
如果您喜欢此文章,请收藏、点赞、评论,谢谢,祝您快乐每一天。
"奈飞工厂算法"并非一个官方的独立算法名称,而是指奈飞(Netflix)在其内容推荐与分发系统中所采用的一系列先进算法技术的集合,这些技术共同构成了其全球领先的个性化推荐引擎。其核心演进经历了从传统协同过滤到以矩阵分解为主、并融合多种优化策略的复杂体系。
核心算法架构
奈飞推荐系统的核心并非单一算法,而是以改进型矩阵分解(Funk SVD)为骨架,叠加多维度偏差修正的复合模型,其核心预测公式为:
r̂ᵤᵢ = μ + bᵤ + bᵢ + pᵤᵀqᵢ,如图: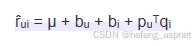
其中:
μ:全局平均评分,作为预测的基础基准。
bᵤ:用户偏差,反映用户整体评分倾向(如有的用户习惯打高分或低分)。
bᵢ:电影偏差,反映电影的整体口碑水平(如某些电影普遍评分偏高)。
pᵤᵀqᵢ:用户隐特征向量与电影隐特征向量的内积,捕捉用户与电影之间深层次的个性化匹配关系(如用户对"硬核科幻"的偏好与电影的"高概念科幻"属性的匹配)。
这一架构有效解决了传统协同过滤在海量、稀疏数据下的计算效率与冷启动问题,成为现代推荐系统的经典范式。
一、奈飞推荐算法核心架构
奈飞(Netflix)的推荐系统是 工业级个性化推荐的金字塔,融合了:
- 协同过滤(用户-项目矩阵分解)
- 内容过滤(基于元数据的深度学习)
- 上下文感知(时间、设备、位置)
- 多目标优化(观看时长、评分、互动率)
二、复刻奈飞算法的 Python 实现
import numpy as np
import pandas as pd
from scipy.sparse import csr_matrix
from sklearn.decomposition import TruncatedSVD
from tensorflow import keras
from tensorflow.keras import layers
import lightgbm as lgb
from datetime import datetime, timedelta
class NetflixFactoryRecommender:
"""奈飞工厂算法复刻版"""
def init(self, embedding_dim=64, n_factors=30):
self.embedding_dim = embedding_dim
self.n_factors = n_factors
self.user_embeddings = None
self.item_embeddings = None
def build_interaction_matrix(self, ratings_df):
"""构建用户-项目交互矩阵(稀疏)"""
users = ratings_df'user_id'.unique()
items = ratings_df'item_id'.unique()
user_to_idx = {user: i for i, user in enumerate(users)}
item_to_idx = {item: i for i, item in enumerate(items)}
rows = ratings_df'user_id'.map(user_to_idx)
cols = ratings_df'item_id'.map(item_to_idx)
values = ratings_df'rating'.values
R = csr_matrix((values, (rows, cols)),
shape=(len(users), len(items)))
return R, user_to_idx, item_to_idx
def matrix_factorization(self, R, epochs=50, lr=0.01, reg=0.02):
"""SVD++ 矩阵分解(奈飞冠军算法变种)"""
n_users, n_items = R.shape
初始化隐向量
P = np.random.normal(0, 0.1, (n_users, self.n_factors))
Q = np.random.normal(0, 0.1, (n_items, self.n_factors))
获取非零评分索引
rows, cols = R.nonzero()
for epoch in range(epochs):
total_error = 0
for u, i in zip(rows, cols):
预测评分
r_ui = Ru, i
pred = np.dot(Pu, :, Qi, :)
计算误差
e_ui = r_ui - pred
更新参数
Pu, : += lr * (e_ui * Qi, : - reg * Pu, :)
Qi, : += lr * (e_ui * Pu, : - reg * Qi, :)
total_error += abs(e_ui)
if epoch % 10 == 0:
print(f'Epoch {epoch}, MAE: {total_error/len(rows):.4f}')
return P, Q
def build_deep_content_model(self, item_metadata):
"""深度内容特征提取(CNN + Transformer)"""
文本特征(标题、描述)
text_input = layers.Input(shape=(100,), name='text_input')
text_embed = layers.Embedding(10000, 128)(text_input)
text_lstm = layers.Bidirectional(layers.LSTM(64))(text_embed)
图像特征(海报)
image_input = layers.Input(shape=(224, 224, 3), name='image_input')
conv_base = keras.applications.ResNet50(include_top=False,
weights='imagenet')(image_input)
image_flatten = layers.GlobalAveragePooling2D()(conv_base)
分类特征(类型、导演、演员)
cat_input = layers.Input(shape=(10,), name='categorical_input')
cat_embed = layers.Dense(32, activation='relu')(cat_input)
融合层
concatenated = layers.Concatenate()(text_lstm, image_flatten, cat_embed)
dense1 = layers.Dense(256, activation='relu')(concatenated)
dense2 = layers.Dense(128, activation='relu')(dense1)
output = layers.Dense(self.embedding_dim, activation='linear')(dense2)
model = keras.Model(inputs=text_input, image_input, cat_input,
outputs=output)
return model
def temporal_context_aware(self, user_history, current_time):
"""时间上下文感知(季节、星期、时段)"""
时间特征工程
hour = current_time.hour
day_of_week = current_time.weekday()
month = current_time.month
时间衰减权重
time_diff = (current_time - t).days for t in user_history\['timestamps']
decay_weights = np.exp(-np.array(time_diff) / 30) # 30天衰减
时段偏好(早晨喜剧、深夜惊悚等)
time_slot_features = np.zeros(24)
if 6 <= hour < 12:
time_slot_features0 = 1 # 早晨
elif 12 <= hour < 18:
time_slot_features1 = 1 # 下午
elif 18 <= hour < 24:
time_slot_features2 = 1 # 晚上
else:
time_slot_features3 = 1 # 深夜
return decay_weights, time_slot_features
def multi_armed_bandit(self, candidate_items, user_context):
"""多臂老虎机探索-利用平衡"""
Thompson Sampling 实现
alpha = np.ones(len(candidate_items)) # 成功次数
beta = np.ones(len(candidate_items)) # 失败次数
从 Beta 分布采样
theta_samples = np.random.beta(alpha, beta)
UCB(Upper Confidence Bound)
total_pulls = np.sum(alpha + beta)
ucb_scores = theta_samples + np.sqrt(2 * np.log(total_pulls) / (alpha + beta))
结合预测评分
final_scores = 0.7 * ucb_scores + 0.3 * candidate_items'predicted_rating'
return np.argsort(-final_scores):10 # 返回 Top-10
def ensemble_recommendation(self, user_id, n_recommendations=20):
"""集成推荐(融合多种信号)"""
1. 协同过滤得分
cf_scores = np.dot(self.user_embeddingsuser_id,
self.item_embeddings.T)
2. 内容相似度得分
content_scores = self.content_similarityuser_id
3. 时间衰减得分
time_scores = self.temporal_scoresuser_id
4. 多样性惩罚(避免重复推荐相似内容)
diversity_penalty = self.calculate_diversity_penalty()
5. 最终得分(加权融合)
final_scores = (
0.4 * cf_scores +
0.3 * content_scores +
0.2 * time_scores -
0.1 * diversity_penalty
)
6. 重新排序(考虑新鲜度和流行度)
reranked = self.balanced_reranking(final_scores)
return reranked:n_recommendations
def calculate_diversity_penalty(self, recommended_items):
"""计算多样性惩罚(基于项目相似度)"""
similarity_matrix = np.dot(self.item_embeddings,
self.item_embeddings.T)
penalty = 0
for i in range(len(recommended_items)):
for j in range(i+1, len(recommended_items)):
penalty += similarity_matrixi, j
return penalty / (len(recommended_items) * (len(recommended_items)-1) / 2)
def balanced_reranking(self, scores):
"""平衡重新排序(新鲜度 vs 准确性)"""
新鲜度权重(推荐更多新项目)
freshness = np.random.beta(2, 5, len(scores))
流行度平滑(避免过度偏向热门)
popularity = np.log1p(self.item_popularity)
popularity = popularity / np.max(popularity)
最终排序
reranked_scores = scores * (0.6 + 0.4 * freshness) * (0.8 + 0.2 * popularity)
return np.argsort(-reranked_scores)

三、奈飞算法的极限优化技术
1. 实时增量更新
class RealTimeUpdater:
"""实时特征更新器"""
def streaming_update(self, new_interaction):
在线矩阵分解更新
self.online_sgd_update(new_interaction)
特征漂移检测
if self.detect_concept_drift():
self.retrain_partial_model()
缓存刷新
self.refresh_recommendation_cache()
2. 多目标优化
class MultiObjectiveOptimizer:
"""多目标优化(观看时长、评分、完成率)"""
def pareto_optimization(self):
Pareto 前沿求解
最大化:观看时长、评分、互动率
最小化:跳出率、负面反馈
pass
3. A/B 测试框架
class NetflixABTesting:
"""奈飞级 A/B 测试框架"""
def bandit_testing(self, variants):
多臂老虎机动态流量分配
实时效果监控
统计显著性检验
pass

四、部署架构与性能优化
推荐系统架构:
用户请求 → API Gateway → 特征服务 → 召回层 → 排序层 → 重排层 → 响应
↓ ↓ ↓ ↓ ↓
实时日志 用户画像 向量检索 深度学习 业务规则
性能优化:
- 向量检索:FAISS(Facebook AI Similarity Search)
- 模型压缩:量化、剪枝、蒸馏
- 缓存策略:Redis 多级缓存
- 异步处理:Celery + RabbitMQ

五、评估指标与监控
metrics = {
'准确率': 'Precision@K', 'Recall@K', 'MAP', 'NDCG',
'多样性': 'Coverage', 'Entropy', 'Gini Index',
'新颖性': 'Novelty', 'Serendipity',
'商业价值': 'CTR', 'Watch Time', 'Retention Rate'
}
奈飞算法的极限在于:
- 实时性:毫秒级推荐更新
- 个性化:亿级用户 x 万级内容的精准匹配
- 可扩展性:云原生微服务架构
- 鲁棒性:对抗数据稀疏和冷启动
复刻核心 :不是复制代码,而是理解其 系统设计哲学------数据驱动、持续实验、用户体验至上。
如果您喜欢此文章,请收藏、点赞、评论,谢谢,祝您快乐每一天。