一、引言
在当今数据爆炸的时代,实时数据处理已经从"锦上添花"变成了"必不可少"。无论是监控用户行为、实时推荐、风险控制还是IoT设备监控,企业都需要能够即时处理和分析数据流的能力。而在众多流处理框架中,Kafka Streams凭借其简洁的设计和与Kafka的无缝集成,正在赢得越来越多开发者的青睐。
Kafka Streams的定位与应用场景
Kafka Streams是Apache Kafka项目的一部分,它是一个用于构建实时流处理应用的客户端库。与其他重量级流处理框架不同,Kafka Streams采用"轻量级"路线,它不需要额外的集群环境,只是一个普通的Java库,可以嵌入到任何Java应用中。
适用场景:
- 🔹 需要处理连续、无界数据流的应用
- 🔹 希望进行实时数据转换、聚合或丰富化的场景
- 🔹 需要构建事件驱动微服务的架构
- 🔹 已经使用Kafka作为消息中间件,希望实现流处理能力的系统
与其他流处理框架的对比
| 特性 | Kafka Streams | Apache Flink | Spark Streaming |
|---|---|---|---|
| 架构复杂度 | 低(仅库) | 高(独立集群) | 高(独立集群) |
| 开发难度 | 低 | 中高 | 中高 |
| 运维成本 | 低 | 高 | 高 |
| 功能完备性 | 中等 | 高 | 高 |
| 性能 | 优秀 | 卓越 | 良好 |
| 社区活跃度 | 高 | 高 | 高 |
| 与Kafka集成 | 原生 | 需适配器 | 需适配器 |
Kafka Streams就像一把瑞士军刀,虽然不如专业工具那么功能强大,但它足够锋利且便于随身携带。它不会尝试解决所有问题,而是专注于Kafka生态下的流处理需求。
为什么选择Kafka Streams进行流处理应用开发
如果你已经在使用Kafka,那么选择Kafka Streams有几个明显的优势:
- 部署简单:没有额外的服务器集群需求,直接嵌入应用
- 学习曲线平缓:使用熟悉的Kafka概念,对Kafka用户友好
- 集成无缝:原生支持Kafka的分区模型和容错机制
- 完全一致性:提供exactly-once语义保证
- 轻量级:资源占用小,适合微服务架构
正如每位大厨都有自己最常用的刀具一样,作为流处理工具,Kafka Streams虽然不是万能的,但在Kafka生态中,它往往是最称手的那一把。
接下来,让我们深入了解Kafka Streams的核心概念,看看这把"流处理利刀"的锋利之处。
二、Kafka Streams核心概念
理解Kafka Streams就像学习开车,掌握了方向盘、油门和刹车这些核心部件的功能,你就能上路了。同样,掌握几个关键概念,你就能开始构建实用的流处理应用。
流处理模型简介
在Kafka Streams中,一切都以"流"为中心。流是一个无限的、持续的事件序列。想象一条永不停歇的河流,数据像水一样持续流动,你的应用则是沿途建立的各种处理站,对流经的水进行过滤、转换或聚合。
数据源 --> [过滤] --> [转换] --> [聚合] --> 数据目的地Kafka Streams采用了处理-保存的流处理范式,每条记录都会被独立处理,应用的状态会在处理过程中被保存。
📌 核心理念:流处理就是把数据视为永不结束的事件流,而不是有限的数据集。
KStream和KTable的概念及区别
Kafka Streams提供了两种主要的抽象来处理数据:KStream和KTable。理解它们的区别是掌握Streams的关键。
KStream:
- 表示事件流(Event Stream)
- 每条记录代表一个独立事件
- 新数据不会覆盖旧数据,而是作为新事件追加
- 适合处理活动日志、传感器数据等
KTable:
- 表示更新流(Changelog Stream)
- 每条记录代表对特定键的更新
- 新数据会覆盖相同键的旧数据
- 适合表示不断变化的状态,如用户配置、商品库存等
这两种抽象就像河流和湖泊的关系:KStream像河流,每一滴水都是独立的;KTable像湖泊,同一位置的水可能被不断替换,但你总能看到最新的状态。
java
// KStream示例:记录每个事件
KStream<String, Long> clickEvents = builder.stream("user-clicks");
// KTable示例:维护最新状态
KTable<String, Long> userClickCounts = clickEvents
.groupByKey()
.count();处理器拓扑(Processor Topology)
Kafka Streams应用的核心是处理器拓扑。你可以将其想象成一张管道图,规定了数据如何从源头流向目的地,以及中间会经历哪些转换。
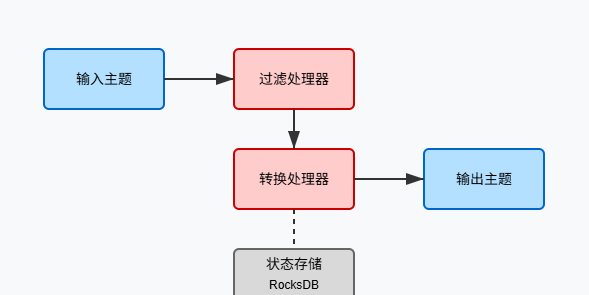
有两种构建处理器拓扑的方式:
- 高级DSL:提供函数式风格的API,如map、filter、join等
- 处理器API:提供更底层的控制,用于实现复杂的自定义逻辑
大多数应用会使用高级DSL,因为它更直观:
java
// 使用高级DSL构建处理器拓扑
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> source = builder.stream("input-topic");
KStream<String, String> processed = source
.filter((key, value) -> value.contains("important"))
.mapValues(value -> value.toUpperCase());
processed.to("output-topic");有状态与无状态操作
Kafka Streams的操作可分为有状态和无状态两种:
无状态操作:
- 不需要记住之前处理过的数据
- 每条记录的处理完全独立
- 例如:filter、map、flatMap等
- 优势:简单、高效,易于并行处理
有状态操作:
- 需要维护状态信息
- 处理依赖于之前的数据
- 例如:count、aggregate、join等
- 挑战:状态管理、容错、一致性保证
💡 实践提示:尽可能使用无状态操作,只在必要时引入有状态操作,这样可以简化应用并提高性能。
在掌握了这些核心概念后,我们就具备了使用Kafka Streams构建流处理应用的基础知识。下一步,让我们看看如何搭建开发环境,为实战做好准备。
三、Kafka Streams开发环境搭建
一个好的开发环境就像厨师的厨房,工具齐全,井井有条,才能高效地烹饪出美味佳肴。同样,配置一个合适的Kafka Streams开发环境,将为我们的流处理应用开发奠定坚实基础。
依赖配置与基础环境准备
先决条件:
- JDK 8或更高版本
- Kafka集群(或单节点开发环境)
- 熟悉Java和构建工具(Maven/Gradle)
Maven依赖配置:
xml
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>3.4.0</version> <!-- 使用与你的Kafka集群兼容的版本 -->
</dependency>
<!-- 可选:用于测试 -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams-test-utils</artifactId>
<version>3.4.0</version>
<scope>test</scope>
</dependency>Gradle依赖配置:
groovy
dependencies {
implementation 'org.apache.kafka:kafka-streams:3.4.0'
testImplementation 'org.apache.kafka:kafka-streams-test-utils:3.4.0'
}🔍 版本选择提示:尽量使用与你的Kafka集群版本匹配的Streams库版本,避免不必要的兼容性问题。
核心配置参数详解
Kafka Streams应用的行为很大程度上由其配置参数决定,就像烹饪时的火候和调料决定了菜肴的口感。以下是一些重要的配置参数:
java
Properties props = new Properties();
// 必须配置
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "my-streams-app"); // 应用ID,同时也是消费者组ID
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); // Kafka集群地址
// 序列化/反序列化配置
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
// 高级配置
props.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, 10 * 1024 * 1024); // 缓存大小,影响性能
props.put(StreamsConfig.COMMIT_INTERVAL_MS_CONFIG, 1000); // 提交间隔,影响延迟和吞吐量
props.put(StreamsConfig.NUM_STREAM_THREADS_CONFIG, 4); // 流处理线程数,影响并行度核心参数说明:
| 参数 | 说明 | 建议值 |
|---|---|---|
| APPLICATION_ID_CONFIG | 应用唯一标识,同时用作消费者组ID | 业务相关的有意义名称 |
| BOOTSTRAP_SERVERS_CONFIG | Kafka集群地址 | 生产环境应配置多个地址以提高可用性 |
| DEFAULT_KEY_SERDE_CLASS_CONFIG | 默认键序列化/反序列化器 | 根据数据类型选择适当的Serde |
| DEFAULT_VALUE_SERDE_CLASS_CONFIG | 默认值序列化/反序列化器 | 根据数据类型选择适当的Serde |
| NUM_STREAM_THREADS_CONFIG | 流处理线程数 | 通常设为CPU核心数的1-2倍 |
| STATE_DIR_CONFIG | 状态存储目录 | 在SSD上的目录,确保足够空间 |
本地开发调试技巧
开发Kafka Streams应用时,良好的调试环境能大幅提升效率。这里分享几个实用技巧:
1. 使用嵌入式Kafka进行单元测试
Kafka Streams提供了TestInputTopic和TestOutputTopic,让你可以在不依赖外部Kafka集群的情况下测试应用逻辑:
java
@Test
public void testWordCount() {
// 创建拓扑
StreamsBuilder builder = new StreamsBuilder();
// ... 构建你的拓扑
Topology topology = builder.build();
// 创建测试驱动
TopologyTestDriver testDriver = new TopologyTestDriver(topology, props);
// 创建测试主题
TestInputTopic<String, String> inputTopic = testDriver.createInputTopic(
"input-topic",
Serdes.String().serializer(),
Serdes.String().serializer()
);
TestOutputTopic<String, Long> outputTopic = testDriver.createOutputTopic(
"output-topic",
Serdes.String().deserializer(),
Serdes.Long().deserializer()
);
// 发送测试数据
inputTopic.pipeInput("key1", "hello world");
inputTopic.pipeInput("key2", "hello kafka streams");
// 验证输出
Map<String, Long> wordCounts = outputTopic.readKeyValuesToMap();
assertEquals(1L, wordCounts.get("hello").longValue());
assertEquals(1L, wordCounts.get("world").longValue());
assertEquals(1L, wordCounts.get("kafka").longValue());
assertEquals(1L, wordCounts.get("streams").longValue());
// 清理
testDriver.close();
}2. 配置日志级别获取更多调试信息
log4j.logger.org.apache.kafka=INFO
log4j.logger.org.apache.kafka.streams=DEBUG3. 使用状态存储调试器
java
// 获取状态存储以进行调试
ReadOnlyKeyValueStore<String, Long> keyValueStore =
streams.store(StoreQueryParameters.fromNameAndType(
"my-store", QueryableStoreTypes.keyValueStore()));
// 查询特定键的值
Long count = keyValueStore.get("some-key");
System.out.println("Current count: " + count);4. 开发环境使用内存状态存储
对于开发和测试,可以使用内存状态存储而不是默认的RocksDB,这样可以简化环境配置:
java
props.put(StreamsConfig.STATE_DIR_CONFIG, TestUtils.tempDirectory().getAbsolutePath());
props.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, 0); // 禁用缓存以便即时看到结果🛠️ 开发者提示 :开发阶段,将
commit.interval.ms设置较小(如100ms),可以更快看到处理结果,但不要在生产环境使用过小的值。
有了这些知识和工具,我们的Kafka Streams "厨房"已经准备就绪。接下来,让我们开始动手实践,构建一个实际的流处理应用!
四、实战案例:实时数据处理pipeline构建
理论知识已经打好基础,现在让我们脚手套膊,通过一个真实的案例来体验Kafka Streams的强大功能。就像学习游泳不能只看书,必须下水一样,只有亲自编写代码才能真正掌握流处理的精髓。
业务场景描述:用户行为数据实时分析
假设我们是一家电商平台的开发团队,需要构建一个实时分析系统,用于:
- 追踪用户点击、搜索、购买等行为
- 计算产品的实时热度指标
- 识别潜在的异常行为模式
- 为推荐系统提供实时数据支持
这些场景都非常适合使用Kafka Streams来实现。
数据流设计与架构
我们的数据流设计如下:
用户行为捕获 --> Kafka主题(user-events) --> Kafka Streams应用 -->
|--> 实时统计结果(product-stats) --> 监控仪表板
|--> 用户画像更新(user-profiles) --> 推荐系统
|--> 异常行为检测(anomaly-events) --> 风控系统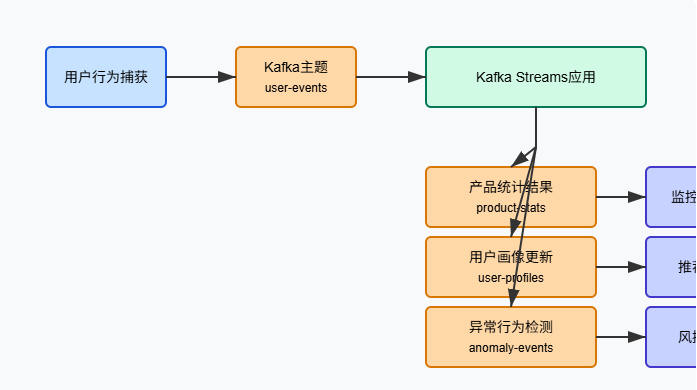
输入数据格式示例(JSON):
json
{
"userId": "user123",
"eventType": "CLICK",
"productId": "prod456",
"categoryId": "cat789",
"timestamp": 1618234760000,
"deviceType": "MOBILE",
"ipAddress": "203.0.113.1"
}核心代码实现
下面我们将实现这个流处理应用的核心部分。我们会逐步构建,从基础配置到完整功能实现。
1. 首先,配置并初始化Streams应用
java
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.*;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.kafka.common.utils.Bytes;
import org.apache.kafka.streams.state.WindowStore;
import java.time.Duration;
import java.util.Properties;
public class UserBehaviorAnalytics {
public static void main(String[] args) {
// 1. 配置流处理应用
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "user-behavior-analytics");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
// 可选配置,用于性能调优
props.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, 10 * 1024 * 1024); // 10MB缓存
props.put(StreamsConfig.COMMIT_INTERVAL_MS_CONFIG, 1000); // 1秒提交间隔
props.put(StreamsConfig.NUM_STREAM_THREADS_CONFIG, 4); // 4个处理线程
// 2. 创建JSON解析器
final ObjectMapper objectMapper = new ObjectMapper();
// 3. 构建处理器拓扑
StreamsBuilder builder = new StreamsBuilder();
// 后续代码将继续添加...2. 实现产品点击统计功能
java
// 从用户事件主题读取数据
KStream<String, String> userEvents = builder.stream("user-events");
// 解析JSON并提取关键字段
KStream<String, JsonNode> parsedEvents = userEvents
.mapValues(value -> {
try {
return objectMapper.readTree(value);
} catch (Exception e) {
// 在实际应用中应该有更好的错误处理
System.err.println("Error parsing JSON: " + e.getMessage());
return null;
}
})
.filter((key, json) -> json != null); // 过滤解析失败的记录
// 按产品ID重新分区,准备进行点击统计
KStream<String, JsonNode> productEvents = parsedEvents
.filter((key, json) -> json.has("eventType") &&
"CLICK".equals(json.get("eventType").asText()) &&
json.has("productId"))
.selectKey((key, json) -> json.get("productId").asText());
// 实现5分钟滚动窗口的产品点击计数
KTable<Windowed<String>, Long> productClickCounts = productEvents
.groupByKey()
.windowedBy(TimeWindows.of(Duration.ofMinutes(5)))
.count(Materialized.<String, Long, WindowStore<Bytes, byte[]>>as("product-clicks-store")
.withKeySerde(Serdes.String())
.withValueSerde(Serdes.Long()));
// 将窗口结果转换为可读的格式并输出到新主题
productClickCounts
.toStream()
.map((windowed, count) -> {
// 创建包含产品ID、时间窗口和计数的JSON
String productId = windowed.key();
long windowStart = windowed.window().start();
long windowEnd = windowed.window().end();
String value = String.format(
"{\"productId\":\"%s\",\"windowStart\":%d,\"windowEnd\":%d,\"clickCount\":%d}",
productId, windowStart, windowEnd, count);
return KeyValue.pair(productId, value);
})
.to("product-clicks-stats", Produced.with(Serdes.String(), Serdes.String()));3. 实现用户行为统计和分析
java
// 用户行为分析:按用户ID分组,计算各类行为的次数
KStream<String, JsonNode> userIdPartitioned = parsedEvents
.selectKey((key, json) -> json.get("userId").asText());
// 按用户ID和事件类型进行分组计数
KTable<String, Long> userEventTypeCounts = userIdPartitioned
.groupBy((userId, json) -> {
// 复合键:userId-eventType
String eventType = json.get("eventType").asText();
return userId + "-" + eventType;
}, Grouped.with(Serdes.String(),
Serdes.serdeFrom(
(topic, data) -> data.toString().getBytes(),
(topic, data) -> objectMapper.readTree(new String(data))
)))
.count(Materialized.as("user-event-counts-store"));
// 将用户行为统计结果转换为JSON并输出
userEventTypeCounts
.toStream()
.map((compoundKey, count) -> {
String[] parts = compoundKey.split("-", 2);
String userId = parts[0];
String eventType = parts[1];
String value = String.format(
"{\"userId\":\"%s\",\"eventType\":\"%s\",\"count\":%d,\"lastUpdated\":%d}",
userId, eventType, count, System.currentTimeMillis());
return KeyValue.pair(userId, value);
})
.to("user-behavior-stats", Produced.with(Serdes.String(), Serdes.String()));4. 异常行为检测
java
// 异常行为检测:识别短时间内频繁点击同一产品的行为
KStream<String, JsonNode> potentialAnomalies = userIdPartitioned
.groupBy((userId, json) -> {
// 复合键:userId-productId
String productId = json.has("productId") ? json.get("productId").asText() : "unknown";
return userId + "-" + productId;
}, Grouped.with(Serdes.String(),
Serdes.serdeFrom(
(topic, data) -> data.toString().getBytes(),
(topic, data) -> objectMapper.readTree(new String(data))
)))
.windowedBy(TimeWindows.of(Duration.ofMinutes(1)))
.count()
.toStream()
.filter((windowedKey, count) -> count >= 10) // 1分钟内点击同一产品10次以上
.map((windowedKey, count) -> {
String[] parts = windowedKey.key().split("-", 2);
String userId = parts[0];
String productId = parts[1];
String value = String.format(
"{\"userId\":\"%s\",\"productId\":\"%s\",\"clickCount\":%d,\"windowStart\":%d,\"windowEnd\":%d,\"type\":\"RAPID_CLICKS\"}",
userId, productId, count, windowedKey.window().start(), windowedKey.window().end());
return KeyValue.pair(userId, value);
});
// 输出异常行为到专门的主题
potentialAnomalies.to("anomaly-events", Produced.with(Serdes.String(), Serdes.String()));5. 启动流处理应用
java
// 构建并启动应用
KafkaStreams streams = new KafkaStreams(builder.build(), props);
// 添加关闭钩子以确保应用正常关闭
Runtime.getRuntime().addShutdownHook(new Thread(streams::close));
// 启动应用
streams.start();
// 为了演示目的,在控制台输出应用状态
System.out.println("用户行为分析应用已启动...");
}
}🚀 实战经验:在实际项目中,通常会将不同的功能模块拆分为独立的类,而不是像示例中那样全部放在一个类中。模块化设计可以大大提高代码的可维护性。
代码解析与核心逻辑说明
我们的实时分析pipeline实现了三个主要功能:
- 产品点击统计:使用滚动时间窗口统计每个产品在5分钟内的点击次数,可帮助识别热门产品
- 用户行为分析:按用户和事件类型分组统计,构建用户行为画像
- 异常行为检测:识别短时间内对同一产品的频繁点击,可能代表爬虫或自动化行为
这个示例展示了Kafka Streams的几个关键能力:
- JSON解析和过滤
- 窗口操作和聚合
- 状态管理和存储
- 流和表操作的结合
在实际应用中,你可能还需要添加错误处理、监控和测试等功能,但这个基本框架已经展示了构建实时数据处理pipeline的核心步骤。
接下来,让我们看看如何利用Kafka Streams的高级特性来增强我们的应用。
五、高级特性与优化
随着我们对Kafka Streams的基本应用愈发熟练,是时候探索一些高级特性了。这些特性就像厨师的秘方,能让我们的流处理应用更加强大、灵活和高效。
窗口操作(Windowing)实战
窗口操作是流处理中的关键概念,它允许我们在无限的数据流上执行有限的聚合操作。Kafka Streams提供了多种窗口类型:
1. 滚动窗口(Tumbling Windows)
滚动窗口将时间划分为大小相等、不重叠的窗口。适合计算固定时间段内的指标,如"每小时访问量"。
java
// 5分钟滚动窗口
KTable<Windowed<String>, Long> hourlyStats = stream
.groupByKey()
.windowedBy(TimeWindows.of(Duration.ofMinutes(5)))
.count();2. 滑动窗口(Hopping Windows)
滑动窗口可以重叠,由窗口大小和滑动间隔定义。适合计算"最近N分钟内"的指标。
java
// 5分钟窗口,每1分钟滑动一次
KTable<Windowed<String>, Long> recentStats = stream
.groupByKey()
.windowedBy(TimeWindows.ofSizeAndGrace(
Duration.ofMinutes(5), // 窗口大小
Duration.ofSeconds(30)) // 允许迟到的数据处理时间
.advanceBy(Duration.ofMinutes(1))) // 滑动间隔
.count();3. 会话窗口(Session Windows)
会话窗口基于活动空闲期来分组事件,适合用户会话分析。
java
// 用户会话窗口,30分钟不活动视为会话结束
KTable<Windowed<String>, Long> userSessions = stream
.groupByKey()
.windowedBy(SessionWindows.ofInactivityGapWithNoGrace(Duration.ofMinutes(30)))
.count();💡 窗口选择技巧:滚动窗口计算简单但粒度固定;滑动窗口更新频繁但计算重复;会话窗口自适应但计算复杂。根据业务需求选择合适的窗口类型。
Join操作与数据关联处理
在实际应用中,我们经常需要关联不同来源的数据流。Kafka Streams提供了多种Join操作:
1. Stream-Stream Join
关联两个流中的事件,需要指定时间窗口:
java
// 关联用户点击事件与搜索事件
KStream<String, String> clickStream = builder.stream("user-clicks");
KStream<String, String> searchStream = builder.stream("user-searches");
// 在5分钟窗口内关联同一用户的点击和搜索
KStream<String, String> joinedStream = clickStream.join(
searchStream,
(clickValue, searchValue) -> {
// 合并两个事件的信息
return "User clicked after searching: " + clickValue + " - " + searchValue;
},
JoinWindows.of(Duration.ofMinutes(5)), // 5分钟窗口
StreamJoined.with(
Serdes.String(), // 键的Serde
Serdes.String(), // 左值的Serde
Serdes.String() // 右值的Serde
)
);2. Stream-Table Join
使用表格数据丰富流事件,常用于查找和数据丰富:
java
// 产品信息表
KTable<String, String> productTable = builder.table("product-info");
// 用产品详细信息丰富点击事件
KStream<String, String> enrichedClickStream = clickStream
.selectKey((ignoredKey, clickValue) -> {
// 提取产品ID作为键
JsonNode clickJson = objectMapper.readTree(clickValue);
return clickJson.get("productId").asText();
})
.join(
productTable,
(clickValue, productInfo) -> {
// 将产品信息添加到点击事件
return "Enriched click: " + clickValue + " with product: " + productInfo;
}
);3. Table-Table Join
关联两个表,类似于数据库的表连接:
java
// 用户信息表
KTable<String, String> userTable = builder.table("user-info");
// 用户偏好表
KTable<String, String> preferencesTable = builder.table("user-preferences");
// 创建包含用户完整信息的综合表
KTable<String, String> userProfileTable = userTable.join(
preferencesTable,
(userInfo, preferences) -> {
// 合并用户信息和偏好
return "User profile: " + userInfo + " with preferences: " + preferences;
}
);⚠️ 实战提醒:Join操作是资源密集型的,特别是在大规模数据上。确保只关联必要的字段,并考虑使用GlobalKTable减少重分区需求。
自定义Serde开发
在处理复杂数据类型时,内置的序列化器往往不够用。开发自定义Serde能让我们无缝处理自定义对象:
java
// 1. 定义领域对象
public class UserEvent {
private String userId;
private String eventType;
private long timestamp;
// 构造函数、getter和setter
// ...
}
// 2. 实现序列化器
public class UserEventSerializer implements Serializer<UserEvent> {
private final ObjectMapper objectMapper = new ObjectMapper();
@Override
public byte[] serialize(String topic, UserEvent data) {
try {
return objectMapper.writeValueAsBytes(data);
} catch (Exception e) {
throw new SerializationException("Error serializing UserEvent", e);
}
}
}
// 3. 实现反序列化器
public class UserEventDeserializer implements Deserializer<UserEvent> {
private final ObjectMapper objectMapper = new ObjectMapper();
@Override
public UserEvent deserialize(String topic, byte[] data) {
try {
return objectMapper.readValue(data, UserEvent.class);
} catch (Exception e) {
throw new SerializationException("Error deserializing UserEvent", e);
}
}
}
// 4. 组合成Serde
public class UserEventSerde implements Serde<UserEvent> {
@Override
public Serializer<UserEvent> serializer() {
return new UserEventSerializer();
}
@Override
public Deserializer<UserEvent> deserializer() {
return new UserEventDeserializer();
}
}
// 5. 在Streams应用中使用
KStream<String, UserEvent> userEventStream = builder.stream(
"user-events",
Consumed.with(Serdes.String(), new UserEventSerde())
);🔧 开发技巧:考虑使用Jackson、Gson或Avro等成熟的序列化库来实现自定义Serde,避免重复造轮子。尤其推荐使用Avro和Schema Registry实现模式演化。
状态存储与交互查询(Interactive Queries)
Kafka Streams应用可以维护本地状态存储,并通过交互式查询API暴露这些状态:
java
// 1. 创建并配置状态存储
StoreBuilder<KeyValueStore<String, Long>> storeBuilder = Stores.keyValueStoreBuilder(
Stores.persistentKeyValueStore("user-click-counts"),
Serdes.String(),
Serdes.Long()
);
// 2. 注册状态存储
builder.addStateStore(storeBuilder);
// 3. 处理器使用状态存储
stream.process(() -> new Processor<String, UserEvent, String, Long>() {
private KeyValueStore<String, Long> stateStore;
@Override
public void init(ProcessorContext<String, Long> context) {
this.stateStore = context.getStateStore("user-click-counts");
}
@Override
public void process(Record<String, UserEvent> record) {
String userId = record.key();
Long currentCount = stateStore.get(userId);
if (currentCount == null) {
currentCount = 0L;
}
stateStore.put(userId, currentCount + 1);
}
}, "user-click-counts");
// 4. 实现REST API以查询状态
@RestController
class StateQueryController {
private final KafkaStreams streams;
@GetMapping("/user/{userId}/clicks")
public ResponseEntity<Long> getUserClickCount(@PathVariable String userId) {
// 查找包含指定键的分区
HostInfo hostInfo = streamsMetadataState.getHostInfo(userId);
// 如果数据在本地,直接查询
if (isHostInfoLocal(hostInfo)) {
ReadOnlyKeyValueStore<String, Long> store = streams.store(
StoreQueryParameters.fromNameAndType(
"user-click-counts",
QueryableStoreTypes.keyValueStore()
)
);
Long count = store.get(userId);
return ResponseEntity.ok(count != null ? count : 0L);
} else {
// 否则,将请求转发到正确的实例
return restTemplate.getForEntity(
"http://" + hostInfo.host() + ":" + hostInfo.port() + "/user/" + userId + "/clicks",
Long.class
);
}
}
}🔍 实践要点:交互式查询功能强大,但引入了分布式系统的复杂性。确保妥善处理实例间的请求路由和错误恢复。
容错与exactly-once语义保证
Kafka Streams提供了exactly-once处理语义,这在需要精确结果的场景(如金融应用)中至关重要:
java
// 启用exactly-once语义
props.put(StreamsConfig.PROCESSING_GUARANTEE_CONFIG, StreamsConfig.EXACTLY_ONCE_V2);实现exactly-once需要满足几个条件:
- Kafka集群需要配置事务协调器
- 生产者需要启用事务
- 消费者需要配置适当的隔离级别
⚠️ 权衡提示:exactly-once处理会带来一定的性能开销,对延迟敏感的应用可能需要考虑使用at-least-once语义并在应用层处理幂等性。
这些高级特性让Kafka Streams能够应对更复杂的流处理需求。下一节,我们将讨论如何优化性能并确保应用健康运行。
六、性能调优与监控
构建Kafka Streams应用就像造赛车,功能实现只是第一步,真正的挑战在于调校性能与确保稳定性。一个高效的流处理应用需要精细调优和全面监控,才能在生产环境中稳定飞驰。
关键性能指标与监控方式
1. 需要关注的核心指标
| 指标类别 | 具体指标 | 关注点 |
|---|---|---|
| 吞吐量 | 每秒处理记录数 | 应用能力上限 |
| 延迟 | 端到端处理时间 | 实时性表现 |
| 资源使用 | CPU、内存、磁盘IO | 资源瓶颈识别 |
| 处理状态 | 积压消息数量 | 处理能力与生产速率的平衡 |
| 错误率 | 处理异常、序列化错误 | 应用稳定性 |
| 再平衡 | 再平衡频率和持续时间 | 集群稳定性 |
2. 监控方式
Kafka Streams提供了丰富的内部指标,可以通过JMX导出并使用各种监控工具收集:
java
// 启用JMX监控
props.put(StreamsConfig.METRICS_RECORDING_LEVEL_CONFIG, "DEBUG");监控工具整合:
- Prometheus + Grafana:使用JMX Exporter将指标暴露给Prometheus,然后在Grafana创建仪表板
- ELK Stack:收集日志并在Kibana创建可视化
- 自定义健康检查API:
java
@RestController
class HealthController {
private final KafkaStreams streams;
@GetMapping("/health")
public ResponseEntity<Map<String, Object>> healthCheck() {
Map<String, Object> health = new HashMap<>();
// 检查Streams应用状态
KafkaStreams.State state = streams.state();
health.put("state", state.name());
health.put("healthy", state == KafkaStreams.State.RUNNING);
// 添加线程级指标
MetricName threadMetric = new MetricName(
"stream-thread-states", "stream-metrics",
"The states of all stream threads", Collections.emptyMap());
health.put("threads", streams.metrics().get(threadMetric).metricValue());
return ResponseEntity.ok(health);
}
}📊 监控建议:创建一个多层次的仪表板,包含应用级视图(总吞吐量、错误率)、流级视图(各主题处理率)和基础设施视图(JVM、主机资源)。
常见性能瓶颈分析
在实际项目中,我们经常遇到几类性能瓶颈,以下是识别和解决这些问题的方法:
1. 数据倾斜
症状:部分分区处理速度显著慢于其他分区,造成整体延迟。
解决方法:
- 检查键的分布,避免"热键"问题
- 考虑使用复合键或哈希函数改善分布
- 示例代码:
java
// 改善键分布的技巧
KStream<String, String> betterDistributedStream = inputStream
.selectKey((key, value) -> {
// 对高频键添加随机后缀,分散负载
if (isHotKey(key)) {
return key + "-" + ThreadLocalRandom.current().nextInt(10);
}
return key;
});2. 序列化/反序列化开销
症状:CPU使用率高,但吞吐量不成比例地低。
解决方法:
- 使用更高效的序列化格式(如Avro、Protobuf代替JSON)
- 优化自定义Serde实现
- 减少不必要的数据传输
java
// 使用高效的Avro序列化
final Map<String, String> serdeConfig = Collections.singletonMap(
AbstractKafkaSchemaSerDeConfig.SCHEMA_REGISTRY_URL_CONFIG,
"http://schema-registry:8081");
final SpecificAvroSerde<UserEvent> userEventSerde = new SpecificAvroSerde<>();
userEventSerde.configure(serdeConfig, false);
KStream<String, UserEvent> efficientStream = builder.stream(
"user-events",
Consumed.with(Serdes.String(), userEventSerde)
);3. 窗口计算资源消耗
症状:内存使用高,可能出现OOM;或磁盘IO高,影响处理速度。
解决方法:
- 调整窗口大小和保留时间
- 限制保留的窗口数量
- 增加RocksDB缓存大小
java
// 优化窗口操作配置
TimeWindows optimizedWindows = TimeWindows
.ofSizeAndGrace(Duration.ofMinutes(5), Duration.ofMinutes(1))
.advanceBy(Duration.ofMinutes(1));
// 配置RocksDB
props.put(StreamsConfig.ROCKSDB_CONFIG_SETTER_CLASS_CONFIG, CustomRocksDBConfig.class.getName());
// 自定义RocksDB配置
public class CustomRocksDBConfig implements RocksDBConfigSetter {
@Override
public void setConfig(String storeName, Options options, Map<String, Object> configs) {
BlockBasedTableConfig tableConfig = new BlockBasedTableConfig();
tableConfig.setBlockCacheSize(64 * 1024 * 1024L); // 64MB缓存
tableConfig.setBlockSize(4 * 1024); // 4KB块大小
options.setTableFormatConfig(tableConfig);
options.setMaxWriteBufferNumber(3);
}
}内存使用优化
Kafka Streams应用的内存使用主要分为几个部分:
- 应用内存:Java堆空间用于流处理逻辑
- 缓存内存:用于批处理和优化
- RocksDB内存:用于状态存储(在有状态操作中)
内存优化策略:
java
// 1. 调整缓存大小
props.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, 10 * 1024 * 1024); // 10MB
// 2. 使用堆外内存存储状态(对大状态应用有益)
props.put(StreamsConfig.ROCKSDB_CONFIG_SETTER_CLASS_CONFIG, CustomRocksDBConfig.class.getName());
// 3. JVM配置优化
// -Xms4g -Xmx4g -XX:+UseG1GC -XX:MaxGCPauseMillis=20🧠 内存管理技巧:不要过度配置缓存,尤其是在内存受限的环境中。适当的缓存大小可以提高性能,但过大可能导致频繁GC甚至OOM。
线程模型与并行度调整
Kafka Streams的并行处理由两层决定:
- 分区并行度:Kafka主题的分区数决定了最大并行度
- 线程并行度:Streams应用中的处理线程数
并行度优化:
java
// 调整处理线程数
props.put(StreamsConfig.NUM_STREAM_THREADS_CONFIG, 8);
// 确保主题有足够的分区
AdminClient adminClient = AdminClient.create(adminProps);
NewTopic newTopic = new NewTopic(
"high-volume-topic",
24, // 24个分区,支持更高并行度
(short) 3 // 复制因子
);
adminClient.createTopics(Collections.singleton(newTopic));最佳线程配置策略:
- 基础规则:线程数 = CPU核心数 * (1 + 磁盘/网络IO等待比例)
- 测试调整:从CPU核心数开始,逐步增加,监控吞吐量变化
- 注意事项:线程过多会导致上下文切换开销增加,性能反而下降
💻 硬件匹配提示:处理线程数不应超过物理CPU核心的2倍。增加线程数可能不会线性提升性能,找到拐点很重要。
通过正确监控、识别瓶颈并优化关键参数,我们的Kafka Streams应用能够以最佳状态运行。下一节,我们将探讨如何将优化后的应用部署到生产环境,并确保其稳定运行。
七、生产环境部署与运维
将精心构建的Kafka Streams应用部署到生产环境,就像将一艘船推向大海。即使船的设计再好,没有适当的航行规划和应对风浪的措施,也可能在真实环境中遇到各种挑战。本节将分享关于生产环境部署与运维的实战经验,帮助你的应用安全稳定地航行。
应用打包与部署最佳实践
1. 构建自包含JAR
使用Maven或Gradle打包时,确保创建"fat JAR"或"uber JAR",包含所有依赖:
xml
<!-- Maven Shade插件配置 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.example.KafkaStreamsApplication</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
groovy
// Gradle Shadow插件配置
plugins {
id 'com.github.johnrengelman.shadow' version '7.1.2'
}
shadowJar {
archiveBaseName.set('kafka-streams-app')
archiveVersion.set('1.0.0')
archiveClassifier.set('')
manifest {
attributes 'Main-Class': 'com.example.KafkaStreamsApplication'
}
}2. 容器化部署
使用Docker可以简化部署并确保环境一致性:
dockerfile
FROM openjdk:11-jre-slim
WORKDIR /app
# 添加应用jar
COPY target/kafka-streams-app-1.0.0.jar /app/app.jar
# 配置JVM参数
ENV JAVA_OPTS="-Xms1g -Xmx2g -XX:+UseG1GC -XX:MaxGCPauseMillis=20"
# 健康检查
HEALTHCHECK --interval=30s --timeout=3s --retries=3 \
CMD curl -f http://localhost:8080/health || exit 1
# 启动应用
CMD java $JAVA_OPTS -jar app.jar3. 配置外部化
将配置从代码中分离,支持不同环境:
java
// 从环境变量或配置文件加载配置
private Properties loadConfig() {
Properties props = new Properties();
// 基础配置
props.put(StreamsConfig.APPLICATION_ID_CONFIG,
System.getenv().getOrDefault("STREAMS_APPLICATION_ID", "my-streams-app"));
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,
System.getenv().getOrDefault("KAFKA_BOOTSTRAP_SERVERS", "localhost:9092"));
// 高级配置,使用Spring配置或配置文件
if (System.getenv("CONFIG_FILE") != null) {
try (InputStream is = new FileInputStream(System.getenv("CONFIG_FILE"))) {
props.load(is);
} catch (IOException e) {
throw new RuntimeException("Failed to load config file", e);
}
}
return props;
}📦 部署提示:为不同环境(开发、测试、生产)创建不同的配置文件,但保持部署流程一致,减少环境差异带来的问题。
扩展与伸缩策略
Kafka Streams应用的扩展性是其核心优势之一,但需要正确理解和应用扩展策略:
1. 水平扩展
Kafka Streams应用可以通过增加实例数量水平扩展,前提是主题有足够的分区:
# Kubernetes部署示例(deployment.yaml片段)
apiVersion: apps/v1
kind: Deployment
metadata:
name: kafka-streams-app
spec:
replicas: 3 # 运行3个实例
selector:
matchLabels:
app: kafka-streams-app
template:
metadata:
labels:
app: kafka-streams-app
spec:
containers:
- name: streams
image: kafka-streams-app:1.0.0
env:
- name: STREAMS_APPLICATION_ID
value: "production-streams-app"
- name: KAFKA_BOOTSTRAP_SERVERS
value: "kafka-broker-1:9092,kafka-broker-2:9092,kafka-broker-3:9092"自动扩展:
yaml
# Kubernetes HPA配置
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: kafka-streams-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: kafka-streams-app
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 702. 扩展时的注意事项
- 分区与并行度:确保主题分区数不少于实例总线程数
- 状态迁移:扩展时会触发再平衡,状态会重新分配,过程中性能可能暂时下降
- 优雅扩展:采用逐步扩展策略,避免一次添加过多实例
⚖️ 扩展策略提示:主动扩展优于被动扩展。监控队列积压情况,在高峰期前提前扩展,而不是等到系统已经过载。
故障恢复机制
Kafka Streams应用的韧性来自于其内置的故障恢复能力,但合理配置才能最大化这一优势:
1. 本地状态存储备份
Kafka Streams自动将本地状态存储变更记录到内部主题,确保实例重启或迁移时能恢复状态:
java
// 配置更高的复制因子以增强可靠性
props.put(StreamsConfig.REPLICATION_FACTOR_CONFIG, 3);2. 错误处理与死信队列
处理不可避免的错误记录,避免整个流处理被阻塞:
java
// 全局异常处理器
props.put(StreamsConfig.DEFAULT_DESERIALIZATION_EXCEPTION_HANDLER_CLASS_CONFIG,
CustomDeserializationExceptionHandler.class.getName());
// 实现自定义异常处理器
public class CustomDeserializationExceptionHandler implements DeserializationExceptionHandler {
private final KafkaProducer<byte[], byte[]> deadLetterProducer;
public CustomDeserializationExceptionHandler() {
Properties producerProps = new Properties();
producerProps.put("bootstrap.servers", "kafka:9092");
producerProps.put("key.serializer", "org.apache.kafka.common.serialization.ByteArraySerializer");
producerProps.put("value.serializer", "org.apache.kafka.common.serialization.ByteArraySerializer");
this.deadLetterProducer = new KafkaProducer<>(producerProps);
}
@Override
public DeserializationHandlerResponse handle(ProcessorContext context,
ConsumerRecord<byte[], byte[]> record,
Exception exception) {
// 记录错误
log.error("Failed to deserialize record", exception);
// 发送到死信队列
deadLetterProducer.send(new ProducerRecord<>("dead-letter-queue",
record.key(), record.value()));
// 继续处理下一条记录
return DeserializationHandlerResponse.CONTINUE;
}
}3. 应用健康监测与自动重启
利用容器编排系统实现自动健康检查和重启:
yaml
# Kubernetes存活探针
livenessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 60
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3🛡️ 韧性提示:不要过度依赖自动重启。虽然Kafka Streams应用具有较强的容错能力,但频繁重启可能导致性能下降。优先解决根本问题。
滚动更新与版本管理
应用升级是运维过程中必不可少的环节,合理的更新策略可以确保服务不中断:
1. 滚动更新策略
在Kubernetes中配置滚动更新:
yaml
spec:
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 25%
maxSurge: 25%2. 版本兼容注意事项
- 拓扑变更:更改处理拓扑可能影响状态兼容性
- 状态存储版本:确保新版本能正确处理旧版本的状态
- 序列化兼容性:维持序列化格式的向前和向后兼容
3. 版本管理最佳实践
java
// 在核心类添加版本注释
/**
* User Behavior Analytics Application
*
* Version History:
* - 1.0.0: Initial implementation
* - 1.1.0: Added anomaly detection
* - 1.2.0: Optimized state stores
* - 2.0.0: Breaking change - new event format
*
* Current Version: 2.0.0
*/
public class UserBehaviorAnalytics {
// 应用代码...
}🔄 升级建议:对于重大架构变更,考虑使用新的应用ID部署并行版本,然后逐步迁移流量,而不是直接更新现有应用。
通过这些生产环境部署与运维策略,你的Kafka Streams应用不仅能在理想条件下运行,还能在复杂多变的生产环境中保持稳定性和可靠性。下一节,我们将分享在实际项目中积累的踩坑经验和解决方案。
八、实战踩坑经验与解决方案
在Kafka Streams开发之路上,即使是经验丰富的开发者也常常会遇到各种坑洼。这些挑战就像江湖中的险阻,唯有亲身经历才能领悟其中奥妙。本节将分享我们在实际项目中遇到的常见问题及解决方案,希望能为你的旅程提供一些指引。
状态存储与RocksDB相关问题
踩坑一:RocksDB内存溢出
现象:应用运行一段时间后突然崩溃,日志中出现RocksDB相关的内存错误。
原因:RocksDB默认配置不适合大规模状态处理,特别是在内存受限环境中。
解决方案:
java
// 自定义RocksDB配置
public class OptimizedRocksDBConfig implements RocksDBConfigSetter {
@Override
public void setConfig(String storeName, Options options, Map<String, Object> configs) {
// 限制写缓冲区大小和数量
options.setWriteBufferSize(64 * 1024 * 1024); // 64MB
options.setMaxWriteBufferNumber(3);
// 配置表格格式
BlockBasedTableConfig tableConfig = new BlockBasedTableConfig();
tableConfig.setBlockCacheSize(32 * 1024 * 1024); // 32MB
tableConfig.setBlockSize(16 * 1024); // 16KB
tableConfig.setCacheIndexAndFilterBlocks(true);
options.setTableFormatConfig(tableConfig);
// 启用压缩以节省空间
options.setCompressionType(CompressionType.LZ4_COMPRESSION);
// 限制后台任务
options.setMaxBackgroundCompactions(1);
options.setMaxBackgroundFlushes(1);
}
@Override
public void close(String storeName, Options options) {
// 清理资源
}
}
// 在Streams配置中应用
props.put(StreamsConfig.ROCKSDB_CONFIG_SETTER_CLASS_CONFIG,
OptimizedRocksDBConfig.class.getName());实战经验:
💡 监控RocksDB的内存使用情况是必要的,因为它使用堆外内存,不会在标准JVM内存监控中显示。考虑使用jemalloc等工具追踪堆外内存使用。
踩坑二:状态存储目录权限问题
现象:容器化环境中,应用启动失败,报错无法创建或访问状态目录。
原因:容器用户权限与挂载卷权限不匹配。
解决方案:
dockerfile
# 在Dockerfile中设置适当的权限
FROM openjdk:11-jre-slim
# 创建专用用户
RUN groupadd -r kafkauser && useradd -r -g kafkauser kafkauser
# 创建状态目录并设置权限
RUN mkdir -p /var/lib/kafka-streams && chown -R kafkauser:kafkauser /var/lib/kafka-streams
# 切换到应用用户
USER kafkauser
# 配置状态目录
ENV STATE_DIR=/var/lib/kafka-streams
# 启动命令
CMD java -jar app.jarKubernetes配置:
yaml
volumeMounts:
- name: kafka-streams-data
mountPath: /var/lib/kafka-streams
volumes:
- name: kafka-streams-data
persistentVolumeClaim:
claimName: kafka-streams-pvc实战经验:
🔒 在生产环境中,状态目录应使用持久化存储,并确保有足够的磁盘空间。监控磁盘使用情况,避免空间耗尽导致应用崩溃。
再平衡(Rebalance)引起的问题及解决方法
踩坑三:频繁再平衡导致性能下降
现象:应用性能周期性降低,日志中频繁出现再平衡相关信息。
原因:消费者会话超时设置不合理,网络波动或GC暂停触发不必要的再平衡。
解决方案:
java
// 调整会话超时和心跳间隔
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 60000); // 60秒
props.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, 20000); // 20秒
// 设置更宽松的消费超时
props.put(StreamsConfig.MAX_POLL_INTERVAL_MS_CONFIG, 300000); // 5分钟
// 优化GC
// JVM参数: -XX:+UseG1GC -XX:MaxGCPauseMillis=20实战经验:
⚖️ 再平衡设置是一种权衡:超时时间过短,轻微网络波动就会触发再平衡;过长则在实例真正失败时恢复太慢。根据应用特性和环境稳定性调整。
踩坑四:再平衡后状态恢复慢导致服务不可用
现象:扩展实例或重启后,应用需要很长时间才能恢复正常处理能力。
原因:状态需要从更改日志主题重建,大状态恢复耗时长。
解决方案:
- 优化存储配置:
java
// 增加状态存储的日志紧凑频率
props.put(TopicConfig.CLEANUP_POLICY_CONFIG, TopicConfig.CLEANUP_POLICY_COMPACT);
props.put(TopicConfig.MIN_COMPACTION_LAG_MS_CONFIG, "0");
props.put(TopicConfig.MAX_COMPACTION_LAG_MS_CONFIG, "3600000"); // 1小时- 实现优雅启动:
java
// 应用启动类中添加预热逻辑
public class GracefulKafkaStreamsApp {
public static void main(String[] args) {
// ... 配置和拓扑创建 ...
KafkaStreams streams = new KafkaStreams(topology, props);
// 添加状态监听器
CountDownLatch stateChangeLatch = new CountDownLatch(1);
streams.setStateListener((newState, oldState) -> {
if (newState == KafkaStreams.State.RUNNING) {
stateChangeLatch.countDown();
}
});
// 启动应用
streams.start();
// 等待应用完全启动
try {
if (!stateChangeLatch.await(5, TimeUnit.MINUTES)) {
log.warn("Application didn't reach RUNNING state within timeout");
} else {
log.info("Application is now fully operational");
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
// 启动REST服务或其他依赖Streams的组件
startRestService();
}
}实战经验:
🚦 使用状态指示器控制流量接入。在实例完全恢复状态前,可以通过健康检查API返回"未就绪"状态,防止负载均衡器过早发送请求。
反序列化异常处理
踩坑五:恶劣数据导致流处理中断
现象:少量错误格式数据导致整个流处理停止,且无法自动恢复。
原因:默认配置下,反序列化异常会停止处理器。
解决方案:
java
// 自定义异常处理器,实现更健壮的处理逻辑
public class ProductionDeserializationHandler implements DeserializationExceptionHandler {
private static final Logger log = LoggerFactory.getLogger(ProductionDeserializationHandler.class);
private int problemRecordCount = 0;
private final AtomicLong lastLoggedTime = new AtomicLong(0);
private final KafkaProducer<byte[], byte[]> dlqProducer;
public ProductionDeserializationHandler() {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, ByteArraySerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, ByteArraySerializer.class);
dlqProducer = new KafkaProducer<>(props);
}
@Override
public DeserializationHandlerResponse handle(
ProcessorContext context,
ConsumerRecord<byte[], byte[]> record,
Exception exception) {
// 记录错误数据,但限制日志频率
problemRecordCount++;
long now = System.currentTimeMillis();
long lastLogged = lastLoggedTime.get();
if (now - lastLogged > 60000 && lastLoggedTime.compareAndSet(lastLogged, now)) {
log.warn("累计处理 {} 条错误记录,最近错误:{}",
problemRecordCount, exception.getMessage());
}
// 将问题记录发送到死信队列
try {
dlqProducer.send(new ProducerRecord<>("streams-deserialization-errors",
record.key(), record.value()));
} catch (Exception e) {
log.error("无法发送到死信队列", e);
}
// 记录问题记录的元数据,以便后续分析
Map<String, Object> metadata = new HashMap<>();
metadata.put("topic", record.topic());
metadata.put("partition", record.partition());
metadata.put("offset", record.offset());
metadata.put("timestamp", record.timestamp());
metadata.put("error", exception.getClass().getName());
metadata.put("message", exception.getMessage());
try {
String metadataJson = new ObjectMapper().writeValueAsString(metadata);
dlqProducer.send(new ProducerRecord<>("streams-error-metadata",
record.key(), metadataJson.getBytes()));
} catch (Exception e) {
log.error("无法记录错误元数据", e);
}
// 继续处理下一条记录
return DeserializationHandlerResponse.CONTINUE;
}
}
// 在Streams配置中应用
props.put(StreamsConfig.DEFAULT_DESERIALIZATION_EXCEPTION_HANDLER_CLASS_CONFIG,
ProductionDeserializationHandler.class.getName());实战经验:
🛑 处理异常数据时,记录足够的上下文信息至关重要。除了发送到死信队列,还应该保存发生异常的主题、分区、偏移量等元数据,以便后续排查和修复。
踩坑六:Schema演化导致的兼容性问题
现象:部署新版本应用后,开始出现序列化异常,但旧版本应用运行正常。
原因:数据模式变更没有保持向前/向后兼容性。
解决方案:
- 使用支持模式演化的序列化格式:
java
// 使用Avro + Schema Registry确保兼容性
final SchemaRegistryClient schemaRegistry = new CachedSchemaRegistryClient(
"http://schema-registry:8081", 100);
final Map<String, String> schemaRegistryConfig = new HashMap<>();
schemaRegistryConfig.put(
AbstractKafkaSchemaSerDeConfig.SCHEMA_REGISTRY_URL_CONFIG,
"http://schema-registry:8081");
// 为UserEvent配置Avro序列化
final SpecificAvroSerde<UserEvent> userEventSerde = new SpecificAvroSerde<>(schemaRegistry);
userEventSerde.configure(schemaRegistryConfig, false); // false表示这是值序列化器
// 在拓扑中使用
builder.stream(
"user-events",
Consumed.with(Serdes.String(), userEventSerde)
);- 实现向后兼容的自定义反序列化器:
java
public class VersionAwareDeserializer<T> implements Deserializer<T> {
private final ObjectMapper mapper = new ObjectMapper();
private final Class<T> targetClass;
public VersionAwareDeserializer(Class<T> targetClass) {
this.targetClass = targetClass;
// 配置忽略未知属性,实现向前兼容
mapper.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false);
// 配置缺失属性使用默认值,实现向后兼容
mapper.configure(DeserializationFeature.FAIL_ON_NULL_FOR_PRIMITIVES, false);
}
@Override
public T deserialize(String topic, byte[] data) {
if (data == null) return null;
try {
return mapper.readValue(data, targetClass);
} catch (Exception e) {
throw new SerializationException("Error deserializing data", e);
}
}
}实战经验:
📝 建立严格的模式演化规则:只允许添加带默认值的新字段,不允许删除或重命名字段,不改变字段类型。Schema Registry能强制执行这些规则。
资源消耗过高排查方法
踩坑七:CPU异常高负载
现象:应用CPU使用率异常高,但吞吐量没有相应提升。
原因:可能是密集型操作、死循环或GC问题。
排查解决方案:
java
// 1. 启用JMX监控
props.put(StreamsConfig.METRICS_RECORDING_LEVEL_CONFIG, "DEBUG");
// 2. 添加性能监控切面
public class PerformanceMonitoringProcessorSupplier<K, V> implements ProcessorSupplier<K, V, K, V> {
private final String operationName;
public PerformanceMonitoringProcessorSupplier(String operationName) {
this.operationName = operationName;
}
@Override
public Processor<K, V, K, V> get() {
return new PerformanceMonitoringProcessor();
}
private class PerformanceMonitoringProcessor implements Processor<K, V, K, V> {
private ProcessorContext<K, V> context;
private final Map<String, DescriptiveStatistics> statistics = new HashMap<>();
private final ScheduledExecutorService scheduler = Executors.newSingleThreadScheduledExecutor();
@Override
public void init(ProcessorContext<K, V> context) {
this.context = context;
statistics.put("processingTime", new DescriptiveStatistics(1000));
// 每分钟输出统计信息
scheduler.scheduleAtFixedRate(() -> {
DescriptiveStatistics stats = statistics.get("processingTime");
log.info("{} - Avg: {} ms, 95p: {} ms, Max: {} ms, Count: {}",
operationName,
stats.getMean(),
stats.getPercentile(95),
stats.getMax(),
stats.getN());
}, 1, 1, TimeUnit.MINUTES);
}
@Override
public void process(Record<K, V> record) {
long start = System.nanoTime();
context.forward(record);
long time = (System.nanoTime() - start) / 1_000_000; // 转为毫秒
statistics.get("processingTime").addValue(time);
}
@Override
public void close() {
scheduler.shutdown();
}
}
}
// 在拓扑中使用
stream.process(new PerformanceMonitoringProcessorSupplier<>("KeyOperation"));- 使用飞行记录器分析:
bash
# 创建飞行记录
jcmd <pid> JFR.start name=StreamsProfile settings=profile duration=120s filename=streams.jfr
# 分析记录
jmc -open streams.jfr实战经验:
🔍 对于CPU密集型操作,考虑使用缓存减少重复计算,或将复杂计算迁移到预处理步骤中,避免在流处理路径上执行。
踩坑八:内存泄漏导致OOM
现象:应用运行数天后内存占用持续增长,最终OOM。
原因:自定义处理器中的集合或缓存无限增长。
解决方案:
java
// 使用有界缓存替代无界集合
public class BoundedCacheProcessor<K, V> implements Processor<K, V, K, V> {
private ProcessorContext<K, V> context;
private final LoadingCache<String, Object> cache;
public BoundedCacheProcessor() {
this.cache = CacheBuilder.newBuilder()
.maximumSize(10_000) // 最大缓存项
.expireAfterWrite(1, TimeUnit.HOURS) // 写入1小时后过期
.recordStats() // 记录统计信息
.build(new CacheLoader<String, Object>() {
@Override
public Object load(String key) throws Exception {
return computeExpensiveValue(key);
}
});
}
@Override
public void init(ProcessorContext<K, V> context) {
this.context = context;
// 定期记录缓存统计信息
context.schedule(Duration.ofMinutes(5), PunctuationType.WALL_CLOCK_TIME, timestamp -> {
CacheStats stats = cache.stats();
log.info("Cache stats - Hit rate: {}, Eviction count: {}, Size: {}",
stats.hitRate(), stats.evictionCount(), cache.size());
});
}
@Override
public void process(Record<K, V> record) {
try {
// 使用缓存而非无限增长的集合
Object enrichment = cache.get(record.key().toString());
// 处理记录...
context.forward(record);
} catch (Exception e) {
log.error("处理失败", e);
}
}
}
// 在堆外内存使用JemAlloc
// 添加JVM参数: -XX:+UnlockExperimentalVMOptions -XX:+UseJEMalloc实战经验:
📉 设置内存使用上限并监控内存曲线。如果看到内存使用持续增长且没有回落(即使在低峰期),很可能存在内存泄漏。使用MAT或YourKit等工具分析堆快照。
处理器拓扑设计不合理导致的性能问题
踩坑九:过度重分区影响性能
现象:应用吞吐量低,CPU利用率不高,网络IO占用大。
原因 :拓扑设计中有过多不必要的重分区操作(如selectKey、groupBy等)。
解决方案:
原始拓扑:
java
// 原始性能低下的拓扑
KStream<String, String> source = builder.stream("input-topic");
// 步骤1: 按用户ID分组
KStream<String, String> userStream = source
.selectKey((key, value) -> extractUserId(value));
// 步骤2: 过滤并按产品分组
KStream<String, String> productStream = userStream
.filter((key, value) -> isValidEvent(value))
.selectKey((key, value) -> extractProductId(value));
// 步骤3: 再次按用户分组进行统计
KTable<String, Long> userStats = productStream
.selectKey((key, value) -> extractUserId(value))
.groupByKey()
.count();优化后拓扑:
java
// 优化后的拓扑,减少重分区
KStream<String, String> source = builder.stream("input-topic");
// 提前过滤无效事件
KStream<String, String> validEvents = source
.filter((key, value) -> isValidEvent(value));
// 使用复合键值对象保留多个键信息,避免重分区
KStream<String, KeyValuePair<String, String>> enrichedStream = validEvents
.map((key, value) -> {
String userId = extractUserId(value);
String productId = extractProductId(value);
return KeyValue.pair(userId, new KeyValuePair<>(productId, value));
});
// 用户统计直接使用userId作为键
KTable<String, Long> userStats = enrichedStream
.groupByKey()
.count();
// 产品统计使用一次显式重分区
KTable<String, Long> productStats = enrichedStream
.selectKey((userId, data) -> data.key) // 只有一次重分区
.groupByKey()
.count();实战经验:
📊 使用拓扑可视化工具帮助识别重分区点。一些工具可以根据Streams应用的描述生成拓扑图,高亮显示数据流动路径和重分区操作。
踩坑十:批量处理不当导致延迟波动
现象:处理延迟不稳定,有时候记录处理很快,有时候突然变慢。
原因:默认的缓冲和提交配置可能导致批处理不稳定。
解决方案:
java
// 平衡批处理大小和延迟
// 减小处理批处理,提高响应性
props.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, 1024 * 1024); // 1MB
props.put(StreamsConfig.COMMIT_INTERVAL_MS_CONFIG, 100); // 100ms
// 对时间敏感的场景,使用基于消息数的触发器而非仅基于时间
KStream<String, String> stream = builder.stream("input-topic");
// 在窗口中实现消息计数触发
stream
.groupByKey()
.windowedBy(TimeWindows.of(Duration.ofMinutes(5)))
.count(Materialized.as("counts-store"))
.toStream()
.filter((windowedKey, count) -> count != null && count > 0)
.map((windowedKey, count) -> {
// ... 处理结果
return KeyValue.pair(windowedKey.key(), result);
})
.to("output-topic");
// 自定义触发器可以使用Processor API实现实战经验:
⏱️ 延迟与吞吐量往往是互相权衡的。较小的缓冲和提交间隔会降低延迟但可能减少吞吐量。根据应用需求(实时性 vs 处理量)调整这些参数。
通过这些实战踩坑经验,你可以避免许多常见的Kafka Streams陷阱,使应用更加健壮和高效。下一节,我们将分享一些真实项目的案例,展示Kafka Streams如何解决实际业务问题。
九、实际项目案例分享
理论知识和实战经验固然重要,但没有什么比真实项目案例更能展示技术的实际价值。就像一位厨师不仅需要知道厨艺理论,更需要能做出美味佳肴一样,我们需要了解Kafka Streams在实际业务中的应用效果。本节将分享几个真实项目案例,展示Kafka Streams如何在不同场景中发挥作用。
电商平台实时数据分析系统
业务背景 :
某大型电商平台需要实时分析用户行为和销售数据,为营销决策和个性化推荐提供支持。传统的批处理分析已无法满足业务需求,尤其在大促活动期间,需要分钟级响应来调整营销策略。
技术挑战:
- 处理峰值超过10万TPS的用户行为事件
- 需要关联多个数据源(用户信息、商品目录、库存状态)
- 大促期间系统负载波动大,需要弹性扩展
- 结果需要实时写入多个存储系统(Redis、ElasticSearch、HBase)
Kafka Streams解决方案:
1. 处理拓扑设计:
java
// 简化版处理拓扑
StreamsBuilder builder = new StreamsBuilder();
// 加载商品目录作为KTable(类似维度表)
KTable<String, ProductInfo> productTable = builder
.table("product-catalog", Consumed.with(Serdes.String(), productInfoSerde));
// 加载用户信息作为GlobalKTable(广播到所有实例)
GlobalKTable<String, UserProfile> userProfileTable = builder
.globalTable("user-profiles", Consumed.with(Serdes.String(), userProfileSerde));
// 主事件流处理
KStream<String, UserEvent> userEvents = builder
.stream("user-events", Consumed.with(Serdes.String(), userEventSerde))
.filter((key, event) -> event != null && event.getUserId() != null);
// 1. 商品浏览分析
KStream<String, ProductViewEvent> enrichedProductViews = userEvents
.filter((key, event) -> "VIEW".equals(event.getEventType()))
// 关联用户信息
.join(userProfileTable,
(eventKey, event) -> event.getUserId(), // 用于关联的键
(event, userProfile) -> enrichWithUserProfile(event, userProfile))
// 关联商品信息
.selectKey((key, event) -> event.getProductId())
.join(productTable,
(event, product) -> enrichWithProductInfo(event, product));
// 商品浏览统计
enrichedProductViews
.map((key, event) -> {
String category = event.getProductCategory();
String userSegment = event.getUserSegment();
// 复合键:类别-用户细分
return KeyValue.pair(category + "-" + userSegment, event);
})
.groupByKey()
.windowedBy(TimeWindows.of(Duration.ofMinutes(5)))
.count()
.toStream()
.map((windowedKey, count) -> {
String[] parts = windowedKey.key().split("-", 2);
String category = parts[0];
String userSegment = parts[1];
CategoryViewStat stat = new CategoryViewStat();
stat.setCategory(category);
stat.setUserSegment(userSegment);
stat.setCount(count);
stat.setWindowStart(windowedKey.window().start());
stat.setWindowEnd(windowedKey.window().end());
return KeyValue.pair(windowedKey.key(), stat);
})
.to("category-view-stats", Produced.with(Serdes.String(), categoryViewStatSerde));
// 2. 实时转化率分析
KStream<String, ConversionEvent> conversionEvents = userEvents
.filter((key, event) -> "PURCHASE".equals(event.getEventType()));
// 使用会话窗口跟踪用户行为路径
KTable<Windowed<String>, UserActivitySession> userSessions = userEvents
.selectKey((key, event) -> event.getUserId())
.groupByKey()
.windowedBy(SessionWindows.with(Duration.ofMinutes(30)))
.aggregate(
UserActivitySession::new,
(key, event, session) -> {
session.addEvent(event);
return session;
},
(key, session1, session2) -> {
session1.merge(session2);
return session1;
},
Materialized.with(Serdes.String(), userActivitySessionSerde)
);
// 计算转化路径和漏斗分析
userSessions
.toStream()
.filter((key, session) -> session.isComplete()) // 只处理完成的会话
.map((key, session) -> {
ConversionPathAnalysis analysis = analyzeConversionPath(session);
return KeyValue.pair(session.getEntryPoint(), analysis);
})
.to("conversion-analysis", Produced.with(Serdes.String(), conversionPathAnalysisSerde));2. 扩展架构:
+----------------+ +-------------------+ +-------------------+
| Kafka Clusters | -> | Streams App Pool | -> | Results Producers |
| (多区域部署) | | (K8s自动扩缩容) | | (多目标系统适配器) |
+----------------+ +-------------------+ +-------------------+
| | |
v v v
+----------------+ +-------------------+ +-------------------+
| 监控与告警系统 | | 状态存储 (RocksDB) | | 实时数据API服务 |
+----------------+ +-------------------+ +-------------------+3. 性能优化关键点:
- 利用GlobalKTable减少小表的重分区需求
- 使用优化的RocksDB配置处理大状态存储
- 实现自适应批处理策略,在低流量时优化延迟,高流量时优化吞吐量
- 针对热键问题实现自定义分区策略
业务成果:
- 将数据分析延迟从小时级降至秒级
- 大促期间系统自动扩展,成功处理20万TPS的峰值
- 实时监控转化漏斗,帮助调整营销策略,提高转化率18%
- 个性化推荐响应时间减少65%,用户体验显著提升
💼 案例要点:这个项目充分利用了Kafka Streams的状态管理和流表连接能力,实现了复杂的实时分析。关键成功因素是将大型问题分解为较小的处理单元,并利用Kafka的分区模型实现横向扩展。
金融风控实时决策引擎
业务背景 :
某支付公司需要对每笔交易进行实时风险评估,以防范欺诈行为。系统需要在毫秒级完成复杂的风控规则评估,并具备自适应学习能力。
技术挑战:
- 严格的延迟要求:90%的请求需在100ms内完成评估
- 复村的风控规则:融合历史行为、地理位置、设备信息等多维数据
- Exactly-once处理语义要求,防止重复计算或遗漏
- 需要频繁更新风控规则和模型,且不能中断服务
Kafka Streams解决方案:
1. 多级风控流水线:
java
// 金融风控处理拓扑
StreamsBuilder builder = new StreamsBuilder();
// 交易事件流
KStream<String, Transaction> transactions = builder
.stream("transactions", Consumed.with(Serdes.String(), transactionSerde))
.peek((k, v) -> metricsCollector.recordEvent("transaction_received", v));
// 用户历史行为作为状态存储
KTable<String, UserBehaviorProfile> userProfiles = builder
.table("user-profiles", Consumed.with(Serdes.String(), userProfileSerde));
// 欺诈模式库 (实时更新的规则集)
GlobalKTable<String, FraudPattern> fraudPatterns = builder
.globalTable("fraud-patterns", Consumed.with(Serdes.String(), fraudPatternSerde));
// 设备黑名单
GlobalKTable<String, DeviceRiskScore> deviceRiskScores = builder
.globalTable("device-risk-scores", Consumed.with(Serdes.String(), deviceRiskScoreSerde));
// 1. 基础风控检查
KStream<String, EnrichedTransaction> enrichedTransactions = transactions
// 添加处理时间戳记
.transform(() -> new Transformer<String, Transaction, KeyValue<String, EnrichedTransaction>>() {
private ProcessorContext context;
@Override
public void init(ProcessorContext context) {
this.context = context;
}
@Override
public KeyValue<String, EnrichedTransaction> transform(String key, Transaction transaction) {
EnrichedTransaction enriched = new EnrichedTransaction(transaction);
enriched.setProcessingTime(System.currentTimeMillis());
return KeyValue.pair(key, enriched);
}
@Override
public void close() {}
})
// 关联用户历史行为
.join(userProfiles,
(transaction, profile) -> {
transaction.setUserProfile(profile);
return transaction;
})
// 匹配已知欺诈模式
.flatMapValues(transaction -> {
List<EnrichedTransaction> results = new ArrayList<>();
// 基础检查,不阻塞主流程
transaction.setPassedBasicChecks(performBasicChecks(transaction));
results.add(transaction);
return results;
});
// 2. 实时风控评分
KStream<String, ScoredTransaction> scoredTransactions = enrichedTransactions
// 对设备进行风险评分
.join(deviceRiskScores,
(txKey, tx) -> tx.getDeviceId(),
(transaction, deviceRisk) -> {
transaction.setDeviceRiskScore(deviceRisk.getScore());
return transaction;
})
// 应用复杂风控规则
.mapValues(transaction -> {
RiskScoreCalculator calculator = new RiskScoreCalculator();
double score = calculator.calculateScore(transaction);
return new ScoredTransaction(transaction, score);
})
// 性能监控点
.peek((k, v) -> {
long processingTime = System.currentTimeMillis() - v.getTransaction().getProcessingTime();
metricsCollector.recordTiming("risk_scoring_time", processingTime);
});
// 3. 决策分流
KStream<String, ScoredTransaction>[] branches = scoredTransactions
.branch(
// 低风险:直接通过
(key, tx) -> tx.getScore() < 0.3,
// 中风险:人工审核队列
(key, tx) -> tx.getScore() >= 0.3 && tx.getScore() < 0.7,
// 高风险:自动拒绝
(key, tx) -> tx.getScore() >= 0.7
);
// 处理低风险交易
branches[0]
.mapValues(tx -> {
Decision decision = new Decision(tx, "APPROVED", "Automatic approval - low risk");
return decision;
})
.to("approved-transactions", Produced.with(Serdes.String(), decisionSerde));
// 处理中风险交易
branches[1]
.mapValues(tx -> {
Decision decision = new Decision(tx, "PENDING", "Requires manual review");
return decision;
})
.to("pending-transactions", Produced.with(Serdes.String(), decisionSerde));
// 处理高风险交易
branches[2]
.mapValues(tx -> {
Decision decision = new Decision(tx, "REJECTED", "Automatic rejection - high risk");
return decision;
})
.to("rejected-transactions", Produced.with(Serdes.String(), decisionSerde));
// 4. 风控自适应学习反馈循环
KStream<String, TransactionFeedback> feedbackStream = builder
.stream("transaction-feedback", Consumed.with(Serdes.String(), feedbackSerde));
// 更新用户行为模型
feedbackStream
.selectKey((key, feedback) -> feedback.getUserId())
.groupByKey()
.aggregate(
UserFeedbackStats::new,
(key, feedback, stats) -> stats.update(feedback),
Materialized.with(Serdes.String(), userFeedbackStatsSerde)
)
.toStream()
.to("user-feedback-stats", Produced.with(Serdes.String(), userFeedbackStatsSerde));2. 异常处理与监控:
java
// 自定义异常处理
public class ResilientDeserializationHandler implements DeserializationExceptionHandler {
@Override
public DeserializationHandlerResponse handle(
ProcessorContext context,
ConsumerRecord<byte[], byte[]> record,
Exception exception) {
try {
// 记录异常详情到监控系统
Map<String, String> tags = new HashMap<>();
tags.put("topic", record.topic());
tags.put("exception", exception.getClass().getSimpleName());
metricsCollector.incrementCounter("deserialization_error", tags);
// 记录原始消息到异常主题,用于离线分析
ProducerRecord<byte[], byte[]> errorRecord = new ProducerRecord<>(
"deserialization-errors",
record.key(),
record.value()
);
errorProducer.send(errorRecord);
// 尝试恢复原始数据的关键字段
if (isRecoverable(exception)) {
byte[] partiallyRecoveredData = tryRecover(record.value());
if (partiallyRecoveredData != null) {
// 将可恢复的部分发送到恢复队列
ProducerRecord<byte[], byte[]> recoveredRecord = new ProducerRecord<>(
"recovered-partial-data",
record.key(),
partiallyRecoveredData
);
errorProducer.send(recoveredRecord);
}
}
} catch (Exception e) {
// 确保异常处理自身不会失败
log.error("Error in exception handler", e);
}
// 继续处理其他记录
return DeserializationHandlerResponse.CONTINUE;
}
}3. 性能优化关键点:
- 使用缓存和预计算减少复杂规则的评估时间
- 将风控流程拆分成不同优先级,关键路径优先执行
- 利用异步处理和结果预读取减少关联操作延迟
- 实现在线/离线混合模式,复杂计算在离线系统完成
业务成果:
- 交易风控评估延迟降至平均57ms,满足严格的实时要求
- 欺诈检测率提高35%,同时误判率降低18%
- 系统可靠性达到99.99%,满足金融级可用性要求
- 支持每秒5000笔交易的风控评估,且可线性扩展
💼 案例要点:这个项目展示了Kafka Streams在延迟敏感场景中的应用。关键是将处理流程分层,优先保证基础风控的低延迟,同时通过异步方式完成更复杂的评估。系统的弹性设计确保了金融级别的可靠性。
IoT设备数据处理平台
业务背景 :
某制造企业需要实时处理和分析来自数万台工业设备的传感器数据,用于设备健康监控、预测性维护和生产优化。
技术挑战:
- 处理高频率、多样化的传感器数据流(温度、压力、振动等)
- 需要在边缘和云端协同处理,部分分析需要在临近设备进行
- 设备连接不稳定,需要处理断连和重连情况
- 既要支持实时监控告警,又要支持长期趋势分析
Kafka Streams解决方案:
1. 分层处理架构:
java
// IoT数据处理拓扑
StreamsBuilder builder = new StreamsBuilder();
// 原始传感器数据流
KStream<String, SensorReading> rawReadings = builder
.stream("device-readings", Consumed.with(Serdes.String(), sensorReadingSerde));
// 1. 数据净化与标准化
KStream<String, NormalizedReading> normalizedReadings = rawReadings
.filter((key, reading) -> isValidReading(reading)) // 过滤无效数据
.mapValues(reading -> {
// 单位转换、异常值处理等
return normalizeReading(reading);
})
// 添加设备元数据
.transformValues(() -> new ValueTransformer<SensorReading, NormalizedReading>() {
private KeyValueStore<String, DeviceMetadata> metadataStore;
@Override
public void init(ProcessorContext context) {
metadataStore = context.getStateStore("device-metadata-store");
}
@Override
public NormalizedReading transform(SensorReading reading) {
DeviceMetadata metadata = metadataStore.get(reading.getDeviceId());
NormalizedReading normalized = new NormalizedReading(reading);
if (metadata != null) {
normalized.enrichWithMetadata(metadata);
}
return normalized;
}
@Override
public void close() {}
}, "device-metadata-store");
// 2. 实时监控与告警
KStream<String, DeviceAlert> alerts = normalizedReadings
// 按设备ID分组
.groupByKey()
// 滑动窗口监控,每5秒评估最近1分钟数据
.windowedBy(TimeWindows.ofSizeWithNoGrace(Duration.ofMinutes(1))
.advanceBy(Duration.ofSeconds(5)))
// 执行告警规则评估
.aggregate(
RollingStats::new,
(deviceId, reading, stats) -> stats.update(reading),
Materialized.with(Serdes.String(), rollingStatsSerde)
)
.toStream()
.flatMap((windowedDeviceId, stats) -> {
List<KeyValue<String, DeviceAlert>> alerts = evaluateAlertRules(
windowedDeviceId.key(), stats, windowedDeviceId.window());
return alerts;
});
// 将告警发送到专用主题
alerts.to("device-alerts", Produced.with(Serdes.String(), deviceAlertSerde));
// 3. 时间序列聚合与降采样
// 按不同时间粒度汇总数据,用于历史趋势分析
Map<String, KTable<Windowed<String>, AggregatedReadings>> timeSeriesAggregations = new HashMap<>();
Duration[] aggregationWindows = {
Duration.ofMinutes(5),
Duration.ofMinutes(15),
Duration.ofHours(1),
Duration.ofHours(6)
};
for (Duration window : aggregationWindows) {
String suffix = formatDuration(window);
KTable<Windowed<String>, AggregatedReadings> aggregation = normalizedReadings
// 按设备类型和ID构建复合键
.map((key, reading) -> {
String deviceType = reading.getDeviceType();
return KeyValue.pair(deviceType + ":" + key, reading);
})
.groupByKey()
.windowedBy(TimeWindows.ofSizeWithNoGrace(window))
.aggregate(
AggregatedReadings::new,
(key, reading, agg) -> agg.addReading(reading),
Materialized.with(Serdes.String(), aggregatedReadingsSerde)
);
// 存储不同粒度的聚合结果
aggregation
.toStream()
.map((windowedKey, value) -> {
String newKey = windowedKey.key() + ":" + windowedKey.window().start();
return KeyValue.pair(newKey, value);
})
.to("device-stats-" + suffix, Produced.with(Serdes.String(), aggregatedReadingsSerde));
timeSeriesAggregations.put(suffix, aggregation);
}
// 4. 设备健康评分
KTable<String, DeviceHealthScore> deviceHealth = normalizedReadings
.selectKey((key, reading) -> reading.getDeviceId())
.groupByKey()
// 使用会话窗口捕捉设备活动周期
.windowedBy(SessionWindows.with(Duration.ofMinutes(30)))
.aggregate(
DeviceHealthMetrics::new,
(key, reading, health) -> health.updateWithReading(reading),
(key, health1, health2) -> health1.merge(health2),
Materialized.with(Serdes.String(), deviceHealthMetricsSerde)
)
.toStream()
// 评估设备健康状况
.map((windowedKey, metrics) -> {
String deviceId = windowedKey.key();
DeviceHealthScore score = calculateHealthScore(deviceId, metrics);
return KeyValue.pair(deviceId, score);
})
// 更新健康评分表
.toTable(Materialized.as("device-health-store"));
// 输出设备健康评分用于仪表板
deviceHealth
.toStream()
.to("device-health-scores", Produced.with(Serdes.String(), deviceHealthScoreSerde));
// 5. 预测性维护模型输入准备
KStream<String, MaintenancePredictionInput> maintenanceInputs = deviceHealth
.toStream()
.filter((deviceId, health) -> health.getScore() < 0.8) // 只关注健康分数较低的设备
.join(
builder.stream("device-maintenance-history"),
(health, history) -> {
MaintenancePredictionInput input = new MaintenancePredictionInput();
input.setDeviceId(health.getDeviceId());
input.setHealthMetrics(health);
input.setMaintenanceHistory(history);
return input;
},
JoinWindows.ofTimeDifferenceWithNoGrace(Duration.ofDays(30))
);
// 将预测模型输入发送到专用主题,供ML模型使用
maintenanceInputs.to("maintenance-prediction-inputs",
Produced.with(Serdes.String(), maintenancePredictionInputSerde));2. 边缘-云协同处理:
java
// 边缘处理实例 (部署在本地网络)
Properties edgeProps = new Properties();
edgeProps.put(StreamsConfig.APPLICATION_ID_CONFIG, "edge-processor");
edgeProps.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "edge-kafka:9092");
// 本地状态配置,优化为边缘设备
edgeProps.put(StreamsConfig.STATE_DIR_CONFIG, "/local-storage/kafka-streams");
edgeProps.put(StreamsConfig.CACHE_MAX_BYTES_BUFFERING_CONFIG, 10 * 1024 * 1024); // 10MB
// 边缘处理拓扑
KafkaStreams edgeProcessor = new KafkaStreams(edgeTopologyBuilder.build(), edgeProps);
// 主云处理实例
Properties cloudProps = new Properties();
cloudProps.put(StreamsConfig.APPLICATION_ID_CONFIG, "cloud-processor");
cloudProps.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "cloud-kafka:9092");
// 云存储配置,优化为大规模分析
cloudProps.put(StreamsConfig.STATE_DIR_CONFIG, "/mnt/kafka-streams");
cloudProps.put(StreamsConfig.NUM_STREAM_THREADS_CONFIG, 16);
// 云处理拓扑
KafkaStreams cloudProcessor = new KafkaStreams(cloudTopologyBuilder.build(), cloudProps);3. 处理设备断连的策略:
java
// 设备状态监控
KTable<String, DeviceConnectionStatus> deviceStatus = rawReadings
.selectKey((key, reading) -> reading.getDeviceId())
.groupByKey()
// 跟踪最后活动时间
.aggregate(
() -> new DeviceConnectionStatus("UNKNOWN", 0),
(key, reading, status) -> {
status.setStatus("ONLINE");
status.setLastActivityTime(reading.getTimestamp());
return status;
},
Materialized.with(Serdes.String(), deviceConnectionStatusSerde)
);
// 使用定时器检测离线设备
builder.addStateStore(
Stores.keyValueStoreBuilder(
Stores.inMemoryKeyValueStore("connection-timers-store"),
Serdes.String(),
Serdes.Long()
)
);
KStream<String, DeviceConnectionStatus> connectionEvents = deviceStatus
.toStream()
.process(() -> new Processor<String, DeviceConnectionStatus, String, DeviceConnectionEvent>() {
private ProcessorContext context;
private KeyValueStore<String, Long> timerStore;
@Override
public void init(ProcessorContext context) {
this.context = context;
this.timerStore = context.getStateStore("connection-timers-store");
// 每分钟检查设备状态
context.schedule(Duration.ofMinutes(1), PunctuationType.WALL_CLOCK_TIME, timestamp -> {
KeyValueIterator<String, Long> all = timerStore.all();
long now = timestamp;
while (all.hasNext()) {
KeyValue<String, Long> entry = all.next();
String deviceId = entry.key;
Long lastActivity = entry.value;
// 5分钟无活动视为离线
if (now - lastActivity > 300000) {
DeviceConnectionEvent event = new DeviceConnectionEvent(
deviceId, "OFFLINE", now);
context.forward(deviceId, event);
// 更新状态
timerStore.put(deviceId, lastActivity);
}
}
all.close();
});
}
@Override
public void process(Record<String, DeviceConnectionStatus> record) {
String deviceId = record.key();
DeviceConnectionStatus status = record.value();
// 更新活动时间
timerStore.put(deviceId, status.getLastActivityTime());
// 发送连接事件
DeviceConnectionEvent event = new DeviceConnectionEvent(
deviceId, status.getStatus(), status.getLastActivityTime());
context.forward(record.withValue(event));
}
@Override
public void close() {}
}, "connection-timers-store");
// 将连接状态变更发送到专用主题
connectionEvents.to("device-connection-events",
Produced.with(Serdes.String(), deviceConnectionEventSerde));业务成果:
- 实现对8万台设备的实时监控,告警响应时间从分钟级降至秒级
- 预测性维护准确率达到86%,减少计划外停机时间37%
- 边缘处理减少了70%的云端数据传输,同时降低了处理延迟
- 系统可以处理每秒50万条传感器读数,为未来扩展提供充足空间
💼 案例要点:此项目充分利用了Kafka Streams的分布式特性,在边缘和云端分别部署处理实例,形成协同处理架构。关键是合理分配计算任务,将实时性要求高的监控放在边缘,将复杂分析放在云端,同时巧妙处理设备连接不稳定的挑战。
这些实际项目案例展示了Kafka Streams在不同场景中的应用价值和实现方法。每个项目都有其独特的挑战和解决思路,但都体现了Kafka Streams的核心优势:轻量级、易于集成、高度可扩展。这些经验可以直接应用到你自己的项目中,帮助你避开常见陷阱,构建高效可靠的流处理应用。
十、总结与展望
经过这段Kafka Streams的探索之旅,我们已经从基础概念到高级特性,从环境搭建到性能调优,从踩坑经验到实际案例,全面了解了这个强大的流处理框架。就像学习一门武术,我们不仅掌握了招式,还理解了其中的精髓和应用之道。在这最后一节,让我们总结经验,并展望未来的发展方向。
Kafka Streams适用场景总结
Kafka Streams在一些特定场景中表现出色,理解这些"最佳战场"能帮助我们做出正确的技术选择:
最适合的场景:
-
实时数据转换和丰富化
- 数据清洗、格式转换、字段提取
- 通过连接操作丰富事件数据
- 实时ETL管道构建
-
流式聚合和计算
- 实时指标计算(计数、求和、平均值等)
- 窗口化分析(滚动窗口、滑动窗口、会话窗口)
- 基于时间的事件序列处理
-
事件驱动型微服务
- 解耦系统组件,基于事件通信
- 持久化状态的无服务器(serverless-like)处理
- 细粒度服务的实现,专注于特定业务功能
-
已有Kafka生态系统的扩展
- 现有Kafka基础设施上的增量功能添加
- 避免引入额外系统的轻量级解决方案
- 与Kafka Connect等组件无缝协作
需慎重考虑的场景:
-
超复杂CEP(复杂事件处理)
- 需要复杂模式匹配和事件关联的场景
- 多阶段、复杂条件的事件检测
-
需要图形化开发界面的环境
- 业务分析师需要自行设计流处理的组织
- 无代码/低代码开发要求
-
极端低延迟要求的场景
- 需要亚毫秒级响应的实时处理
- 硬实时系统的实现
-
非常大规模的机器学习推理
- 需要复杂模型的在线推理
- 需要GPU加速的深度学习应用
📋 技术选择指南:Kafka Streams的优势在于其简单性和与Kafka的紧密集成。如果你已在使用Kafka且需求相对直接,它通常是最佳选择;如果需要更复杂的功能或更广泛的连接器,可能需要考虑Flink或Spark Streaming。
开发流程建议与最佳实践
基于前面章节的内容,以下是开发Kafka Streams应用的推荐流程和最佳实践:
1. 设计阶段
- 详细绘制处理拓扑图,标识流、表及其转换
- 识别有状态和无状态操作,评估状态大小
- 确定输入/输出主题的分区数,规划并行度
- 设计容错策略和错误处理机制
2. 开发阶段
- 从小处着手,逐步构建复杂性
- 使用测试驱动开发,充分利用TopologyTestDriver
- 将业务逻辑与Streams处理分离,便于单元测试
- 实现自定义的错误处理和监控机制
3. 测试阶段
- 使用TopologyTestDriver进行单元测试
- 创建端到端集成测试,验证真实环境交互
- 进行性能测试,确认延迟和吞吐量满足需求
- 模拟故障场景,验证恢复能力
4. 部署阶段
- 制定扩展策略,确定初始实例数
- 配置健康检查和监控指标
- 实现自动化部署和滚动更新机制
- 确保日志收集和分析系统到位
5. 运维阶段
- 建立性能基准,设置自动告警
- 定期审查状态存储大小和清理策略
- 监控再平衡事件和处理延迟
- 实施定期备份和恢复演练
核心最佳实践:
+--------------------------------+
| 拓扑设计最佳实践 |
+--------------------------------+
| ✓ 尽早过滤不需要的数据 |
| ✓ 减少重分区操作次数 |
| ✓ 利用合适的窗口类型 |
| ✓ 明确状态存储的命名和管理 |
+--------------------------------+
+--------------------------------+
| 性能优化最佳实践 |
+--------------------------------+
| ✓ 调整缓存大小与提交间隔 |
| ✓ 使用高效的序列化格式 |
| ✓ 优化RocksDB配置 |
| ✓ 合理设置线程数与并行度 |
+--------------------------------+
+--------------------------------+
| 可靠性最佳实践 |
+--------------------------------+
| ✓ 实现健壮的异常处理 |
| ✓ 利用DLQ处理问题数据 |
| ✓ 使用适当的processing.guarantee|
| ✓ 实施监控和告警机制 |
+--------------------------------+🛠️ 开发指导:始终记住,简单>复杂。Kafka Streams最大的优势在于其简单性,尽量利用内置功能,只在必要时实现自定义逻辑。这样可以减少维护负担,提高代码可读性。
Kafka Streams未来发展趋势
作为流处理领域的重要参与者,Kafka Streams正在不断发展。以下是一些值得关注的趋势和方向:
1. 云原生集成增强
- 与Kubernetes更深入的集成
- 自动扩缩容和资源管理优化
- 与云服务提供商特定服务的集成
2. 性能和可用性提升
- 进一步减少启动和再平衡时间
- 增强流处理的吞吐量和延迟特性
- 改进故障恢复机制,减少停机时间
3. 状态管理创新
- 更高效的状态后端存储选项
- 改进跨实例的状态查询能力
- 增强交互式查询API的易用性
4. 开发体验改进
- 更友好的DSL和API设计
- 更好的调试和监控工具
- 与现代开发框架(如Spring Boot)的更深入集成
- 可视化工具辅助拓扑设计和分析
5. 功能扩展
- 支持更复杂的处理模式和分析功能
- 增强与机器学习框架的集成
- 更丰富的内置统计和分析操作
- 增强对时间序列数据处理的支持
6. 生态系统拓展
- 更多预构建的连接器和处理器
- 与数据治理和元数据管理工具的集成
- 社区驱动的模式库和最佳实践共享
- 第三方监控和管理工具的增加
🔮 技术展望:未来Kafka Streams可能会进一步简化开发体验,同时增强高级功能,特别是在云原生环境下的自动化运维和弹性扩展方面。保持关注Apache Kafka的版本更新是把握最新趋势的好方法。
个人使用心得
在多年使用Kafka Streams的经验中,我积累了一些个人感悟,希望能对你有所启发:
-
从简单开始,循序渐进
许多开发者初次接触流处理时往往想一步到位,实现复杂功能。但在Kafka Streams中,先从简单的流转换开始,逐步添加状态操作和高级功能,是更有效的学习路径。就像学习烹饪一样,先掌握基本刀工和火候,再尝试复杂菜肴。
-
测试驱动开发是成功关键
Kafka Streams应用的潜在复杂性使得测试变得尤为重要。我发现采用测试驱动的方法,先编写测试用例,再实现功能,能大大减少线上问题。TopologyTestDriver是一个强大的盟友,它让我们无需启动完整集群即可验证逻辑。
-
学会透过API看本质
理解底层概念往往比熟记API更重要。一旦掌握了流和表的本质区别、状态存储的工作原理、处理器拓扑的执行模式,你就能更灵活地运用Kafka Streams,解决各种实际问题。
-
拥抱函数式编程思维
Kafka Streams的高级DSL采用了函数式风格,理解map、filter、reduce等操作的组合方式,能帮助你编写更简洁、更可维护的代码。这种声明式的编程方式初期可能不适应,但长期来看会大大提高生产力。
-
性能调优需要数据驱动
调优Kafka Streams应用时,避免基于猜测进行更改。建立监控体系,收集关键指标,然后有针对性地调整参数,观察效果。记住,过早优化是万恶之源,只有数据表明存在问题时才需要调优。
💭 个人建议:Kafka Streams最大的魅力在于它的简单性与强大功能的平衡。不要因为它"只是一个库"而低估它的能力,也不要因为想要实现复杂功能而过度设计。保持简单,专注于业务问题,往往能达到最好的效果。
结语
Kafka Streams为我们提供了一种简单而强大的方式来构建实时数据处理应用。它不需要额外的集群,不需要复杂的配置,只需几行代码就能开始流处理之旅。正如一把好用的瑞士军刀,它可能不是所有场景下的最佳工具,但它的便携性和实用性使它成为许多开发者的首选。
无论你是处理用户行为数据、构建实时推荐系统、开发风控引擎,还是分析IoT设备信息,Kafka Streams都能提供一个稳固的基础。通过本文介绍的概念、技术和最佳实践,希望你能更自信地使用这一工具,构建自己的流处理应用。
记住,流处理是一个不断发展的领域,保持学习和实践的态度,跟进社区动态,你的Kafka Streams技能将不断提升,为业务创造更多价值。
随着数据量的增长和实时性要求的提高,流处理技术的重要性只会增加。掌握Kafka Streams,你已经拥有了迎接这一挑战的有力工具。祝你在实时数据处理的道路上一帆风顺!
参考资源: