文章目录
- [一、安装中文分词器 IK](#一、安装中文分词器 IK)
-
- [1) 安装](#1) 安装)
- [2) 验证](#2) 验证)
- 二、深入复合查询与高亮显示
- 三、思考
- 四、下期预告
继续了解ES.按照学习路线图,这篇博客介绍如下2点:
【本期】1、 安装中文分词器 IK 2、深入复合查询与高亮显示
一、安装中文分词器 IK
1) 安装
java
# 1. 停止当前 ES + Kibana 容器(确保数据卷未被占用)
docker compose down
# 2. 启动临时 Alpine 容器,挂载 es-plugins 数据卷,安装 IK 7.17.9(完整插件)
docker run --rm -v es-docker_es-plugins:/usr/share/elasticsearch/plugins \
alpine sh -c "mkdir -p /usr/share/elasticsearch/plugins/ik && \
cd /usr/share/elasticsearch/plugins/ik && \
wget https://release.infinilabs.com/analysis-ik/stable/elasticsearch-analysis-ik-7.17.9.zip && \
unzip elasticsearch-analysis-ik-7.17.9.zip && \
rm -rf elasticsearch-analysis-ik-7.17.9.zip"
# 3. 重新启动 ES + Kibana 容器
docker compose up -d
# 4. 验证 ES 是否正常启动(访问 http://localhost:9200,返回正常 JSON 即成功)介绍下核心参数:
--rm 表示创建完后就删除;
sh -c 表示shell脚本方式执行后面字符串中的命令。-c表示commands
alpine是 极简版linux镜像名,也就8M左右,自带:wget命令
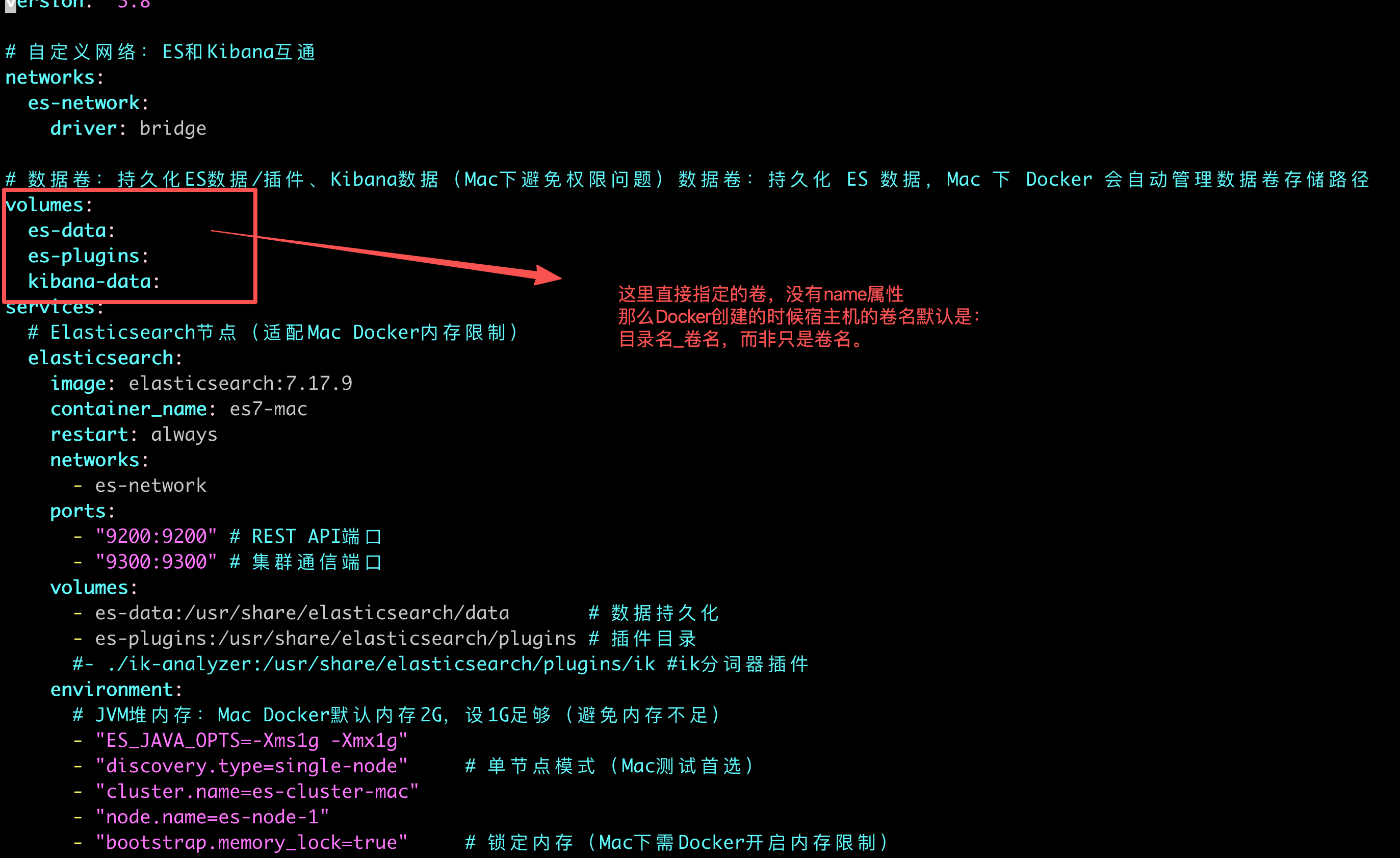
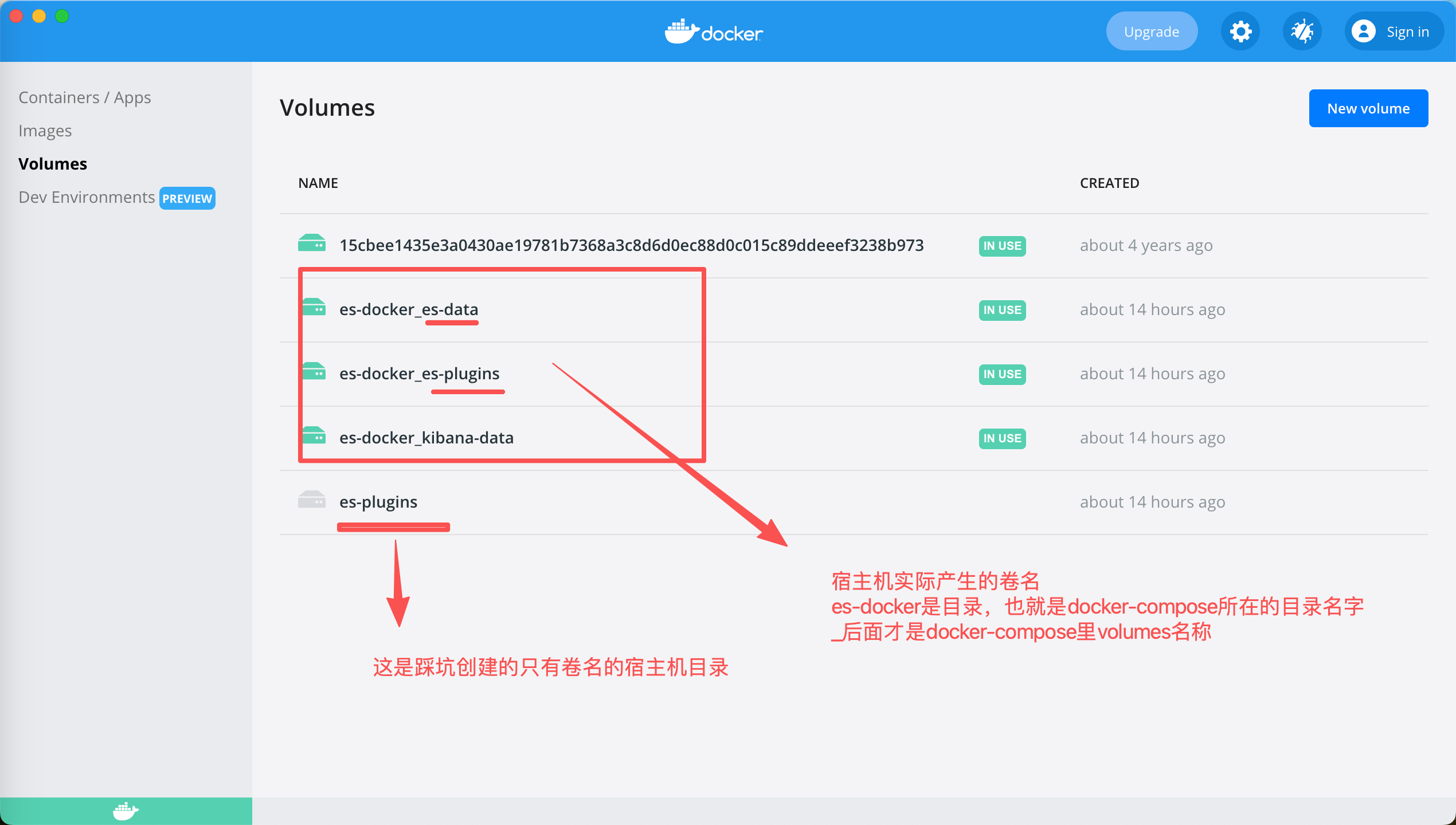
-v es-docker_es-plugins: 这里要注意,如果docker-compose里的volumes没有指定name,那么容器的卷名字格式是:目录名_卷名。 我的目录是es-docker,卷名是es-plugins。所以这里要创建一致,否则宿主机的卷和容器对应不上。
这里的思路是利用alpine这个极简化的临时容器来在宿主机里创建ik相关的目录,这样重启es容器的时候就会把宿主机的目录同步到容器里,这样容器里就有了ik相关的东西。
当然我们也可以直接docker exec -it es7-mac /bin/sh里去下载,但是需要安装wget命令(unzip默认有);也可以下载好docker cp进去,但是这样docker down之后容器就没了。
所以这里的这种做法思路挺好的,因为我们没法直接去控制Mac的DockerDesktop的卷。
这里的好处有:
1、通过临时容器来控制Mac(宿主机)的卷,来通过容器反向映射到宿主机(效果是这样),这样宿主机es-plugins目录就有了ik相关内容(不会丢失了);
2、利用了alpine容器自带的wget命令,方便下载安装包;
3、多行命令通过统一方式组织起来,有完整链路,知道执行了什么,清晰简洁又笼统;
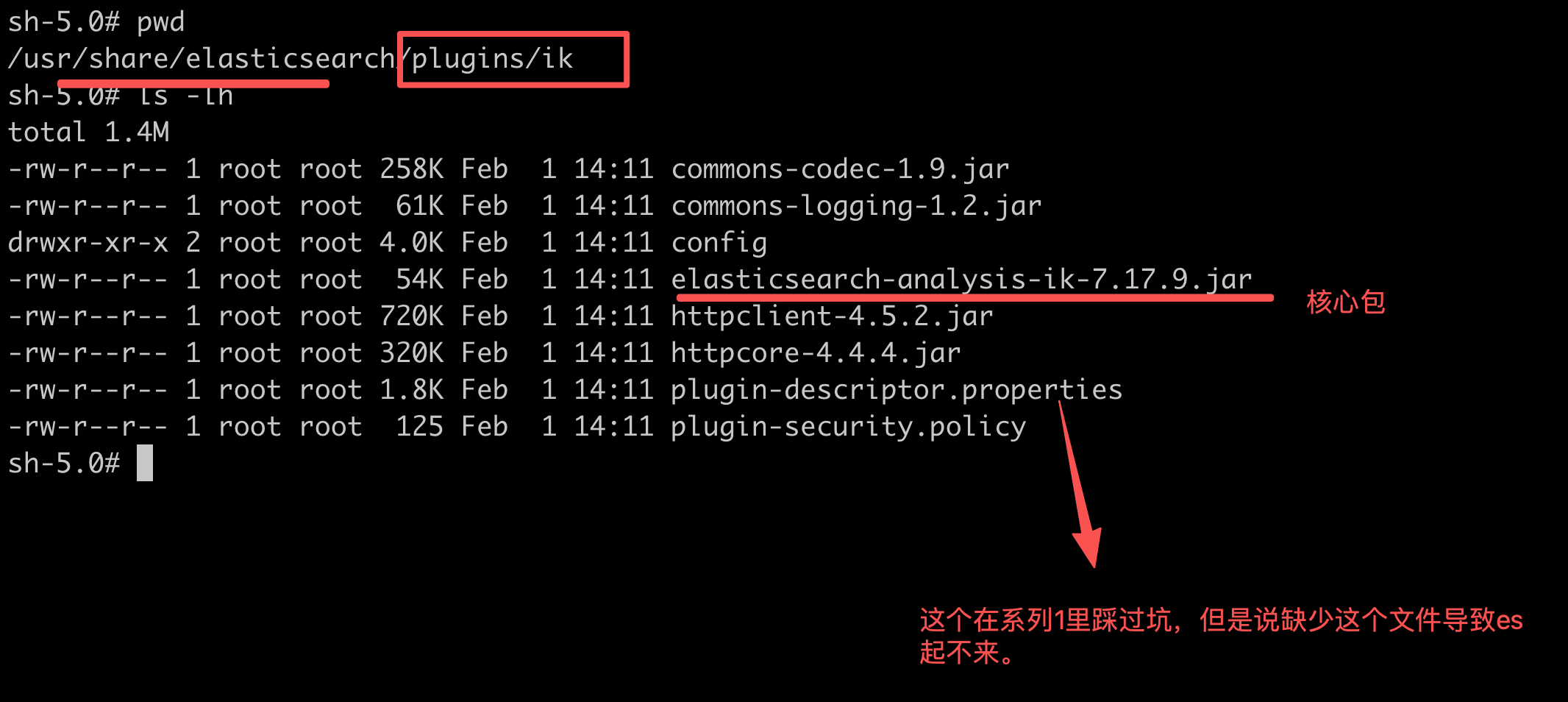
接下来详细看看ik的目录结构:
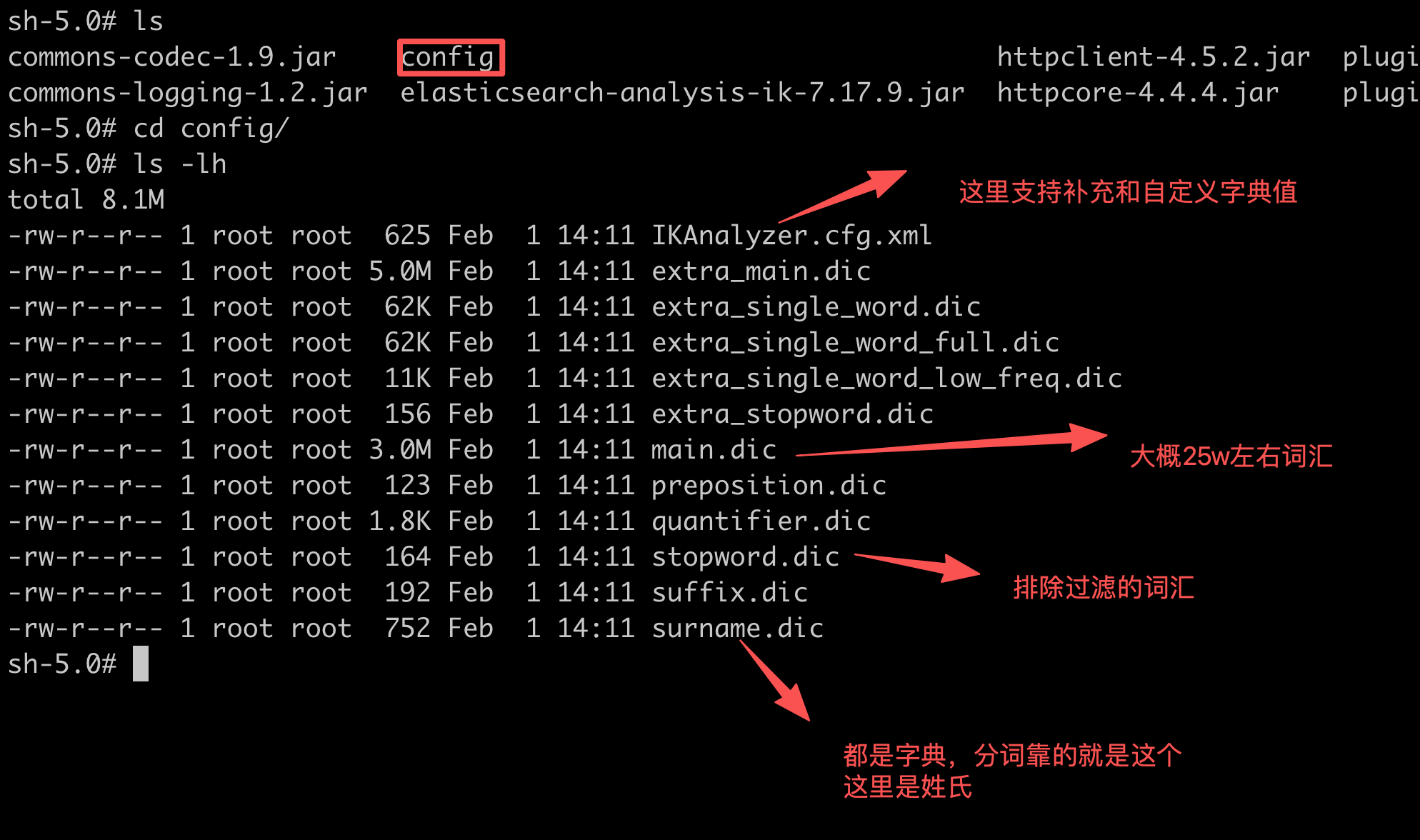
重点看下config目录:
安装成功后进入es容器会发现plugins下有ik目录,里面是有内容的,表明安装成功。
2) 验证
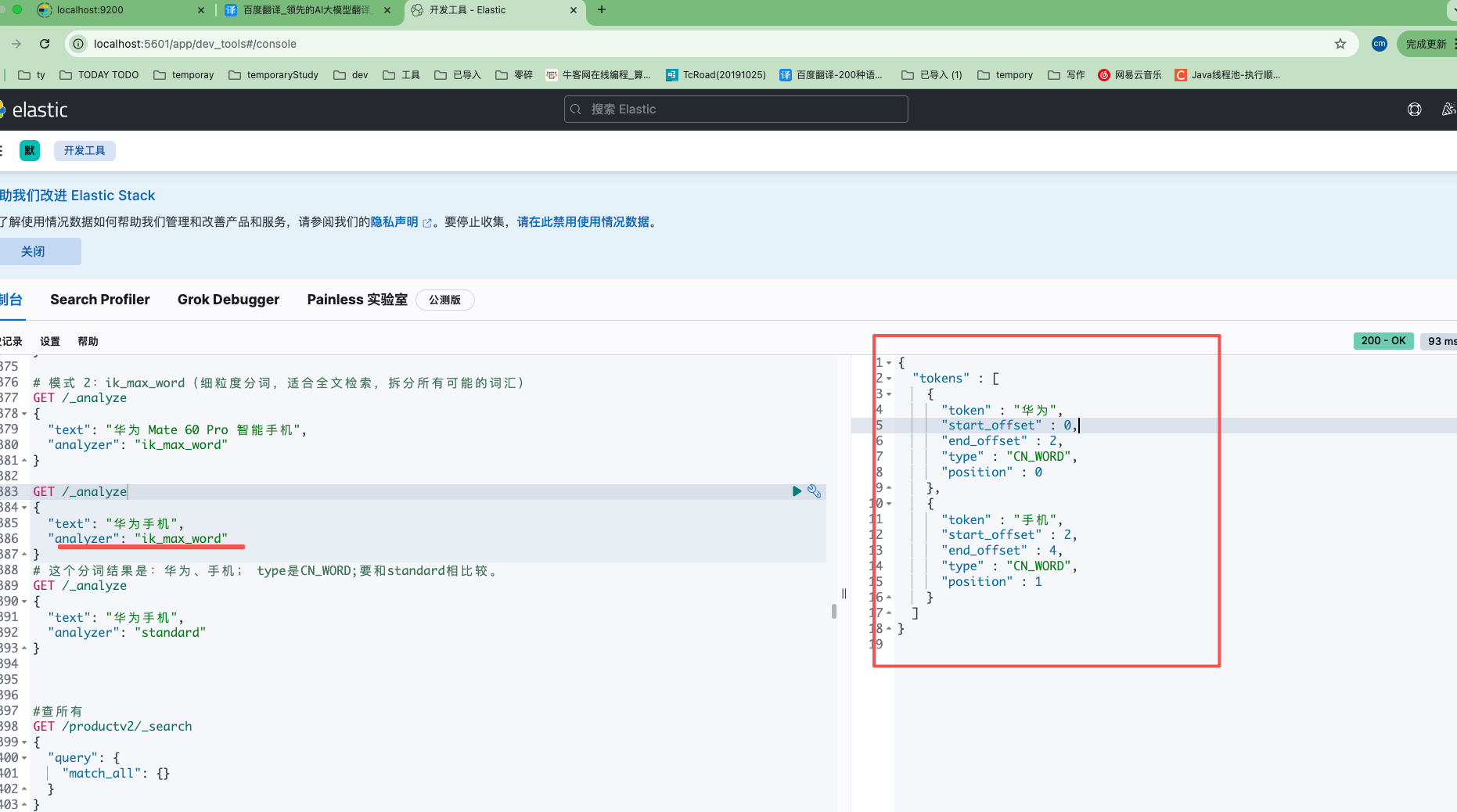
验证下IK分词器效果:
java
#安装成功后验证:IK 两种分词模式(ik_smart 粗粒度、ik_max_word 细粒度)
# 模式 1:ik_smart(粗粒度分词,适合精准匹配,拆分最少词汇)
GET /_analyze
{
"text": "华为 Mate 60 Pro 智能手机",
"analyzer": "ik_smart"
}
# 模式 2:ik_max_word(细粒度分词,适合全文检索,拆分所有可能的词汇)
GET /_analyze
{
"text": "华为 Mate 60 Pro 智能手机",
"analyzer": "ik_max_word"
}
GET /_analyze
{
"text": "华为手机",
"analyzer": "ik_max_word"
}
# 这个分词结果是:华为、手机; type是CN_WORD;要和standard相比较。
GET /_analyze
{
"text": "华为手机",
"analyzer": "standard"
}
#查所有
GET /productv2/_search
{
"query": {
"match_all": {}
}
}
# 1. 删除旧的 product 索引(可选,方便演示)
#DELETE /product
#"analyzer": "ik_max_word", # 全文检索用 ik_max_word(细粒度)
#"search_analyzer": "ik_smart" # 搜索时用 ik_smart(粗粒度,提升查询效率)
# 2. 创建带 IK 分词器的索引(核心:name 字段指定 analyzer: ik_max_word)
PUT /productv3
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"id": {
"type": "integer"
},
"name": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"price": {
"type": "double"
},
"category": {
"type": "keyword"
},
"brand": {
"type": "keyword"
},
"create_time": {
"type": "date",
"format": "yyyy-MM-dd||yyyy-MM-dd HH:mm:ss"
}
}
}
}
# 3. 插入测试数据(多条中文商品数据,方便后续检索)
PUT /productv3/_doc/1
{
"id": 1,
"name": "华为 Mate 60 Pro 智能手机",
"price": 6799.0,
"category": "智能手机",
"brand": "华为",
"create_time": "2024-01-01"
}
PUT /productv3/_doc/2
{
"id": 2,
"name": "华为 MatePad 11 平板电脑",
"price": 2499.0,
"category": "平板电脑",
"brand": "华为",
"create_time": "2024-02-01"
}
PUT /productv3/_doc/3
{
"id": 3,
"name": "苹果 iPhone 15 智能手机",
"price": 5999.0,
"category": "智能手机",
"brand": "苹果",
"create_time": "2024-03-01"
}
PUT /productv3/_doc/4
{
"id": 4,
"name": "小米 14 智能手机",
"price": 3999.0,
"category": "智能手机",
"brand": "小米",
"create_time": "2024-04-01"
}
PUT /productv3/_doc/5
{
"id": 5,
"name": "华商日报",
"price": 5.0,
"category": "报纸",
"brand": "华商",
"create_time": "2026-02-02"
}
# 4. 测试中文检索(使用 match 查询,验证 IK 分词效果)
GET /productv3/_search
{
"query": {
"match": {
"name": "华为手机"
}
}
}
GET /productv2/_mapping
GET /productv2/_search
{
"query": {
"match_all": {}
}
}
#总结:
#IK 分词器两个核心模式:ik_max_word(建索引时用,提升检索命中率)、ik_smart(查询时用,提升效率)。
#中文字段需在 Mapping 中明确指定 analyzer: ik_max_word,否则仍会使用默认 standard 分词器。
#IK 插件版本必须与 ES 版本严格一致,否则会导致 ES 启动失败或分词无效。二、深入复合查询与高亮显示
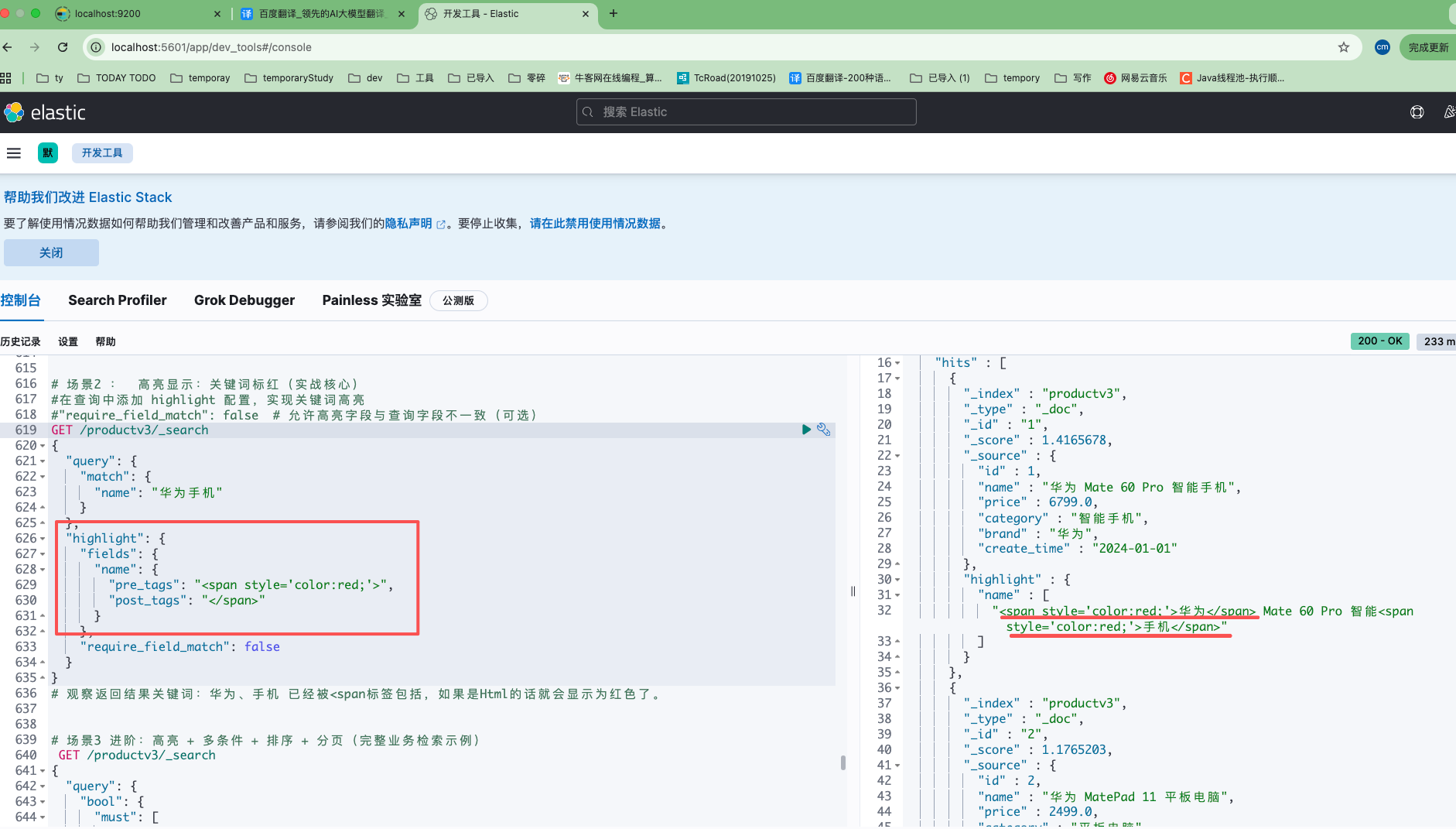
先看下效果:
具体操作步骤如下:
sql
# 二、深入复合查询与高亮显示
#掌握 bool 查询的完整子句(must/should/must_not/filter),实现复杂多条件组合。
#实现搜索结果高亮显示(关键词标红),提升用户体验。
#掌握常见辅助查询(排序、分页、字段过滤),完善检索功能。
#must:必须满足(相当于 AND,参与评分)。
#should:可选满足(相当于 OR,满足越多评分越高)。
#must_not:必须不满足(相当于 NOT,不参与评分)。
#filter:过滤条件(不参与评分,性能更优,优先使用)
#场景 1:查询「智能手机」分类中,品牌为「华为」或「苹果」,价格大于 3000 且不等于 5999 的商品
GET /productv3/_search
{
"query": {
"match_all": {}
}
}
GET /productv3/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"category": "智能手机"
}
}
],
"should": [
{
"term": {
"brand": "华为"
}
},
{
"term": {
"brand": "苹果"
}
}
],
"must_not": [
{
"term": {
"price": 5999.0
}
}
],
"filter": [
{
"range": {
"price": {
"gt": 3000
}
}
}
]
}
},
"sort": [
{
"price": {
"order": "desc"
}
}
],
"from": 0,
"size": 10,
"_source": ["name", "price", "brand", "category"]
}
#注意这里 小米手机也返回了。满足must不满足should,所以也返回了。如果只是should,那么小米不会返回。
#"If the bool query includes at least one must or filter clause, no should clauses are required to match."
#must 定生死,should 定高低;要过滤 should,必加 minimum_should_match!
# 1)召回优先原则
#must 定义"必须满足的硬条件",should 定义"锦上添花的软条件"
#→ 避免因次要条件丢失有效结果(如用户搜"智能手机",小米手机仍是有效结果)
# 2)评分与过滤分离
#过滤(Filter):用 must/filter 做硬性筛选(结果非黑即白)
#评分(Scoring):用 should 调整排序(结果有优劣之分) 符合搜索"先召回再排序"的核心流程
# 3)灵活性
#通过 minimum_should_match 精细控制:
#0 = 完全可选(默认)
#1 = 至少满足1个
#2 = 必须满足全部
#"75%" = 满足75%的 should 条件
# 场景2 : 高亮显示:关键词标红(实战核心)
#在查询中添加 highlight 配置,实现关键词高亮
#"require_field_match": false # 允许高亮字段与查询字段不一致(可选)
GET /productv3/_search
{
"query": {
"match": {
"name": "华为手机"
}
},
"highlight": {
"fields": {
"name": {
"pre_tags": "<span style='color:red;'>",
"post_tags": "</span>"
}
},
"require_field_match": false
}
}
# 观察返回结果关键词:华为、手机 已经被<span标签包括,如果是Html的话就会显示为红色了。
# 场景3 进阶:高亮 + 多条件 + 排序 + 分页(完整业务检索示例)
GET /productv3/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "手机"
}
}
],
"filter": [
{
"range": {
"price": {
"gte": 2000,
"lte": 8000
}
}
}
]
}
},
"highlight": {
"fields": {
"name": {
"pre_tags": "<span style='color:red;'>",
"post_tags": "</span>"
}
}
},
"sort": [
{
"price": {
"order": "asc"
}
}
],
"from": 0,
"size": 10,
"_source": ["name", "price", "brand"]
}
#优先使用 filter 做条件过滤(如范围、精确匹配),性能优于 must,因为 filter 会缓存结果。
#should 子句在 must 存在时,满足一个即可提升评分;无 must 时,至少满足一个(否则返回所有数据)。
#高亮显示的核心是 highlight 配置,pre_tags 和 post_tags 可自定义(适配前端页面样式)三、思考
1、IK分词器原理?
四、下期预告
【下期】3、Java 客户端整合 4、性能优化入门:了解分片策略、避免深度分页、优化查询语句,解决实战中的性能问题