文章目录
- 一、概述
- 二、结构
-
- [2.1 输入](#2.1 输入)
- [2.2 Encoder Block](#2.2 Encoder Block)
-
- [2.2.1 多头自注意力层(Multi-Head Self-Attention, MHSA)](#2.2.1 多头自注意力层(Multi-Head Self-Attention, MHSA))
- [2.2.2 前馈网络层(Multi-Layer Perceptron, MLP)](#2.2.2 前馈网络层(Multi-Layer Perceptron, MLP))
- [2.3 输出](#2.3 输出)
- 三、总结
一、概述
Vision Transformer(ViT) 是将自然语言处理领域的 Transformer 架构直接迁移到计算机视觉的开创性模型,由 Google 在 2020 年提出,论文标题为 《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》。
简单来说,ViT就是把图片当成一句话,用 Transformer 做图像分类。
ViT论文链接https://arxiv.org/pdf/2010.11929
二、结构
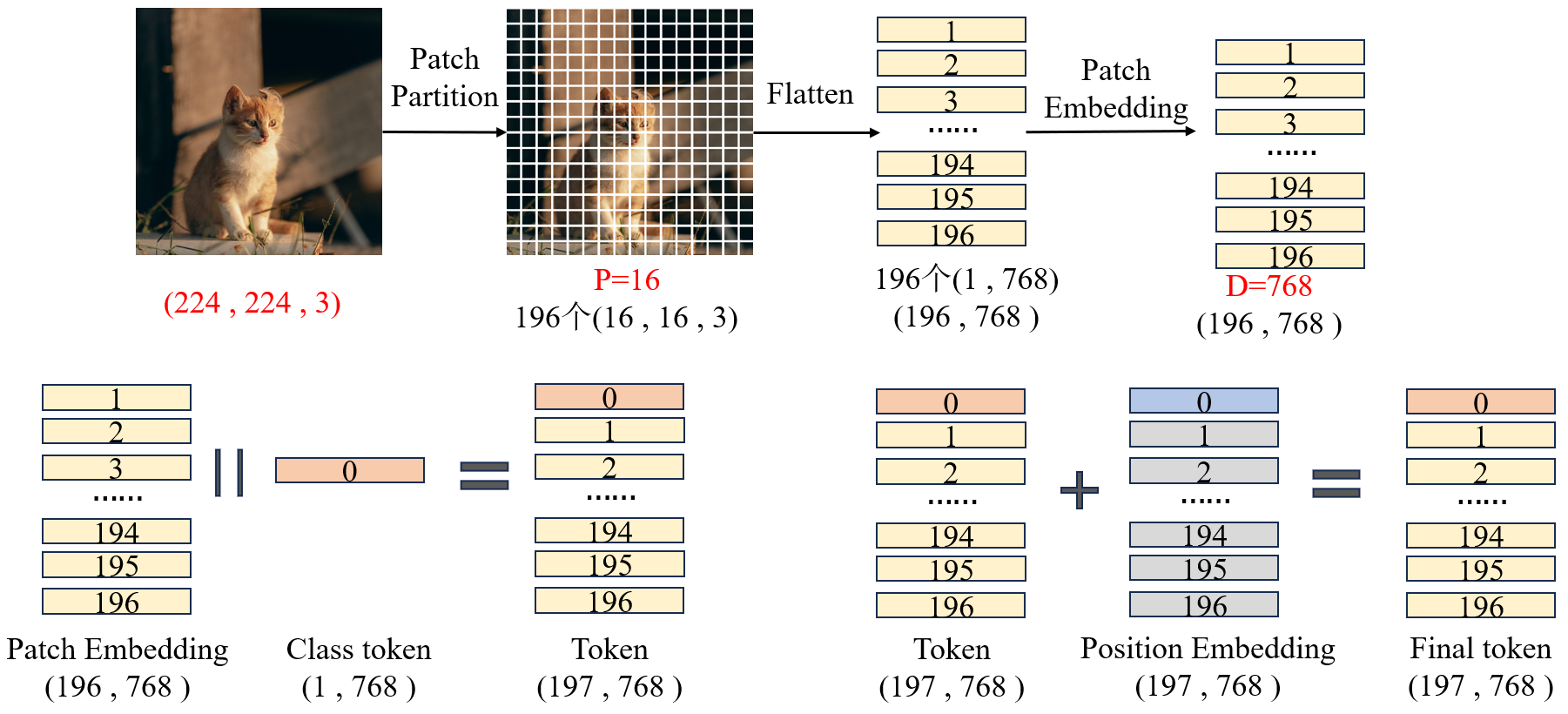
2.1 输入
CNN 以局部感受野逐层提取特征,依赖卷积的局部归纳偏置。而 Transformer 天然处理序列数据,无法直接输入二维图像。因此需要将二维图像结构化地拆分为一维序列,同时保留空间结构信息,使图像能够输入 Transformer Encoder。
通过分块、展平、线性投影,将图像转化为 Transformer 可处理的Token 序列,同时保留图像的空间结构信息,为自注意力机制提供全局建模基础。
1、原始图像表示
设输入图像为: X ∈ R H × W × C \mathbf{X} \in \mathbb{R}^{H \times W \times C} X∈RH×W×C- H H H:高度
- W W W:宽度
- C C C:通道数(RGB 为 3)
2、分块操作(Patch Partition)
选择分块尺寸 P×P,将图像均匀切分成互不重叠的图像块(Patch)。- 分块数量: N = H P × W P N = \frac{H}{P} \times \frac{W}{P} N=PH×PW
- 每个块为: X p ∈ R P × P × C \mathbf{X_p} \in \mathbb{R}^{P \times P \times C} Xp∈RP×P×C
3、展平(Flatten)
将每个 Patch 展平为一维向量:- 展开后的一维向量的维度为 P 2 ⋅ C {P^2 \cdot C} P2⋅C,即 x p flat ∈ R P 2 ⋅ C \mathbf{x}_p^\text{flat} \in \mathbb{R}^{P^2 \cdot C} xpflat∈RP2⋅C
- 此时图像从: H × W × C ⟹ N × ( P 2 C ) H×W×C⟹N×(P^2C) H×W×C⟹N×(P2C)
4、线性映射(Patch Embedding)- 上述维度并不一定是 ViT 想要的维度,ViT 想要的输入维度为隐藏维度D。因此需要把长度不一样的向量,统一变成长度一样的向量。
- z p = x p f l a t ⋅ W E \mathbf{z}_p=\mathbf{x}_p^{flat}⋅W_E zp=xpflat⋅WE
- W E ∈ R ( P 2 C ) × D 为投影矩阵 W_E∈\mathbb{R}^{(P^2C)×D} 为投影矩阵 WE∈R(P2C)×D为投影矩阵
5、增加class token- class token 是一个 可学习的一维向量(维度 1×D),在输入序列最前面插入,让输入序列从 N×D 变成 (N+1)×D。
- 我们的目标是对整张图像分类,但现在有 N 个 Patch 的特征,该用哪一个?
- Transformer 的自注意力机制会让 class token 和所有 Patch token 交互------ 它会看遍所有 Patch 的特征,把整张图的全局信息整合到自己身上。
6、增加Position Embedding- 位置编码的唯一目的:给每个 Patch Token 打上 "空间位置标签",让 Transformer 知道每个 Patch 在图像中的具体位置。
- 位置编码的维度和Patch Embedding 完全一致(D 维,比如 768)。数量和输入序列长度一致(N+1 个)。将位置编码与向量直接相加,相加后维度不变。
- ViT 用的是 可学习的位置编码(区别于原始 Transformer 的正弦余弦位置编码),是模型的可训练参数,训练过程中自动学习不同位置该怎么编码。
最终得到 Patch Embedding: Z 0 ∈ R ( N + 1 ) × D Z_0∈\mathbb{R}^{(N+1)×D} Z0∈R(N+1)×D
z 0 = x c l a s s ; x 1 f l a t ⋅ W E ; . . . . . . ; x N f l a t ⋅ W E + P E z0=\\mathbf{x}_{class};\\mathbf{x}_1\^{flat}⋅WE;......;\\mathbf{x}_N\^{flat}⋅WE+PE z0=xclass;x1flat⋅WE;......;xNflat⋅WE+PE
- 输入图像:224×224×3 、Patch 大小:P=16、 Transformer 隐层维度:D=768
- 图像被切成 196 个 16×16 的小块。(224*224/16*16=196块)
- 每个patch展平后变成 768 维向量。(16*16*3=768),196个patch最终维度为196*768
- 这里刚好展开后的维度 P 2 ∗ C P^2*C P2∗C = 隐藏维度 D D D =768,所以映射后维度不变,仍是 768。得:196×768
- 在最前面加 1 个可学习向量:1×768。序列为:197×768
- 为序列添加位置编码,最终序列不变,仍为:197×768
2.2 Encoder Block
ViT 里的 Encoder 是重复堆叠 L 层(比如 ViT-Base 堆 12 层),每层结构完全一致,核心是【自注意力 + 前馈网络】的组合,还加了 Layer Norm 和残差连接(Residual Connection)。
假设:第 ℓ ℓ ℓ 层输入: Z ℓ − 1 Z_{ℓ−1} Zℓ−1。第 ℓ ℓ ℓ 层输出: Z ℓ Z_ℓ Zℓ
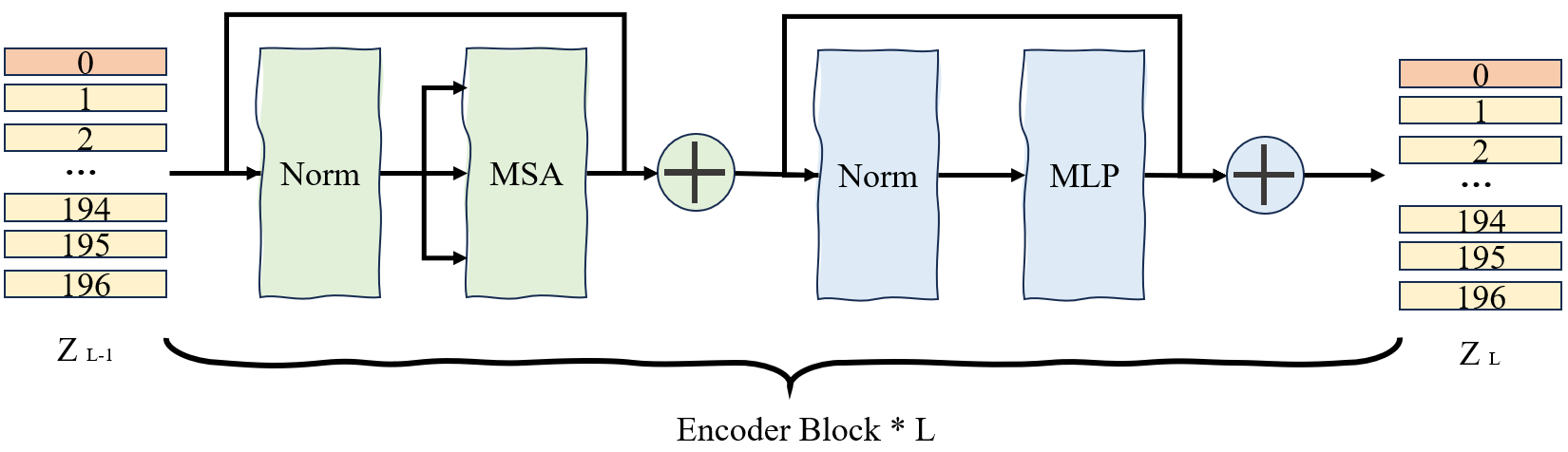
2.2.1 多头自注意力层(Multi-Head Self-Attention, MHSA)
Z ℓ ′ = M H S A ( L a y e r N o r m ( Z ℓ − 1 ) ) + Z ℓ − 1 Z_ℓ^′=MHSA(LayerNorm(Z_{ℓ−1}))+Z_{ℓ−1} Zℓ′=MHSA(LayerNorm(Zℓ−1))+Zℓ−1
子模块1:层归一化:对每个 token 独立做归一化,稳定训练、消除特征尺度差异。子模块2:多头自注意力机制:建模全局依赖关系,捕捉不同空间、不同语义层次的关联,结合位置编码,使模型感知空间结构子模块3:残差连接:解决深度网络梯度消失,保证浅层信息直接传递到深层
2.2.2 前馈网络层(Multi-Layer Perceptron, MLP)
Z ℓ = M L P ( L a y e r N o r m ( Z ℓ ′ ) ) + Z ℓ ′ Z_ℓ=MLP(LayerNorm(Z_ℓ^′))+Z_ℓ^′ Zℓ=MLP(LayerNorm(Zℓ′))+Zℓ′
子模块1:层归一化:对每个 token 独立做归一化,稳定训练、消除特征尺度差异。子模块2:MLP 前馈网络:ViT 的 MLP 为两层线性变换 + 非线性激活,对每个 token 特征进行非线性变换与特征增强,提升模型表达能力。
M L P ( Z ) = L i n e a r 2 ( G E L U ( L i n e a r 1 ( Z ) ) ) MLP(Z)=Linear_2(GELU(Linear_1(Z))) MLP(Z)=Linear2(GELU(Linear1(Z)))
- 升维:让特征在高维空间变得线性可分
- 非线性激活:引入复杂函数拟合能力
- 降维:把学到的高阶信息压缩回固定维度
子模块3:残差连接:解决深度网络梯度消失,保证浅层信息直接传递到深层
2.3 输出
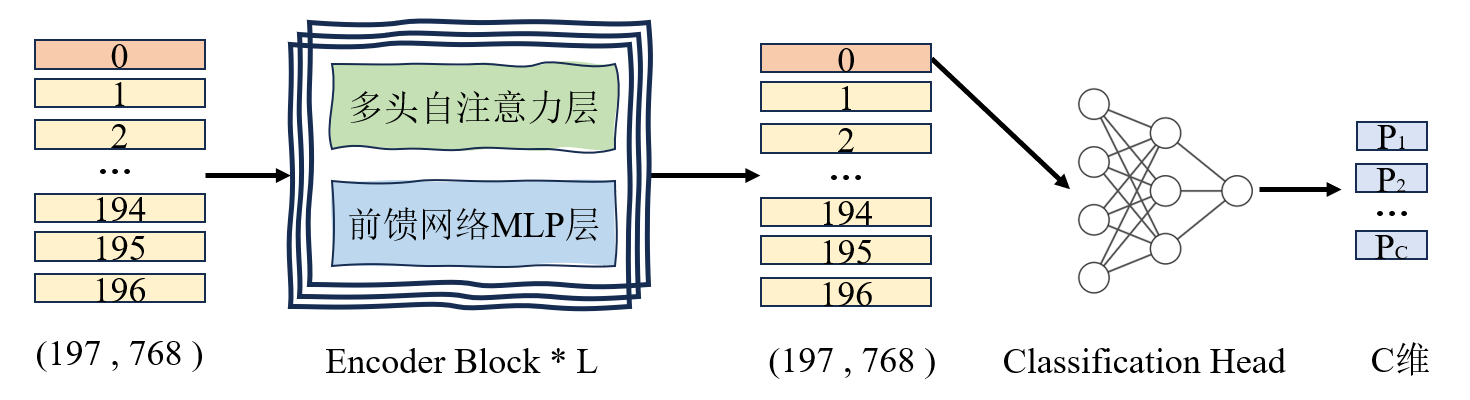
输入:经过 L 层 Encoder 后,模型输出一个序列: Z l ∈ R ( N + 1 ) × D Z_l∈\mathbb{R}^{(N+1)×D} Zl∈R(N+1)×D。这一步输出的是 所有 token 的高级特征。提取 class token:我们只拿第 0 号位置的 class token 代表整张图像,这个向量 = 整张图片的全局特征表示。送入分类头:分类头(Classification Head)就是一个线性层,把 D 维特征映射到类别数 C。C 为数据集类别总数。输出Logits模型最后一层线性层直接输出的原始分数,可正可负。softmax:经过 Softmax 归一化后的值,范围 0, 1,且所有类别的和 = 1。最终输出是一个 长度 = 类别数量 C 的向量,C 为数据集类别总数。向量中每一维表示输入图像属于对应类别的预测概率。
三、总结
核心创新:
- 直接将图像视为序列,使用纯 Transformer 结构完成视觉任务。
- 依靠自注意力实现全局感受野,突破 CNN 逐层扩大感受野的限制。
- 使用 class token 聚合全局信息,位置编码保留空间结构。
- 在大规模数据上表现优异,泛化性与表达能力强。
和CNN的主要对比:
| 对比维度 | CNN | Vision Transformer (ViT) |
|---|---|---|
| 核心结构 | 卷积层 + 池化层 + 全连接层 | Patch Embedding + Transformer Encoder |
| 特征建模方式 | 局部卷积,逐层提取 | 全局自注意力,序列建模 |
| 感受野 | 从小到大,逐层扩大 | 第一层即可覆盖全局 |
| 先验知识 | 强(局部性、权重共享、平移不变) | 弱,几乎无人工先验 |
| 位置信息 | 天然自带,无需额外处理 | 必须显式加入位置编码 |
| 全局依赖建模 | 弱,需多层堆叠间接实现 | 强,可直接建模长距离关系 |
| 数据依赖 | 小数据集即可训练良好 | 需要大规模数据预训练 |
| 计算复杂度 | 相对较低,推理快 | 较高,注意力复杂度为 O(N2) |
| 擅长任务 | 边缘 / 纹理特征、轻量任务、小数据场景 | 全局结构、语义理解、大数据场景 |
| 分类依据 | 卷积输出全局平均池化 | 取 class token 作为全局特征 |
ViT 去掉分类头后,特征可以被复用,适配各种下游任务:
| 任务类型 | 改造方式 | 典型模型 |
|---|---|---|
| 目标检测 | 在 patch 特征上添加检测头 | DETR, ViT-FRCNN, YOLOv8-ViT |
| 语义分割 | 对 patch 特征做上采样 / 解码 | SegViT, SETR, Mask2Former |
| 图像生成 | 用 Transformer 做生成式建模 | Stable Diffusion (ViT 变体), DALL-E |
| 多模态任务 | 与文本 Transformer 对齐 | CLIP, BLIP, Flamingo |
| 姿态估计 / 跟踪 | 提取 patch 特征做回归 | ViTPose, TrackFormer |