Content-Type:请求体数据类型
text/html:HTML 格式
text/plain:纯文本格式
image/jpeg:jpg 图片格式
application/json:JSON 数据格式
application/x-www-form-urlencoded:表单默认的提交数据格式
multipart/form-data:在表单中进行文件上传时使用
接口测试流程:
- 需求分析:明确接口要实现的业务目标
- 接口文档解析:明确接口功能、请求方式(GET/POST 等)、入参 / 出参格式、响应码、异常规则
- 设计测试用例:覆盖正常场景(参数合法、功能达标)、异常场景(参数缺失 / 格式错误 / 越权)、边界场景(参数极值)。
- 脚本开发:编写自动化测试脚本
- 执行及缺陷跟踪:对应之前的 "接口调用验证 + 缺陷管理"
- 生成测试报告:和之前的 "报告输出" 一致
- 接口自动化持续集成(可选):(补充了自动化测试的后续维护环节)
Postman断言
1. 验证响应状态码(最常用)
javascript
// 验证接口返回200成功
pm.test("响应状态码为200", function () {
pm.response.to.have.status(200);
});
// 验证接口返回指定错误状态码(比如404/401)
pm.test("响应状态码为401(未授权)", function () {
pm.response.to.have.status(401);
});2. 验证响应时间(性能初筛)
javascript
// 验证接口响应时间≤2000ms(可根据需求调整)
pm.test("响应时间≤2000ms", function () {
pm.expect(pm.response.responseTime).to.be.below(2000);
});3. 验证JSON响应体的业务字段(核心)
javascript
// 先解析响应体为JSON对象
const resData = pm.response.json();
// 验证业务状态码(比如code=0代表成功)
pm.test("业务状态码为0", function () {
pm.expect(resData.code).to.eql(0); // eql是严格相等
});
// 验证提示信息(比如message为"操作成功")
pm.test("提示信息为操作成功", function () {
pm.expect(resData.message).to.eql("操作成功");
});
// 验证返回数据非空(比如data字段存在且不为空)
pm.test("返回数据data非空", function () {
pm.expect(resData.data).to.exist.and.not.be.empty;
});4. 验证JSON数组的长度/内容
javascript
const resData = pm.response.json();
// 验证列表数据长度≥1(比如查询接口返回至少1条数据)
pm.test("列表数据至少有1条", function () {
pm.expect(resData.data.list).to.be.an("array").and.have.lengthOf.at.least(1);
});
// 验证数组中某条数据的字段值(比如第一条数据的id=1001)
pm.test("列表第一条数据的id为1001", function () {
pm.expect(resData.data.list[0].id).to.eql(1001);
});5. 验证响应体包含特定字符串
javascript
// 适用于非JSON响应(比如HTML/文本),验证包含指定内容
pm.test("响应体包含'成功'关键词", function () {
pm.response.to.have.body("成功");
// 模糊匹配用:pm.response.to.have.body.match(/成功/);
});响应头验证
javascript
// 验证响应头的Content-Type(比如JSON格式)
pm.test("响应格式为JSON", function () {
pm.response.to.have.header("Content-Type", "application/json; charset=utf-8");
});
// 验证响应头包含指定字段(比如Token)
pm.test("响应头包含Token字段", function () {
pm.expect(pm.response.headers.has("Token")).to.be.true;
});业务逻辑断言
javascript
const resData = pm.response.json();
// 验证分页参数匹配(比如当前页page=1,每页条数size=10)
pm.test("分页参数符合预期", function () {
pm.expect(resData.data.page).to.eql(1);
pm.expect(resData.data.size).to.eql(10);
});
// 验证字段类型(比如id是数字类型)
pm.test("id字段为数字类型", function () {
pm.expect(resData.data.id).to.be.a("number");
});requests发送请求
请求方法格式:
python
requests.请求方法(url, params=None, data=None, json=None, headers=None)说明:
- 请求方法: get/post/put/delete
- url: 请求的url地址
- params: 请求查询参数(URL 后
? key=value) - data: 表单参数
- json: json参数
- headers: 请求头参数, 比如
token
这些参数都使用python字典传输
Get方式传参:
如果接口是路径参数:
python
user_id = 1
url = f"{baseUrl}/users/{user_id}"
response = requests.get(url)如果接口是查询参数:
python
# 如果后端API设计为 /users?user_id=1
url = f"{baseUrl}/users"
response = requests.get(url, params={"user_id": 1}) # ✅ params必须是字典post 的参数
python
# data 是表单参数
response=requests.post(url=baseUrl+"/users",data=userInfo)
# 正确:使用json参数发送JSON数据
response = requests.post(url=baseUrl + "/users", json=userInfo)基本用法
python
import requests
# 发送GET请求
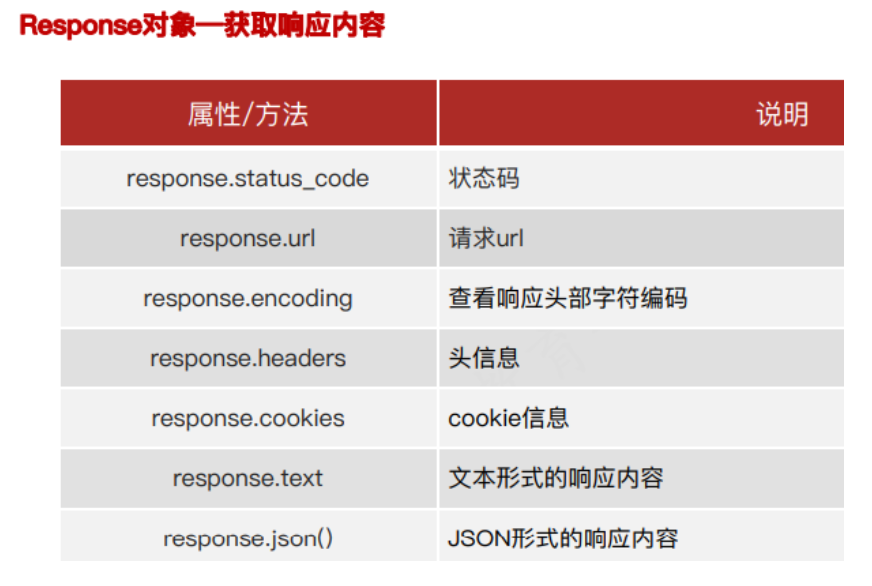
r = requests.get('https://www.baidu.com')
# 查看响应状态码
print(r.status_code)
# 查看响应内容
print(r.text)
# 查看Cookies
print(r.cookies)
# 请求的URL
print(r.url)
# 请求历史
print(r.history)
# 响应头
print(r.headers) 设置请求头:
python
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:95.0) Gecko/20100101 Firefox/95.0',
'my-test': 'Hello'
}
r = requests.get('http://httpbin.org/get', headers=headers)文件上传:
python
files = {'file': open('favicon.ico', 'rb')}
r = requests.post('http://httpbin.org/post', files=files)获取Cookies:
python
r = requests.get('https://www.baidu.com')
print(r.cookies)
for key, value in r.cookies.items():
print(key + '=' + value)使用Cookies维持登录状态:
python
headers = {
'Cookie': 'your_cookie_string',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:95.0) Gecko/20100101 Firefox/95.0'
}
r = requests.get('https://www.zhihu.com', headers=headers)会话维持(Session)
python
s = requests.Session()
s.get('http://httpbin.org/cookies/set/number/123456789')
r = s.get('http://httpbin.org/cookies')
print(r.text)总超时时间
python
r = requests.get('https://www.taobao.com', timeout=1)分别指定连接和读取超时
python
r = requests.get('https://www.taobao.com', timeout=(5, 30))永久等待
python
r = requests.get('https://www.taobao.com', timeout=None)PyMysql操作
1.安装pymysql:
bash
pip install PyMySQL 2.数据库操作的固定流程
python
# 1. 导包(必须第一步)
import pymysql
# 2. 创建数据库连接(核心参数PPT已给出)
conn = pymysql.connect(
host="数据库地址", # 示例:211.103.136.244(PPT测试地址)
port=端口号, # 示例:7061(默认3306,非默认必须写)
user="用户名", # 示例:student
password="密码", # 示例:iHRM_student_2021
database="数据库名",# 示例:test_db
charset="utf8" # 固定值,避免中文乱码
)
# 3. 获取游标(执行SQL的工具)
cursor = conn.cursor()
# 4. 执行SQL操作(查询/增删改,核心步骤)
# TODO:这里替换成具体SQL
# 5. 释放资源(必须做,避免占用连接)
cursor.close() # 先关游标
conn.close() # 再关连接3. 核心操作:增删改查
(1)查询操作(最常用,用于"数据校验")
python
# 示例:验证"新增图书"接口后,查询t_book表是否有该图书
import pymysql
conn = pymysql.connect(host="211.103.136.244", port=7061, user="student", password="iHRM_student_2021", database="test_db", charset="utf8")
cursor = conn.cursor()
# 执行查询SQL
sql = "select * from t_book where title='西游记'"
cursor.execute(sql) # 执行SQL
# 3种获取结果的方式
result1 = cursor.fetchone() # 取结果集的第1条(最常用,验证单条数据)
result2 = cursor.fetchmany(2) # 取指定条数(比如前2条)
result3 = cursor.fetchall() # 取所有结果(比如验证批量新增)
print("查询结果:", result1) # 输出:(5, '西游记', '1986-01-01', ...)
cursor.close()
conn.close()(2)增删改操作(用于"造数据/清环境")
这三类操作需要事务提交,否则操作无效,且要处理异常
python
import pymysql
import traceback # 捕获异常
conn = pymysql.connect(host="211.103.136.244", port=7061, user="student", password="iHRM_student_2021", database="test_db", charset="utf8")
cursor = conn.cursor()
try:
# 1. 新增数据(造测试数据)
sql_insert = "insert into t_book(id, title, pub_date) values(5, '西游记', '1986-01-01')"
# 2. 更新数据(比如修改测试数据状态)
sql_update = "update t_book set `read` = `read` + 1 where title='西游记'"
# 3. 删除数据(清理测试环境)
sql_delete = "delete from t_book where title='西游记'"
# 执行其中一个操作(按需选)
cursor.execute(sql_insert)
conn.commit() # 必须提交事务,否则数据不生效
print("操作成功")
except Exception as e:
conn.rollback() # 出错时回滚,避免数据混乱
print("操作失败:", traceback.format_exc()) # 打印异常信息
finally:
# 无论成功失败,都关闭资源
cursor.close()
conn.close()4. 重复写连接/关闭代码太繁琐,封装成工具类:
python
import pymysql
import traceback
class DBUtil:
# 1. 获取数据库连接(类方法,无需实例化)
@classmethod
def get_conn(cls):
conn = None
try:
conn = pymysql.connect(
host="211.103.136.244",
port=7061,
user="student",
password="iHRM_student_2021",
database="test_db",
charset="utf8"
)
except Exception as e:
print("连接数据库失败:", e)
return conn
# 2. 关闭连接(统一释放资源)
@classmethod
def close_conn(cls, conn, cursor):
if cursor:
cursor.close()
if conn:
conn.close()
# 3. 查询一条数据(验证接口常用)
@classmethod
def get_one(cls, sql):
conn = cls.get_conn()
cursor = conn.cursor()
result = None
try:
cursor.execute(sql)
result = cursor.fetchone()
except Exception as e:
print("查询失败:", traceback.format_exc())
finally:
cls.close_conn(conn, cursor)
return result
# 4. 执行增删改(造数据/清环境常用)
@classmethod
def uid_db(cls, sql):
conn = cls.get_conn()
cursor = conn.cursor()
try:
cursor.execute(sql)
conn.commit()
return True # 操作成功返回True
except Exception as e:
conn.rollback()
print("执行失败:", traceback.format_exc())
return False # 失败返回False
finally:
cls.close_conn(conn, cursor)
# 直接调用
if __name__ == "__main__":
# 查数据(验证接口)
sql_select = "select * from t_book where id=5"
print(DBUtil.get_one(sql_select))
# 删数据(清环境)
sql_delete = "delete from t_book where id=5"
DBUtil.uid_db(sql_delete)6. 场景1:接口测试数据校验
python
import requests
from DBUtil import DBUtil # 导入上面封装的工具类
# 1. 调用新增图书接口
url = "https://your-api.com/book/add"
headers = {"Content-Type": "application/json"}
json_data = {"id": 5, "title": "西游记", "pub_date": "1986-01-01"}
requests.post(url=url, headers=headers, json=json_data)
# 2. 数据库校验
sql = "select title from t_book where id=5"
result = DBUtil.get_one(sql)
# 3. 断言(测开核心:验证接口是否真的生效)
assert result[0] == "西游记", f"数据校验失败,实际结果:{result}"
print("接口测试通过")7. 场景2:批量造测试数据(实习效率神器)
python
from DBUtil import DBUtil
for i in range(10, 20): # id从10到19
sql = f"insert into t_book(id, title, pub_date) values({i}, '测试图书{i}', '2024-01-01')"
DBUtil.uid_db(sql)
print("10条测试数据创建完成")日志
常见日志级别(从低到高)
| 级别 | 含义 | 适用场景 |
|---|---|---|
| DEBUG | 调试级(最详细),打印代码调试信息(如变量值、函数调用细节) | 开发/测试阶段调试代码 |
| INFO | 信息级,记录系统核心运行步骤(如"接口请求发起""脚本执行开始") | 监控正常流程 |
| WARNING | 警告级,潜在错误(不影响系统当前运行) | 如"参数格式不规范但已兼容" |
| ERROR | 错误级,程序出现BUG(功能异常) | 如"接口调用失败""数据查询报错" |
| CRITICAL | 严重错误级,系统无法继续运行 | 如"数据库连接失败""核心服务崩溃" |
当为程序指定一个日志级别后,程序会记录所有日志级别大于或等于指定日志级别的日志信息,而不是仅仅记录指定级别的日志信息
日志文件需要避免过大(难以打开),建议 按时间切割(如每日生成1个日志文件),并限制备份数量(如保留3天的日志)
实操:用Python Logging收集日志
| 组件 | 作用 |
|---|---|
| Logger(日志器) | 核心入口,负责发起日志记录请求,设置全局日志级别 |
| Handler(处理器) | 决定日志输出位置(控制台/文件),支持同时绑定多个处理器(如既打控制台又存文件) |
| Formatter(格式化器) | 定义日志的显示格式(如包含时间、级别、代码位置、日志内容) |
python
# logger_utils.py(日志工具类,直接复制复用)
import logging
import logging.handlers
import os
# 1. 配置日志路径(可按需修改)
LOG_DIR = "./logs"
if not os.path.exists(LOG_DIR):
os.makedirs(LOG_DIR)
# 2. 创建日志器(避免重复输出)
logger = logging.getLogger("auto_test_logger") # 给日志器命名,避免全局冲突
logger.setLevel(logging.DEBUG)
# 3. 仅在无处理器时添加(解决重复打印问题)
if not logger.handlers:
# 控制台处理器(只显示≥INFO级别,避免调试信息刷屏)
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.INFO)
# 文件处理器(按时间切割,保留3天)
file_handler = logging.handlers.TimedRotatingFileHandler(
filename=os.path.join(LOG_DIR, "auto_test.log"),
when='MIDNIGHT',
interval=1,
backupCount=3,
encoding='utf-8' # 解决中文乱码
)
file_handler.setLevel(logging.DEBUG)
# 日志格式(包含关键信息,便于排查)
fmt = "%(asctime)s - %(levelname)s - [%(filename)s:%(funcName)s:%(lineno)d] - %(message)s"
formatter = logging.Formatter(fmt)
# 绑定格式和处理器
console_handler.setFormatter(formatter)
file_handler.setFormatter(formatter)
logger.addHandler(console_handler)
logger.addHandler(file_handler)
# 对外暴露logger,供其他文件导入
if __name__ == "__main__":
# 测试日志是否正常输出
logger.debug("工具类调试信息")
logger.info("工具类初始化成功")关键API说明
(1)Logger日志器
- 创建:
logging.getLogger()(全局唯一,重复调用返回同一对象) - 设置级别:
logger.setLevel(logging.XXX)(XXX为DEBUG/INFO等) - 记录日志:
logger.debug(msg)/logger.info(msg)/logger.warning(msg)等(方法名小写)
(2)Handler处理器
- 控制台输出:
logging.StreamHandler() - 普通文件输出:
logging.FileHandler(filename)(不切割,文件会越来越大) - 按时间切割文件:
logging.handlers.TimedRotatingFileHandler()(需导包logging.handlers) - 绑定格式化器:
handler.setFormatter(formatter)
(3)Formatter格式化器
- 常用格式参数:
%(asctime)s:当前时间(默认格式:2003-07-08 16:49:45,896)%(levelname)s:日志级别(如DEBUG、INFO)%(filename)s:产生日志的文件名%(funcName)s:产生日志的函数名%(lineno)d:产生日志的代码行号%(message)s:日志核心内容(自定义消息)
接口自动化框架
项目结构
txt
apiTestFramework
├── api # 封装被测系统接口
├── scripts # 测试用例脚本
├── data # 测试数据文件
├── report # 测试报告
├── common # 通用工具类
├── logs # 日志文件
├── config.py # 项目配置信息
├── run_suite.py # 执行测试套件的入口
├── requirements.txt # 依赖库清单
├── pytest.ini # pytest配置文件
└── docs # 文档目录json schema
用于校验json的格式
在线校验工具:
python
SCHEMA = {
"$schema": "http://json-schema.org/draft-07/schema#",
"type": "object",
"properties": {
"username": {"type": "string", "minLength": 2},
"age": {"type": "integer", "minimum": 18, "maximum": 60},
"gender": {"type": "string", "enum": ["male", "female"]}
},
"required": ["username", "age", "gender"]
}| 关键字 | 描述 |
|---|---|
type |
限定JSON元素的数据类型 |
properties |
定义JSON对象中各字段的校验规则(仅type为object时使用) |
required |
指定JSON对象中必须存在的字段(数组格式,元素唯一) |
const |
强制字段值等于指定内容(精准匹配) |
pattern |
用正则表达式约束字符串类型字段 |
在python中校验:
安装依赖库:
bash
pip install jsonschema核心函数:
python
jsonschema.validate(instance=待校验JSON数据, schema=校验规则Schema)instance:接口返回的实际JSON数据(如response.json())schema:提前定义的JSON Schema校验规则
异常处理:
jsonschema.exceptions.SchemaError:Schema规则本身不合法时抛出jsonschema.exceptions.ValidationError:JSON数据不符合Schema规则时抛出
CI/CD
持续集成目的:快速迭代 保持高质量
持续集成
开发人员提交新代码后,立刻构建,部署到「测试环境」,执行测试并反馈
持续交付
在持续集成的基础上,将集成后的代码部署到「类生产环境」
持续部署
在持续交付的基础上,自动部署到生产环境加粗样式