过去一年,AI 计算基础设施的讨论大多集中在数据中心:更大的 GPU、更高密度的算力集群、更大规模的大模型。但随着 AI Agent、私有化大模型部署以及本地推理需求的快速增长,另一条技术路线正在逐渐受到关注------本地 AI Agent 运行环境(Local AI Agent Runtime)。
在这一背景下,AMD 最近推出了一个面向开发者的开源框架 OpenClaw,并配套提出两种硬件参考配置:RyzenClaw 与 RadeonClaw。其核心思路并不是继续把 AI 推向更大的数据中心,而是尝试让 AI Agent 能够稳定运行在本地计算设备上,并支持多 Agent 协作、长期上下文记忆以及离线运行。
从技术路线来看,这套方案其实代表着一个很明确的趋势:未来部分 AI 工作负载会从云端回流到本地算力设备。

一、OpenClaw:面向本地 AI Agent 的运行框架
OpenClaw 的定位并不是一个新的大模型,而是一套 用于在本地运行 AI Agent 的开发框架与参考环境。整个系统基于 Windows 平台构建,通过 WSL2(Windows Subsystem for Linux) 提供 Linux 运行环境,并结合本地推理框架实现完整 AI Agent 运行能力。
核心技术栈包括:
●WSL2:在 Windows 上提供 Linux 运行环境
●LM Studio:本地模型管理与推理工具
●llama.cpp:高效 CPU/GPU 推理后端
●Memory.md:基于 embedding 的本地记忆系统

在该架构下,大模型推理完全在本地执行,不依赖云端 API。开发者可以直接运行诸如:
Qwen 3.5 35B A3B
这样的中大型模型,并构建 多 Agent 协作系统(multi-agent workflow)。
Memory.md 则用于构建本地知识记忆体系,使 AI Agent 能够持续积累上下文,而无需依赖云端数据库或外部服务。
从设计思路来看,OpenClaw 的目标非常明确:构建一个完全本地化、可控、可扩展的 AI Agent 运行环境。

二、RyzenClaw:高上下文、本地多 Agent 运行方案
OpenClaw 提供的第一套参考配置是 RyzenClaw 。
RyzenClaw 路径依赖 Ryzen AI Max+ 平台。AMD 推荐使用配备 128GB 统一内存的系统,并建议将其中约 96GB 预留为可变显存。统一内存架构使 CPU 与 GPU 可以直接共享同一块内存空间,避免了传统独立显卡在 PCIe 总线上的数据复制开销。在这种配置下,运行 Qwen 3.5 35B A3B 模型时,系统每秒大约可以生成 45 个 token,处理 10,000 个输入 token 约需 19.5 秒,同时支持约 26 万 token 的上下文窗口,并能够并行运行最多 6 个代理实例。
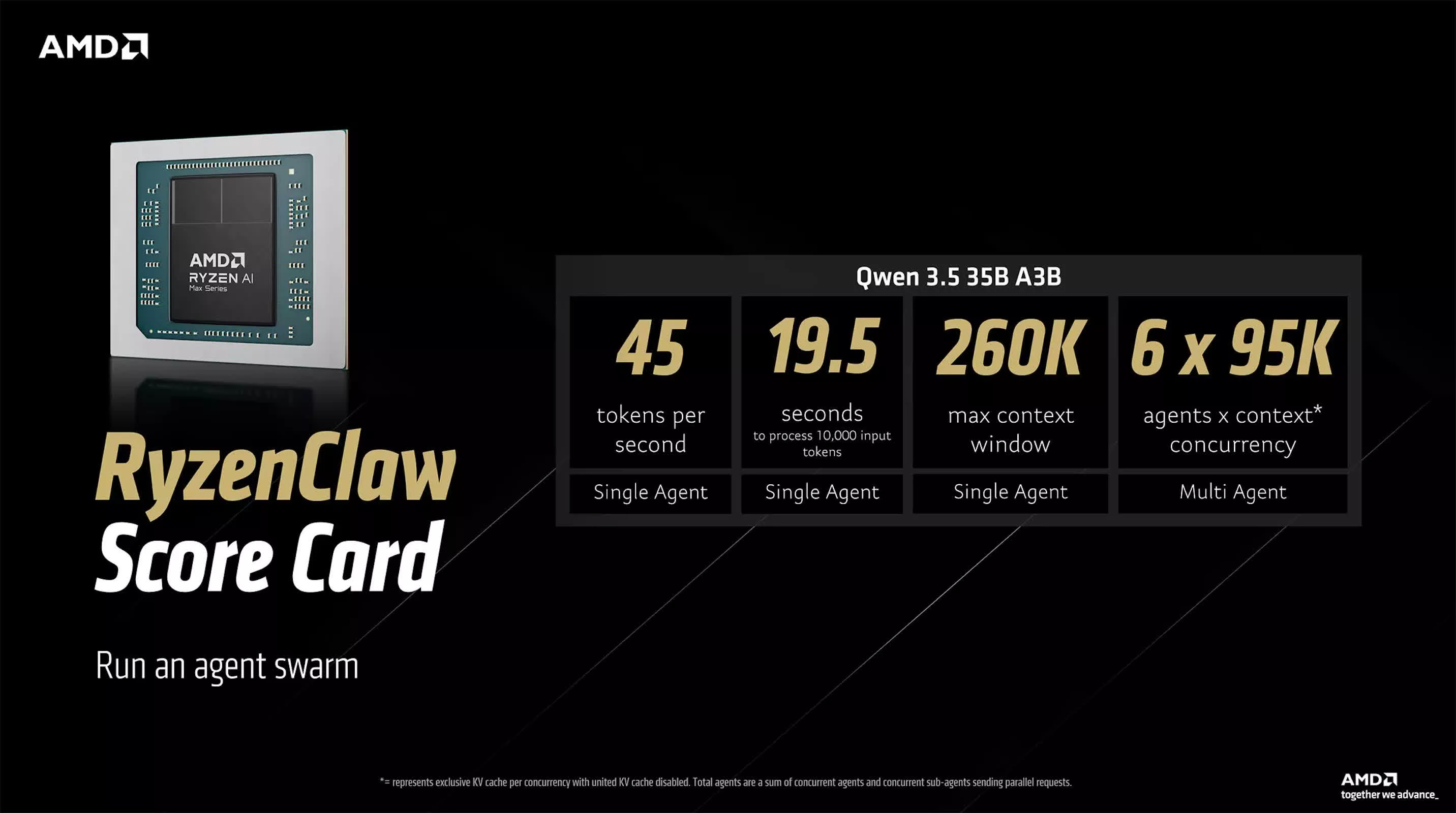
可以看到,这种架构的特点并不是极致推理速度,而是 大上下文 + 多 Agent 并发能力。
对于以下场景尤其有价值:
●多 Agent 协作系统
●长上下文知识分析
●本地 AI 工作流自动化
●Agent Swarm 实验环境
换句话说,RyzenClaw 更像是一种 AI Agent 工作站架构。
三、RadeonClaw:高推理吞吐 GPU 方案
OpenClaw 的第二种参考配置是 RadeonClaw ,该方案把计算负载转移到独立 GPU。
RadeonClaw 则采用独立显卡方案,核心硬件为 Radeon AI PRO R9700。这是一款面向工作站的 GPU,配备 32GB 显存。在相同模型下,其推理速度明显更高,每秒约 120 token,处理 10,000 个输入 token 的时间约为 4.4 秒。独立显存容量限制了上下文窗口规模,最大约 19 万 token,并发代理数量也减少至两个。

与 RyzenClaw 相比,这种架构更偏向:
●更高推理吞吐
●更低响应延迟
●更适合实时 Agent 交互
但由于显存限制,其上下文窗口和 Agent 并发数量会有所降低。
这也是典型的 CPU统一内存 vs GPU高吞吐 的架构取舍。
四、两种架构的核心差异
如果从系统设计角度来看,RyzenClaw 与 RadeonClaw 实际代表了 两种不同的本地 AI Agent 计算模式:
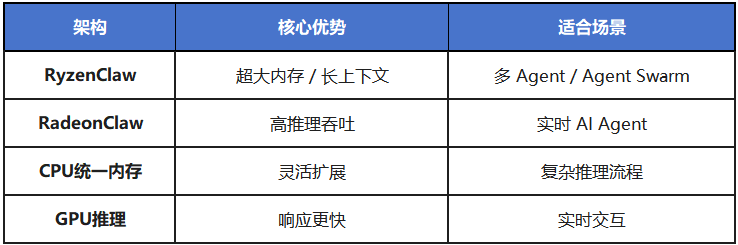
换句话说:
RyzenClaw = AI Agent 实验平台
RadeonClaw = AI Agent 高性能推理节点
五、本地 AI Agent 的现实意义
虽然 OpenClaw 目前主要面向开发者和工程师,但它背后其实反映的是一个正在快速形成的趋势:
AI Agent 不一定必须运行在云端。
本地化部署带来的价值包括:
●数据隐私与安全控制
●无需持续 API 费用
●低网络依赖
●更高系统可控性
●可持续运行的个人 AI 助手
随着本地算力设备持续升级,本地 AI Agent 很可能成为 未来个人计算设备的重要形态之一。
六、从技术方案到实际部署
从基础架构角度看,OpenClaw 提供的是一套 参考实现方案。
但在实际企业或研发环境中,往往还需要进一步优化,例如:
●GPU / CPU 架构选型
●本地大模型部署优化
●Agent 框架整合
●多节点算力扩展
●私有化 AI 推理环境构建
我们在此前已经针对 Intel CPU 工作站方案 以及 NVIDIA GPU AI 工作站方案进行了大量实测与部署实践,包括本地大模型推理、AI Agent 系统以及企业私有化 AI 环境。
在此基础上,针对 AMD OpenClaw 所提出的 RyzenClaw / RadeonClaw 架构,我们同样可以提供对应的 AI Agent 本地运行工作站方案,包括:
●Ryzen AI Max 系列 AI 工作站
●Radeon AI PRO GPU 推理工作站
●本地大模型部署环境
●AI Agent 开发测试平台
对于需要构建 本地 AI Agent 研发环境或私有化 AI 推理平台的团队来说,这类架构已经逐渐具备实际落地价值。
随着本地算力不断增强,未来 AI Agent 工作站与数据中心算力之间的界限,可能也会越来越模糊。