目录
- 一、什么是Seata
- 二、什么是分布式事务
- 三、项目搭建
- 四、分布式事务问题的理论模型
-
- [4.1 CAP理论](#4.1 CAP理论)
- [4.2 BASE理论](#4.2 BASE理论)
- [4.3 X/Open 分布式事务模型](#4.3 X/Open 分布式事务模型)
- [4.4 两阶段提交](#4.4 两阶段提交)
- [4.5 三阶段提交](#4.5 三阶段提交)
- [4.6 TCC事务](#4.6 TCC事务)
- 五、使用seata
-
- [5.1 下载与布署](#5.1 下载与布署)
-
- [5.1.1 修改配置](#5.1.1 修改配置)
- [5.1.2 修改Seata存储模式](#5.1.2 修改Seata存储模式)
-
- [5.1.2.1 初始化数据库](#5.1.2.1 初始化数据库)
- [5.1.2.2 修改store.mode](#5.1.2.2 修改store.mode)
- [5.1.3 启动](#5.1.3 启动)
- [5.2 微服务集成seata](#5.2 微服务集成seata)
-
- [5.2.1 引⼊依赖](#5.2.1 引⼊依赖)
- [5.2.2 修改配置⽂件](#5.2.2 修改配置⽂件)
- 六、Seata事务模式
-
- [6.1 XA模式](#6.1 XA模式)
-
- [6.1.1 介绍](#6.1.1 介绍)
- [6.1.2 配置与使⽤](#6.1.2 配置与使⽤)
- [6.1.3 优缺点](#6.1.3 优缺点)
- [6.2 AT 模式](#6.2 AT 模式)
-
- [6.2.1 介绍](#6.2.1 介绍)
- [6.2.2 读写隔离](#6.2.2 读写隔离)
-
- [6.2.2.1 写隔离](#6.2.2.1 写隔离)
- [6.2.2.2 读隔离](#6.2.2.2 读隔离)
- [6.2.3 ⼯作机制](#6.2.3 ⼯作机制)
- [6.2.4 配置与使⽤](#6.2.4 配置与使⽤)
- [6.3 TCC模式](#6.3 TCC模式)
-
- [6.3.1 介绍](#6.3.1 介绍)
- [6.3.2 TCC 设计](#6.3.2 TCC 设计)
-
- [6.3.2.1 业务操作分析](#6.3.2.1 业务操作分析)
- [6.3.2.2 并发控制](#6.3.2.2 并发控制)
- [6.3.2.3 允许空回滚](#6.3.2.3 允许空回滚)
- [6.3.2.4 防悬挂控制](#6.3.2.4 防悬挂控制)
- [6.3.2.5 幂等控制](#6.3.2.5 幂等控制)
- [6.3.2.6 Seata解决⽅法](#6.3.2.6 Seata解决⽅法)
- [6.3.3 TCC实现](#6.3.3 TCC实现)
-
- [6.3.3.1 创建事务控制表](#6.3.3.1 创建事务控制表)
- [6.3.3.2 添加冻结字段](#6.3.3.2 添加冻结字段)
- [6.3.3.3 修改相应的实体类](#6.3.3.3 修改相应的实体类)
- [6.3.3.4 TCC接⼝定义&实现](#6.3.3.4 TCC接⼝定义&实现)
- [6.3.3.5 TCC核⼼注解及参数描述](#6.3.3.5 TCC核⼼注解及参数描述)
- [6.4 Saga模式](#6.4 Saga模式)
-
- [6.4.1 介绍](#6.4.1 介绍)
- [6.4.2 适⽤场景及优缺点](#6.4.2 适⽤场景及优缺点)
- [6.5 四种模式对⽐](#6.5 四种模式对⽐)

一、什么是Seata
Seata 是⼀款开源的分布式事务解决⽅案,致⼒于提供⾼性能和简单易⽤的分布式事务服务。Seata 将为⽤⼾提供了 AT、TCC、SAGA 和 XA 事务模式,为⽤⼾打造⼀站式的分布式解决⽅案。
官方介绍:https://seata.apache.org/zh-cn/docs/overview/what-is-seata
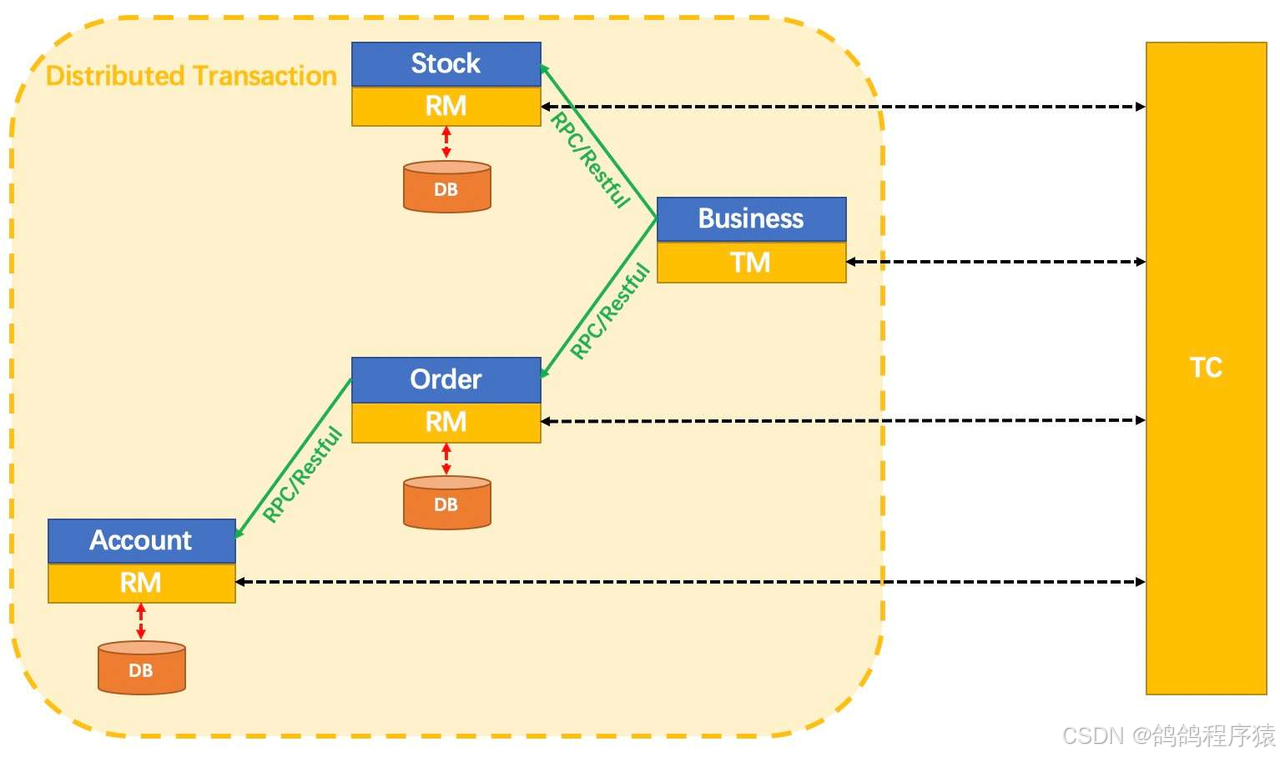
二、什么是分布式事务
分布式事务是指在分布式系统中,为了保证数据的⼀致性和完整性,对多个节点上的数据进⾏操作的事务。当⼀个事务涉及到多个不同的数据库、服务或应⽤实例时,就构成了分布式事务。
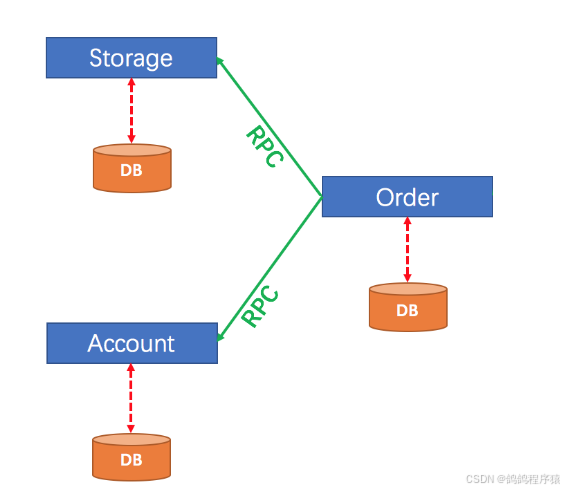
三、项目搭建
我们搭建一个简单的下图结构的项目来了解Seata
sql语句:
sql
CREATE DATABASE IF NOT EXISTS seata_test;
use seata_test;
DROP TABLE IF EXISTS `storage_tbl`;
CREATE TABLE `storage_tbl` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`commodity_code` varchar(255) DEFAULT NULL,
`count` int(11) DEFAULT 0,
PRIMARY KEY (`id`),
UNIQUE KEY (`commodity_code`),
CONSTRAINT `count_chk` CHECK (`count` >= 0)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
DROP TABLE IF EXISTS `order_tbl`;
CREATE TABLE `order_tbl` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` varchar(255) DEFAULT NULL,
`commodity_code` varchar(255) DEFAULT NULL,
`count` int(11) DEFAULT 0,
`money` int(11) DEFAULT 0,
PRIMARY KEY (`id`),
CONSTRAINT `count_chk_2` CHECK (`count` >= 0),
CONSTRAINT `money_chk` CHECK (`money` >= 0)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
DROP TABLE IF EXISTS `account_tbl`;
CREATE TABLE `account_tbl` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` varchar(255) DEFAULT NULL,
`money` int(11) DEFAULT 0,
PRIMARY KEY (`id`),
CONSTRAINT `money_chk_2` CHECK (`money` >= 0)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 数据
INSERT INTO `storage_tbl` VALUES (1, '2001', 160);
INSERT INTO `storage_tbl` VALUES (2, '2002', 1000);
INSERT INTO `storage_tbl` VALUES (3, '2003', 500);
INSERT INTO `storage_tbl` VALUES (4, '2004', 400);
INSERT INTO `storage_tbl` VALUES (5, '2005', 600);
INSERT INTO `account_tbl` VALUES (1, '1001', 800);
INSERT INTO `account_tbl` VALUES (2, '1002', 2000);
INSERT INTO `account_tbl` VALUES (3, '1003', 1400);
INSERT INTO `account_tbl` VALUES (4, '1004', 2800);
INSERT INTO `account_tbl` VALUES (5, '1005', 3000);
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) NOT NULL,
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
`ext` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;项目文件压缩包在:https://gitee.com/yj20040627/java-exercises/tree/master/
测试接口:
问题演⽰:
当库存充⾜,余额不⾜时,会发现余额扣减失败,但是库存和订单均不会回滚,这就是分布式事务问题。
创建订单:
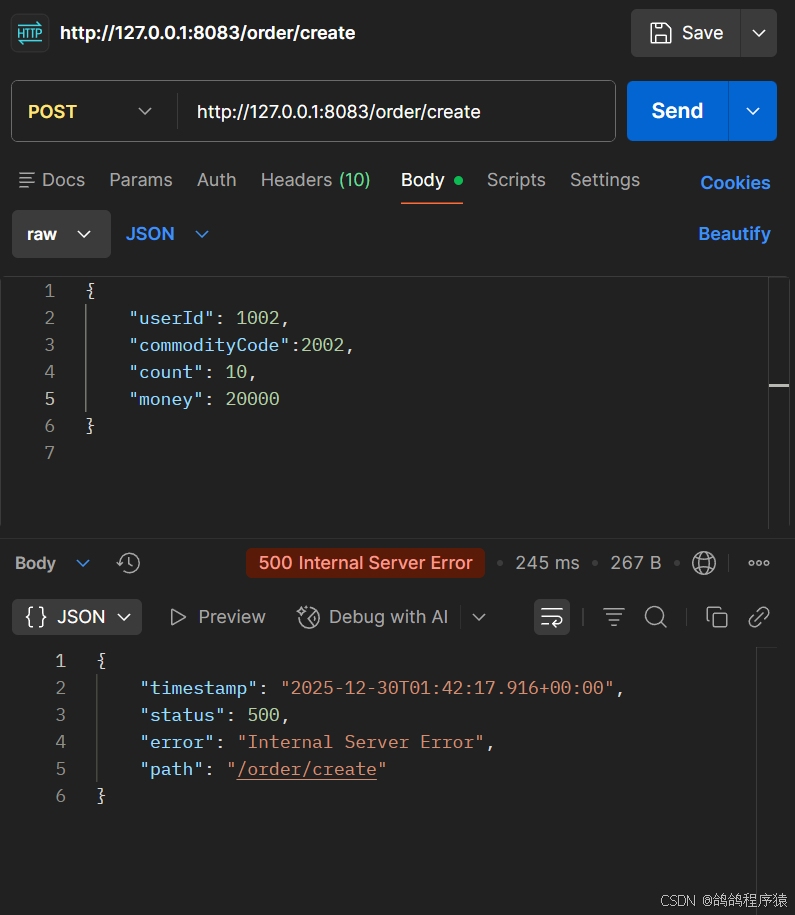
数据库变化:库存扣减成功,但是扣减余额时,因为余额不⾜,发⽣异常,库存也并没有得到回滚,这就是分布式事务问题。

四、分布式事务问题的理论模型
分布式事务问题也叫分布式数据⼀致性问题。就是如何在分布式场景中保证多个节点数据的⼀致性。
分布式事务产⽣的核⼼原因在于存储资源的分布性,⽐如多个数据库,或者MySQL和Redis两种不同存储设备的数据⼀致性等。
在实际应⽤中,我们应该尽可能地从设计层⾯去避免分布式事务的问题,因为任何⼀种解决⽅案都会增加系统的复杂度。
接下来介绍⼀下分布式事务问题的常⻅解决⽅案与相关的基础理论。
4.1 CAP理论
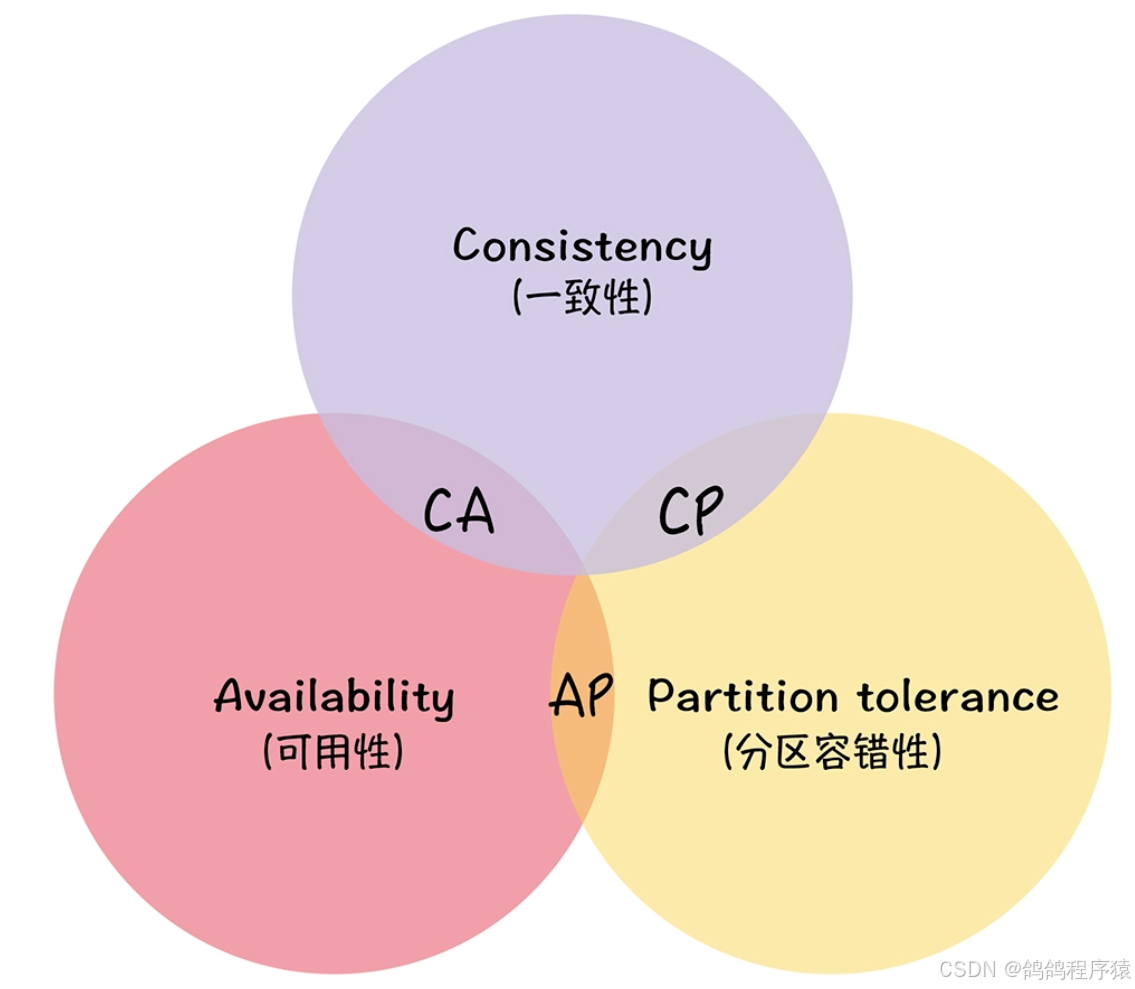
- ⼀致性(Consistency) CAP理论中的⼀致性,指的是强⼀致性。所有节点在同⼀时间具有相同的数据
- 可⽤性(Availability) 保证每个请求都有响应(响应结果可能不对)
- 分区容错性(Partition Tolerance) 当出现⽹络分区后,系统仍然能够对外提供服务
CAP 理论告诉我们:⼀个分布式系统不可能同时满⾜数据⼀致性,服务可⽤性和分区容错性这三个基本需求,最多只能同时满⾜其中的两个。
在分布式系统中,系统间的⽹络不能100%保证健康,服务⼜必须对外保证服务。因此Partition Tolerance不可避免。那就只能在C和A中选择⼀个。也就是CP或者AP架构。
4.2 BASE理论
BASE理论是由于CAP中⼀致性和可⽤性不可兼得⽽衍⽣出来的⼀种新的思想,BASE理论的核⼼思想是通过牺牲数据的强⼀致性来获得⾼可⽤性。
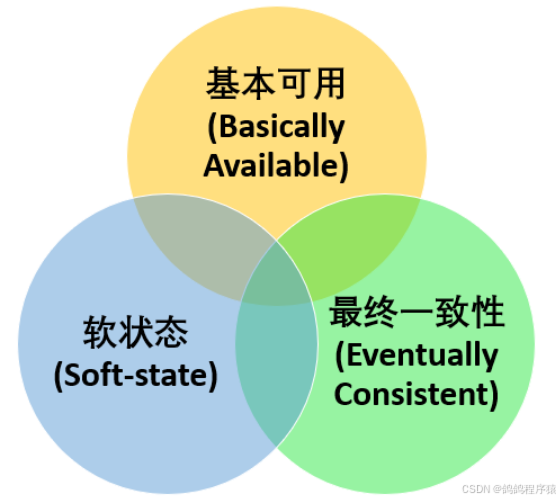
- Basically Available (基本可⽤):分布式系统在出现故障时,允许损失⼀部分功能的可⽤性,保证核⼼功能的可⽤
- Soft state (软状态):允许系统中的数据存在中间状态,也就是允许系统中不同节点的数据副本之间的同步存在延时,这个状态不影响系统的可⽤性
- Eventually Consistent (最终⼀致性):中间状态的数据在经过⼀段时间之后,会达到⼀个最终的数据⼀致性
BASE理论不要求数据的强⼀致,⽽是允许数据在⼀段时间内是不⼀致的,但是数据最终会在某个时间点实现⼀致。在互联⽹产品中,⼤部分都会采⽤BASE理论来实现数据的⼀致,因为产品的可⽤性对于⽤⼾来说更加重要。
与CAP理论的对⽐:
CAP理论指出:⼀个分布式系统不可能同时满⾜⼀致性 ( C ) 、可⽤性 ( A ) 和分区容错性 ( P )这三个特性。
BASE理论则是CAP理论的补充,通过放宽对⼀致性的严格要求,换取系统更⾼的可⽤性和灵活性。
BASE理论的核⼼思想是:如果不是必须的话,不推荐使⽤事务或强⼀致性,⿎励可⽤性和性能优先。允许在牺牲⼀定⼀致性的前提下获得更⾼的可⽤性。
4.3 X/Open 分布式事务模型
X/Open 是⼀个组织,X/Open DTP ( Distributed Transaction Process Reference Model) 是X/Open这个组织定义的⼀套分布式事务的标准。这个标准提出了使⽤两阶段提交(2PC,Two-Phase-Commit) 来保证分布式事务的完整性。
这套标准主要定义了实现分布式事务的规范和API,具体的实现则交给相应的⼚商来实现。
DTP 参考模型:https://pubs.opengroup.org/onlinepubs/9294999599/toc.pdf
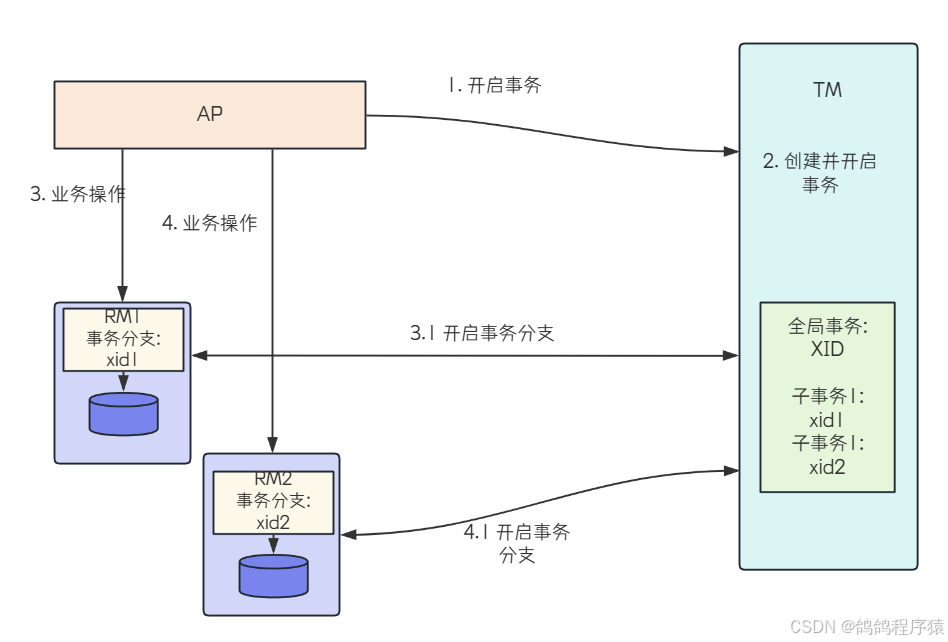
X/Open DTP参考模型包含三种⻆⾊:
- AP:Application,应⽤程序。
- RM:Resource Manager,资源管理器,⽐如数据库。应⽤程序可以通过资源管理器对相应的资源进⾏有效的控制,让应用程序可以操作数据库
- TM:Transaction Manager,事务管理器,⼀般指事务协调者,负责协调和管理各个⼦事务,可以理解为管理RM。
-
- 应⽤程序(AP) 通过资源管理器操作多个资源。
-
- 应⽤程序通过TM提供的接⼝,定义事务边界
-
- TM和RM交换事务信息(执⾏成功或失败)。
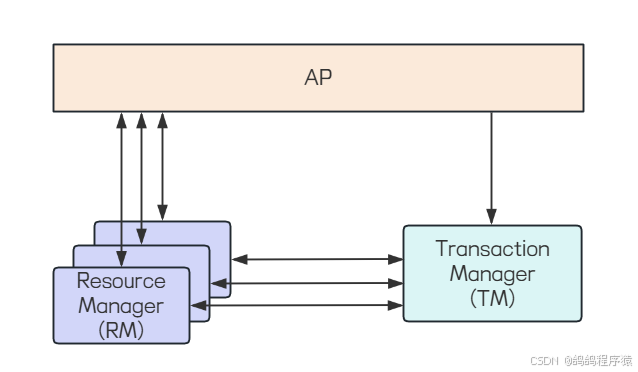
X/Open DTP模型的执⾏流程:
- 配置TM,把多个RM注册到TM
- AP从TM管理的RM中获取连接,⽐如JDBC连接
- AP向TM发起⼀个全局事务,⽣成全局事务ID(XID),XID会通知各个RM
- AP通过第⼆步获得的连接直接操作RM完成数据操作。AP在每次操作时会把XID传递给RM
- AP结束全局事务,TM会通知各个RM全局事务结束。根据各个RM的事务执⾏结果,执⾏提交或者回滚操作
4.4 两阶段提交
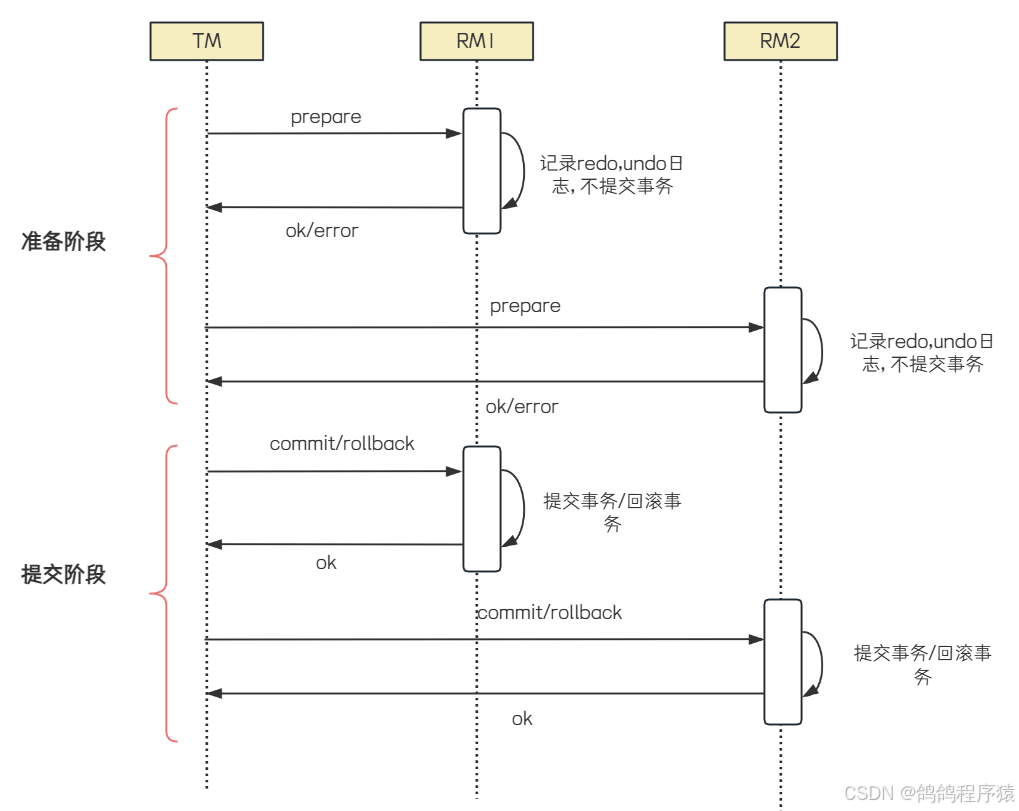
X/Open DTP 标准提出了使⽤两阶段提交(2PC,Two-Phase-Commit) 来保证分布式事务的完整性,TM对多个RM事务的管理,就会涉及两个阶段的提交。
第⼀个阶段是事务的准备阶段,第⼆个是事务的提交或者回滚阶段。
- 准备阶段 (Prepare Phase ):
-
- 协调者发送准备请求:协调者向所有参与者发送 prepare 请求,询问它们是否准备好提交事务。这个请求包含了事务的详细信息,要求参与者对事务进⾏预处理,并准备好回滚或提交事务所需的所有资源
-
- 参与者响应准备请求:参与者在收到 prepare 请求后,会执⾏事务操作,但不提交。如果参与者成功执⾏了事务操作,它会将事务的执⾏结果和准备状态记录在本地⽇志中,并向协调者发送 ready 消息,表⽰已经准备好提交事务。如果执⾏失败或⽆法准备,则向协调者发送 abort 消息。
- 提交阶段 (Commit Phase ):
-
- 协调者根据准备阶段的反馈进⾏决策:协调者收到所有参与者的响应后,会根据反馈结果做出决策。如果所有参与者都返回 ready ,则协调者决定提交事务。如果有任何⼀个参与者返回 abort ,则协调者决定回滚事务
-
- 协调者发送提交或回滚请求:
-
-
- 提交事务:如果协调者决定提交事务,它会向所有参与者发送 commit 请求。参与者在收到commit 请求后,会正式提交事务,并释放所有资源,然后向协调者发送 ack 消息,表⽰事务已成功提交。
-
-
-
- 回滚事务:如果协调者决定回滚事务,它会向所有参与者发送 rollback 请求。参与者在收到 rollback 请求后,会回滚事务,并释放所有资源,然后向协调者发送 ack 消息,表⽰事务已成功回滚。
-
两阶段提交把⼀个事务的处理过程分为 准备 和 提交/回滚 两个阶段,采⽤简单的⽅式来解决分布式事务的问题,但是这个过程中,存在以下缺点:
- 阻塞问题:两个阶段都是事务阻塞型的,对于每⼀个指令都需要有明确的响应,如果在这个过程中,TM宕机或者⽹络出现故障,则会⼀直处于阻塞状态。⽐如第⼀阶段完成后TM宕机或⽹络出现故障了,此时RM会⼀直阻塞,⽆法进⾏其他操作。所以3PC针对此问题,加⼊了timeout机制。
- 资源占⽤:参与者在收到准备请求后,会锁定相关资源以保证事务的原⼦性。在整个两阶段提交过程中,这些资源⼀直被锁定,直到事务提交或回滚完成。这会导致资源利⽤率降低,其他事务可能因⽆法获取所需资源⽽等待。
- 数据不⼀致:第⼆阶段中,TM向所有的RM发送commit请求,由于局部⽹络异常,导致只有⼀部分RM收到了commit请求,这些RM节点执⾏commit操作,没有收到commit请求的节点由于事务⽆法提交,出现数据不⼀致的情况
相应也存在以下优点
- 保证事务的原⼦性:2PC通过两个阶段的严格控制,确保了事务要么全部提交,要么全部回滚,从⽽保证了事务的原⼦性。
- 实现相对简单:相⽐于其他分布式事务协议,2PC的实现相对简单,易于理解和实现。
4.5 三阶段提交
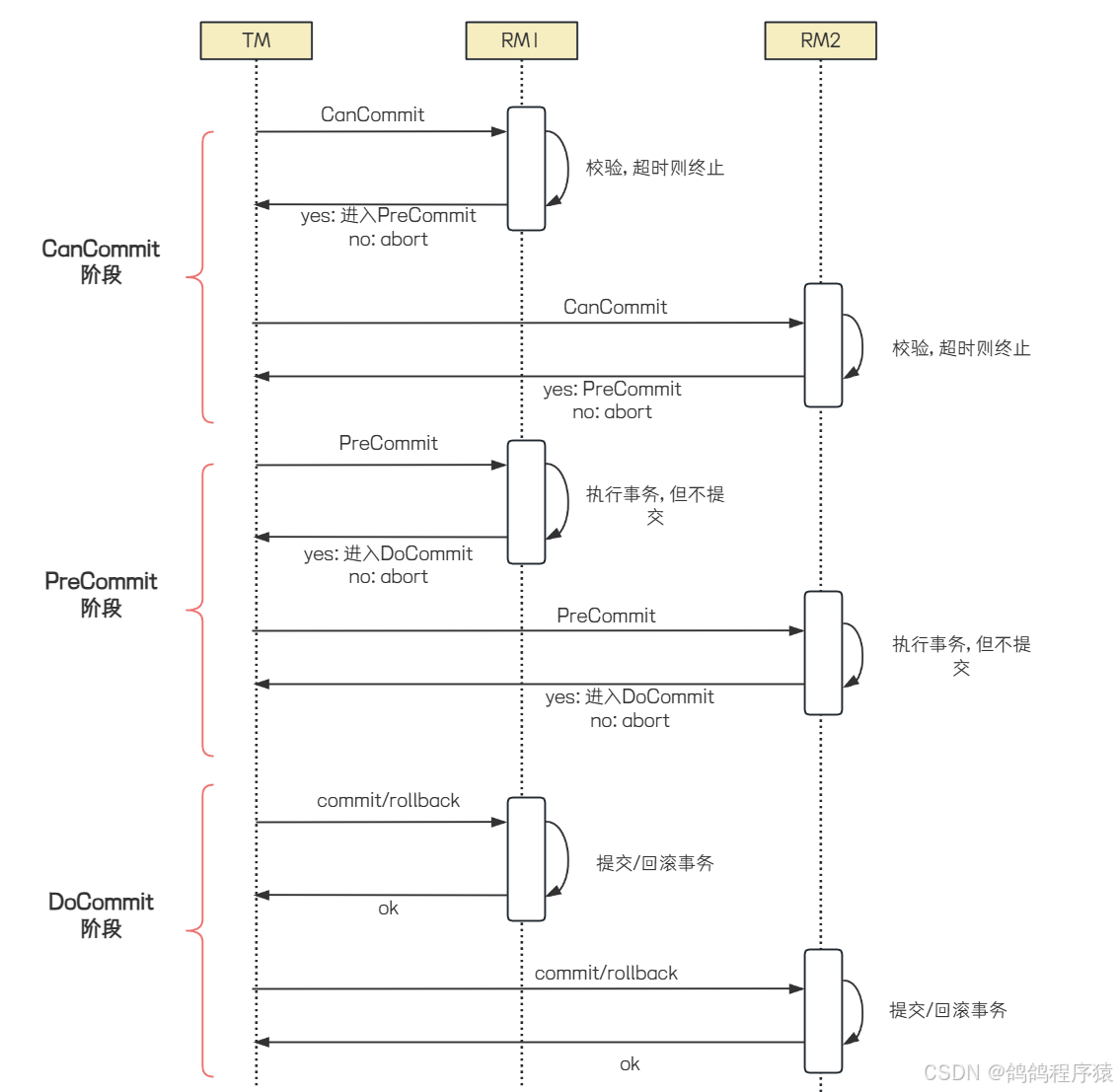
3PC(Three-Phase-Commit),是2PC的改进版本,共分为 CanCommit ,PreCommit 和 DoCommit三个阶段
- CanCommit阶段
-
- 协调者发起请求:协调者向所有参与者发送 CanCommit 请求,询问它们是否可以执⾏事务提交操作。此阶段不涉及实际的数据修改,只是确认每个参与者是否有⾜够的资源和条件来完成事务。
-
- 参与者响应:参与者根据⾃⾝情况返回Yes或No。如果所有参与者都返回Yes,则进⼊PreCommit阶段
- PreCommit阶段
-
- 协调者发送PreCommit请求:协调者向所有参与者发送 PreCommit 请求,询问是否可以进⾏事务的预提交操作
-
- 参与者准备事务:参与者执⾏事务操作,并将事务执⾏结果和准备状态 (Yes/No) 发送给协调者。参与者会记录预提交⽇志,并确保这些⽇志是持久化的。
-
- 协调者收集反馈并决策:如果所有参与者都返回Yes,则进⼊DoCommit阶段。如果有任何⼀个参与者返回No或超时未响应,协调者会发送 abort 请求,通知所有参与者回滚事务。
- DoCommit阶段
-
- 协调者发送DoCommit请求:协调者向所有参与者发送 DoCommit 请求,指⽰它们正式提交事务。
-
- 参与者执⾏提交:参与者收到 DoCommit 请求后,执⾏事务提交操作,并向协调者发送 Ack 消息,表⽰事务已提交。
-
- 超时机制:如果参与者在等待 DoCommit 请求时超时,会默认执⾏提交操作。
优点
- 减少阻塞:3PC通过引⼊超时机制,减少了2PC中的阻塞问题。避免了资源被永久锁定。
- 增强容错能⼒:即使协调者在DoCommit阶段之前出现故障,参与者也可以基于其预提交的状态⾃主决定继续提交或回滚事务,从⽽减少了对协调者的依赖。
缺点:
- 实现复杂度⾼:3PC的实现⽐2PC更复杂,增加了系统的开发和维护成本。
- 数据不⼀致⻛险:在某些情况下,如⽹络分区,参与者在收到 PreCommit 消息后,如果⽹络出现故障,协调者和参与者⽆法进⾏后续通信,参与者在超时后可能会⾃⾏提交事务,导致数据不⼀致。
4.6 TCC事务
TCC (Try-Confirm-Cancel) 是⼀种分布式事务解决⽅案,是由Pat Helland在2007年发表的论⽂《Life beyond Distributed Transactions:An Apostate's Opinion》中提出。TCC事务相对于传统两阶段,其特征在于它不依赖资源管理器(RM)对XA的⽀持,⽽是通过对 (由业务系统提供的) 业务逻辑的接⼝调⽤来实现分布式事务。
TCC 通过将事务操作拆分为三个阶段:
- Try阶段:尝试执⾏业务操作,完成所有业务检查,并预留必要的业务资源。这个阶段不真正执⾏事务,只是进⾏资源的预占。
- Confirm阶段:如果所有参与者在Try阶段都成功,那么进⼊Confirm阶段,正式完成操作,使⽤之前预留的资源
- Cancel阶段:如果任何⼀个参与者在Try阶段失败,那么进⼊Cancel阶段,所有参与者回滚在Try阶段执⾏的操作,释放预留的资源。
TCC事务属于两阶段提交思想的变体,它在设计上借鉴了两阶段提交的核⼼理念,第⼀阶段通过Try进⾏准备⼯作,第⼆阶段Confirm/Cancel表⽰Try阶段操作的确认和回滚。
在主业务⽅法中,会先调⽤业务服务对外提供的 Try ⽅法来做资源预留,如果业务服务 Try ⽅法处理都正常,TCC事务协调器就会调⽤ Confirm ⽅法对预留资源进⾏实际应⽤。否则就会调⽤各个服务的Cancel ⽅法进⾏回滚,从⽽保证数据的⼀致性。
优点:
- ⽆需依赖第三⽅中间件或数据库来实现分布式事务,降低了系统复杂度和成本。
- ⽆需锁定全局资源,提⾼了系统的并发性能和可⽤性
- 适⽤于各种类型的业务场景,只要能够定义出清晰的Try、Confirm和Cancel逻辑
缺点:
- 需要开发⼈员⼿动编写三个阶段的业务逻辑,并保证其正确性和⼀致性,增加了开发难度和维护成本
- 需要考虑各种异常情况和边界情况,并提供相应的补偿策略和重试机制,增加了系统复杂度和⻛险
五、使用seata
5.1 下载与布署
下载链接:https://seata.apache.org/zh-cn/download/seata-server/
操作文档链接:https://seata.apache.org/zh-cn/docs/user/registry/namingserver/
5.1.1 修改配置
修改配置:使⽤Nacos来作为Seata的配置中⼼和注册中心,修改 /seata-server/conf/application.yml 中seata相关的配置。
配置内容参考: /seata-server/conf/application.example.yml
5.1.2 修改Seata存储模式
Server端存储模式(store.mode) ⽀持file,db,redis,raft。
- file模式为单机模式,全局事务会话信息内存中读写并异步(默认)持久化本地⽂件root.data,性能较⾼;
- db模式为⾼可⽤模式,全局事务会话信息通过db共享,相应性能差些。
如果使⽤file模式,⽆需改动,直接启动即可,我们使⽤DB。
5.1.2.1 初始化数据库
全局事务会话信息由3块内容构成,全局事务-->分⽀事务-->全局锁,对应表global_table、branch_table、lock_table。
创建数据库seata:
sql
CREATE DATABASE IF NOT EXISTS seata;建表语句在文件:/seata-server/script/server/db/mysql.sql
5.1.2.2 修改store.mode
修改 /seata-server/conf/application.yml 中 store.mode 相关的配置
配置内容参考: /seata-server/conf/application.example.yml ,将其db相关配置复制⾄application.yml,进⾏修改store.db相关属性
5.1.3 启动
Windows双击 /seata-server/bin/seata-server.bat
nacos中可以看见实例:

5.2 微服务集成seata
5.2.1 引⼊依赖
在需要的微服务(每一个服务pom)中引⼊seata依赖
xml
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
</dependency>5.2.2 修改配置⽂件
修改application.yml,添加seata相关配置
每个服务都添加配置,根据配置信息确定TC服务地址信息。
yml
seata:
registry: #定义了Seata Server的注册中⼼配置, 微服务根据配置信息去注册中⼼获取tc服务地址
type: nacos #指定注册中⼼的类型
nacos:
application: seata-server #Seata Server在Nacos中的应⽤名称
server-addr: ip:8848 #Nacos服务器地址
group : "SEATA_GROUP" #Seata Server在Nacos中的分组名称
namespace: "" #Nacos的命名空间, 设置为空, 表⽰使⽤默认的命名空间public
tx-service-group: default_tx_group #定义事务服务组的名称
service:
vgroup-mapping:
default_tx_group: default
- eata.tx-service-group :定义了事务服务组的名称,这⾥设置为default_tx_group 。事务服务组⽤于将Seata Server和Seata Client进⾏分组管理,确保它们能够正确地发现和通信。
- seata.service.vgroup-mapping.事务分组名 :定义了Seata Server的服务配置,事务服务组到Seata Server集群的映射关系,这⾥将 default_tx_group 映射到 default 集群
- default :Seata Server的集群名称
- 事务分组介绍参考:https://seata.apache.org/zh-cn/docs/user/txgroup/transaction-group
六、Seata事务模式
Seata提供了多种事务模式:
- AT模式
- TCC模式
- Saga模式
- XA模式
6.1 XA模式
6.1.1 介绍
XA 模式是从 1.2 版本⽀持的事务模式。XA 规范 是 X/Open 组织定义的分布式事务处理标准。Seata XA 模式是利⽤事务资源 (数据库、消息服务等 ) 对 XA 协议的⽀持,以 XA 协议的机制来管理分⽀事务的⼀种事务模式。
XA实现的原理是基于两阶段提交。
Seata 对原始的XA模式做了简单的封装和改造,以适应⾃⼰的事务模型,在 Seata 定义的分布式事务框架内,利⽤事务资源 (数据库、消息服务等 ) 对 XA 协议的⽀持,以 XA 协议的机制来管理分⽀事务的⼀种事务模式。
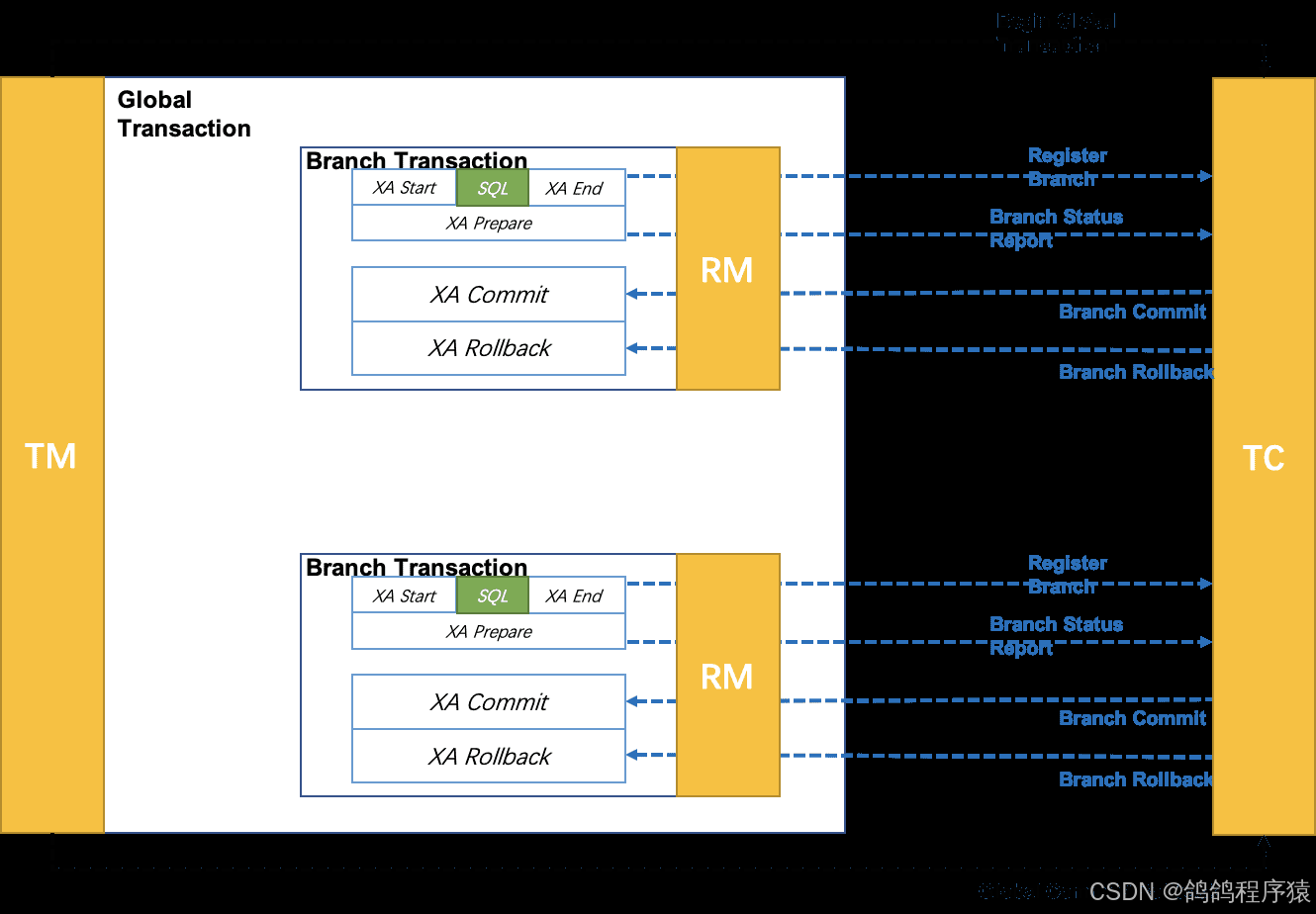
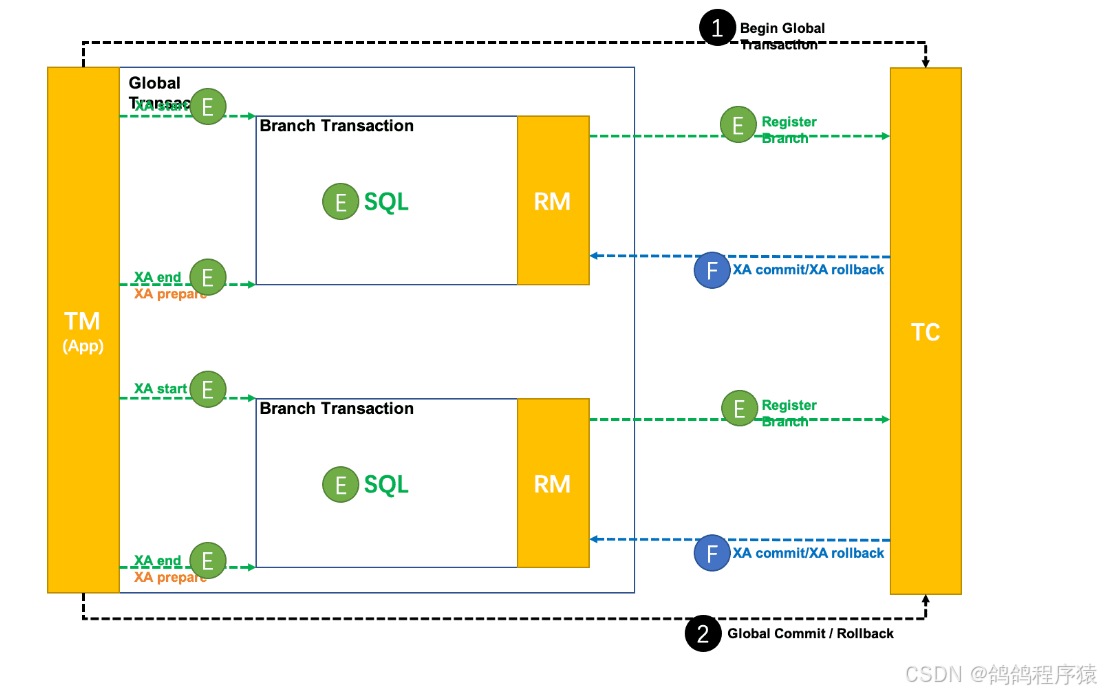
整体机制:
- 开启事务:事务管理器 ™ 开启⼀个全局事务,并与事务协调器 (TC) 建⽴连接,TC返回⼀个全局事务ID(XID) 给TM
- 分⽀事务注册与执⾏:资源管理器(RM) 收到业务操作请求后,会向TC注册分⽀事务,执⾏业务SQL,并携带XID以保证事务的⼀致性。
- 分⽀事务状态报告:RM执⾏完分⽀事务后,向TC报告分⽀事务的执⾏状态
- 事务提交或回滚决策:TM在所有分⽀事务执⾏完毕后,会通知TC事务结束。TC接收到事务结束通知后,会检查各分⽀事务的执⾏状态。如果所有分⽀事务都成功,则TC通知所有RM提交事务。如果有任意⼀个分⽀事务失败,则TC通知所有RM回滚事务。
- 分⽀事务提交或回滚:RM接收到TC的提交或回滚指令后,执⾏相应的commit或rollback操作。
6.1.2 配置与使⽤
- 在application.yml中配置seata的事务模式
yml
seata:
data-source-proxy-mode: XA- 给发起全局事务的⼊⼝⽅法添加 @GlobalTransactional 注解
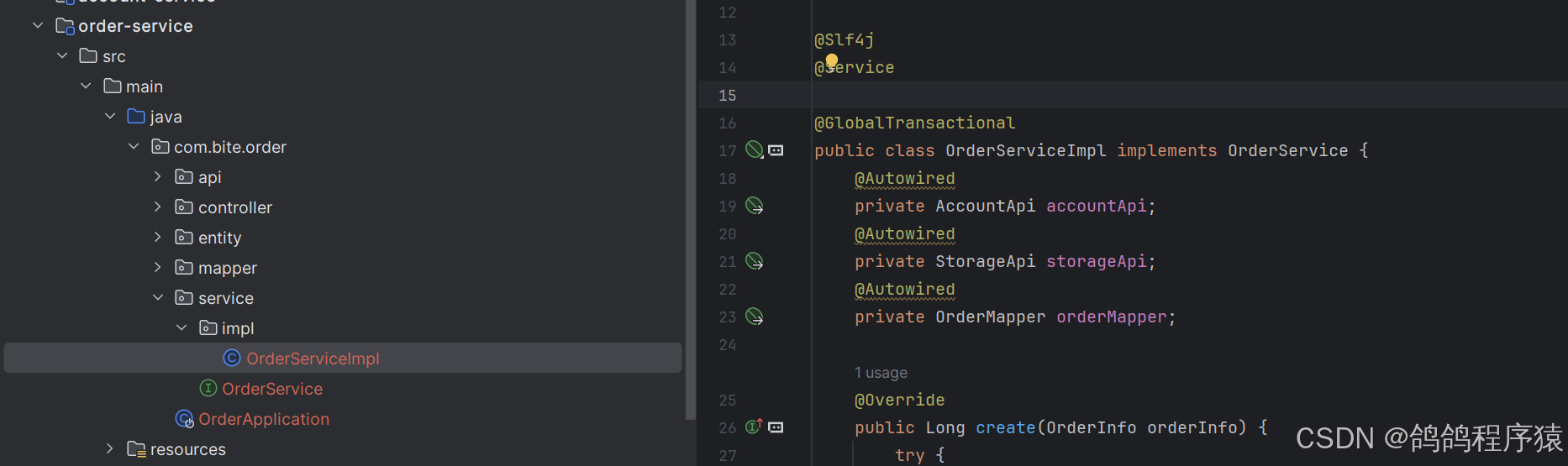
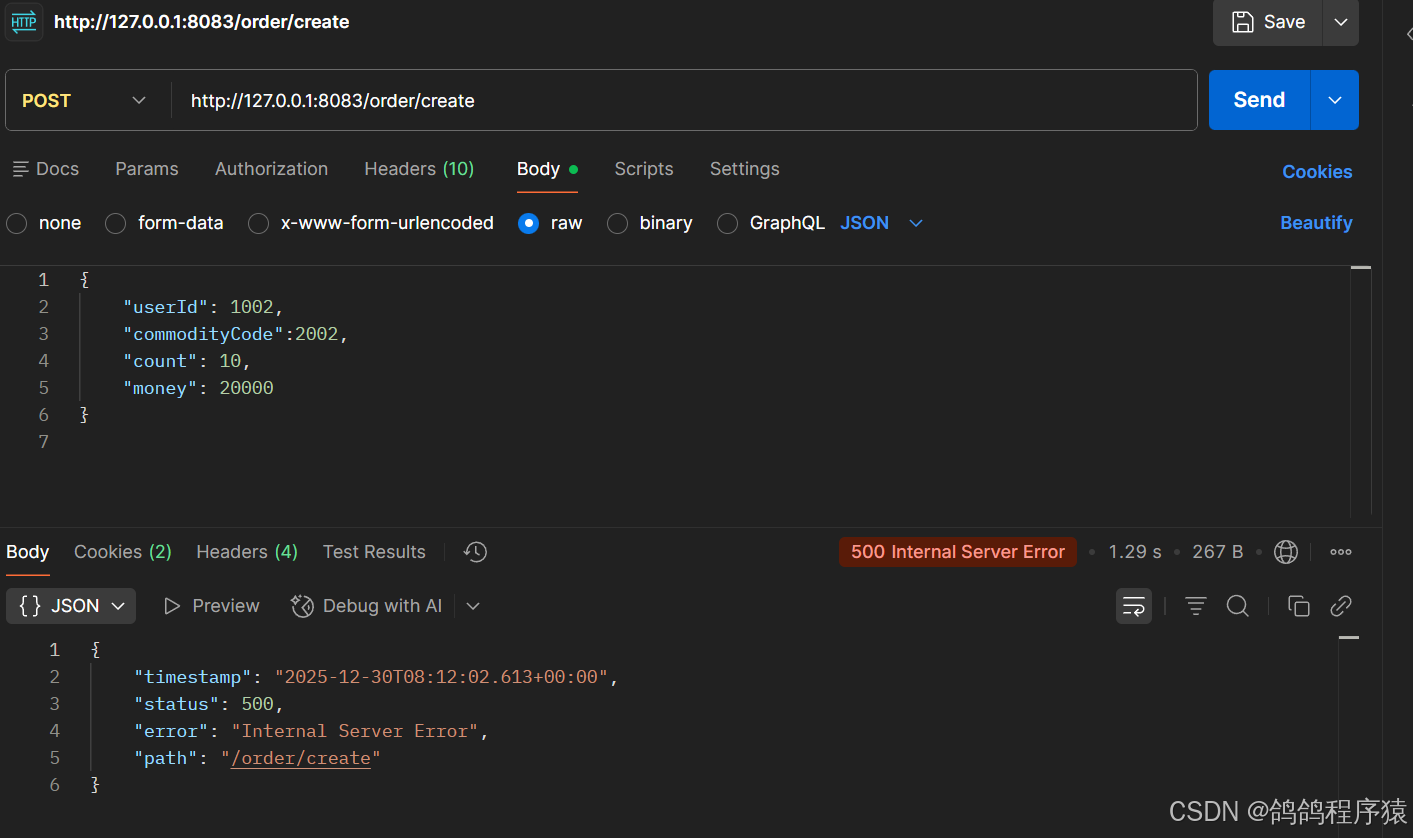
- 重启服务,并测试
当测试余额不足的时候,会全部回滚,数据库全部回滚。
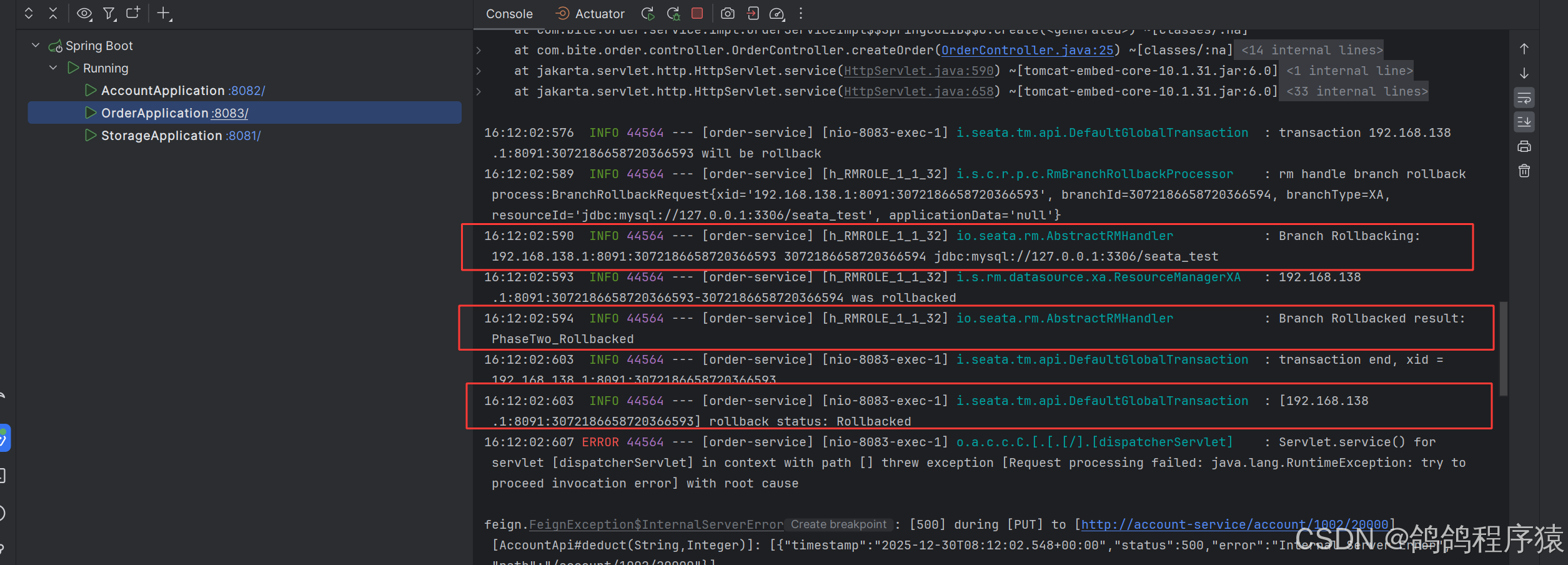
6.1.3 优缺点
优点
- 事务强⼀致性:XA模式能够满⾜ACID原则,确保分布式事务的强⼀致性。
- 实现简单且⽆代码侵⼊:常⽤数据库都⽀持XA协议,使⽤Seata的XA模式⽆需修改业务代码,只需进⾏简单的配置即可。
缺点
- 性能较差:⼀阶段需要锁定数据库资源,等待⼆阶段结束才释放,导致事务资源⻓时间得不到释放,锁定周期⻓,从⽽影响性能
- 依赖关系型数据库:XA模式依赖数据库实现事务,对于⼀些⾮关系型数据库或不⽀持XA协议的数据库,⽆法使⽤。
6.2 AT 模式
6.2.1 介绍
AT 模式是 Seata 创新的⼀种⾮侵⼊式的分布式事务解决⽅案。Seata 在内部做了对数据库操作的代理层,我们使⽤ Seata AT 模式时,实际上⽤的是 Seata ⾃带的数据源代理 DataSourceProxy,Seata 在这层代理中加⼊了很多逻辑,⽐如插⼊回滚 undo_log ⽇志,检查全局锁等。
Seata AT模式针对两阶段提交协议的演变:
-
⼀阶段:业务数据和回滚⽇志记录在同⼀个本地事务中提交,释放本地锁和连接资源
-
⼆阶段:
-
- 提交异步化,⾮常快速地完成
-
- 回滚通过⼀阶段的回滚⽇志进⾏反向补偿
-
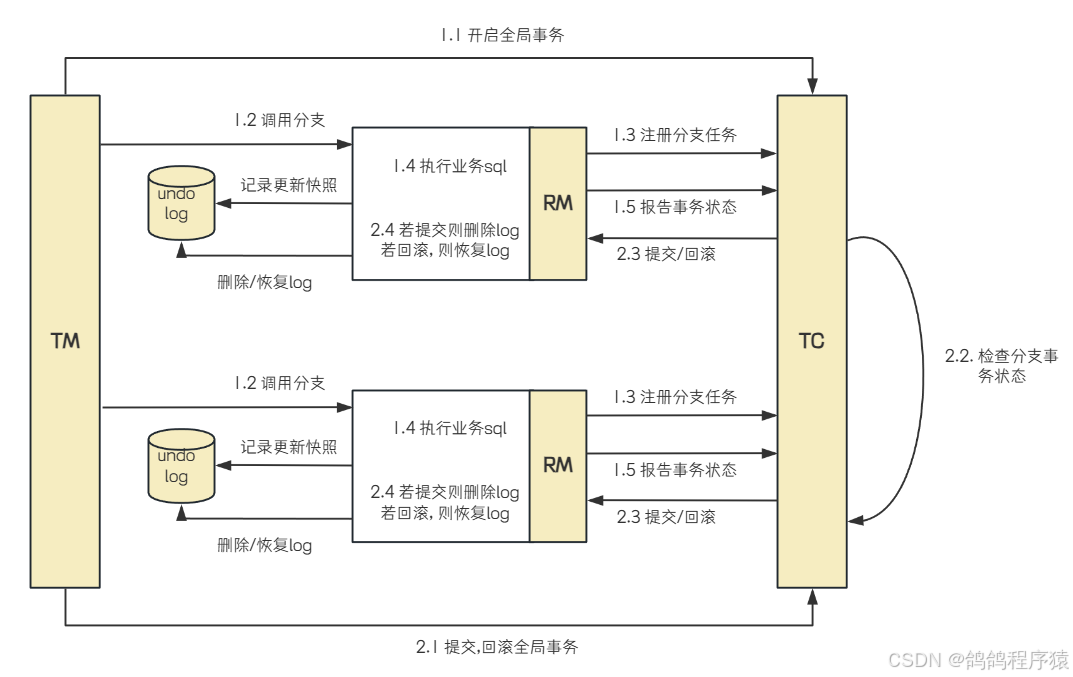
整体机制
- ⼀阶段:
-
- 注册分⽀事务:TM注册全局事务,资源管理器(RM) 向事务协调器(TC ) 注册分⽀事务
-
- 记录undo_log:RM在执⾏业务SQL操作前,会先解析SQL语句,记录SQL更新前的快照和更新后的快照到undo_log⽇志表中。undo_log记录了⾜够的信息,以便在需要回滚时能够恢复数据。
-
- 执⾏SQL并提交本地事务:RM执⾏业务SQL操作,并直接提交本地事务,此时数据会真实地提交到数据库中
-
- 报告事务状态:RM向TC报告分⽀事务的执⾏状态,告知其本地事务已提交
- ⼆阶段:
-
- 提交成功:如果所有分⽀事务都成功,TC会通知RM清理undo_log相关的补偿信息,完成整个分布式事务的处理
-
- 提交失败:如果有任意⼀个分⽀事务失败,TC会通知RM进⾏回滚。RM根据undo_log中的补偿信息对数据进⾏反向补偿,从⽽实现事务的回滚
6.2.2 读写隔离
6.2.2.1 写隔离
在多线程并发操作同⼀个数据时,有可能会出现脏写问题
- 此时数据库的数据为1000,那么久丢失了⼀次更新,出现脏写
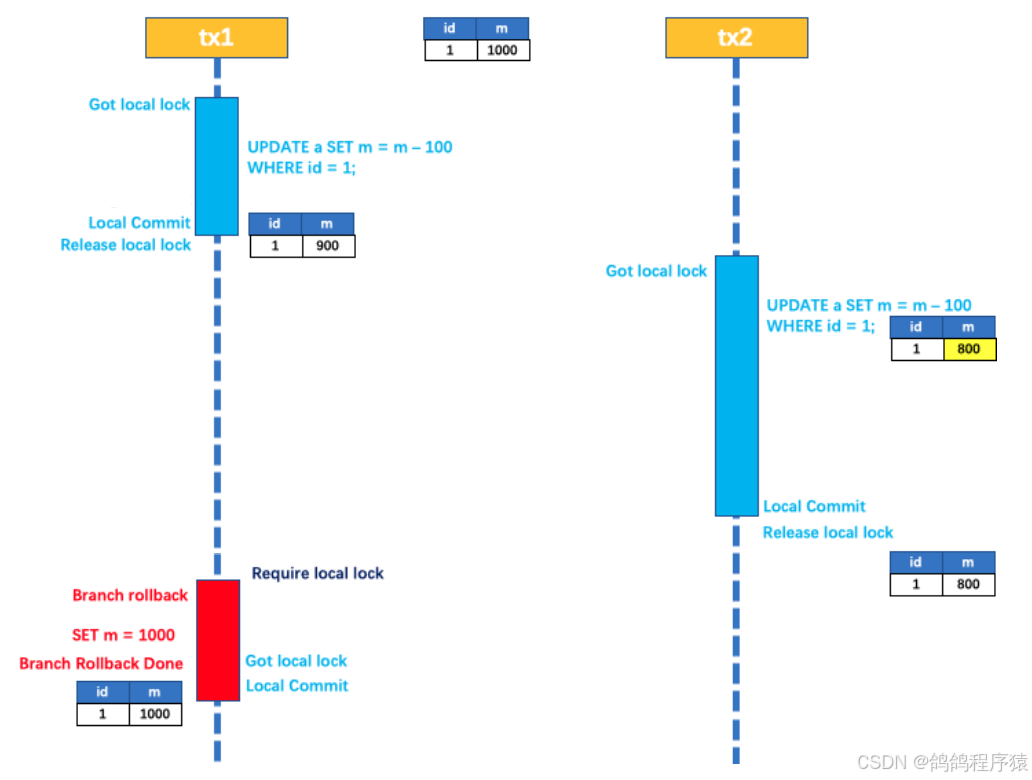
Seata的AT模式解决思路就是引⼊全局锁的概念,在释放本地锁之前,先拿到全局锁,避免同⼀时刻有另外⼀个事务来操作当前数据。
- ⼀阶段本地事务提交前,需要确保先拿到 全局锁
- 拿不到全局锁,不能提交本地事务
- 拿 全局锁 的尝试被限制在⼀定范围内,超出范围将放弃,并回滚本地事务,释放本地锁
6.2.2.2 读隔离
在数据库本地事务隔离级别 读已提交 (Read Committed) 或以上的基础上,Seata (AT模式)的默认全局隔离级别是 读未提交 (Read Uncommitted)
如果应⽤在特定场景下,必需要求全局的 读已提交,⽬前 Seata 的⽅式是通过 SELECT FOR UPDATE 语句的代理。
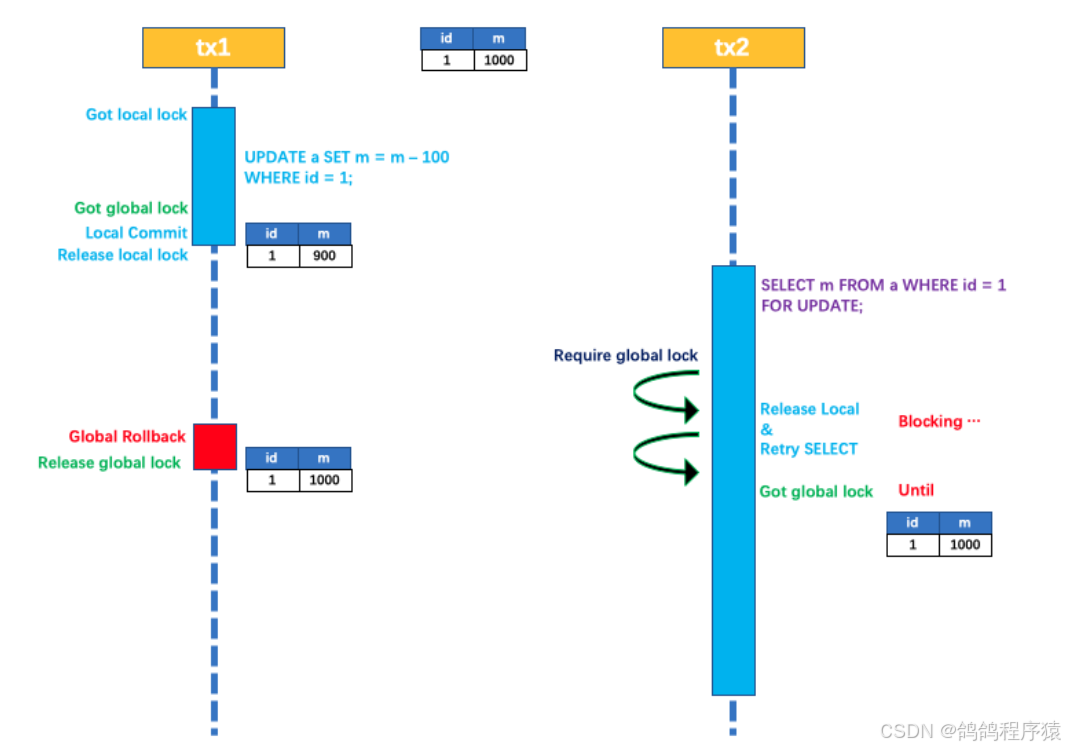
SELECT FOR UPDATE 语句的执⾏会申请 全局锁,如果 全局锁 被其他事务持有,则释放本地锁 (回滚 SELECT FOR UPDATE 语句的本地执⾏) 并重试。这个过程中,查询是被 block 住的,直到 全局锁 拿到,即读取的相关数据是 已提交 的,才返回。
出于总体性能上的考虑,Seata⽬前的⽅案并没有对所有 SELECT语句都进⾏代理,仅针对 FOR UPDATE 的 SELECT 语句
6.2.3 ⼯作机制
以⼀个⽰例来说明整个 AT 分⽀的⼯作过程。
业务表: product
| Field | Type | Key |
|---|---|---|
| id | bigint(20) | PRI |
| name | varchar(100) | |
| since | varchar(100) |
AT分⽀事务的业务逻辑:
sql
update product set name = 'GTS' where name = 'TXC';⼀阶段
过程:
- 解析 SQL:得到 SQL 的类型 (UPDATE),表(product),条件(where name = 'TXC') 等相关的信息。
- 查询前镜像:根据解析得到的条件信息,⽣成查询语句,定位数据。
sql
select id, name, since from product where name = 'TXC';
- 执⾏业务 SQL:更新这条记录的 name 为 'GTS'
- 查询后镜像:根据前镜像的结果,通过 主键 定位数据
sql
select id, name, since from product where id = 1;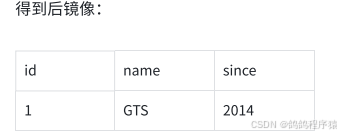
- 插⼊回滚⽇志:把前后镜像数据以及业务 SQL 相关的信息组成⼀条回滚⽇志记录,插⼊到 UNDO_LOG 表中
- 申请 product 表中,主键值等于 1 的记录的 全局锁
- 本地事务提交:业务数据的更新和前⾯步骤中⽣成的 UNDO LOG ⼀并提交
- 将本地事务提交的结果上报给TC
⼆阶段-回滚
- 收到 TC 的分⽀回滚请求,开启⼀个本地事务,执⾏如下操作
- 通过 XID 和 Branch ID 查找到相应的 UNDO LOG 记录
- 数据校验:拿 UNDO LOG 中的后镜与当前数据进⾏⽐较,如果有不同,说明数据被当前全局事务之外的动作做了修改。这种情况,需要根据配置策略来做处理
- 根据 UNDO LOG 中的前镜像和业务 SQL 的相关信息⽣成并执⾏回滚的语句
sql
update product set name = 'TXC' where id = 1;- 提交本地事务,并把本地事务的执⾏结果 (即分⽀事务回滚的结果 ) 上报给 TC
⼆阶段-提交
- 收到 TC 的分⽀提交请求,把请求放⼊⼀个异步任务的队列中,⻢上返回提交成功的结果给 TC
- 异步任务阶段的分⽀提交请求将异步和批量地删除相应 UNDO LOG 记录
6.2.4 配置与使⽤
- 在微服务关联的数据库创建undo_log表,已经在前面项目搭建的时候执行的sql语句执行了。
sql
-- 注意此处0.3.0+ 增加唯⼀索引 ux_undo_log
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) NOT NULL,
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
`ext` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;- 配置事务模式为AT
yml
seata:
data-source-proxy-mode: AT- 测试
测试余额不⾜时,接⼝发⽣错误,发现事务全部回滚了,库存服务会有⼀些简单的⽇志
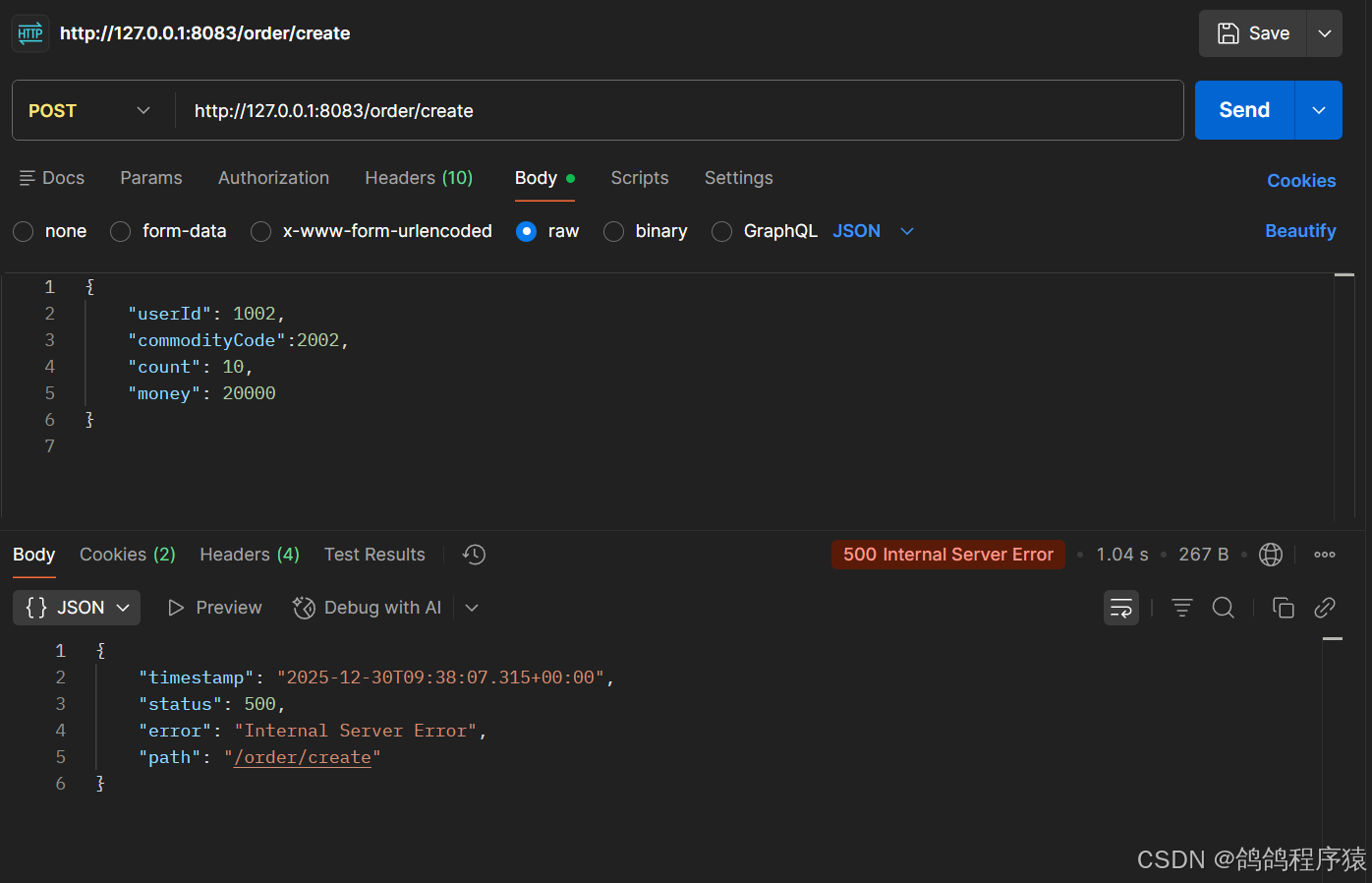
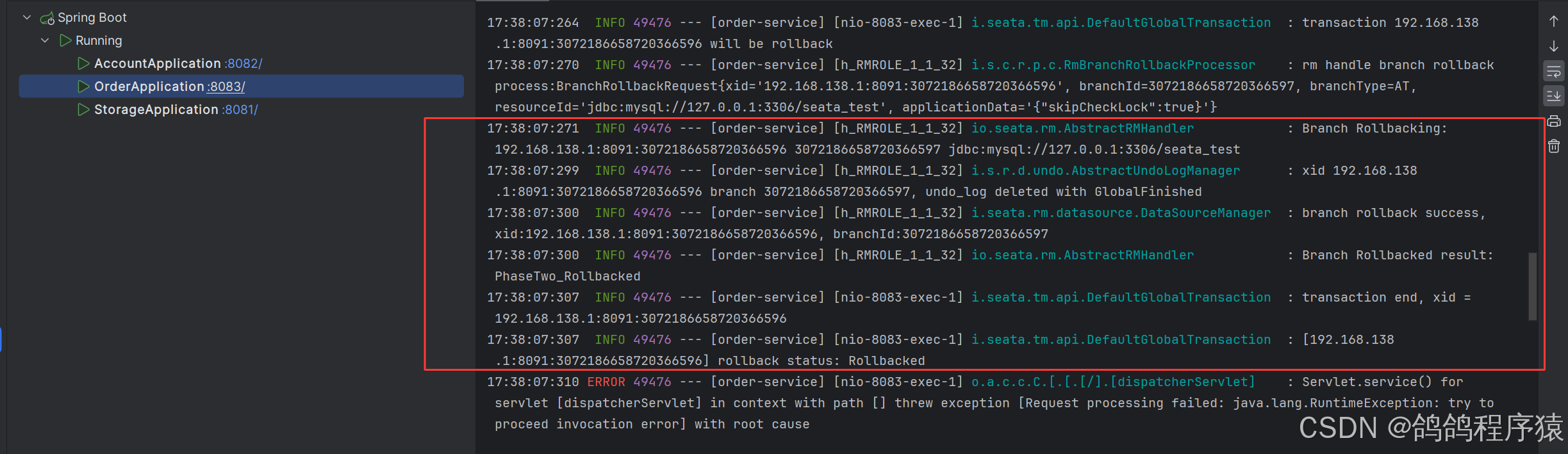
6.3 TCC模式
6.3.1 介绍
TCC 模式是 Seata ⽀持的⼀种由业务⽅细粒度控制的侵⼊式分布式事务解决⽅案,是继 AT 模式后第⼆种⽀持的事务模式,最早由蚂蚁⾦服贡献。其分布式事务模型直接作⽤于服务层,不依赖底层数据库,可以灵活选择业务资源的锁定粒度,减少资源锁持有时间,可扩展性好,可以说是为独⽴部署的 SOA 服务⽽设计的。
Seata的全局事务,整体是 两阶段提交 的模型。全局事务是由若⼲分⽀事务组成的,分⽀事务要满⾜两阶段提交 的模型要求,即需要每个分⽀事务都具备⾃⼰的
- ⼀阶段prepare⾏为
- ⼆阶段commit或rollback⾏为
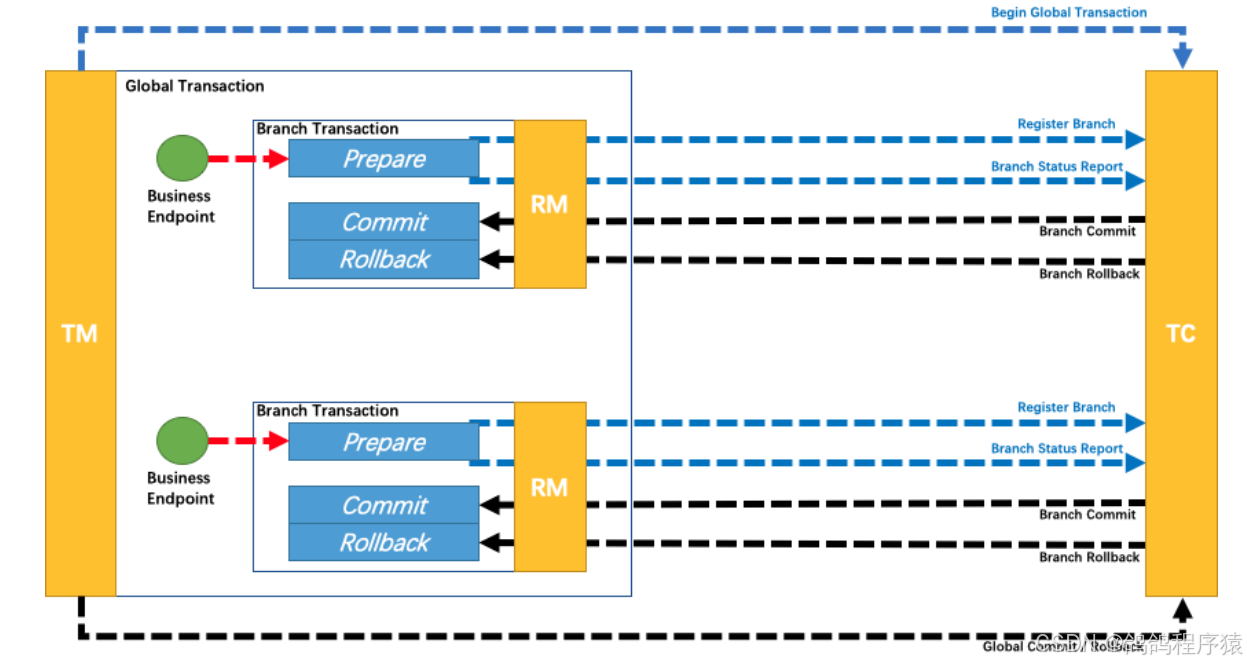
根据两阶段⾏为模式的不同,将分⽀事务划分为 Automatic Transaction Mode 和 TCC Transaction Mode
AT 模式和TCC模式⾮常相似,每阶段都是独⽴事务,不同的是TCC通过⼈⼯编码来实现数据的恢复。
AT 模式基于 ⽀持本地 ACID 事务 的 关系型数据库:
- ⼀阶段 prepare ⾏为:在本地事务中,⼀并提交业务数据更新和相应回滚⽇志记录
- ⼆阶段 commit ⾏为:⻢上成功结束,⾃动 异步批量清理回滚⽇志
- ⼆阶段 rollback ⾏为:通过回滚⽇志,⾃动 ⽣成补偿操作,完成数据回滚
相应的,TCC 模式,不依赖于底层数据资源的事务⽀持:
- ⼀阶段 prepare ⾏为:调⽤ ⾃定义 的 prepare 逻辑
- ⼆阶段 commit ⾏为:调⽤ ⾃定义 的 commit 逻辑
- ⼆阶段 rollback ⾏为:调⽤ ⾃定义 的 rollback 逻辑
所谓 TCC 模式,是指⽀持把 ⾃定义 的分⽀事务纳⼊到全局事务的管理中
6.3.2 TCC 设计
我们使⽤ Seata TCC 模式实现⼀个分布式事务。
6.3.2.1 业务操作分析
接⼊ TCC 前,业务操作只需要⼀步就能完成,但是在接⼊ TCC 之后,需要考虑如何将其分成 2 阶段完成,把资源的检查和预留放在⼀阶段的 Try 操作中进⾏,把真正的业务操作的执⾏放在⼆阶段的 Confirm 操作中进⾏
我们以库存扣减为例。下订单之后,需要扣减相应的库存。
接⼊TCC之后,需要考虑,如何将扣库存分成两步完成。
- Try 操作:资源的检查和预留
在扣库存场景下,Try 操作要做的事情就是先检查 A 商品库存是否⾜够,再冻结要扣的 20 个 (预留资源),此阶段不会发⽣真正的扣库存 - Confirm 操作:执⾏真正业务的提交。
在扣库存场景下,Confirm 阶段⾛的事情就是发⽣真正的扣库存,把A商品中已经冻结的 30 个库存扣掉。 - Cancel 操作:预留资源的是否释放
在扣库存场景下,扣库存操作取消,Cancel 操作执⾏的任务是释放 Try 操作冻结的 20个库存,使 A 商品回到初始状态 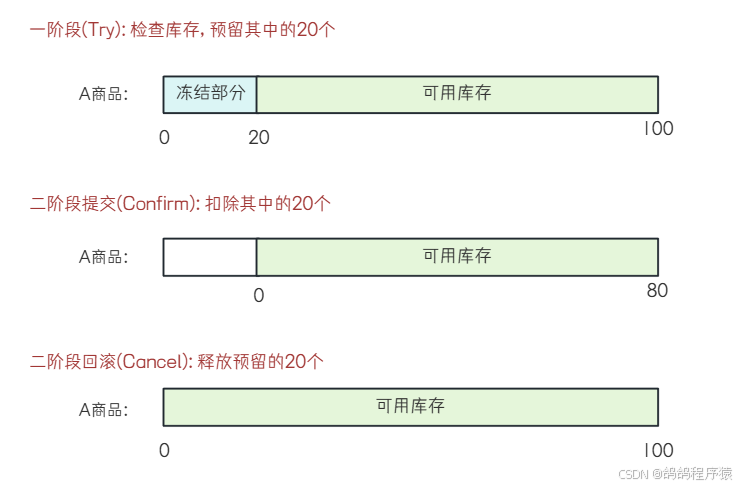
6.3.2.2 并发控制
在实现 TCC 时,要考虑并发性问题,将锁的粒度降到最低,以最⼤限度的提⾼分布式事务的并发
性。
以下还是以A商品扣库存为例,"A商品 有 100 个库存,事务 T1 要扣除其中的 20个,事务 T2 也要扣除 20个,出现并发"
在⼀阶段 Try 操作中,分布式事务 T1 和分布式事务 T2 分别冻结资⾦的那⼀部分资⾦,相互之间⽆⼲扰
这样在分布式事务的⼆阶段,⽆论 T1 是提交还是回滚,都不会对 T2 产⽣影响,这样 T1 和 T2 在同⼀笔业务数据上并⾏执⾏

6.3.2.3 允许空回滚
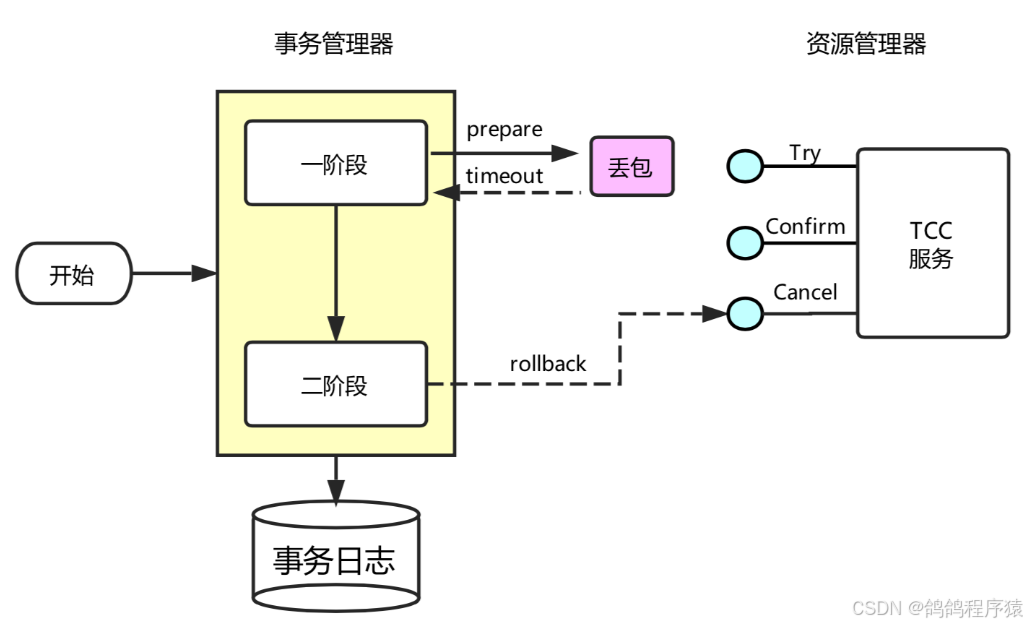
如下图所⽰,事务协调器在调⽤ TCC 服务的⼀阶段 Try 操作时,可能会出现因为丢包⽽导致的⽹络超时,
此时事务管理器会触发⼆阶段回滚,调⽤ TCC 服务的 Cancel 操作,⽽ Cancel 操作调⽤未出现超时。TCC 服务在未收到 Try 请求的情况下收到 Cancel 请求,这种场景被称为空回滚。空回滚在⽣产环境经常
出现,⽤⼾在实现TCC服务时,应允许空回滚的执⾏,即收到空回滚时返回成功
6.3.2.4 防悬挂控制
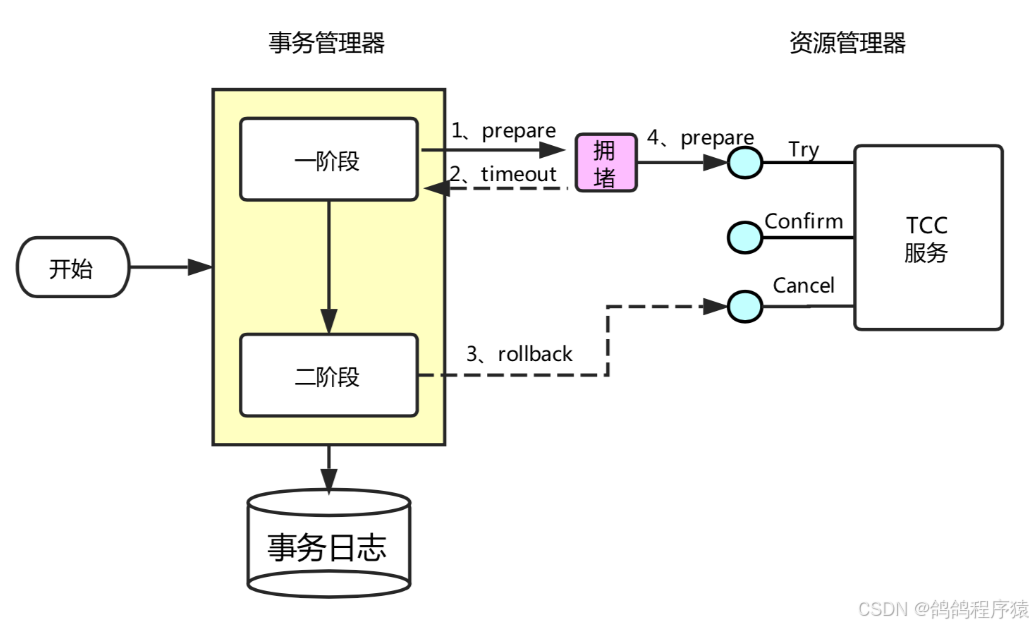
如下图所⽰,事务协调器在调⽤ TCC服务的⼀阶段 Try 操作时,可能会出现因⽹络拥堵⽽导致的超时,此
时事务管理器会触发⼆阶段回滚,调⽤ TCC 服务的 Cancel 操作,Cancel 调⽤未超时。在此之后,拥堵在
⽹络上的⼀阶段 Try 数据包被 TCC 服务收到,出现了⼆阶段 Cancel 请求⽐⼀阶段 Try 请求先执⾏的情况,TCC 服务在执⾏晚到的 Try 之后,将永远不会再收到⼆阶段的 Confirm 或者 Cancel,造成 TCC 服务悬挂
⽤⼾在实现 TCC 服务时,要允许空回滚,但是要拒绝执⾏空回滚之后 Try 请求,要避免出现悬挂。
6.3.2.5 幂等控制
⽆论是⽹络数据包重传,还是异常事务的补偿执⾏,都会导致 TCC服务的 Try、Confirm 或者 Cancel 操作被重复执⾏。⽤⼾在实现 TCC 服务时,需要考虑幂等控制,即 Try、Confirm、Cancel 执⾏⼀次和执⾏多次的业务结果是⼀样的
6.3.2.6 Seata解决⽅法
TCC 模式中存在的三⼤问题是幂等、悬挂和空回滚。在 Seata1.5.1 版本中,增加了⼀张事务控制表tcc_fence_log,包含事务的 XID 和 BranchID 信息,来解决这个问题
sql
CREATE TABLE IF NOT EXISTS `tcc_fence_log`
(
`xid` VARCHAR(128) NOT NULL COMMENT 'global id',
`branch_id` BIGINT NOT NULL COMMENT 'branch id',
`action_name` VARCHAR(64) NOT NULL COMMENT 'action name',
`status` TINYINT NOT NULL COMMENT
'status(tried:1;committed:2;rollbacked:3;suspended:4)',
`gmt_create` DATETIME(3) NOT NULL COMMENT 'create time',
`gmt_modified` DATETIME(3) NOT NULL COMMENT 'update time',
PRIMARY KEY (`xid`, `branch_id`),
KEY `idx_gmt_modified` (`gmt_modified`),
KEY `idx_status` (`status`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;- 空回滚
在 Try ⽅法执⾏时插⼊⼀条记录,表⽰⼀阶段执⾏了,执⾏ Cancel ⽅法时读取这条记录,如果记录不存在,说明 Try ⽅法没有执⾏,以此来避免空回滚 - 悬挂
在 Rollback 阶段,如果查询到事务控制表中没有记录,说明Cancle先于Try执⾏了。因此插⼊⼀条 status=4 状态的记录。当Try阶段执⾏时,判断status=4,则说明有⼆阶段 Cancel 已执⾏,并返回 false 以阻⽌⼀阶段 Try ⽅法执⾏成功 - 幂等
在 TCC 事务控制表中增加⼀个记录状态的字段 status,该字段有 4 个值,分别为: -
- tried(1) :表⽰Try 阶段已经执⾏过
-
- committed(2):表⽰⼆阶段 Commit 已经执⾏完成
-
- rollbacked(3):表⽰⼆阶段 Rollback 已经执⾏完成
-
- suspended(4):表⽰空回滚/悬挂/中⽌状态
⼆阶段 Confirm/Cancel ⽅法执⾏后,将状态改为 committed 或 rollbacked 状态。当重复调⽤⼆阶段
Confirm/Cancel ⽅法时,判断事务状态即可解决幂等问题
6.3.3 TCC实现
6.3.3.1 创建事务控制表
为了解决幂等,悬挂和空回滚,Seata1.5.1版本增加了⼀张事务控制表tcc_fence_log,包含事务的 XID 和
BranchID 信息,来解决这个问题。
在业务数据库中执⾏以下SQL:
sql
CREATE TABLE IF NOT EXISTS `tcc_fence_log`
(
`xid` VARCHAR(128) NOT NULL COMMENT 'global id',
`branch_id` BIGINT NOT NULL COMMENT 'branch id',
`action_name` VARCHAR(64) NOT NULL COMMENT 'action name',
`status` TINYINT NOT NULL COMMENT
'status(tried:1;committed:2;rollbacked:3;suspended:4)',
`gmt_create` DATETIME(3) NOT NULL COMMENT 'create time',
`gmt_modified` DATETIME(3) NOT NULL COMMENT 'update time',
PRIMARY KEY (`xid`, `branch_id`),
KEY `idx_gmt_modified` (`gmt_modified`),
KEY `idx_status` (`status`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8mb4;6.3.3.2 添加冻结字段
为了完成⼀阶段(Try)资源的预检,以及T2阶段事务的提交或回滚,需要增加⼀个新的字段,表⽰冻结部分.
sql
ALTER TABLE storage_tbl ADD COLUMN freeze_count INT(11) unsigned DEFAULT 0 COMMENT '冻结库存';6.3.3.3 修改相应的实体类
增加⼀个冻结字段对应的实体类。
java
@Data
@TableName("storage_tbl")
public class StorageInfo {
@TableId
private Long id;
private String commodityCode;
private Integer count;
private Integer freezeCount;
}6.3.3.4 TCC接⼝定义&实现
TCC的Try、Confirm、Cancel⽅法都需要⾃⼰来实现。
在库存服务中定义TCC接⼝
java
import io.seata.rm.tcc.api.BusinessActionContext;
public interface StorageTccService {
/**
* 扣减库存
*/
void deduct(String commodityCode, Integer count);
boolean confirm(BusinessActionContext context);
boolean cancel(BusinessActionContext context);
}TCC接⼝定义实现:
java
import com.baomidou.mybatisplus.core.conditions.update.UpdateWrapper;
import com.bite.storage.entity.StorageInfo;
import com.bite.storage.mapper.StorageMapper;
import com.bite.storage.service.StorageTccService;
import io.seata.rm.tcc.api.BusinessActionContext;
import io.seata.rm.tcc.api.BusinessActionContextParameter;
import io.seata.rm.tcc.api.LocalTCC;
import io.seata.rm.tcc.api.TwoPhaseBusinessAction;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Slf4j
@Service
@LocalTCC
public class StorageTccServiceImpl implements StorageTccService {
@Autowired
private StorageMapper storageMapper;
@TwoPhaseBusinessAction(name = "storageDeduct", commitMethod = "confirm", rollbackMethod = "cancel",useTCCFence = true)
@Override
public void deduct(@BusinessActionContextParameter("commodityCode") String commodityCode,
@BusinessActionContextParameter("count") Integer count) {
log.info("一阶段try.....");
//扣减可⽤库存, 记录冻结库存
try {
UpdateWrapper<StorageInfo> updateWrapper = new UpdateWrapper<>();
updateWrapper.lambda().setSql("count = count - "+ count)
.setSql("freeze_count = freeze_count + " + count)
.eq(StorageInfo::getCommodityCode, commodityCode);
storageMapper.update(updateWrapper);
} catch (Exception e) {
log.error("扣减库存失败, e:", e);
throw new RuntimeException("扣减库存失败!", e);
}
}
@Override
public boolean confirm(BusinessActionContext context) {
log.info("二阶段confirm.....");
//真实扣除冻结库存
UpdateWrapper<StorageInfo> updateWrapper = new UpdateWrapper<>();
updateWrapper.lambda()
.setSql("freeze_count = freeze_count - " + context.getActionContext("count"))
.eq(StorageInfo::getCommodityCode, context.getActionContext("commodityCode"));
int result = storageMapper.update(updateWrapper);
return 1==result;
}
@Override
public boolean cancel(BusinessActionContext context) {
log.info("二阶段cancel.....");
//恢复可⽤库存, 清除冻结库存
Integer count = (Integer) context.getActionContext("count");
String commodityCode = (String) context.getActionContext("commodityCode");
UpdateWrapper<StorageInfo> updateWrapper = new UpdateWrapper<>();
updateWrapper.lambda().setSql("count = count + "+ count)
.setSql("freeze_count = freeze_count - "+ count)
.eq(StorageInfo::getCommodityCode, commodityCode);
int result = storageMapper.update(updateWrapper);
return result == 1;
}
}6.3.3.5 TCC核⼼注解及参数描述
TCC有两个核⼼注解 @TwoPhaseBusinessAction 和 @LocalTCC ,以及两个重要参数:
BusinessActionContext 和 @BusinessActionContextParameter
-
@LocalTCC
@LocalTCC 注解⽤来表⽰实现了⼆阶段提交的本地的TCC接⼝
-
BusinessActionContext
事务上下⽂。可以使⽤此⼊参在TCC模式下,在事务上下⽂中,传递查询参数。如下属性:
-
- xid 全局事务id
-
- branchId 分⽀事务id
-
- actionName 分⽀资源id, (resource id )
-
- actionContext 业务传递参数Map,可以通过@BusinessActionContextParameter来标注需要传递的参数
-
@BusinessActionContextParameter
⽤此注解标注需要在事务上下⽂中传递的参数。被此注解修饰的参数,会被设置在 BusinessActionContext中,可以在commit和rollback阶段中,可以通过BusinessActionContext的getActionContext⽅法获取传递的业务参数值。
-
@TwoPhaseBusinessAction
@TwoPhaseBusinessAction 表⽰了当前⽅法使⽤TCC模式管理事务提交,被@TwoPhaseBusinessAction 所修饰的⽅法便是Try阶段执⾏的逻辑
@TwoPhaseBusinessAction 属性说明:
-
- name:给当前事务注册了⼀个全局唯⼀的的TCC bean name。
-
- commitMethod:对应TCC模型的⼆阶段Confirm阶段执⾏的⽅法名称
-
- commitArgsClasses:commitMethod 默认的参数为BusinessActionContext,如果需要修改,需要指定commitArgsClasses
-
- rollbackMethod:对应TCC模型的⼆阶段Cancel执⾏的⽅法名称
-
- rollbackArgsClasses:rollbackMethod默认的参数为BusinessActionContext,如果需要修改,需要指定rollbackArgsClasses
-
- useTCCFence:是否启⽤栅栏功能,主要⽤于解决 TCC 模式下的幂等性、空回滚和悬挂问题。需要创建事务控制表。默认为false,即不启⽤栅栏功能。
6.4 Saga模式
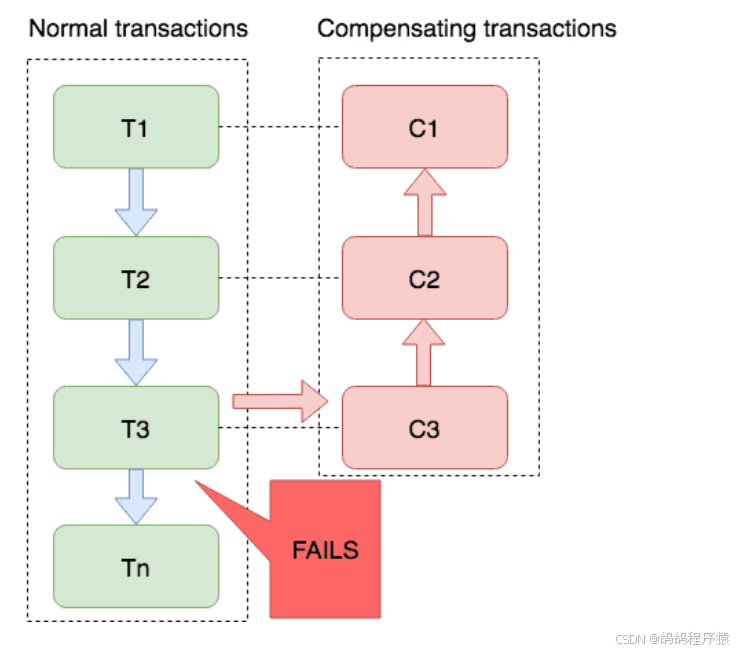
6.4.1 介绍
Saga 模式是 SEATA 提供的⻓事务解决⽅案,在 Saga 模式中,业务流程中每个参与者都提交本地事务,当出现某⼀个参与者失败则补偿前⾯已经成功的参与者,⼀阶段正向服务和⼆阶段补偿服务都由业务开发实现
6.4.2 适⽤场景及优缺点
适⽤场景:
- 业务流程⻓、业务流程多
- 参与者包含其它公司或遗留系统服务,⽆法提供 TCC 模式要求的三个接⼝
优势:
- ⼀阶段提交本地事务,⽆锁,⾼性能
- 事件驱动架构,参与者可异步执⾏,⾼吞吐
- 补偿服务易于实现
缺点:
- 不保证隔离性。⽐如⽤⼾购买⼀个商品后系统赠送⼀张优惠券,如果⽤⼾已经把优惠券使⽤了,那么事务如果出现异常要回滚时就会出现问题
6.5 四种模式对⽐
| XA | AT | TCC | SAGA | |
|---|---|---|---|---|
| 实现⽅式 | 依赖数据库对XA协议的⽀持,通过XA规范来实现事务的提交和回滚。 不需要额外的undo_log 表,但要求数据库⽀持XA协议 | 通过记录数据快照( undo_log 表)来实现数据的回滚。 适⽤于⼏乎所有的数据库,但需要在业务库中创建undo_log 表。 | 开发⼈员⼿动实现Try、Confirm、Cancel三阶段 | 事件驱动,每个事务包含正向操作和逆向补偿操作。 失败时按顺序执⾏逆向补偿 |
| ⼀致性 | 强⼀致性,事务的中间状态对⽤⼾不可⻅ | 最终⼀致性,在事务的两阶段之间,数据可能处于中间状态 | 最终⼀致性(通过业务实现) | 最终⼀致性 |
| 性能 | 性能较差,⼀阶段锁定资源,等待⼆阶段结束才释放 | 性能较好,⼀阶段直接提交,不锁定资源 | 较⾼,但开发成本⾼(需要处理空回滚,业务悬挂等) | ⾼(⽆锁),适合⻓事务 |
| 代码侵⼊ | ⽆代码侵⼊ | ⽆代码侵⼊ | 有,需要⼿动编写三个接⼝ | 有,需要编写状态机和补偿业务 |
| 数据库⽀持 | 依赖数据库对XA协议的⽀持 | 适⽤于⼏乎所有⽀持SQL的数据库 | 不依赖底层数据库的事务机制 | 不依赖底层数据库的事务机制 |