是为了把一堆零散的车辆数据变成有用的信息,实实在在地帮大家看清楚车辆排放这回事。通过大数据分析技术,我们能很直观地展示不同品牌、不同车型到底哪类更环保,让消费者在买车时心里有数,不光看性能,也能参考环保指标,选个低排放的车。对于相关管理部门来说,系统能分析出高排放车辆的共同特征,比如发动机尺寸大还是燃料类型的问题,这样就能更有针对性地制定限行或者激励政策。当然,作为毕业设计,它也有助于锻炼处理大规模数据的能力,学习如何从复杂的变量里找规律,把数据分析技术应用到实际的生活场景中,让技术真正能解决点实际问题,而不是纸上谈兵。
三、开发环境
- 大数据技术:Hadoop、Spark、Hive
- 开发技术:Python、Django框架、Vue、Echarts
- 软件工具:Pycharm、DataGrip、Anaconda
- 可视化 工具 Echarts
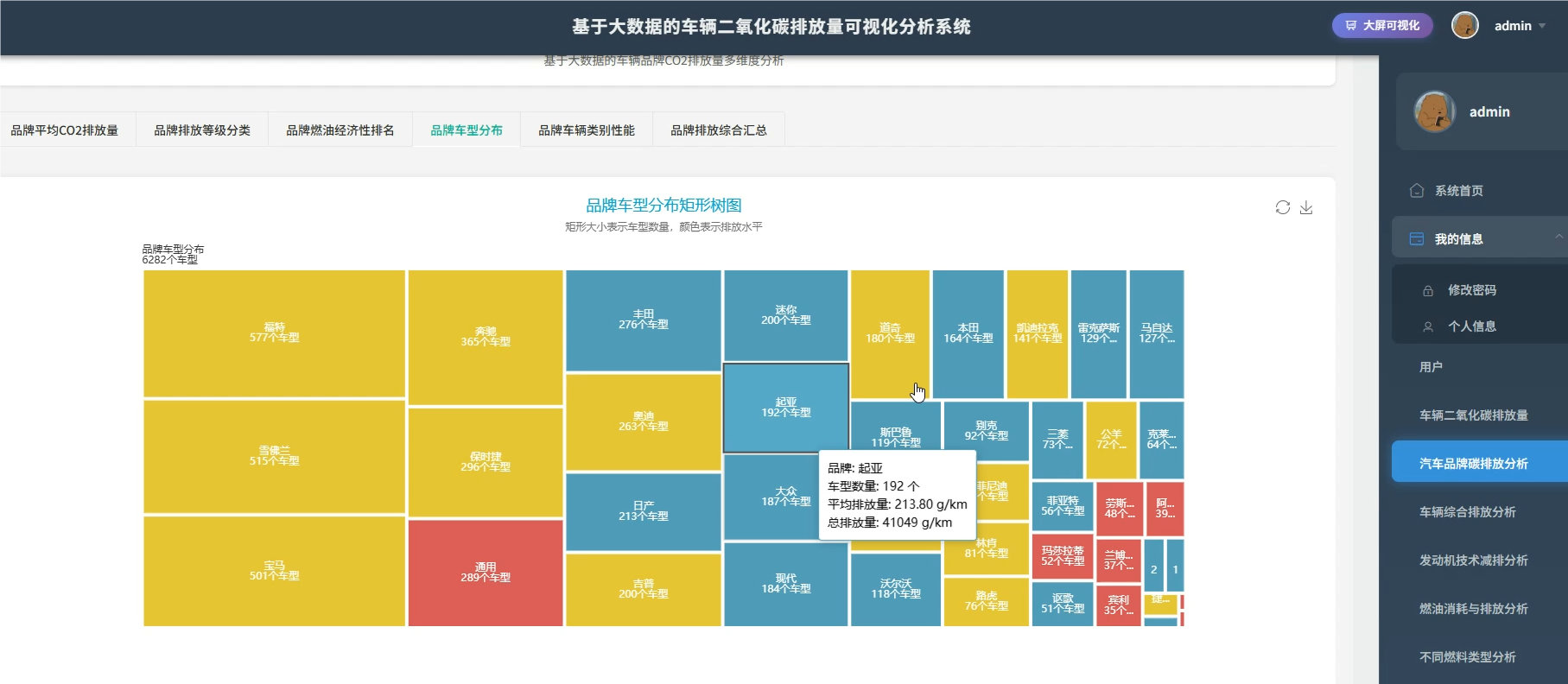
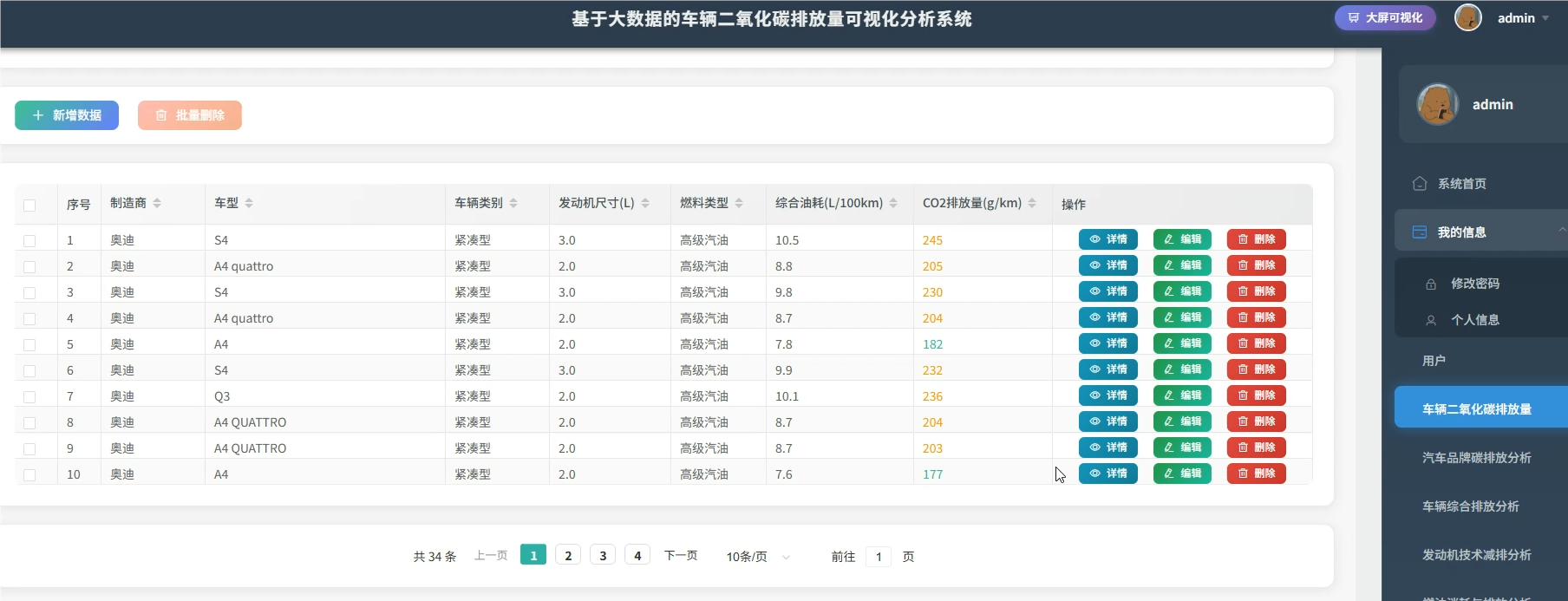
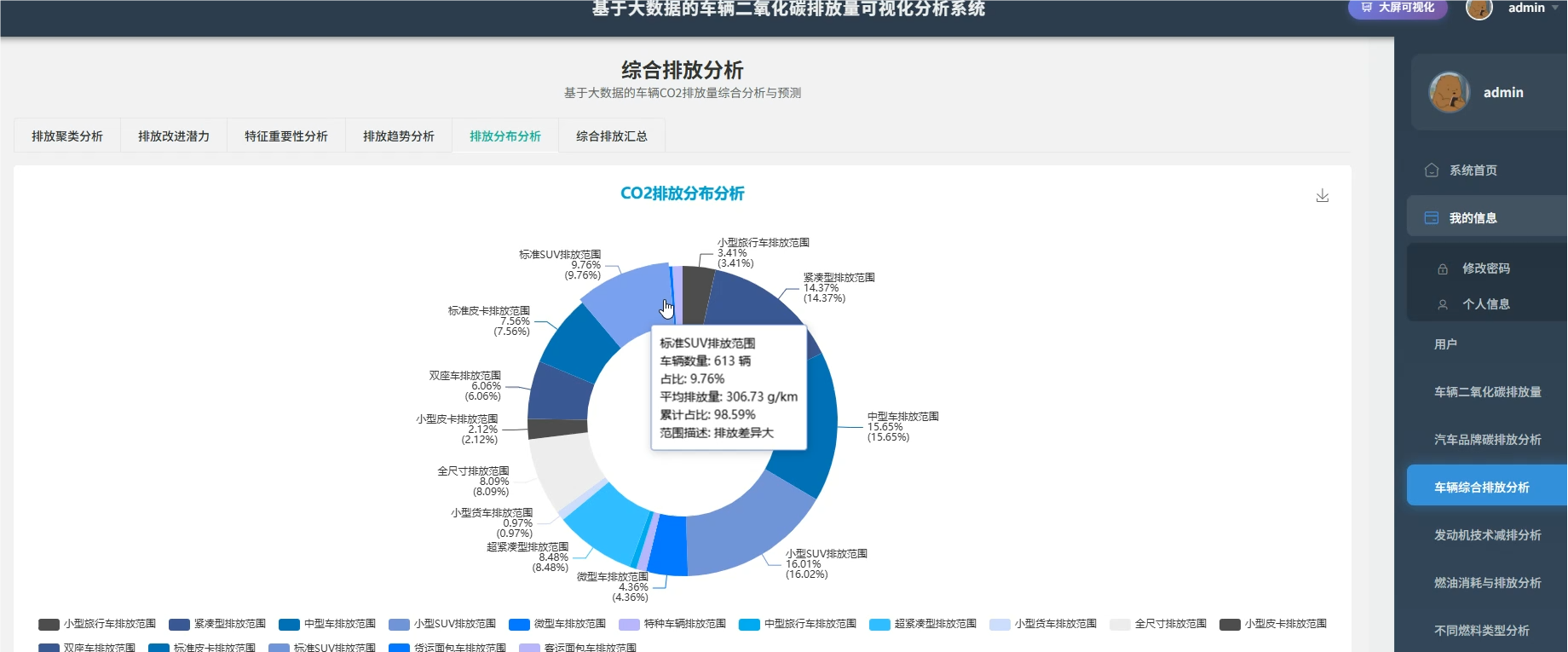
四、系统展示
系统模块展示:
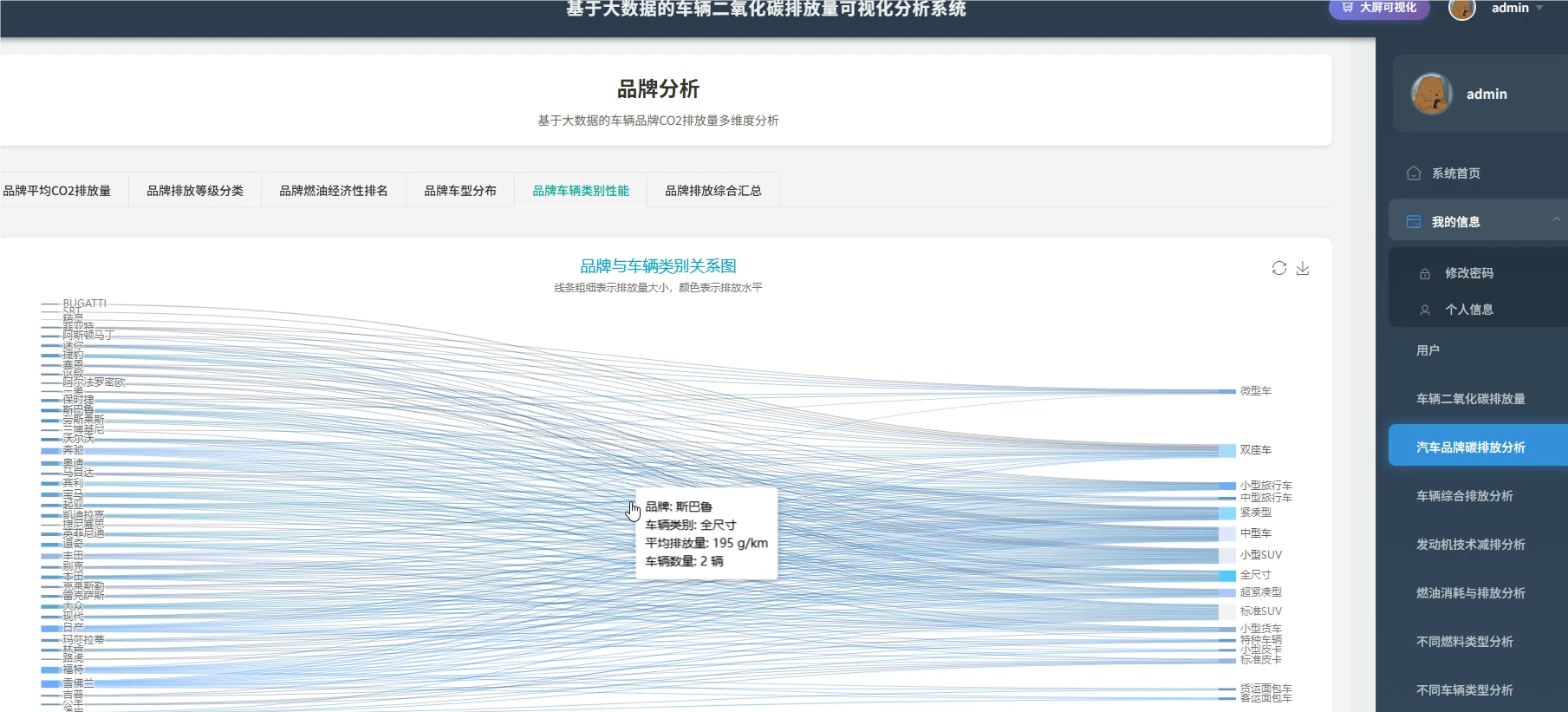
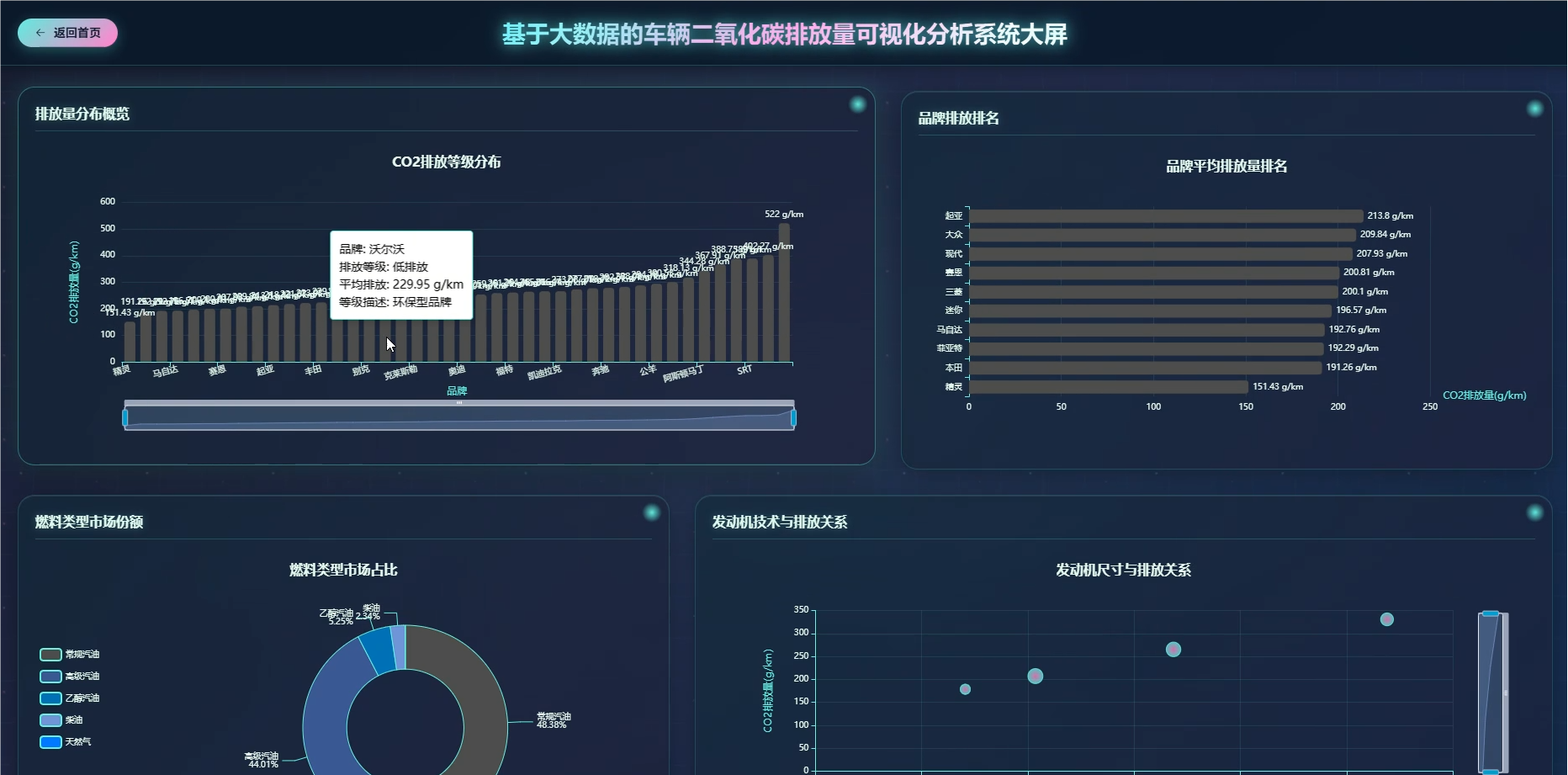
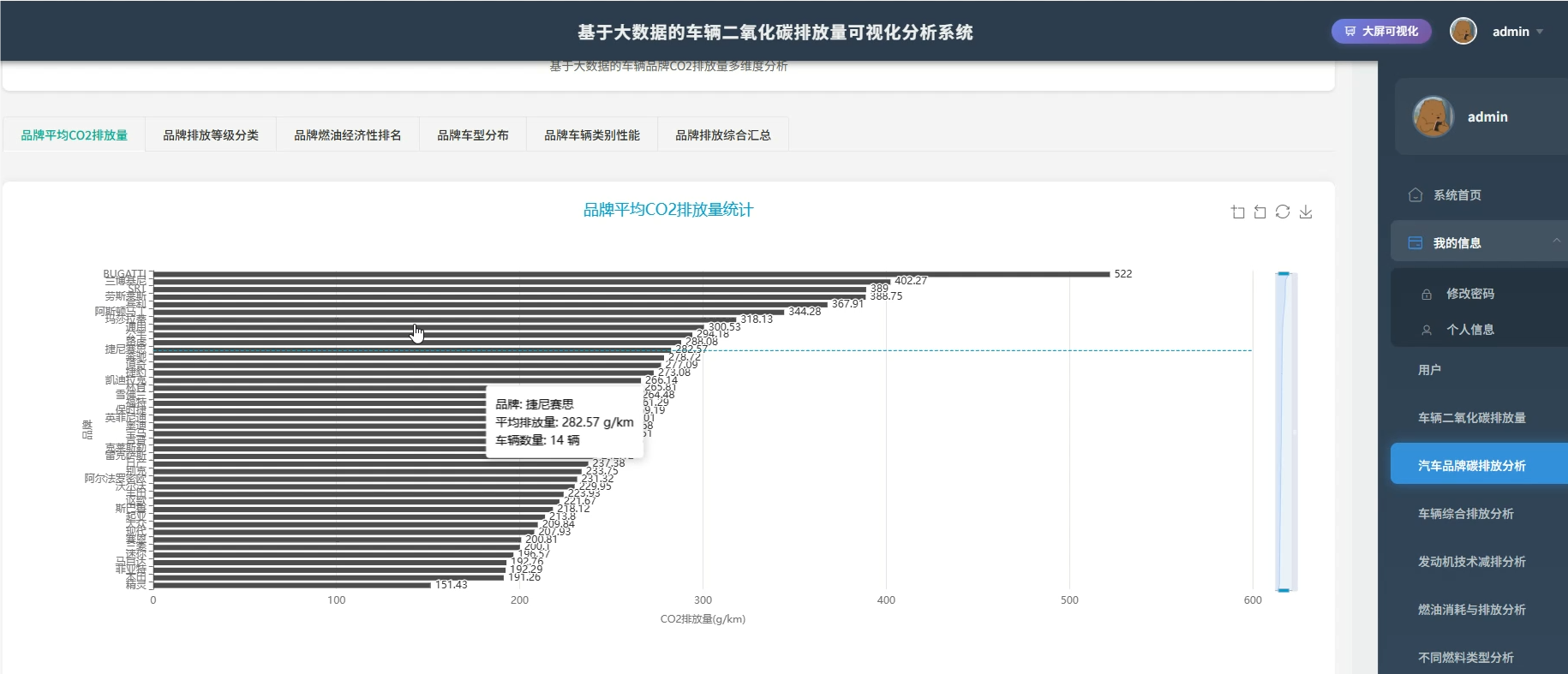
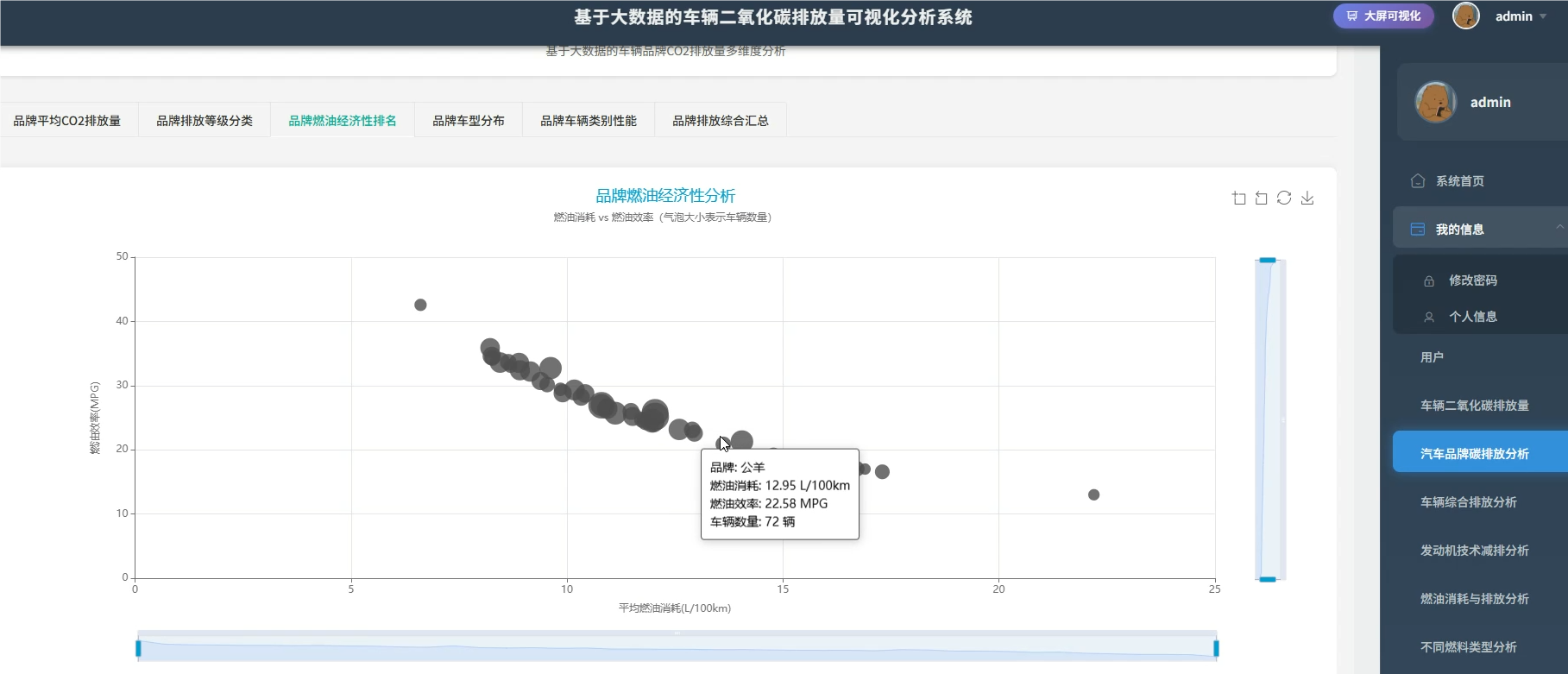
五、代码展示
bash
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, when, count, avg, stddev, lag, expr, row_number, log
from pyspark.ml.feature import VectorAssembler, StringIndexer
from pyspark.ml.classification import LogisticRegression
from pyspark.ml.evaluation import BinaryClassificationEvaluator
from pyspark.sql.window import Window
spark = SparkSession.builder.appName("CancerDataAnalysis").config("spark.sql.adaptive.enabled", "true").config("spark.sql.adaptive.coalescePartitions.enabled", "true").getOrCreate()
df = spark.read.csv("cancer_data.csv", header=True, inferSchema=True)
df = df.filter(col("Age").isNotNull() & col("CancerStage").isNotNull() & col("SurvivalStatus").isNotNull())
df = df.withColumn("AgeGroup", when(col("Age") < 40, 0).when(col("Age") < 60, 1).otherwise(2))
df = df.withColumn("StageNum", when(col("CancerStage") == "I期", 1).when(col("CancerStage") == "II期", 2).when(col("CancerStage") == "III期", 3).otherwise(4))
df = df.withColumn("MetastasisFlag", when(col("Metastasis") == "是", 1).otherwise(0))
df = df.withColumn("SurvivalLabel", when(col("SurvivalStatus") == "存活", 1).otherwise(0))
assembler = VectorAssembler(inputCols=["Age", "StageNum", "MetastasisFlag", "TumorSize"], outputCol="features")
assembled_df = assembler.transform(df)
train_df, test_df = assembled_df.randomSplit([0.8, 0.2], seed=42)
lr = LogisticRegression(labelCol="SurvivalLabel", featuresCol="features", maxIter=10, regParam=0.1)
model = lr.fit(train_df)
predictions = model.transform(test_df)
evaluator = BinaryClassificationEvaluator(labelCol="SurvivalLabel", metricName="areaUnderROC")
auc = evaluator.evaluate(predictions)
predictions.select("Age", "CancerStage", "SurvivalStatus", "probability", "prediction").show(10)
type_stats = df.groupBy("TumorType").agg(count("*").alias("total_cases"), avg("Age").alias("avg_age"), stddev("TumorSize").alias("size_std"))
type_stats = type_stats.withColumn("case_ratio", col("total_cases") / df.count() * 100)
window_spec = Window.partitionBy("TumorType").orderBy("DiagnosisYear")
trend_df = df.groupBy("TumorType", "DiagnosisYear").agg(count("*").alias("yearly_count"))
trend_df = trend_df.withColumn("prev_count", lag("yearly_count", 1).over(window_spec))
trend_df = trend_df.withColumn("growth_rate", when(col("prev_count").isNotNull(), ((col("yearly_count") - col("prev_count")) / col("prev_count") * 100)).otherwise(0))
trend_df = trend_df.join(type_stats, "TumorType")
trend_df.select("TumorType", "DiagnosisYear", "yearly_count", "growth_rate", "avg_age").filter(col("growth_rate") != 0).orderBy(col("growth_rate").desc()).show(15)
treatment_stats = df.groupBy("TreatmentType").agg(
avg("FollowUpMonths").alias("avg_followup"),
count(when(col("SurvivalStatus") == "存活", 1)).alias("survival_cases"),
count("*").alias("total_cases"),
stddev("FollowUpMonths").alias("std_followup")
)
treatment_stats = treatment_stats.withColumn("survival_rate", (col("survival_cases") / col("total_cases")) * 100)
treatment_stats = treatment_stats.withColumn("mortality_rate", 100 - col("survival_rate"))
treatment_stats = treatment_stats.withColumn("effect_score", col("survival_rate") * log(col("avg_followup") + 1))
treatment_stats = treatment_stats.orderBy(col("effect_score").desc())
treatment_stats.select("TreatmentType", "survival_rate", "avg_followup", "effect_score").show()六、项目文档展示

七、项目总结
总结:本系统设计并实现了一个基于大数据的车辆二氧化碳排放量可视化分析平台,利用Spark大数据处理框架,对车辆的多维度数据进行了深入的清洗、分析和挖掘。通过对品牌、车型、发动机技术及燃料类型的综合评估,系统成功揭示了各因素对碳排放的具体影响规律,并利用聚类和预测模型识别了高排放车辆特征及关键影响因子。整个项目从实际需求出发,构建了从数据接入到可视化展示的完整流程,不仅验证了大数据技术在环保领域的应用价值,也为车辆排放评估提供了一种科学、高效的分析手段。虽然系统在数据广度和算法复杂度上还有提升空间,但作为毕业设计,它基本达到了预期目标,能够为相关决策提供参考,同时也展示了处理和分析实际业务数据的能力。
大家可以帮忙点赞、收藏、关注、评论啦 👇🏻
💖🔥作者主页 :计算机毕设木哥🔥 💖