- 🍨 本文为 🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者: K同学啊
一、前置知识
1、VGG-16算法介绍
VGG-16 是深度学习计算机视觉领域中非常著名且经典的卷积神经网络(CNN)模型,由牛津大学的 Visual Geometry Group (VGG) 提出。它在 2014 年的 ImageNet 竞赛中取得了极好的成绩,并且因为其结构简洁、规整,至今仍常被用作教学示例或特征提取的基础模型。
VGG-16 最显著的特点就是它的"深度"(16层带权重的层)以及它对小尺寸卷积核(3x3)的坚持使用。我们可以一起来探索它的奥秘。
1.1、网络架构与"积木"结构
为了理解 VGG-16 的架构,我们可以把它想象成一个"5级浓缩果汁加工厂"。
标准化的车间(卷积块):
- 这个工厂有 5 个主要车间(对应 5 个卷积块)。
- 虽然车间的大小不同,但里面的工序是一模一样的:都是用同一种小刀(3*3 卷积核)去切水果(提取特征)。
- 前两个车间比较初级,每个车间有 2 道 工序(2 层卷积);后三个车间比较高级,每个车间有 3 道工序(3 层卷积)。
过滤筛网(池化层):
- 每通过一个车间,果汁就会经过一个筛子(最大池化层 Max Pooling)。
- 这个筛子的作用是把渣滓滤掉,只保留最浓缩的精华。
- 结果是:果汁的体积变小了 (图片尺寸减半),但是浓度变高了(通道数/特征维度翻倍)。
品鉴专家(全连接层):
- 经过 5 个车间的反复提炼,最后得到的"高浓缩浆"被送到了 3 位专家面前(3 层全连接层)。
- 他们不再关心水果的形状,只根据浓缩浆的成分,拍板定案:这是"苹果汁"还是"橙汁"(分类结果)。
1.2、核心创新:为什么是 3x3?
为了理解为什么要"舍大求小",我们可以想象 "警察审讯嫌疑人" 的场景。
大卷积核(一次审完):
- 就像一个彪悍的警察,把嫌疑人抓来,直接问一个非常宏大的问题(看 7*7 的大范围)。
- 他只问一次,虽然覆盖面广,但只有一次判断机会。如果嫌疑人撒谎,很难立刻识破,细节容易丢失。
小卷积核堆叠(层层盘问):
- 就像三个精明的侦探轮流审讯(三层 3 * 3)。
- 第一个侦探问细节,整理出初级线索;
- 第二个侦探拿着初级线索,进一步挖掘逻辑矛盾;
- 第三个侦探基于前两人的报告,得出最终结论。
- 结果: 虽然每次每个人问的范围小,但三个人加起来覆盖的信息量(感受野)和那个彪悍警察一样大。更重要的是,中间多了两次"思考和分析"(非线性激活),能挖出更深层的真相,而且雇佣这三个人的成本(参数量)比那个大牌警察还低!
1.3、从输入到输出的流程
把 VGG-16 想象成一条"数据流水线"。我们将追踪一张猫的照片**(224 * 224 像素)是如何进入网络,被层层"扒皮",最后变成一个简单的单词"Cat"的。
我们可以把这个过程想象成 "从拼图碎片到鉴定报告" 的过程
输入端(一堆碎片):
- 你给了机器一盒 224x224 的拼图碎片(原始像素),看起来乱七八糟,毫无意义。
浅层处理(Block 1-2:整理员):
- 机器先把碎片按颜色、直边、转角分类。
- 它看到了什么: 线条、边缘、颜色斑点。
- 状态: 拼图还很散,但每一堆分类变得更厚了。
中层处理(Block 3-4:拼凑员):
- 机器开始把碎片拼成小块,比如"圆圆的东西"(可能是眼睛)或"毛茸茸的三角"(可能是耳朵)。
- 它看到了什么: 纹理、五官、局部形状。
- 状态: 拼图块变大了(特征图尺寸变小),信息更具体了(通道数变多)。
深层处理(Block 5:统筹师):
- 机器把局部拼在一起,发现是一个"有着尖耳朵和胡须的头像"。
- 它看到了什么: 完整的物体概念(猫的头、猫的腿)。
全连接层(鉴定官):
- 鉴定官不再看图了,他拿着统筹师给的"特征清单"(有胡须、有尖耳、有瞳孔),直接在表格上打勾。
- 输出: "猫"的概率是 98%,"狗"的概率是 2%。
到现在为止,你已经掌握了 VGG-16 的架构 (2-2-3-3-3) 、核心原理 (小卷积核) 以及数据流向 (宽变窄,薄变厚)。
二、代码实现
1、准备工作
1.1.设置GPU
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0],"GPU")
print(gpus)
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]1.2.导入数据
import os,PIL,pathlib
import matplotlib.pyplot as plt
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers,models
# 查看当前工作路径(确认路径是否正确)
print("当前工作路径:", os.getcwd())
# 定义数据目录(建议用绝对路径更稳妥,相对路径依赖当前工作路径)
data_dir = './data/day07/'
data_dir = pathlib.Path(data_dir)
# 获取数据目录下的所有子路径(文件夹或文件)
data_paths = list(data_dir.glob('*'))
# 提取每个子路径的名称(即类别名,自动适配系统分隔符)
classeNames = [path.name for path in data_paths]
classeNames
2026-03-12 23:43:35.439613: I tensorflow/core/util/util.cc:169] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
当前工作路径: /root/autodl-tmp/TensorFlow2
['Green', 'Medium', 'Light', 'Dark']1.3.查看数据
image_count = len(list(data_dir.glob('*/*.png')))
print("图片总数为:",image_count)
图片总数为: 12001.4.可视化图片
roses = list(data_dir.glob('Green/*.png'))
PIL.Image.open(str(roses[0]))
2、数据预处理
2.1.加载数据
-
使用image_dataset_from_directory方法将磁盘中的数据加载到tf.data.Dataset中
batch_size = 32
img_height = 224
img_width = 224#训练集
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)Found 1200 files belonging to 4 classes.
Using 960 files for training.验证集
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)Found 1200 files belonging to 4 classes.
Using 240 files for validation.class_names = train_ds.class_names
print(class_names)['Dark', 'Green', 'Light', 'Medium']
2.2.可视化数据
plt.figure(figsize=(10, 4)) # 图形的宽为10高为5
for images, labels in train_ds.take(1):
for i in range(10):
ax = plt.subplot(2, 5, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
2.3.检查数据
- Image_batch是形状的张量(32,180,180,3)。这是一批形状180x180x3的32张图片(最后一维指的是彩色通道RGB)。
-
Label_batch是形状(32,)的张量,这些标签对应32张图片
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break(32, 224, 224, 3)
(32,)
2.4.配置数据集
- shuffle() :打乱数据,关于此函数的详细介绍可以参考
- prefetch() :预取数据,加速运行
-
cache() :将数据集缓存到内存当中,加速运行
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)normalization_layer = layers.experimental.preprocessing.Rescaling(1./255)
train_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
val_ds = val_ds.map(lambda x, y: (normalization_layer(x), y))image_batch, labels_batch = next(iter(val_ds))
first_image = image_batch[0]查看归一化后的数据
print(np.min(first_image), np.max(first_image))
0.0 1.0
3、训练模型
3.1.构建VGG-16网络
from tensorflow.keras import layers, models, Input
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Flatten, Dropout
def VGG16(nb_classes, input_shape):
input_tensor = Input(shape=input_shape)
# 1st block
x = Conv2D(64, (3,3), activation='relu', padding='same',name='block1_conv1')(input_tensor)
x = Conv2D(64, (3,3), activation='relu', padding='same',name='block1_conv2')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block1_pool')(x)
# 2nd block
x = Conv2D(128, (3,3), activation='relu', padding='same',name='block2_conv1')(x)
x = Conv2D(128, (3,3), activation='relu', padding='same',name='block2_conv2')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block2_pool')(x)
# 3rd block
x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv1')(x)
x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv2')(x)
x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv3')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block3_pool')(x)
# 4th block
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv1')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv2')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv3')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block4_pool')(x)
# 5th block
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv1')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv2')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv3')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block5_pool')(x)
# full connection
x = Flatten()(x)
x = Dense(4096, activation='relu', name='fc1')(x)
x = Dense(4096, activation='relu', name='fc2')(x)
output_tensor = Dense(nb_classes, activation='softmax', name='predictions')(x)
model = Model(input_tensor, output_tensor)
return model
model=VGG16(len(class_names), (img_width, img_height, 3))
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 224, 224, 3)] 0
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
flatten (Flatten) (None, 25088) 0
fc1 (Dense) (None, 4096) 102764544
fc2 (Dense) (None, 4096) 16781312
predictions (Dense) (None, 4) 16388
=================================================================
Total params: 134,276,932
Trainable params: 134,276,932
Non-trainable params: 0
_________________________________________________________________3.2.编译模型
SparseCategoricalCrossentropy函数注意事项:
from_logits参数:布尔值,默认值为 False。
- 当为 True 时,函数假设传入的预测值是未经过激活函数处理的原始 logits 值。如果模型的最后一层没有使用 softmax 激活函数(即返回 logits),需要将 from_logits 设置为 True。
-
当为 False 时,函数假设传入的预测值已经是经过 softmax 处理的概率分布。
设置初始学习率
initial_learning_rate = 1e-4
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate,
decay_steps=30, # 敲黑板!!!这里是指 steps,不是指epochs
decay_rate=0.92, # lr经过一次衰减就会变成 decay_rate*lr
staircase=True)设置优化器
opt = tf.keras.optimizers.Adam(learning_rate=initial_learning_rate)
model.compile(optimizer=opt,
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['accuracy'])
3.3.训练模型
epochs = 20
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
Epoch 1/20
30/30 [==============================] - 13s 160ms/step - loss: 1.3507 - accuracy: 0.3385 - val_loss: 1.1250 - val_accuracy: 0.2750
Epoch 2/20
30/30 [==============================] - 4s 142ms/step - loss: 0.8362 - accuracy: 0.6146 - val_loss: 0.6616 - val_accuracy: 0.5917
....
Epoch 19/20
30/30 [==============================] - 4s 138ms/step - loss: 0.0256 - accuracy: 0.9917 - val_loss: 0.0535 - val_accuracy: 0.9917
Epoch 20/20
30/30 [==============================] - 4s 138ms/step - loss: 0.0121 - accuracy: 0.9937 - val_loss: 0.0499 - val_accuracy: 0.99584、模型评估
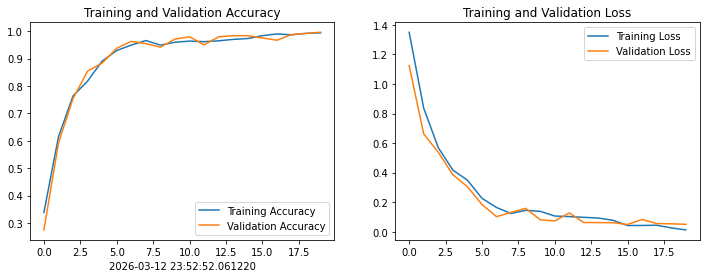
4.1.Loss与Accuracy图
from datetime import datetime
current_time = datetime.now() # 获取当前时间
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.xlabel(current_time) # 打卡请带上时间戳,否则代码截图无效
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()