文章目录
摘要
本周对论文RS-STE进行了复线,在复现过程中发现了训练时间长和需要较大数据集的问题,阅读RandAR来寻找解决方法。
Abstract
This week, I revisited the paper RS-STE, and during the replication process, I found issues with long training times and the need for large datasets. I read RandAR to look for solutions.
1.实验
RS-STE的模型是一个自回归模型,由于自回归模型的原因,导致训练天然的就慢,对于原论文所提到的4M数据集和循环训练就会让训练时间很长很长。要解决这个问题,如下:
1.让预测token一次得到多个,而不是原始自回归,一个一个token的输出。
2.让模型预测得到的token更准确,更少的epoch就可以让模型收敛。
3.减少输入序列的长度,让自回归的预测计算少。
目前的结果是从下载的15k数据集上训练模型100epoch,模型在少的数据集上学习更多次,让模型有稍微的收敛,但是相比论文的数据集少了二十多倍,还需要继续完善数据集的部分。


从结果上看,得到的效果还是很差。后续将会继续完成。
2.RandAR

字节提出的RandAR,达到了相比之前的自回归生成模型的SoTA.
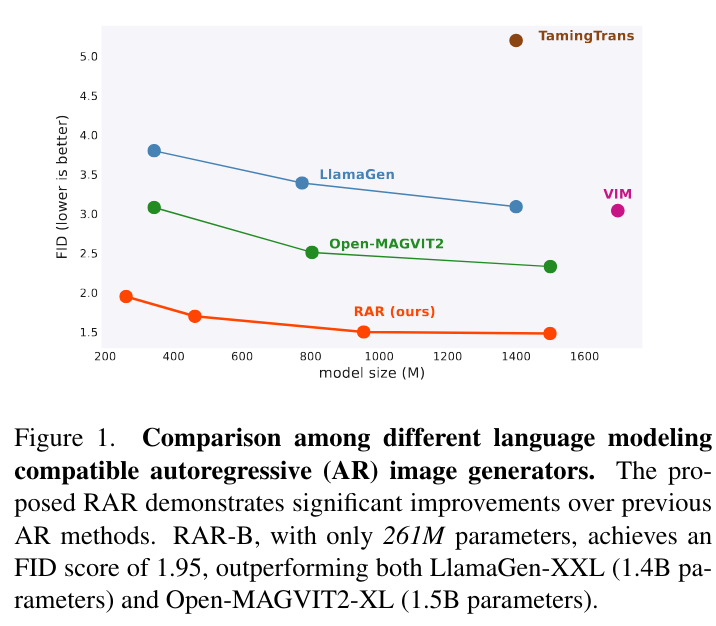
以较少的参数达到了更好的效果。
单向依赖:传统的AR模型(如GPT)使用因果注意力(causal attention),每个token只能看到它之前的token。这在处理文本时很自然(从左到右),但在处理图像时就成了瓶颈。
图像需要双向上下文:图像中的像素/图块(token)之间存在强烈的双向相关性。一个位置的像素可能依赖于它上方、下方、左侧或右侧的信息。强制使用固定的光栅扫描顺序(raster scan,逐行从左到右)会限制模型学习这种全局依赖关系的能力。
随机排列(Random Permutation)
做法:在训练过程中,对于每一个输入的图像token序列,不是每次都按照固定的光栅顺序 1, 2, 3, ..., T 来处理,而是以一定的概率 r 将其随机打乱成一个新的顺序,例如 3, 1, 5, 4, 2。
目标:模型的目标变成了最大化所有可能排列顺序下的期望似然。这意味着,在整个训练过程中,任何一个token x_t 都有机会出现在序列的任何位置,并被要求基于各种不同的上下文(可能是它左边、右边、上边、下边的token组合)来预测。

随机性退火(Randomness Annealing)
如果在整个训练过程中都使用完全随机的顺序,模型可能会难以收敛,因为排列的可能性(T!)很大,而且已知某些固定顺序(如光栅扫描)在生成时效果更好。
做法:引入一个退火参数 r。
训练初期:r = 1,模型总是使用随机排列进行训练。这有助于模型在早期就广泛地探索和学习双向上下文。
训练后期:r 线性衰减到 0。模型逐渐切换回标准的、固定的光栅扫描顺序。
训练结束:r = 0,模型完全等同于一个标准的AR模型。
效果:这个策略完美地平衡了探索(学习双向上下文)和利用(适应高效的生成顺序)。最终,模型既拥有了强大的双向建模能力,又能无缝地使用标准AR框架进行高效推理。
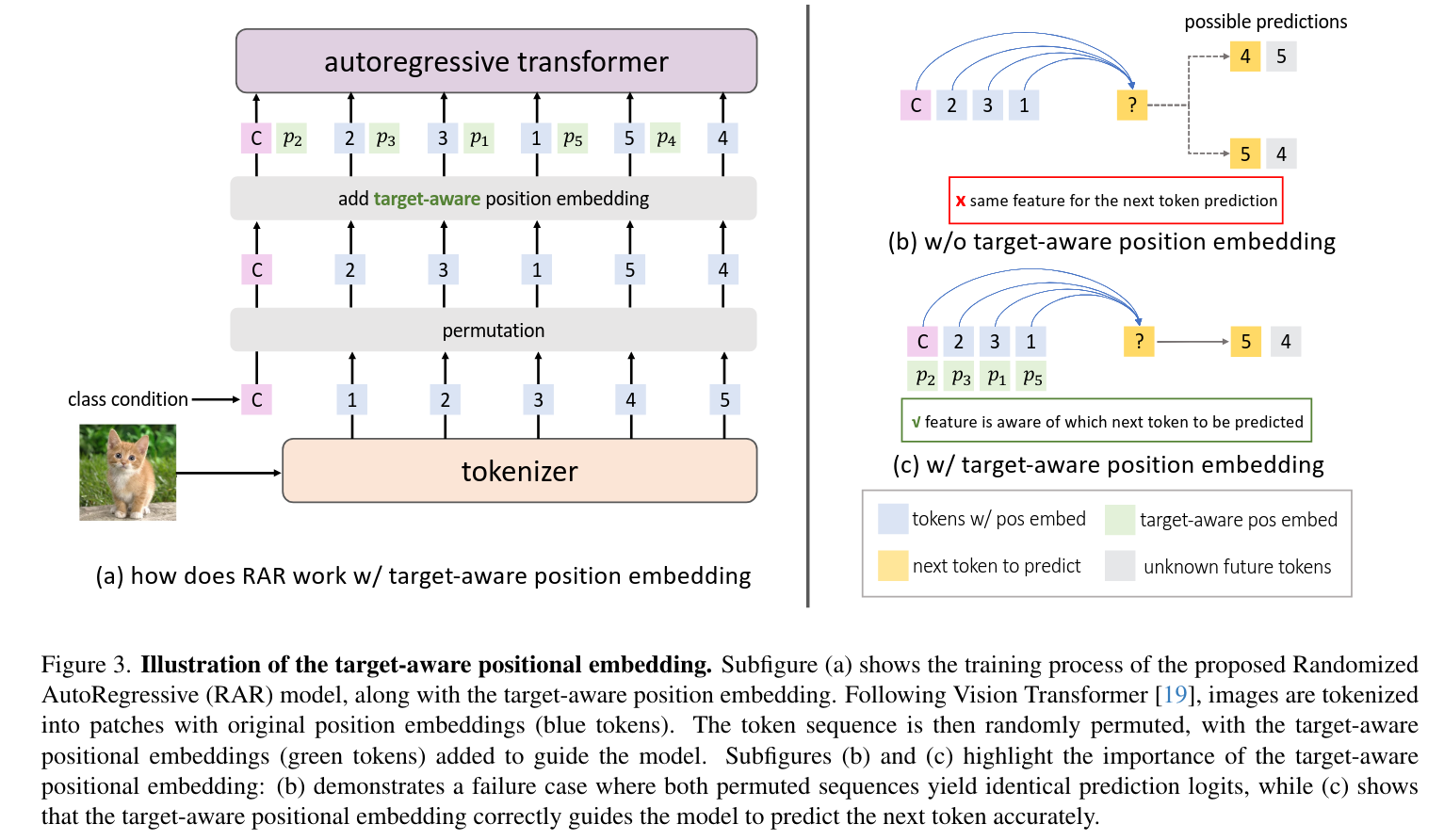
目标感知的位置编码(Target-aware Positional Embedding)
问题:在随机排列后,标准的位置编码可能会失效。例如,当模型需要预测序列中的倒数第二个token时,无论这个token原本在图像中的哪个位置,只要它的上下文相同,模型就会给出相同的预测,这是错误的。
做法:引入第二套位置编码,称为"目标感知位置编码"。在预测下一个token时,不仅会加上当前token的位置信息,还会加上"下一个要预测的token"的位置信息。
效果:这明确告诉模型现在是为哪个位置做预测,解决了因随机排列导致的位置信息混淆问题,确保了预测的准确性。
总结
RandAR对实验的优化就是通过随机化序列的预测和输入,首先融合了数据本身的归纳偏置,图像和上下左右都相关;其次,随机化序列的输入和预测,模型不是简单的一次一次的重复学习,避免了之前的"偷懒"。