
这个export模块实现了Ultralytics YOLO项目的模型多种不同格式导出功能,主要包含:
-
engine.py:核心格式转换引擎
-
支持PyTorch到ONNX的转换
-
支持ONNX到TensorRT引擎的转换
-
支持INT8量化和FP16精度优化
-
支持动态形状和DLA加速
-
-
imx.py:Sony IMX500设备专用导出
-
使用Model Compression Toolkit进行量化
-
支持YOLOv8n和YOLO11n模型
-
支持检测、姿态估计、分割和分类任务
-
生成IMX500兼容的模型格式
-
-
tensorflow.py:TensorFlow生态系统导出
-
支持ONNX到SavedModel的转换
-
支持TFLite、Edge TPU和TensorFlow.js格式
-
支持INT8和FP16量化
-
处理各种兼容性问题
-
本文主要是对ultralytics.utils.export结构下不同子模块的整体解读记录,考虑到这部分代码功能比较单一且整体量级不大,所以这里选择汇总一起来进行学习。
一、整体架构逻辑分析
导出模块整体架构示意图如下所示:
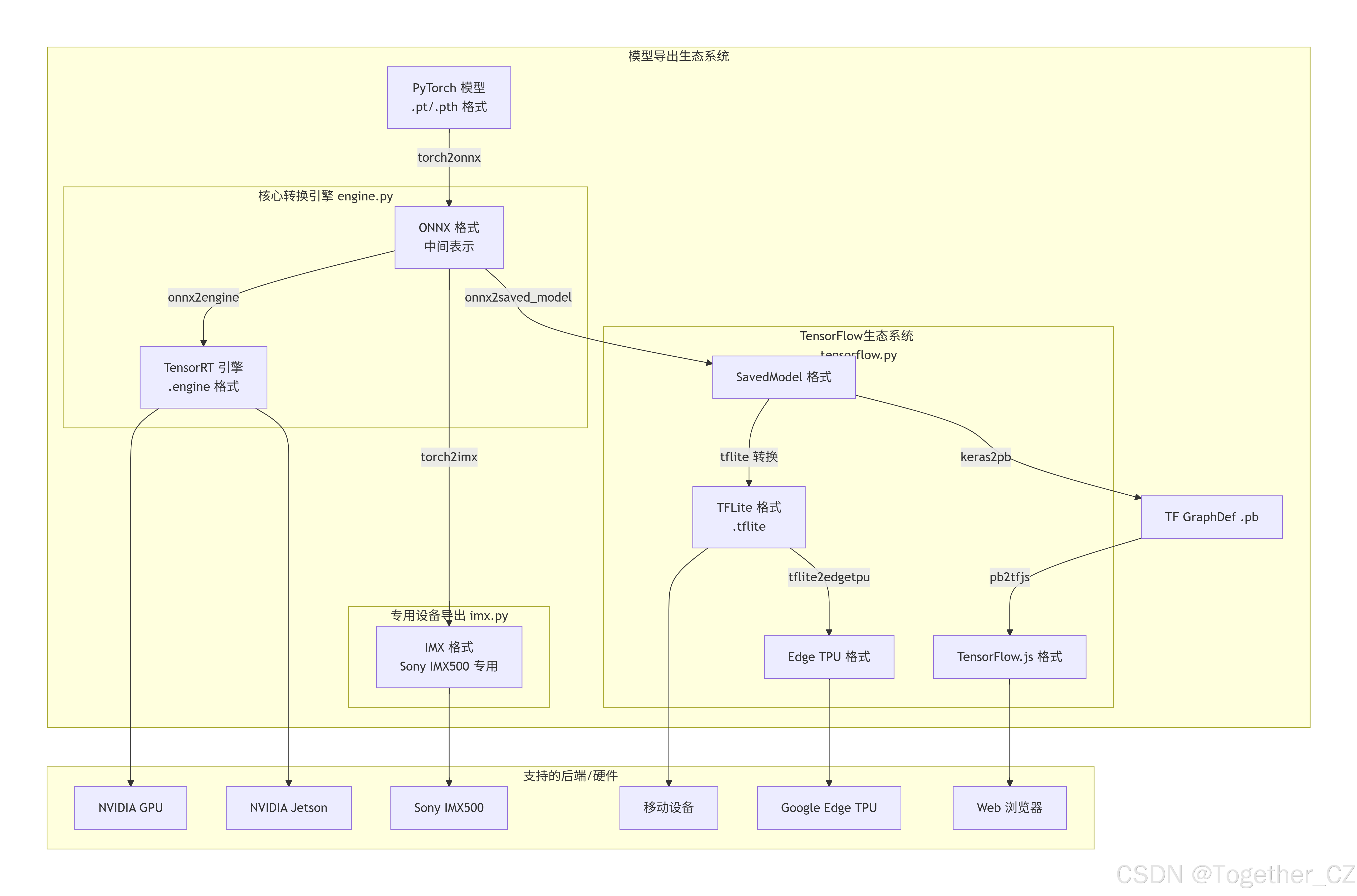
模块间依赖关系详情如下所示:

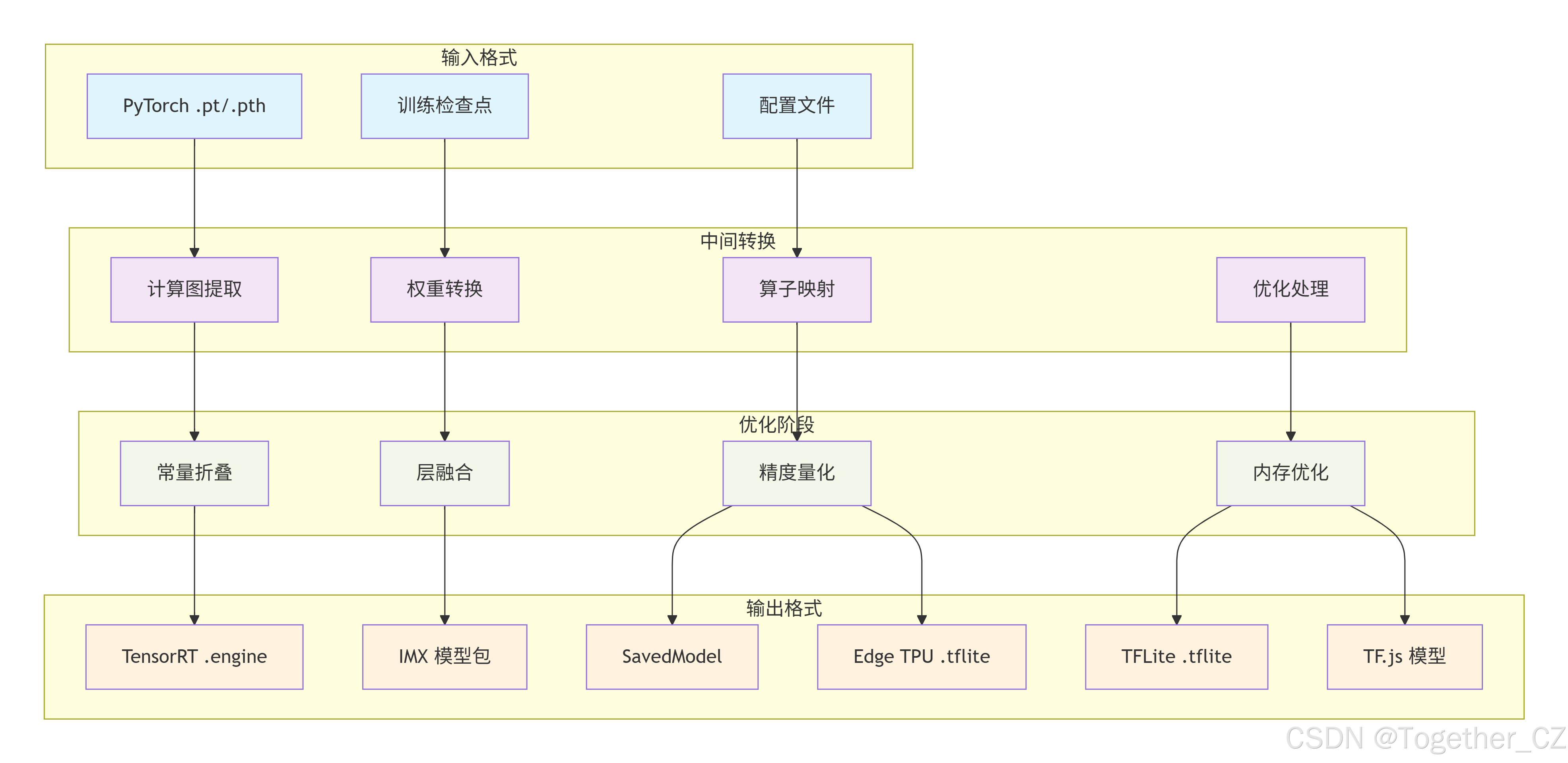
数据流转与格式转化流程如下所示:
二、代码解读
engine.py 模块 - 模型格式转换引擎
引擎模块详细处理流程如下:
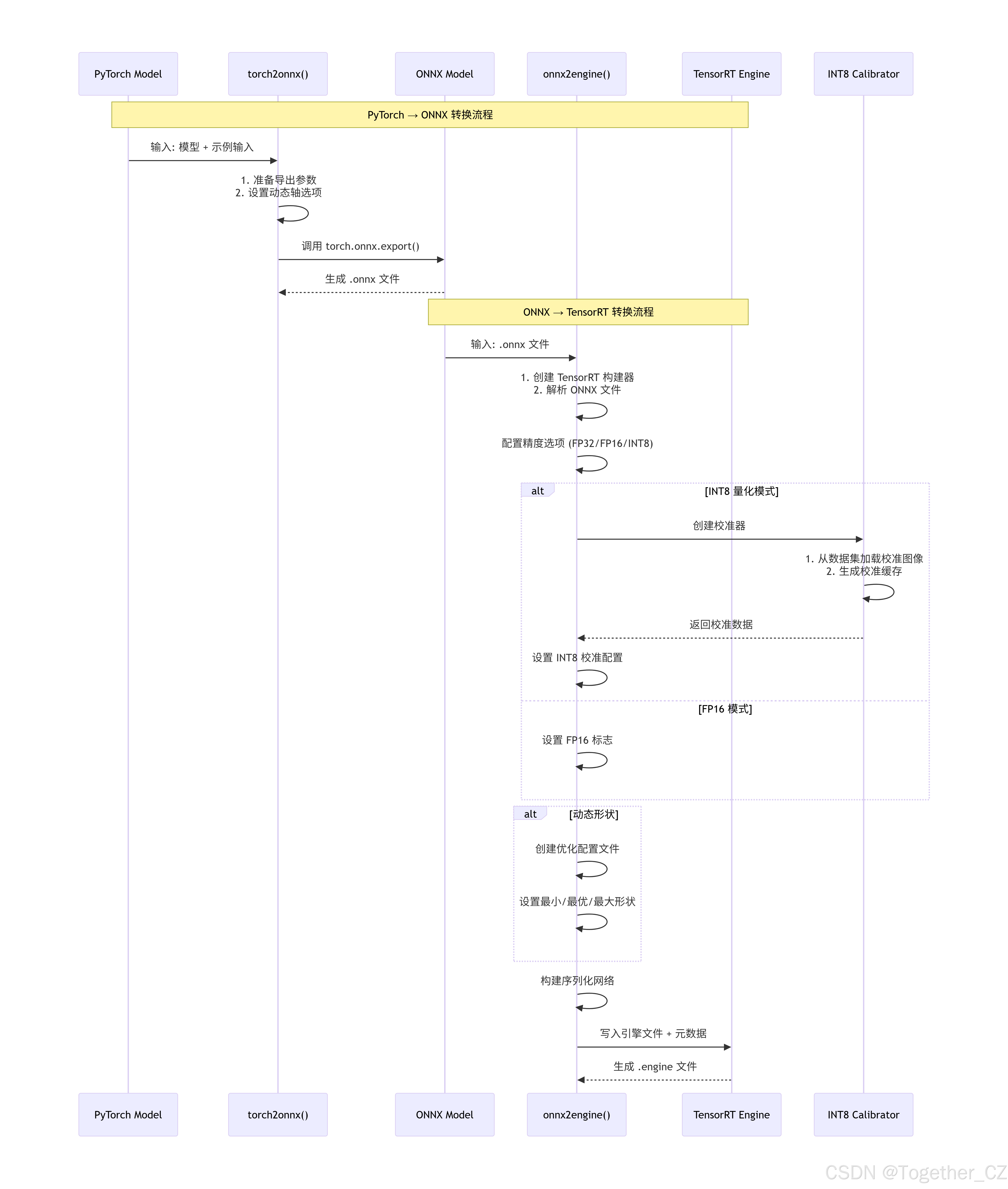
代码解读如下:
python
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
from __future__ import annotations
import json
from pathlib import Path
import torch
from ultralytics.utils import IS_JETSON, LOGGER
from ultralytics.utils.torch_utils import TORCH_2_4
def torch2onnx(
torch_model: torch.nn.Module, # 要导出的PyTorch模型
im: torch.Tensor, # 示例输入张量,用于模型追踪
onnx_file: str, # 保存ONNX文件的路径
opset: int = 14, # ONNX操作集版本
input_names: list[str] = ["images"], # 输入张量名称列表
output_names: list[str] = ["output0"], # 输出张量名称列表
dynamic: bool | dict = False, # 是否启用动态轴(支持动态输入尺寸)
) -> None:
"""将PyTorch模型导出为ONNX格式"""
# 根据PyTorch版本决定是否使用dynamo(PyTorch 2.4+的新特性)
kwargs = {"dynamo": False} if TORCH_2_4 else {}
# 调用PyTorch的ONNX导出功能
torch.onnx.export(
torch_model, # 要导出的模型
im, # 示例输入,用于追踪计算图
onnx_file, # 输出ONNX文件路径
verbose=False, # 不显示详细日志
opset_version=opset, # ONNX操作集版本
do_constant_folding=True, # 启用常量折叠优化(将常量计算预先计算)
# 警告:对于torch>=1.12版本,DNN推理可能需要设置为False
input_names=input_names, # 输入节点名称
output_names=output_names, # 输出节点名称
dynamic_axes=dynamic or None, # 动态轴配置,None表示静态形状
**kwargs, # 其他参数(如dynamo)
)
def onnx2engine(
onnx_file: str, # 要转换的ONNX文件路径
engine_file: str | None = None, # 生成的TensorRT引擎文件路径
workspace: int | None = None, # TensorRT工作空间大小(GB)
half: bool = False, # 是否启用FP16精度
int8: bool = False, # 是否启用INT8精度
dynamic: bool = False, # 是否启用动态输入形状
shape: tuple[int, int, int, int] = (1, 3, 640, 640), # 输入形状(批次, 通道, 高, 宽)
dla: int | None = None, # DLA核心编号(仅Jetson设备)
dataset=None, # INT8校准数据集
metadata: dict | None = None, # 要包含在引擎文件中的元数据
verbose: bool = False, # 是否启用详细日志
prefix: str = "", # 日志消息前缀
) -> None:
"""将YOLO模型导出为TensorRT引擎格式"""
import tensorrt as trt # 导入TensorRT库
# 如果未指定引擎文件路径,则使用ONNX文件同名但扩展名为.engine
engine_file = engine_file or Path(onnx_file).with_suffix(".engine")
# 创建TensorRT日志记录器
logger = trt.Logger(trt.Logger.INFO) # 默认信息级别
if verbose: # 如果启用详细日志,则设置为VERBOSE级别
logger.min_severity = trt.Logger.Severity.VERBOSE
# 创建TensorRT构建器
builder = trt.Builder(logger)
# 创建构建器配置
config = builder.create_builder_config()
# 计算工作空间字节大小(GB转换为字节)
workspace_bytes = int((workspace or 0) * (1 << 30)) # 1<<30 = 1GB的字节数
# 检查TensorRT版本是否>=10
is_trt10 = int(trt.__version__.split(".", 1)[0]) >= 10
# 根据TensorRT版本设置工作空间限制
if is_trt10 and workspace_bytes > 0:
# TensorRT 10+使用内存池限制
config.set_memory_pool_limit(trt.MemoryPoolType.WORKSPACE, workspace_bytes)
elif workspace_bytes > 0: # TensorRT 7, 8版本
# 旧版本使用最大工作空间大小
config.max_workspace_size = workspace_bytes
# 创建网络定义标志,启用显式批次维度
flag = 1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
# 创建网络
network = builder.create_network(flag)
# 检查平台是否支持FP16和INT8,并相应设置
half = builder.platform_has_fast_fp16 and half
int8 = builder.platform_has_fast_int8 and int8
# 如果启用了DLA(深度学习加速器)
if dla is not None:
# 检查是否为Jetson设备(DLA仅适用于NVIDIA Jetson)
if not IS_JETSON:
raise ValueError("DLA仅在NVIDIA Jetson设备上可用")
LOGGER.info(f"{prefix} 在核心 {dla} 上启用DLA...")
# DLA需要FP16或INT8精度
if not half and not int8:
raise ValueError(
"DLA需要启用'half=True'(FP16)或'int8=True'(INT8)。请启用其中一个并重试。"
)
# 设置默认设备类型为DLA
config.default_device_type = trt.DeviceType.DLA
# 设置DLA核心
config.DLA_core = int(dla)
# 启用GPU回退(如果DLA失败,使用GPU)
config.set_flag(trt.BuilderFlag.GPU_FALLBACK)
# 创建ONNX解析器
parser = trt.OnnxParser(network, logger)
# 从文件解析ONNX模型
if not parser.parse_from_file(onnx_file):
raise RuntimeError(f"无法加载ONNX文件: {onnx_file}")
# 获取网络输入和输出
inputs = [network.get_input(i) for i in range(network.num_inputs)]
outputs = [network.get_output(i) for i in range(network.num_outputs)]
# 记录输入输出信息
for inp in inputs:
LOGGER.info(f'{prefix} 输入 "{inp.name}" 形状{inp.shape} 数据类型{inp.dtype}')
for out in outputs:
LOGGER.info(f'{prefix} 输出 "{out.name}" 形状{out.shape} 数据类型{out.dtype}')
# 如果启用动态形状
if dynamic:
# 创建优化配置文件
profile = builder.create_optimization_profile()
# 最小输入形状
min_shape = (1, shape[1], 32, 32) # (批次, 通道, 最小高, 最小宽)
# 最大输入形状(基于工作空间大小缩放)
max_shape = (*shape[:2], *(int(max(2, workspace or 2) * d) for d in shape[2:]))
# 为每个输入设置形状范围
for inp in inputs:
profile.set_shape(inp.name, min=min_shape, opt=shape, max=max_shape)
# 将优化配置文件添加到配置中
config.add_optimization_profile(profile)
# 对于INT8校准,在TensorRT 10以下版本设置校准配置文件
if int8 and not is_trt10:
config.set_calibration_profile(profile)
# 记录正在构建的引擎信息
LOGGER.info(f"{prefix} 正在构建 {'INT8' if int8 else 'FP' + ('16' if half else '32')} 引擎为 {engine_file}")
# 如果启用INT8量化
if int8:
# 设置INT8标志
config.set_flag(trt.BuilderFlag.INT8)
# 设置详细性能分析
config.profiling_verbosity = trt.ProfilingVerbosity.DETAILED
# 定义INT8校准器类
class EngineCalibrator(trt.IInt8Calibrator):
"""TensorRT引擎优化的自定义INT8校准器"""
def __init__(
self,
dataset, # 校准数据集
cache: str = "", # 校准缓存文件路径
) -> None:
"""使用数据集和缓存路径初始化INT8校准器"""
# 调用父类初始化
trt.IInt8Calibrator.__init__(self)
self.dataset = dataset # 数据集
self.data_iter = iter(dataset) # 数据集迭代器
# 根据是否使用DLA选择校准算法
self.algo = (
trt.CalibrationAlgoType.ENTROPY_CALIBRATION_2 # DLA量化需要熵校准2
if dla is not None
else trt.CalibrationAlgoType.MINMAX_CALIBRATION # 否则使用最小最大校准
)
self.batch = dataset.batch_size # 批次大小
self.cache = Path(cache) # 缓存文件路径
def get_algorithm(self) -> trt.CalibrationAlgoType:
"""获取要使用的校准算法"""
return self.algo
def get_batch_size(self) -> int:
"""获取用于校准的批次大小"""
return self.batch or 1 # 如果没有设置批次大小,返回1
def get_batch(self, names) -> list[int] | None:
"""获取用于校准的下一个批次,作为设备内存指针列表"""
try:
# 从数据集中获取下一个图像批次
im0s = next(self.data_iter)["img"] / 255.0 # 归一化到[0,1]
# 如果数据在CPU上,移动到GPU
im0s = im0s.to("cuda") if im0s.device.type == "cpu" else im0s
# 返回数据指针列表
return [int(im0s.data_ptr())]
except StopIteration:
# 返回None表示没有更多校准数据
return None
def read_calibration_cache(self) -> bytes | None:
"""使用现有缓存而不是重新校准,否则隐式返回None"""
# 如果缓存文件存在且是.cache文件,读取并返回
if self.cache.exists() and self.cache.suffix == ".cache":
return self.cache.read_bytes()
def write_calibration_cache(self, cache: bytes) -> None:
"""将校准缓存写入磁盘"""
# 将缓存字节写入文件
_ = self.cache.write_bytes(cache)
# 使用校准器配置INT8校准
config.int8_calibrator = EngineCalibrator(
dataset=dataset, # 数据集
cache=str(Path(onnx_file).with_suffix(".cache")), # 缓存文件路径
)
elif half: # 如果启用FP16
# 设置FP16标志
config.set_flag(trt.BuilderFlag.FP16)
# 写入引擎文件
if is_trt10: # TensorRT 10+版本
# TensorRT 10+直接返回字节序列,而不是上下文管理器
engine = builder.build_serialized_network(network, config)
if engine is None:
raise RuntimeError("TensorRT引擎构建失败,请检查日志中的错误")
# 以二进制模式写入文件
with open(engine_file, "wb") as t:
if metadata is not None: # 如果有元数据
# 将元数据序列化为JSON字符串
meta = json.dumps(metadata)
# 先写入元数据长度(4字节,小端序)
t.write(len(meta).to_bytes(4, byteorder="little", signed=True))
# 再写入元数据内容
t.write(meta.encode())
# 写入引擎数据
t.write(engine)
else: # TensorRT 10以下版本
# 构建引擎(返回上下文管理器)
with builder.build_engine(network, config) as engine, open(engine_file, "wb") as t:
if metadata is not None: # 如果有元数据
# 将元数据序列化为JSON字符串
meta = json.dumps(metadata)
# 先写入元数据长度(4字节,小端序)
t.write(len(meta).to_bytes(4, byteorder="little", signed=True))
# 再写入元数据内容
t.write(meta.encode())
# 序列化并写入引擎
t.write(engine.serialize())imx.py 模块 - Sony IMX500设备导出
该模块专门用于将YOLO模型导出为Sony IMX500边缘设备兼容的格式。IMX500是Sony的AI图像传感器处理器,需要特定的模型格式和量化策略。
量化计算流程如下所示:
代码解读如下:
python
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
from __future__ import annotations
import subprocess
import sys
import types
from pathlib import Path
from shutil import which
import numpy as np
import torch
from ultralytics.nn.modules import Detect, Pose, Segment
from ultralytics.utils import LOGGER, WINDOWS
from ultralytics.utils.patches import onnx_export_patch
from ultralytics.utils.tal import make_anchors
from ultralytics.utils.torch_utils import copy_attr
# MCT(模型压缩工具包)的配置
MCT_CONFIG = {
"YOLO11": { # YOLO11模型的配置
"detect": { # 检测任务配置
"layer_names": ["sub", "mul_2", "add_14", "cat_19"], # 需要特殊处理的层名称
"weights_memory": 2585350.2439, # 权重内存限制(字节)
"n_layers": 238, # 模型层数
},
"pose": { # 姿态估计任务配置
"layer_names": ["sub", "mul_2", "add_14", "cat_21", "cat_22", "mul_4", "add_15"],
"weights_memory": 2437771.67,
"n_layers": 257,
},
"classify": { # 分类任务配置
"layer_names": [], # 无需特殊处理的层
"weights_memory": np.inf, # 内存限制为无穷大(不限制)
"n_layers": 112,
},
"segment": { # 分割任务配置
"layer_names": ["sub", "mul_2", "add_14", "cat_21"],
"weights_memory": 2466604.8,
"n_layers": 265,
},
},
"YOLOv8": { # YOLOv8模型的配置
"detect": {
"layer_names": ["sub", "mul", "add_6", "cat_15"],
"weights_memory": 2550540.8,
"n_layers": 168,
},
"pose": {
"layer_names": ["add_7", "mul_2", "cat_17", "mul", "sub", "add_6", "cat_18"],
"weights_memory": 2482451.85,
"n_layers": 187,
},
"classify": {"layer_names": [], "weights_memory": np.inf, "n_layers": 73},
"segment": {"layer_names": ["sub", "mul", "add_6", "cat_17"], "weights_memory": 2580060.0, "n_layers": 195},
},
}
class FXModel(torch.nn.Module):
"""
用于torch.fx兼容性的自定义模型类
"""
def __init__(self, model, imgsz=(640, 640)):
"""
初始化FXModel
Args:
model (nn.Module): 要包装的原始模型,使其与torch.fx兼容
imgsz (tuple[int, int]): 输入图像大小(高, 宽)。默认为(640, 640)
"""
super().__init__() # 调用父类初始化
# 从原始模型复制属性到当前实例
copy_attr(self, model)
# 显式设置`model`属性,因为`copy_attr`有时无法复制它
self.model = model.model
self.imgsz = imgsz # 保存图像尺寸
def forward(self, x):
"""
模型前向传播
此方法执行模型的前向传播,处理层之间的依赖关系并保存中间输出。
Args:
x (torch.Tensor): 模型的输入张量
Returns:
(torch.Tensor): 模型的输出张量
"""
y = [] # 保存各层输出的列表
# 遍历模型的所有层
for m in self.model:
# 如果m.f不是-1,表示该层的输入不是前一层
if m.f != -1:
# 从更早的层获取输入
# 如果m.f是整数,直接使用对应层的输出
# 如果m.f是列表,从多个层获取输出
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f]
# 如果是检测层(Detect)
if isinstance(m, Detect):
# 将_inference方法绑定到Detect实例
m._inference = types.MethodType(_inference, m)
# 计算锚点和步幅
m.anchors, m.strides = (
x.transpose(0, 1) # 转置维度
for x in make_anchors(
# 基于图像尺寸和步幅创建锚点
torch.cat([s / m.stride.unsqueeze(-1) for s in self.imgsz], dim=1),
m.stride, # 特征图步幅
0.5, # 锚点中心偏移
)
)
# 如果是姿态估计层(Pose)
if type(m) is Pose:
# 将pose_forward方法绑定到Pose实例
m.forward = types.MethodType(pose_forward, m)
# 如果是分割层(Segment)
if type(m) is Segment:
# 将segment_forward方法绑定到Segment实例
m.forward = types.MethodType(segment_forward, m)
# 执行当前层的前向传播
x = m(x)
# 保存输出到列表
y.append(x)
# 返回最终输出
return x
def _inference(self, x: list[torch.Tensor] | dict[str, torch.Tensor]) -> tuple[torch.Tensor]:
"""
解码IMX对象检测的边界框和类别分数
"""
# 如果输入是字典(来自某些模型的输出格式)
if isinstance(x, dict):
box, cls = x["boxes"], x["scores"] # 从字典获取边界框和分数
else:
# 如果输入是张量列表,将其连接起来
# 将每个特征图的形状调整为(batch, no, -1)然后连接
x_cat = torch.cat([xi.view(x[0].shape[0], self.no, -1) for xi in x], 2)
# 将连接后的张量分割为边界框和类别部分
box, cls = x_cat.split((self.reg_max * 4, self.nc), 1)
# 解码边界框
# 1. 使用DFL(分布焦点损失)层处理边界框
# 2. 使用锚点和步幅解码为实际坐标
dbox = self.decode_bboxes(self.dfl(box), self.anchors.unsqueeze(0)) * self.strides
# 返回解码后的边界框和经过sigmoid激活的类别分数
# dbox转置维度:(batch, 4, num_anchors) -> (batch, num_anchors, 4)
# cls经过sigmoid激活并转置维度:(batch, nc, num_anchors) -> (batch, num_anchors, nc)
return dbox.transpose(1, 2), cls.sigmoid().permute(0, 2, 1)
def pose_forward(self, x: list[torch.Tensor]) -> tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
"""
IMX姿态估计的前向传播,包括关键点解码
"""
bs = x[0].shape[0] # 获取批次大小
# 获取关键点输出数量,如果不存在则使用默认值
nk_out = getattr(self, "nk_output", self.nk)
# 处理关键点
# 对每个特征图使用对应的卷积层(cv4)处理,然后调整形状并连接
kpt = torch.cat([self.cv4[i](x[i]).view(bs, nk_out, -1) for i in range(self.nl)], -1)
# 如果使用Pose26格式(有5个维度),转换为3个维度以便导出
# Pose26格式通常包含:x, y, visibility, sigma_x, sigma_y
if hasattr(self, "nk_output") and self.nk_output != self.nk:
spatial = kpt.shape[-1] # 空间维度大小
# 重塑为(batch, num_keypoints, 5, spatial)
kpt = kpt.view(bs, self.kpt_shape[0], self.kpt_shape[1] + 2, spatial)
# 移除sigma_x和sigma_y维度
kpt = kpt[:, :, :-2, :]
# 重塑回(batch, self.nk, spatial)
kpt = kpt.view(bs, self.nk, spatial)
# 调用Detect基类的前向传播获取检测结果
x = Detect.forward(self, x)
# 解码关键点
pred_kpt = self.kpts_decode(kpt)
# 返回检测结果和转置后的关键点
# *x: 解包检测结果(边界框和分数)
# pred_kpt.permute(0, 2, 1): 转置关键点维度
return *x, pred_kpt.permute(0, 2, 1)
def segment_forward(self, x: list[torch.Tensor]) -> tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor]:
"""
IMX分割的前向传播
"""
# 生成掩模原型(prototype)
p = self.proto(x[0]) # 使用第一个特征图生成原型
bs = p.shape[0] # 获取批次大小
# 生成掩模系数
# 对每个特征图使用对应的卷积层(cv4)处理,然后调整形状并连接
mc = torch.cat([self.cv4[i](x[i]).view(bs, self.nm, -1) for i in range(self.nl)], 2)
# 调用Detect基类的前向传播获取检测结果
x = Detect.forward(self, x)
# 返回检测结果、转置后的掩模系数和原型
# *x: 解包检测结果(边界框和分数)
# mc.transpose(1, 2): 转置掩模系数维度
# p: 掩模原型
return *x, mc.transpose(1, 2), p
class NMSWrapper(torch.nn.Module):
"""
使用edge-mdt-cl的multiclass_nms层包装PyTorch模块
"""
def __init__(
self,
model: torch.nn.Module, # 模型实例
score_threshold: float = 0.001, # 非极大值抑制的分数阈值
iou_threshold: float = 0.7, # 非极大值抑制的IoU阈值
max_detections: int = 300, # 要返回的检测数量
task: str = "detect", # 任务类型,'detect'或'pose'
):
"""使用PyTorch模块和NMS参数初始化NMSWrapper"""
super().__init__() # 调用父类初始化
self.model = model # 保存原始模型
self.score_threshold = score_threshold # 分数阈值
self.iou_threshold = iou_threshold # IoU阈值
self.max_detections = max_detections # 最大检测数
self.task = task # 任务类型
def forward(self, images):
"""包含模型推理和NMS后处理的前向传播"""
from edgemdt_cl.pytorch.nms.nms_with_indices import multiclass_nms_with_indices
# 模型推理
outputs = self.model(images)
# 获取边界框和分数
boxes, scores = outputs[0], outputs[1]
# 执行多类非极大值抑制
nms_outputs = multiclass_nms_with_indices(
boxes=boxes, # 边界框
scores=scores, # 分数
score_threshold=self.score_threshold, # 分数阈值
iou_threshold=self.iou_threshold, # IoU阈值
max_detections=self.max_detections, # 最大检测数
)
# 如果是姿态估计任务
if self.task == "pose":
# 获取关键点 (批次, 最大检测数, 关键点 17*3)
kpts = outputs[2]
# 根据NMS返回的索引选择关键点
out_kpts = torch.gather(kpts, 1, nms_outputs.indices.unsqueeze(-1).expand(-1, -1, kpts.size(-1)))
# 返回NMS结果和筛选后的关键点
return nms_outputs.boxes, nms_outputs.scores, nms_outputs.labels, out_kpts
# 如果是分割任务
if self.task == "segment":
# 获取掩模系数和原型
mc, proto = outputs[2], outputs[3]
# 根据NMS返回的索引选择掩模系数
out_mc = torch.gather(mc, 1, nms_outputs.indices.unsqueeze(-1).expand(-1, -1, mc.size(-1)))
# 返回NMS结果和筛选后的掩模系数及原型
return nms_outputs.boxes, nms_outputs.scores, nms_outputs.labels, out_mc, proto
# 对于检测任务,返回基本NMS结果
return nms_outputs.boxes, nms_outputs.scores, nms_outputs.labels, nms_outputs.n_valid
def torch2imx(
model: torch.nn.Module, # 要导出的YOLO模型。必须是YOLOv8n或YOLO11n
file: Path | str, # 导出模型的输出文件路径
conf: float, # NMS后处理的置信度阈值
iou: float, # NMS后处理的IoU阈值
max_det: int, # 要返回的最大检测数量
metadata: dict | None = None, # 嵌入ONNX模型的元数据。默认为None
gptq: bool = False, # 是否使用基于梯度的训练后量化。如果为False,使用标准的训练后量化
dataset=None, # 量化校准的代表性数据集。默认为None
prefix: str = "", # 日志前缀字符串。默认为""
):
"""将YOLO模型导出为Sony IMX500设备部署的IMX格式"""
import model_compression_toolkit as mct
import onnx
from edgemdt_tpc import get_target_platform_capabilities
LOGGER.info(f"\n{prefix} 使用 model_compression_toolkit {mct.__version__} 开始导出...")
def representative_dataset_gen(dataloader=dataset):
"""代表性数据集生成器,用于量化校准"""
for batch in dataloader:
img = batch["img"] # 获取图像
img = img / 255.0 # 归一化到[0,1]
yield [img] # 生成一个批次的图像
# 注意:姿态估计模型需要tpc_version为"4.0"
tpc = get_target_platform_capabilities(tpc_version="4.0", device_type="imx500")
# 创建位宽配置
bit_cfg = mct.core.BitWidthConfig()
# 确定使用哪个模型的MCT配置
# 如果模型字符串中包含"C2PSA",则使用YOLO11的配置,否则使用YOLOv8
model_type = "YOLO11" if "C2PSA" in model.__str__() else "YOLOv8"
# 根据任务类型获取对应的配置
mct_config = MCT_CONFIG[model_type][model.task]
# 检查模型是否具有预期的层数
if len(list(model.modules())) != mct_config["n_layers"]:
raise ValueError("IMX导出仅支持YOLOv8n和YOLO11n模型。")
# 为特定层设置手动激活位宽为16位
for layer_name in mct_config["layer_names"]:
bit_cfg.set_manual_activation_bit_width(
[mct.core.common.network_editors.NodeNameFilter(layer_name)], # 层名称过滤器
16 # 16位激活
)
# 创建核心配置
config = mct.core.CoreConfig(
mixed_precision_config=mct.core.MixedPrecisionQuantizationConfig(num_of_images=10), # 混合精度配置
quantization_config=mct.core.QuantizationConfig(concat_threshold_update=True), # 量化配置
bit_width_config=bit_cfg, # 位宽配置
)
# 创建资源利用率配置
resource_utilization = mct.core.ResourceUtilization(weights_memory=mct_config["weights_memory"])
# 执行量化
if gptq:
# 执行基于梯度的训练后量化
quant_model = mct.gptq.pytorch_gradient_post_training_quantization(
model=model, # 原始模型
representative_data_gen=representative_dataset_gen, # 代表性数据生成器
target_resource_utilization=resource_utilization, # 目标资源利用率
gptq_config=mct.gptq.get_pytorch_gptq_config(
n_epochs=1000, # 训练轮数
use_hessian_based_weights=False, # 不使用基于Hessian的权重
use_hessian_sample_attention=False # 不使用Hessian样本注意力
),
core_config=config, # 核心配置
target_platform_capabilities=tpc, # 目标平台能力
)[0] # 返回量化后的模型
else:
# 执行标准的训练后量化
quant_model = mct.ptq.pytorch_post_training_quantization(
in_module=model, # 输入模型
representative_data_gen=representative_dataset_gen, # 代表性数据生成器
target_resource_utilization=resource_utilization, # 目标资源利用率
core_config=config, # 核心配置
target_platform_capabilities=tpc, # 目标平台能力
)[0] # 返回量化后的模型
# 如果不是分类任务,添加NMS包装器
if model.task != "classify":
quant_model = NMSWrapper(
model=quant_model, # 量化后的模型
score_threshold=conf or 0.001, # 置信度阈值
iou_threshold=iou, # IoU阈值
max_detections=max_det, # 最大检测数
task=model.task, # 任务类型
)
# 创建输出目录
f = Path(str(file).replace(file.suffix, "_imx_model")) # 将原文件扩展名替换为"_imx_model"
f.mkdir(exist_ok=True) # 创建目录,如果已存在则不报错
# 创建ONNX模型文件路径
onnx_model = f / Path(str(file.name).replace(file.suffix, "_imx.onnx"))
# 使用ONNX导出补丁
with onnx_export_patch():
# 导出PyTorch模型为ONNX格式
mct.exporter.pytorch_export_model(
model=quant_model, # 量化后的模型
save_model_path=onnx_model, # 保存路径
repr_dataset=representative_dataset_gen, # 代表性数据集
)
# 加载ONNX模型
model_onnx = onnx.load(onnx_model)
# 添加元数据到ONNX模型
if metadata:
for k, v in metadata.items():
meta = model_onnx.metadata_props.add() # 添加元数据属性
meta.key, meta.value = k, str(v) # 设置键值对
# 保存带元数据的ONNX模型
onnx.save(model_onnx, onnx_model)
# 查找imxconv-pt二进制文件 - 首先检查虚拟环境bin目录,然后检查PATH
bin_dir = Path(sys.executable).parent # Python可执行文件所在目录
# 根据操作系统确定可执行文件名
imxconv = bin_dir / ("imxconv-pt.exe" if WINDOWS else "imxconv-pt")
# 如果虚拟环境目录中不存在,从PATH中查找
if not imxconv.exists():
imxconv = which("imxconv-pt") # 从PATH中查找
# 如果仍未找到,抛出异常
if not imxconv:
raise FileNotFoundError("未找到imxconv-pt。请使用以下命令安装:pip install imx500-converter[pt]")
# 运行imxconv-pt工具进行转换
subprocess.run(
[
str(imxconv), # 转换工具路径
"-i", str(onnx_model), # 输入ONNX文件
"-o", str(f), # 输出目录
"--no-input-persistency", # 禁用输入持久化
"--overwrite-output", # 覆盖输出
],
check=True, # 检查命令执行是否成功
)
# 为IMX模型创建标签文件
with open(f / "labels.txt", "w", encoding="utf-8") as file:
# 将类别名称写入文件,每行一个
file.writelines([f"{name}\n" for _, name in model.names.items()])
# 返回导出目录路径
return ftensorflow.py 模块 - TensorFlow格式导出
该模块提供了将ONNX模型转换为各种TensorFlow格式的功能,包括SavedModel、TFLite、Edge TPU和TensorFlow.js格式。
多格式模型导出处理流程如下所示:

代码详读如下:
python
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
from __future__ import annotations
from pathlib import Path
import numpy as np
import torch
from ultralytics.utils import LOGGER
from ultralytics.utils.downloads import attempt_download_asset
from ultralytics.utils.files import spaces_in_path
def tf_wrapper(model: torch.nn.Module) -> torch.nn.Module:
"""TensorFlow导出兼容性的包装器(TF特定的处理现在在头部模块中)"""
return model # 直接返回模型,TF特定的处理已集成到模型头部模块中
def onnx2saved_model(
onnx_file: str, # ONNX文件路径
output_dir: Path, # SavedModel的输出目录路径
int8: bool = False, # 启用INT8量化。默认为False
images: np.ndarray = None, # INT8量化的校准图像(BHWC格式)
disable_group_convolution: bool = False, # 禁用组卷积优化。默认为False
prefix="", # 日志前缀。默认为""
):
"""通过ONNX将ONNX模型转换为TensorFlow SavedModel格式"""
# 预下载校准文件以修复 https://github.com/PINTO0309/onnx2tf/issues/545
onnx2tf_file = Path("calibration_image_sample_data_20x128x128x3_float32.npy")
if not onnx2tf_file.exists(): # 如果校准文件不存在
# 尝试下载并解压校准文件
attempt_download_asset(f"{onnx2tf_file}.zip", unzip=True, delete=True)
np_data = None # 初始化校准数据
if int8: # 如果启用INT8量化
# 创建临时INT8校准图像文件
tmp_file = output_dir / "tmp_tflite_int8_calibration_images.npy"
if images is not None: # 如果提供了校准图像
output_dir.mkdir(parents=True, exist_ok=True) # 创建输出目录
np.save(str(tmp_file), images) # 保存图像为numpy文件(BHWC格式)
# 创建校准数据配置
np_data = [["images", tmp_file, [[[[0, 0, 0]]]], [[[[255, 255, 255]]]]]]
# 为onnx_graphsurgeon兼容性修补onnx.helper(ONNX>=1.17)
# ONNX 1.17中移除了float32_to_bfloat16函数,但onnx_graphsurgeon仍在使用它
import onnx.helper
if not hasattr(onnx.helper, "float32_to_bfloat16"): # 如果不存在该函数
import struct
def float32_to_bfloat16(fval):
"""将float32转换为bfloat16(截断尾数的低16位)"""
# 将float32打包为整数,然后右移16位得到bfloat16
ival = struct.unpack("=I", struct.pack("=f", fval))[0]
return ival >> 16
# 将函数添加到onnx.helper模块
onnx.helper.float32_to_bfloat16 = float32_to_bfloat16
# 导入onnx2tf(在ONNX导出后作用域化以减少导入冲突)
import onnx2tf
LOGGER.info(f"{prefix} 使用 onnx2tf {onnx2tf.__version__} 开始TFLite导出...")
# 使用onnx2tf进行转换
keras_model = onnx2tf.convert(
input_onnx_file_path=onnx_file, # 输入ONNX文件路径
output_folder_path=str(output_dir), # 输出文件夹路径
not_use_onnxsim=True, # 不使用onnxsim优化(避免兼容性问题)
verbosity="error", # 日志详细程度
# 注意INT8-FP16激活错误 https://github.com/ultralytics/ultralytics/issues/15873
output_integer_quantized_tflite=int8, # 输出整数量化TFLite
custom_input_op_name_np_data_path=np_data, # 自定义输入操作和numpy数据路径
enable_batchmatmul_unfold=True and not int8, # 启用批矩阵乘法展开(GPU委托上检测对象数量较少的修复)
output_signaturedefs=True, # 输出signaturedefs(修复注意力块组卷积错误)
disable_group_convolution=disable_group_convolution, # 禁用组卷积(修复组卷积错误)
)
# 移除/重命名TFLite模型
if int8: # 如果启用了INT8量化
tmp_file.unlink(missing_ok=True) # 删除临时校准文件
# 重命名动态范围量化模型
for file in output_dir.rglob("*_dynamic_range_quant.tflite"):
# 将"_dynamic_range_quant"替换为"_int8"
file.rename(file.with_name(file.stem.replace("_dynamic_range_quant", "_int8") + file.suffix))
# 删除额外的fp16激活TFLite文件
for file in output_dir.rglob("*_integer_quant_with_int16_act.tflite"):
file.unlink()
# 返回转换后的Keras模型
return keras_model
def keras2pb(keras_model, file: Path, prefix=""):
"""
将Keras模型转换为TensorFlow GraphDef (.pb)格式
"""
import tensorflow as tf
from tensorflow.python.framework.convert_to_constants import convert_variables_to_constants_v2
LOGGER.info(f"\n{prefix} 使用 tensorflow {tf.__version__} 开始导出...")
# 创建完整的模型函数
m = tf.function(lambda x: keras_model(x)) # 完整模型
# 获取具体函数(指定输入形状和类型)
m = m.get_concrete_function(
tf.TensorSpec(keras_model.inputs[0].shape, keras_model.inputs[0].dtype)
)
# 将变量转换为常量(冻结图)
frozen_func = convert_variables_to_constants_v2(m)
# 获取图定义
frozen_func.graph.as_graph_def()
# 将冻结图写入文件
tf.io.write_graph(
graph_or_graph_def=frozen_func.graph, # 图定义
logdir=str(file.parent), # 输出目录
name=file.name, # 文件名
as_text=False, # 以二进制格式写入(非文本格式)
)
def tflite2edgetpu(tflite_file: str | Path, output_dir: str | Path, prefix: str = ""):
"""
使用Edge TPU编译器将TensorFlow Lite模型转换为Edge TPU格式
"""
import subprocess
# 构建Edge TPU编译器命令
cmd = (
"edgetpu_compiler " # Edge TPU编译器命令
f'--out_dir "{output_dir}" ' # 输出目录
"--show_operations " # 显示操作
"--search_delegate " # 搜索委托
"--delegate_search_step 30 " # 委托搜索步长
"--timeout_sec 180 " # 超时时间(秒)
f'"{tflite_file}"' # 输入TFLite文件
)
LOGGER.info(f"{prefix} 运行 '{cmd}'")
# 运行命令
subprocess.run(cmd, shell=True)
def pb2tfjs(pb_file: str, output_dir: str, half: bool = False, int8: bool = False, prefix: str = ""):
"""
将TensorFlow GraphDef (.pb)模型转换为TensorFlow.js格式
"""
import subprocess
import tensorflow as tf
import tensorflowjs as tfjs
LOGGER.info(f"\n{prefix} 使用 tensorflowjs {tfjs.__version__} 开始导出...")
# 创建TensorFlow图定义
gd = tf.Graph().as_graph_def() # TF GraphDef
# 读取.pb文件
with open(pb_file, "rb") as file:
gd.ParseFromString(file.read()) # 解析二进制数据
# 获取输出节点名称
outputs = ",".join(gd_outputs(gd))
LOGGER.info(f"\n{prefix} 输出节点名称: {outputs}")
# 设置量化选项
quantization = "--quantize_float16" if half else "--quantize_uint8" if int8 else ""
# 处理路径中的空格(导出器无法处理路径中的空格)
with spaces_in_path(pb_file) as fpb_, spaces_in_path(output_dir) as f_:
# 构建tensorflowjs_converter命令
cmd = (
"tensorflowjs_converter " # 转换器命令
f'--input_format=tf_frozen_model {quantization} ' # 输入格式和量化选项
f'--output_node_names={outputs} ' # 输出节点名称
f'"{fpb_}" ' # 输入.pb文件(已处理空格)
f'"{f_}"' # 输出目录(已处理空格)
)
LOGGER.info(f"{prefix} 运行 '{cmd}'")
# 运行命令
subprocess.run(cmd, shell=True)
# 警告路径中的空格问题
if " " in output_dir:
LOGGER.warning(f"{prefix} 您的模型在路径 '{output_dir}' 中包含空格,可能无法正常工作。")
def gd_outputs(gd):
"""
返回TensorFlow GraphDef模型的输出节点名称
"""
name_list, input_list = [], [] # 初始化名称列表和输入列表
# 遍历图中的所有节点
for node in gd.node: # tensorflow.core.framework.node_def_pb2.NodeDef
name_list.append(node.name) # 添加节点名称
input_list.extend(node.input) # 添加节点的所有输入
# 找出输出节点(在名称列表中但不在输入列表中的节点)
# 过滤掉以"NoOp"开头的节点
output_nodes = list(set(name_list) - set(input_list))
filtered_outputs = [x for x in output_nodes if not x.startswith("NoOp")]
# 添加":0"后缀(TensorFlow的命名约定)并排序
return sorted(f"{x}:0" for x in filtered_outputs)三、总体分析
不同层次量化对比如下:
| 量化类型 | 适用场景 | 技术实现 | 精度损失 |
|---|---|---|---|
| INT8后训练量化 | 通用部署,速度优先 | 校准数据集统计 | 中等 |
| FP16混合精度 | GPU推理,精度敏感 | 自动类型转换 | 低 |
| GPTQ梯度量化 | IMX专用,精度最优 | 梯度优化调整 | 最低 |
不同导出格式模型对比详情如下所示:
| 导出格式 | FP32 支持 | FP16 支持 | INT8 支持 | 主要目标硬件 |
|---|---|---|---|---|
| TensorRT | 完全支持 | 高度支持 | 高度支持 | NVIDIA GPU, Jetson |
| TFLite | 完全支持 | 完全支持 | 高度支持 | 移动设备, CPU |
| IMX | 有限支持 | 中等支持 | 高度支持 | Sony IMX500 |
| TF.js | 完全支持 | 高度支持 | 中等支持 | Web 浏览器 |
实例使用场景流程如下:
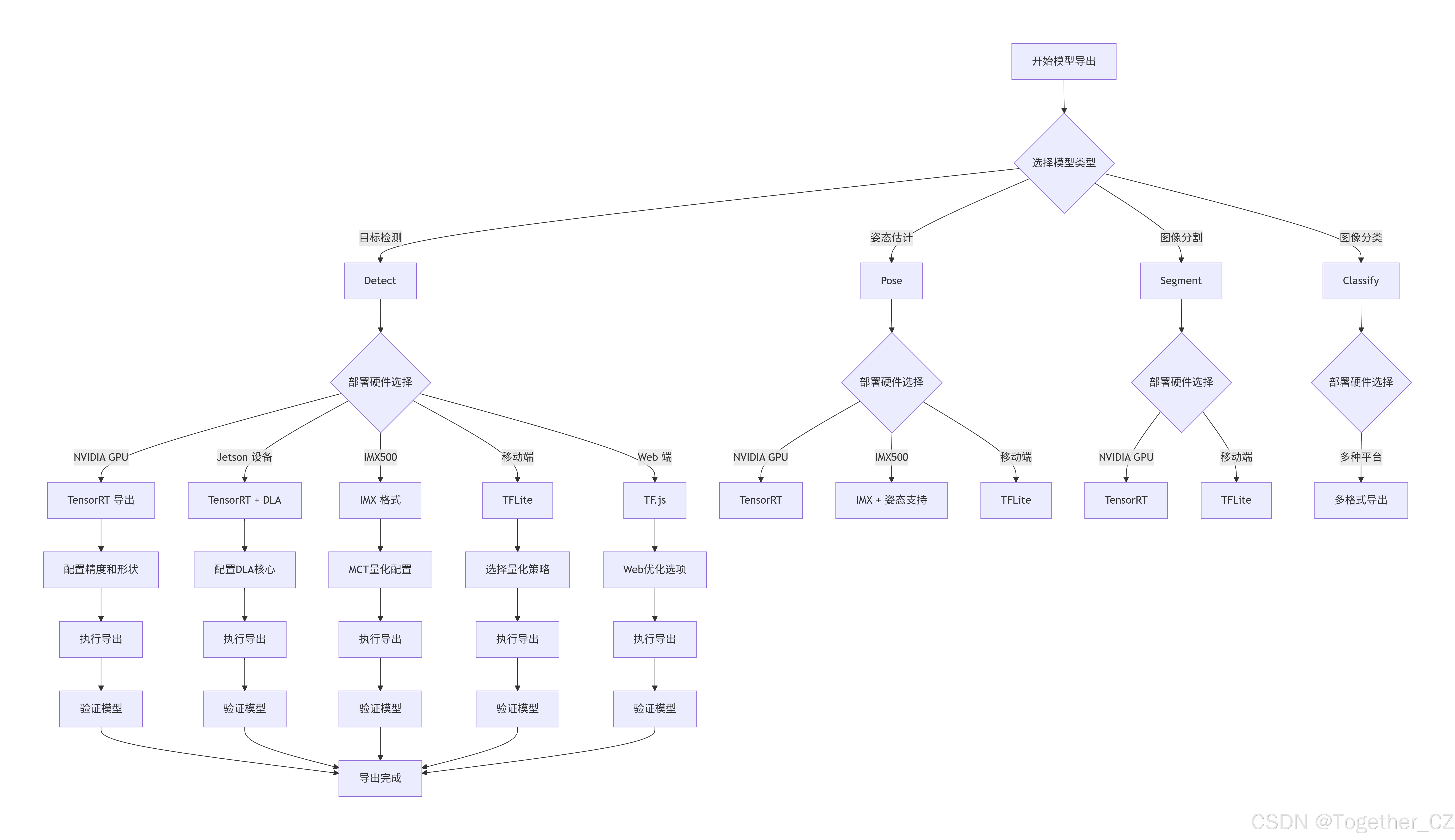
数据流转关键点:
-
PyTorch → ONNX :通过
torch.onnx.export实现计算图提取 -
ONNX → 目标格式:各模块使用专用转换器进行格式映射
-
精度转换:在转换过程中进行量化、剪枝等优化
-
硬件适配:根据目标硬件调整算子实现和内存布局
针对不同硬件的差异化优化策略:
-
NVIDIA GPU:TensorRT的层融合、内核自动调优
-
Jetson设备:DLA核心分配、GPU回退机制
-
IMX500:强制INT8量化、特定算子优化
-
Edge TPU:算子委托、内存布局优化