1.下载requests库
在Python中,有两个非常流行的库用于爬虫开发:
-
requests:用于发送网络请求,获取网页内容.
-
BeautifulSoup:用于解析网页内容,提取需要的数据.
先安装爬虫的必要库
pip install requests
pip install beautifulsoup4
安装成功以后可以用这个查看库的信息
pip show requests
pip show beautifulsoup4
2.简单爬虫示例
接下来,我们会编写一个简单的爬虫,从一个网页上获取数据.
2.1. 获取网页内容
第一步是使用 requests 库来获取网页的内容.我们以获取百度首页为例.
import requests
url = 'https://www.baidu.com'
response = requests.get(url)
print(response.text)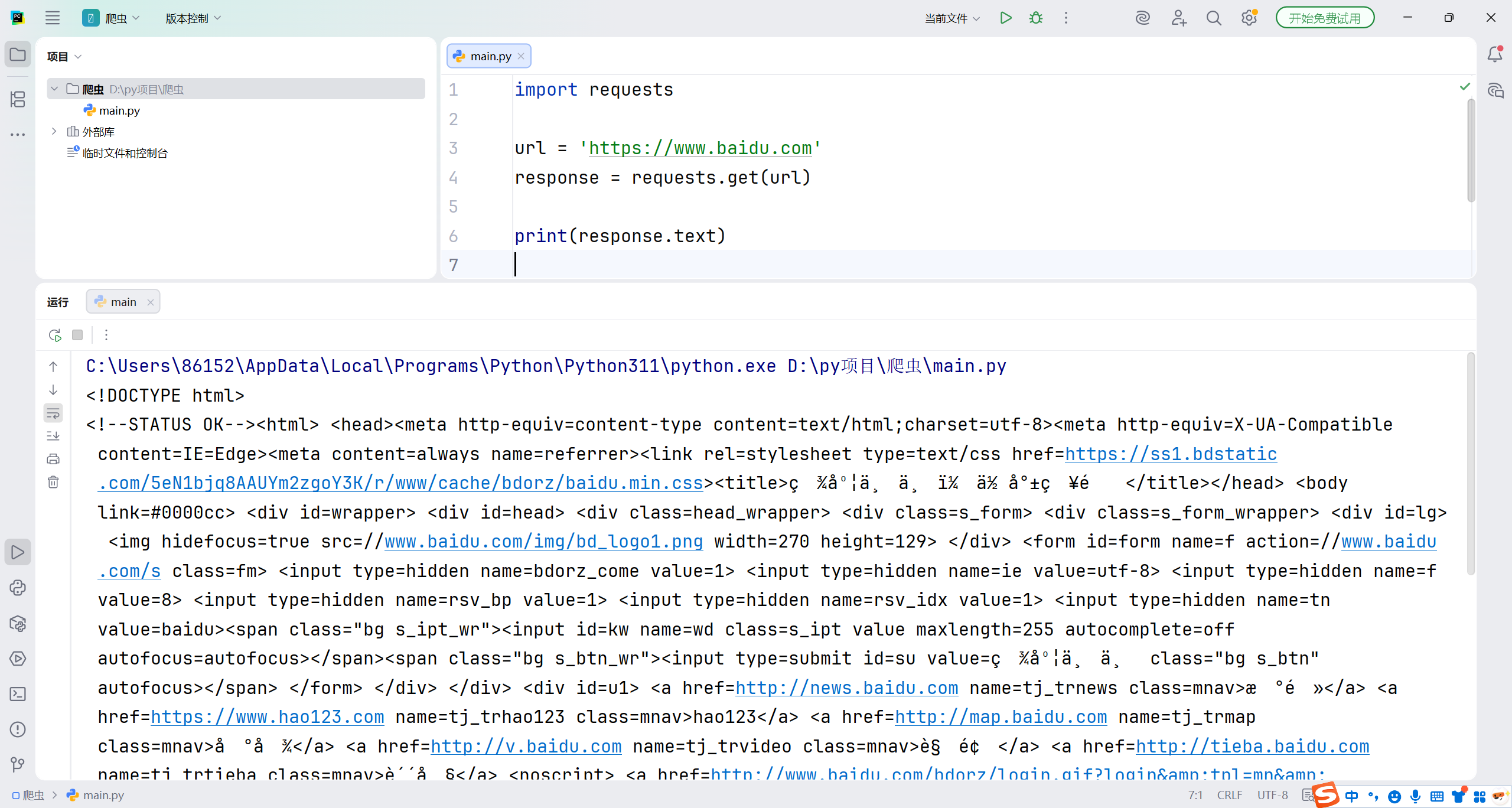
你会发现是乱码,这时候就要设置中文编码utf-8
import requests
url = 'https://www.baidu.com'
response = requests.get(url)
response.encoding = 'utf-8'
print(response.text)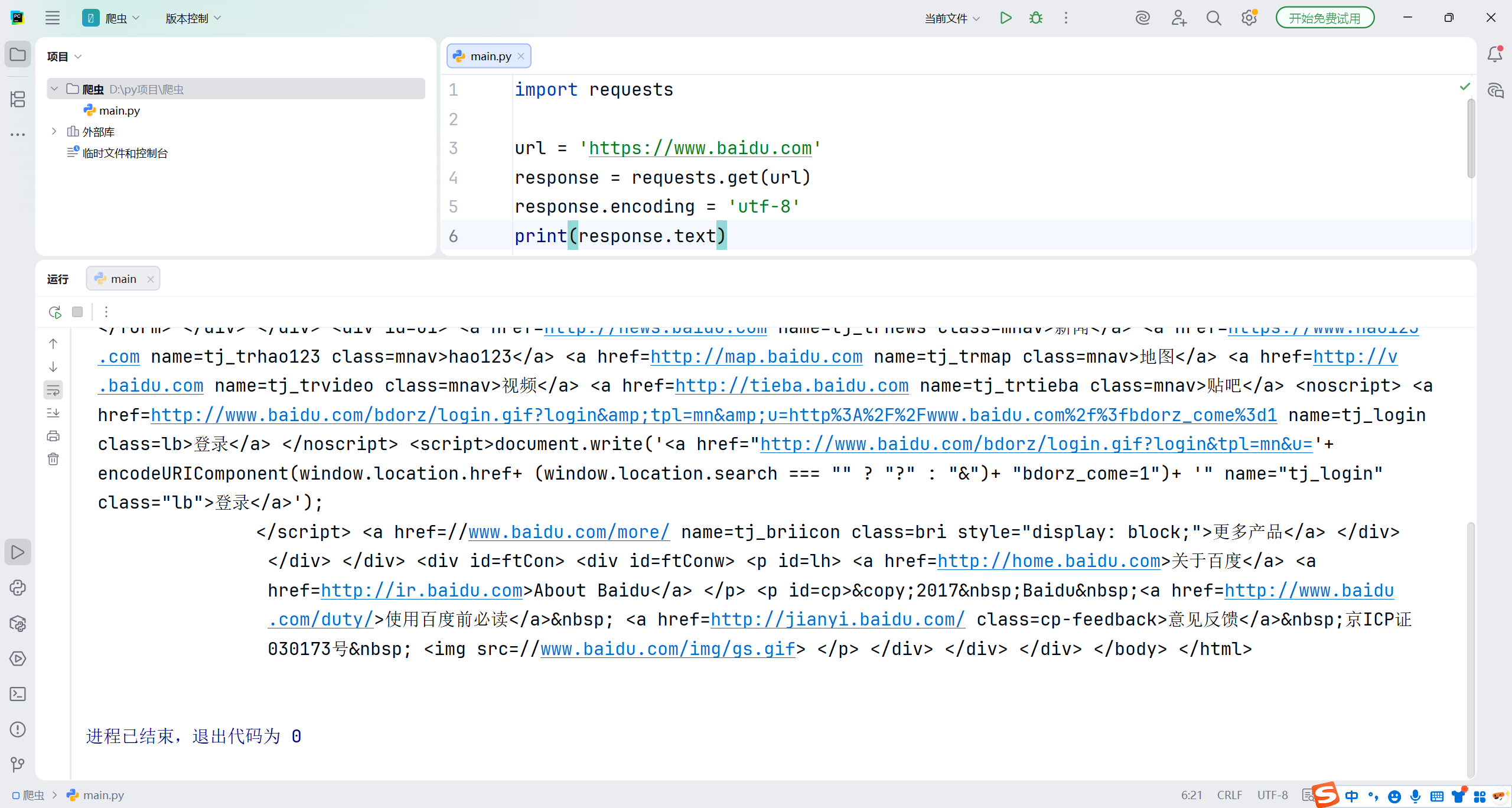
这些HTML代码,这就是百度首页的内容。
2. 2解析网页内容
获取网页内容后,我们需要用 BeautifulSoup 库来解析HTML,提取我们需要的信息,接下来我们解析百度首页的标题。
import requests
url = 'https://www.baidu.com'
response = requests.get(url)
response.encoding = 'utf-8'
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.title.text
print('网页标题:', title)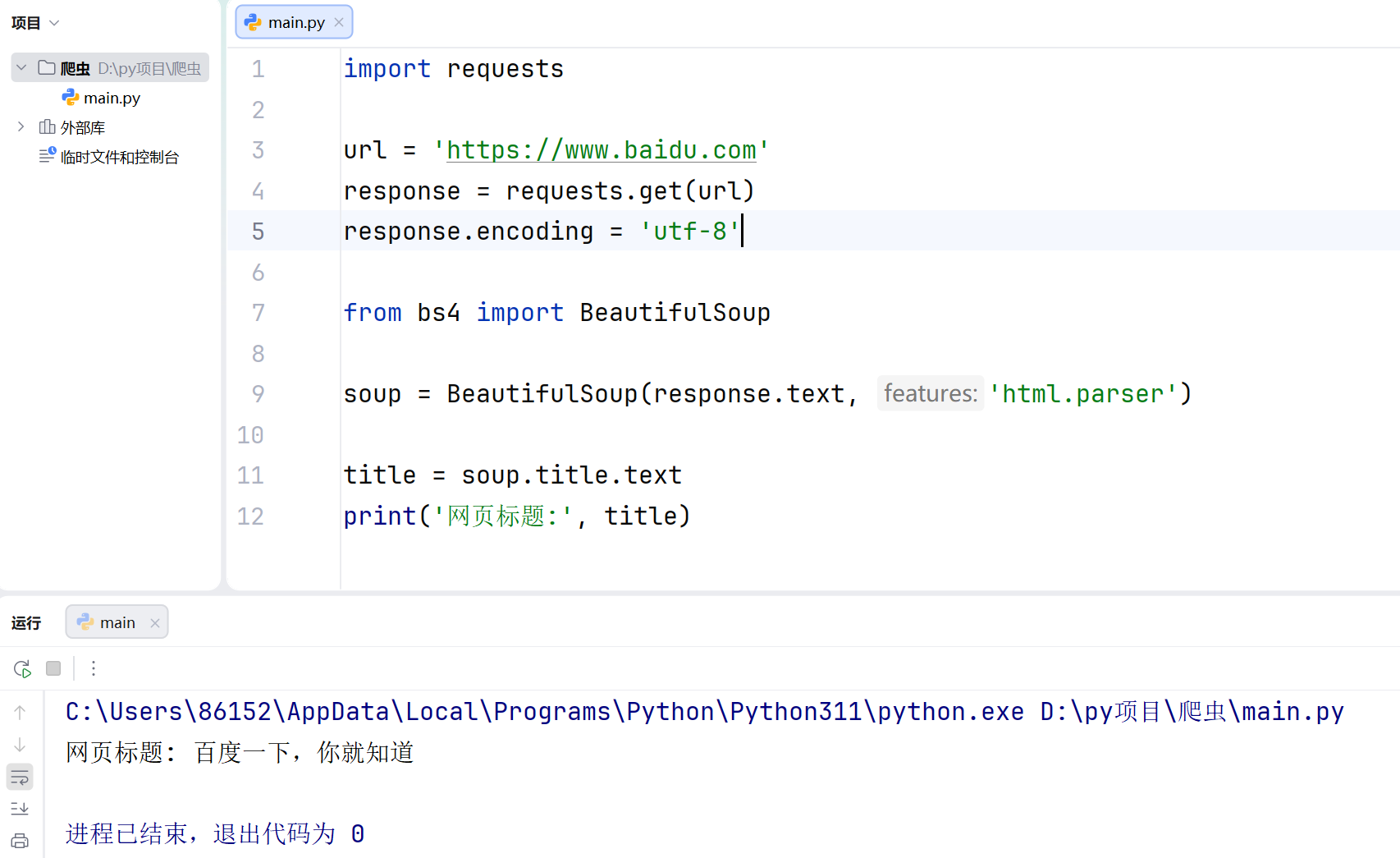
2.3. 提取更多信息
让我们继续提取网页中的链接(<a>标签中的 href 属性)。这非常有用,例如你想抓取某个网站上的所有文章链接。
import requests
url = 'https://www.baidu.com'
response = requests.get(url)
response.encoding = 'utf-8'
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.title.text
links = soup.find_all('a')
for link in links:
href = link.get('href')
print(href)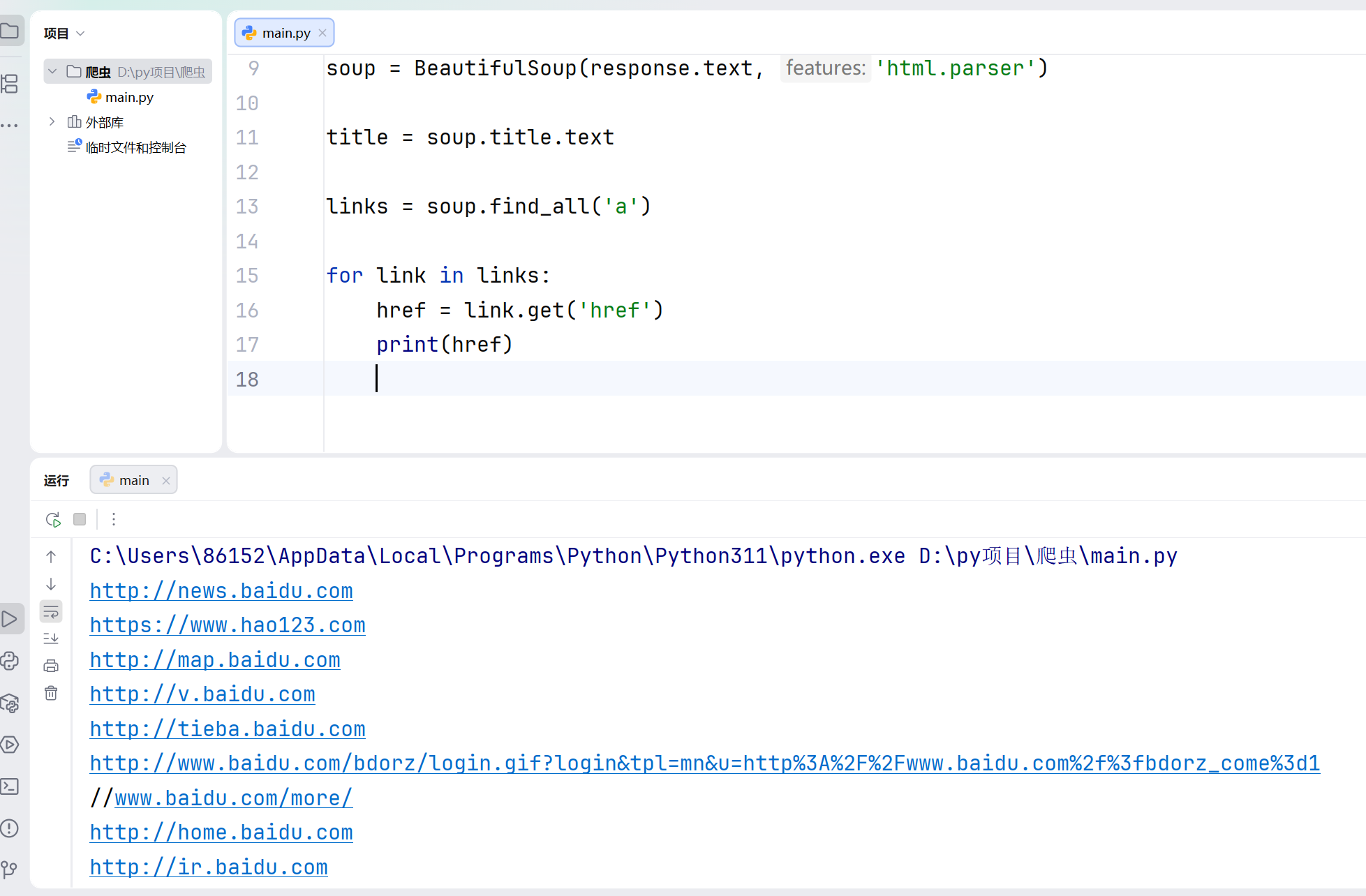
soup.find_all('a')用于获取网页中的所有链接。
link.get('href')获取每个链接的href属性,也就是网址。
日记
2月1日,星期日
无话可说
今天是单休日,我无话可说。