一、变化率
1.1、rate函数
用于计算变化率的最常见函数是 rate(),rate() 函数用于计算在指定时间范围内计数器平均每秒的增加量。因为是计算一个时间范围内的平均值,所以我们需要在序列选择器之后添加一个时间范围选择器。
|--------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 序号 | rate函数的注意事项 |
| 1 | 当被抓取指标进的程重启时,Counter 指标可能会重置为 0,但 rate() 函数会自动处理这个问题,它会假设 Counter 指标的值只要是减少了就认为是被重置了,然后它可以调整后续的样本。 (如:如果时间序列的值为[5,10,4,6],则将其视为[5,10,14,16])。 |
| 2 | 变化率是从指定的时间范围下包含的样本进行计算的,需要注意的是这个时间窗口的边界并不一定就是一个样本数据,可能会不完全对齐。 |
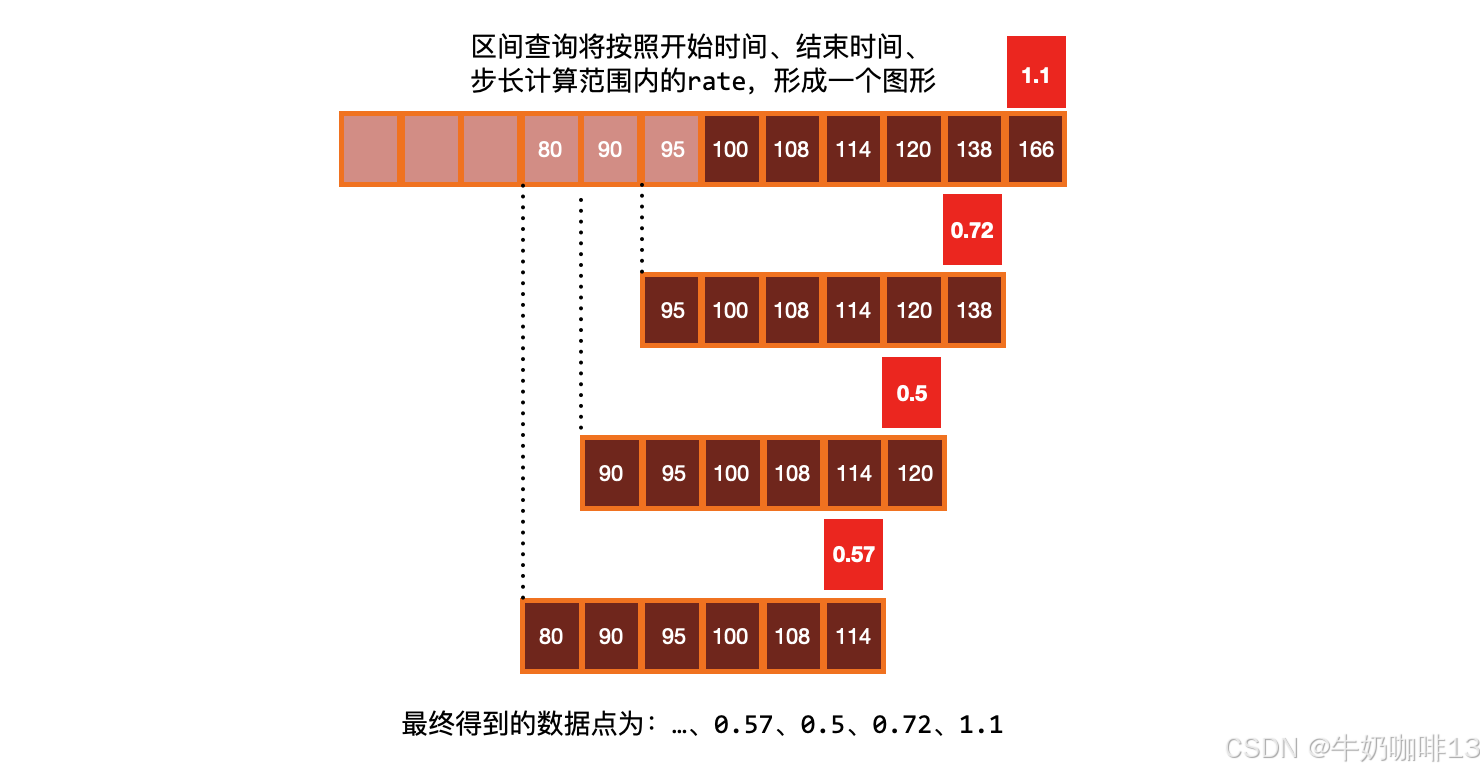
| 3 | rate() 函数需要在指定时间窗口下至少有两个样本才能计算输出。一般来说,比较好的做法是选择范围窗口大小至少是抓取间隔的4倍,这样即使在遇到窗口对齐或抓取故障时也有可以使用的样本进行计算。 (如:对于prometheus的默认抓取数据间隔是15秒,则可以使用1分钟(4*15=60秒)的 Rate 计算;若抓取时间为1分钟,则可以使用4分钟的Rate计算,但是通常将其四舍五入为 5 分钟)。所以如果使用 query_range 区间查询,那么范围应该至少是步长的大小,否则会丢失一些数据。 |
[rate函数的注意事项]
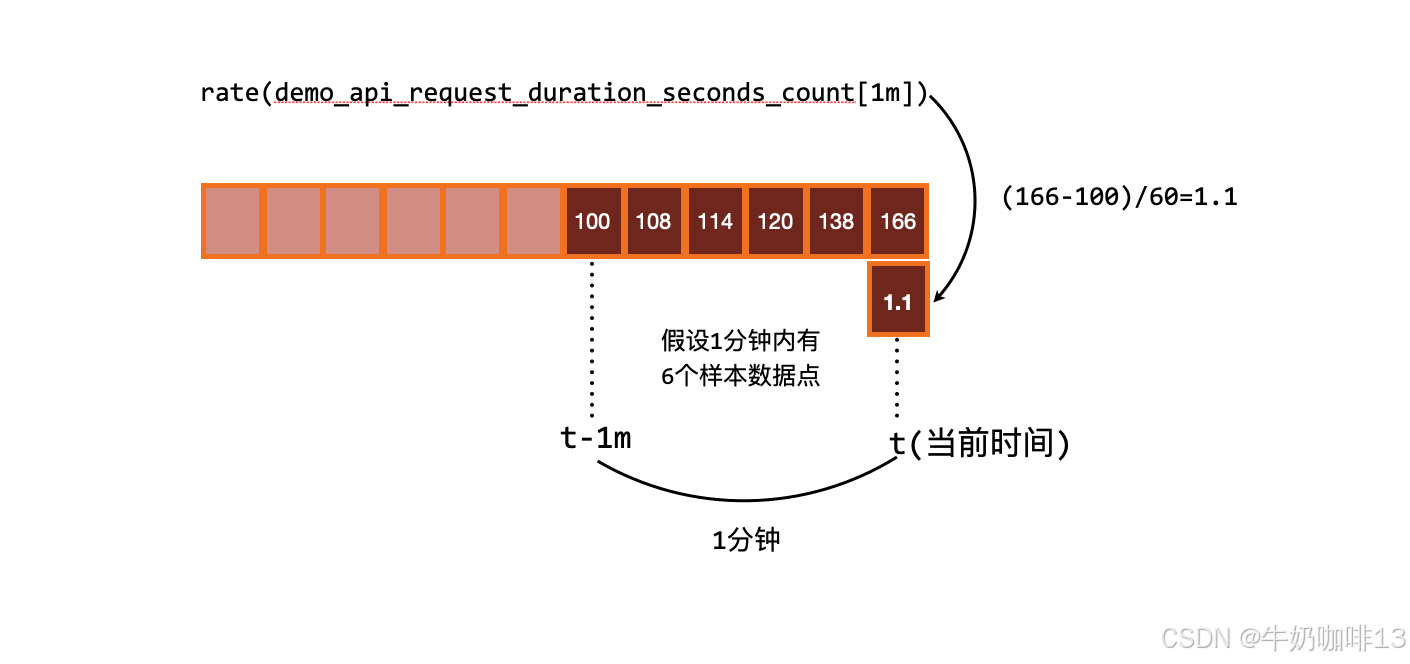
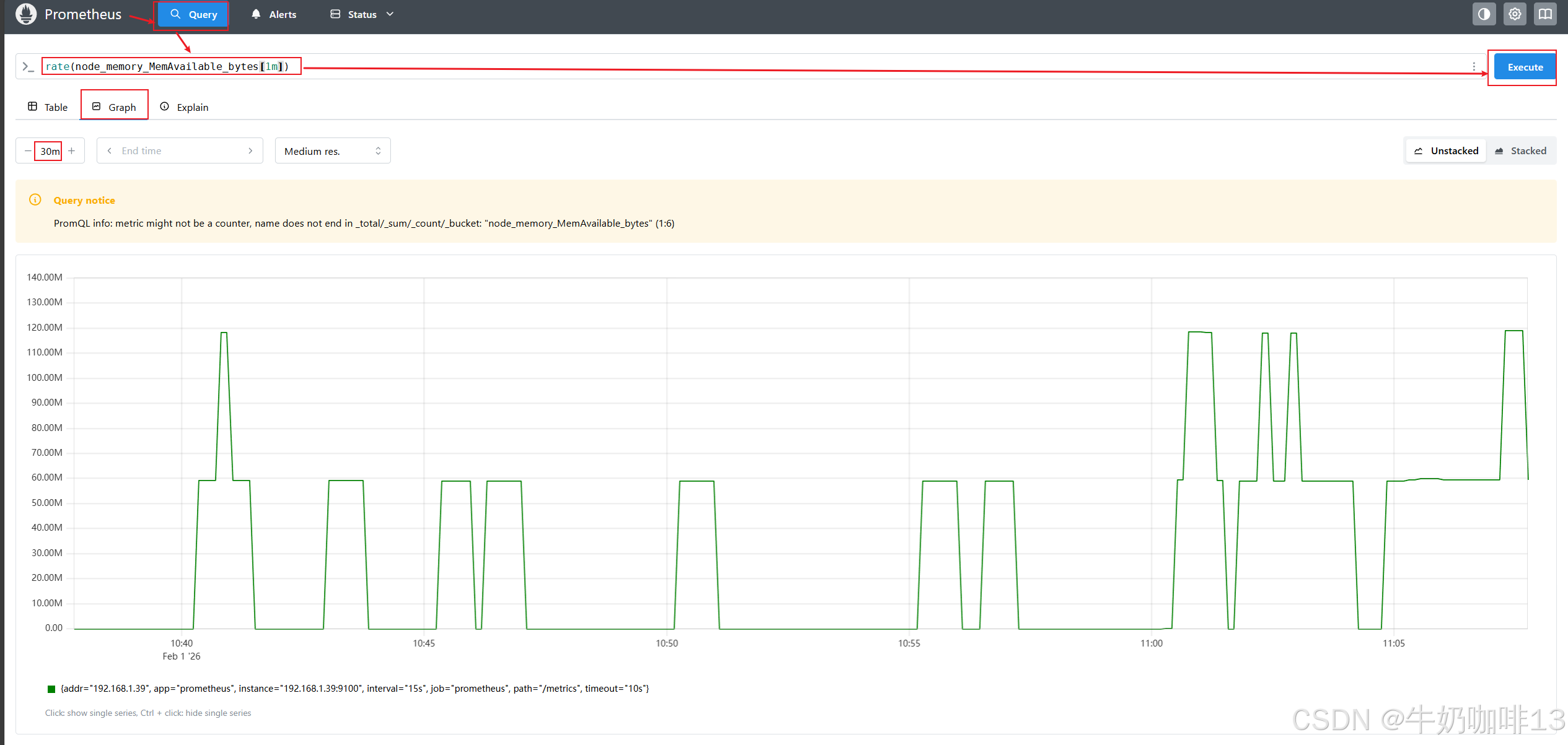
进行 rate 计算的时候是选择指定时间范围下的**第一和最后一个样本进行计算;**当需要的是绘制一个图形,那么就需要进行区间查询,指定一个时间范围内进行多次计算,将结果串联起来形成一个图形。
bash
#rate函数示例
node_memory_MemAvailable_bytes[1m]
rate(node_memory_MemAvailable_bytes[1m])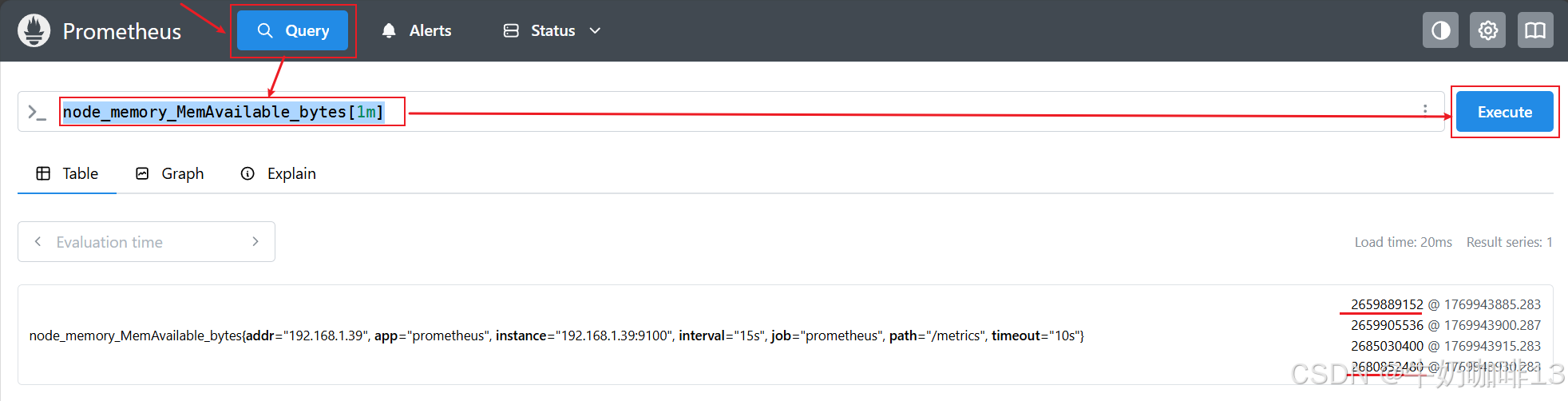
1.2、irate函数
由于使用 rate 或者 increase 函数去计算样本的平均增长速率,容易陷入长尾问题 当中,其无法反应在时间窗口内样本数据的突发变化。(如:对于主机而言在 2 分钟的时间窗口内,可能在某一个由于访问量或者其它问题导致 CPU 占用 100%的情况,但是通过计算在时间窗口内的平均增长率却无法反应出该问题)。
为了解决该问题,PromQL 提供了另外一个灵敏度更高的函数irate(v range-vector)。irate 同样用于计算区间向量的增长率,但是其反应出的是瞬时增长率。
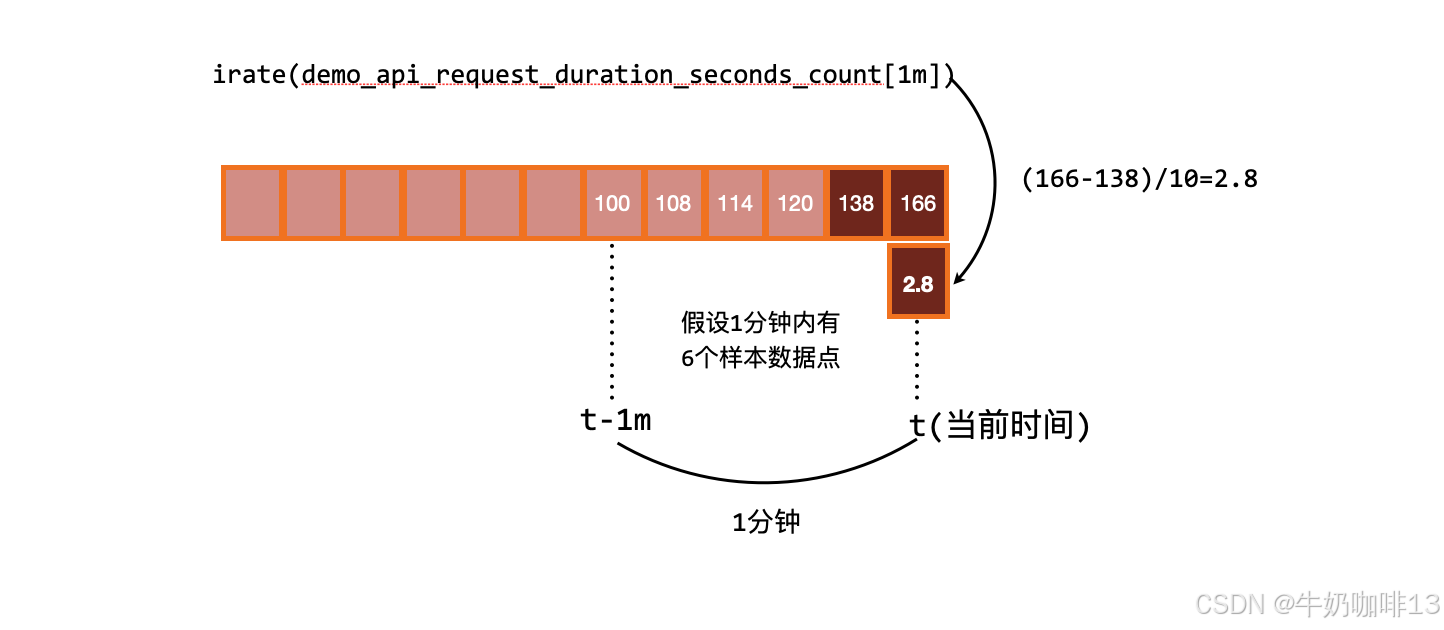
【irate】函数是通过区间向量中最后两个样本数据来计算区间向量的增长速率 。这种方式可以避免在时间窗口范围内的长尾问题,并且体现出更好的灵敏度,通过 irate 函数绘制的图标能够更好的反应样本数据的瞬时变化状态。
那既然是使用最后两个点计算,那为什么还要指定类似于 [1m] 的时间范围呢?这个 [1m] 不是用来计算的,irate 在计算的时候会最多向前在 [1m] 范围内找点,如果超过 [1m] 没有找到数据点,这个点的计算就放弃了。
由于 rate() 提供了更平滑的结果,因此在长期趋势分析或者告警中更推荐使用 rate 函数,因为当速率只出现一个短暂的峰值时,不应该触发该报警。
bash
#rate函数查看node_memory_MemAvailable_bytes指标在1分钟内的时间序列百分比情况
rate(node_memory_MemAvailable_bytes[1m])
#irate函数查看node_memory_MemAvailable_bytes指标在1分钟内的时间序列百分比情况
irate(node_memory_MemAvailable_bytes[1m])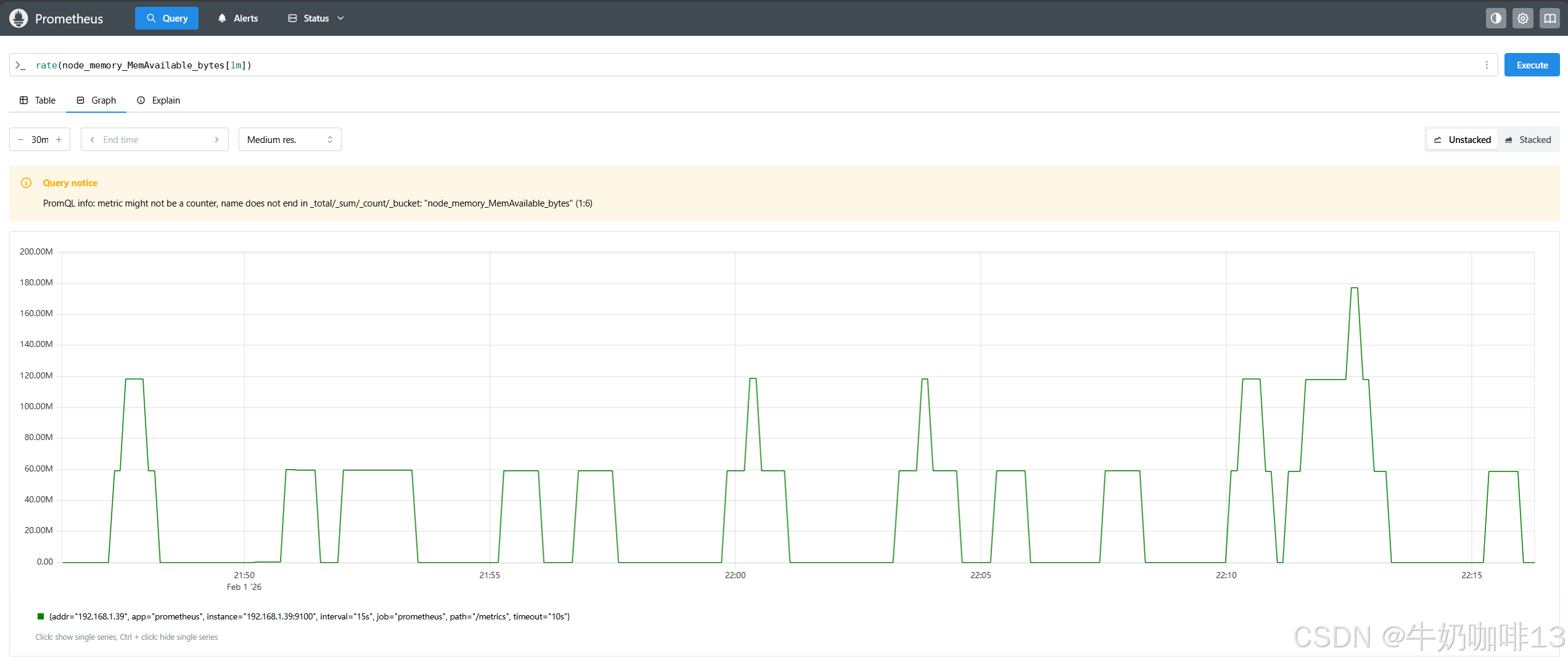
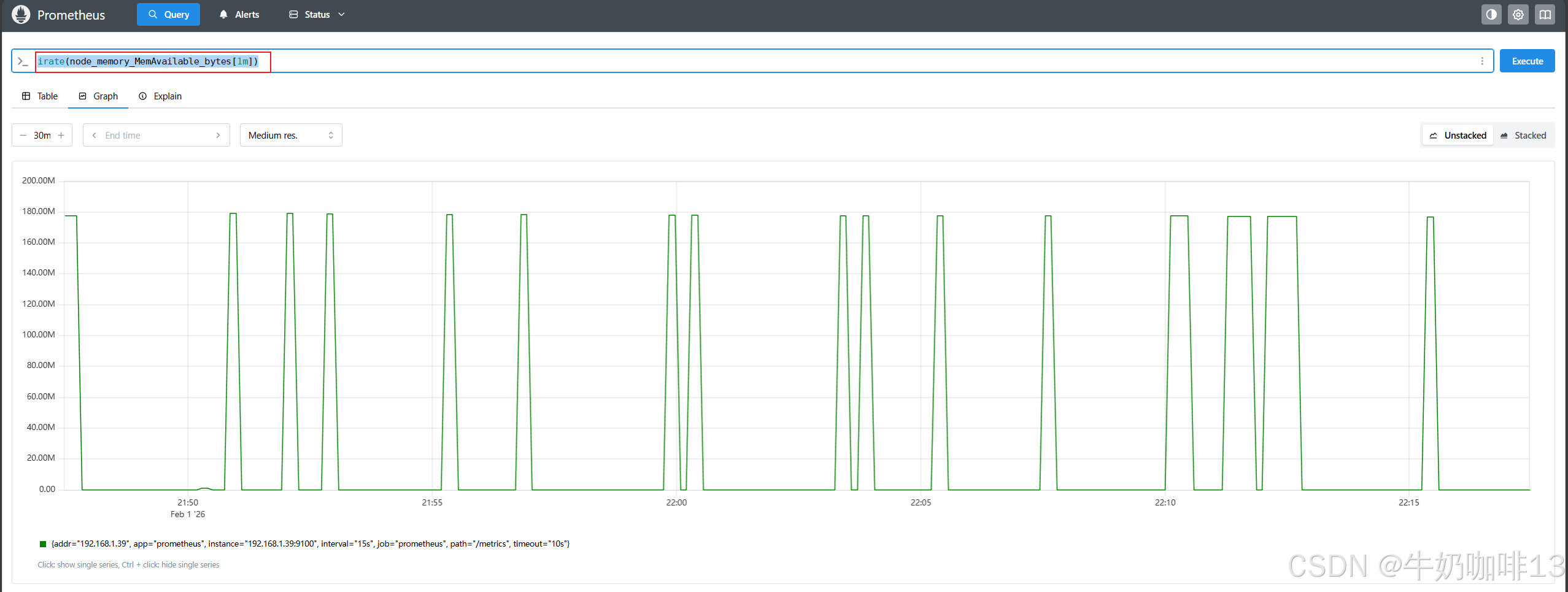
除了计算每秒速率,还可以使用【increase()】函数查询指定时间范围内的总增量,它基本上相当于速率乘以时间范围选择器中的秒数:
bash
#increase函数查看node_memory_MemAvailable_bytes指标在1分钟内的时间序列数量情况
increase(node_memory_MemAvailable_bytes[1m])如上的表达式的【increase()】函数结果和使用【rate()】函数计算的结果整体图形趋势都是一样的,只是 Y 轴的数据不一样而已,一个表示数量,一个表示百分比。
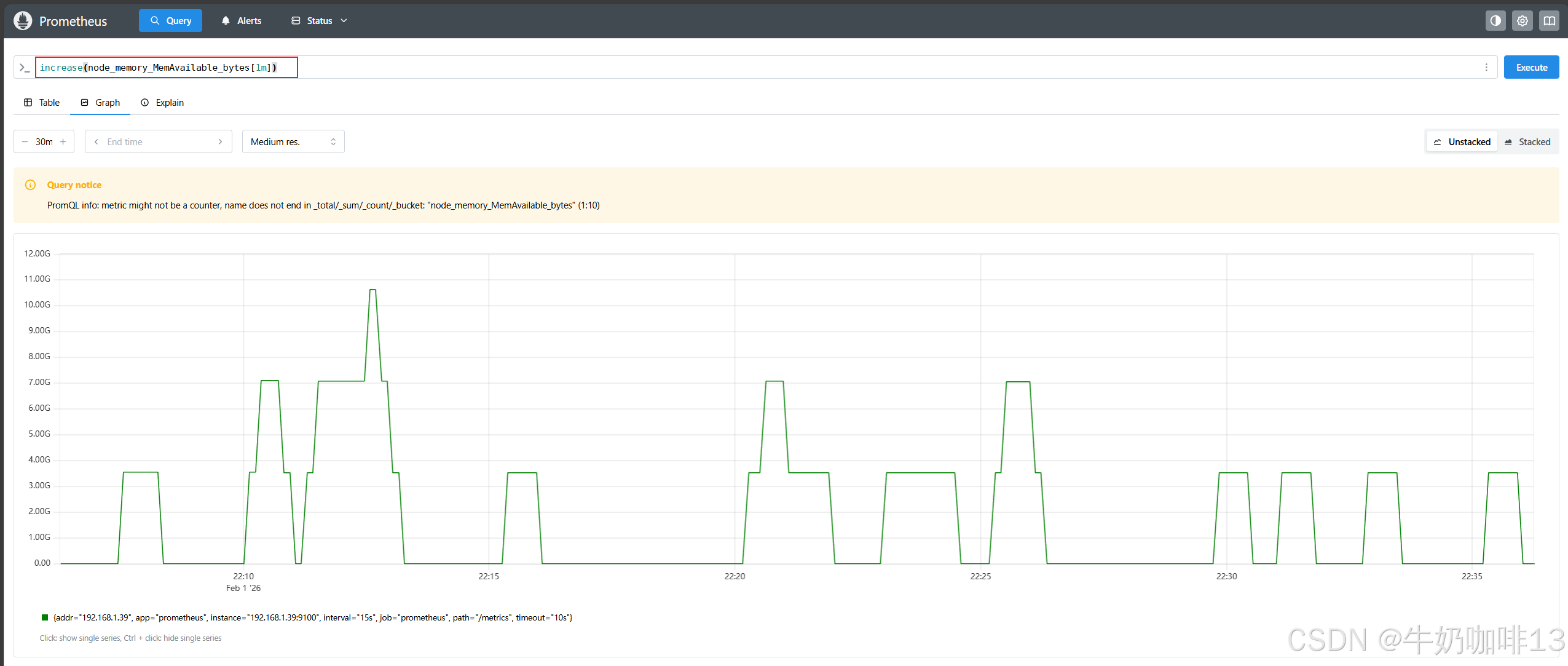
注意:rate()、irate() 和 increase() 函数只能输出非负值的结果。
二、聚合
Prometheus 时间序列数据是多维数据模型,当有对 各个维度进行汇总的需求时,就需要用到聚合。更通俗的说法是:将相同的样本数据整合到一起,得到整体的趋势数据
(如:在一套集群系统中,假设有10个节点,那么这10个节点的运行状态是什么样的?平时我们对这些节点的关注点是在CPU、磁盘、内存、网络等资源的使用量,都只是关注到集群中单个节点的资源使用情况;若想要从整体上对集群有一个了解,如想要查看该集群中CPU的使用量是什么样的状态,这个时候就需要使用聚合的功能【所谓的聚合就是将整个集群中所有节点中同一类的监控数据合并起来,得到一个整体的趋势数据】;就以CPU的使用率来说,针对该集群中10个节点CPU在一天中的使用状态,就需要将10个节点的CPU使用量数据加起来,然后看一个整体的变化率,可以了解到整个集群在一天中哪个时段的CPU使用量是高的,哪个时段使用CPU的量是低的,通过这样一个整体的数据汇总,就可以判断出在CPU使用的高峰有没有达到一个饱和的状态 ,是否需要扩容,这就是聚合的功能,通过聚合可以查看一个整体的状态情况,这就是聚合的实际应用示例)。
2.1、基于标签聚合
|--------|---------------------|---------------------|
| 序号 | 标签聚合器名称 | 说明 |
| 1 | sum() | 对聚合分组中的所有值进行求和 |
| 2 | min() | 获取一个聚合分组中最小值 |
| 3 | max() | 获取一个聚合分组中最大值 |
| 4 | avg() | 计算聚合分组中所有值的平均值 |
| 5 | stddev() | 计算聚合分组中所有数值的标准差 |
| 6 | stdvar() | 计算聚合分组中所有数值的标准方差 |
| 7 | count() | 计算聚合分组中所有序列的总数 |
| 8 | count_values() | 计算具有相同样本值的元素数量 |
| 9 | bottomk(k, ...) | 计算按样本值计算的最小的 k 个元素 |
| 10 | topk(k,...) | 计算最大的 k 个元素的样本值 |
| 11 | quantile(φ,...) | 计算维度上的 φ-分位数(0≤φ≤1) |
| 12 | group(...) | 只是按标签分组,并将样本值设为 1 |
[prometheus支持的标签聚合器]
bash
#想知道prometheus这个服务下消耗的cpu总时间,那么可以将多个标签下每个标签的速率相加即可
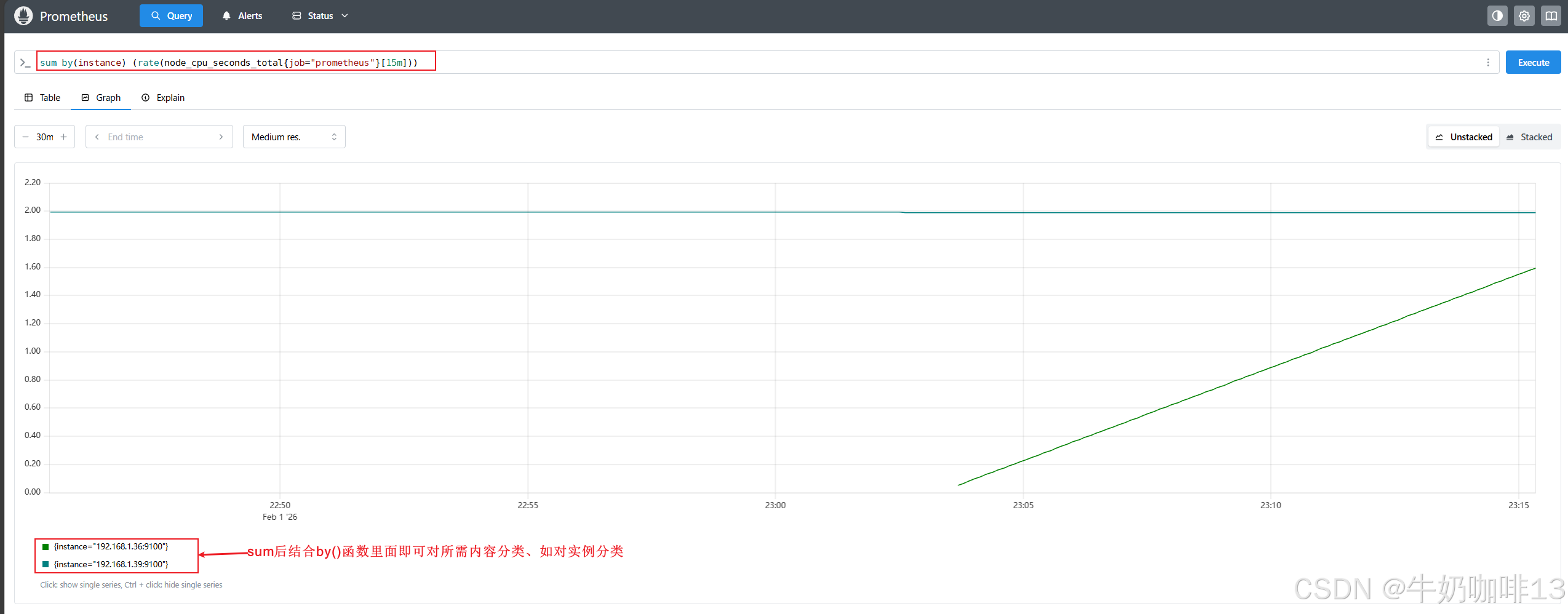
#可以看到绘制出来的图形没有保留任何标签维度,一般来说可能我们希望保留一些维度,例如,我们可能更希望计算每个 instance 上CPU的变化率,但并不关心哪个 cpu或者 mode 的结果,这个时候我们可以在 sum() 聚合器中添加一个 by() 的修饰符
sum (rate(node_cpu_seconds_total{job="prometheus"}[15m]))
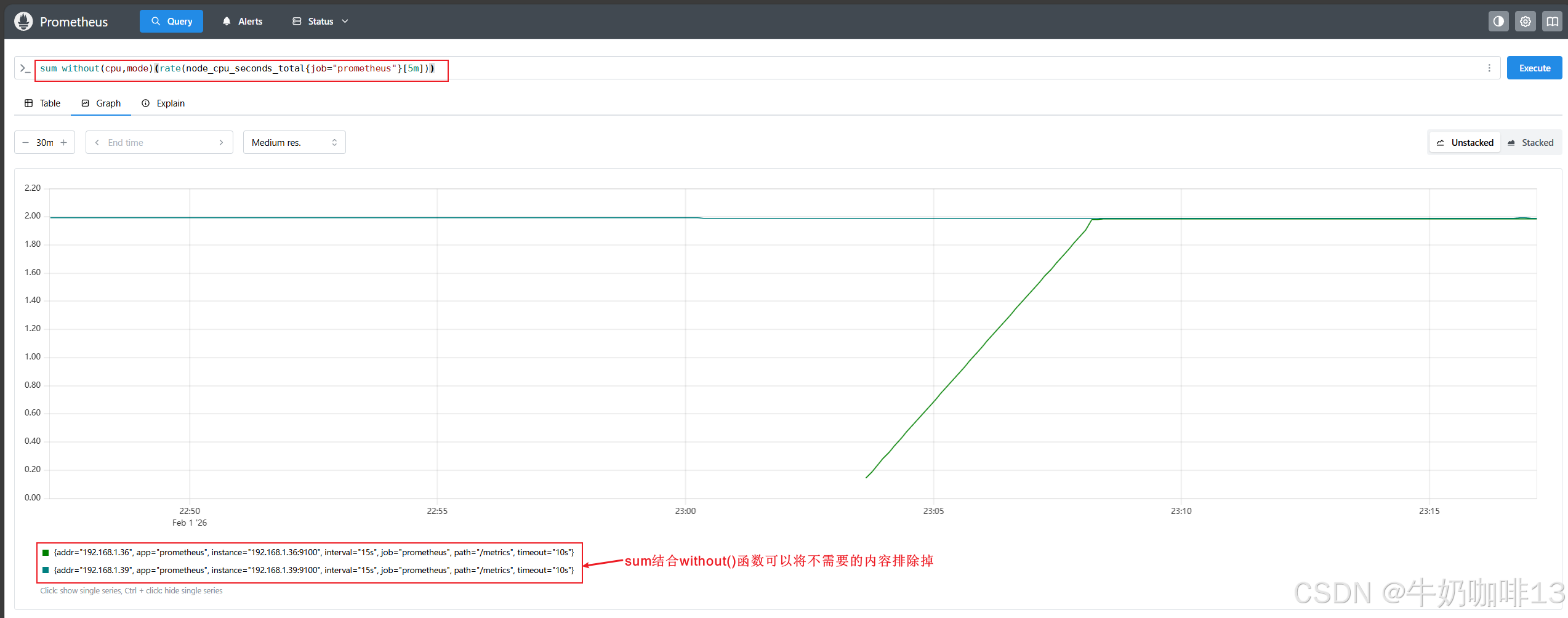
#对聚合内容进行分类或者排除内容
sum by(instance) (rate(node_cpu_seconds_total{job="prometheus"}[15m]))
sum without(cpu,mode)(rate(node_cpu_seconds_total{job="prometheus"}[5m]))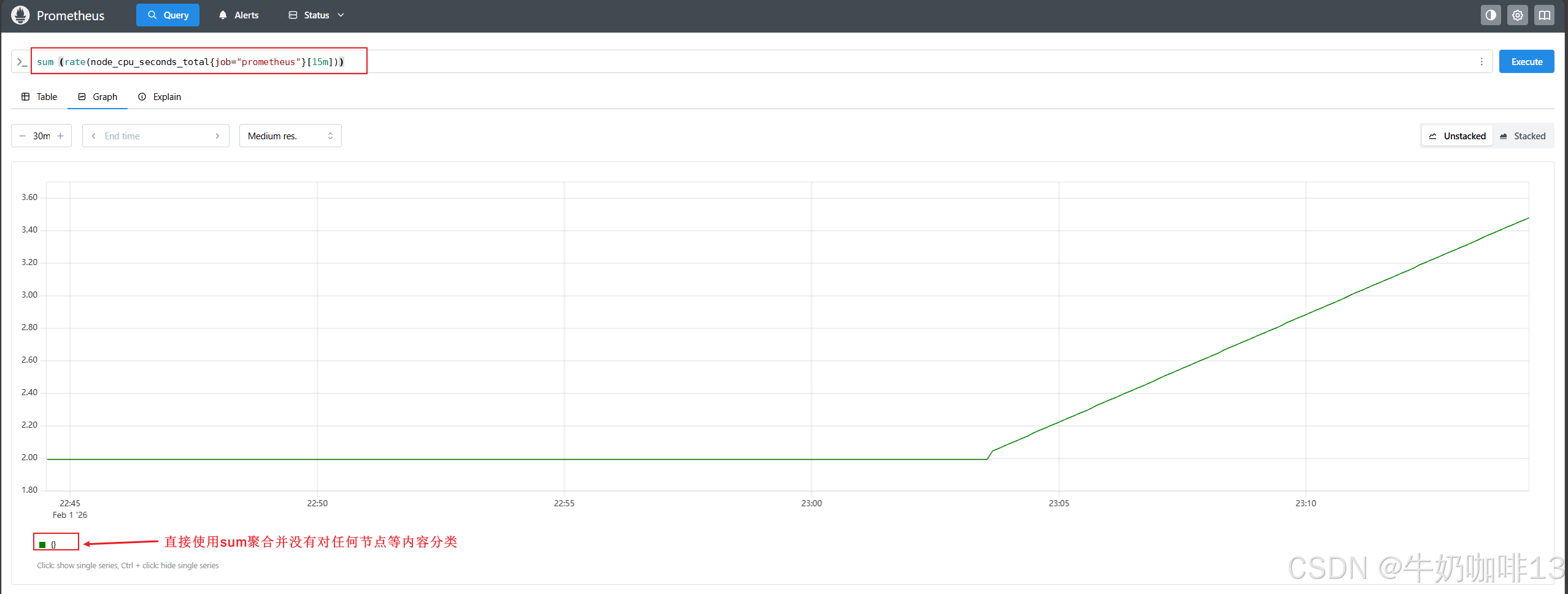
bash
#聚合示例
#示例1-获取指标node_cpu_seconds_total在最近5分钟内的最大使用比例情况
max by(instance) (rate(node_cpu_seconds_total{job="prometheus"}[5m]))
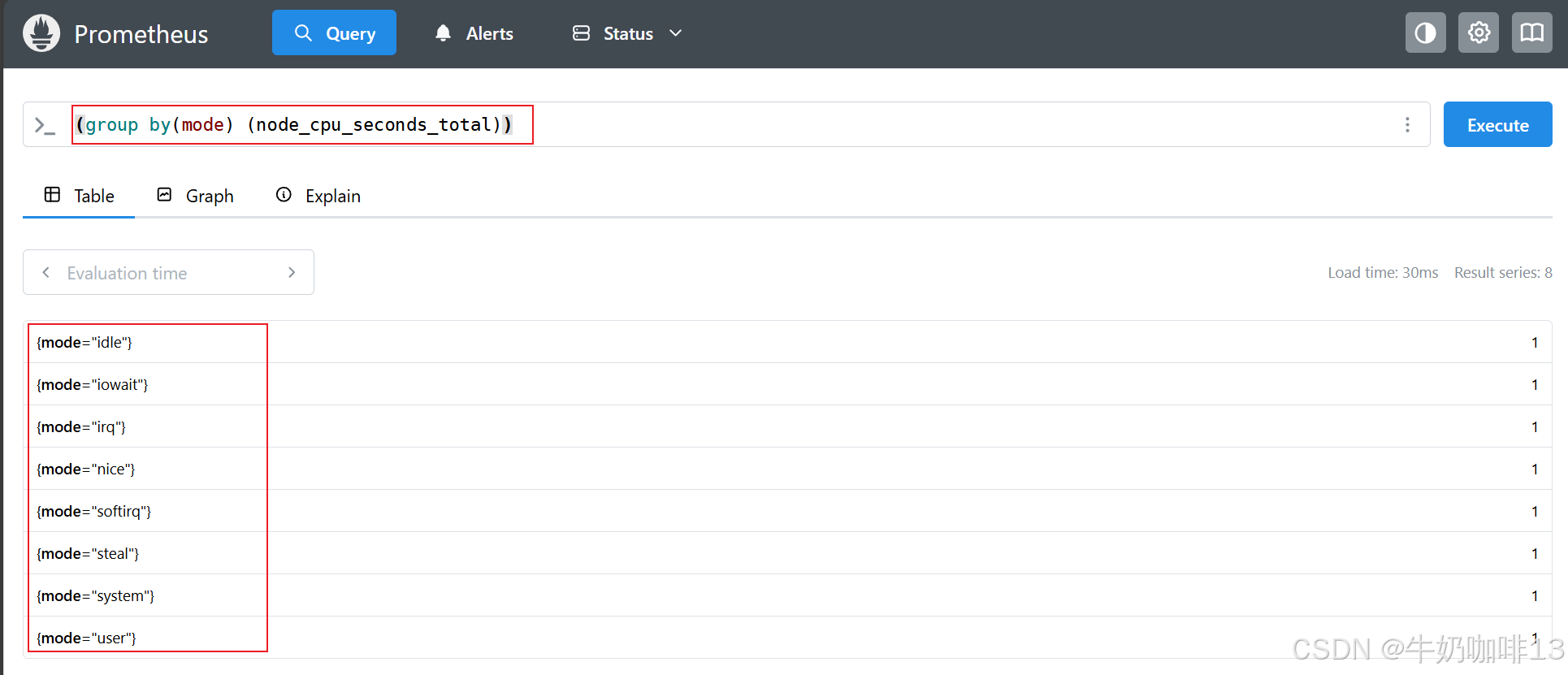
#示例2-计算 node_cpu_seconds_total 指标有多少不同的 CPU 模式
(group by(mode) (node_cpu_seconds_total))
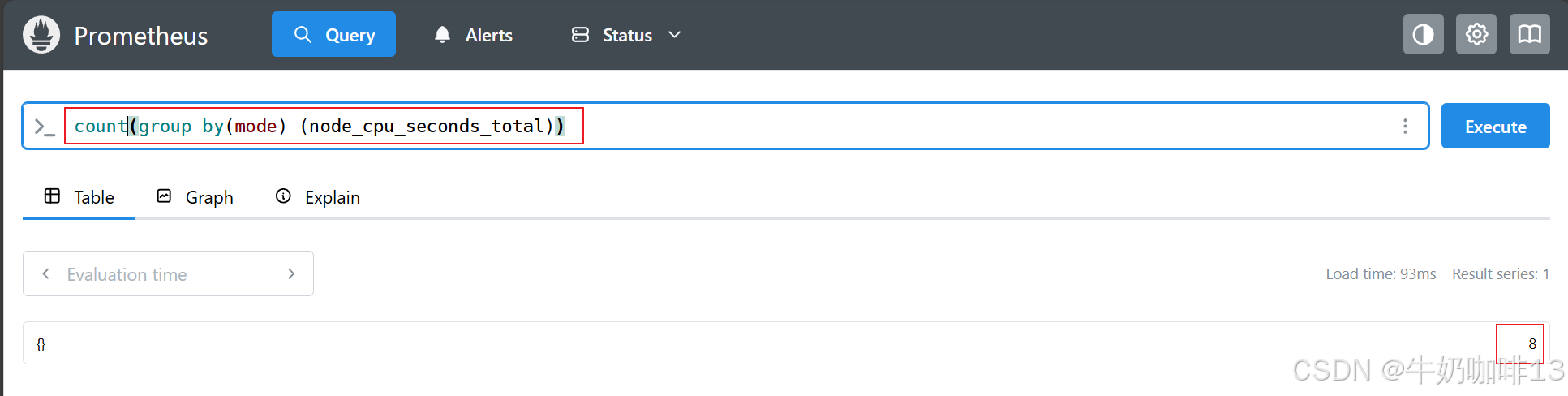
count(group by(mode) (node_cpu_seconds_total))
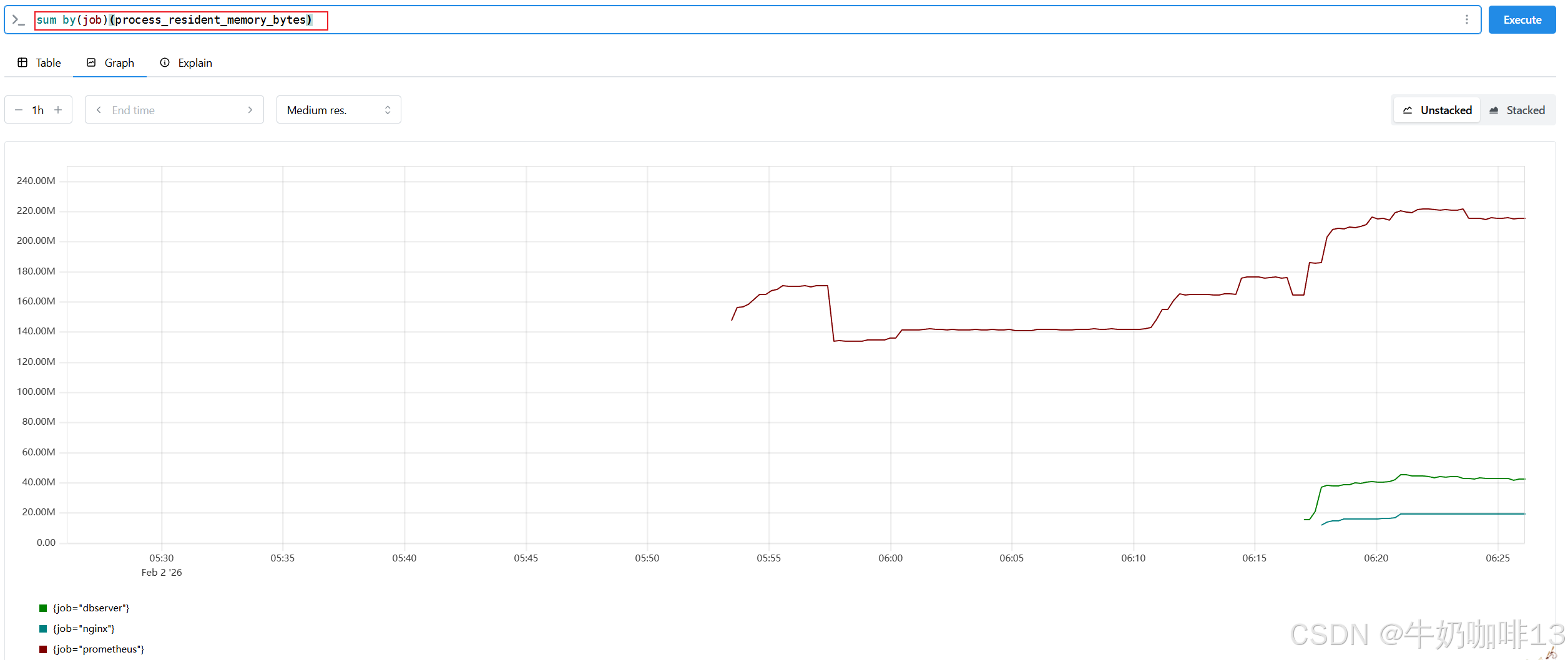
#示例3-按【job】或【instance】分组聚合,计算prometheus进程的总内存使用量
sum by(job)(process_resident_memory_bytes)
sum by(instance)(process_resident_memory_bytes)
#示例4-计算每个【instance】和指标名称的时间序列数量
count by(instance) (node_cpu_seconds_total)
count by(instance,__name__) ({__name__!=""})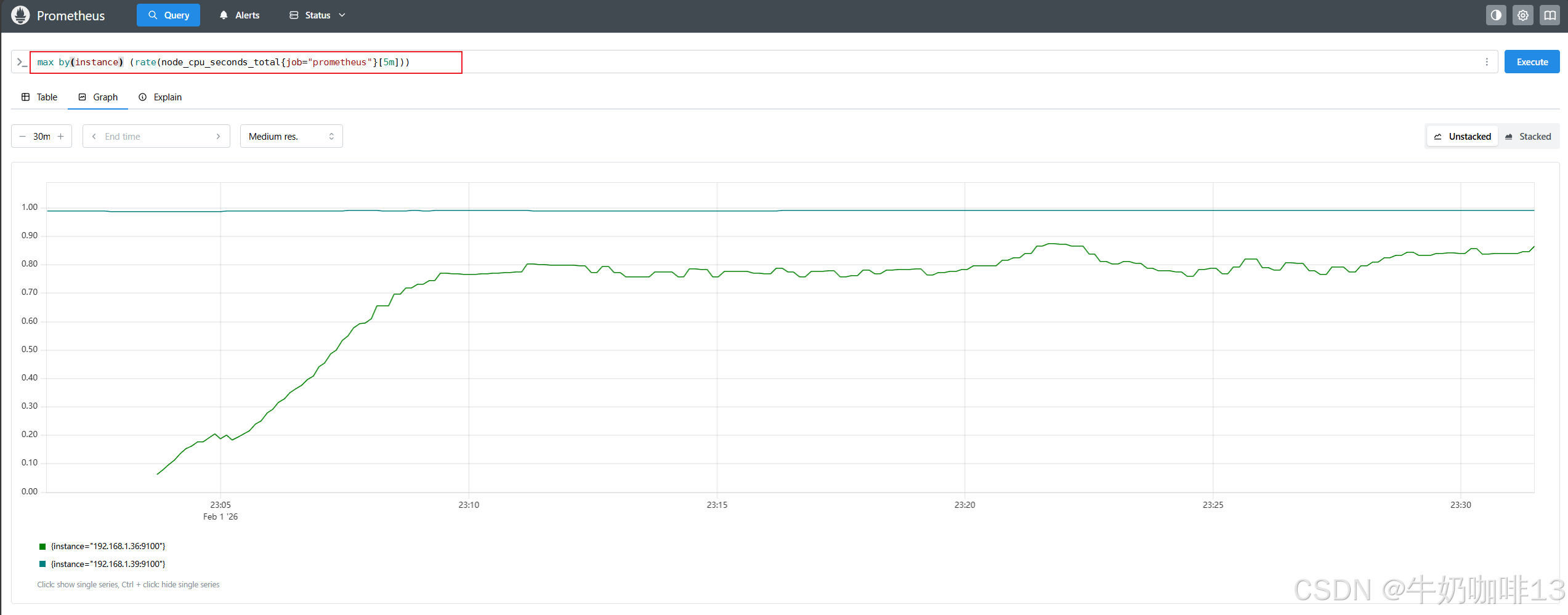
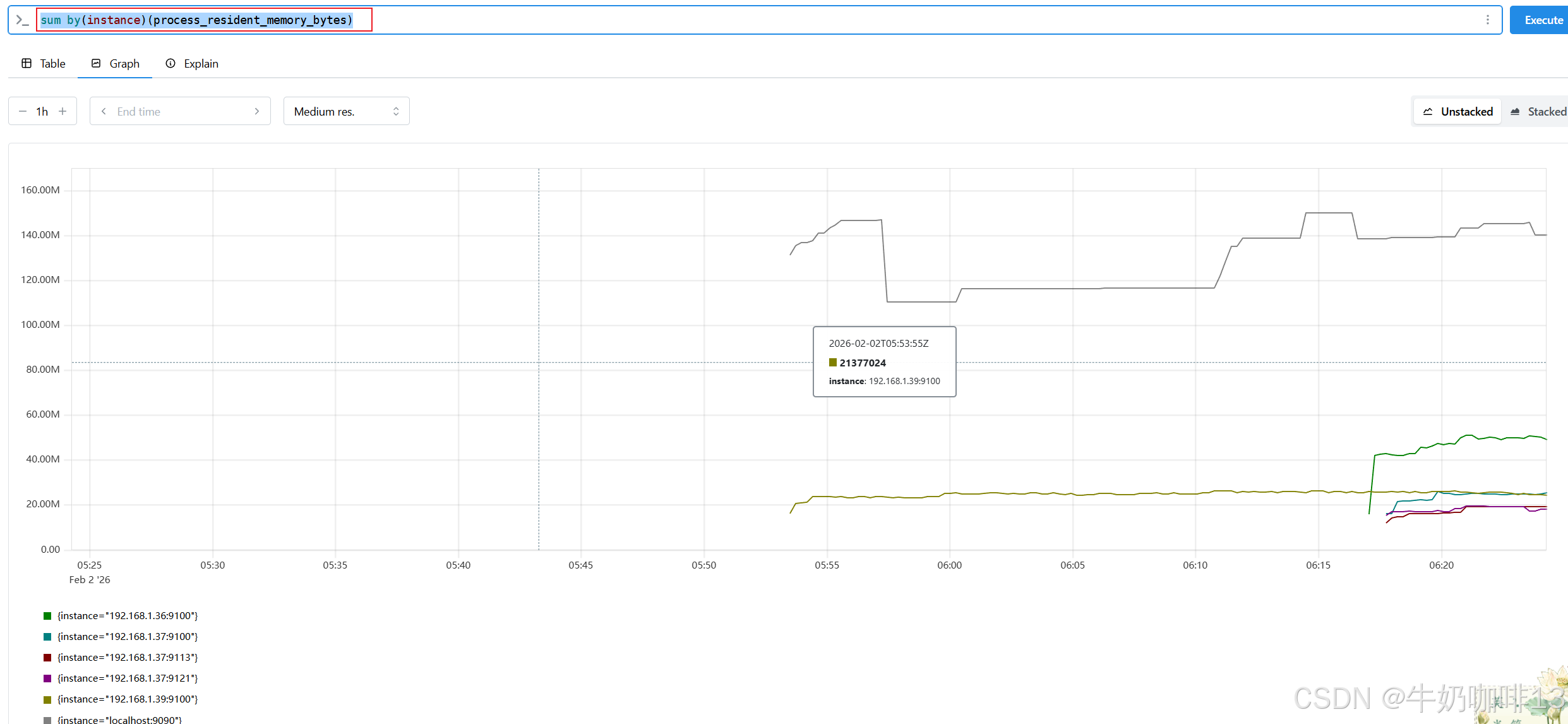
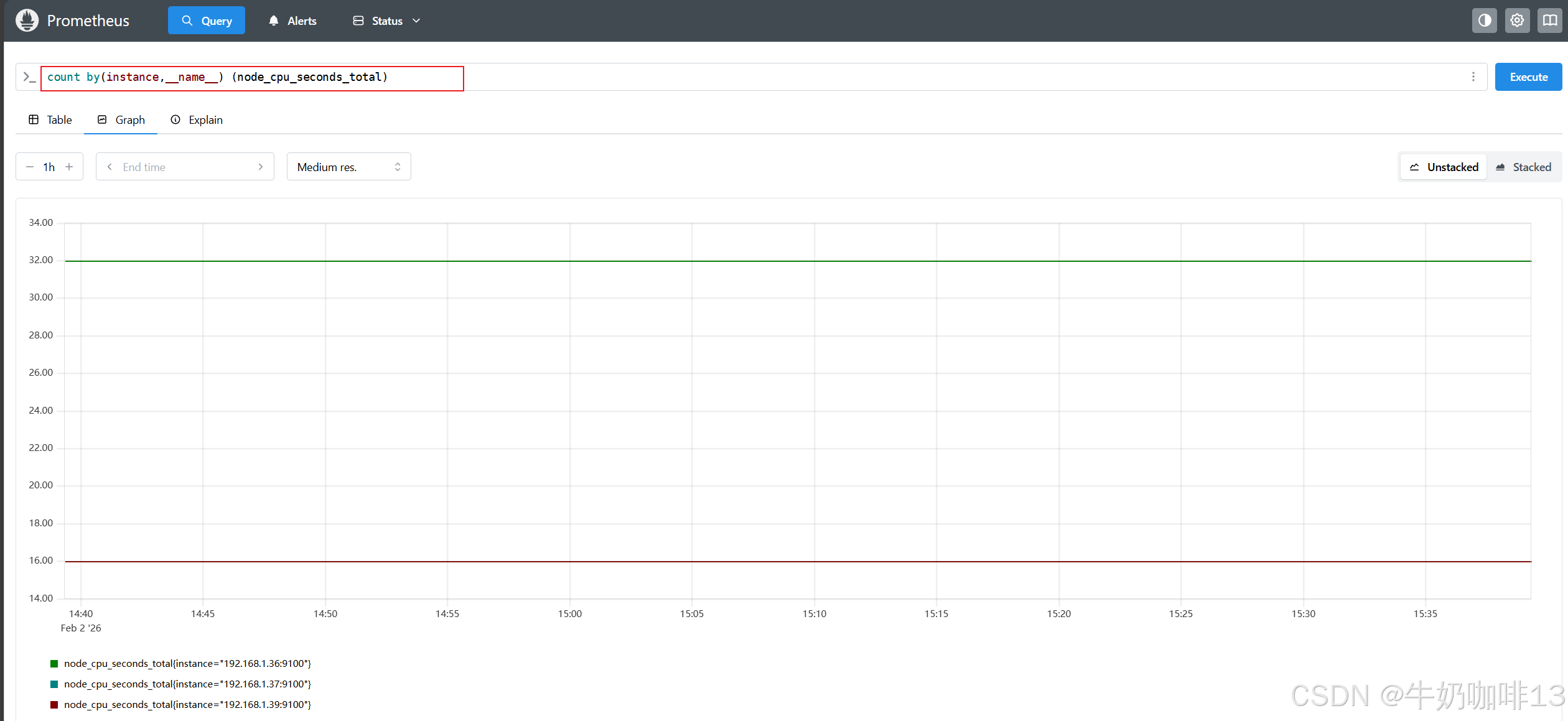
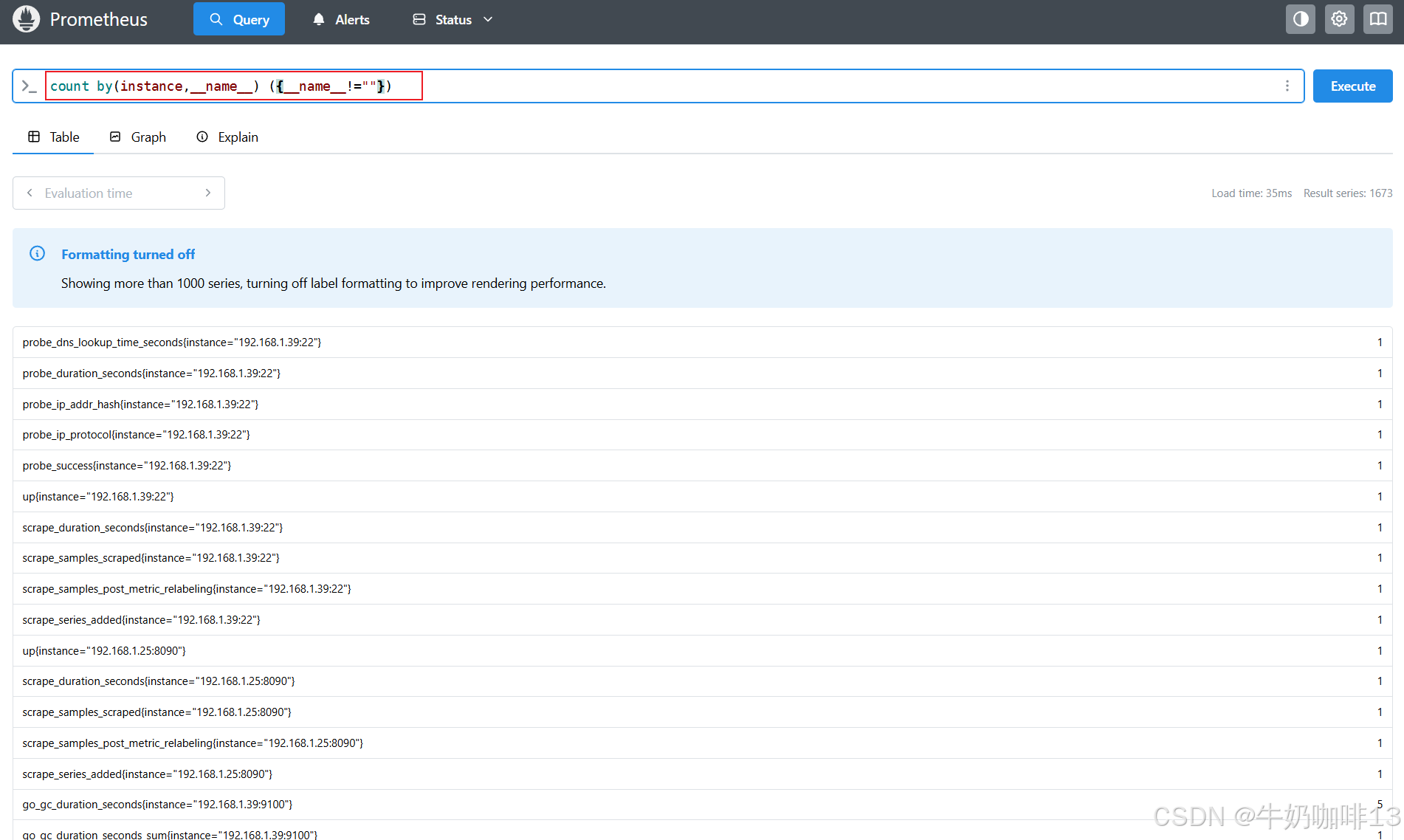
2.2、基于时间聚合
前面已经讲解了使用 sum()、avg() 和相关的聚合运算符从标签维度进行聚合;但是有时候我们可能想在每个序列中按时间进行聚合(如:使尖锐的曲线更平滑,或深入了解一个序列在一段时间内的最大值)。
|--------|----------------------------------------------|--------------------|
| 为了基于时间来计算这些聚合,PromQL 提供了一些与标签聚合运算符类似的函数,但是在这些函数名前面附加了 _over_time() |||
| 序号 | 时间聚合函数 | 说明 |
| 1 | avg_over_time(range-vector) | 区间向量内每个指标的平均值 |
| 2 | min_over_time(range-vector) | 区间向量内每个指标的最小值 |
| 3 | max_over_time(range-vector) | 区间向量内每个指标的最大值 |
| 4 | sum_over_time(range-vector) | 区间向量内每个指标的求和 |
| 5 | count_over_time(range-vector) | 区间向量内每个指标的样本数据个数 |
| 6 | quantile_over_time(scalar, range-vector) | 区间向量内每个指标的样本数据值分位数 |
| 7 | stddev_over_time(range-vector) | 区间向量内每个指标的总体标准差。 |
| 8 | stdvar_over_time(range-vector) | 区间向量内每个指标的总体标准方差 |
[基于时间聚合的函数]
bash
#基于标签聚合示例
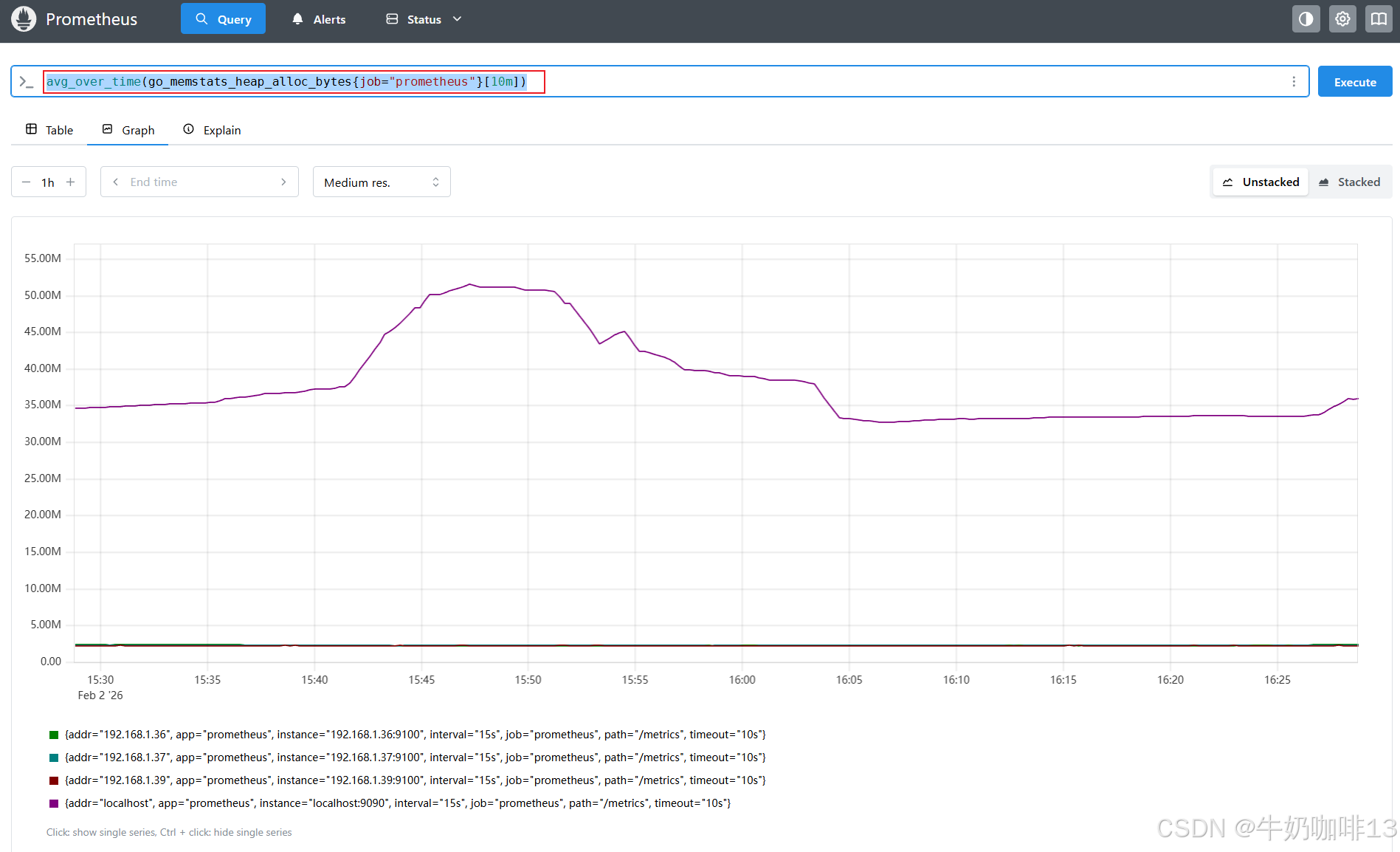
#示例1-查看指标【go_memstats_heap_alloc_bytes】的原始数量
#会产生一些尖锐的峰值图,此时,可以通过对图中的每一个点来计算 10 分钟内的go_memstats_heap_alloc_bytes 的值进行平均,来使图形更加平滑
go_memstats_heap_alloc_bytes{job="prometheus"}
avg_over_time(go_memstats_heap_alloc_bytes{job="prometheus"}[10m])
#示例2-计算物理内存使用率,但node-exporter并不直接进行计算,计算的公式为:(总内存 -(空闲内存 + 缓冲缓存 + 页面缓存))/ 总内存 * 100
(1-((avg_over_time(node_memory_MemFree_bytes[1h])+avg_over_time(node_memory_Buffers_bytes[1h])+avg_over_time(node_memory_Cached_bytes[1h]))/avg_over_time(node_memory_MemTotal_bytes[1h])))*100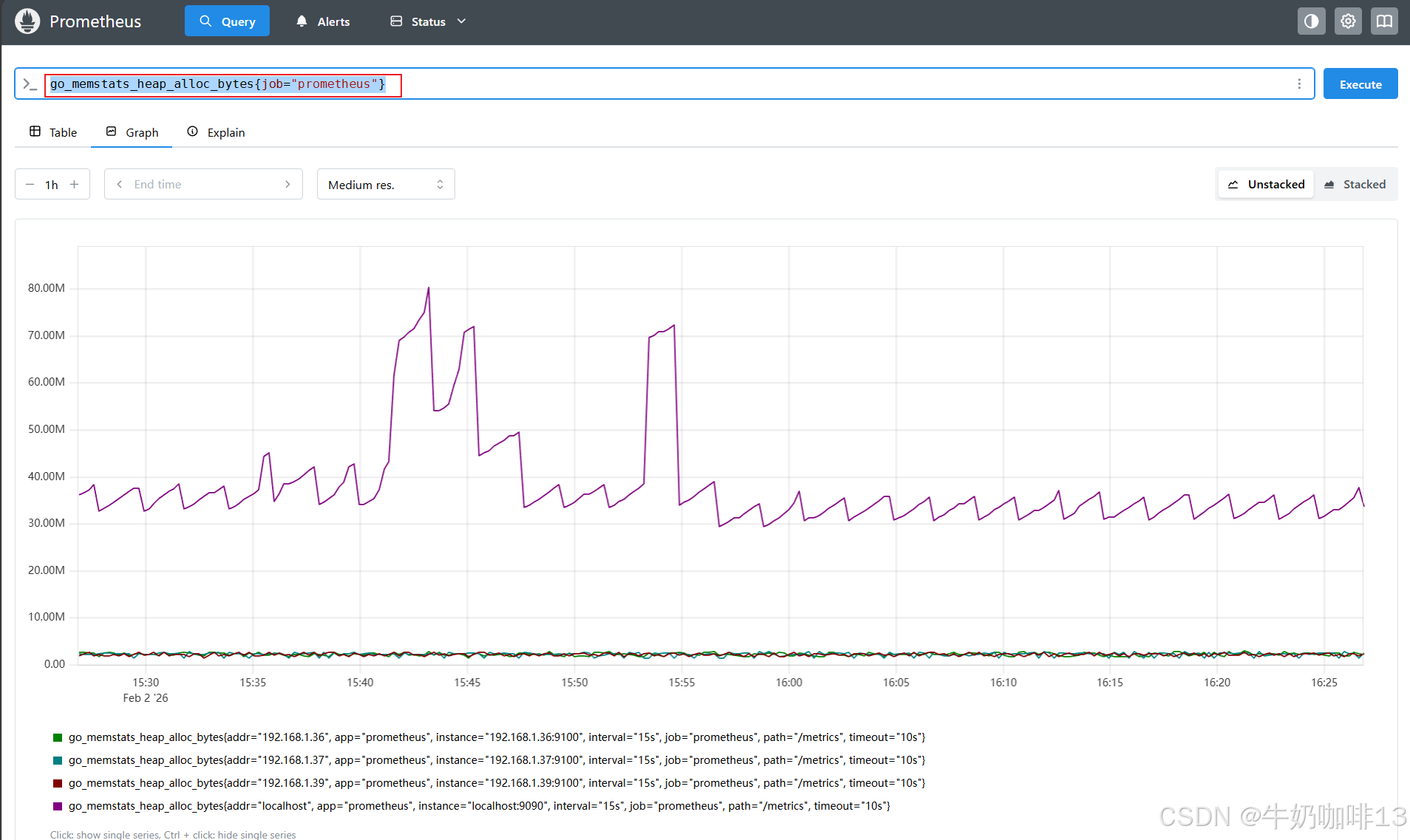
2.3、子查询
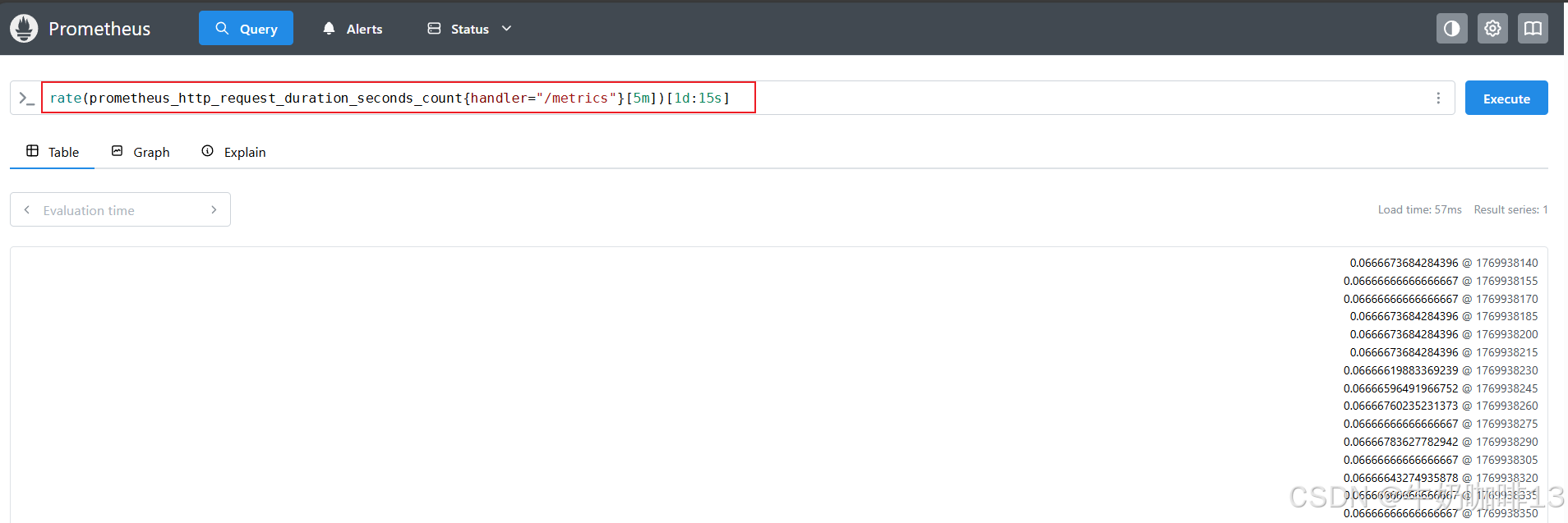
如果现在想使用如 max_over_time() 函数来找出过去一天中某个服务的最大请求率应该怎么办呢?要计算一天中最大的请求率,就是要将rate函数计算出来的值进行二次计算,这就是子查询,子查询下的时间范围需要冒号后添加了一个额外的步长参数:[<duration>:<resolution>]
bash
#子查询示例
#找出过去一天中某个服务在指定时间范围内的最大请求率
rate(prometheus_http_request_duration_seconds_count{handler="/metrics"}[5m])
rate(prometheus_http_request_duration_seconds_count{handler="/metrics"}[5m])[1d:15s]
#在1天内范围内执行内部查询,步长为15秒。步长可以省略,但冒号仍然是需要的,在省略步长的情况下,Prometheus 会使用配置的全局 `evaluation_interval` 参数来设置步长值。
max_over_time(rate(prometheus_http_request_duration_seconds_count{handler="/metrics"}[5m])[1d:15s])
#子查询还允许添加一个偏移修饰符 offset 来对内部查询进行时间偏移
max_over_time(rate(prometheus_http_request_duration_seconds_count{handler="/metrics"}[5m] offset 1h)[1d:15s])


三、二元操作符
Prometheus 的查询语言支持基本的【逻辑运算】和【算术运算】。
3.1、二元算术运算符
|--------|-------------|--------|
| 序号 | 二元算术运算符 | 说明 |
| 1 | + | 加法 |
| 2 | - | 减法 |
| 3 | * | 乘法 |
| 4 | / | 除法 |
| 5 | % | 模 |
| 6 | ^ | 幂等 |
[prometheus支持的二元算术运算符]
bash
#prometheus的Query界面可以直接当做计算器(即两个标量之间的计算、向量与标量之间的计算、向量与向量之间的计算)
#示例1-标量运算(返回的是一个值为 69 的标量(scalar)类型的数据)
(6+9/3)*3^2-12
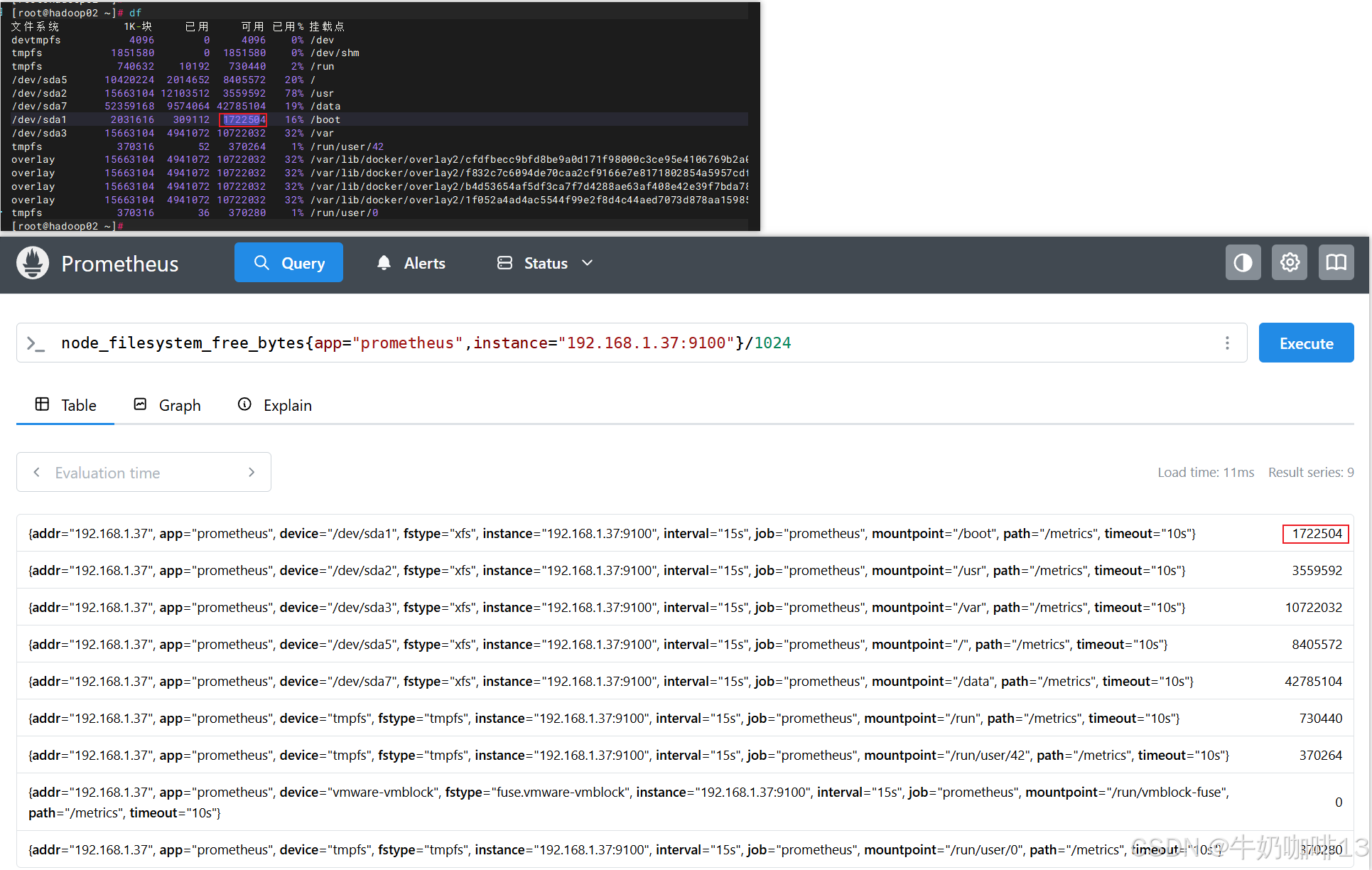
#示例2-向量与标量计算(如:可以将文件系统可用空间字节数除以 1024 来转换为kb)
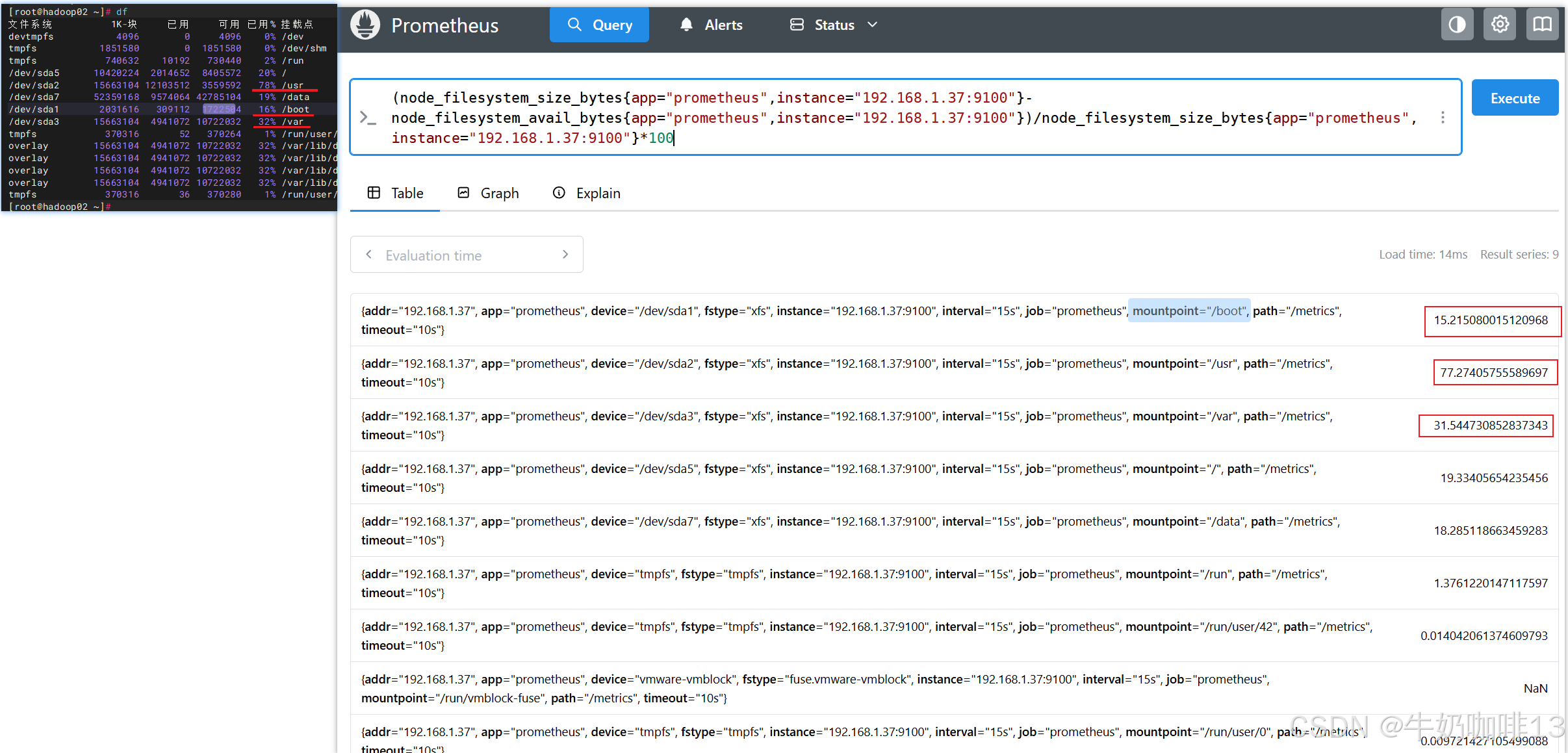
node_filesystem_avail_bytes{app="prometheus",instance="192.168.1.37:9100"}/1024
node_filesystem_free_bytes{app="prometheus",instance="192.168.1.37:9100"}/1024
#示例3-向量与向量计算(如:(文件系统总空间-文件系统可用空间)/文件系统总空间=文件系统空间使用率)
(node_filesystem_size_bytes{app="prometheus",instance="192.168.1.37:9100"}-node_filesystem_avail_bytes{app="prometheus",instance="192.168.1.37:9100"})/node_filesystem_size_bytes{app="prometheus",instance="192.168.1.37:9100"}*100
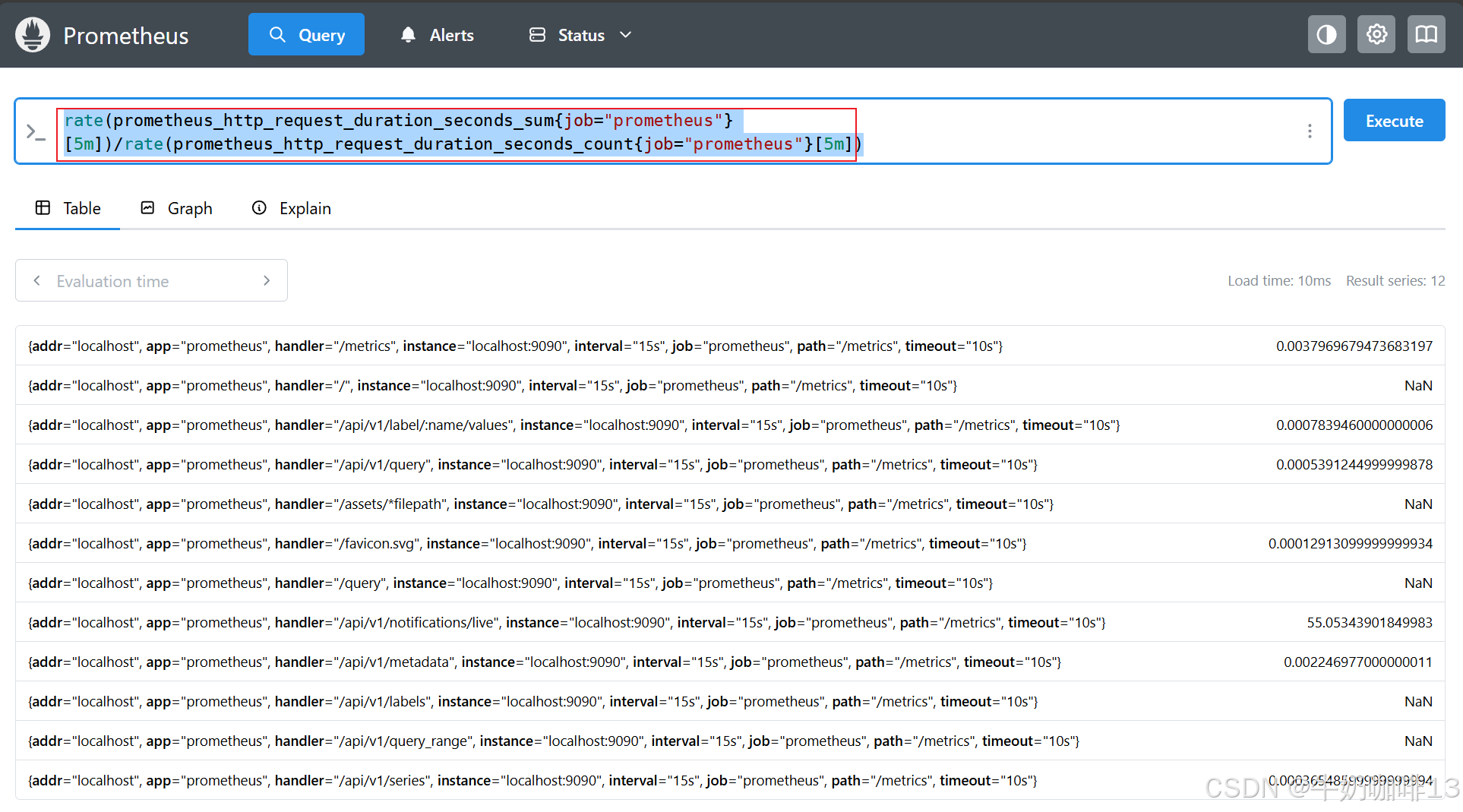
#示例3-向量与向量的计算(如:Prometheus自身处理HTTP请求的耗时与Prometheus自身处理HTTP请求的总数量)
#PromQL 会通过相同的标签集自动匹配操作符左边和右边的元素,并将二元运算应用到它们身上。由于这两个指标的标签集合都是一致的,因此可以得到相同标签集的平均请求延迟结果
rate(prometheus_http_request_duration_seconds_sum{job="prometheus"}[5m])/rate(prometheus_http_request_duration_seconds_count{job="prometheus"}[5m])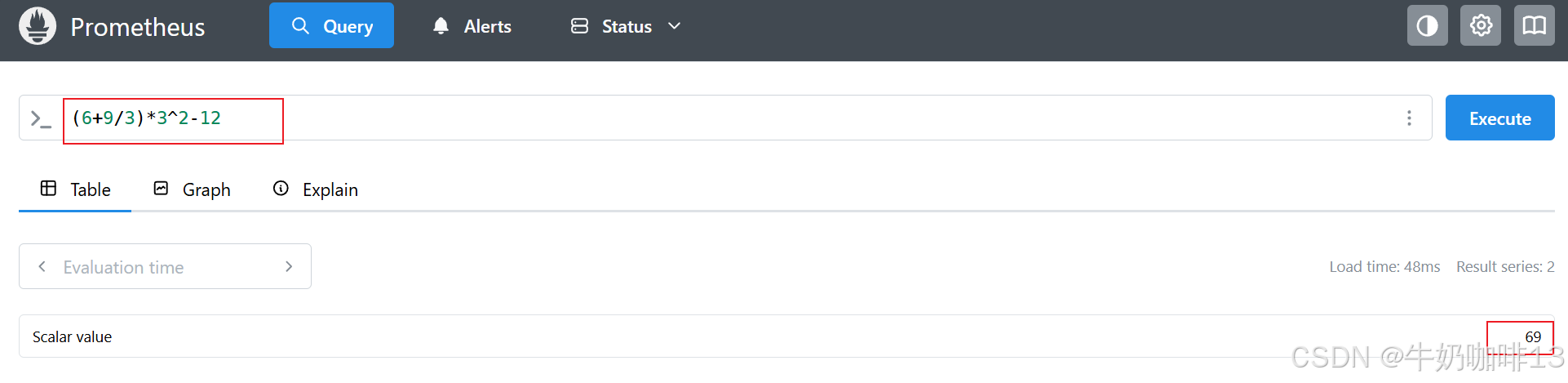
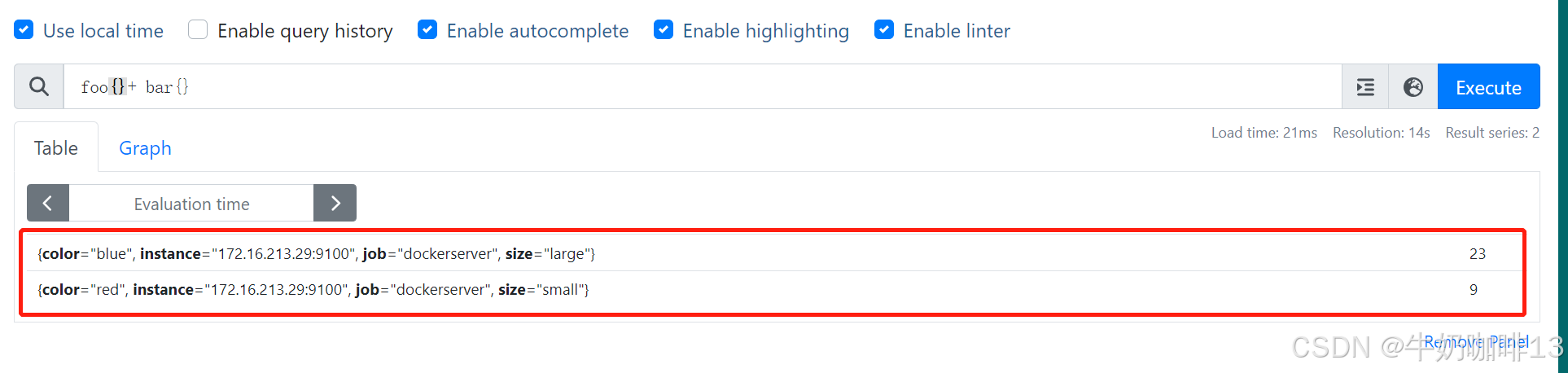
3.2、向量匹配
一对一向量匹配也有两种情况,就是是否按照所有标签匹配进行计算:下图中两个指标 foo 和 bar,分别生成了 3 个序列:当执行查询语句 foo{} + bar{} 的时候,对于向量左边的每一个元素,操作符都会尝试在右边里面找到一个匹配的元素,匹配是通过比较所有的标签来完成的,没有匹配的元素会被丢弃,我们可以看到其中的 foo{color="green", size="medium"} 与 bar{color="green", size="xlarge"} 两个序列的标签是不匹配的,其余两个序列标签匹配,所以计算结果会抛弃掉不匹配的序列,得到的结果为其余序列的值相加。

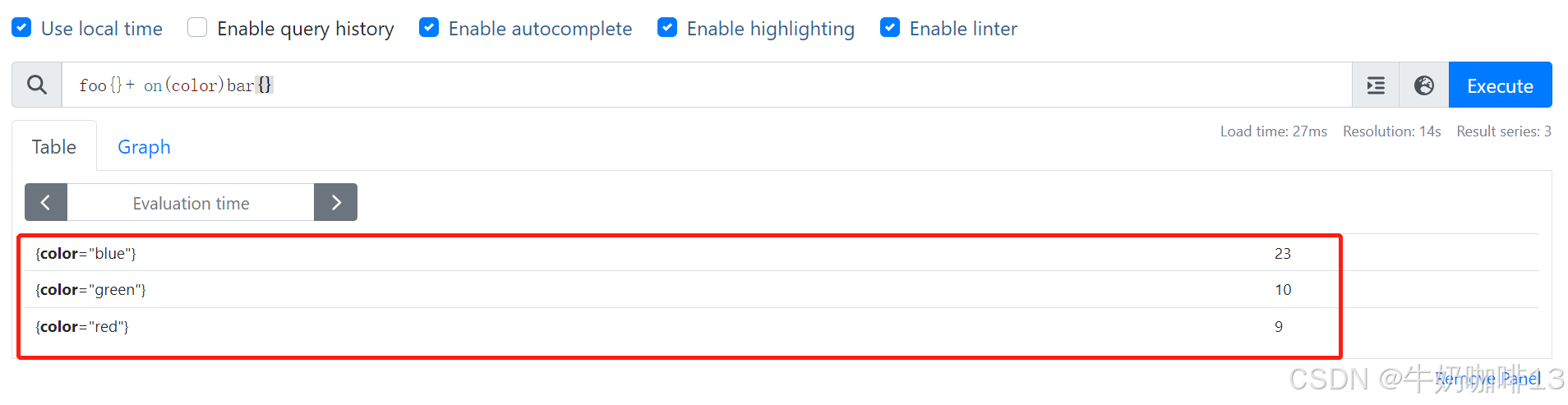
上面例子中其中不匹配的标签主要是因为第二个 size 标签不一致造成的,那么如果在计算的时候忽略掉这个标签可以吗? 当然可以。在进行计算的时候可以使用 on 或者 ignoring 修饰符来指定用于匹配的标签进行计算,由于示例中两边的标签都具有 color 标签,所以在进行计算的时候我们可以基于该标签(on (color))或者忽略其他的标签(ignoring (size))进行计算,这样得到的结果就是 所有匹配的标签序列相加的结果。如下图: 如下图所示:

上面讲解的【一对一的向量计算】是最直接的方式,在多数情况下,on 或者 ignoring 修饰符有助于查询返回合理的结果,但通常情况用于计算的两个向量之间并不是一对一的关系,更多的是一对多或者多对一的关系,对于这种场景我们就不能简单使用上面的方式进行处理了。
【多对一】和【一对多】两种匹配模式指的是: 一侧的每一个向量元素可以与另一侧的多个元素匹配的情况,在这种情况下,必须使用 group 修饰符:【group_left】 或者 【group_right】来确定哪一个向量具有更高的基数(充当多的角色)。多对一和一对多两种模式一定是出现在操作符两侧表达式返回的向量标签不一致的情况,因此同样需要使用 ignoring 和 on 修饰符来排除或者限定匹配的标签列表。
假定有个指标node_cpu_num可以返回每个实例的 CPU 核数,只有 instance 和 job 这两个标签维度。
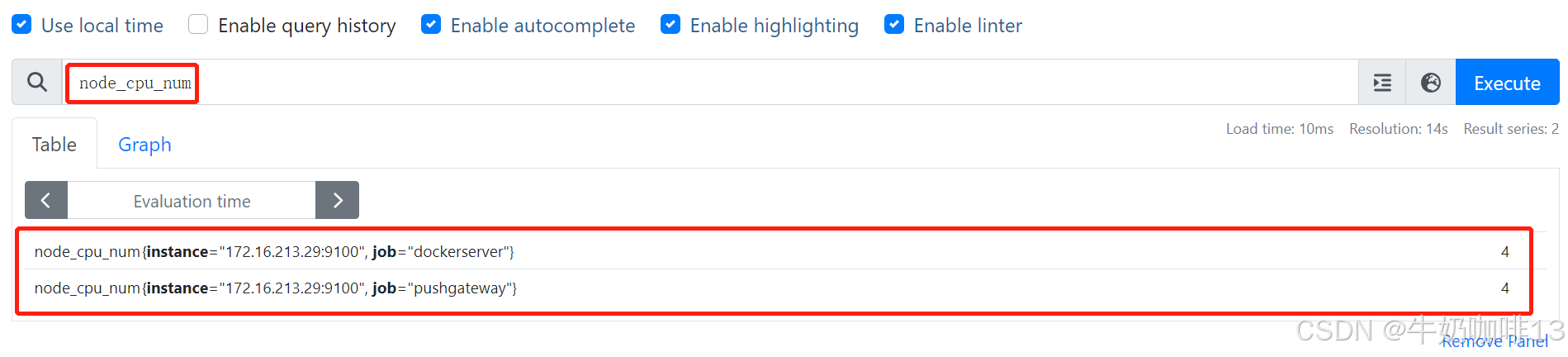
而另一个指标node_cpu_seconds_total则多了一个 mode 标签的维度、一个cpu标签维度。而mode模式又划分了idle、system、user等多个模式下CPU的使用情况,如下图:
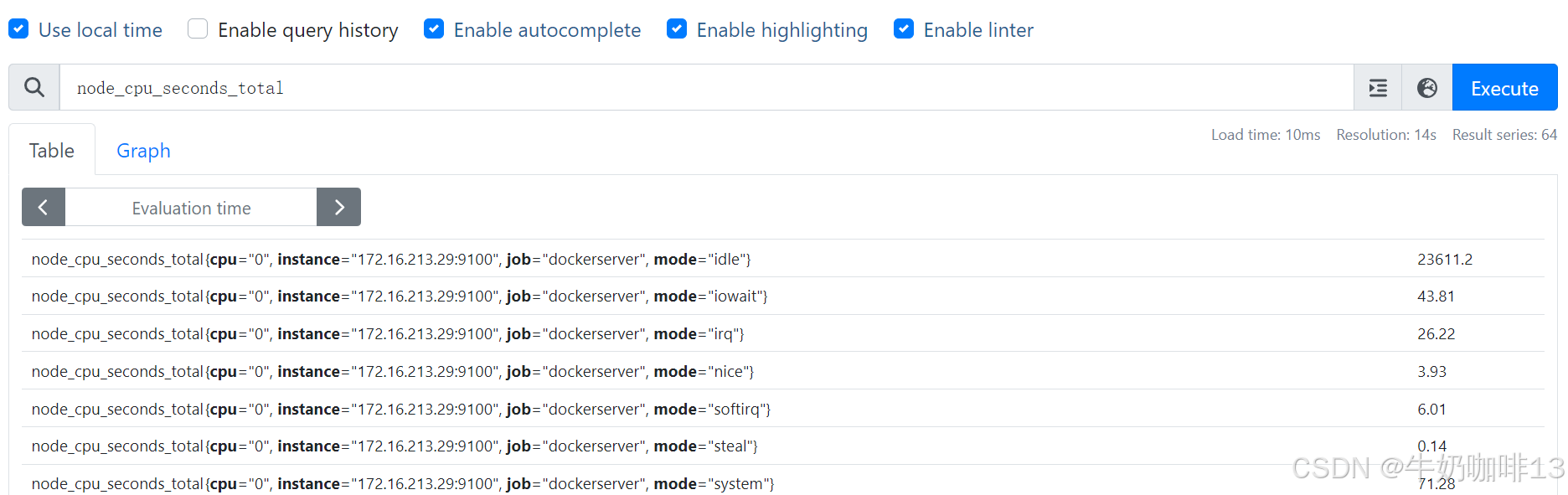
而现在的需求是:统计每个模式下CPU的平均使用量,也就是每个模式下的cpu使用率除以CPU核数,此时,我们可以使用 group_left(表示左边的向量具有更高的基数)修饰符来实现。同时,我们还需要通过 on() 修饰符明确将所考虑的标签集减少到需要匹配的标签列表:
bash
rate(node_cpu_seconds_total{job="dockerserver"}[5m]) / on(job, instance) group_left node_cpu_num{job="dockerserver"}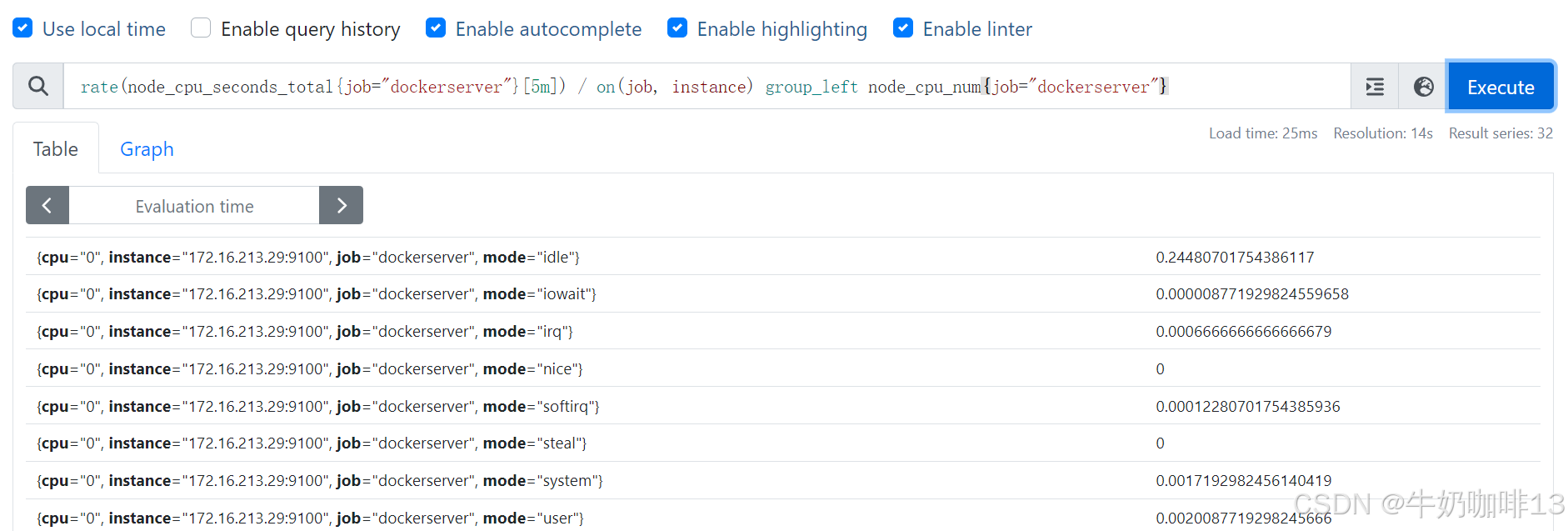
除了 on() 之外,还可以使用相反的 ignoring() 修饰符,可以用来将一些标签维度从二元运算操作匹配中忽略掉,如果在操作符的右侧有额外的维度,则应该使用 group_right(表示右边的向量具有更高的基数)修饰符。比如上面的查询语句同样可以用 ignoring 关键字来完成:
bash
rate(node_cpu_seconds_total{job="dockerserver"}[5m]) / ignoring(cpu,mode) group_left node_cpu_num{job="dockerserver"}得到的结果和前面用 on() 查询的结果是一致的。
bash
#计算过去 5 分钟内每个实例的 user 和 system 的模式(node_cpu_seconds_total指标)下 CPU 使用量平均值总和。
sum by(job,instance) (rate(node_cpu_seconds_total{mode=~"system|user"}[5m]))
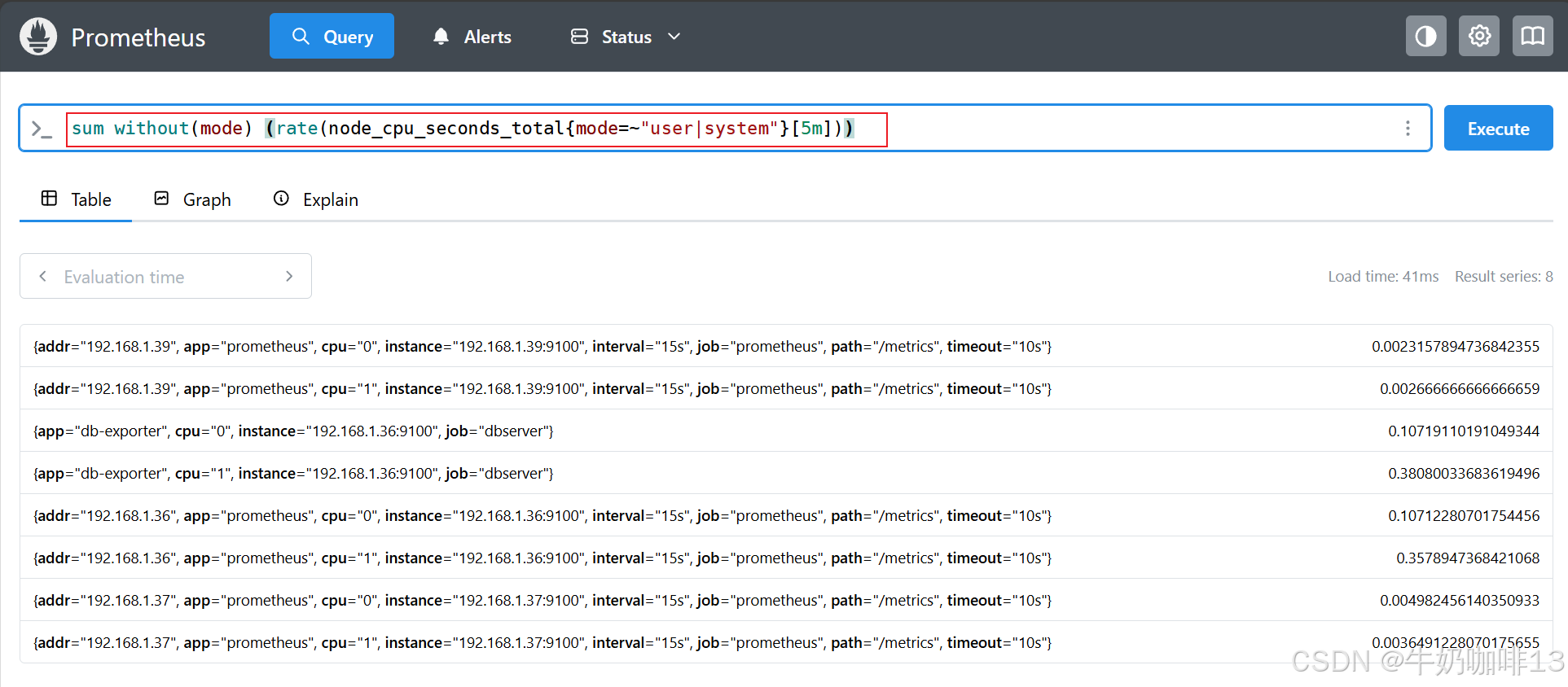
sum without(mode) (rate(node_cpu_seconds_total{mode=~"user|system"}[5m]))
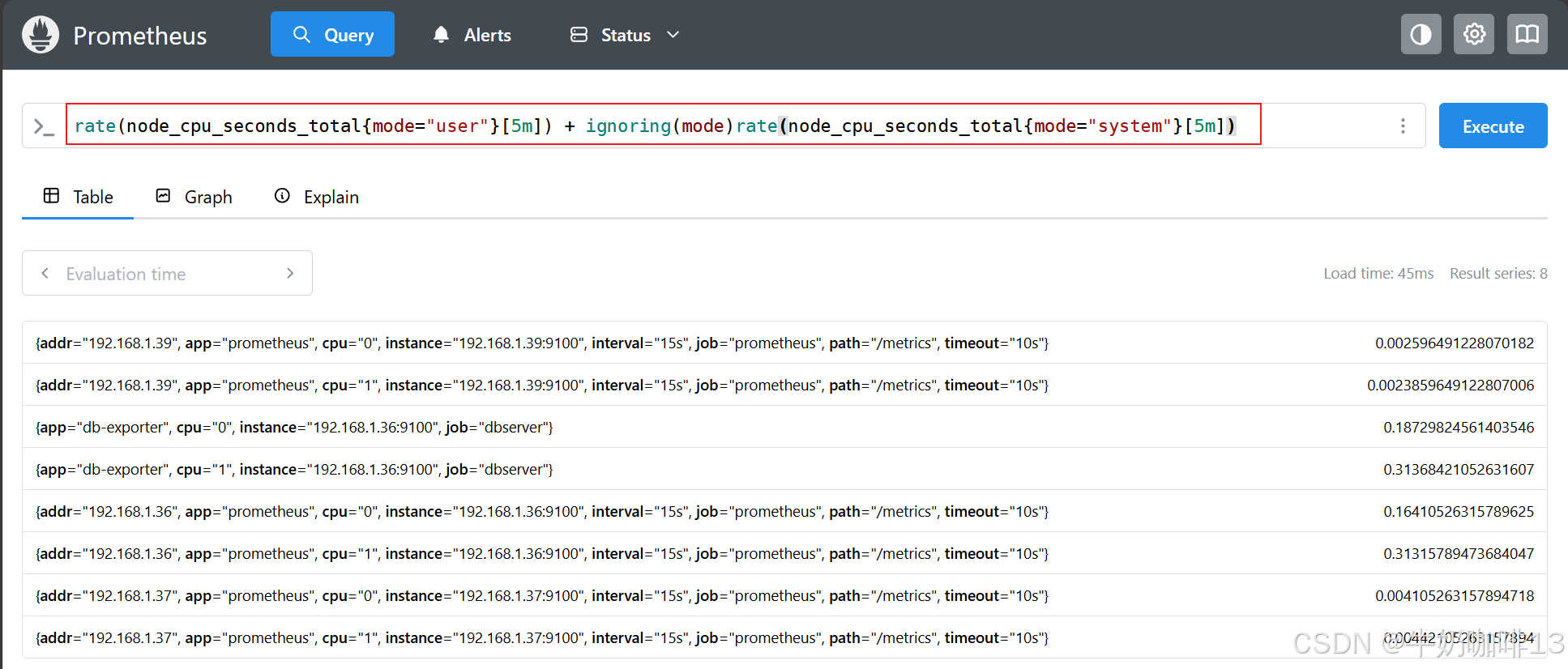
rate(node_cpu_seconds_total{mode="user"}[5m]) + ignoring(mode)rate(node_cpu_seconds_total{mode="system"}[5m])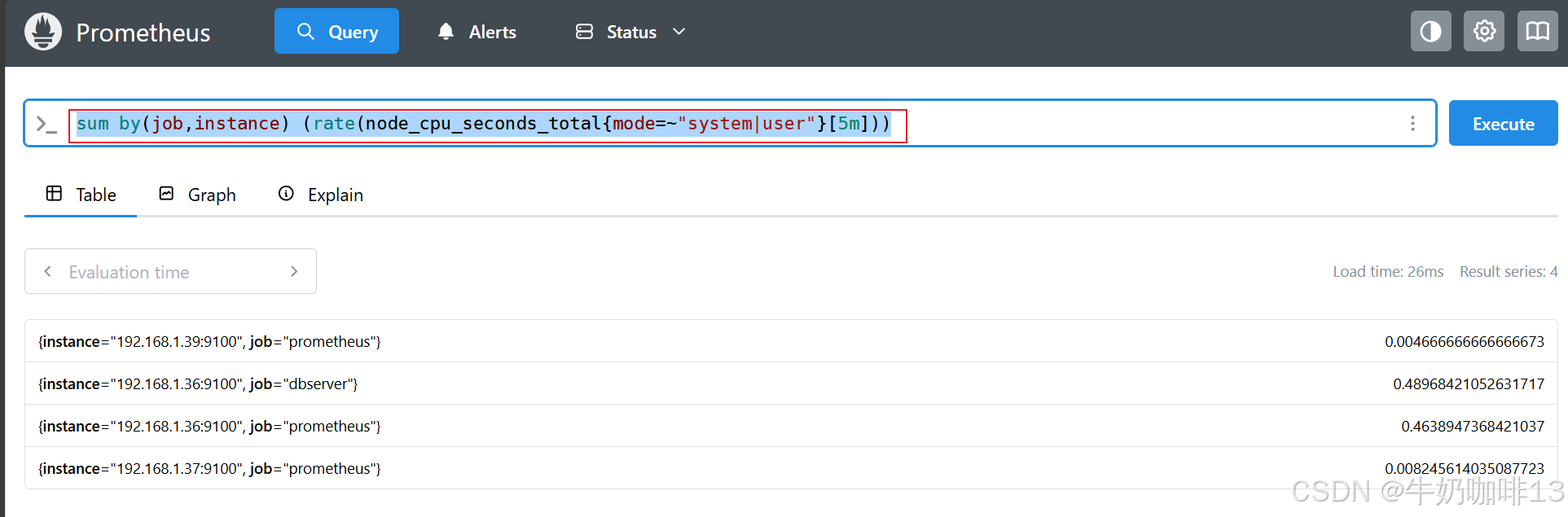
3.3、二元过滤运算符
PromQL 通过提供一组过滤的二元运算符(>、<、== 、<=、>=等),允许根据其样本值过滤一组序列,这种过滤最常见的场景就是在报警规则中使用的阈值。
bash
#二元过滤运算符示例
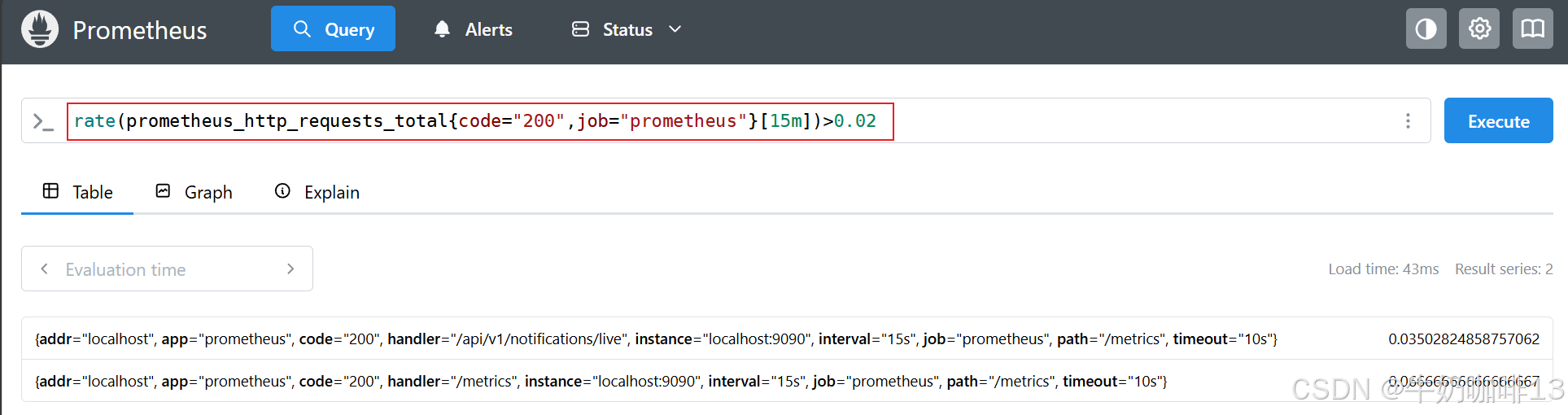
#示例1-查找在过去 15 分钟内的 code="500" 错误率大于 20% 的所有 HTTP 路径,在 rate 表达式后面添加一个 >0.2 的过滤运算符:
rate(prometheus_http_requests_total{code="500",job="prometheus"}[15m]) > 0.2
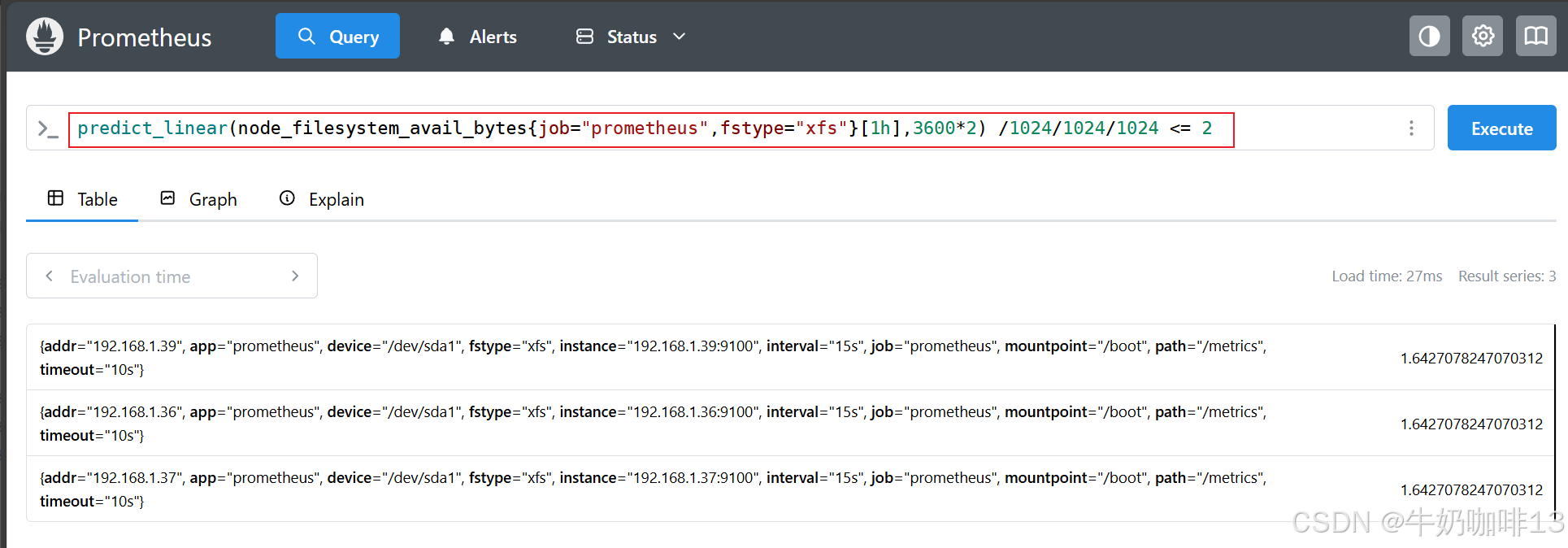
#示例2-预测在2个小时内的磁盘剩余量,是否小于2GB(注意:【predict_linear()】预测函数里面指标中括号里面的是预测使用样本在时间范围内的数据,后面的2*3600秒(2个小时)是需要预测的时间)
predict_linear(node_filesystem_avail_bytes{job="prometheus",fstype=~"xfs|ext4"}[1h],3600*2) /1024/1024/1024 <= 2
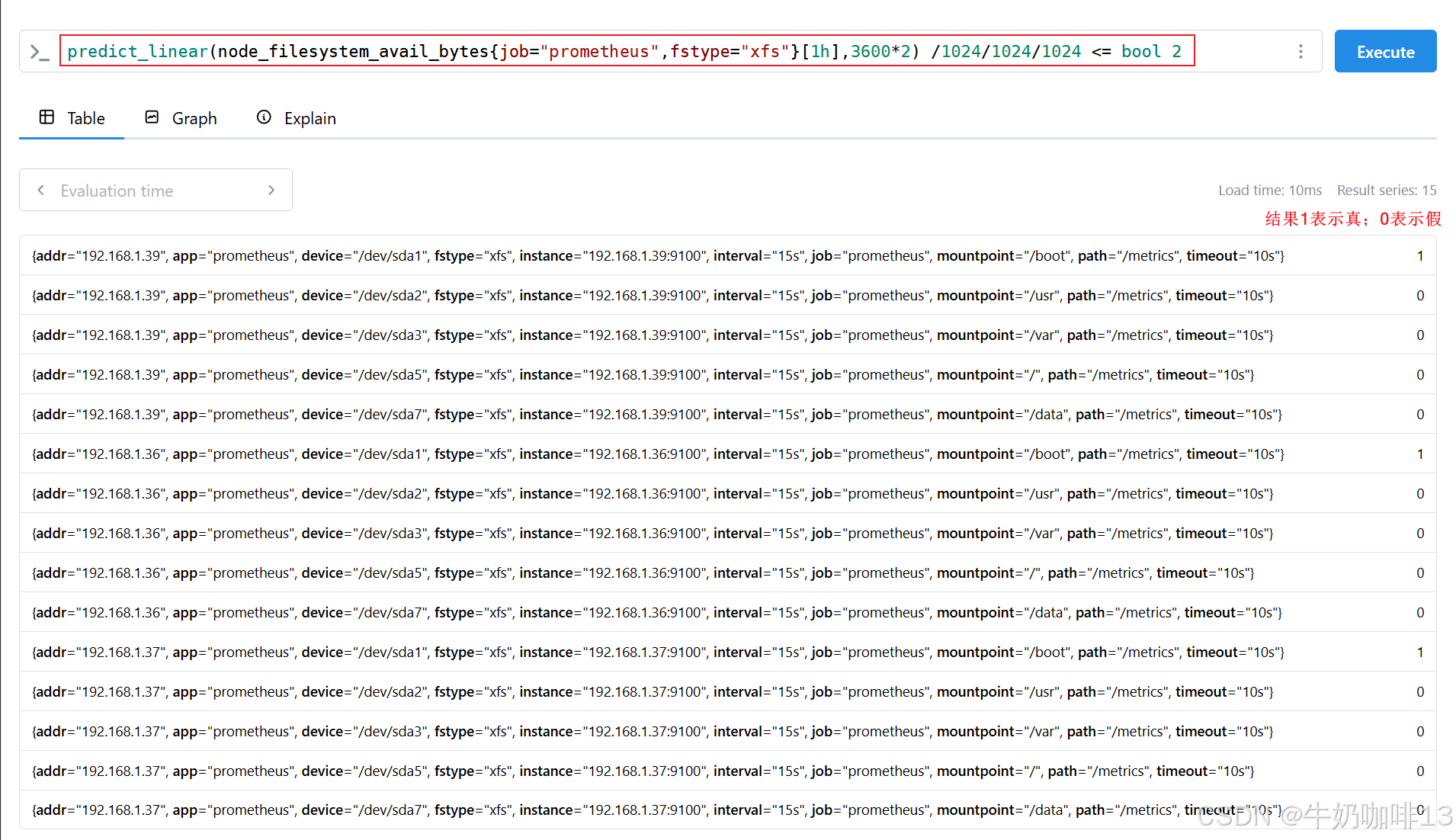
#示例2.1-有时可能想知道比较运算符的结果而不是输出值。要实现这一点,我们可以向运算符添加一个 bool 修饰符来保留所有的序列,这样,输出样本值就变成了设置为 1(比较为真)或 0(比较为假)
predict_linear(node_filesystem_avail_bytes{job="prometheus",fstype=~"xfs|ext4"}[1h],3600*2) /1024/1024/1024 <= bool 2
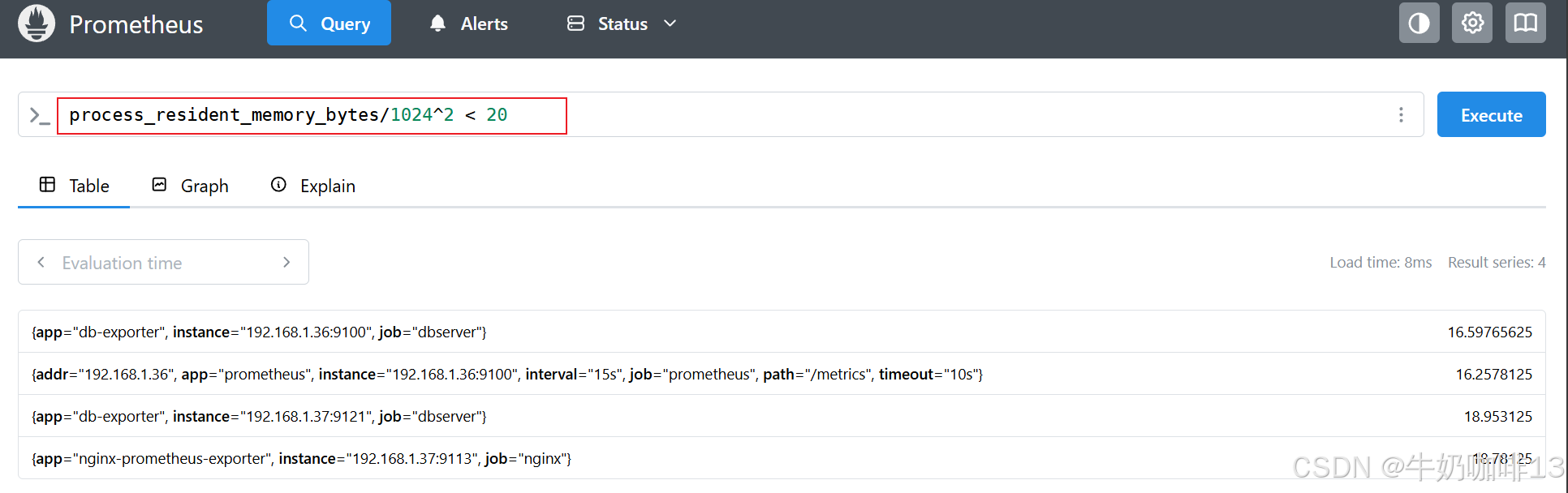
#示例3-查询显示使用少于 20MB 内存的目标(process_resident_memory_bytes指标)
process_resident_memory_bytes/1024^2 < 20
#示例4-查询显示 Prometheus 服务内部所有在过去 5 分钟内没有收到任何查询的 HTTP 请求
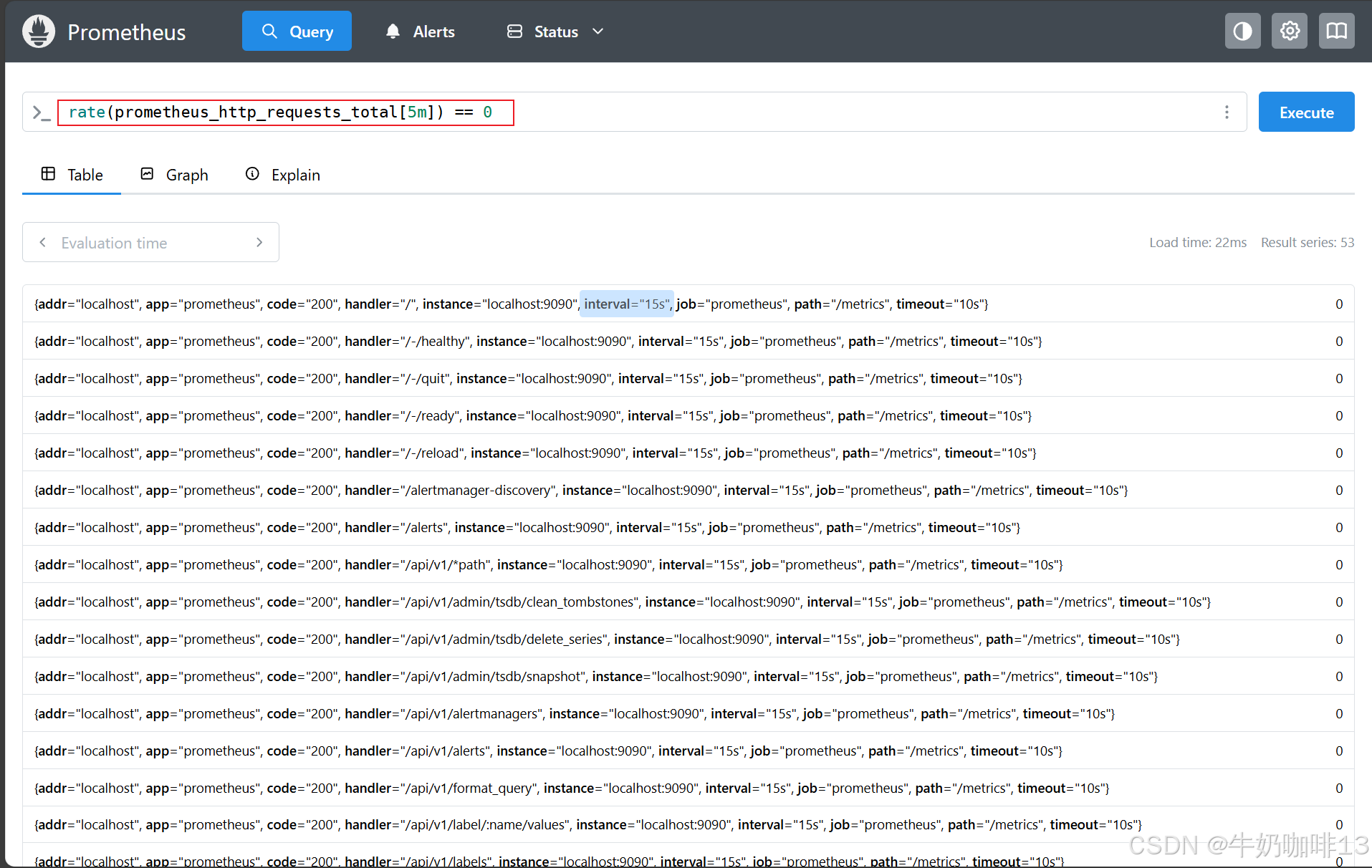
rate(prometheus_http_requests_total[5m]) == 0