文章目录
-
- [1、232 用栈实现队列](#1、232 用栈实现队列)
-
- [1. 核心原因:栈顶指针(Top)的定义](#1. 核心原因:栈顶指针(Top)的定义)
- [2. 代码执行顺序拆解](#2. 代码执行顺序拆解)
- [3. 如果误用了后缀 `stackInTop--` 会发生什么?](#3. 如果误用了后缀
stackInTop--会发生什么?) - [4. 黄金法则:入栈后缀加,出栈前缀减](#4. 黄金法则:入栈后缀加,出栈前缀减)
- 总结
- [2、225 用队列实现栈](#2、225 用队列实现栈)
-
- [1. 语法拆解](#1. 语法拆解)
- [2. 为什么在这里使用 `assert(obj)`?](#2. 为什么在这里使用
assert(obj)?) - [3. `assert` 与 `if` 的区别](#3.
assert与if的区别) - [4. 生产环境的秘密:`NDEBUG`](#4. 生产环境的秘密:
NDEBUG) - [5. 你的代码示例](#5. 你的代码示例)
- 总结
- [3、20 有效的括号](#3、20 有效的括号)
- [4、1047 删除字符串中的所有相邻重复项](#4、1047 删除字符串中的所有相邻重复项)
- [5、150 逆波兰表达式求值](#5、150 逆波兰表达式求值)
-
- **优化版:**
- [1. 逻辑闭环分析](#1. 逻辑闭环分析)
- [2. 内存与溢出的最后提醒(进阶建议)](#2. 内存与溢出的最后提醒(进阶建议))
-
- [A. 中间结果溢出](#A. 中间结果溢出)
- [B. 代码简洁度(使用 `switch`)](#B. 代码简洁度(使用
switch))
- [3. 终极优化版参考](#3. 终极优化版参考)
- [6、239 滑动窗口最大值](#6、239 滑动窗口最大值)
-
- [1. 核心思想:单调性](#1. 核心思想:单调性)
- [2. 三步走逻辑详解](#2. 三步走逻辑详解)
- [3. 举例模拟](#3. 举例模拟)
- [4. 为什么是 O ( N ) O(N) O(N) ?](#4. 为什么是 O ( N ) O(N) O(N) ?)
- [5. 注意事项](#5. 注意事项)
- [1. 为什么要"踢人"?(`while` 循环逻辑)](#1. 为什么要“踢人”?(
while循环逻辑)) - [2. 逐行代码拆解](#2. 逐行代码拆解)
- [3. 为什么是 `tail++`?(入队逻辑)](#3. 为什么是
tail++?(入队逻辑)) - [4. 形象类比:末位淘汰制](#4. 形象类比:末位淘汰制)
- [5. 这样做的好处](#5. 这样做的好处)
- [7、347 前 K 个高频元素](#7、347 前 K 个高频元素)
-
- [1. 结构体定义:建立"数字与频率"的档案](#1. 结构体定义:建立“数字与频率”的档案)
- [2. 步骤一:统计频率(填表)](#2. 步骤一:统计频率(填表))
- [3. 步骤二:建立桶(反向映射)](#3. 步骤二:建立桶(反向映射))
- [4. 步骤三:逆序收集(结果提取)](#4. 步骤三:逆序收集(结果提取))
- [5. 步骤四:内存清理(避坑必备)](#5. 步骤四:内存清理(避坑必备))
- [🌟 思维升华:为什么这个方法快?](#🌟 思维升华:为什么这个方法快?)
1、232 用栈实现队列
题目
代码
用两个栈来模拟队列
c
/*
1.两个type为int的数组(栈),大小为100
第一个栈stackIn用来存放数据,第二个栈stackOut作为辅助用来输出数据
2.两个指针stackInTop和stackOutTop,分别指向栈顶
*/
typedef struct {
int stackInTop,stackOutTop;
int stackIn[100],stackOut[100];
} MyQueue;
/*
1.开辟一个队列的大小空间
2.将指针stackInTop和stackOutTop初始化为0
3.返回开辟的队列
*/
MyQueue* myQueueCreate() {
MyQueue* queue = (MyQueue*)malloc(sizeof(MyQueue));
queue->stackInTop = 0;
queue->stackOutTop = 0;
return queue;
}
/*
将元素存入第一个栈中,存入后栈顶指针+1
*/
void myQueuePush(MyQueue* obj, int x) {
obj->stackIn[(obj->stackInTop)++] = x;
}
/*
1.若输出栈为空且当第一个栈中有元素(stackInTop>0时),将第一个栈中元素复制到第二个栈中(stackOut[stackTop2++] = stackIn[--stackTop1])
2.将栈顶元素保存
3.当stackTop2>0时,将第二个栈中元素复制到第一个栈中(stackIn[stackTop1++] = stackOut[--stackTop2])
*/
int myQueuePop(MyQueue* obj) {
//优化:复制栈顶指针,减少对内存的访问次数
int stackInTop = obj->stackInTop;
int stackOutTop = obj->stackOutTop;
//若输出栈为空
if(stackOutTop == 0){
//将第一个栈中元素复制到第二个栈中
while(stackInTop > 0){
obj->stackOut[stackOutTop++] = obj->stackIn[--stackInTop];
}
}
//将第二个栈中栈顶元素(队列的第一个元素)出栈,并保存
int top = obj->stackOut[--stackOutTop];
//将输出栈中元素放回输入栈中
while(stackOutTop > 0){
obj->stackIn[stackInTop++] = obj->stackOut[--stackOutTop];
}
//更新栈顶指针
obj->stackInTop = stackInTop;
obj->stackOutTop = stackOutTop;
//返回队列中第一个元素
return top;
}
//返回输入栈中的栈底元素
int myQueuePeek(MyQueue* obj) {
return obj->stackIn[0];
}
//若栈顶指针均为0,则代表队列为空
bool myQueueEmpty(MyQueue* obj) {
return obj->stackInTop == 0 && obj->stackOutTop == 0;
}
//将栈顶指针置0
void myQueueFree(MyQueue* obj) {
obj->stackInTop = 0;
obj->stackOutTop = 0;
}
/**
* Your MyQueue struct will be instantiated and called as such:
* MyQueue* obj = myQueueCreate();
* myQueuePush(obj, x);
* int param_2 = myQueuePop(obj);
* int param_3 = myQueuePeek(obj);
* bool param_4 = myQueueEmpty(obj);
* myQueueFree(obj);
*/时间复杂度: 都为O(1)。pop和peek看起来像O(n),实际上一个循环n会被使用n次,最后还是O(1)。
空间复杂度: O(n)
return obj->stackIn0;为什么可以直接获得栈底元素
在 C 语言中,return obj->stackIn0; 之所以能直接获得栈底元素,是因为这个栈是用 "静态数组" 实现的,而数组具有 随机访问(Random Access) 的特性。
obj->stackOutstackOutTop++ = obj->stackIn--stackInTop;为什么是先减一而不是操作结束后再减一
这个问题触及了 C 语言中**自增/自减运算符(++ 和 --)**在前缀和后缀使用时的核心差异。
简单来说:--stackInTop 是**"先减后用",而 stackInTop-- 是 "先用后减"。在栈的操作中,使用前缀 -- 是为了精准指向当前的合法数据**。
1. 核心原因:栈顶指针(Top)的定义
在代码中,stackInTop 的含义是:"下一个存放数据的位置",也就是当前栈内元素的个数。
- 初始状态 :栈为空,
stackInTop = 0。 - Push 1 次 :数据存入
index 0,然后stackInTop变成 1。 - 此时此刻:
- 栈里有一个元素。
- 但是这个元素存放在
index 0。 - 指针
stackInTop(即 1)指向的是一个空的、待写入的位置。
因此,当你想要从栈中取出(Pop)最顶上的元素时,你不能 直接访问 stackIn[1](那是空的),你必须先将指针减 1 ,退回到 index 0,才能拿到真正的数据。
2. 代码执行顺序拆解
我们把这行复合代码 obj->stackOut[stackOutTop++] = obj->stackIn[--stackInTop]; 拆解开来看:
右半部分:--stackInTop(出栈)
- 第一步 :执行
stackInTop = stackInTop - 1;(假设原来是 1,现在变成 0)。 - 第二步 :访问
obj->stackIn[0]。 - 结果:成功拿到了栈顶的合法数据。
左半部分:stackOutTop++(入栈)
- 第一步 :访问
obj->stackOut[0](此时stackOutTop还是原来的值)。 - 第二步:将刚才拿到的数据存入这个位置。
- 第三步 :执行
stackOutTop = stackOutTop + 1;(为下一次存入做准备)。
3. 如果误用了后缀 stackInTop-- 会发生什么?
假设 stackInTop = 3,数组里有 3 个元素(下标为 0, 1, 2)。
- 代码 :
obj->stackIn[stackInTop--] - 逻辑 :它会先去尝试读取
obj->stackIn[3]。 - 后果:
index 3是空的,或者存的是随机的脏数据。- 读取完这个垃圾数据后,
stackInTop才变成 2。 - 结论 :你不仅没拿到真正想拿的
index 2的数据,还越界访问了内存。
4. 黄金法则:入栈后缀加,出栈前缀减
在用数组模拟栈时,有一个非常经典的口诀,你可以记一下:
-
**入栈(Push)用后缀
++**:stack[top++] = val; -
解释:存在当前空位,存完后指向下一个空位。
-
**出栈(Pop)用前缀
--**:val = stack[--top]; -
解释:先从空位退回到有数据的位置,再取值。
总结
使用 --stackInTop 是因为 stackInTop 始终超前于实际数据一个位置。为了取到最后存入的那个数,必须先"退一步"。
2、225 用队列实现栈
题目
代码
用一个队列(单向链表)模拟栈
pop操作就是得先把n-1个元素先出队再入队,然后再把第n个元素出队即可。
结构定义:管理者与零件
-
Node_t: 链表的节点,包含数据 val 和指向下一个节点的指针 next。
-
MyStack: 栈的容器。
-
head: 指向链表的第一个节点(栈底)。
-
foot: 指向链表的最后一个节点(栈顶)。
-
size: 记录当前栈内有多少元素。
c
typedef struct Node{
int val;
struct Node *next;
}Node_t;
//用单向链表实现queue
typedef struct {
Node_t *head;
Node_t *foot;
int size;
} MyStack;
MyStack* myStackCreate() {
MyStack *obj = (MyStack*)malloc(sizeof(MyStack));
assert(obj);
obj->head = NULL;
obj->foot = NULL;
obj->size = 0;
return obj;
}
void myStackPush(MyStack* obj, int x) {
Node_t *temp = (Node_t *)malloc(sizeof(Node_t));
assert(temp);
temp->val = x;
temp->next = NULL;
//添加至queue末尾
if(obj->foot){
obj->foot->next = temp;
}
else{
obj->head = temp;
}
obj->foot = temp;
obj->size++;
}
int myStackPop(MyStack* obj) {
//获取末尾元素
int target = obj->foot->val;
if(obj->head == obj->foot){
free(obj->foot);
obj->head = NULL;
obj->foot = NULL;
}else{
Node_t *prev = obj->head;
//移动至queue尾部节点前一个节点
while(prev->next != obj->foot){
prev = prev->next;
}
free(obj->foot);
obj->foot = prev;
obj->foot->next = NULL;
}
obj->size--;
return target;
}
int myStackTop(MyStack* obj) {
return obj->foot->val;
}
bool myStackEmpty(MyStack* obj) {
return obj->size == 0;
}
void myStackFree(MyStack* obj) {
Node_t *curr = obj->head;
while(curr != NULL){
Node_t *temp = curr->next;
free(curr);
curr = temp;
}
free(obj);
}
/**
* Your MyStack struct will be instantiated and called as such:
* MyStack* obj = myStackCreate();
* myStackPush(obj, x);
* int param_2 = myStackPop(obj);
* int param_3 = myStackTop(obj);
* bool param_4 = myStackEmpty(obj);
* myStackFree(obj);
*/时间复杂度: pop为O(n),top为O(n),其他为O(1)
空间复杂度: O(n)
详解assert(obj);
在 C 语言中,assert(obj); 是一个**断言(Assertion)**语句。它的核心作用是:确保某个条件必须为真,如果为假,程序立即崩溃并报错。
在上述代码上下文中,它是用来检查内存分配是否成功的。
1. 语法拆解
assert 定义在 <assert.h> 头文件中。
- 如果
obj不为 NULL:程序继续正常运行,什么都不会发生。 - 如果
obj为 NULL:程序会立即终止运行(Abort),并在控制台(标准错误输出)打印出一条错误信息,告诉你在哪一个文件的哪一行、哪一个函数里出了错。
2. 为什么在这里使用 assert(obj)?
在 myStackCreate 函数中:
c
MyStack *obj = (MyStack*)malloc(sizeof(MyStack));
assert(obj);- 内存分配风险 :
malloc申请内存时,如果系统内存极其紧张(虽然在刷题或普通 PC 上很少见),malloc会返回NULL。 - 防止"空指针异常" :如果没有这行
assert,一旦内存分配失败,后面的obj->head = NULL;就会尝试操作一个空地址,导致程序产生难以调试的"段错误(Segmentation Fault)"。 - 调试利器 :
assert就像是一个"报警器"。它告诉开发者:"这里绝对不能出问题,如果出了问题,一定是系统环境或者逻辑出了巨大的 Bug,请立刻修好它!"
3. assert 与 if 的区别
你可能会想,为什么不写 if (obj == NULL) return NULL; 呢?
| 特性 | assert |
if 检查 |
|---|---|---|
| 目的 | 捕获 "不应该发生的" 编程错误。 | 处理 "可能发生的" 业务逻辑(如非法输入)。 |
| 行为 | 直接终止程序。 | 优雅地返回错误码或跳过。 |
| 性能 | 可以通过编译参数一次性全部关闭,不占运行时间。 | 永远存在于代码中。 |
4. 生产环境的秘密:NDEBUG
assert 有一个神奇的特性:它只在调试(Debug)模式 下生效。
如果你在编译时加上 -DNDEBUG 选项,所有的 assert 语句都会被编译器直接删掉,完全不占用运行速度。因此,它是开发者在开发阶段保护逻辑的"脚手架"。
5. 你的代码示例
c
void myStackPush(MyStack* obj, int x) {
Node_t *temp = (Node_t *)malloc(sizeof(Node_t));
assert(temp); // 如果申请新节点失败,直接报警停机
...
}这保证了你的链表在每一个节点创建时都是安全的。
总结
assert(obj); 的意思是:"我断定 obj 绝对不是空指针。如果是,那就别跑了,直接告诉我哪行代码坏了。"
3、20 有效的括号
题目
先分析好有哪几种不匹配的情况:

代码
c
//辅助函数:判断栈顶元素与输入的括号是否为一对。若不是,则返回False
int notMatch(char par,char* stack,int stackTop){
switch(par){
case ']':
return stack[stackTop - 1] != '[';
case ')':
return stack[stackTop - 1] != '(';
case '}':
return stack[stackTop - 1] != '{';
}
return 0;
}
bool isValid(char* s) {
int strLen = strlen(s);
//开辟栈空间
char stack[10000];
int stackTop = 0;
//遍历字符串
int i;
for(i = 0;i < strLen;i++){
//取出当前下标所对应字符
char tempChar = s[i];
//若当前字符为左括号,则入栈
if(tempChar == '(' || tempChar == '[' || tempChar == '{'){
stack[stackTop++] = tempChar;
}
//若当前字符为右括号,且栈中无元素或右括号与栈顶元素不符,返回False
else if(stackTop == 0 || notMatch(tempChar,stack,stackTop)){
return 0;
}
//当前字符与栈顶元素为一对括号,将栈顶元素出栈
else{
stackTop--;
}
}
//若栈中有元素,返回False。若没有元素(stackTop为0),返回True
return !stackTop;
}时间复杂度:O(n)
空间复杂度:O(n)
封装的notMatch这段代码是解决"有效括号"(Valid Parentheses)算法题中的一个核心辅助函数。它的作用是:当遇到右括号时,检查它与栈顶最近的左括号是否能"配对"。
1. 核心逻辑拆解
这个函数的核心在于逻辑判断的"反转":它不是在问"它们匹配吗?",而是在问它们不匹配吗?。
-
输入参数:
-
char par:当前遍历到的右括号(可能是)、]或})。 -
char* stack:存储左括号的字符数组(栈)。 -
int stackTop:栈顶指针(指向下一个待存入的位置,所以stackTop - 1才是当前栈顶元素)。 -
返回值:
-
返回
1(True):表示不匹配 ,说明括号顺序错了(比如(])。 -
返回
0(False):表示匹配,说明是一对合法的括号。
2. 逐行详解
栈顶元素的定位
c
stack[stackTop - 1]在你的程序中,stackTop 始终指向"空位"。因此,如果你想看最后放进去的那个左括号,必须往后退一步。
switch 语句匹配规则
- 如果是
]:它去检查栈顶是不是[。如果不是 (使用!=),说明不匹配,返回1。 - 如果是
):同理检查栈顶是不是(。 - 如果是
}:检查栈顶是不是{。
默认返回值
c
return 0;如果传入的 par 不是右括号(虽然在逻辑严谨的程序中通常不会发生),或者匹配成功了,函数最后返回 0。
3. 为什么这样写很有用?
在主函数中,你会这样调用它:
c
if (notMatch(s[i], stack, stackTop)) {
return false; // 只要发现一个不匹配,整个字符串就是无效的
}这种设计让主代码变得非常整洁。它体现了**"早期返回"(Early Return)**的思想:一旦发现错误(不匹配),立刻上报。
总结
这是一个典型的逻辑谓词函数 。它利用 switch 处理了三种不同的括号情况,并通过 stackTop - 1 精准捕捉最近的左括号进行比对。
另解一:
c
bool isValid(char* s) {
char mp[128] = {};
mp[')'] = '(';
mp[']'] = '[';
mp['}'] = '{';//在数组 mp 的第 125 个位置,存入数值 123。
int top = 0;//直接把s当作栈
for(int i = 0;s[i];i++){
char c = s[i];
if(mp[c] == 0){//c是左括号
s[top++] = c;//入栈
}else if(top == 0 || s[--top] != mp[c]){//c是右括号
return false;//没有左括号,或者左括号类型不对
}
}
return top == 0;//所有左括号必须匹配完毕
}另解二:
感觉这种比较直观,也好理解~
c
bool isValid(char* s) {
int top = 0;//直接把s当作栈
for(int i = 0;s[i];i++){
char c = s[i];
if(c == '('){
s[top++] = ')';//入栈对应的右括号
}else if(c == '['){
s[top++] = ']';
}else if(c == '{'){
s[top++] = '}'
}else if(top == 0 || s[--top] != c){//c是右括号
return false;//没有左括号,或者左括号类型不对
}
}
return top == 0;//所有左括号必须匹配完毕
}4、1047 删除字符串中的所有相邻重复项
题目
代码
c
char* removeDuplicates(char* s) {
int strLen = strlen(s);
char* stack = (char*)malloc(sizeof(char)*(strLen+1));
int stackTop = 0;
int index = 0;
while(index < strLen){
char letter = s[index++];
if(stackTop > 0 && letter == stack[stackTop-1]){
stackTop--;
}
else{
stack[stackTop++] = letter;
}
}
stack[stackTop] = '\0';
return stack;
}思路:利用栈来处理相邻重复项。当你发现当前字符与栈顶字符相同时,就说明它们是"相邻重复"的,应该一起抵消。
逐行图解
假设输入为 s = "abbaca":
-
遇到 'a' :栈为空,入栈。
stack = [a],stackTop = 1。 -
遇到 'b' :栈顶是 'a',不相等,入栈。
stack = [a, b],stackTop = 2。 -
遇到 'b' :栈顶是 'b',相等! 执行
stackTop--。此时stackTop变为 1。 -
你的原代码:
if里减到 1,花括号里又减到 0,导致 'a' 也没了。 -
遇到 'a' :此时栈顶是 'a'(刚才剩下的),相等! 执行
stackTop--。此时stackTop变为 0。 -
遇到 'c' :栈为空,入栈。
stack = [c],stackTop = 1。 -
遇到 'a' :栈顶是 'c',不相等,入栈。
stack = [c, a],stackTop = 2。
最终结果 :"ca"。
时间复杂度:O(n)
空间复杂度:O(n)
另解:
双指针法,代码和栈其实很类似,但是双指针的时间复杂度更低。
c
char* removeDuplicates(char* s) {
int slow = 0;
int fast = 0;
int strLen = strlen(s);
while(fast < strLen){
char letter = s[slow] = s[fast++];
if(slow > 0 && letter == s[slow-1]){
slow--;
}
else{
slow++;
}
}
s[slow] = '\0';
return s;
}时间复杂度:O(n)
空间复杂度:O(1)
5、150 逆波兰表达式求值
题目
代码
使用栈,如果遇到算符就弹出栈顶两个数然后运算,将结果入栈,如果遇到数符就直接入栈。
c
int evalRPN(char** tokens, int tokensSize) {
int stack[10001];
int stackTop = 0;
int i = 0;
while(i < tokensSize){
char* temp = tokens[i];
if(strlen(temp) == 1 && temp[0] == '+'){
int nums1 = stack[stackTop-1];
int nums2 = stack[stackTop-2];
stackTop = stackTop-2;
stack[stackTop++] = nums1+nums2;
}
else if(strlen(temp) == 1 && temp[0] == '-'){
int nums1 = stack[stackTop-1];
int nums2 = stack[stackTop-2];
stackTop = stackTop-2;
stack[stackTop++] = nums2-nums1;
}
else if(strlen(temp) == 1 && temp[0] == '*'){
int nums1 = stack[stackTop-1];
int nums2 = stack[stackTop-2];
stackTop = stackTop-2;
stack[stackTop++] = nums1*nums2;
}
else if(strlen(temp) == 1 && temp[0] == '/'){
int nums1 = stack[stackTop-1];
int nums2 = stack[stackTop-2];
stackTop = stackTop-2;
stack[stackTop++] = nums2/nums1;
}
else{
stack[stackTop++] = atoi(temp);
}
i++;
}
int result = stack[stackTop-1];
return result;
}时间复杂度:O(n)
空间复杂度:O(n)
优化版:
1. 逻辑闭环分析
- 正数入栈 :
"123"长度为 3,进入else,atoi转换成功。 - 负数入栈 :
"-11"长度为 3,进入else,atoi转换成功。 - 运算符执行 :
"-"长度为 1 且字符匹配,执行减法。 - 运算顺序 :
nums2 - nums1和nums2 / nums1保证了非交换律运算的正确性。
2. 内存与溢出的最后提醒(进阶建议)
虽然你的逻辑已经能通过大部分测试用例,但在 C 语言的实际面试或竞赛中,有两点细微的优化可以让你的代码更"硬核":
A. 中间结果溢出
力扣的 150 题有些极端用例,其乘法结果可能会超过 int 的范围( 到 )。
- 建议 :将栈的类型改为
long long,或者在运算时强制转换。
B. 代码简洁度(使用 switch)
当 if-else 分支变多时,使用 switch 不仅让代码更好读,编译器生成的汇编指令通常也更高效。
3. 终极优化版参考
如果你追求极致的简洁和稳健,可以参考下面的写法:
c
#include <stdlib.h>
#include <string.h>
int evalRPN(char** tokens, int tokensSize) {
long long stack[tokensSize]; // 栈大小刚好等于 token 数量即可
int top = 0;
for (int i = 0; i < tokensSize; i++) {
char* s = tokens[i];
// 如果是运算符(长度为 1 且不是数字)
if (strlen(s) == 1 && (s[0] < '0' || s[0] > '9')) {
long long n1 = stack[--top];
long long n2 = stack[--top];
switch (s[0]) {
case '+': stack[top++] = n2 + n1; break;
case '-': stack[top++] = n2 - n1; break;
case '*': stack[top++] = n2 * n1; break;
case '/': stack[top++] = n2 / n1; break;
}
} else {
stack[top++] = atoll(s); // 使用 atoll 处理长整数
}
}
return (int)stack[0];
}6、239 滑动窗口最大值
题目
代码
暴力解:超出时间限制了
c
/**
* Note: The returned array must be malloced, assume caller calls free().
*/
int* maxSlidingWindow(int* nums, int numsSize, int k, int* returnSize) {
int a = numsSize-k+1;
*returnSize = a;
int index = 0;
int* res = (int*)malloc(sizeof(int)*(a));
for(int i = 0; i < a;i++){
int max = nums[i];
for(int j = 0;j < k;j++){
if(nums[i+j] > max){
max = nums[i+j];
}
}
res[index++] = max;
}
return res;
}时间复杂度:O(NxK)
空间复杂度:O(N)
单调栈法
c
int* maxSlidingWindow(int* nums, int numsSize, int k, int* returnSize) {
int* res = (int*)malloc(sizeof(int) * (numsSize - k + 1));
int* deque = (int*)malloc(sizeof(int) * numsSize); // 存储下标
int head = 0, tail = 0; // 队头队尾指针
*returnSize = 0;
for (int i = 0; i < numsSize; i++) {
// 1. 入队:维持队列单调递减
while (tail > head && nums[i] >= nums[deque[tail - 1]]) {
tail--;
}
deque[tail++] = i;
// 2. 出队:检查队首元素是否已经在窗口之外
if (deque[head] <= i - k) {
head++;
}
// 3. 记录答案:当窗口形成(达到k个)后开始记录
if (i >= k - 1) {
res[(*returnSize)++] = nums[deque[head]];
}
}
free(deque);
return res;
}时间复杂度:O(N)
空间复杂度:O(N)
这段代码是解决"滑动窗口最大值"问题的最优解 ,采用了**单调双端队列(Monotonic Deque)**算法。它的精妙之处在于将原本需要 O ( N × K ) O(N \times K) O(N×K) 的暴力计算优化到了 O ( N ) O(N) O(N)。
以下是这段代码的深度拆解:
1. 核心思想:单调性
队列 deque 存储的是数组的下标 ,但它维护了一个重要的性质:下标对应的元素值是严格递减的。
- 为什么要存下标? 因为下标既能让我们找到值(
nums[i]),又能让我们判断这个元素是否已经"过期"(超出了当前 k 长度的窗口)。 - 为什么要递减? 如果新来的数比队尾的数大,那么队尾的数永远不可能成为后续窗口的最大值了(因为它既比新数小,又比新数早过期)。所以,我们可以放心地把它踢走。
2. 三步走逻辑详解
第一步:维持单调递减(入队)
c
while (tail > head && nums[i] >= nums[deque[tail - 1]]) {
tail--;
}
deque[tail++] = i;- 逻辑 :当新元素
nums[i]准备进队时,观察队尾。只要队尾元素比nums[i]小,就执行tail--(弹出队尾)。 - 结果:新元素入队后,队列依然保持从大到小的顺序。
第二步:清理过期元素(出队)
c
if (deque[head] <= i - k) {
head++;
}- 场景:窗口向右滑动了,我们需要检查队首(当前最大值的下标)是否还在窗口范围内。
- 计算 :当前窗口的范围是 i − k + 1 , i i-k+1, i i−k+1,i 。如果队首下标
deque[head]≤ i − k \le i - k ≤i−k,说明它已经在左边界之外了,必须通过head++将其弹出。
第三步:记录答案
c
if (i >= k - 1) {
res[(*returnSize)++] = nums[deque[head]];
}- 逻辑 :只有当遍历到第 k 个元素(下标 k-1)时,第一个窗口才正式形成,此后每滑动一步,队首
nums[deque[head]]都是当前窗口的王者。
3. 举例模拟
假设 nums = [1, 3, -1, -3, 5], k = 3:
步数 i |
当前值 | 队列操作 (下标) | 队列对应值 | 最大值 (队首) |
|---|---|---|---|---|
| 0 | 1 | 入队 [0] |
[1] |
- (未满k) |
| 1 | 3 | 踢走 0,入队 [1] |
[3] |
- (未满k) |
| 2 | -1 | 入队 [1, 2] |
[3, -1] |
3 |
| 3 | -3 | 入队 [1, 2, 3] |
[3, -1, -3] |
3 |
| 4 | 5 | 踢走 3,2,1,入队 [4] |
[5] |
5 |
4. 为什么是 O ( N ) O(N) O(N) ?
虽然代码里有 for 循环嵌套 while 循环,看起来像 O ( N 2 ) O(N^2) O(N2),但请注意:
- 每个下标最多进队一次,出队一次。
tail++和tail--/head++的总操作次数加起来不会超过 2 N 2N 2N。- 因此,平均时间复杂度是**线性的 O ( N ) O(N) O(N) **。
5. 注意事项
- 内存申请 :
deque数组大小设为numsSize是安全的上限。 - 指针操作 :使用
res[(*returnSize)++]是 C 语言返回动态数组的标准写法,既填充了数据,又记录了最终的数组长度。
这段代码是滑动窗口类问题的"天花板"解法。
// 1. 入队:维持队列单调递减
while (tail > head && numsi >= numsdeque\[tail - 1]) {
tail--;
}
dequetail++ = i;
这段代码是单调队列算法的"灵魂"。它的目的非常明确:保证队列里的元素永远是从大到小排列的,并且及时踢掉那些"没有前途"的竞争者。
为了让你彻底理解,我们把它拆开来看:
1. 为什么要"踢人"?(while 循环逻辑)
在这个逻辑中,队列存储的是下标。当我们准备把当前元素 nums[i] 放入队列时,它会先观察队尾:
-
如果
nums[i]比队尾元素大 :这意味着队尾的那个旧元素永远不可能成为最大值了。
-
原因 1 :它比
nums[i]小。 -
原因 2 :它比
nums[i]老(更早滑出窗口)。既然
nums[i]又强又年轻,只要它还在窗口里,旧的队尾就没机会了。所以执行tail--,直接把它从队尾剔除。 -
重复这个过程 :
直到队列为空,或者遇到一个比
nums[i]还要大的元素,才停止剔除。
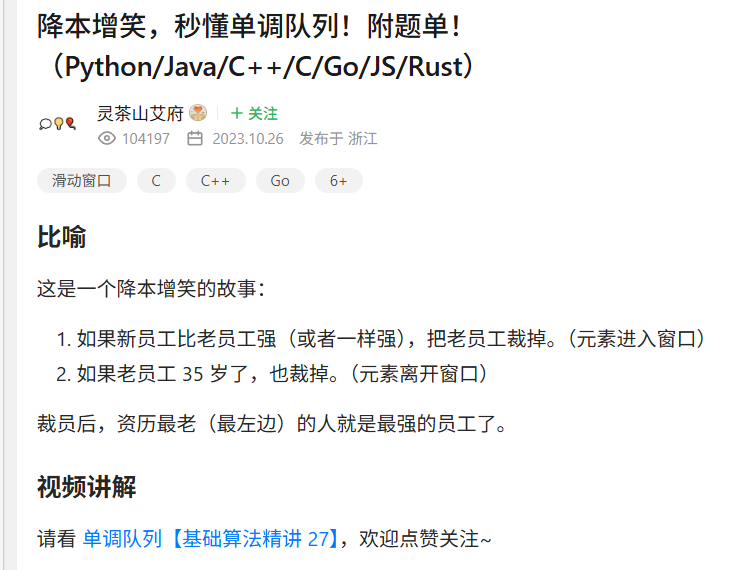
哈哈哈哈哈这个比喻有点儿难绷
2. 逐行代码拆解
c
while (tail > head && nums[i] >= nums[deque[tail - 1]]) {
tail--;
}tail > head:
确保队列不是空的。如果队列空了,就没法跟队尾比较了。nums[i] >= nums[deque[tail - 1]]:
deque[tail - 1]是当前队尾元素的下标。nums[deque[tail - 1]]就是那个队尾元素的值。- 只要当前值大于等于队尾值,就执行
tail--。
tail--:
这相当于从队尾"弹栈"。我们不需要真正删除数组数据,只需要把指针往回挪一格,下次写入就会覆盖它。
3. 为什么是 tail++?(入队逻辑)
c
deque[tail++] = i;当所有的"竞争者"都被踢走后,nums[i] 的下标 i 终于可以入队了。
- 把它放在当前
tail的位置。 tail++让指针指向下一个空位。- 由于之前踢走了所有比它小的数,此时队列依然保持了**从大到小(单调递减)**的性质。
4. 形象类比:末位淘汰制
想象这是一个"最有潜力球员"名单:
- 新球员 (
nums[i])进场了。 - 他看了一眼名单上排在最后的老球员 (
nums[deque[tail-1]])。 - 如果新球员比老球员更有实力(数值更大),老球员就被开除了(
tail--),因为只要新球员在,老球员就永远没机会上头条。 - 新球员会一直往前比,直到遇到一个比他更强的大神。
- 最后,新球员把自己写在名单末尾(
deque[tail++] = i)。
5. 这样做的好处
这样处理后,队首(head 位置)永远存储着当前窗口内实力最强(数值最大)的下标 。你不需要每次都去遍历窗口找最大值,只需要看一眼队首,时间复杂度直接从 O ( K ) O(K) O(K) 降到了 O ( 1 ) O(1) O(1) 。
其实上面讲的很好,本来不需要这个细节讲解的,唉,还是需要继续静下心来学习~不过搞懂了一道hard题开心开心!
7、347 前 K 个高频元素
题目
代码
c
/**
* Note: The returned array must be malloced, assume caller calls free().
*/
typedef struct{
int key; //数字本身
int count; //出现的频率
UT_hash_handle hh; //让结构体具备哈希表退化的能力
}HashNode;
int* topKFrequent(int* nums, int numsSize, int k, int* returnSize) {
HashNode *hashTable = NULL,*currNode,*tmp;
//步骤一:统计频率
for(int i = 0;i < numsSize;i++){
HASH_FIND_INT(hashTable,&nums[i],currNode);
if(currNode == NULL){
currNode = (HashNode*)malloc(sizeof(HashNode));
currNode->key = nums[i];
currNode->count = 1;
HASH_ADD_INT(hashTable,key,currNode);
}else{
currNode->count++;
}
}
//步骤二:建立桶
//桶的下标i代表频率,内容是具有该频率的数字列表
//为了节省空间并处理动态长度,我们使用二维指针
int** buckets = (int**)calloc(numsSize+1,sizeof(int*));
int* bucketSizes = (int*)calloc(numsSize+1,sizeof(int));
//遍历哈希表,将数字放入对应的"频率桶"中
HASH_ITER(hh,hashTable,currNode,tmp){
int freq = currNode->count;
bucketSizes[freq]++;
//根据当前桶的大小动态分配/重分配空间
buckets[freq] = (int*)realloc(buckets[freq],sizeof(int)*bucketSizes[freq]);
buckets[freq][bucketSizes[freq]-1] = currNode->key;
}
//步骤三:逆序收集结果
int* result = (int*)malloc(sizeof(int)*k);
int resCount = 0;
//从频率最高的桶(numsSize)开始倒序遍历
for(int i = numsSize;i >= 0 && resCount < k;i--){
if(bucketSizes[i] > 0){
for(int j = 0;j < bucketSizes[i] && resCount < k;j++){
result[resCount++] = buckets[i][j];
}
}
}
//步骤四:清理内存
//释放哈希表
HASH_ITER(hh,hashTable,currNode,tmp){
HASH_DEL(hashTable,currNode);
free(currNode);
}
//释放各个桶
for(int i = 0;i <= numsSize;i++){
if(buckets[i]) free(buckets[i]);
}
free(buckets);
free(bucketSizes);
*returnSize = k;
return result;
}太难了ε=(´ο`*)))唉,不仅要自己写哈希表还得自己建桶
下面给出代码得详细解释from gimini老师
这段代码是一个非常标准且高效的**桶排序(Bucket Sort)**实现。它的核心智慧在于:利用数组下标来表示"频率",从而把排序问题转化为了查找问题。
1. 结构体定义:建立"数字与频率"的档案
c
typedef struct{
int key; // 档案的主键:数字本身
int count; // 档案的内容:出现的次数
UT_hash_handle hh; // 挂载工具:让结构体支持哈希操作
} HashNode;- 为什么要这么写? C 语言原生数组只能用整数做下标。如果输入的数字是
1000000或者是负数,数组就存不下了。哈希表(uthash)能让我们把任意数字映射到一个小空间里。
2. 步骤一:统计频率(填表)
c
for(int i = 0; i < numsSize; i++){
HASH_FIND_INT(hashTable, &nums[i], currNode); // 看看这个数在档案里吗?
if(currNode == NULL){ // 如果是新面孔
currNode = (HashNode*)malloc(sizeof(HashNode));
currNode->key = nums[i];
currNode->count = 1;
HASH_ADD_INT(hashTable, key, currNode); // 录入档案
}else{
currNode->count++; // 如果是老面孔,频率加 1
}
}- 推演逻辑 :通过这一步,我们将原始数组
[1, 1, 1, 2, 2, 3]转化为了哈希表1 -> 3, 2 -> 2, 3 -> 1。
3. 步骤二:建立桶(反向映射)
这是最巧妙的一步,将"频率"变为"索引"。
c
int** buckets = (int**)calloc(numsSize + 1, sizeof(int*));
int* bucketSizes = (int*)calloc(numsSize + 1, sizeof(int));- 观察点 :
buckets是一个二维数组。buckets[i]存储的是所有出现了i次的数字。 - 内存管理 :使用
calloc是为了把所有桶初始化为空(NULL/0),防止野指针。
c
HASH_ITER(hh, hashTable, currNode, tmp){
int freq = currNode->count; // 拿到当前数字的频率
bucketSizes[freq]++; // 这个频率桶里的成员又多了一个
// 动态扩容:给这个频率桶分个位置给当前数字
buckets[freq] = (int*)realloc(buckets[freq], sizeof(int) * bucketSizes[freq]);
buckets[freq][bucketSizes[freq] - 1] = currNode->key; // 把数字塞进去
}- 核心逻辑 :遍历哈希表,如果数字
1出现了3次,就把1丢进buckets[3]。
4. 步骤三:逆序收集(结果提取)
c
for(int i = numsSize; i >= 0 && resCount < k; i--){ // 从最大的可能频率往下找
if(bucketSizes[i] > 0){ // 如果这个频率桶里有数字
for(int j = 0; j < bucketSizes[i] && resCount < k; j++){
result[resCount++] = buckets[i][j]; // 挨个取出,直到凑够 k 个
}
}
}- 观察切入点 :为什么从
numsSize开始?因为最极端的频率就是所有数字都一样。 - 推演过程 :我们先看最右边的桶(频率最高),把里面的数字拿出来,再看左边一点的,直到填满
result。
5. 步骤四:内存清理(避坑必备)
在 C 语言中,malloc 和 free 必须成对出现。这段代码清理了三层内存:
- 哈希表节点:统计完就没用了。
- 桶内部的小数组 :
buckets[i]里的具体数字列表。 - 桶数组本身 :
buckets指针数组。
🌟 思维升华:为什么这个方法快?
如果不加思考,我们可能会想:"先统计频率,再对频率排序"。
- 排序的代价 :即使是用快排,也要 O ( N log N ) O(N \log N) O(NlogN) 。
- 桶的优势 :因为频率是有范围的 (一定是 1 到 n ),所以我们可以用一个长度为 n+1 的数组作为"天然的排序器"。扫描一遍,顺序就自动出来了。这就是 O ( n ) O(n) O(n) 时间复杂度的秘诀。
时间复杂度:O(N)
空间复杂度:O(N)