第一章 自然语言处理入门
什么是NLP?
NLP (Natural Language Process,自然语言处理)是人工智能领域的一个重要分支,其核心目标是让程序能够理解并处理我们所说的语言文字。
简单来说,就是让计算机能够像人类一样理解、分析和生成自然语言文本。
第二章 文本预处理
文本预处理是NLP任务中最基础也是最关键的一步,直接影响后续模型的效果。
1. 分词器
分词是将连续的文本切分成独立的词语或词汇单元的过程。
python
import jieba
# 基础分词
sentence = "我爱自然语言处理"
list = jieba.lcut(sentence)
print(list) # ['我', '爱', '自然语言', '处理']特点:
-
支持简体和繁体中文分词
-
采用基于统计和规则的分词算法
自定义词典
当处理特定业务场景时,通用分词可能无法满足需求,需要引入自定义词典:
python
jieba.load_userdict("自定义词典路径.txt")适用场景: 专业领域术语、公司内部产品名、特定人名等
2. 命名实体识别(NER)
NER(Named Entity Recognition)用于识别文本中具有特殊含义的实体。
常见的实体类型:
-
👤 人名(如:张三、李白)
-
🏠 地名(如:北京、珠穆朗玛峰)
-
🏢 机构名(如:清华大学、阿里巴巴)
-
🏛️ 组织名(如:联合国、红十字会)
3. 词性标注(POS)
POS(Part-of-Speech Tagging)是对每个词语进行词性分类的过程。
常见的词性类型:
-
名词(n.)
-
动词(v.)
-
形容词(adj.)
-
副词(adv.)
-
等等...
文本张量的表示形式
计算机无法直接理解文字,需要将文本转换为数值形式(张量)。
1. One-hot编码
将每个词表示为一个长向量,只有一个位置为1,其余为0。
优点:
-
✅ 实现简单,容易理解
-
✅ 直观明了
缺点:
-
❌ 稀疏向量:占用大量存储空间和计算资源
-
❌ 语义割裂:无法体现词与词之间的关系,近义词无法关联
2. Word2Vec
Word2Vec通过训练将词映射为稠密向量,能够捕捉词语之间的语义关系。
两种训练模式:
CBOW连续词袋模式
-
原理:用上下文预测中间词
-
示意图:
-
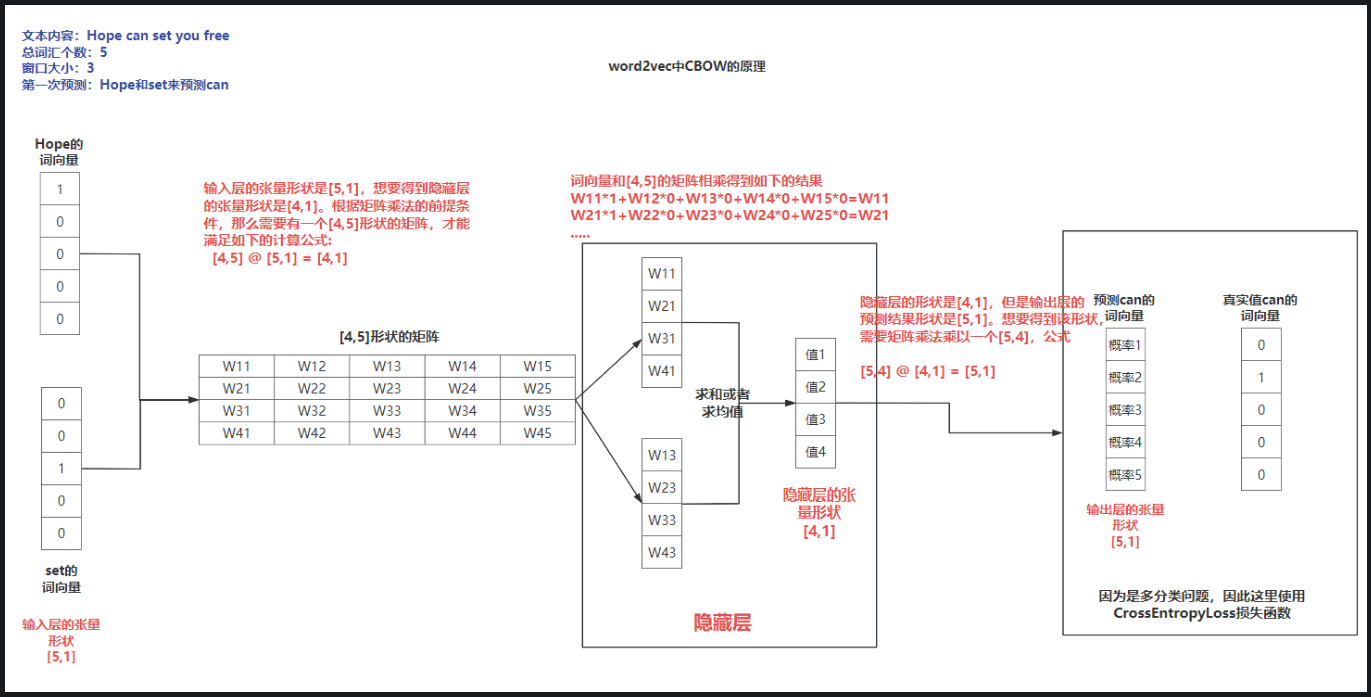
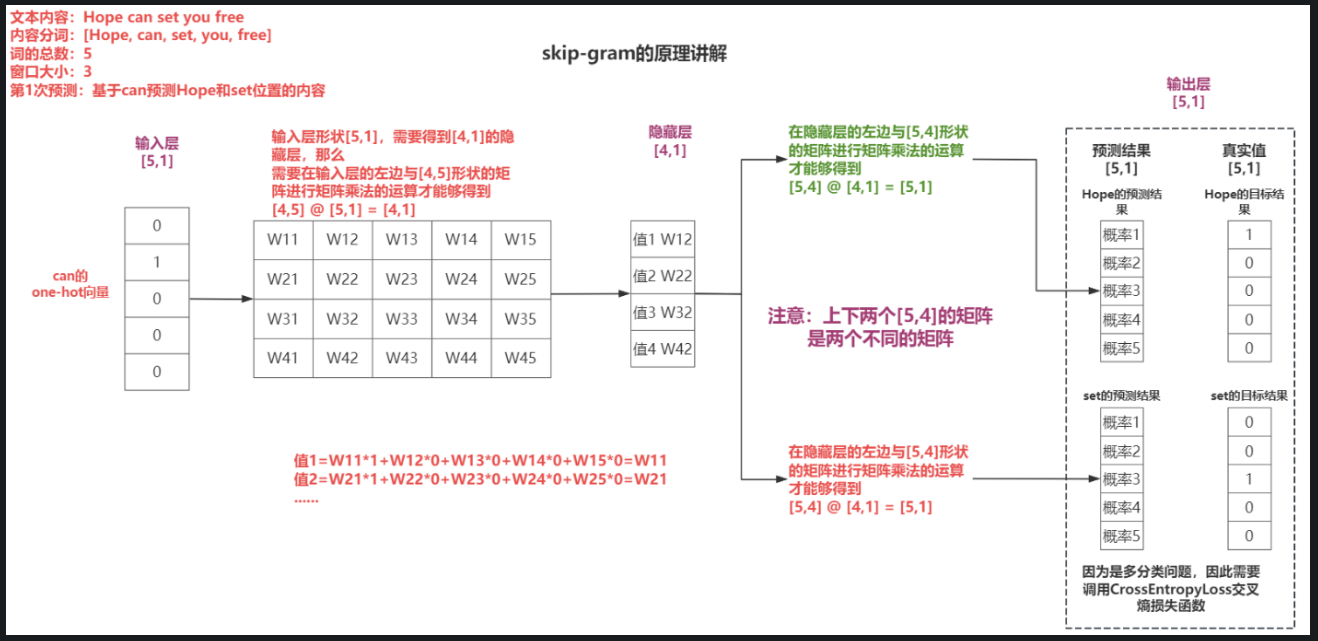
skip-gram跳词模式
-
原理:用中间词预测上下文
-
示意图:
-
python
"""
如果不管是安装fasttext还是fasttext-wheel都失败,那么原因是python版本过高。
操作步骤如下:
1- 先进入对应的虚拟环境
2- 安装低版本的python解释器
conda install python=3.10
3- 安装fasttext
pip install fasttext-wheel -i https://mirrors.aliyun.com/pypi/simple/
"""
import fasttext
def demo01():
# 1- 使用无监督学习训练模型
"""
为什么这里只能使用无监督学习?
答:因为数据中没有明确标记目标值。有监督学习对文件内容有严格要求,有__label__
"""
# model = fasttext.train_unsupervised("data/fil9")
model = fasttext.train_unsupervised("../data/gz03ag")
# 2- 保存训练好的模型
model.save_model("../model/word2vec.pkl")
def demo02():
# 1- 加载训练好的模型
model = fasttext.load_model("../model/word2vec.pkl")
# 2- 获得某个词的词向量
word_vec = model.get_word_vector("hello")
print(word_vec)
def demo03():
# 1- 加载训练好的模型
model = fasttext.load_model("../model/word2vec.pkl")
# 2- 获得相近的几个词
# 会从词形、词义方面进行查找。
# result_list = model.get_nearest_neighbors("dog")
result_list = model.get_nearest_neighbors("cat")
# 3- 输出
print(result_list)
def demo04():
"""
参数解释:
input:训练集路径
model:word2vec的模式。默认是skipgram,可以设置为cbow
dim:词向量的维度
epoch:训练的轮次
lr:初始学习率
thread:训练的线程个数
"""
model = fasttext.train_unsupervised(
input="data/gz03ag",
model="cbow",
dim=200,
epoch=1,
lr=0.1,
thread=10
)
model.save_model("../model/word2vec_better.pkl")
if __name__ == '__main__':
# 1- 训练并保存模型
# demo01()
# 2- 获得词的词向量
# demo02()
# 3- 获得相近的词
# demo03()
# 4- 超参数调优设置【掌握】
demo04()3. Word Embedding(词嵌入)
Word Embedding是将词语映射到低维稠密向量空间的技术,是Word2Vec等方法的统称。它能保持词语之间的语义相似性,是深度学习NLP任务的基础。
python
import jieba
from keras.src.legacy.preprocessing.text import Tokenizer
import torch.nn as nn
import torch
from torch.utils.tensorboard import SummaryWriter
if __name__ == '__main__':
# 1- 准备文本内容
sentence1 = '阿珍爱上了阿强,再一个没有星星的夜晚'
sentence2 = "我爱自然语言处理"
sentence_list = [sentence1,sentence2]
# 2- 对每条句子进行分词
word_list = []
for sen in sentence_list:
word_list.append(jieba.lcut(sen))
# print(word_list)
# 3- 训练得到词汇映射器
tokenizer = Tokenizer()
tokenizer.fit_on_texts(word_list)
index_word = tokenizer.index_word
"""
排序过程如下:
1- 默认按照词在句子中出现的顺序排序
2- 然后出现次数高(词频)的排在前面
3- 如果词频也相同,再词在句子中出现的顺序排序
"""
# print(type(index_word))
# print(index_word)
# 4- 创建词嵌入层
word_nums = len(index_word)
"""
参数解释:
num_embeddings:词汇表中词的个数
embedding_dim:词向量维度
"""
ebd = nn.Embedding(num_embeddings=word_nums,embedding_dim=8)
# 5- 遍历获得每个词的词向量
for key,value in index_word.items():
# 5.1- 通过【key词索引】获得词向量
# 注意:key是词索引,是从1开始的
word_vec = ebd(torch.tensor(key-1))
# 5.2- 打印输出
print(f"词:{value},词向量:{word_vec}")
# 6- 【了解】可视化展示:展示词和词之间的相似性
# 注意:runs的父目录不能有中文名称
summary = SummaryWriter("../../runs")
summary.add_embedding(ebd.weight.data, index_word.values())
summary.close()文本数据分析
文本数据分析也称为EDA(Exploratory Data Analysis,探索性数据分析)。
分析要点:
-
目标值分布情况
-
检查数据类别是否均衡
-
如果不均衡,需要考虑采样策略
-
-
句子长度分布
-
统计绝大数句子的长度范围
-
用于确定模型输入的最大长度
-
-
词频统计
-
分析高频词和低频词
-
决定词典大小(计算概率时需要考虑的词数量)
-
-
词云可视化
-
直观展示文本中的关键词
-
辅助理解数据特点
-
文本特征处理
1. N-gram
N-gram是将相邻的N个词语组合成新特征的方法,帮助模型更好地理解上下文信息。
分类:
-
uni-gram(1-gram):单个词,如:"我"、"爱"、"北京"
-
bi-gram(2-gram):相邻两个词,如:"我爱"、"爱北京"
-
tri-gram(3-gram):相邻三个词,如:"我爱北京"
python
def n_gram_fn(n_gram):
# 1- 测试数据
word_list = ["aa","bb","cc","dd"]
# 2- 对相邻的词进行合并
"""
2-gram:
["aa","bb","cc","dd"]
["bb","cc","dd"]
3-gram:
["aa","bb","cc","dd"]
["bb","cc","dd"]
["cc","dd"]
"""
lists = [word_list[i:] for i in range(n_gram)]
print(lists)
print(list(zip(*lists)))
if __name__ == '__main__':
n_gram_fn(n_gram=1)
n_gram_fn(n_gram=2)
n_gram_fn(n_gram=3)
"""
结果:
[['aa', 'bb', 'cc', 'dd']]
[('aa',), ('bb',), ('cc',), ('dd',)]
[['aa', 'bb', 'cc', 'dd'], ['bb', 'cc', 'dd']]
[('aa', 'bb'), ('bb', 'cc'), ('cc', 'dd')]
[['aa', 'bb', 'cc', 'dd'], ['bb', 'cc', 'dd'], ['cc', 'dd']]
[('aa', 'bb', 'cc'), ('bb', 'cc', 'dd')]
"""作用: 捕捉局部上下文信息,增强模型对短语的理解能力
2. 句子长度规范
为了让模型能够并行处理数据,需要将所有句子统一为相同的长度。
常用方法:
-
截断:超出长度的部分截断
-
填充:不足长度的部分用特殊标记填充
python
from keras.preprocessing import sequence
"""
句子长度规范的作用【掌握】:
1- 数据加载器Dataloader(batch_size=1),张量的形状不相同的时候只能设置为1。
因为里面是使用stack对张量进行拼接
stack的要求是张量形状完全相同
stack() 会改变维度数, 拼接张量. 所有的维度都必须保持一致.
t1 = torch.randn(2, 3)
t2 = torch.randn(2, 3)
result = torch.stack([t1, t2], dim=0) # 结果形状: (2, 2, 3)
这里底层使用stack拼接一批样本的整体样本特征张量,特征数必须保持一致
2- 迁移学习中有现成的参数可以进行设置
"""
# 1- 准备数据,两条句子
sen_list = [
[1, 23, 5, 32, 55, 63, 2, 21, 78, 32, 23, 1],
[2, 32, 1, 23, 1]
]
# 2- 对句子进行截断和填充
max_length = 10
"""
参数解释:
sequences:要处理的句子列表
maxlen:最大长度限制
padding:填充的方式。默认pre,在句子前面填充;post在句子后面填充
truncating:截断的方式。默认pre,在句子前面截断;post在句子后面截断
value:用来进行填充的值。一般不会修改该参数,使用默认的0即可
"""
# result = sequence.pad_sequences(sequences=sen_list,maxlen=max_length)
result = sequence.pad_sequences(
sequences=sen_list,
maxlen=max_length,
padding="post",
truncating="post",
value=6666)
print(result)总结与要点回顾
| 模块 | 核心内容 | 重要性 |
|---|---|---|
| NLP定义 | 让计算机理解处理语言文字 | ⭐⭐⭐ |
| 分词 | jieba分词、自定义词典 | ⭐⭐⭐ |
| NER/POS | 实体识别、词性标注 | ⭐⭐ |
| 文本表示 | One-hot、Word2Vec、Word Embedding | ⭐⭐⭐ |
| 数据分析 | EDA、分布分析 | ⭐⭐ |
| 特征处理 | N-gram、长度规范 | ⭐⭐ |
实战小贴士 💡
-
分词阶段:提前整理好领域词典,可以大幅提升分词效果
-
文本表示:对于大部分任务,预训练的Word Embedding比随机初始化效果更好
-
数据分析:不要跳过EDA,它能帮你避免很多后续的"坑"
-
N-gram选择:通常使用bi-gram和tri-gram,太大容易导致数据稀疏
欢迎讨论交流,如有错误请指正, 持续更新, 大家可关注等待!
#NLP #自然语言处理 #文本预处理 #机器学习 #深度学习 #AI入门