目录
[(3)词嵌入 除偏 例子](#(3)词嵌入 除偏 例子)
1.情感分类
(1)是什么
- 情感分类(sentiment classification)任务就是看一段文本,然后分辨这个人是否喜欢他们在讨论的这个东西,这是NLP中最重要的模块之一,经常用在许多应用中。
- 情感分类一个最大的挑战就是可能标记的训练集没有那么多,训练集大小从10,000到100,000个单词都很常见,甚至有时会小于10,000个单词,但是有了词嵌入,即使只有中等大小的标记的训练集,你也能构建一个不错的情感分类器,让我们看看是怎么做到的。
(2)例子

- 上图所示,是一个情感分类问题的例子,输入x是一段文本,而输出y是要预测的相应情感。例如一个餐馆评价的星级。
- 比如"The dessert is excellent."(甜点很棒),四星的评价(review);"Service was quite slow"(服务太慢),这是两星评价;"Good for a quick meal but nothing special"(适合吃快餐但没什么亮点),三星评价;还有比较刁钻的评论,"Completely lacking in good taste, good service and good ambiance."(完全没有好的味道,好的服务,好的氛围),给了一星评价。
- 如果你能训练一个从x到y的映射,基于这样的标记的数据集,那么你就了解大家对餐馆的评价。
(3)简单模型
- 先来介绍一个简单的用于情感分类任务的模型,他采用了平均运算单元
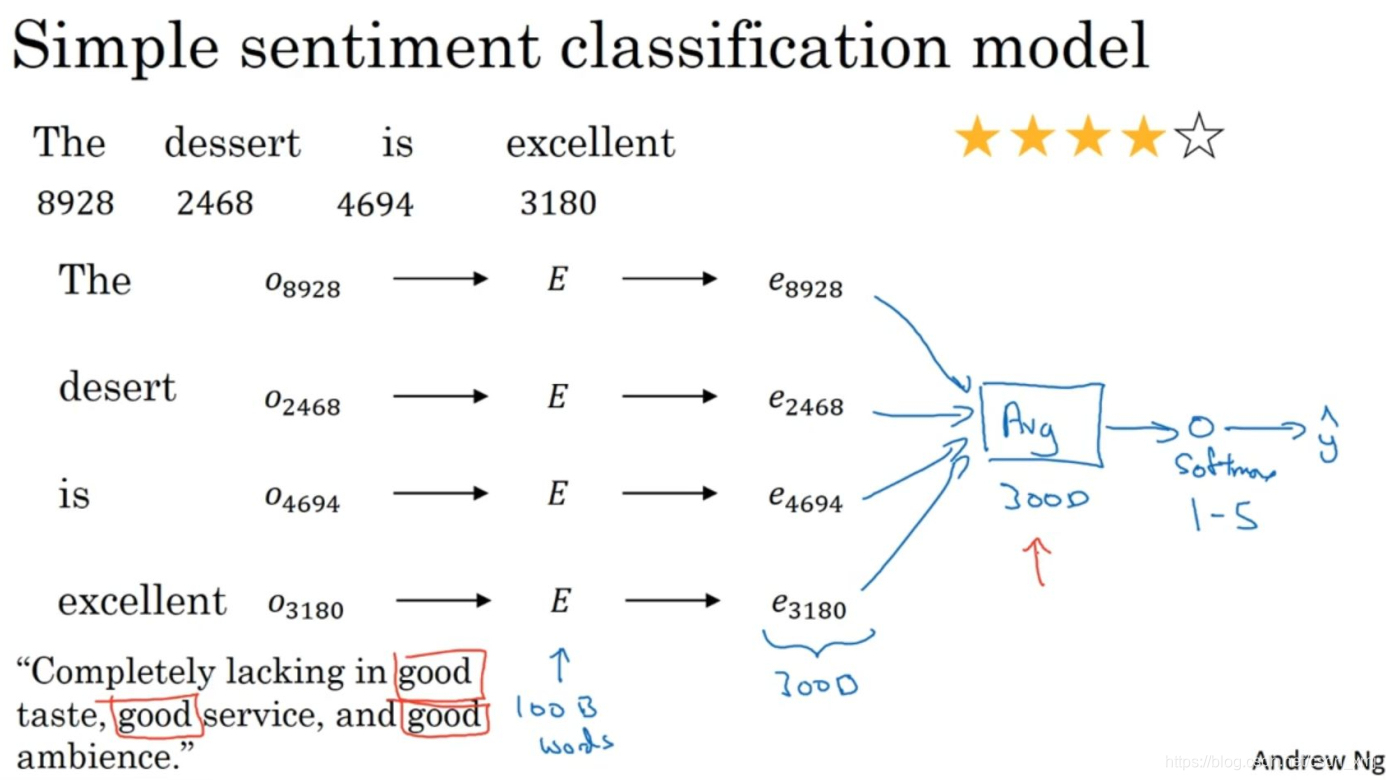
- 取输入词的嵌入向量(假设是是300维度的向量),接着把它们求和或者求平均。这里取平均之后会得到一个300维的特征向量,把这个特征向量送进softmax分类器,然后输出y帽。这个softmax能够输出5个可能结果的概率值,从一星到五星,这个就是5个可能输出的softmax结果用来预测y的值。这里用的平均值运算单元。
- 这个算法适用于任何长短的评论,即使你的评论是100个词长,你也可以对这一百个词的特征向量求和或者平均它们,然后得到一个表示一个300维的特征向量表示,然后把它送进你的softmax分类器,所以这个平均值运算效果不错。
- 这个算法有一个问题就是 没考虑词序,所以可能把好评差评混淆
(4)RNN做情感分类

- 上图所示,首先取这条评论,"Completely lacking in good taste, good service, and good ambiance.",用每一个one-hot向量乘以词嵌入矩阵E,得到词嵌入表达e,然后把它们送进RNN里。RNN的工作就是在最后一步(上图编号<1>)计算一个特征表示,用来预测y帽,这是一个多对一的网络结构。这个算法考虑到了词的顺序,所以效果更好。
2.词嵌入除偏
(1)简介
- 人工智能算法正渐渐地被信任用以辅助或是制定极其重要的决策,因此我们想尽可能地确保它们不受非预期形式偏见影响,比如说性别歧视、种族歧视等。本节视频中Andrew会展示词嵌入中一些有关减少或是消除这些形式的偏见的办法
(2)偏见的例子

- 如上图,我们讨论的大部分内容是词嵌入是怎样学习类比像Man:Woman,就像King:Queen,另外,如果Man对应Computer Programmer,那么Woman会对应什么呢?
- 一个已经完成学习的词嵌入可能会输出Man:Computer Programmer,同时输出Woman:Homemaker,那个结果看起来是不好的的,因为它体现了性别歧视。如果算法输出的是Man:Computer Programmer,同时Woman:Computer Programmer这样就比较好。
- 其他例子比如:Father对应Doctor,那么Mother应该对应什么呢?一个十分不幸的结果是,有些完成学习的词嵌入会输出Mother:Nurse。
(3)词嵌入 除偏 例子
-

-
如上,已经完成一个词嵌入的学习,那么babysitter,doctor,grandmother,grandfather分布在左上方的坐标系中,也许girl嵌入在这里,boy嵌入在这里,也许she嵌在这里,he在这里,所以首先我们要做的事就是辨别出我们想要减少或想要消除的特定偏见的趋势。
-
这里以性别歧视为例(分析思路对其他类型的偏见是通用的),如何?主要有以下三个步骤:
-
第一:对于性别歧视这种情况来说,我们能做的是e_he - e_she,因为它们的性别不同,然后将e_male - e_female,然后将这些差简单地求平均。
-
第二步:中和步,对于那些中性的词可以将其处理一下,避免偏见。比如doctor,nurse这种我们就可以将它们在这个轴上进行处理,来减少或是消除他们的性别歧视趋势的成分。
-
第三步:均衡步 ,对于grandmother和grandfather或者是girl和boy这样的词对,我们只希望其区别是性别。nurse和grandmother之间的距离实际上是小于nurse和grandfather之间的,因此这可能会加重偏见,所以在最后的均衡步中,我们想要确保的是像grandmother和grandfather这样的词都能够有一致的相似度(相等的距离)