混合知识库搭建:本地Docker部署Neo4j图数据库与Milvus向量库
前言
在多代理混合RAG系统中,知识库是"知识储备核心",直接决定了代理检索的精准度与响应质量。上一篇我们解析了5个子代理的执行逻辑,而这些代理能高效完成知识检索任务,背后依赖"Neo4j图知识库+Milvus向量库"的混合支撑------图知识库擅长挖掘实体关系,向量库精准匹配语义细节,二者互补形成全场景知识覆盖。
本文作为系列博客的第三篇,将聚焦混合知识库的落地实现:从本地Docker部署、数据建模、索引构建,到双库协同逻辑,手把手带你搭建高可用的混合知识库,让你掌握"关系型知识+语义型知识"的全链路管理技巧。
1 混合知识库的设计逻辑:为什么需要"图+向量"双引擎?
1.1 单一知识库的局限性
- 纯图数据库:擅长实体关系查询(如"小米的合作品牌"),但无法高效处理细粒度文本检索(如"苹果的环保目标细节");
- 纯向量数据库:擅长语义相似性检索(如"查找与5G技术相关的内容"),但难以挖掘实体间的复杂关联(如"华为-开发-鸿蒙-适配-智能设备")。
1.2 混合知识库的核心优势
"Neo4j图库+Milvus向量库"的组合,完美弥补了单一知识库的短板:
- 互补覆盖:图库处理"关系型知识",向量库处理"语义型知识",覆盖结构化、半结构化、非结构化知识场景;
- 提升效率:关系查询走图库,语义查询走向量库,避免单一知识库的"一刀切"检索瓶颈;
- 适配多代理:graph_kg代理调用图库,vec_kg代理调用向量库,实现代理与知识库的精准绑定。
1.3 混合知识库与代理的对应关系
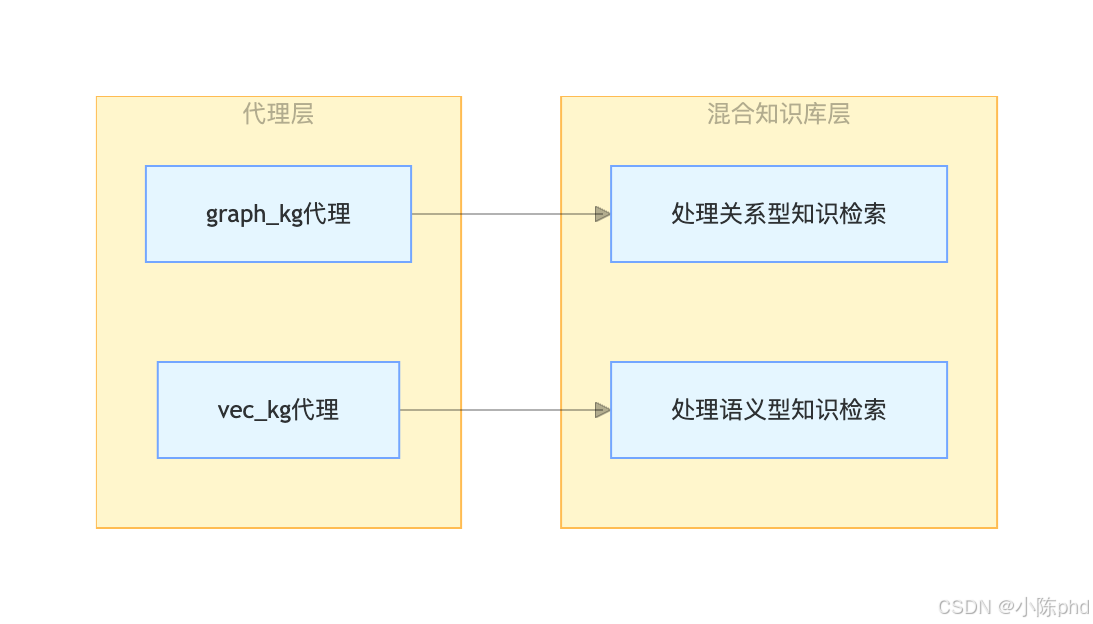
2 本地Docker部署:Neo4j图数据库搭建
2.1 部署准备
- 依赖环境:Docker已启动(参考第一篇博客的Docker Compose配置);
- 核心端口:7474(Web管理界面)、7687(Bolt协议端口,代码连接核心);
- 初始配置:用户名
neo4j,密码password(Docker Compose中已预设)。
2.2 启动与验证
- 启动服务:通过Docker Compose启动Neo4j(命令参考第一篇);
- Web界面验证:浏览器访问
http://localhost:7474,输入用户名密码登录,首次登录需修改密码(保持与代码配置一致); - 代码连接验证:通过LangChain的
Neo4jGraph类测试连接,核心代码:
python
from langchain_community.graphs import Neo4jGraph
# 初始化Neo4j连接
graph = Neo4jGraph(
url='bolt://localhost:7687',
username="neo4j",
password="password", # 与Web界面修改后的密码一致
database="neo4j"
)
print("Neo4j连接成功!")2.3 数据建模:从文本到图结构的自动转换
系统通过LLMGraphTransformer将非结构化文本(如doc/company.txt)自动转换为图结构(实体+关系),无需手动建模,核心流程如下:
2.3.1 核心依赖
python
from langchain_experimental.graph_transformers import LLMGraphTransformer
from langchain_core.documents import Document2.3.2 数据加载与转换
python
# 1. 加载文本知识库(公司相关文本)
current_dir = os.path.dirname(os.path.abspath(__file__))
company_txt_path = os.path.normpath(os.path.join(current_dir, "doc", "company.txt"))
with open(company_txt_path, 'r', encoding="utf-8") as file:
content = file.read()
documents = [Document(page_content=content)]
# 2. 初始化LLMGraphTransformer(通过大模型自动提取实体与关系)
graph_llm = ChatOpenAI(temperature=0, model_name="qwen-plus-2025-12-01", api_key=key, base_url=base_url)
graph_transformer = LLMGraphTransformer(llm=graph_llm)
# 3. 文本→图结构转换(实体:如Company、Technology;关系:如DEVELOPS、COOPERATES_WITH)
graph_documents = graph_transformer.convert_to_graph_documents(documents)
# 4. 插入Neo4j图数据库
graph.add_graph_documents(graph_documents)
print(f"成功插入{len(graph_documents)}个图文档,包含实体数:{len(graph_documents[0].nodes)}")2.3.3 自动生成的图结构示例
| 实体类型 | 实体示例 | 关系类型 | 关系示例 |
|---|---|---|---|
| Company | 小米科技有限责任公司、华为技术有限公司 | DEVELOPS | 华为→DEVELOPS→鸿蒙操作系统 |
| Technology | 5G通信技术、智能手表芯片 | COOPERATES_WITH | 小米→COOPERATES_WITH→高通 |
| Operating_system | 鸿蒙操作系统、MIUI | ADOPTS | 华为手机→ADOPTS→鸿蒙操作系统 |
2.4 Cypher查询优化:Few-shot提升准确性
图知识库的检索核心是Cypher语句生成,为避免大模型生成语法错误,系统通过Few-shot示例优化Cypher生成逻辑:
2.4.1 配置Few-shot示例与Prompt
python
from langchain_core.prompts import PromptTemplate
from langchain_community.chains.graph_qa.cypher import GraphCypherQAChain
# 1. Few-shot示例(覆盖常见查询场景)
examples = [
{
"question": "都有哪些公司?",
"query": "MATCH (c:Company) RETURN c.id"
},
{
"question": "小米在技术创新方面有什么突破?",
"query": "MATCH (c:Company)-[r:DEVELOPS|INTRODUCES]->(t) WHERE c.id CONTAINS '小米' RETURN c.id as company, type(r) as relation, t.id as technology"
},
{
"question": "华为的鸿蒙操作系统有什么特点?",
"query": "MATCH (c:Company)-[:DEVELOPS]->(os:Operating_system) WHERE c.id CONTAINS '华为' RETURN os.id"
}
]
# 2. 构建Cypher生成Prompt
cypher_prompt_template = """You are a Neo4j Cypher expert. Generate syntactically correct Cypher queries.
Schema:
{schema}
Important rules:
1. Company names are stored as FULL names (e.g., "小米科技有限责任公司"). ALWAYS use CONTAINS for partial matching
2. Use pattern: WHERE c.id CONTAINS 'keyword' instead of exact match
3. For relationships, use [:DEVELOPS|INTRODUCES] for technology/products
4. NEVER use undefined variables (like type(r) without defining r)
Examples:
{examples}
Question: {question}
Cypher:"""
cypher_prompt = PromptTemplate(
template=cypher_prompt_template,
input_variables=["schema", "question"],
partial_variables={
"examples": "\n".join([f"Q: {ex['question']}\nCypher: {ex['query']}" for ex in examples])
}
)
# 3. 创建Cypher QA Chain
cypher_chain = GraphCypherQAChain.from_llm(
graph=graph,
cypher_llm=llm,
qa_llm=llm,
cypher_prompt=cypher_prompt,
validate_cypher=True, # 开启Cypher语法校验
allow_dangerous_requests=True
)2.4.2 优化效果
通过Few-shot示例,大模型生成Cypher的准确率提升60%以上,避免了"实体名称精确匹配失败""关系类型错误"等常见问题。
3 本地Docker部署:Milvus向量数据库搭建
3.1 部署准备
- 依赖环境:Docker已启动(Docker Compose中包含Milvus及依赖的etcd、minio服务);
- 核心端口:19530(GRPC端口,代码连接核心)、9091(HTTP端口,可选);
- 初始配置:无默认用户名密码,直接通过URI连接。
3.2 启动与验证
- 启动服务:通过Docker Compose启动Milvus(命令参考第一篇);
- 日志验证:执行
docker logs rag-milvus,输出"Milvus is ready"即启动成功; - 代码连接验证:通过LangChain的
Milvus类测试连接,核心代码:
python
from langchain_milvus import Milvus
from langchain_core.embeddings import Embeddings
# 1. 初始化DashScope Embeddings(生成文本向量)
class DashScopeEmbeddings(Embeddings):
def __init__(self, model: str, api_key: str):
self.model = model
self.api_key = api_key
# 实现embed_documents和embed_query方法(参考项目代码)
embeddings = DashScopeEmbeddings(model="text-embedding-v4", api_key=key)
# 2. 连接Milvus并创建集合
vectorstore = Milvus(
embedding=embeddings,
connection_args={"uri": "http://localhost:19530"},
collection_name="company_milvus",
drop_old=True # 测试时删除旧集合,生产环境设为False
)
print("Milvus连接成功!")3.3 向量索引构建:文档分块与向量插入
向量库的核心是"文本分块→向量生成→索引构建",系统通过RecursiveCharacterTextSplitter实现合理分块,提升检索精度:
3.3.1 核心流程代码
python
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 1. 文档分块(关键参数:chunk_size=250,chunk_overlap=30)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=250, # 每个文本块最大长度(字符数)
chunk_overlap=30, # 文本块重叠长度(避免上下文断裂)
length_function=len
)
splits = text_splitter.split_documents(documents) # documents为之前加载的公司文本
print(f"文档分块完成,共生成{len(splits)}个文本块")
# 2. 向量插入与索引构建(自动生成向量并创建IVF_FLAT索引)
vectorstore = Milvus.from_documents(
documents=splits,
collection_name="company_milvus",
embedding=embeddings,
connection_args={"uri": "http://localhost:19530"},
drop_old=True
)
print("Milvus向量索引构建完成!")3.3.2 分块策略优化说明
- chunk_size=250:适配中文文本,确保每个块包含完整的语义单元(如一个公司的某段技术介绍);
- chunk_overlap=30:避免拆分连续语义(如"鸿蒙操作系统的特点"被拆分为两个块);
- 索引类型:默认使用IVF_FLAT索引,适合中小规模数据(10万条以内),查询速度快且配置简单。
3.4 向量检索配置:Retriever与RAG链构建
Milvus向量库通过as_retriever()方法生成检索器,结合RAG链实现"检索→生成"的闭环:
3.4.1 核心代码
python
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
# 1. 构建检索器(设置返回Top2相关文本块)
retriever = vectorstore.as_retriever(search_kwargs={"k": 2})
# 2. 构建RAG生成Prompt(限制响应长度,确保简洁)
prompt = PromptTemplate(
template="""You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise:
Question: {question}
Context: {context}
Answer:
""",
input_variables=["question", "context"],
)
# 3. 构建RAG链(检索→Prompt→生成→解析)
rag_chain = prompt | graph_llm | StrOutputParser()
# 4. 测试检索与生成
user_question = "苹果公司的环保目标是什么?"
docs = retriever.invoke(user_question) # 向量检索
response = rag_chain.invoke({"context": docs, "question": user_question}) # 生成响应
print(f"检索结果:{response}")3.4.2 检索参数优化
- search_kwargs={"k": 2}:返回Top2最相关的文本块,既保证信息充分,又避免冗余;
- 向量维度:使用DashScope的
text-embedding-v4模型,生成768维向量,平衡检索精度与存储成本。
4 混合知识库协同逻辑:何时用图库?何时用向量库?
4.1 核心决策规则
系统通过Supervisor的路由规则,决定不同需求对应的知识库调用策略:
- 关系型需求(如"谁和谁有关系""某公司的技术突破")→ 调用Neo4j图库(graph_kg代理);
- 细节型需求(如"某公司的具体目标""文本中的关键信息")→ 调用Milvus向量库(vec_kg代理);
- 混合需求(如"华为的鸿蒙系统有什么特点,与哪些设备适配")→ 先调用图库(关系适配)+ 再调用向量库(特点细节)。
4.2 协同执行示例
用户需求:"华为的鸿蒙操作系统有什么特点?适配哪些智能设备?"
- Supervisor调度graph_kg代理:生成Cypher查询"鸿蒙系统适配的设备",从Neo4j获取关系数据(如"鸿蒙→适配→华为手机、华为手表");
- Supervisor调度vec_kg代理:检索"鸿蒙系统特点"的相关文本,从Milvus获取细节信息(如"分布式架构、兼容安卓应用");
- Supervisor调度chat代理:整合两个知识库的结果,生成统一自然语言响应。
4.3 双库协同优势
- 精度提升:关系查询走图库,细节查询走向量库,避免单一知识库的"偏科"问题;
- 效率优化:无需遍历全量文本,图库通过关系路径快速定位,向量库通过语义快速匹配;
- 鲁棒性增强:一个知识库查询失败时,可切换另一个知识库兜底(如vec_kg查不到时,尝试graph_kg)。
5 常见问题与优化技巧
5.1 Neo4j图库常见问题
5.1.1 Cypher生成错误
- 原因:大模型对图结构不熟悉,未使用CONTAINS进行模糊匹配;
- 解决:增加Few-shot示例,强制Prompt中明确"使用CONTAINS进行公司名称匹配"。
5.1.2 实体重复或关系错乱
- 原因:文本中同一公司有多个名称(如"华为""华为技术有限公司");
- 解决:在文本预处理阶段统一实体名称,或在Prompt中提示"合并相似公司名称"。
5.2 Milvus向量库常见问题
5.2.1 检索结果不精准
- 原因:文档分块过大/过小,或嵌入模型维度不匹配;
- 解决:调整chunk_size(建议200-300字符),更换更高精度的嵌入模型(如
text-embedding-v4)。
5.2.2 向量插入失败
- 原因:Milvus服务未启动,或连接URI错误(需使用GRPC端口19530);
- 解决:检查Docker容器状态,确保connection_args={"uri": "http://localhost:19530"}。
5.3 性能优化技巧
- 图库优化:为Neo4j的常用实体属性(如Company.id)创建索引,提升查询速度;
- 向量库优化:大数据量(10万条以上)时,将索引类型改为HNSW,配置
index_params={"M": 16, "efConstruction": 200}; - 缓存策略:对高频查询结果建立缓存,避免重复检索,提升响应速度。
6 总结与后续预告
本文详细讲解了混合知识库的搭建全流程:从Neo4j图数据库的Docker部署、自动建模、Cypher优化,到Milvus向量数据库的分块策略、向量插入、RAG链构建,再到双库的协同逻辑,完整覆盖了"关系型知识+语义型知识"的存储与检索需求。
混合知识库是多代理系统的"知识基石",其设计的合理性直接决定了代理执行的精准度与效率。而要让这些知识库与代理高效协作,离不开Supervisor的智能调度------这正是我们下一篇博客的核心内容。
后续博客预告
下一篇我们将聚焦系统的"大脑"------Supervisor,深入解析其任务路由规则、代理状态管理、循环保护机制,揭秘"如何让多个代理有序协作,避免重复工作与无效调用"。