机器学习17-tensorflow2 线性代数
- 二次代价函数
-
-
- 1)实验设置与现象观察
- 2)现象原因分析
- 3)⼆次代价函数的局限性
- 4)关键结论
- [二次代价函数(Quadratic Cost Function)详解](#二次代价函数(Quadratic Cost Function)详解)
- 一、核心原理(通俗理解)
-
- 数学公式
-
- [1. 单样本二次代价](#1. 单样本二次代价)
- [2. 批量样本(均方误差 MSE)](#2. 批量样本(均方误差 MSE))
- [二、TensorFlow 中使用二次代价函数(MSE)](#二、TensorFlow 中使用二次代价函数(MSE))
-
- [1. 基础使用(回归任务)](#1. 基础使用(回归任务))
- [2. 关键参数与变种](#2. 关键参数与变种)
- [3. 为什么分类任务不用二次代价函数?](#3. 为什么分类任务不用二次代价函数?)
-
- [对比示例(分类任务用MSE vs 交叉熵)](#对比示例(分类任务用MSE vs 交叉熵))
- 三、关键使用技巧
-
- [1. 适用场景(核心)](#1. 适用场景(核心))
- [2. 梯度计算(理解优化过程)](#2. 梯度计算(理解优化过程))
- [3. 与优化器配合](#3. 与优化器配合)
- 总结
-
- 交叉熵
-
-
- [TensorFlow中的交叉熵(Cross Entropy)详解](#TensorFlow中的交叉熵(Cross Entropy)详解)
- 一、核心概念:交叉熵的本质
-
- [1. 通俗理解](#1. 通俗理解)
- [2. 数学公式](#2. 数学公式)
- 二、TensorFlow/Keras中的交叉熵函数
-
- [1. 场景1:标签是「整数形式」(如MNIST的0-9)](#1. 场景1:标签是「整数形式」(如MNIST的0-9))
- [2. 场景2:标签是「one-hot形式」(如0,1,0)](#2. 场景2:标签是「one-hot形式」(如[0,1,0]))
- 代码解释:
- 关键点:
- 何时使用哪种损失函数:
- 验证等价性:
-
- [3. 场景3:二分类任务(如是否为猫)](#3. 场景3:二分类任务(如是否为猫))
- 三、实战注意事项(避坑指南)
-
- [1. 模型输出与损失函数匹配](#1. 模型输出与损失函数匹配)
- [2. 避免数值不稳定](#2. 避免数值不稳定)
- [3. 在模型编译中使用](#3. 在模型编译中使用)
- 总结
-
- Dropout
-
- 一、Dropout的工作原理(通俗理解)
- 二、TensorFlow中使用Dropout的两种方式
-
- [1. 方式1:Keras层(推荐,简单易用)](#1. 方式1:Keras层(推荐,简单易用))
- 训练时Dropout自动生效,验证/测试时自动关闭
- 加载数据并训练
- 归一化并增加通道维度
-
-
- [2. 方式2:函数式API(自定义控制)](#2. 方式2:函数式API(自定义控制))
- 三、关键参数与使用技巧
-
- [1. 核心参数](#1. 核心参数)
- [2. 避坑指南](#2. 避坑指南)
- [3. 效果对比(直观理解)](#3. 效果对比(直观理解))
- 总结
-
- 正则化
-
- 一、正则化的核心原理(通俗理解)
- 二、TensorFlow中正则化的使用方法
-
- [1. 基础使用(L2正则化,最常用)](#1. 基础使用(L2正则化,最常用))
- [2. L1正则化(特征选择)](#2. L1正则化(特征选择))
- [3. L1-L2混合正则化(弹性网正则化)](#3. L1-L2混合正则化(弹性网正则化))
- [4. 卷积层的正则化](#4. 卷积层的正则化)
- 三、关键参数与使用技巧
-
- [1. 核心参数(正则化器)](#1. 核心参数(正则化器))
- [2. 关键使用原则](#2. 关键使用原则)
- [四、正则化 vs Dropout(核心区别)](#四、正则化 vs Dropout(核心区别))
- 优化器
-
- 一、优化器的核心原理(通俗理解)
- 二、TensorFlow中常用优化器(从基础到进阶)
- 三、关键参数与使用技巧
-
- [1. 核心参数(所有优化器通用)](#1. 核心参数(所有优化器通用))
- [2. 核心使用原则](#2. 核心使用原则)
- 四、优化器对比(直观参考)
二次代价函数
例题:⼆次代价函数与交叉熵函数⽐较
1)实验设置与现象观察
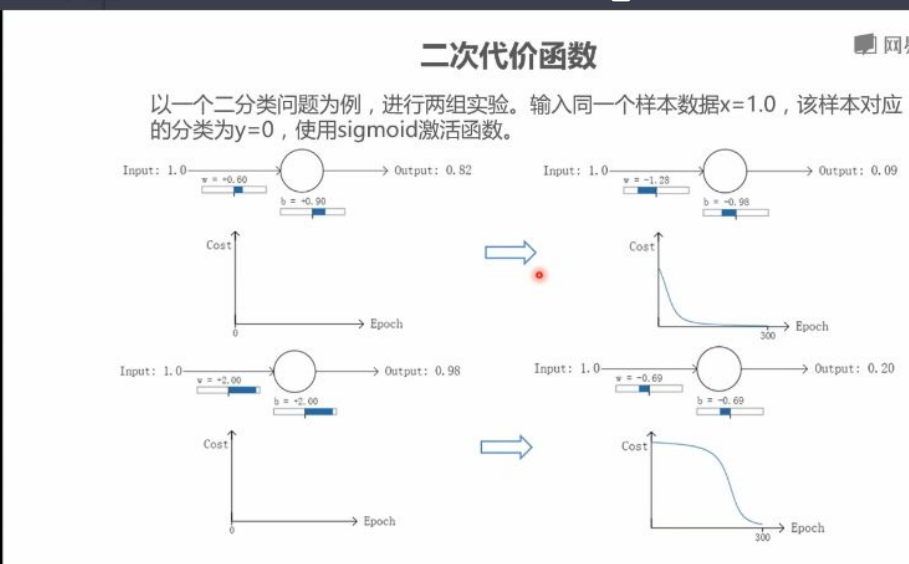
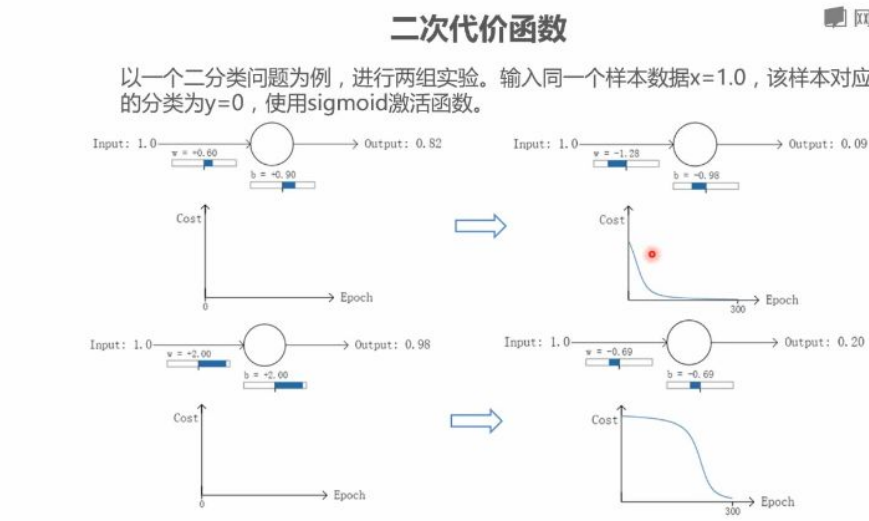
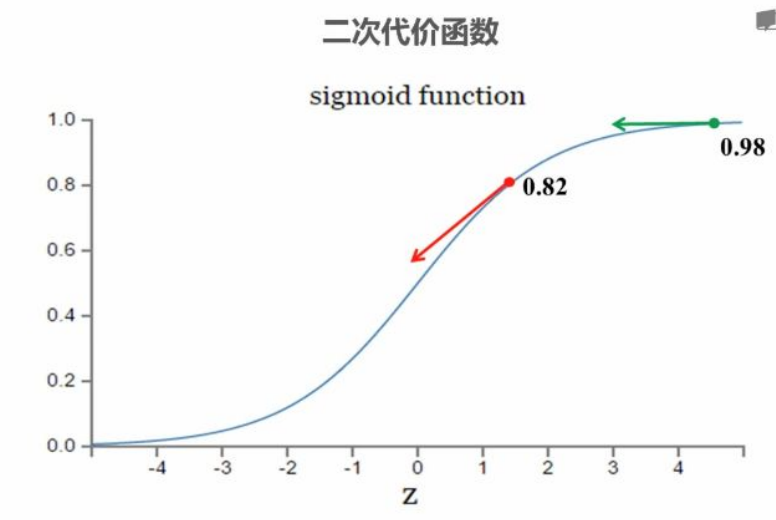
实验设计:两组⼆分类实验使⽤相同样本(x=1.0, y=0)和sigmoid激活函数,区别在于初始权重(w)和偏置(b)不同
第⼀组实验:
初始输出:0.82
300次训练后输出:0.09
代价曲线特征:初期快速下降,后期缓慢下降
第⼆组实验:
初始输出:0.98
300次训练后输出:0.20
代价曲线特征:初期缓慢下降,中期快速下降,后期⼜变缓
2)现象原因分析
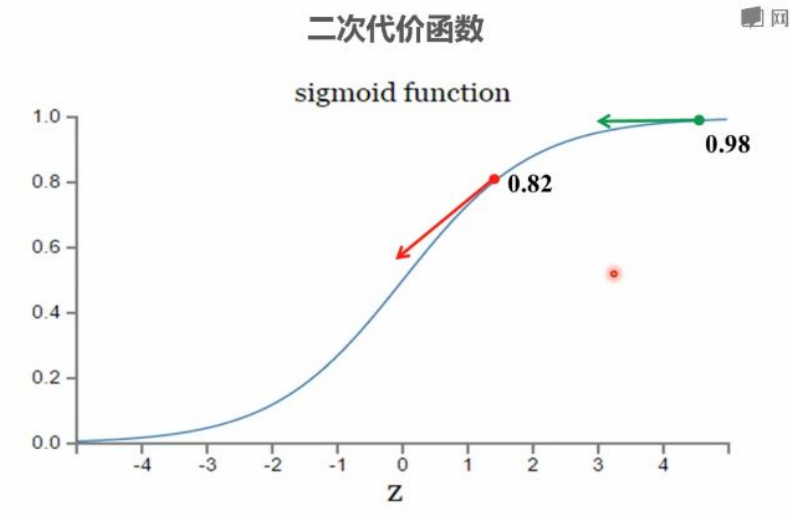
梯度差异:
输出0.82时梯度较⼤
输出0.98时梯度接近零
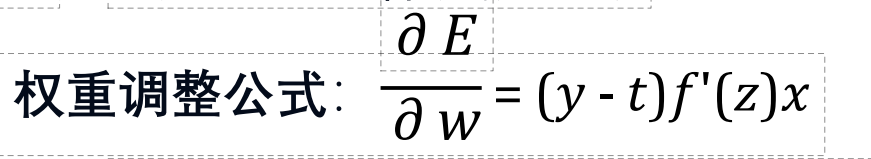
调整速度:与激活函数导数发f'(z)成正⽐
快速调整条件:当f'(z)较⼤时,权重调整快,训练收敛快慢速调整条件:当f'(z)较⼩时,权重调整慢,训练收敛慢

曲线形态解释:
第⼀组:初始梯度⼤→快速下降;接近⽬标时梯度减⼩→下降变缓
第⼆组:初始梯度⼩→缓慢下降;中期输出值降低梯度增⼤→快速下降;后期梯度再次减⼩→下降变缓
3)⼆次代价函数的局限性
不合理现象:
误差⼤(0.98)时调整慢误差⼩(0.82)时调整快
理想情况:误差越⼤应该调整越快
根本原因:⼆次代价函数的权重更新与激活函数导数直接相关,导致调整速度不完全由误差⼤⼩决定
⼆次代价函数缺陷:⽆法实现"误差越⼤调整越快"的合理学习⾏为
改进⽅向:需要新的代价函数设计,使权重调整速度与误差⼤⼩成正⽐
4)关键结论
二次代价函数(Quadratic Cost Function)详解
二次代价函数(也叫均方误差 MSE, Mean Squared Error)是深度学习中回归任务的核心损失函数,也曾用于早期分类任务(现已被交叉熵替代)。其核心是计算「模型预测值」与「真实值」之间差值的平方和,值越小代表预测越准确。
一、核心原理(通俗理解)
可以把二次代价函数比作"打靶":
- 真实值:靶心位置;
- 预测值:子弹击中的位置;
- 二次代价:子弹到靶心距离的平方(平方的作用是放大偏差,且保证非负)。
数学公式
1. 单样本二次代价
C = 1 2 ( y − y ^ ) 2 C = \frac{1}{2}(y - \hat{y})^2 C=21(y−y^)2
- y y y:真实标签(回归任务为连续值,如房价、温度);
- y ^ \hat{y} y^:模型预测值;
- 1 2 \frac{1}{2} 21:是为了求导时抵消平方的系数,简化计算(不影响最小化目标)。
2. 批量样本(均方误差 MSE)
实际训练中用批量样本的平均误差,即均方误差 :
M S E = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 MSE = \frac{1}{n}\sum_{i=1}^n (y_i - \hat{y}_i)^2 MSE=n1i=1∑n(yi−y^i)2
- n n n:批量样本数;
- 这是 TensorFlow 中
MeanSquaredError损失函数的核心公式。
二、TensorFlow 中使用二次代价函数(MSE)
1. 基础使用(回归任务)
python
import tensorflow as tf
import numpy as np
# 示例:房价预测(回归任务)
# 模拟数据:面积(x)→ 房价(y,单位:万)
x = np.array([50, 60, 70, 80, 90], dtype=np.float32) # 面积(㎡)
y = np.array([100, 120, 140, 160, 180], dtype=np.float32) # 真实房价
# 构建简单回归模型
model = tf.keras.Sequential([
tf.keras.layers.Dense(1, input_shape=(1,)) # 输出连续值,无激活函数
])
# 编译模型:使用二次代价函数(MSE)
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=0.1),
loss=tf.keras.losses.MeanSquaredError() # 二次代价函数(MSE)
)
# 训练模型
model.fit(x, y, epochs=100, verbose=0)
# 预测
pred = model.predict([75], verbose=0)
print(f"75㎡房价预测值:{pred[0][0]:.2f}万(真实值约150万)")
print(f"当前MSE损失:{model.evaluate(x, y, verbose=0):.4f}")2. 关键参数与变种
| 损失函数 | 公式 | 适用场景 |
|---|---|---|
MeanSquaredError() |
M S E = 1 n ∑ ( y − y ^ ) 2 MSE = \frac{1}{n}\sum (y-\hat{y})^2 MSE=n1∑(y−y^)2 | 普通回归任务(默认选择) |
MeanAbsoluteError() |
$MAE = \frac{1}{n}\sum | y-\hat{y} |
Huber() |
结合MSE(小偏差)和MAE(大偏差) | 兼顾精度与鲁棒性 |
示例:Huber损失(抗异常值)
python
# Huber损失:小偏差用MSE,大偏差用MAE,避免异常值影响
huber_loss = tf.keras.losses.Huber(delta=1.0) # delta:偏差阈值
model.compile(optimizer='adam', loss=huber_loss)3. 为什么分类任务不用二次代价函数?
早期有人将二次代价函数用于分类任务(如MNIST),但效果远不如交叉熵,核心原因:
- 梯度消失 :分类任务最后一层用
sigmoid/softmax激活,当预测值与真实值差距大时,sigmoid导数接近0,导致权重更新极慢(梯度消失); - 交叉熵优势:交叉熵的梯度与预测误差直接相关,无梯度消失问题,收敛更快。
对比示例(分类任务用MSE vs 交叉熵)
python
# 1. 分类任务用MSE(效果差)
model_mse = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28,28)),
tf.keras.layers.Dense(10, activation='softmax')
])
model_mse.compile(optimizer='adam', loss='mse', metrics=['accuracy'])
# 2. 分类任务用交叉熵(效果好)
model_ce = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28,28)),
tf.keras.layers.Dense(10, activation='softmax')
])
model_ce.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 加载MNIST数据
(x_train, y_train), _ = tf.keras.datasets.mnist.load_data()
x_train = x_train / 255.0
# 训练对比(仅5个epoch)
model_mse.fit(x_train, y_train, epochs=5, batch_size=64, validation_split=0.1, verbose=0)
model_ce.fit(x_train, y_train, epochs=5, batch_size=64, validation_split=0.1, verbose=0)
print(f"MSE分类准确率:{model_mse.evaluate(x_train, y_train, verbose=0)[1]:.4f}") # ~0.90
print(f"交叉熵分类准确率:{model_ce.evaluate(x_train, y_train, verbose=0)[1]:.4f}") # ~0.98三、关键使用技巧
1. 适用场景(核心)
- ✅ 回归任务:预测连续值(房价、温度、销量、股价);
- ❌ 分类任务:优先用交叉熵(SparseCategoricalCrossentropy/BinaryCrossentropy);
- ❗ 特殊回归场景 :
- 对异常值敏感 → 用MAE(MeanAbsoluteError);
- 兼顾精度与鲁棒性 → 用Huber损失。
2. 梯度计算(理解优化过程)
二次代价函数的梯度(以单样本为例):
∂ C ∂ w = − ( y − y ^ ) ⋅ σ ′ ( z ) ⋅ x \frac{\partial C}{\partial w} = - (y - \hat{y}) \cdot \sigma'(z) \cdot x ∂w∂C=−(y−y^)⋅σ′(z)⋅x
- w w w:权重;
- z z z:神经元输入( z = w x + b z=wx+b z=wx+b);
- σ ′ ( z ) \sigma'(z) σ′(z):激活函数导数;
- 问题:当 y ^ \hat{y} y^ 与 y y y 差距大时,若用sigmoid激活, σ ′ ( z ) ≈ 0 \sigma'(z)≈0 σ′(z)≈0,梯度≈0 → 权重更新停滞(梯度消失)。
3. 与优化器配合
-
回归任务优先用 Adam 优化器(收敛快);
-
若数据噪声大,可降低学习率(如0.001),配合早停(EarlyStopping):
pythonearly_stop = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=3) model.fit(x, y, epochs=100, validation_split=0.2, callbacks=[early_stop])
总结
- 二次代价函数(MSE)核心是计算预测值与真实值的平方误差,是回归任务的首选损失函数;
- 分类任务禁用MSE(易梯度消失),优先用交叉熵;
- 关键技巧:
- 普通回归用
MeanSquaredError(); - 异常值多的回归用
MeanAbsoluteError()或Huber(); - 配合Adam优化器+早停,提升回归精度。
- 普通回归用
交叉熵
TensorFlow中的交叉熵(Cross Entropy)详解
交叉熵是深度学习中分类任务的核心损失函数,本质是衡量「模型预测的概率分布」与「真实标签分布」之间的差异:差异越小,交叉熵值越低,模型预测越准。TensorFlow/Keras提供了多种封装好的交叉熵损失函数,适配不同的标签格式和任务场景。
一、核心概念:交叉熵的本质
1. 通俗理解
假设分类任务是识别手写数字(0-9):
- 真实标签:比如样本是数字5,真实分布是「只有5的概率为1,其余为0」(one-hot形式);
- 模型预测:模型输出的是10个概率值(如5的概率0.8,3的概率0.1,其余0.01);
- 交叉熵:计算这两个分布的"不匹配程度"------值越小,说明模型预测越接近真实标签。
2. 数学公式
对于单样本:
- 真实标签分布: y y y(one-hot形式,如 0 , 0 , 1 , 0 , . . .0 0,0,1,0,...0 0,0,1,0,...0)
- 模型预测分布: y ^ \hat{y} y^(softmax输出的概率,和为1)
- 交叉熵损失: H ( y , y ^ ) = − ∑ i = 1 n y i ⋅ log ( y ^ i ) H(y, \hat{y}) = -\sum_{i=1}^n y_i \cdot \log(\hat{y}_i) H(y,y^)=−∑i=1nyi⋅log(y^i)
👉 关键:只有真实标签为1的位置,其预测概率的对数才会被计算(其他项都是0),因此交叉熵可简化为: − log ( y ^ t r u e ) -\log(\hat{y}_{true}) −log(y^true)(真实类别对应的预测概率的负对数)。
二、TensorFlow/Keras中的交叉熵函数
TensorFlow将交叉熵封装在tf.keras.losses中,核心分为两类(适配不同标签格式):
1. 场景1:标签是「整数形式」(如MNIST的0-9)
真实标签不是one-hot,而是直接的类别索引(如5、3、7),用SparseCategoricalCrossentropy:
python
import tensorflow as tf
# 示例:MNIST分类(标签是整数)
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy()
# 模拟真实标签(3个样本,类别0、2、1)
y_true = [0, 2, 1]
# 模拟模型预测(softmax输出的概率分布)
y_pred = [[0.9, 0.05, 0.05], # 预测0(概率0.9)
[0.1, 0.2, 0.7], # 预测2(概率0.7)
[0.3, 0.6, 0.1]] # 预测1(概率0.6)
# 计算损失
loss = loss_fn(y_true, y_pred)
print(f"稀疏交叉熵损失:{loss.numpy():.4f}") # 输出:0.3203在这段代码中,y_pred 表示模型对每个样本的预测概率分布。
具体来说:
- 形状 :
y_pred是一个形状为(3, 3)的二维数组- 第一个维度
3:表示有3个样本 - 第二个维度
3:表示有3个可能的类别(对于MNIST就是数字0-9,这里简化为3个类别)
- 第一个维度
- 内容 :每一行对应一个样本,每一列对应一个类别的预测概率
- 第一行
[0.9, 0.05, 0.05]:模型预测第一个样本属于类别0的概率是90%,类别1的概率是5%,类别2的概率是5% - 第二行
[0.1, 0.2, 0.7]:模型预测第二个样本属于类别2的概率是70% - 第三行
[0.3, 0.6, 0.1]:模型预测第三个样本属于类别1的概率是60%
- 第一行
关键点:
- 每一行的所有概率值之和应该为1(因为使用了softmax激活函数)
- 使用
SparseCategoricalCrossentropy时,y_true是整数标签(如[0, 2, 1]),而不是one-hot编码 - 这个损失函数会计算预测概率分布与真实标签之间的交叉熵
验证:
python
# 验证每行概率和为1
for i, probs in enumerate(y_pred):
print(f"样本{i}的概率和:{sum(probs):.2f}")
# 输出:
# 样本0的概率和:1.00
# 样本1的概率和:1.00
# 样本2的概率和:1.00这就是为什么损失值为0.3203 - 它衡量了预测概率分布与真实标签之间的差异程度。
2. 场景2:标签是「one-hot形式」(如0,1,0)
真实标签是one-hot编码(如二分类1,0、多分类0,0,1),用CategoricalCrossentropy:
python
# 示例:标签为one-hot形式
loss_fn = tf.keras.losses.CategoricalCrossentropy()
# 真实标签(one-hot)
y_true = [[1,0,0], [0,0,1], [0,1,0]]
# 模型预测(同上文)
y_pred = [[0.9, 0.05, 0.05], [0.1, 0.2, 0.7], [0.3, 0.6, 0.1]]
loss = loss_fn(y_true, y_pred)
print(f"标准交叉熵损失:{loss.numpy():.4f}") # 输出:0.3203(和稀疏版结果一致)这段代码演示了TensorFlow中使用CategoricalCrossentropy 损失函数处理one-hot编码标签的情况。
代码解释:
python
import tensorflow as tf
# 示例:标签为one-hot形式
loss_fn = tf.keras.losses.CategoricalCrossentropy() # 创建标准交叉熵损失函数
# 真实标签(one-hot)
y_true = [[1,0,0], # 第一个样本属于类别0
[0,0,1], # 第二个样本属于类别2
[0,1,0]] # 第三个样本属于类别1
# 模型预测(同上文)
y_pred = [[0.9, 0.05, 0.05], # 预测类别0的概率为90%
[0.1, 0.2, 0.7], # 预测类别2的概率为70%
[0.3, 0.6, 0.1]] # 预测类别1的概率为60%
loss = loss_fn(y_true, y_pred)
print(f"标准交叉熵损失:{loss.numpy():.4f}") # 输出:0.3203(和稀疏版结果一致)关键点:
-
损失函数选择:
CategoricalCrossentropy():用于one-hot编码的标签- 对比之前的
SparseCategoricalCrossentropy():用于整数标签
-
标签格式:
y_true是one-hot编码:每个样本用一个向量表示,其中正确类别位置为1,其他为0- 示例中3个类别,所以每个标签是长度为3的向量
-
预测格式:
y_pred与之前相同:每个样本的类别概率分布- 每行概率和为1(softmax输出)
-
数学等价性:
- 输出结果0.3203与之前使用
SparseCategoricalCrossentropy的结果相同 - 这是因为两种损失函数在数学上是等价的,只是输入格式不同
- 输出结果0.3203与之前使用
何时使用哪种损失函数:
- 使用
CategoricalCrossentropy:当标签已经是one-hot编码时 - 使用
SparseCategoricalCrossentropy:当标签是整数(0, 1, 2...)时,更节省内存
验证等价性:
python
# 两种损失函数计算相同数据的对比
sparse_loss_fn = tf.keras.losses.SparseCategoricalCrossentropy()
categorical_loss_fn = tf.keras.losses.CategoricalCrossentropy()
# 整数标签
y_true_sparse = [0, 2, 1]
# one-hot标签(与上面等价)
y_true_categorical = [[1,0,0], [0,0,1], [0,1,0]]
# 相同预测
y_pred = [[0.9, 0.05, 0.05], [0.1, 0.2, 0.7], [0.3, 0.6, 0.1]]
loss1 = sparse_loss_fn(y_true_sparse, y_pred)
loss2 = categorical_loss_fn(y_true_categorical, y_pred)
print(f"Sparse损失: {loss1.numpy():.4f}") # 0.3203
print(f"Categorical损失: {loss2.numpy():.4f}") # 0.3203
print(f"是否相等: {loss1.numpy() == loss2.numpy()}") # True3. 场景3:二分类任务(如是否为猫)
二分类任务(输出只有两个类别),推荐用BinaryCrossentropy(模型输出用sigmoid而非softmax):
python
# 示例:二分类任务
loss_fn = tf.keras.losses.BinaryCrossentropy()
# 真实标签(二分类,0或1)
y_true = [0, 1, 1]
# 模型预测(sigmoid输出的单个概率值,代表正类概率)
y_pred = [[0.1], [0.8], [0.9]]
loss = loss_fn(y_true, y_pred)
print(f"二分类交叉熵损失:{loss.numpy():.4f}") # 输出:0.1446- 关键 :二分类时模型最后一层用
Dense(1, activation='sigmoid'),而非Dense(2, activation='softmax'),配合BinaryCrossentropy更高效。
三、实战注意事项(避坑指南)
1. 模型输出与损失函数匹配
| 任务类型 | 模型最后一层激活函数 | 损失函数 | 标签格式 |
|---|---|---|---|
| 多分类(整数标签) | softmax | SparseCategoricalCrossentropy | 整数(如5) |
| 多分类(one-hot) | softmax | CategoricalCrossentropy | one-hot(如0,0,1) |
| 二分类 | sigmoid | BinaryCrossentropy | 0/1(单值) |
2. 避免数值不稳定
- 交叉熵中的
log(0)会导致无穷大,TensorFlow的损失函数默认加了小epsilon(如1e-7)避免该问题; - 无需手动处理,直接用官方封装的损失函数即可。
3. 在模型编译中使用
python
# 示例:MNIST模型编译(整数标签)
model.compile(
optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(), # 匹配整数标签
metrics=['accuracy']
)总结
- 交叉熵的核心是衡量概率分布的差异,值越低模型预测越准;
- TensorFlow中交叉熵损失函数分三类:
SparseCategoricalCrossentropy:适配整数标签(多分类);CategoricalCrossentropy:适配one-hot标签(多分类);BinaryCrossentropy:适配二分类(sigmoid输出);
- 关键原则:模型输出激活函数 ↔ 损失函数 ↔ 标签格式 三者必须匹配。
Dropout
TensorFlow中的Dropout详解
Dropout是深度学习中防止过拟合的核心技术之一,由Google在2014年提出。它的核心思想是:在模型训练过程中,随机"关闭"(置零)一部分神经元,迫使模型学习更鲁棒的特征,避免过度依赖某几个神经元,从而提升泛化能力。
一、Dropout的工作原理(通俗理解)
可以把神经网络的神经元想象成一个团队:
- 无Dropout:训练时所有神经元都工作,模型可能过度依赖少数"核心"神经元(比如某几个特征),导致在训练集上表现极好,但测试集上拉胯(过拟合);
- 有Dropout:训练时随机让一部分神经元"休息"(输出置0),每个批次休息的神经元都不同。这样模型必须学习多个特征组合,而不是单靠少数特征,就像团队成员不能只依赖某个人,必须全员具备解决问题的能力。
关键细节:
- 训练阶段 :随机丢弃比例为
rate的神经元(比如rate=0.2就是20%的神经元被置零); - 测试/推理阶段 :所有神经元都工作,但输出会乘以
(1 - rate)(或通过缩放权重),保证输出的数值规模和训练时一致; - TensorFlow的
Dropout层会自动区分训练/测试模式,无需手动切换。
二、TensorFlow中使用Dropout的两种方式
1. 方式1:Keras层(推荐,简单易用)
在Sequential/Functional模型中直接添加tf.keras.layers.Dropout层,核心参数是rate(丢弃比例)。
实战示例(MNIST分类模型):
python
import tensorflow as tf
from tensorflow.keras import layers, models
# 构建带Dropout的CNN模型
def build_model_with_dropout():
model = models.Sequential([
# 卷积层(特征提取)
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
# 展平后接入全连接层,加入Dropout防过拟合
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dropout(0.2), # 丢弃20%的神经元(常用值:0.1~0.5)
layers.Dense(10, activation='softmax')
])
model.compile(
optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy']
)
return model
# 加载数据并训练
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train = x_train / 255.0[..., tf.newaxis]
x_test = x_test / 255.0[..., tf.newaxis]
model = build_model_with_dropout()
# 训练时Dropout自动生效,验证/测试时自动关闭
history = model.fit(
x_train, y_train,
epochs=5,
batch_size=64,
validation_split=0.1 # 验证集看是否过拟合
)
# 测试集评估(Dropout自动关闭)
test_loss, test_acc = model.evaluate(x_test, y_test)
print(f"测试集准确率:{test_acc:.4f}")这段代码构建了一个带Dropout正则化的CNN模型用于MNIST手写数字识别,并演示了两种交叉熵损失函数的使用。让我详细解释:
主要结构:
- CNN模型构建 (build_model_with_dropout函数)
python
def build_model_with_dropout():
model = models.Sequential([
# 卷积层(特征提取)
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
# 展平后接入全连接层,加入Dropout防过拟合
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dropout(0.2), # 丢弃20%的神经元(常用值:0.1~0.5)
layers.Dense(10, activation='softmax')
])
model.compile(
optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy']
)
return model关键组件:
Conv2D层:提取图像特征
MaxPooling2D层:降维,减少计算量
Dropout层:正则化技术,防止过拟合
SparseCategoricalCrossentropy:适用于整数标签的损失函数
- Dropout的工作原理
训练时Dropout自动生效,验证/测试时自动关闭
history = model.fit(
x_train, y_train,
epochs=5,
batch_size=64,
validation_split=0.1 # 验证集看是否过拟合
)
Dropout特性:
训练时:随机丢弃20%的神经元(Dropout(0.2))
验证/测试时:自动关闭,使用所有神经元
目的:防止模型过度依赖某些特定神经元,提高泛化能力
- 数据预处理
Apply
加载数据并训练
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
归一化并增加通道维度
x_train = (x_train / 255.0)..., tf.newaxis # 形状:(60000, 28, 28, 1)
x_test = (x_test / 255.0)..., tf.newaxis # 形状:(10000, 28, 28, 1)
- 两种交叉熵损失函数的对比(注释部分)
整数标签(MNIST标准格式):
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy()
y_true = 0, 2, 1 # 整数标签
y_pred = \[0.9, 0.05, 0.05, 0.1, 0.2, 0.7, 0.3, 0.6, 0.1]
loss = loss_fn(y_true, y_pred) # 输出:0.3203
one-hot编码标签:
loss_fn = tf.keras.losses.CategoricalCrossentropy()
y_true = \[1,0,0, 0,0,1, 0,1,0] # one-hot编码
y_pred = \[0.9, 0.05, 0.05, 0.1, 0.2, 0.7, 0.3, 0.6, 0.1]
loss = loss_fn(y_true, y_pred) # 输出:0.3203(结果相同)
模型流程总结:
数据加载:MNIST数据集(28×28灰度图像,10个类别)
预处理:归一化到0,1,增加通道维度
模型构建:CNN + Dropout正则化
训练:Dropout在训练时激活,验证时关闭
评估:测试集上评估最终性能
损失函数演示:展示两种交叉熵损失函数的等价性
为什么使用SparseCategoricalCrossentropy?
MNIST的标签是整数(0-9),使用SparseCategoricalCrossentropy:
内存效率高:不需要转换为one-hot编码
计算效率高:直接处理整数标签
结果相同:与CategoricalCrossentropy数学等价
模型输出:
最后一层:Dense(10, activation='softmax') 输出10个类别的概率分布
损失函数:计算预测概率与真实标签的交叉熵
Dropout:在训练时随机丢弃神经元,提高泛化能力
2. 方式2:函数式API(自定义控制)
如果需要更精细控制(比如手动指定训练/测试模式),可以用tf.keras.layers.Dropout的call方法:
python
dropout_layer = tf.keras.layers.Dropout(0.2)
# 训练模式(training=True,启用Dropout)
x_train_mode = dropout_layer(x, training=True)
# 测试模式(training=False,禁用Dropout)
x_test_mode = dropout_layer(x, training=False)三、关键参数与使用技巧
1. 核心参数
| 参数 | 作用 |
|---|---|
rate |
要丢弃的神经元比例(0~1,常用0.2、0.3、0.5) |
seed |
随机种子(固定种子可复现结果) |
noise_shape |
自定义丢弃的维度(比如只丢弃某些通道的神经元,进阶用法) |
2. 避坑指南
-
不要滥用Dropout :
- 丢弃比例过高(如>0.5)会导致模型欠拟合(学不到足够特征);
- 卷积层一般不用Dropout(卷积层参数少,过拟合风险低,常用BN层),Dropout主要用在全连接层;
-
训练/测试模式区分 :
- 模型
fit()/train_on_batch()时,Dropout自动启用; - 模型
predict()/evaluate()时,Dropout自动禁用; - 如果自定义训练循环,必须手动指定
training=True/False;
- 模型
-
和其他正则化配合 :
Dropout + L2正则化(kernel_regularizer)+ 早停(EarlyStopping),防过拟合效果更好:python# 示例:Dropout + L2正则化 layers.Dense(64, activation='relu', kernel_regularizer=tf.keras.regularizers.l2(0.001)), # L2正则 layers.Dropout(0.2),
3. 效果对比(直观理解)
| 模型配置 | 训练集准确率 | 测试集准确率 | 结论 |
|---|---|---|---|
| 无Dropout | 99.5% | 97.0% | 过拟合 |
| 有Dropout(rate=0.2) | 99.0% | 97.8% | 泛化更好 |
| Dropout(rate=0.6) | 98.0% | 96.5% | 欠拟合 |
总结
- Dropout的核心是训练时随机丢弃神经元,迫使模型学习更鲁棒的特征,解决过拟合;
- TensorFlow中优先用
tf.keras.layers.Dropout层,自动区分训练/测试模式,无需手动控制; - 使用技巧:
- 主要用于全连接层,丢弃比例选0.2~0.5;
- 避免过高丢弃比例,可配合L2正则、早停进一步提升泛化能力;
- 测试/推理时Dropout会自动关闭,所有神经元正常工作。
正则化
TensorFlow中的正则化(Regularization)详解
正则化是深度学习中防止模型过拟合的核心手段之一,其本质是在模型的损失函数中加入「惩罚项」,约束模型的权重参数不要过大,迫使模型学习更简单、泛化能力更强的特征,而非死记硬背训练数据。
TensorFlow/Keras将正则化功能深度集成在层的参数中,常用的有L1正则化 、L2正则化 和L1-L2混合正则化,下面从原理、使用方法到实战技巧全面讲解。
一、正则化的核心原理(通俗理解)
可以把模型训练比作"学生考试":
- 无正则化:学生死记硬背训练题(训练集),遇到原题(训练集)满分,但遇到新题(测试集)就不会(过拟合);
- 有正则化:老师规定"答题步骤不能太复杂"(惩罚复杂的权重),学生必须理解核心规律,而不是死记硬背,新题也能做对(泛化能力强)。
数学本质(损失函数)
最终损失 = 任务损失(如交叉熵、MSE) + 正则化惩罚项
L o s s = L o s s t a s k + λ ⋅ R ( W ) Loss = Loss_{task} + \lambda \cdot R(W) Loss=Losstask+λ⋅R(W)
其中:
- W W W:模型的权重参数;
- λ \lambda λ:正则化强度(控制惩罚力度,越小惩罚越轻);
- R ( W ) R(W) R(W):正则化惩罚项,分三种:
- L1正则化 : R ( W ) = ∑ ∣ W ∣ R(W) = \sum |W| R(W)=∑∣W∣(惩罚权重的绝对值,会让部分权重变为0,实现特征选择);
- L2正则化 : R ( W ) = ∑ W 2 R(W) = \sum W^2 R(W)=∑W2(惩罚权重的平方,会让权重整体变小,不会归零,最常用);
- L1-L2混合 : R ( W ) = α ∑ ∣ W ∣ + ( 1 − α ) ∑ W 2 R(W) = \alpha\sum |W| + (1-\alpha)\sum W^2 R(W)=α∑∣W∣+(1−α)∑W2(结合两者特点)。
二、TensorFlow中正则化的使用方法
TensorFlow的正则化主要通过tf.keras.regularizers模块实现,核心是将正则化器传入层的kernel_regularizer(权重正则化)、bias_regularizer(偏置正则化,一般不用)等参数。
1. 基础使用(L2正则化,最常用)
示例:MNIST分类模型(全连接层+L2正则)
python
import tensorflow as tf
from tensorflow.keras import layers, models, regularizers
# 构建带L2正则化的模型
def build_model_with_l2():
model = models.Sequential([
layers.Flatten(input_shape=(28, 28)),
# 全连接层添加L2正则化
layers.Dense(128,
activation='relu',
# L2正则化,lambda=0.001(常用0.0001~0.01)
kernel_regularizer=regularizers.l2(0.001)),
layers.Dense(64,
activation='relu',
kernel_regularizer=regularizers.l2(0.001)),
layers.Dense(10, activation='softmax')
])
model.compile(
optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy']
)
return model
# 加载数据并训练
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train = x_train / 255.0
x_test = x_test / 255.0
model = build_model_with_l2()
history = model.fit(
x_train, y_train,
epochs=10,
batch_size=64,
validation_split=0.1, # 验证集监控过拟合
callbacks=[tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=2)]
)
# 评估测试集
test_loss, test_acc = model.evaluate(x_test, y_test)
print(f"测试集准确率:{test_acc:.4f}")2. L1正则化(特征选择)
L1正则化会让部分权重变为0,相当于自动"删除"不重要的特征,适合需要精简模型的场景:
python
# L1正则化(lambda=0.001)
layers.Dense(128,
activation='relu',
kernel_regularizer=regularizers.l1(0.001)),3. L1-L2混合正则化(弹性网正则化)
结合L1和L2的优点,既可以精简特征,又能避免权重过大:
python
# L1-L2混合正则化(l1=0.001,l2=0.001)
layers.Dense(128,
activation='relu',
kernel_regularizer=regularizers.l1_l2(l1=0.001, l2=0.001)),4. 卷积层的正则化
正则化不仅能用在全连接层,也能用于卷积层(但卷积层参数少,一般正则化强度更低):
python
# 卷积层添加L2正则化
layers.Conv2D(32, (3, 3),
activation='relu',
kernel_regularizer=regularizers.l2(0.0001)), # 卷积层lambda更小三、关键参数与使用技巧
1. 核心参数(正则化器)
| 正则化器 | 函数 | 作用 |
|---|---|---|
| L1正则化 | regularizers.l1(lamda) |
惩罚权重绝对值,使部分权重为0(特征选择) |
| L2正则化 | regularizers.l2(lamda) |
惩罚权重平方,使权重整体变小(最常用,防过拟合) |
| L1-L2混合 | regularizers.l1_l2(l1, l2) |
结合L1和L2的优点 |
2. 关键使用原则
(1)选择合适的λ(正则化强度)
- λ过小:惩罚太轻,防过拟合效果差;
- λ过大:惩罚太重,模型欠拟合(学不到足够特征);
- 经验值:
-
全连接层:λ=0.001 ~ 0.01;
-
卷积层:λ=0.0001 ~ 0.001(卷积层参数少,无需强惩罚);
-
可通过网格搜索 确定最优λ:
python# 示例:简单网格搜索λ lambda_list = [0.0001, 0.001, 0.01] for lam in lambda_list: model = build_model(lam) # 自定义模型函数,传入λ model.fit(...) print(f"λ={lam},测试准确率:{model.evaluate(x_test, y_test)[1]:.4f}")
-
(2)正则化的适用层
- 优先用在全连接层:全连接层参数多,过拟合风险最高,正则化效果最明显;
- 卷积层慎用:卷积层共享参数,参数数量远少于全连接层,过拟合风险低,一般用BN层替代;
- 输出层一般不用:输出层权重直接影响最终预测,惩罚可能导致预测偏差。
(3)和其他防过拟合手段配合
正则化 + Dropout + 早停(EarlyStopping)是"黄金组合",效果远优于单一手段:
python
# 示例:组合防过拟合
layers.Dense(128,
activation='relu',
kernel_regularizer=regularizers.l2(0.001)), # L2正则
layers.Dropout(0.2), # Dropout
# 早停回调
early_stop = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=3, restore_best_weights=True)(4)避免正则化偏置项
默认情况下,kernel_regularizer只惩罚权重(kernel),偏置项(bias)一般不惩罚(偏置项对模型复杂度影响小):
python
# 如需惩罚偏置项,用bias_regularizer(不推荐)
layers.Dense(128,
activation='relu',
kernel_regularizer=regularizers.l2(0.001),
bias_regularizer=regularizers.l2(0.001)), # 极少使用四、正则化 vs Dropout(核心区别)
很多新手会混淆正则化和Dropout,两者核心目标都是防过拟合,但原理不同:
| 维度 | 正则化(L1/L2) | Dropout |
|---|---|---|
| 原理 | 损失函数加惩罚项,约束权重大小 | 训练时随机丢弃神经元,避免依赖少数特征 |
| 作用对象 | 权重参数 | 神经元输出 |
| 适用层 | 全连接层(优先)、卷积层(慎用) | 全连接层(核心) |
| 副作用 | 权重变小,无明显欠拟合风险 | 丢弃比例过高易欠拟合 |
最佳实践:两者结合使用,而非二选一。
总结
- 正则化的核心是给损失函数加权重惩罚项,约束模型复杂度,防止过拟合;
- TensorFlow中优先使用
tf.keras.regularizers.l2()(L2正则),λ选0.001~0.01(全连接层); - 关键技巧:
- 正则化主要用在全连接层,卷积层慎用;
- 配合Dropout+早停,防过拟合效果最佳;
- λ需调参,避免过大导致欠拟合、过小无效果。
优化器
TensorFlow中的优化器(Optimizer)详解
优化器是深度学习模型训练的"核心引擎",其作用是根据模型的损失函数梯度,调整权重参数,让模型的预测结果不断逼近真实标签(最小化损失)。TensorFlow/Keras封装了多种经典优化器,适配不同的任务场景和模型结构,下面从原理、使用方法到选型技巧全面讲解。
一、优化器的核心原理(通俗理解)
可以把模型训练比作"下山找最低点"(损失函数的最小值):
- 损失函数:是一座"山",山顶是损失最大的位置,山谷是损失最小的位置;
- 梯度:是当前位置的"坡度方向"(告诉我们往哪走能下山);
- 优化器:是"下山的策略"------不同优化器决定了"每一步走多远、往哪个方向走",最终目的是高效走到山谷。
数学本质
优化器的核心是梯度下降 :
W t + 1 = W t − η ⋅ ∇ L ( W t ) W_{t+1} = W_t - \eta \cdot \nabla L(W_t) Wt+1=Wt−η⋅∇L(Wt)
其中:
- W t W_t Wt:t时刻的权重参数;
- η \eta η(学习率):步长(每一步走多远);
- ∇ L ( W t ) \nabla L(W_t) ∇L(Wt):损失函数在 W t W_t Wt处的梯度(下山方向)。
TensorFlow的优化器本质是对基础梯度下降的改进,解决"步长难调、容易卡在局部最优、收敛慢"等问题。
二、TensorFlow中常用优化器(从基础到进阶)
梯度下降类:
o tf.train.GradientDescentOptimizer: 基础梯度下降
o tf.train.MomentumOptimizer: 带动量项的梯度下降
o tf.train.AdagradOptimizer: ⾃适应学习率
o tf.train.AdadeltaOptimizer: 改进的⾃适应学习率
o tf.train.RMSPropOptimizer: 均⽅根传播优化器
o tf.train.AdamOptimizer: ⾃适应矩估计(最常⽤)
性能对比
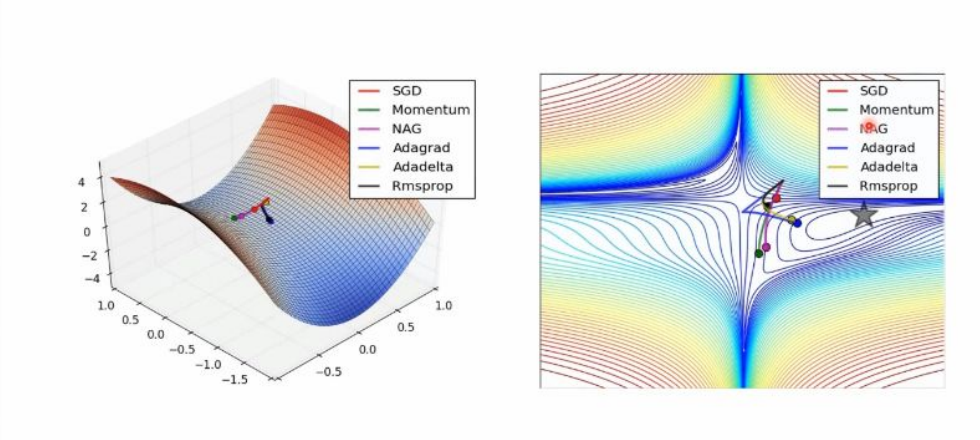
收敛速度:
o Adam和RMSProp收敛最快
o 普通SGD收敛最慢
路径平滑度:
o Momentum和NAG路径振荡较⼩
o Adagrad在后期容易出现剧烈波动
所有优化器都在tf.keras.optimizers模块下,核心使用方式是在model.compile()中指定,下面按"常用程度"排序讲解:
1. 基础优化器:SGD(随机梯度下降)
原理
最基础的优化器,分两种形式:
- 纯SGD:每次用单个样本的梯度更新参数(波动大,收敛慢);
- Mini-batch SGD:每次用一批样本的梯度更新(最常用,平衡速度和稳定性);
- SGD+动量(Momentum):模拟物理"惯性",加速收敛,减少波动。
使用示例
python
import tensorflow as tf
from tensorflow.keras import layers, models, optimizers
# 构建简单模型
def build_model(optimizer):
model = models.Sequential([
layers.Flatten(input_shape=(28, 28)),
layers.Dense(128, activation='relu'),
layers.Dense(10, activation='softmax')
])
model.compile(
optimizer=optimizer,
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy']
)
return model
# 1. 纯SGD(学习率lr=0.01)
sgd = optimizers.SGD(learning_rate=0.01)
# 2. SGD+动量(momentum=0.9,推荐)
sgd_momentum = optimizers.SGD(learning_rate=0.01, momentum=0.9)
# 加载MNIST数据
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train = x_train / 255.0
x_test = x_test / 255.0
# 训练模型(SGD+动量)
model = build_model(sgd_momentum)
history = model.fit(
x_train, y_train,
epochs=10,
batch_size=64,
validation_split=0.1
)
print(f"SGD+动量测试准确率:{model.evaluate(x_test, y_test)[1]:.4f}")特点
- 优点:简单、稳定,适合数据量大的场景;
- 缺点:学习率难调,收敛慢,容易卡在局部最优;
- 适用场景:基础验证、大规模数据集训练。
2. 进阶优化器:Adam(最常用)
原理
Adam = Adagrad(自适应学习率) + RMSprop(动量),是目前最通用、效果最好的优化器:
- 自适应调整每个参数的学习率(参数更新频繁则步长小,反之则步长大);
- 结合动量机制,加速收敛,减少波动。
使用示例
python
# Adam优化器(默认参数已适配大部分场景)
adam = optimizers.Adam(
learning_rate=0.001, # 默认学习率,无需手动调整
beta_1=0.9, # 一阶动量系数(默认)
beta_2=0.999 # 二阶动量系数(默认)
)
model = build_model(adam)
history = model.fit(x_train, y_train, epochs=10, batch_size=64, validation_split=0.1)
print(f"Adam测试准确率:{model.evaluate(x_test, y_test)[1]:.4f}")特点
- 优点:收敛快、学习率无需手动调参、适配绝大多数任务(分类、回归、GAN等);
- 缺点:在极小规模数据集上可能不如SGD稳定;
- 适用场景:几乎所有深度学习任务(优先选择)。
3. 其他常用优化器(按需选择)
| 优化器 | 核心特点 | 适用场景 |
|---|---|---|
| RMSprop | 改进Adagrad,解决学习率衰减过快问题,适合循环神经网络(RNN/LSTM) | 序列任务(文本、语音) |
| Adagrad | 对稀疏特征(如文本)自适应调整学习率,学习率随时间衰减 | 稀疏数据(NLP、推荐系统) |
| Adadelta | 无需手动设置学习率,自适应调整步长 | 学习率难调的场景 |
| Nadam | Adam + Nesterov动量,收敛更快 | 高精度要求的任务 |
示例:RMSprop(适配RNN)
python
rmsprop = optimizers.RMSprop(learning_rate=0.001, rho=0.9)
# 用于LSTM模型(文本分类)
model = models.Sequential([
layers.LSTM(64, input_shape=(None, 28)), # 序列输入
layers.Dense(10, activation='softmax')
])
model.compile(optimizer=rmsprop, loss='sparse_categorical_crossentropy', metrics=['accuracy'])三、关键参数与使用技巧
1. 核心参数(所有优化器通用)
| 参数 | 作用 |
|---|---|
learning_rate |
学习率(步长),核心参数,常用值:0.001(Adam)、0.01(SGD) |
clipnorm |
梯度裁剪(防止梯度爆炸),如clipnorm=1.0(RNN/LSTM必备) |
clipvalue |
梯度值裁剪(限制梯度绝对值不超过指定值) |
2. 核心使用原则
(1)学习率(lr)调参技巧
学习率是优化器最关键的参数,直接决定模型是否收敛:
- lr过大:损失震荡不下降(步子太大,跨出山谷);
- lr过小:收敛极慢,甚至无法收敛(步子太小,走不到山谷);
- 调参方法:
-
先试默认值:Adam=0.001,SGD=0.01;
-
网格搜索:试
[0.0001, 0.001, 0.01, 0.1],选损失下降最快的; -
学习率衰减:训练后期减小学习率,精准收敛(用回调函数):
python# 示例:学习率衰减(每5个epoch减半) lr_scheduler = tf.keras.callbacks.ReduceLROnPlateau( monitor='val_loss', # 监控验证集损失 factor=0.5, # 衰减因子(减半) patience=5, # 5个epoch没提升则衰减 min_lr=1e-6 # 最小学习率 ) model.fit(..., callbacks=[lr_scheduler])
-
(2)优化器选型优先级
- 优先用Adam:适配90%以上的任务(分类、回归、CNN、简单RNN);
- 序列任务(RNN/LSTM/Transformer):试RMSprop或Nadam;
- 大规模数据集/需要稳定收敛:试SGD+动量;
- 稀疏数据(文本/推荐):试Adagrad或Adam。
(3)梯度裁剪(解决梯度爆炸)
在RNN/LSTM、深度CNN中,梯度容易"爆炸"(梯度值过大),需用clipnorm/clipvalue:
python
# Adam + 梯度裁剪(clipnorm=1.0)
adam_clip = optimizers.Adam(learning_rate=0.001, clipnorm=1.0)(4)自定义优化器(进阶)
如需定制优化逻辑(如自定义学习率更新),可继承tf.keras.optimizers.Optimizer:
python
class CustomOptimizer(optimizers.Optimizer):
def __init__(self, learning_rate=0.001, **kwargs):
super().__init__(**kwargs)
self.lr = learning_rate
def update_step(self, gradient, variable):
# 自定义更新规则(如SGD+自定义衰减)
variable.assign_sub(self.lr * gradient)四、优化器对比(直观参考)
| 优化器 | 收敛速度 | 稳定性 | 调参难度 | 适用场景 |
|---|---|---|---|---|
| SGD | 慢 | 高 | 高 | 大规模数据集、基础验证 |
| SGD+动量 | 中 | 高 | 中 | 需稳定收敛的场景 |
| Adam | 快 | 中 | 低 | 绝大多数任务(优先选) |
| RMSprop | 快 | 中 | 低 | 序列任务(RNN/LSTM) |
总结
- 优化器的核心是根据梯度调整权重,不同优化器是梯度下降的不同"下山策略";
- 选型优先级:Adam(通用)> RMSprop(序列任务)> SGD+动量(大规模数据);
- 关键技巧:
- 学习率是核心参数,默认值优先,需时用衰减策略;
- RNN/LSTM需加梯度裁剪(clipnorm);
- 训练后期用学习率衰减,提升模型精度。