目录
[一、简单了解 OpenCV DNN 模块及使用流程](#一、简单了解 OpenCV DNN 模块及使用流程)
[二、代码案例:DNN 实战实现性别年龄检测](#二、代码案例:DNN 实战实现性别年龄检测)
[1. 环境准备与模块导入](#1. 环境准备与模块导入)
[2. 模型初始化(加载3个核心预训练模型)](#2. 模型初始化(加载3个核心预训练模型))
[3. 变量初始化(定义预测标签与模型参数)](#3. 变量初始化(定义预测标签与模型参数))
[4. 自定义函数(人脸检测+中文显示)](#4. 自定义函数(人脸检测+中文显示))
[(1)人脸检测函数 getBoxes()](#(1)人脸检测函数 getBoxes())
[(2)中文显示函数 cv2_put_chinese_text()](#(2)中文显示函数 cv2_put_chinese_text())
[5. 主程序(打开摄像头,实时检测与预测)](#5. 主程序(打开摄像头,实时检测与预测))
在计算机视觉领域,实时性别与年龄检测是一个非常经典且实用的场景,无论是相机美颜功能、门禁识别还是短视频特效,都能看到它的身影。而 OpenCV 中的 DNN(深度神经网络)模块,正是实现这一功能的"捷径"------无需搭建复杂的深度学习训练框架,只需加载预训练模型,就能快速完成推理预测。
一、简单了解 OpenCV DNN 模块及使用流程
OpenCV 的 DNN 模块,核心作用是加载预训练的深度学习模型,并完成图像预处理、网络推理等一系列操作,让开发者无需深入研究深度学习底层原理,就能快速实现各类视觉任务。
DNN 模块的核心使用流程非常简洁,仅需3步,也是我们本次实战的核心逻辑:
-
模型加载 :通过
cv2.dnn.readNet()函数,加载预训练模型的"权重文件"和"配置文件",初始化网络模型(本次需加载人脸检测、年龄预测、性别预测3个模型)。 -
图像预处理 :通过
cv2.dnn.blobFromImage()函数,将原始图像转换成模型能接受的输入格式(Blob 格式),完成尺寸缩放、均值减法等预处理操作。 -
网络推理 :将预处理后的图像输入模型,通过
net.setInput()设置输入,net.forward()执行前向传播,最终得到预测结果,再对结果进行解析,输出我们需要的信息(本次为性别和年龄)。
二、代码案例:DNN 实战实现性别年龄检测
下面我们结合完整代码,逐段拆解如何用 DNN 模块实现实时性别年龄检测,代码已优化注释,贴合实战场景,可直接复制运行(需提前准备好模型文件)。
1. 环境准备与模块导入
首先需要安装依赖库,本次用到 OpenCV、PIL(解决中文显示)、numpy(图像数组处理),安装命令和模块导入代码如下:
python
import cv2
from PIL import Image, ImageDraw, ImageFont # 用于解决OpenCV中文显示问题,需执行pip install pillow
import numpy as np2. 模型初始化(加载3个核心预训练模型)
本次实战需要3个预训练模型,分别用于人脸检测(定位画面中的人脸)、年龄预测、性别预测。首先指定模型文件路径(代码中路径为 model1 文件夹,可根据自己的文件位置修改),再加载网络模型。
python
# =====模型初始化======
# 模型路径:分别对应人脸检测、年龄预测、性别预测的配置文件和权重文件
faceProto = "model1/opencv_face_detector.pbtxt"
faceModel = "model1/opencv_face_detector_uint8.pb"
ageProto = "model1/deploy_age.prototxt"
ageModel = "model1/age_net.caffemodel"
genderProto = "model1/deploy_gender.prototxt"
genderModel = "model1/gender_net.caffemodel"
# 加载网络模型(DNN核心步骤1:模型加载)
ageNet = cv2.dnn.readNet(ageModel, ageProto) # 加载年龄预测模型(权重+配置)
genderNet = cv2.dnn.readNet(genderModel, genderProto) # 加载性别预测模型
faceNet = cv2.dnn.readNet(faceModel, faceProto) # 加载人脸检测模型3. 变量初始化(定义预测标签与模型参数)
定义年龄和性别的预测标签列表,以及模型预处理需要用到的均值(均值参数由模型训练时确定,直接沿用即可)。
python
# =======变量初始化===========
# 年龄段标签(模型预定义的8个年龄段,与模型输出对应)
ageList = ["0-2岁", "4-6岁", "8-12岁", "15-20岁", "25-32岁", "38-43岁", "48-53岁", "60-100岁"]
# 性别标签(模型输出仅两类:男性、女性)
genderList = ["男性", "女性"]
# 模型均值:用于图像预处理,消除光照等因素对预测结果的影响
mean = (78.4263377603, 87.7689143744, 114.895847746) # 模型训练时用到的均值,直接复用4. 自定义函数(人脸检测+中文显示)
封装两个核心自定义函数,分别用于检测人脸并绘制人脸框、解决 OpenCV 默认不支持中文显示的问题(避免预测结果中的中文显示为方框)。
(1)人脸检测函数 getBoxes()
该函数接收模型和图像帧,完成人脸检测、置信度筛选、人脸框绘制,最终返回绘制好人脸框的图像和人脸坐标列表,完整复现 DNN 模块的3步核心流程。
python
# =======自定义函数,获取人脸包围框=======
def getBoxes(net, frame):
frameHeight, frameWidth = frame.shape[:2] # 获取图像的高度和宽度,用于后续坐标转换
# DNN核心步骤2:图像预处理,将原始图像转换成模型可接受的Blob格式
blob = cv2.dnn.blobFromImage(frame, scalefactor=1.0, size=(300, 300),
mean=[104, 117, 123], swapRB=True, crop=False)
# DNN核心步骤3:网络推理,获取人脸检测结果
net.setInput(blob) # 给模型设置输入(预处理后的Blob图像)
detections = net.forward() # 执行前向传播,得到检测结果(四维数组)
faceBoxes = [] # 用于存储检测到的所有人脸坐标(左上角x1,y1,右下角x2,y2)
# 遍历所有检测结果,筛选出置信度大于0.7的人脸(置信度越高,检测越准确)
for i in range(detections.shape[2]):
confidence = detections[0, 0, i, 2] # 获取当前检测结果的置信度
if confidence > 0.7: # 筛选置信度>0.7的有效人脸,过滤误检测
# 将归一化的坐标转换为原始图像的实际坐标
x1 = int(detections[0, 0, i, 3] * frameWidth)
y1 = int(detections[0, 0, i, 4] * frameHeight)
x2 = int(detections[0, 0, i, 5] * frameWidth)
y2 = int(detections[0, 0, i, 6] * frameHeight)
faceBoxes.append([x1, y1, x2, y2]) # 将有效人脸坐标存入列表
# 绘制人脸框(绿色边框,线条粗细自适应图像高度,线条类型更流畅)
cv2.rectangle(frame, (x1, y1), (x2, y2),
(0, 255, 0), int(round(frameHeight / 150)), 6)
# 返回绘制了人脸框的图像、以及所有人脸的坐标列表
return frame, faceBoxes(2)中文显示函数 cv2_put_chinese_text()
利用 PIL 库将 OpenCV 图像转换为 PIL 图像,绘制中文后再转换回 OpenCV 图像格式,解决中文显示问题(代码中使用系统自带的宋体字体,无需额外下载)。
python
def cv2_put_chinese_text(img, text, pos, font_size=30, color=(0, 255, 0)):
# 将OpenCV的BGR图像转换为PIL的RGB图像(两者色彩空间不同,避免颜色失真)
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
pil_img = Image.fromarray(img_rgb) # 转换为PIL图像对象
# 加载系统自带的宋体字体(路径为Windows系统默认字体路径,Linux/Mac需修改路径)
font = ImageFont.truetype("C:/Windows/Fonts/simsun.ttc", font_size, encoding="utf-8")
draw = ImageDraw.Draw(pil_img) # 创建绘制对象
# 绘制中文文本(注意:PIL的颜色通道是RGB,与OpenCV的BGR相反,需转换颜色顺序)
draw.text(pos, text, font=font, fill=(color[2], color[1], color[0]))
# 将PIL图像转换回OpenCV的BGR图像,返回用于后续显示
img_bgr = cv2.cvtColor(np.array(pil_img), cv2.COLOR_RGB2BGR)
return img_bgr5. 主程序(打开摄像头,实时检测与预测)
打开电脑摄像头,逐帧捕获图像,调用上述函数完成人脸检测、性别年龄预测,实时显示结果,按 ESC 键退出程序。
python
"""打开摄像头,将每一帧画面传入神经网络中,实现实时检测"""
cap = cv2.VideoCapture(0) # 装载摄像头(0表示默认摄像头,外接摄像头可改为1)
while True:
_, frame = cap.read() # 读取一帧图像(_表示忽略返回的状态值)
frame = cv2.flip(frame, flipCode=1) # 镜像处理图像,让画面与实际动作一致(更自然)
# 调用人脸检测函数,获取绘制好人脸框的图像和人脸坐标列表
frame, faceBoxes = getBoxes(faceNet, frame)
if not faceBoxes: # 若未检测到人脸,打印提示并跳过后续操作,继续捕获下一帧
print("当前镜头中没有人")
continue
# 遍历每一个检测到的人脸,分别预测其性别和年龄
for faceBox in faceBoxes:
x1,y1,x2,y2 = faceBox # 提取单个人脸的坐标
face = frame[y1:y2,x1:x2] # 从原始图像中截取人脸区域(只对人脸进行预测,提高效率)
# 对截取的人脸进行预处理,适配年龄/性别模型的输入尺寸(227x227,参考模型论文要求)
blob = cv2.dnn.blobFromImage(face, scalefactor=1.0, size=(227, 227), mean=mean)
# 调用性别预测模型,得到性别结果
genderNet.setInput(blob)
genderOuts = genderNet.forward() # 得到性别预测的概率分布
gender = genderList[genderOuts[0].argmax()] # 取概率最大的标签作为性别结果
# 调用年龄预测模型,得到年龄结果
ageNet.setInput(blob)
ageOuts = ageNet.forward() # 得到年龄预测的概率分布
age = ageList[ageOuts[0].argmax()] # 取概率最大的标签作为年龄结果
# 格式化性别和年龄结果,用于后续显示
result = "{},{}".format(gender, age)# 拼接性别和年龄,格式为"性别,年龄"
# 调用中文显示函数,将结果绘制在人脸框上方(避免遮挡人脸)
frame = cv2_put_chinese_text(frame, result, (x1, y1-30))
cv2.imshow("result", frame) # 显示实时检测结果窗口
# 按下Esc键(ASCII码27),退出循环,结束程序
if cv2.waitKey(1) == 27:
break
# 释放摄像头资源,关闭所有显示窗口(避免占用资源)
cv2.destroyAllWindows()
cap.release()运行效果展示:
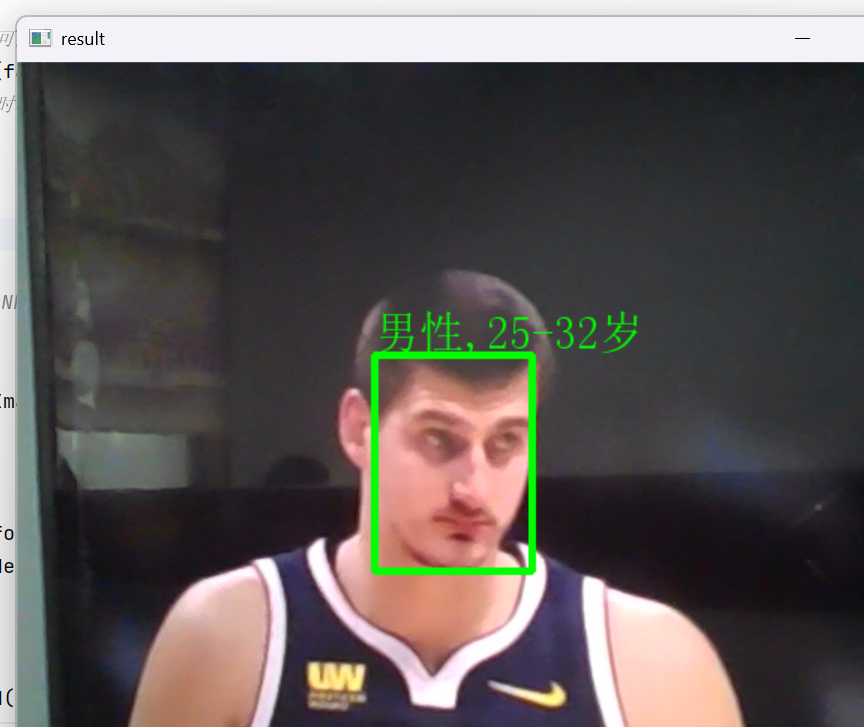
三、运行注意事项(必看)
-
模型文件:确保 model1 文件夹中存在代码中指定的6个模型文件(3个配置文件 .prototxt,3个权重文件 .pb/.caffemodel),可从 OpenCV 官方仓库下载。
-
中文显示:若为 Linux 或 Mac 系统,需修改
cv2_put_chinese_text()中的字体路径,替换为对应系统的宋体/黑体路径。 -
摄像头权限:运行程序时,需允许电脑摄像头访问权限,否则无法捕获图像。
-
检测效果:该案例使用轻量级预训练模型,在光线充足、正脸清晰的场景下效果最佳,侧脸、暗光环境可能会影响预测精度。
总结
通过本次实战,我们不难发现,OpenCV DNN 模块极大降低了深度学习视觉任务的实现门槛------只需遵循"模型加载→图像预处理→网络推理"3步流程,就能快速实现实时性别年龄检测。
整个代码的核心的是利用 DNN 模块加载预训练模型,避免了从零训练模型的复杂流程,适合初学者快速上手。如果想提升预测精度,可以替换更复杂的预训练模型;如果想拓展功能,还可以加入人脸跟踪、结果保存等逻辑。