原子操作类LongAdder
- [为什么需要 LongAdder](#为什么需要 LongAdder)
- [LongAdder 核心原理](#LongAdder 核心原理)
-
- [一、 核心数据结构](#一、 核心数据结构)
- [二、 关键性能优化:@sun.misc.Contended 注解解决伪共享](#二、 关键性能优化:@sun.misc.Contended 注解解决伪共享)
- [三、 最小累加单元:Cell 类核心细节](#三、 最小累加单元:Cell 类核心细节)
- [四、 结果聚合:sum() 与 longValue() 方法](#四、 结果聚合:sum() 与 longValue() 方法)
- [五、 核心累加:add(long x) 方法实现逻辑](#五、 核心累加:add(long x) 方法实现逻辑)
LongAdder 是 Java 中的一种原子操作类,它在并发编程中用于高效地进行累加操作,尤其适用于多线程环境下的累加。它是 java.util.concurrent.atomic 包的一部分,与 AtomicLong 相似,但在高并发场景中表现得更加高效。
为什么需要 LongAdder
在 JDK 1.8 之前,Java 中实现线程安全的长整型累加操作,最常用的工具类是 AtomicLong。然而,随着并发量的增加,AtomicLong 在高并发场景下会面临性能瓶颈,因此 JDK 1.8 引入了 LongAdder,用以解决这一问题。
AtomicLong 的原理与高并发瓶颈
AtomicLong 内部维护一个 volatile long 类型的原子变量,确保变量的可见性。每次执行累加(如incrementAndGet())时,它会通过 CAS 尝试更新这个全局变量:线程先读取当前变量值,计算目标值,再通过 CAS 指令比较当前值与预期值,若一致则更新,若不一致(说明有其他线程并发修改),则进入自旋重试(循环执行 CAS 操作直到成功)。
这种基于单一变量的 CAS 自旋设计,在低并发场景下表现得非常高效。因为在此时,线程之间的竞争较少,CAS 操作通常能够在少数几次重试内成功。然而,在高并发场景下,多个线程同时竞争更新同一个全局变量时,CAS 操作会频繁失败,导致大量线程进入自旋重试状态,浪费 CPU 资源。更严重的是,频繁的缓存一致性协议交互可能引发总线风暴,进一步导致性能急剧下降,吞吐量大幅降低。
LongAdder 的设计思路与优势
为了解决 AtomicLong 在高并发累加场景下的性能瓶颈,JDK 1.8 引入了 LongAdder。其核心设计理念是 "分散竞争,聚合结果":通过将单一的全局变量拆分为多个独立的累加单元(Cell),让线程分散到不同的 Cell 上进行操作,从而减少线程间的竞争冲突。最终,LongAdder 会将各个 Cell 和基础值(base)的累加结果进行聚合,得到最终的累加值。
通过对比 AtomicLong 和 LongAdder 的竞争模型,可以更直观地理解它们的设计差异:
AtomicLong 的竞争模型:
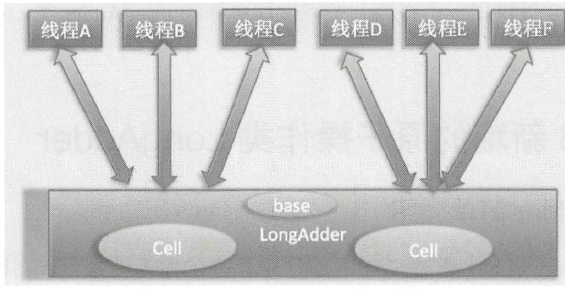
在AtomicLong的设计中,所有线程(线程 A~F)会竞争同一个全局原子变量。高并发下,大量线程同时对该变量执行 CAS 操作,冲突概率极高,导致多数线程陷入自旋重试,浪费大量 CPU 资源,并且由于频繁的缓存一致性协议交互,可能会发生总线风暴,从而大幅降低系统吞吐量。
LongAdder 的竞争模型:
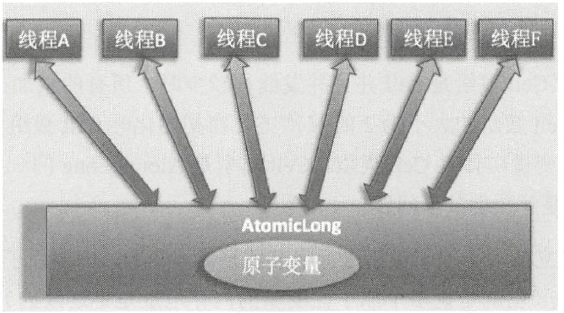
相比之下,LongAdder 内部包含多个 Cell 累加单元和一个基础值(base)。每个 Cell 维护一个独立的 volatile long 值,类似于一个小型的 AtomicLong。线程会分配到不同的 Cell 上进行 CAS 操作,避免了对同一个 Cell 的竞争。即便某个 Cell 上的 CAS 操作失败,线程也能尝试切换到其他 Cell 继续操作,从而避免了无效的自旋重试。
LongAdder 核心原理
一、 核心数据结构
LongAdder 继承自 java.util.concurrent.atomic.Striped64 类,后者是专为分段累加与分散热点设计的并发基础类。LongAdder 通过复用父类 Striped64 中的核心变量,优化了高并发累加操作。具体来说,LongAdder 内部有三个关键的数据结构:
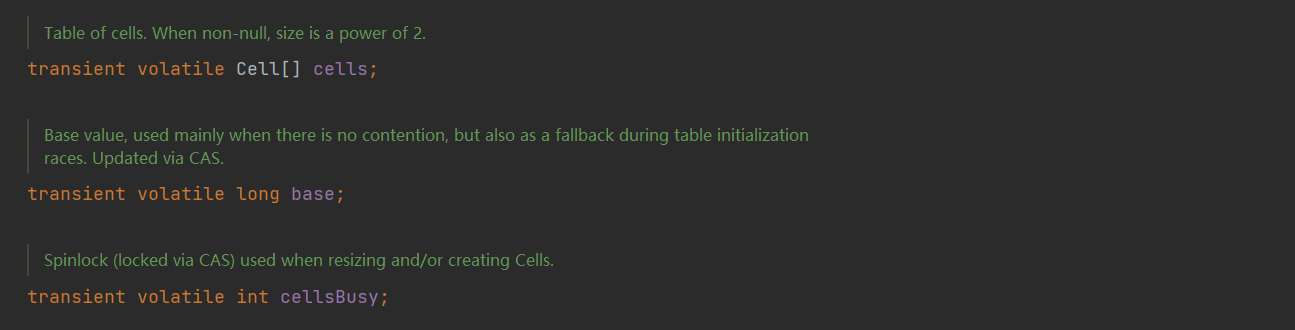
1、基值变量:base
- 类型:transient volatile long 类型,默认初始值为 0。
其中 volatile 关键字保证多线程间的内存可见性与禁止指令重排序,transient 确保该变量在序列化时被排除(base 是运行时累加变量,无需持久化存储)。 - 作用: 作为低并发场景下的累加体。
- 设计背景:由于 cells\[\] 数组中的每个 Cell 实例包含额外的内存空间,导致其内存开销较大。为了优化内存占用并提高低并发性能,LongAdder 在初始化时不会立即创建 cells\[\] 数组(默认为 null),而是使用 base 变量进行累加,避免不必要的内存开销。
- 当满足以下任一条件时,所有累加操作均直接作用于 base 变量,此时 LongAdder 的原子性保障逻辑与 AtomicLong 完全一致:
cells\[\] 数组未初始化(即 null);
并发线程数量较少,CAS 更新 base 可快速成功;
线程无法操作 cells\[\] 数组(如获取 cellsBusy 自旋锁失败或扩容未完成)。
2、原子性累加数组 Cell\[\] cells
- 类型:transient volatile Cell\[\] cells 类型,默认初始值为 null,采用惰性加载。
其中 volatile 确保 cells\[\] 数组引用本身的内存可见性与禁止指令重排序,transient 排除序列化; - 作用: 用于高并发场景下的累加操作。数组元素 Cell 是 LongAdder 的最小累加单元,负责原子累加操作。
- 初始化触发条件:当线程尝试 CAS 更新 base 失败(表明当前存在明显并发竞争),且 cells\[\] 仍为 null 时,线程会尝试获取 cellsBusy 锁,获取成功后初始化 cells\[\] 数组,首次初始化的数组长度固定为 2(满足 2 的幂次特性)。
- 核心作用:高并发场景下,将单点竞争(base 变量)分散到多个独立的 Cell 累加单元,降低了共享资源的竞争烈度,从而解决了 AtomicLong 在高并发下的 CAS 风暴问题,从而提升累加吞吐量。
3、轻量级自旋锁 cellsBusy:
- 类型: transient volatile int cellsBusy,基于 CAS 操作实现的无锁轻量级自旋锁。
- 作用: 用于保护 cells\[\] 数组的结构性修改,确保线程安全。它避免了重量级锁的上下文切换开销,提供更高效的并发控制。
- 核心功能(由 Striped64 的 longAccumulate() 方法实现):
初始化 cells 数组:当 cells\[\] 为 null 且线程对 base 的 CAS 更新失败时,线程会尝试获取 cellsBusy 锁并初始化 cells\[\] 数组;
创建单个 Cell 实例并填充至 cells\[\]: 当 cells\[\] 中某个 Cell 为 null 时,线程尝试获取 cellsBusy 锁并创建该 Cell 实例;
扩容 cells\[\] 数组: 当某个 Cell 的 CAS 更新失败(表明该 Cell 存在竞争),且 cells\[\] 数组长度未达到与 CPU 核心数相关的上限时,线程会获取 cellsBusy 锁并将 cells\[\] 数组扩容至原长度的两倍,保证系统能够处理更高的并发。
二、 关键性能优化:@sun.misc.Contended 注解解决伪共享
LongAdder 对 Cell 类使用 @sun.misc.Contended 注解进行字节填充,这是提升并发性能的关键优化,其原理和必要性如下:
伪共享问题
CPU 与主存之间有多级高速缓存(L1、L2、L3,其中 L1 和 L2 为线程或核心私有,L3 为多核共享)。缓存的最小单位是缓存行(通常为 64 字节)。CPU 在读取数据时,会将目标变量以及周围连续内存地址的数据一同加载到同一个缓存行中,利用数据局部性提高后续数据访问效率,但这也可能引发伪共享问题。
对于 Cell\[\] 数组而言,内部的 Cell 实例内存地址通常是连续的。多个相邻的 Cell 实例可能会被加载到同一个缓存行中。此时,如果一个线程修改某个 Cell 的值,缓存一致性协议会导致整个缓存行失效,其他线程访问同一缓存行中的其他 Cell 时,必须重新从主存加载数据,这会大幅降低缓存命中率,严重影响并发性能。
@sun.misc.Contended 注解的作用
@sun.misc.Contended 是 JDK 提供的专门用于解决伪共享问题的注解,它通过在类或字段前后填充额外的字节(默认填充至 64 字节,即一个缓存行的大小),使得每个 Cell 实例都独占一个缓存行,避免多个 Cell 共享同一缓存行。这样,在多个线程操作不同的 Cell 时,仅会失效对应 Cell 的缓存行,而不会影响其他 Cell 的缓存有效性,显著提高缓存命中率,从而提升高并发下的性能。
补充说明:自 JDK 9 起,@sun.misc.Contended 被迁移至 jdk.internal.vm.annotation 包,且默认仅对 JDK 内部类生效。如果自定义类使用该注解,需要启用 JVM 参数 -XX:-RestrictContended。
三、 最小累加单元:Cell 类核心细节
Cell 是 LongAdder 的最小累加单元,实质上是一个迷你版的 AtomicLong,其核心结构和特性如下:

volatile long value:存储累加值,volatile 保证可见性与禁止指令重排序;
cas(long cmp, long val) 方法:使用 CAS 确保单个 Cell 实例的 value 累加操作是原子性的,是 Cell 单元自身线程安全的核心保障;
@sun.misc.Contended 注解:解决伪共享问题,提升缓存命中率。
四、 结果聚合:sum() 与 longValue() 方法
sum() 是 LongAdder 用于获取累加结果的核心方法,其核心逻辑和特性如下:
核心实现:遍历 cells 数组中的所有 Cell 实例,累加每个 Cell 的 value 值,最后再累加 base 的值,返回聚合后的总和(源码如下):

关键特性是弱一致性,sum() 返回的结果是近似值,而非调用时刻的原子快照,存在一定误差,原因如下:
遍历 cells 数组和累加 base 的过程中,没有对 cells 数组或 Cell 实例加锁,其他线程可能正在修改某个 Cell 的 value,或对 cells 数组进行扩容,导致当前线程无法读取到最新的实时值;累加 Cell 值和 base 值是分步执行的,并非原子操作,两者之间可能存在其他线程的累加操作,导致结果不完整;
适用场景:适用于统计汇总场景(如接口调用次数、数据流量统计),这类场景允许少量结果延迟或近似值;若需获取精确原子快照,需在调用 sum() 前通过额外同步机制(如锁)保证所有累加线程已结束。
longValue() 方法的返回值与 sum() 完全一致,其底层实现直接调用 sum() 方法,仅为了满足 Number 类的接口规范,源码如下:

除此之外,doubleValue()、floatValue() 等方法也均基于 sum() 方法实现,仅做了类型转换。
补充:sumThenReset() 方法
为满足批量统计后重置计数器的场景,LongAdder 提供了 sumThenReset() 方法,该方法是 sum() 和 reset() 的组合操作:先返回聚合后的累加结果,再将 base 和所有 Cell 的 value 重置为 0。该方法比单独调用 sum() 再调用 reset() 更高效,因为它仅需遍历一次 cells 数组,即可完成聚合结果和重置两个操作。
五、 核心累加:add(long x) 方法实现逻辑
LongAdder 为了方便用户实现自增 1 和自减 1 这两个高频操作,提供了 increment() 和 decrement() 两个便捷方法,这两个方法的底层实现完全依赖于 add(long x)。

add(long x) 的核心功能是将指定的数值 x 原子性地累加到 LongAdder 中,是 LongAdder 实现计数或累加的核心方法。源码如下:
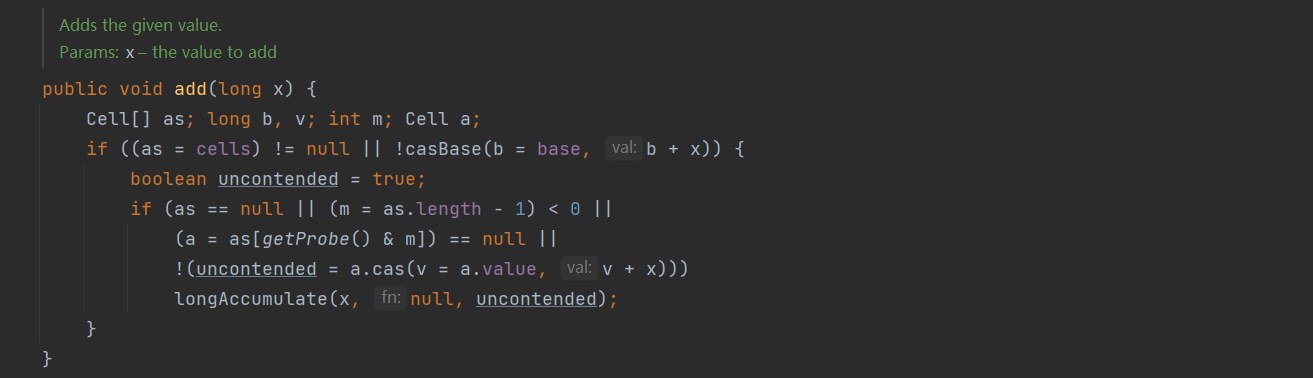
核心流程如下:
前置判断:获取当前 cells 数组赋值给 as,同时尝试通过 casBase() 方法 CAS 更新 base(累加 x)。
- 分支 1:低并发路径
如果 cells\[\] 为 null 且 casBase() 成功更新 base,则直接返回,不进行后续处理。此路径适用于低并发,快速完成操作。 - 分支 2:高并发路径
若 cells\[\] 已初始化,或 casBase() 更新 base 失败,则进入复杂逻辑处理,具体步骤如下:
第一步:检查 cells\[\] 是否有效:确保 cells\[\] 不为 null,且其长度有效(m = as.length - 1 >= 0);
第二步:计算 Cell 下标:使用 getProbe() 获取当前线程的哈希值,计算对应 Cell 的下标(getProbe() & m);
第三步:尝试更新 Cell:如果对应 Cell 存在,尝试通过 cas() 更新该 Cell 的 value(累加 x);
第四步:如果 CAS 更新失败或 Cell 为 null,调用 longAccumulate(x, null, uncontended) 处理复杂情况(如初始化、扩容或重新哈希等),然后退出。
确保在低并发环境下高效执行,在高并发时逐步升级竞争策略。
补充:reset() 方法
reset() 方法用于将 LongAdder 恢复至初始状态(所有累加值归 0),方便后续复用。
其核心逻辑:将基值变量 base 重置为 0;遍历 cells 数组,将所有非 null Cell 实例的 value 值重置为 0。
注意事项:reset() 方法并不保证原子性,在并发环境中,如果其他线程同时进行累加操作,可能导致不一致的重置结果。因此,应确保在无并发累加的情况下使用该方法。