「MPC+RL」
目录
[01 主要方法](#01 主要方法)
[1. 整体架构:RL决策 + MPC执行](#1. 整体架构:RL决策 + MPC执行)
[2. Actor设计:学习代价而非动作](#2. Actor设计:学习代价而非动作)
[3. Critic设计与模型预测价值扩展](#3. Critic设计与模型预测价值扩展)
[02 实验结果](#02 实验结果)
[3.可解释性:打开 RL 的黑盒](#3.可解释性:打开 RL 的黑盒)
[4.真实世界部署:零样本迁移的 21m/s](#4.真实世界部署:零样本迁移的 21m/s)
[03 总结](#03 总结)
在机器人控制领域,长期存在着模型驱动(MPC)与数据驱动(RL)的路线之争。前者理论完备但依赖人工调参,后者探索力强却受困于黑盒不可解释性。苏黎世大学 RPG 组的这项 T-RO 最新工作,为这一争论提供了一个优雅的融合解。
论文提出的 AC-MPC 架构,创造性地将可微 MPC嵌入到 Actor-Critic 框架的策略网络末端。这不仅让无人机跑出了 21m/s 的超人级速度,更重要的是解决了两大痛点:
-
鲁棒性突破:利用 MPC 内置的动力学先验,算法在面对风扰和模型参数失配等 OOD场景时,展现出了纯神经网络无法比拟的稳定性。
-
理论可解释性:论文通过实证分析揭示了一个惊人的数学联系,Critic 网络学到的 Value Function 的 Hessian 矩阵,与 MPC 学到的 Cost 矩阵高度相关。这意味着 RL 真正学会了控制成本的二阶曲率,打通了价值函数与优化目标之间的壁垒。
这篇文章不仅是工程上的胜利,更是对学习型控制(Learning-based Control)内部机理的一次精彩剖析。

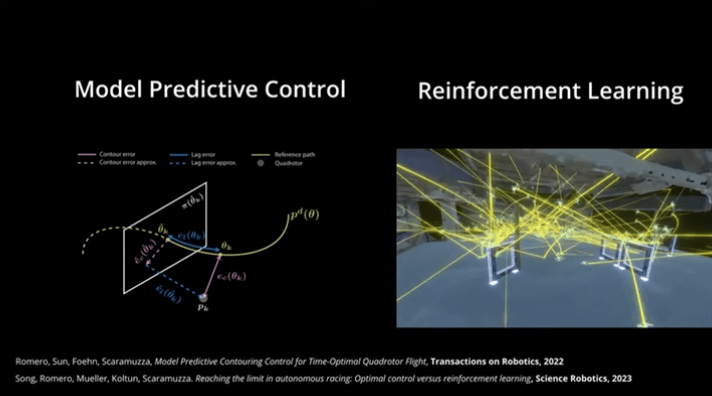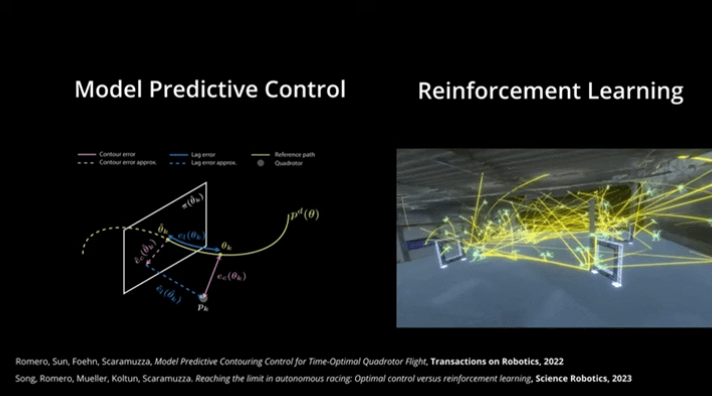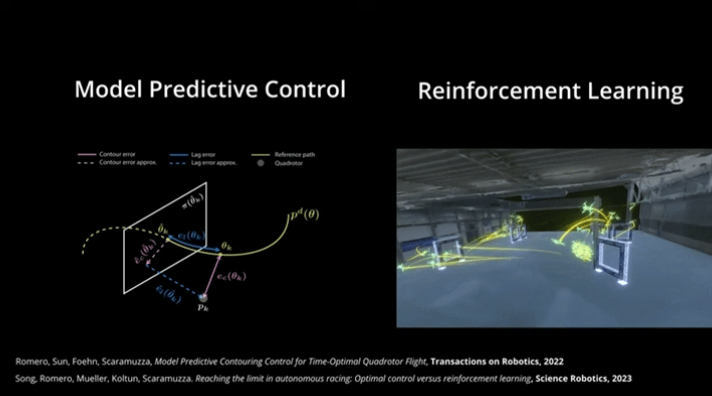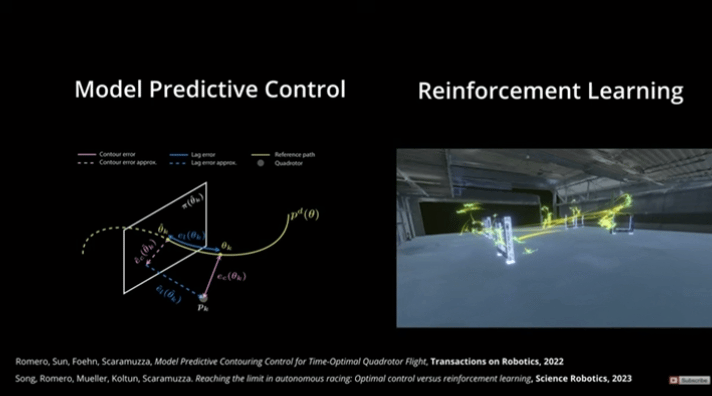
图1| MPC与RL对比图
01 主要方法
论文提出了一种将模型预测控制(MPC)作为可微层嵌入到强化学习(RL)Actor-Critic框架中的新方法。其核心思想并非用神经网络直接输出控制量,而是让神经网络学习当前状态下最优的控制目标是什么,然后交由内置动力学模型的MPC求解器去计算具体的控制指令。
1. 整体架构:RL决策 + MPC执行
传统RL直接从观测映射到动作,缺乏物理约束;传统MPC依赖人工设计的Cost Function,难以适应复杂任务。AC-MPC结合两者:Critic网络负责长期的价值评估,Actor网络被拆解为神经代价图(Neural Cost Map)和"可微MPC(Differentiable MPC)两部分。
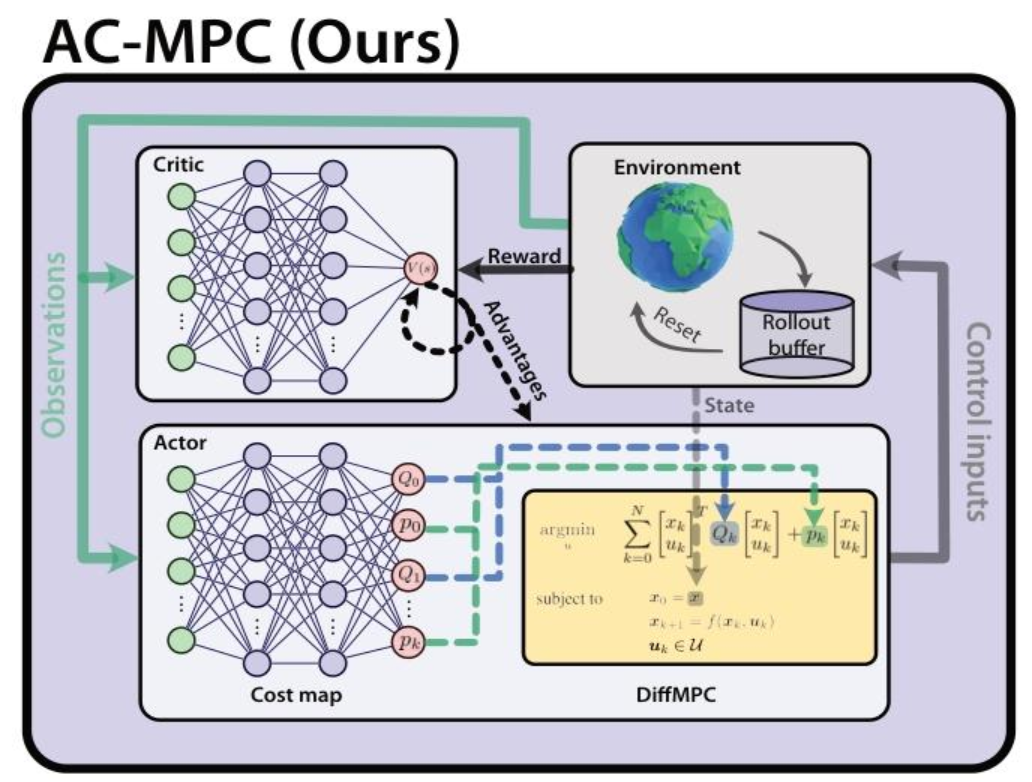
图2| AC-MPC 架构图解。与传统RL不同,AC-MPC的Actor网络并不直接输出动作。它首先通过一个神经网络预测出当前最优的二次型代价函数参数,然后将这些参数连同当前状态输入到一个可微MPC层中。该层利用四旋翼动力学模型求解优化问题,最终输出满足物理约束的控制指令。
2. Actor设计:学习代价而非动作
AC-MPC 的 Actor 不直接学习控制策略,而是学习一个从观测到 MPC 代价函数的映射。具体流程为 Actor 接收当前观测(如状态、赛道门位置),输出定义 MPC 优化目标的二次型参数 和
。这相当于让 Actor 在每一时刻动态调整 MPC 的优化目标。
在获得 Actor 输出的二次型参数后,AC-MPC 通过求解以下最优控制问题来生成动作。由于 AC-MPC 可微,该 Actor 的输出支持梯度反向传播。优化目标公式如下:
其中,是 Actor 的观测输入,
和
是神经网络的输出,
分别是系统状态和控制动作,满足动力学约束
。
最终的控制动作为 MPC 的最优解,为了实现充分探索,AC-MPC 在训练阶段会叠加高斯噪声,在部署阶段则直接执行 MPC 解。
3. Critic设计与模型预测价值扩展
为了进一步提高采样效率,论文引入了模型预测价值扩展(MPVE)技术。由于MPC求解器会预测未来 H 步的状态序列,这些预测信息被用来辅助Critic的学习,减少对真实环境采样的依赖,并缓解价值估计的方差。MPVE的价值估计公式如下:
其中, 和
来自 MPC 内部模型的预测,而非环境交互。这种设计使得 Critic 能更准确地评估当前策略的长期价值,同时利用 MPC 的预测能力加速训练收敛。
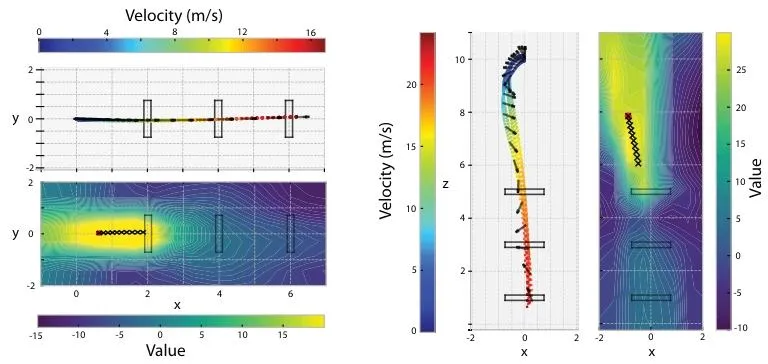
图3| 价值函数与飞行轨迹可视化。图中颜色代表Critic网络评估的价值(黄色为高价值区)。可以看到,AC-MPC学到的价值函数就像一个势能场,引导无人机穿越赛道门。当无人机穿过一个门后,高价值区域会迅速切换指向下一个门,体现了Critic通过学习Cost Function实现了类似离散模式切换的高级决策能力。
02 实验结果
论文在仿真环境和真实世界中进行了广泛的验证,不仅证明了 AC-MPC 能达到与 SOTA 强化学习同等的超人级速度,更在鲁棒性和数据效率上展现了压倒性优势。
1.训练效率与极限性能:学得更快,飞得更猛
在无人机竞速任务中,AC-MPC 展现了极高的采样效率。特别是在高难度的 SplitS(垂直S弯) 和 Vertical(垂直飞行) 赛道中,AC-MPC 能够利用 MPC 内部的动力学先验,比纯神经网络(AC-MLP)更快地收敛到高分奖励区域。此外,在控制指令层面,AC-MPC 能够更一致地触及无人机的物理极限(如推力饱和),通过极致地压榨性能来实现时间最优飞行。
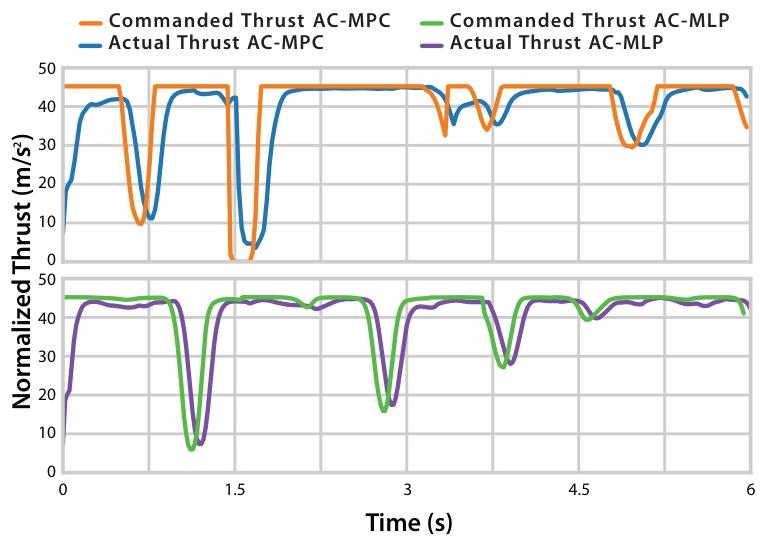
图4| 推力指令饱和度对比。AC-MPC(橙线)能够持续且稳定地将推力打到最大值(饱和),充分利用无人机的物理性能;而 AC-MLP(绿线)的推力输出则显得犹豫和波动,难以维持极限飞行。
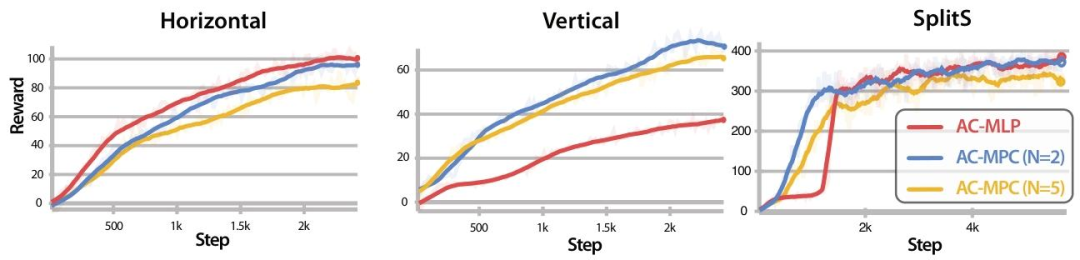
图5| 不同赛道下的训练曲线对比。在简单的水平赛道(左)上两者表现相当;但在高难度的垂直赛道(中)和 SplitS 赛道(右)中,AC-MPC(蓝/黄线)凭借动力学先验,展现出了比 AC-MLP(红线)更高的采样效率和最终性能上限。
2.鲁棒性:无惧风扰与参数偏差
由于MPC具有较强的抗扰动能力,即使面对在训练中未见过的强风干扰,或者无人机自身的质量、惯量发生巨大变化时,AC-MPC 依然能保持极高的成功率,而无需重新训练。
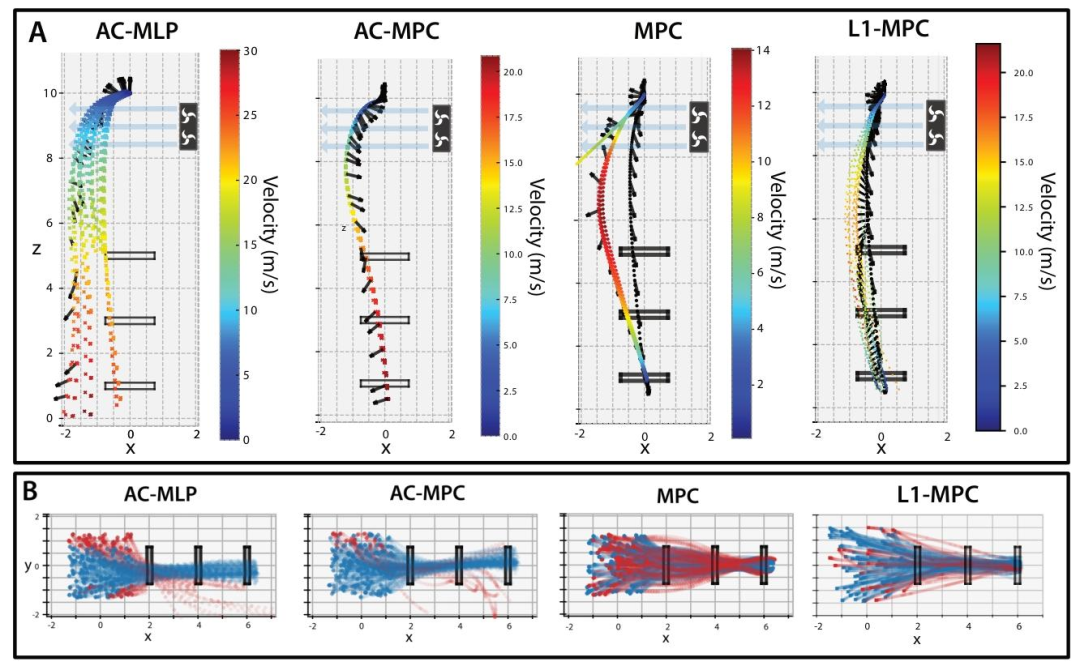
图6| 抗干扰能力可视化。(A) 在垂直飞行中施加 1.5 倍重力的侧向风扰。纯 RL 方法(AC-MLP)和传统 MPC 均告坠毁,只有自适应 L1-MPC 和本文的 AC-MPC 成功穿越,且 AC-MPC 速度更快。(B) 面对初始位置的随机变化,AC-MPC(中)的轨迹一致性显著优于 AC-MLP(左)。
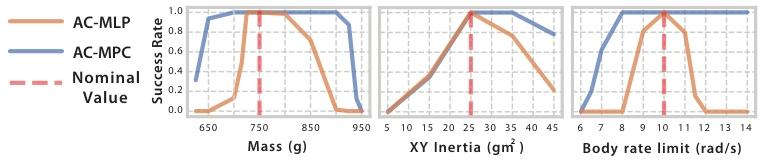
图7| 动力学参数泛化测试。在未重新训练的情况下,测试不同质量(Mass)和转动惯量(Inertia)下的飞行成功率。红线为训练时的标称值。可以看到,AC-MPC(橙线)在参数大幅偏离标称值时仍能保持近 100% 的成功率,而 AC-MLP(蓝线)则迅速崩溃。
3.可解释性:打开 RL 的黑盒
除性能验证外,论文还深入探究了Critic 网络到底学到了什么。通过线性探测实验,作者发现 Critic 网络学到的价值函数的 Hessian 矩阵,与 Actor 网络学到的 MPC 代价矩阵高度相关。这证明了 RL 确实学到了符合物理直觉的控制代价。
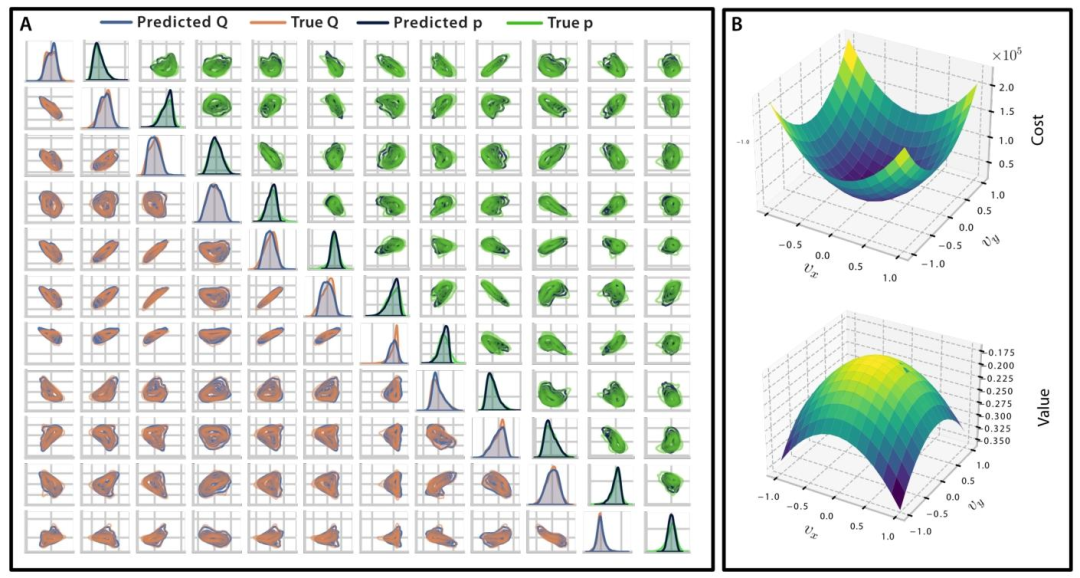
图8| 价值函数与 MPC 代价矩阵的关联性分析。(A) 预测的 Q 矩阵与真实的 Q 矩阵高度吻合,说明 Critic 深刻理解了控制任务的代价结构。(B) 3D 视图下,MPC 的代价函数曲面(上)与 Critic 的价值函数曲面(下)形状惊人一致,验证了两者在数学本质上的统一性。
4.真实世界部署:零样本迁移的 21m/s
最终,基于 AC-MPC 训练好的策略在无任何处理的情况下,通过零样本迁移直接部署在真实的竞速无人机上。在复杂的 SplitS 赛道中,AC-MPC 达到了 21m/s 的峰值速度,不仅追平了 SOTA 的纯 RL 方法,更证明了该架构在现实物理世界中的可行性与安全性。
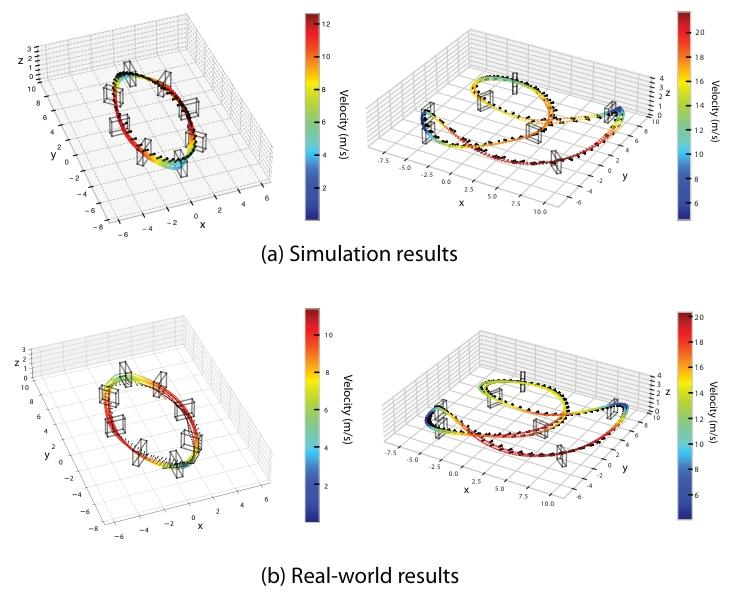
图9| 真实世界飞行轨迹。AC-MPC 在圆形赛道(左)和 SplitS 赛道(右)的真实飞行数据(实线)与仿真数据(虚线)高度重合。AC-MPC在真实环境中跑出了 21m/s 的峰值速度,实现了从仿真到现实的完美复刻。
03 总结
UZH RPG组的 AC-MPC 工作提出了一种将可微MPC无缝嵌入到Actor-Critic 强化学习框架的全新范式。该方法打破了传统学习动作的桎梏,转而让策略网络学习 MPC 的内部代价函数,从而在保留 RL 强大探索与端到端优化能力的同时,充分利用了物理模型处理约束和动态规划的优势。
实验证明,AC-MPC 不仅在真实世界无人机竞速中实现了与 SOTA 纯 RL 方法持平的 21m/s 超人级速度,更在抗风扰和参数泛化等非分布场景下展现出压倒性的鲁棒性,为机器人从仿真到现实的零样本迁移提供了一条可解释且高效的新路径。
论文题目:Actor-Critic Model Predictive Control: Differentiable Optimizationmeets Reinforcement Learning for Agile Flight
论文作者:Angel Romero, Elie Aljalbout, Yunlong Song, Davide Scaramuzza
论文地址:https://ieeexplore.ieee.org/document/11301631
代码地址:https://github.com/uzh-rpg/acmpc public