文章目录
-
- 一、整体架构概述
- 二、官方示例代码输出记录
- 三、核心组件详解
-
- [1. 配置类 (Lines 38-58)](#1. 配置类 (Lines 38-58))
- [2. CompressedTokenizer (Lines 60-121)](#2. CompressedTokenizer (Lines 60-121))
- [3. ShortConv (Lines 123-179)](#3. ShortConv (Lines 123-179))
- [4. NgramHashMapping (Lines 188-303)](#4. NgramHashMapping (Lines 188-303))
- [5. MultiHeadEmbedding (Lines 305-324)](#5. MultiHeadEmbedding (Lines 305-324))
- [6. Engram 模块 (Lines 326-378)](#6. Engram 模块 (Lines 326-378))
-
- 核心模块,整合上述组件。
- [6.1 初始化 (Lines 326-356)](#6.1 初始化 (Lines 326-356))
- [6.2 前向传播 (Lines 358-378)](#6.2 前向传播 (Lines 358-378))
- 执行流程:
- 门控激活函数:
- [7. TransformerBlock (Lines 380-394)](#7. TransformerBlock (Lines 380-394))
- 四、完整数据流
- 五、设计要点
- 六、优势
一、整体架构概述
Engram 是一个条件记忆模块,通过 N-gram 嵌入实现 O(1) 查找,作为 MoE 的补充。
核心思路:用静态 N-gram 记忆增强动态隐藏状态。
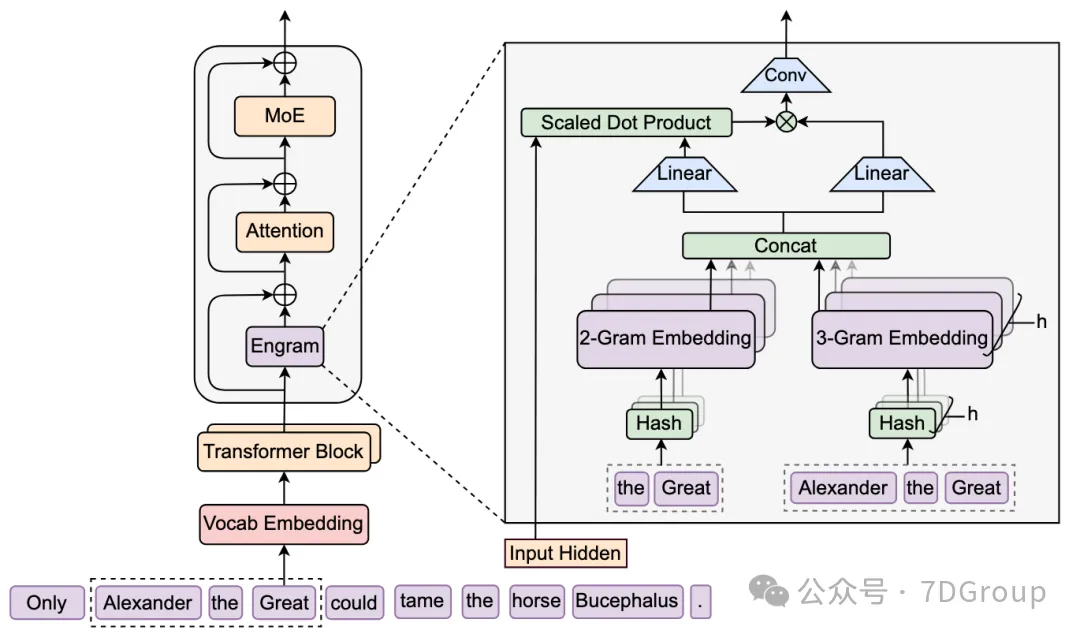
架构链路:
Vocab Embedding → Input Hidden → Transformer Block → (Conv / MoE / Scaled Dot Product Attention) → Concat → Engram (2-Gram Embedding / 3-Gram Embedding) → Hash → Hash
示例输入文本:Only Alexander the Great could tame the horse Bucephalus
二、官方示例代码输出记录
bash
(engram) gaolou@GaodeMacBook-Pro Engram-main % python engram_demo_v1.py
============================================================
🚀 Engram 架构演示程序启动
============================================================
============================================================
📋 Engram 配置信息
============================================================
Tokenizer路径: deepseek-ai/DeepSeek-V3
N-gram词汇表大小: [646400, 646400]
最大N-gram大小: 3
每个N-gram嵌入维度: 512
每个N-gram头数: 8
插入Engram的层: [1, 15]
隐藏层大小: 1024
Hyper-connection倍数: 4
词汇表大小: 129280
Transformer层数: 30
============================================================
📦 正在构建模型架构...
🏗️ 初始化Engram模块 (层 1)...
🔧 初始化N-gram哈希映射模块...
🔄 正在加载Tokenizer: deepseek-ai/DeepSeek-V3
✅ Tokenizer加载完成,原始词汇表大小: 128815
🔄 正在构建token压缩查找表...
处理进度: 128815/128815 (100.0%)
✅ 查找表构建完成,压缩后词汇表大小: 128815 (压缩率: 100.00%)
为 2 个层生成哈希乘数...
✅ 层 1 的哈希乘数已生成
✅ 层 15 的哈希乘数已生成
正在为各层选择质数作为哈希模数...
层 1, 2-gram, 头 1: 质数 646403
层 1, 3-gram, 头 1: 质数 646537
层 15, 2-gram, 头 1: 质数 646631
层 15, 3-gram, 头 1: 质数 646781
✅ N-gram哈希映射模块初始化完成
✅ Engram模块 (层 1) 初始化完成
🏗️ 初始化Engram模块 (层 15)...
🔧 初始化N-gram哈希映射模块...
🔄 正在加载Tokenizer: deepseek-ai/DeepSeek-V3
✅ Tokenizer加载完成,原始词汇表大小: 128815
🔄 正在构建token压缩查找表...
处理进度: 128815/128815 (100.0%)
✅ 查找表构建完成,压缩后词汇表大小: 128815 (压缩率: 100.00%)
为 2 个层生成哈希乘数...
✅ 层 1 的哈希乘数已生成
✅ 层 15 的哈希乘数已生成
正在为各层选择质数作为哈希模数...
层 1, 2-gram, 头 1: 质数 646403
层 1, 3-gram, 头 1: 质数 646537
层 15, 2-gram, 头 1: 质数 646631
层 15, 3-gram, 头 1: 质数 646781
✅ N-gram哈希映射模块初始化完成
✅ Engram模块 (层 15) 初始化完成
✅ 模型架构构建完成: 1个嵌入层 + 30个Transformer块 + 1个输出层
📝 输入文本: Only Alexander the Great could tame the horse Bucephalus.
🔄 正在加载tokenizer并编码文本...
✅ 文本编码完成,token数量: 14
🔄 开始前向传播...
输入形状: torch.Size([1, 14])
层 0: 词嵌入层
输入: torch.Size([1, 14])
嵌入后: torch.Size([1, 14, 1024])
Hyper-connection扩展后: torch.Size([1, 14, 4, 1024])
层 2 (Transformer块 1): 包含Engram模块
[层 1] 步骤1: 计算N-gram哈希索引...
🔄 正在计算N-gram哈希值...
Token压缩完成,输入序列长度: 14
✅ 层 1 的哈希值计算完成,形状: (1, 14, 16)
✅ 层 15 的哈希值计算完成,形状: (1, 14, 16)
[层 1] 步骤2: 从嵌入表查找N-gram嵌入...
[层 1] 步骤3: 计算门控值 (共 4 个通道)...
[层 1] 步骤4: 投影N-gram嵌入为值并应用门控...
[层 1] 步骤5: 通过短卷积增强特征...
[层 1] ✅ Engram处理完成,输出形状: torch.Size([1, 14, 4, 1024])
层 5 (Transformer块 4): 标准Transformer块
层 10 (Transformer块 9): 标准Transformer块
层 15 (Transformer块 14): 标准Transformer块
层 16 (Transformer块 15): 包含Engram模块
[层 15] 步骤1: 计算N-gram哈希索引...
🔄 正在计算N-gram哈希值...
Token压缩完成,输入序列长度: 14
✅ 层 1 的哈希值计算完成,形状: (1, 14, 16)
✅ 层 15 的哈希值计算完成,形状: (1, 14, 16)
[层 15] 步骤2: 从嵌入表查找N-gram嵌入...
[层 15] 步骤3: 计算门控值 (共 4 个通道)...
[层 15] 步骤4: 投影N-gram嵌入为值并应用门控...
[层 15] 步骤5: 通过短卷积增强特征...
[层 15] ✅ Engram处理完成,输出形状: torch.Size([1, 14, 4, 1024])
层 20 (Transformer块 19): 标准Transformer块
层 25 (Transformer块 24): 标准Transformer块
层 30 (Transformer块 29): 标准Transformer块
层 31: 输出投影层
Hyper-connection收缩后: torch.Size([1, 14, 1024])
输出: torch.Size([1, 14, 129280])
============================================================
✅ 前向传播完成!
============================================================
📊 输入形状: torch.Size([1, 14])
📊 输出形状: torch.Size([1, 14, 129280])
============================================================三、核心组件详解
1. 配置类 (Lines 38-58)
engram_demo_v1.py:38-58行
python
@dataclass # 使用数据类装饰器,自动生成__init__、__repr__等方法
class EngramConfig:
tokenizer_name_or_path: str = "deepseek-ai/DeepSeek-V3" # tokenizer的路径或名称
engram_vocab_size: List[int] = field(default_factory=lambda: [129280*5, 129280*5]) # 每个N-gram的词汇表大小列表(2-gram和3-gram)
max_ngram_size: int = 3 # 最大N-gram大小,支持2-gram和3-gram
n_embed_per_ngram: int = 512 # 每个N-gram的嵌入维度总数
n_head_per_ngram: int = 8 # 每个N-gram使用的注意力头数量
layer_ids: List[int] = field(default_factory=lambda: [1, 15]) # 插入Engram模块的层ID列表
pad_id: int = 2 # 填充token的ID,用于N-gram边界处理
seed: int = 0 # 随机种子,确保哈希乘数的可复现性
kernel_size: int = 4 # ShortConv卷积层的核大小
@dataclass # 使用数据类装饰器定义骨干网络配置
class BackBoneConfig:
hidden_size: int = 1024 # 隐藏状态的维度大小
hc_mult: int = 4 # hyper-connection的倍数,表示并行通道数
vocab_size: int = 129280 # 原始词汇表大小
num_layers: int = 30 # Transformer的总层数关键参数说明:
engram_vocab_size: 每个 N-gram 的词汇表大小(2-gram 和 3-gram)max_ngram_size: 最大 N-gram 大小(2 和 3)layer_ids: 插入 Engram 的层位置(第 1 和 15 层)
2. CompressedTokenizer (Lines 60-121)
作用:
- 压缩 tokenizer 词汇表,合并等价 token。
- engram_demo_v1.py: 84-110行
核心代码 (Lines 84-110):
python
def _build_lookup_table(self):
old2new = {} # 原始token ID到新token ID的映射字典
key2new = {} # 归一化后的key到新token ID的映射字典
new_tokens = [] # 存储压缩后的唯一token列表
vocab_size = len(self.tokenizer) # 获取原始tokenizer的词汇表大小
for tid in range(vocab_size): # 遍历所有原始token ID
text = self.tokenizer.decode([tid], skip_special_tokens=False) # 将token ID解码为文本
if "" in text: # 如果文本中包含空字符串(可能是特殊token)
key = self.tokenizer.convert_ids_to_tokens(tid) # 直接使用原始token表示作为key
else: # 对于普通token
norm = self.normalizer.normalize_str(text) # 对文本进行归一化处理(NFKC、NFD、去重音等)
key = norm if norm else text # 如果归一化结果为空,则使用原始文本
nid = key2new.get(key) # 查找该key是否已经存在
if nid is None: # 如果key不存在,创建新的ID
nid = len(new_tokens) # 新ID等于当前新token列表的长度
key2new[key] = nid # 将key映射到新ID
new_tokens.append(key) # 将key添加到新token列表
old2new[tid] = nid # 将原始token ID映射到新ID
lookup = np.empty(vocab_size, dtype=np.int64) # 创建numpy数组用于快速查找
for tid in range(vocab_size): # 填充查找表
lookup[tid] = old2new[tid] # 将映射关系存入数组
return lookup, len(new_tokens) # 返回查找表和压缩后的词汇表大小核心机制:
- 归一化:NFKC、NFD、去重音、小写、空格规范化
- 映射:将原始 token ID 映射到压缩后的 ID,减少词汇表大小
3. ShortConv (Lines 123-179)
作用:
- 对 Engram 输出进行短卷积处理,捕获局部模式。
- ngram_demo_v1.py: 156-179行
核心代码 (Lines 156-179):
python
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
Input: (B,L,HC_MULT,D) # 输入形状:批次大小、序列长度、hyper-connection倍数、特征维度
Output: (B,L,HC_MULT,D) # 输出形状:与输入相同
"""
B, T, G, C = x.shape # 解包输入张量的维度:批次、时间步、组数、通道数
assert G == self.hc_mult, f"Input groups {G} != hc_mult {self.hc_mult}" # 验证输入组数是否匹配配置
normed_chunks = [] # 存储归一化后的每个通道的chunk
for i in range(G): # 遍历每个hyper-connection通道
chunk = x[:, :, i, :] # 提取第i个通道的所有数据 [B, T, C]
normed_chunks.append(self.norms[i](chunk)) # 对每个通道独立进行归一化
x_norm = torch.cat(normed_chunks, dim=-1) # 在最后一个维度拼接所有归一化的chunk
x_bct = x_norm.transpose(1, 2) # 转置为 [B, C, T] 格式,适配卷积层输入
y_bct = self.conv(x_bct) # 执行深度可分离卷积操作
y_bct = y_bct[..., :T] # 裁剪输出长度,确保与输入序列长度一致
if self.activation: # 如果配置了激活函数
y_bct = self.act_fn(y_bct) # 应用激活函数(如SiLU)
y = y_bct.transpose(1, 2).view(B, T, G, C).contiguous() # 转置回 [B, T, G, C] 并确保内存连续
return y # 返回处理后的张量关键特性:
- 分组归一化:对每个 hyper-connection 通道独立归一化
- 深度可分离卷积:
groups=total_channels,每个通道独立卷积 - 激活:SiLU
4. NgramHashMapping (Lines 188-303)
核心功能:
- 将 N-gram 序列映射到哈希索引,用于查找嵌入。
- engram_demo_v1.py: 219-233行
4.1 初始化阶段 (Lines 219-233)
python
self.layer_multipliers = {} # 存储每层的哈希乘数字典
for layer_id in self.layer_ids: # 遍历所有需要插入Engram的层ID
base_seed = int(seed + PRIME_1 * int(layer_id)) # 为每层生成唯一的随机种子(基于层ID)
g = np.random.default_rng(base_seed) # 创建该层的随机数生成器
r = g.integers( # 生成随机整数数组
low=0, # 最小值
high=half_bound, # 最大值(half_bound是某个上界的一半)
size=(self.max_ngram_size,), # 数组大小等于最大N-gram大小
dtype=np.int64 # 数据类型为64位整数
)
multipliers = r * 2 + 1 # 将随机数转换为奇数(乘以2加1确保为奇数)
self.layer_multipliers[layer_id] = multipliers # 存储该层的乘数数组
self.vocab_size_across_layers = self.calculate_vocab_size_across_layers() # 计算所有层的词汇表大小配置设计要点:
- 为每层生成随机乘数(奇数),用于哈希计算
- 使用种子确保可复现
4.2 质数选择策略 (Lines 235-260)
python
def calculate_vocab_size_across_layers(self):
seen_primes = set() # 记录已使用的质数,避免重复
vocab_size_across_layers = {} # 存储每层每个N-gram每个head的词汇表大小
for layer_id in self.layer_ids: # 遍历所有需要Engram的层
all_ngram_vocab_sizes = [] # 存储该层所有N-gram的词汇表大小
for ngram in range(2, self.max_ngram_size + 1): # 遍历2-gram到max_ngram_size
current_ngram_heads_sizes = [] # 存储当前N-gram所有head的词汇表大小
vocab_size = self.vocab_size_per_ngram[ngram - 2] # 获取当前N-gram的基础词汇表大小
num_head = self.n_head_per_ngram # 获取每个N-gram的head数量
current_prime_search_start = vocab_size - 1 # 从基础词汇表大小-1开始搜索质数
for _ in range(num_head): # 为每个head分配一个质数
found_prime = find_next_prime( # 查找下一个未使用的质数
current_prime_search_start, # 搜索起始点
seen_primes # 已使用的质数集合
)
seen_primes.add(found_prime) # 将找到的质数加入已使用集合
current_ngram_heads_sizes.append(found_prime) # 将质数添加到当前N-gram的head大小列表
current_prime_search_start = found_prime # 更新搜索起始点,继续查找下一个质数
all_ngram_vocab_sizes.append(current_ngram_heads_sizes) # 将当前N-gram的所有head大小添加到列表
vocab_size_across_layers[layer_id] = all_ngram_vocab_sizes # 存储该层的所有N-gram配置
return vocab_size_across_layers # 返回所有层的词汇表大小配置设计要点:
- 为每个 N-gram 的每个 head 选择不同的质数作为模数
- 质数模数有助于减少哈希冲突
4.3 N-gram 哈希计算 (Lines 262-296)
- engram_demo_v1.py: 262-296行
python
def _get_ngram_hashes(
self,
input_ids: np.ndarray, # 输入的token ID数组 [B, T]
layer_id: int, # 当前处理的层ID
) -> np.ndarray: # 返回所有N-gram和head的哈希索引 [B, T, num_heads_total]
x = np.asarray(input_ids, dtype=np.int64) # 确保输入为int64类型的numpy数组
B, T = x.shape # 获取批次大小和序列长度
multipliers = self.layer_multipliers[layer_id] # 获取当前层的哈希乘数数组
def shift_k(k: int) -> np.ndarray: # 定义时间偏移函数,用于构建N-gram
if k == 0: return x # k=0时返回原始序列
shifted = np.pad(x, ((0, 0), (k, 0)), # 在序列左侧填充k个pad_id
mode='constant', constant_values=self.pad_id)[:, :T] # 填充后截取前T个元素
return shifted # 返回偏移后的序列,用于构建不同位置的N-gram
base_shifts = [shift_k(k) for k in range(self.max_ngram_size)] # 生成所有可能的偏移序列
all_hashes = [] # 存储所有N-gram和head的哈希值
for n in range(2, self.max_ngram_size + 1): # 遍历2-gram到max_ngram_size
n_gram_index = n - 2 # 计算N-gram在列表中的索引(2-gram对应索引0)
tokens = base_shifts[:n] # 获取构建n-gram所需的n个偏移序列
mix = (tokens[0] * multipliers[0]) # 初始化混合值:第一个token乘以第一个乘数
for k in range(1, n): # 对剩余的token进行XOR混合
mix = np.bitwise_xor(mix, tokens[k] * multipliers[k]) # 将第k个token乘以对应乘数后与mix进行XOR
num_heads_for_this_ngram = self.n_head_per_ngram # 获取当前N-gram的head数量
head_vocab_sizes = self.vocab_size_across_layers[layer_id][n_gram_index] # 获取当前N-gram所有head的词汇表大小(质数)
for j in range(num_heads_for_this_ngram): # 为每个head计算哈希索引
mod = int(head_vocab_sizes[j]) # 获取当前head的模数(质数)
head_hash = mix % mod # 对混合值取模,得到该head的哈希索引
all_hashes.append(head_hash.astype(np.int64, copy=False)) # 将哈希索引添加到列表
return np.stack(all_hashes, axis=2) # 将所有哈希值堆叠为 [B, T, num_heads_total] 形状哈希算法:
- 时间偏移:生成不同位置的 token 序列(用于构建 N-gram)
- 混合计算:
mix = (token[0] * mult[0]) XOR (token[1] * mult[1]) XOR ... - 取模:
hash = mix % prime,得到每个 head 的索引
示例:
对于 "hello world",2-gram 为 ["hello", "world"],3-gram 为 ["hello", "world", "next"]。
5. MultiHeadEmbedding (Lines 305-324)
作用:
多 head 嵌入查找,将不同 N-gram 和 head 的嵌入拼接。
- engram_demo_v1.py: 305-324行
python
class MultiHeadEmbedding(nn.Module): # 多head嵌入查找模块
def __init__(self, list_of_N: List[int], D: int): # list_of_N: 每个head的词汇表大小列表,D: 嵌入维度
super().__init__() # 调用父类初始化
self.num_heads = len(list_of_N) # 记录head的总数量
self.embedding_dim = D # 记录嵌入维度
offsets = [0] # 初始化偏移列表,第一个head偏移为0
for n in list_of_N[:-1]: # 遍历除最后一个head外的所有head
offsets.append(offsets[-1] + n) # 计算每个head的起始偏移量(累加前一个head的词汇表大小)
self.register_buffer("offsets", torch.tensor(offsets, dtype=torch.long)) # 将偏移量注册为buffer(不参与梯度更新)
total_N = sum(list_of_N) # 计算所有head的总词汇表大小
self.embedding = nn.Embedding(num_embeddings=total_N, embedding_dim=D) # 创建统一的嵌入表
def forward(self, input_ids: torch.Tensor) -> torch.Tensor: # input_ids: [B, T, num_heads] 形状的哈希索引
shifted_input_ids = input_ids + self.offsets # 为每个head的索引添加偏移量,确保不同head使用不同的ID范围
output = self.embedding(shifted_input_ids) # 从嵌入表中查找对应的嵌入向量
return output # 返回查找的嵌入向量 [B, T, num_heads, D]设计要点:
- 偏移策略:为每个 head 分配不同的 ID 范围,避免冲突
- 统一嵌入表:所有 head 共享一个大嵌入表,通过偏移区分
6. Engram 模块 (Lines 326-378)
核心模块,整合上述组件。
6.1 初始化 (Lines 326-356)
python
class Engram(nn.Module): # Engram核心模块,整合所有组件
def __init__(self,layer_id): # layer_id: 当前层的ID
super().__init__() # 调用父类初始化
self.layer_id = layer_id # 保存层ID
self.hash_mapping = NgramHashMapping( # 初始化N-gram哈希映射模块
engram_vocab_size=engram_cfg.engram_vocab_size, # 每个N-gram的词汇表大小
max_ngram_size = engram_cfg.max_ngram_size, # 最大N-gram大小
n_embed_per_ngram = engram_cfg.n_embed_per_ngram, # 每个N-gram的总嵌入维度
n_head_per_ngram = engram_cfg.n_head_per_ngram, # 每个N-gram的head数量
layer_ids = engram_cfg.layer_ids, # 所有需要Engram的层ID列表
tokenizer_name_or_path=engram_cfg.tokenizer_name_or_path, # tokenizer路径
pad_id = engram_cfg.pad_id, # 填充token ID
seed = engram_cfg.seed, # 随机种子
)
self.multi_head_embedding = MultiHeadEmbedding( # 初始化多head嵌入查找模块
list_of_N = [x for y in self.hash_mapping.vocab_size_across_layers[self.layer_id] for x in y], # 展平当前层所有N-gram所有head的词汇表大小
D = engram_cfg.n_embed_per_ngram // engram_cfg.n_head_per_ngram, # 每个head的嵌入维度
)
self.short_conv = ShortConv( # 初始化短卷积模块
hidden_size = backbone_config.hidden_size, # 隐藏状态维度
kernel_size = engram_cfg.kernel_size, # 卷积核大小
dilation = engram_cfg.max_ngram_size, # 卷积膨胀率
hc_mult = backbone_config.hc_mult, # hyper-connection倍数
)
engram_hidden_size = (engram_cfg.max_ngram_size-1) * engram_cfg.n_embed_per_ngram # 计算Engram隐藏状态大小(2-gram和3-gram的总嵌入维度)
self.value_proj = nn.Linear(engram_hidden_size,backbone_config.hidden_size) # 值投影层:将N-gram嵌入投影到隐藏空间
self.key_projs = nn.ModuleList( # 为每个hyper-connection通道创建独立的key投影层
[nn.Linear(engram_hidden_size,backbone_config.hidden_size) for _ in range(backbone_config.hc_mult)] # 创建hc_mult个线性层
)
self.norm1 = nn.ModuleList([nn.RMSNorm(backbone_config.hidden_size) for _ in range(backbone_config.hc_mult)]) # key的归一化层列表
self.norm2 = nn.ModuleList([nn.RMSNorm(backbone_config.hidden_size) for _ in range(backbone_config.hc_mult)]) # query的归一化层列表6.2 前向传播 (Lines 358-378)
- engram_demo_v1.py: 358-378行
python
def forward(self,hidden_states,input_ids): # hidden_states: 隐藏状态,input_ids: token ID序列
"""
hidden_states: [B, L, HC_MULT, D] # 输入隐藏状态:批次、序列长度、hyper-connection倍数、特征维度
input_ids: [B, L] # 输入token ID:批次、序列长度
"""
hash_input_ids = torch.from_numpy(self.hash_mapping.hash(input_ids)[self.layer_id]) # 将input_ids转换为N-gram哈希索引,并选择当前层的哈希结果
embeddings = self.multi_head_embedding(hash_input_ids).flatten(start_dim=-2) # 从嵌入表中查找N-gram嵌入,并展平head维度 [B, L, total_embed_dim]
gates = [] # 存储每个hyper-connection通道的门控值
for hc_idx in range(backbone_config.hc_mult): # 遍历每个hyper-connection通道
key = self.key_projs[hc_idx](embeddings) # 将N-gram嵌入投影为key [B, L, D]
normed_key = self.norm1[hc_idx](key) # 对key进行RMS归一化
query = hidden_states[:,:,hc_idx,:] # 从隐藏状态中提取当前通道的query [B, L, D]
normed_query = self.norm2[hc_idx](query) # 对query进行RMS归一化
gate = (normed_key * normed_query).sum(dim=-1) / math.sqrt(backbone_config.hidden_size) # 计算点积相似度并缩放(类似注意力机制)
gate = gate.abs().clamp_min(1e-6).sqrt() * gate.sign() # 特殊激活:取绝对值、开方、恢复符号,增强区分度
gate = gate.sigmoid().unsqueeze(-1) # 应用sigmoid激活并增加维度 [B, L, 1]
gates.append(gate) # 将门控值添加到列表
gates = torch.stack(gates,dim=2) # 堆叠所有通道的门控值 [B, L, HC_MULT, 1]
value = gates * self.value_proj(embeddings).unsqueeze(2) # 将N-gram嵌入投影为value,并通过门控机制加权 [B, L, HC_MULT, D]
output = value + self.short_conv(value) # 残差连接:将卷积增强后的值与原始值相加
return output # 返回处理后的输出 [B, L, HC_MULT, D]执行流程:
- 哈希查找:将
input_ids转换为 N-gram 哈希索引 - 嵌入检索:从嵌入表中查找对应的 N-gram 嵌入
- 门控机制:
- Key:从 N-gram 嵌入生成
- Query:从隐藏状态生成
- Gate:通过点积计算相似度,使用特殊激活函数
- 值投影:将 N-gram 嵌入投影到隐藏空间
- 门控融合:
value = gate * projected_embeddings - 卷积增强:通过
ShortConv进一步处理
门控激活函数:
python
gate = gate.abs().clamp_min(1e-6).sqrt() * gate.sign() # 取绝对值、确保最小值、开方、恢复原始符号
gate = gate.sigmoid() # 应用sigmoid激活函数,将值压缩到(0,1)区间先取绝对值、开方、恢复符号,再 sigmoid,增强门控的区分度。
7. TransformerBlock (Lines 380-394)
- engram_demo_v1.py: 380-394行
python
class TransformerBlock(nn.Module): # Transformer块,整合Engram、Attention和MoE
def __init__(self,layer_id): # layer_id: 当前层的ID
super().__init__() # 调用父类初始化
self.attn = lambda x:x # 注意力模块占位符(demo中为恒等映射)
self.moe = lambda x:x # MoE模块占位符(demo中为恒等映射)
self.engram = None # 初始化Engram模块为None
if layer_id in engram_cfg.layer_ids: # 如果当前层ID在配置的层列表中
self.engram = Engram(layer_id=layer_id) # 创建Engram模块实例
def forward(self,input_ids,hidden_states): # input_ids: token ID,hidden_states: 隐藏状态
if self.engram is not None: # 如果当前层有Engram模块
hidden_states = self.engram(hidden_states=hidden_states,input_ids=input_ids) + hidden_states # Engram增强:残差连接
hidden_states = self.attn(hidden_states) + hidden_states # 注意力层:残差连接
hidden_states = self.moe(hidden_states) + hidden_states # MoE层:残差连接
return hidden_states # 返回处理后的隐藏状态设计要点:
- 仅在指定层插入 Engram
- 残差连接:
hidden_states = engram_output + hidden_states - Attention 和 MoE 为占位(demo 中为恒等映射)
四、完整数据流
- engram_demo_v1.py: 396-422行
python
if __name__ == '__main__': # 主程序入口
LLM = [ # 构建完整的语言模型结构
nn.Embedding(backbone_config.vocab_size,backbone_config.hidden_size), # 词嵌入层:将token ID转换为嵌入向量
*[TransformerBlock(layer_id=layer_id) for layer_id in range(backbone_config.num_layers)], # 展开所有Transformer块(第1和15层包含Engram)
nn.Linear(backbone_config.hidden_size, backbone_config.vocab_size) # 输出投影层:将隐藏状态投影到词汇表大小
]
text = "Only Alexander the Great could tame the horse Bucephalus." # 测试文本
tokenizer = AutoTokenizer.from_pretrained(engram_cfg.tokenizer_name_or_path,trust_remote_code=True) # 加载tokenizer
input_ids = tokenizer(text,return_tensors='pt').input_ids # 将文本转换为token ID张量 [1, L]
B,L = input_ids.shape # 获取批次大小和序列长度
for idx, layer in enumerate(LLM): # 遍历模型的所有层
if idx == 0: # 第一层:词嵌入层
hidden_states = LLM[0](input_ids) # 将token ID转换为嵌入向量 [B, L, D]
## mock hyper-connection # 模拟hyper-connection:扩展维度
hidden_states = hidden_states.unsqueeze(2).expand(-1, -1, backbone_config.hc_mult, -1) # [B, L, D] -> [B, L, HC_MULT, D]
elif idx == len(LLM)-1: # 最后一层:输出投影层
## mock hyper-connection # 模拟hyper-connection:只使用第一个通道
hidden_states = hidden_states[:,:,0,:] # 从 [B, L, HC_MULT, D] 提取第一个通道 [B, L, D]
output = layer(hidden_states) # 投影到词汇表大小 [B, L, vocab_size]
else: # 中间层:Transformer块
hidden_states = layer(input_ids=input_ids,hidden_states=hidden_states) # 通过Transformer块处理
print("✅ Forward Complete!") # 打印完成信息
print(f"{input_ids.shape=}\n{output.shape=}") # 打印输入和输出的形状执行流程:
- Tokenization:文本 → token IDs
- Embedding:token IDs → 初始嵌入
- Hyper-connection 扩展:
[B, L, D]→[B, L, HC_MULT, D] - 逐层处理:
- 第 1、15 层:Engram 增强
- 其他层:标准 Transformer 块(demo 中为占位)
- 输出投影:
[B, L, HC_MULT, D]→[B, L, vocab_size]
五、设计要点
- O(1) 查找:通过哈希直接索引嵌入表
- 确定性寻址:相同 N-gram 总是映射到相同索引
- 多 head 设计:每个 N-gram 使用多个 head 减少冲突
- 条件记忆:通过门控机制动态融合静态 N-gram 记忆与动态隐藏状态
- 稀疏激活:仅在特定层使用 Engram
六、优势
- 效率:O(1) 查找,可卸载到主机内存
- 知识存储:静态 N-gram 记忆存储常见模式
- 互补性:与 MoE 形成计算与存储的权衡
- 可扩展:嵌入表可独立扩展
注意:该实现展示了 Engram 的核心逻辑,生产环境需要 CUDA 优化和分布式支持。