前言
在分布式系统中,我们需要为海量的数据、消息、订单生成全局唯一的标识符(ID)。这个需求听起来简单,但真正实现起来却充满挑战------既要保证ID全局唯一、趋势递增,又要支撑高并发、低延迟,还要具备高可用性。数据库自增ID?UUID?Snowflake?它们各有短板,难以完美适配所有场景。
美团点评开源的Leaf项目,提供了一种高效的解决方案。其中,号段模式(Leaf-segment) 以其巧妙的"预分发号段"设计,在保证高性能的同时,极大地降低了对数据库的压力,成为众多业务线的首选。今天,我将结合分布式ID生成的核心挑战,深入剖析Leaf号段模式的原理、优化与实践,带你彻底搞懂这个"既简单又强大"的技术方案。
一、分布式ID生成:为什么需要专门的系统?
在单库单表时代,直接使用数据库的自增ID就能满足需求。但随着业务发展,数据量激增,分库分表成为必然。此时,单库的自增ID无法保证全局唯一,我们迫切需要一套独立的ID生成系统。概括下来,一个优秀的ID生成系统必须满足以下要求:
- 全局唯一性:绝对不能出现重复ID,这是底线。
- 趋势递增:作为数据库主键时,有序的ID能提升写入性能(B-tree索引需要有序插入)。
- 单调递增:某些场景(如事务版本号、IM消息)要求严格递增。
- 信息安全:ID不宜连续,防止恶意爬取(如订单号)。
- 高可用、低延迟:服务必须稳定可靠,响应迅速(TP99在毫秒级)。
业界常见的ID生成方案各有优劣:
| 方案 | 优点 | 缺点 |
|---|---|---|
| UUID | 本地生成,性能极高,无网络消耗 | 128位太长,不易存储;作为主键无序,严重影响性能;可能泄露MAC地址 |
| 数据库自增 | 简单,利用现有数据库功能,ID单调自增 | 强依赖DB,DB宕机则服务不可用;单库写入瓶颈;水平扩展困难 |
| Snowflake | 64位长整型,趋势递增,不依赖数据库,高性能 | 强依赖机器时钟,时钟回拨会导致ID重复或服务不可用 |
面对这些方案的局限性,美团点评的Leaf团队在数据库生成ID的基础上进行了深度优化,推出了Leaf号段模式(Leaf-segment),在保持数据库可靠性的同时,实现了高性能、高可用的分布式ID生成。
二、先搞懂基础:号段预分配的核心思想
Leaf号段模式的核心思想非常简单:不再每次生成ID都请求数据库,而是一次性从数据库获取一个"号段"(例如1000个ID),缓存在本地内存中,然后直接在内存中分配ID返回给客户端。只有当这个号段用完了,才再次去数据库取新的号段。
这个过程就像你去窗口排队领号码牌------以前每拿一个号就要找工作人员要一次;现在工作人员一次性给你一沓号码牌(比如1~1000),你直接撕一张给一个人,用完了再去领新的一沓。这样,你和工作人员的交互频率就从"每来一个人一次"降低到了"每来1000个人一次",大大减轻了工作人员的压力。
Leaf的数据库表设计如下:
sql
CREATE TABLE `leaf_alloc` (
`biz_tag` varchar(128) NOT NULL COMMENT '业务标识,区分不同业务线',
`max_id` bigint(20) NOT NULL DEFAULT '1' COMMENT '当前已分配的最大ID',
`step` int(11) NOT NULL COMMENT '号段长度',
`description` varchar(256) DEFAULT NULL COMMENT '描述',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`biz_tag`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;biz_tag:业务标识,例如order、coupon,不同业务的ID隔离,互不影响。max_id:当前该业务已分配的最大ID值。step:每次获取号段的长度,比如1000。
获取号段的SQL使用乐观锁更新,保证并发安全:
sql
UPDATE leaf_alloc SET max_id = max_id + step WHERE biz_tag = 'order';
SELECT biz_tag, max_id, step FROM leaf_alloc WHERE biz_tag = 'order';例如,假设order业务的max_id=3000,step=1000。当Leaf服务请求号段时,DB将max_id更新为4000,并返回max_id=3000,step=1000,表示该服务获得了3001~4000这个号段。Leaf服务将这段号码加载到内存,后续请求直接从内存递增分配。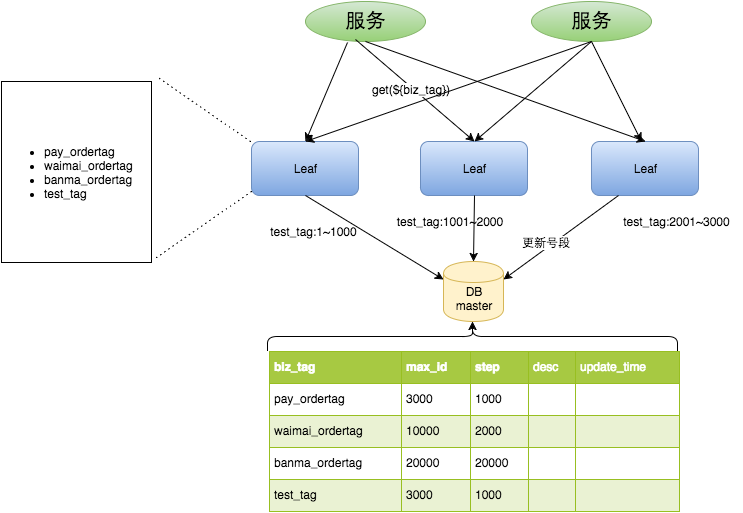
这种设计带来了巨大优势:
- 数据库压力骤减:从每次请求读写一次,降低为每
step次请求读写一次。 - 服务可线性扩展:多个Leaf节点可以同时服务不同业务,或通过负载均衡共同承担同一业务的流量。
- 号码趋势递增,满足数据库主键要求。
- 即使数据库短暂宕机,已缓存的号段仍可继续提供服务,提升了容灾能力。
三、Leaf号段模式的核心实现与优化
虽然基础设计已经大大降低了数据库压力,但在实际生产环境中,我们还需要应对更复杂的挑战:如何避免号段用尽时的阻塞?如何动态适应流量变化?Leaf通过一系列精巧的优化,让号段模式真正走向成熟。
3.1 双Buffer异步更新:消除临界点阻塞
在原始设计中,当内存中的号段用完时,Leaf会同步去数据库取新号段。这会导致两个问题:
- 临界点耗时尖刺:取号段涉及网络I/O和数据库更新,会阻塞请求线程,造成TP999延迟飙升。
- 数据库不可用影响:若号段刚好用完时数据库宕机,服务将无法继续分配ID。
为了解决这些问题,Leaf引入了双Buffer异步更新 机制: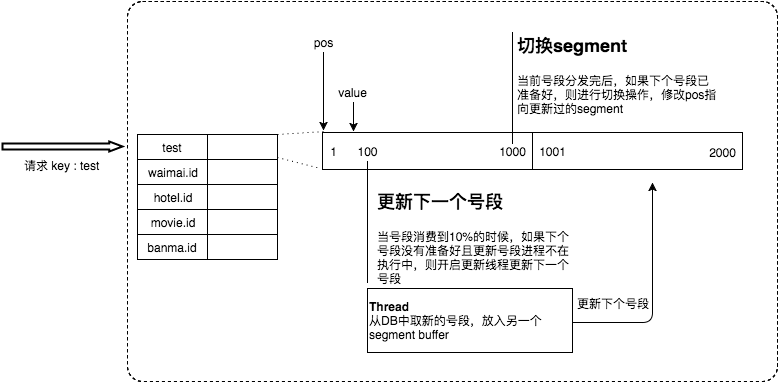
- Leaf内部维护两个号段缓存区:
segment(当前号段)和nextSegment(预备号段)。 - 当前号段正常下发ID,当使用量达到一定阈值(例如10%)时,触发一个异步线程去数据库加载下一个号段,存入
nextSegment。 - 当前号段耗尽时,立即切换到
nextSegment作为新的当前号段,同时继续异步加载下一个预备号段。
这样一来,取号段的过程与请求处理解耦,临界点的阻塞被彻底消除。即使数据库响应变慢,只要能在当前号段消耗完之前恢复,服务就始终可用。这种"空间换时间"的策略,让Leaf号段模式具备了极高的稳定性。
这里我要特别强调: 异步更新的触发点(10%)并不是固定的,可以根据业务流量动态调整。流量大时可适当提前触发,避免号段用完时还在等待异步加载;流量小时可延后触发,减少不必要的数据库请求。
3.2 动态调整号段长度:自适应流量波动
在实际生产中,业务流量是波动的。固定step会导致两个问题:
- 流量突增时:号段很快耗尽,数据库更新频繁,容灾时间缩短。
- 流量低谷时:号段过长,ID跨度大,造成浪费,且可能引起ID跳跃过大。
Leaf根据号段消耗周期 动态调整step,实现自适应:
- 假设服务QPS为Q,号段长度L,消耗周期T = L / Q。
- 期望T稳定在某个范围(如10-20分钟)。Leaf每次更新号段时,记录上一次号段消耗耗时T,并根据T调整下一次的
step:- T < 15分钟 (消耗过快) →
nextStep = step * 2(扩大号段,降低数据库压力) - 15分钟 < T < 30分钟 (消耗正常) →
nextStep = step(保持不变) - T > 30分钟 (消耗过慢) →
nextStep = step / 2(缩小号段,避免浪费)
- T < 15分钟 (消耗过快) →
这种动态调整策略,让Leaf号段模式能够平滑应对突发流量和低谷,始终保持数据库压力和容灾能力在合理水平。例如,在美团点评内部,有些业务流量在午餐、晚餐时段暴涨,号段长度会自动翻倍,保证数据库更新频率不变;而在凌晨低谷,号段长度自动缩小,减少ID浪费。
3.3 数据库高可用架构
尽管Leaf号段模式通过缓存降低了数据库依赖,但数据库仍然是最终的数据源,其高可用至关重要。美团点评的实践方案如下: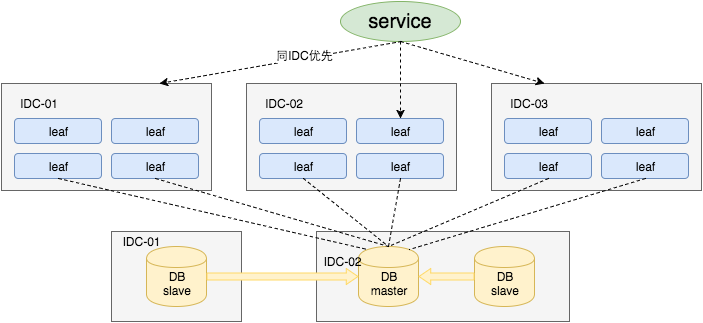
- 半同步复制 + 多机房部署:数据库采用主从半同步复制,保证数据不丢失;同时跨机房部署,防止单机房故障。
- 数据库中间件:使用Atlas/DBProxy做主从切换和读写分离,提高可用性。
- 服务层容灾:Leaf服务本身多机房部署,客户端优先调用同机房服务,跨机房互备;服务治理平台提供过载保护、流量控制等功能。
在极端场景下,即使数据库完全不可用,由于号段缓存的存在,Leaf仍能继续提供10-20分钟的服务(取决于号段大小和流量),为恢复争取宝贵时间。
四、Leaf号段模式 vs 其他ID生成方案
为了更清晰地展示Leaf号段模式的优势,我们将其与常见方案进行全面对比:
| 特性 | 数据库自增ID | UUID | Snowflake | Leaf号段模式 |
|---|---|---|---|---|
| 全局唯一 | 是 | 是 | 是 | 是 |
| 趋势递增 | 是 | 否(无序) | 是 | 是 |
| 单调递增 | 是 | 否 | 在单节点内单调递增 | 在单节点内单调递增,跨节点可能略有跳跃 |
| 性能 | 低(每次写DB) | 高(本地生成) | 高(本地生成) | 高(内存生成,极少DB交互) |
| 高可用 | 低(依赖DB) | 高(无依赖) | 中(依赖时钟,时钟回拨有问题) | 高(缓存容灾,多机房部署) |
| 水平扩展 | 困难(需调整步长) | 易(无状态) | 易(无状态,但需分配workerID) | 易(线性增加Leaf节点) |
| ID长度 | 64位或更少 | 128位 | 64位 | 64位 |
| 安全性(不可预测) | 低(连续) | 中(部分版本基于MAC) | 低(趋势递增) | 低(趋势递增) |
| 删除支持 | 不适用 | 不适用 | 不适用 | 不适用 |
| 实现复杂度 | 简单 | 简单 | 中等(需处理时钟回拨) | 中等(需处理双buffer和动态调整) |
需要特别说明的是: Leaf号段模式在安全性方面存在固有短板------ID是趋势递增的,可能泄露业务量信息。如果业务对ID的随机性有严格要求(如订单号),可以选用Leaf的Snowflake模式(基于时间戳+机器号+自增序列),或者结合加密算法进行二次处理。
五、Leaf号段模式的不足与参数调优
5.1 固有不足
任何技术方案都不是万能的,Leaf号段模式也有其局限性:
- ID可预测:由于趋势递增,攻击者可以通过ID大致估算业务量。对于敏感场景,需要额外增加混淆层。
- 数据库依赖:虽然通过缓存减轻了压力,但最终仍需依赖数据库,极端情况下数据库故障会影响服务(但缓存可撑一段时间)。
- 号段浪费:如果业务重启或切换节点,未用完的号段可能被废弃,造成ID空洞和浪费。
- TP999偶尔尖刺:虽然双buffer消除了同步取号段的阻塞,但在切换号段时,如果异步加载线程卡顿(如GC、网络抖动),仍可能短暂阻塞请求。
5.2 关键参数优化建议
要让Leaf号段模式发挥最佳性能,需要根据业务场景合理配置参数:
-
step(号段长度):
- 一般建议设置为业务高峰期QPS的600倍(10分钟消耗量)。例如高峰期QPS=1000,则step可设为60万,这样即使数据库故障,服务也能持续10分钟。
- 对于流量波动大的业务,开启动态step调整,让系统自动适应。
-
异步加载阈值:
- 默认10%触发异步加载,可根据号段长度和网络延迟调整。号段越长,阈值可适当降低(如5%),留足缓冲时间;网络延迟高,可提前触发。
-
数据库连接池:
- 由于数据库请求频率低,连接池大小无需过大,但需保证有足够的连接处理突发请求(如多个业务同时取号段)。
-
监控与报警:
- 监控每个biz_tag的号段消耗速度、剩余量、数据库请求延迟、异步加载状态。当剩余量低于阈值(如20%)且异步加载失败时,及时报警。
六、实际应用场景:什么时候选用Leaf号段模式?
结合我多年的工程实践经验,Leaf号段模式最适合以下场景:
- 需要趋势递增ID作为数据库主键的场景:例如订单表、用户表,有序主键能显著提升写入性能。
- 业务量较大,对数据库压力敏感的场景 :号段模式大幅降低数据库I/O,避免频繁的
REPLACE INTO操作。 - 可以接受ID趋势递增(可预测)的场景:如内部系统、非敏感业务。
- 需要一定的容灾能力,但又不希望引入复杂组件:号段模式基于成熟的关系型数据库,运维成本低,且有缓存容灾。
不建议使用的场景:
- 对ID随机性要求极高的场景:如外部订单号、优惠券码,容易被爬取。
- 需要严格单调递增且跨节点一致性的场景:例如全局事务版本号,号段模式在不同节点间可能存在小范围回退(节点重启导致号段未用完被废弃)。
- 资源受限的环境(如嵌入式系统):号段模式需要维护内存缓存和异步线程,资源开销相对较大。
七、总结
Leaf号段模式通过号段预分配 + 双buffer异步更新 + 动态step调整,在保证全局唯一、趋势递增的前提下,实现了高性能、高可用的分布式ID生成。它的核心亮点在于:
- 极致性能:内存生成ID,极少数据库交互,4C8G机器QPS可达5万+,TP99<1ms。
- 高可用:号段缓存容灾,多机房部署,数据库故障时可继续服务10-20分钟。
- 自适应:动态调整号段长度,轻松应对流量波动。
- 易运维:基于成熟的关系型数据库,无需引入额外组件,监控和管理方便。
对于绝大多数业务系统,Leaf号段模式是一个"开箱即用"的优秀选择。当然,如果业务对ID随机性有要求,可以选择Leaf的Snowflake模式,或者对生成的ID进行二次混淆。希望本文能帮助你深入理解Leaf号段模式的原理,在实际项目中做出合适的技术选型。
最后我想强调: 没有完美的技术,只有适合的场景。理解每个方案的底层逻辑和权衡,才能设计出真正健壮的系统。如果你对Leaf的其他模式(如Snowflake)感兴趣,欢迎继续关注后续的解析文章。