一、本地部署 local
1、准备spark配置文件,并上传到centos
我用夸克网盘分享了「spark-3.0.1-bin-hadoop2.7.tgz」,点击链接即可保存。打开「夸克APP」,无需下载在线播放视频,畅享原画5倍速,支持电视投屏。
链接:https://pan.quark.cn/s/0c0404eab4bb
2、解压到指定目录
tar -zxvf spark-3.0.1-bin-hadoop2.7.tgz -C /root3、将 spark-3.0.1-bin-hadoop2.7改名为spark-local
mv spark-3.0.1-bin-hadoop2.7 spark-local4、进入spark-local
cd spark-local5、启动spark
bin/spark-shell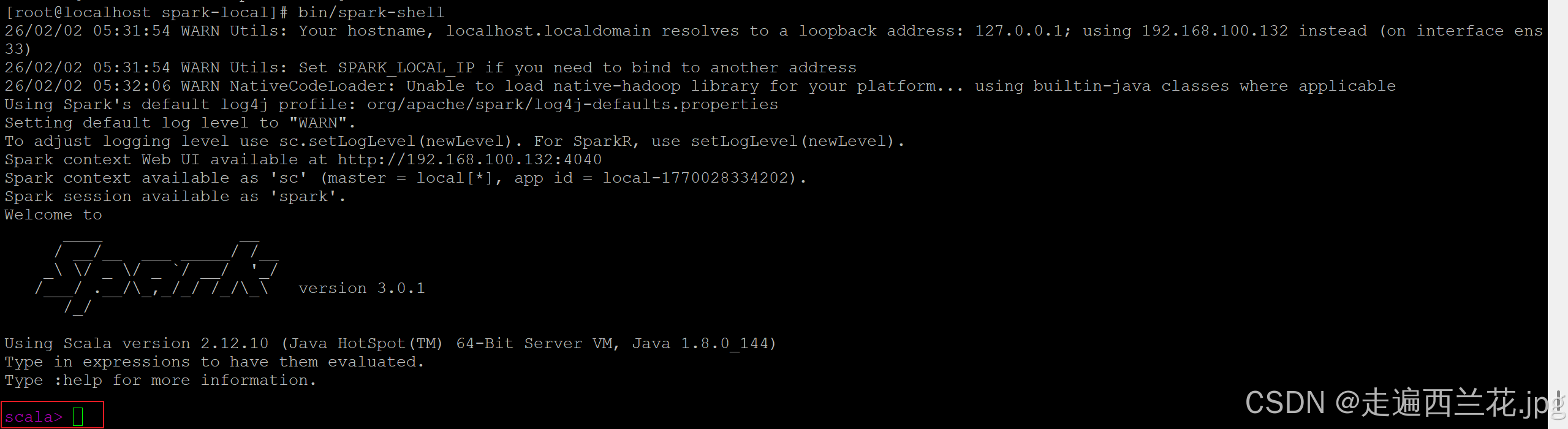
出现scala这个代表启动成功
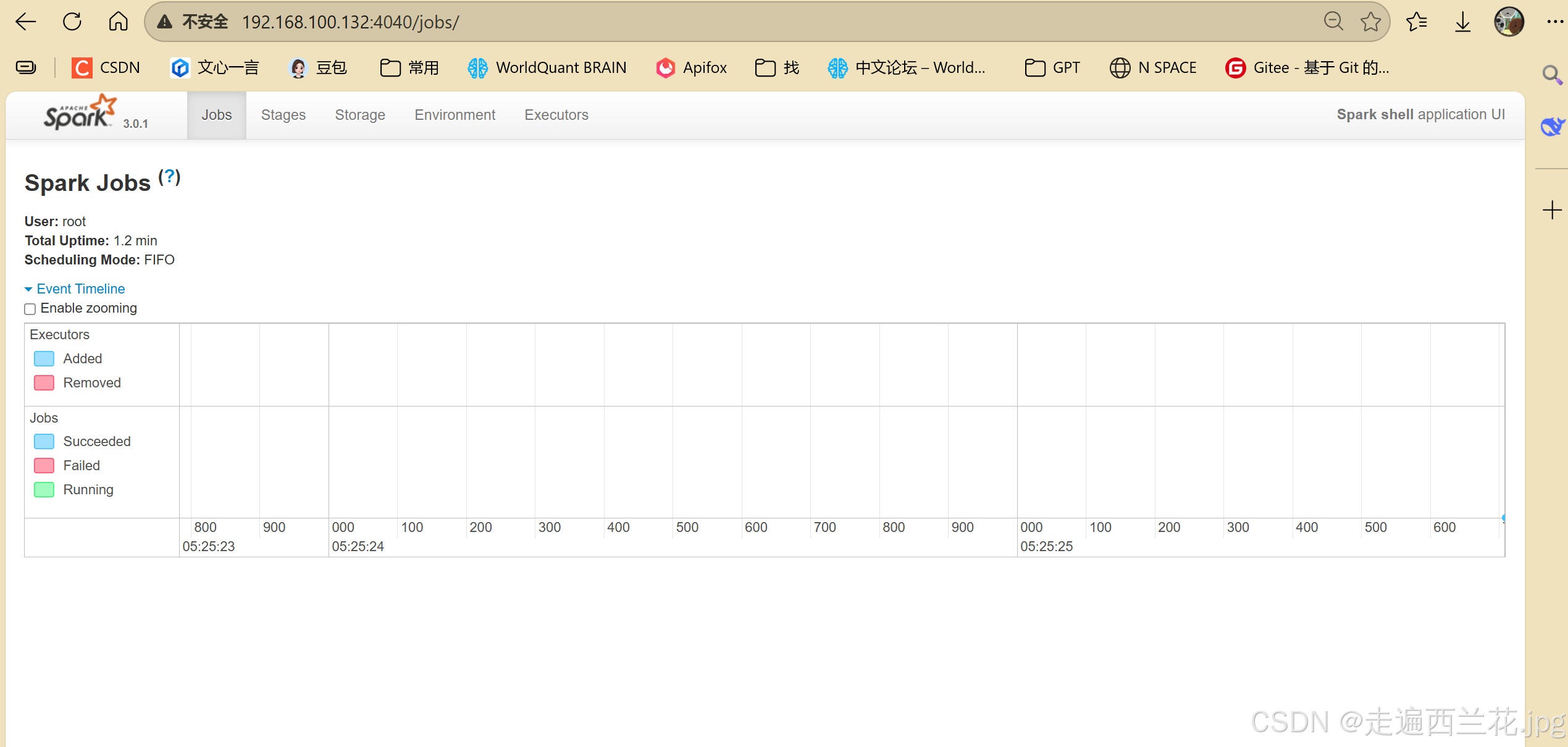
6、启动后可以去http://192.168.100.132:4040查看任务执行情况
7、在spark-local目录下新建一个data目录,并编辑一个1.txt,内容如下:
hello world
hello spark
hello java
hello python
8、在scala下执行指令测试一下
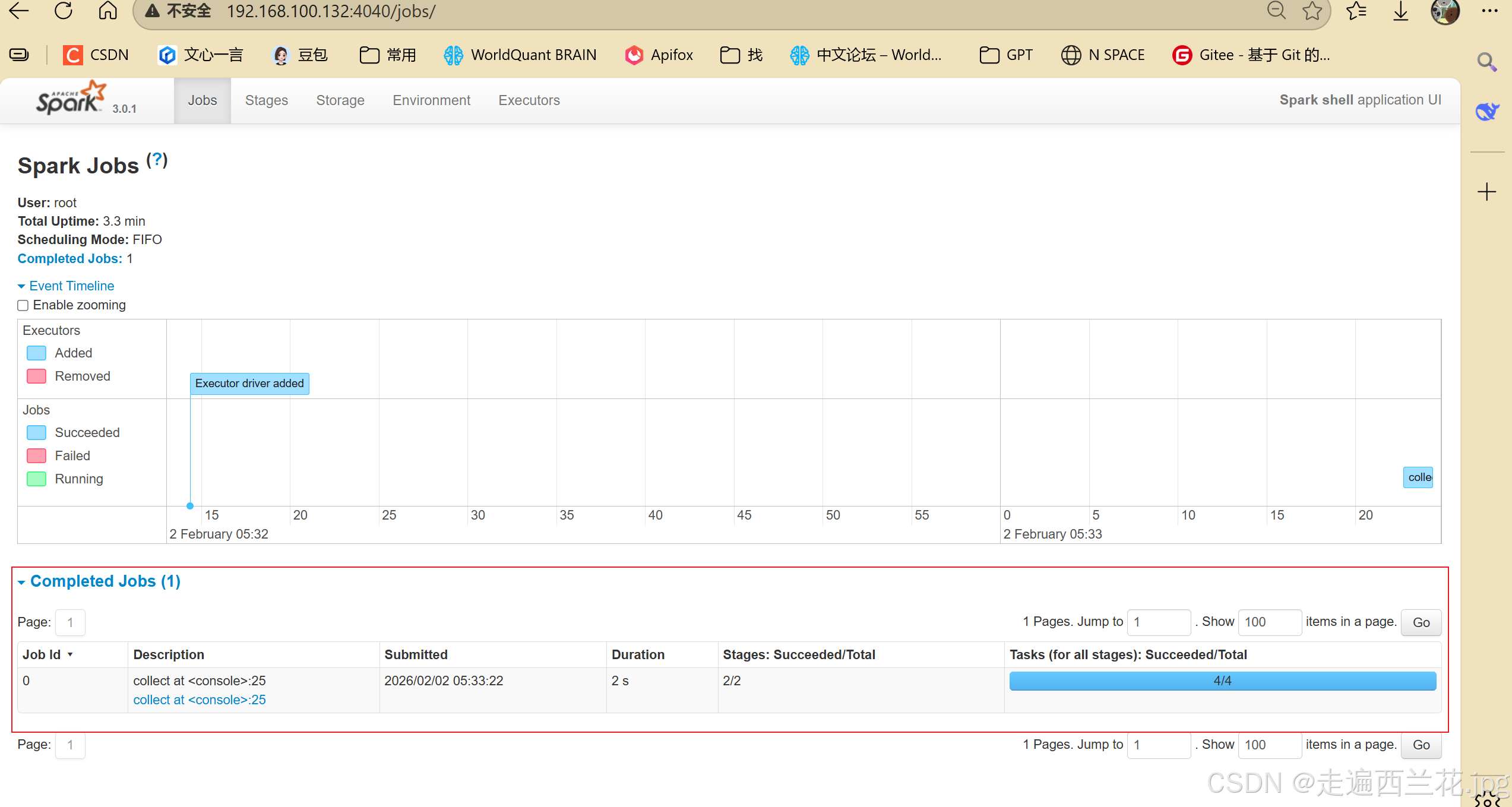
sc.textFile("data/1.txt").flatMap(_.split("")).map((_,1)).reduceByKey(_+_).collect
9、还可以将idea的文件打包,放在spark中运行
点击maven-->双击package,在下面控制台可以看到保存的路径
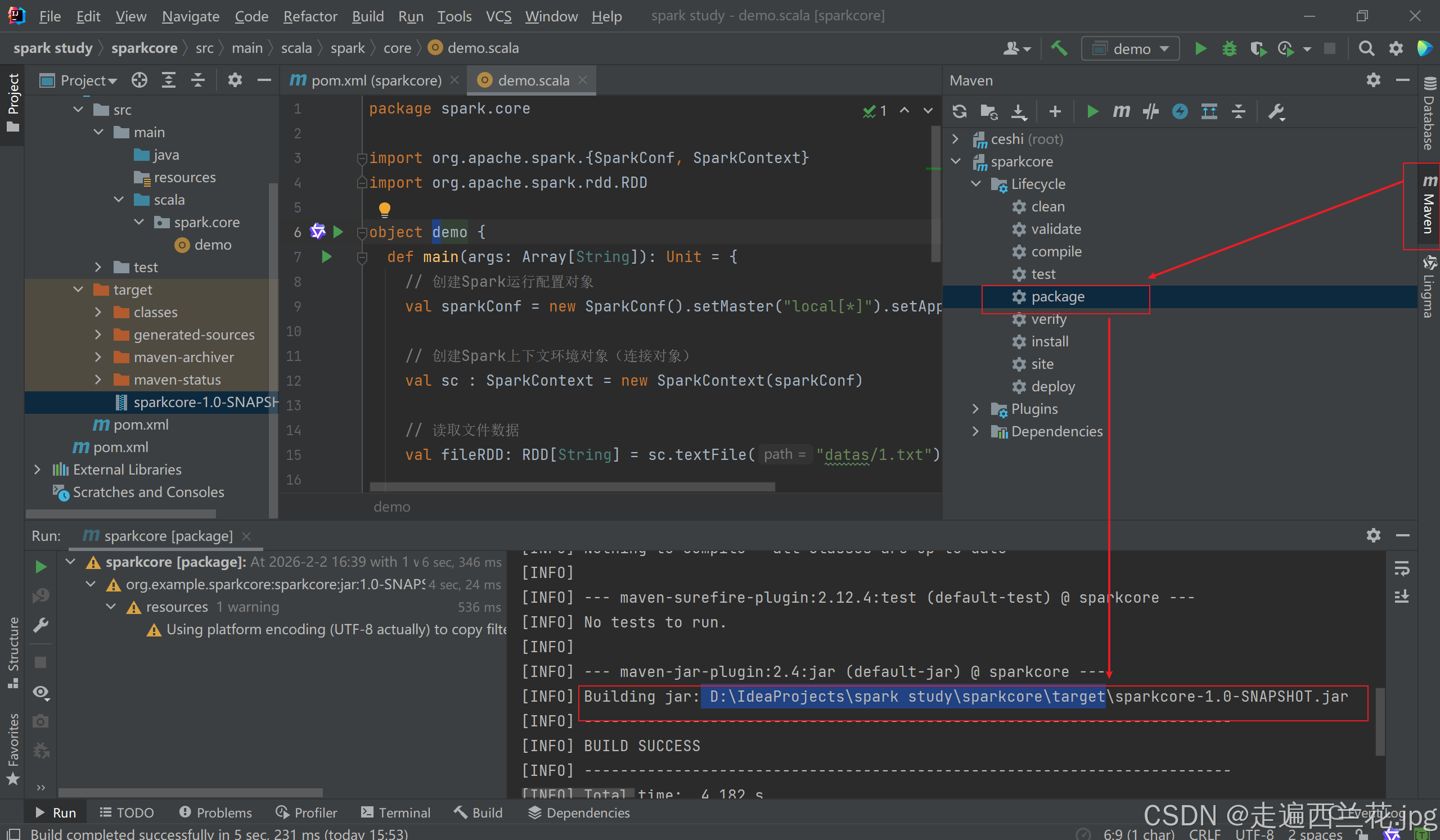
将这个压缩包直接上传到centos,不用解压
在spark-local目录下执行下面的指令
bin/spark-submit \
--class spark.core.demo \
--master spark://192.168.100.132:7070 \
/root/sparkcore-1.0-SNAPSHOT.jar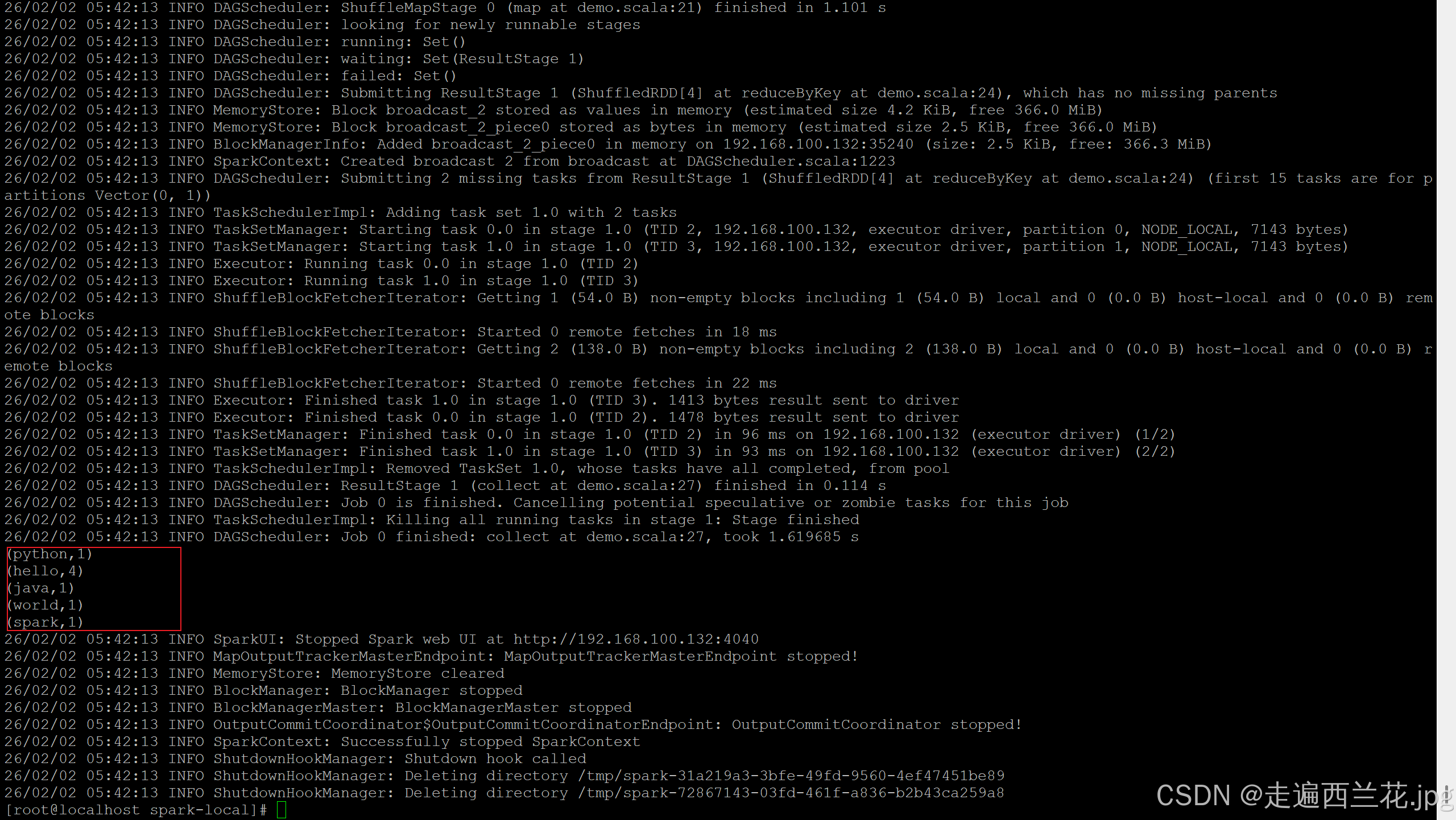
二、部署 standalone
1、还是之前的文件spark-3.0.1-bin-hadoop2.7.tgz解压到root下
tar -zxvf spark-3.0.1-bin-hadoop2.7.tgz -C /root2、进入root下,将spark-3.0.1-bin-hadoop2.7名字改为spark-standalone
mv spark-3.0.1-bin-hadoop2.7 spark-standalone3、进入spark-standalone/conf
cd spark-standalone/conf4、将slaves.template重命名为slaves
mv slaves.template slaves5、编辑slaves,把localhost.localdomain改为localhost,
vim slaves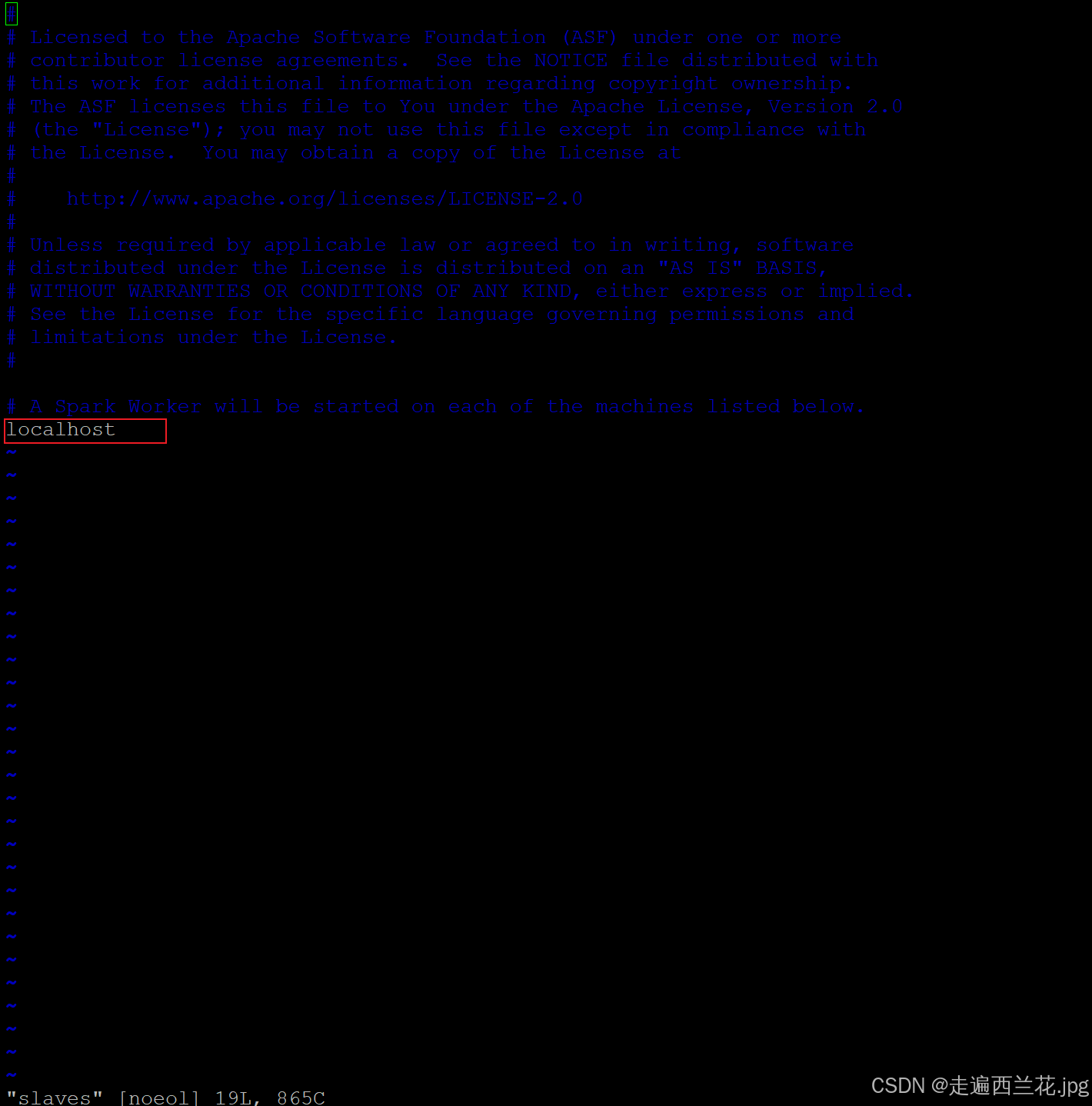
6、将spark-env.sh.template 重命名为spark-env.sh
mv spark-env.sh.template spark-env.sh7、编辑spark-env.sh,在文件最后添加三行命令
vim spark-env.sh
export JAVA_HOME=/home/jdk1.8.0_144
SPARK_MASTER_HOST=192.168.100.132
SPARK_MASTER_PORT=7077
//如何查看JDK版本:echo $JAVA_HOME8、回到上一级目录spark-standalone
cd ..9、启动spark进程
sbin/start-all.sh
查看进程

10、启动hadoop进程
start-all.sh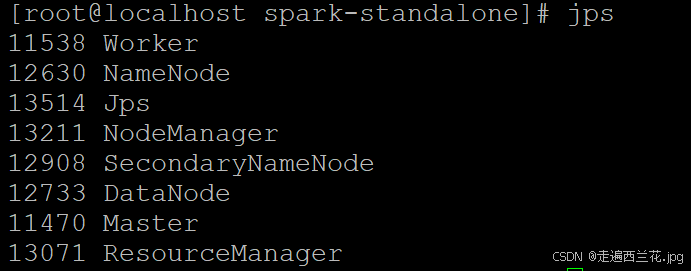
11、进入http://192.168.100.132:8080
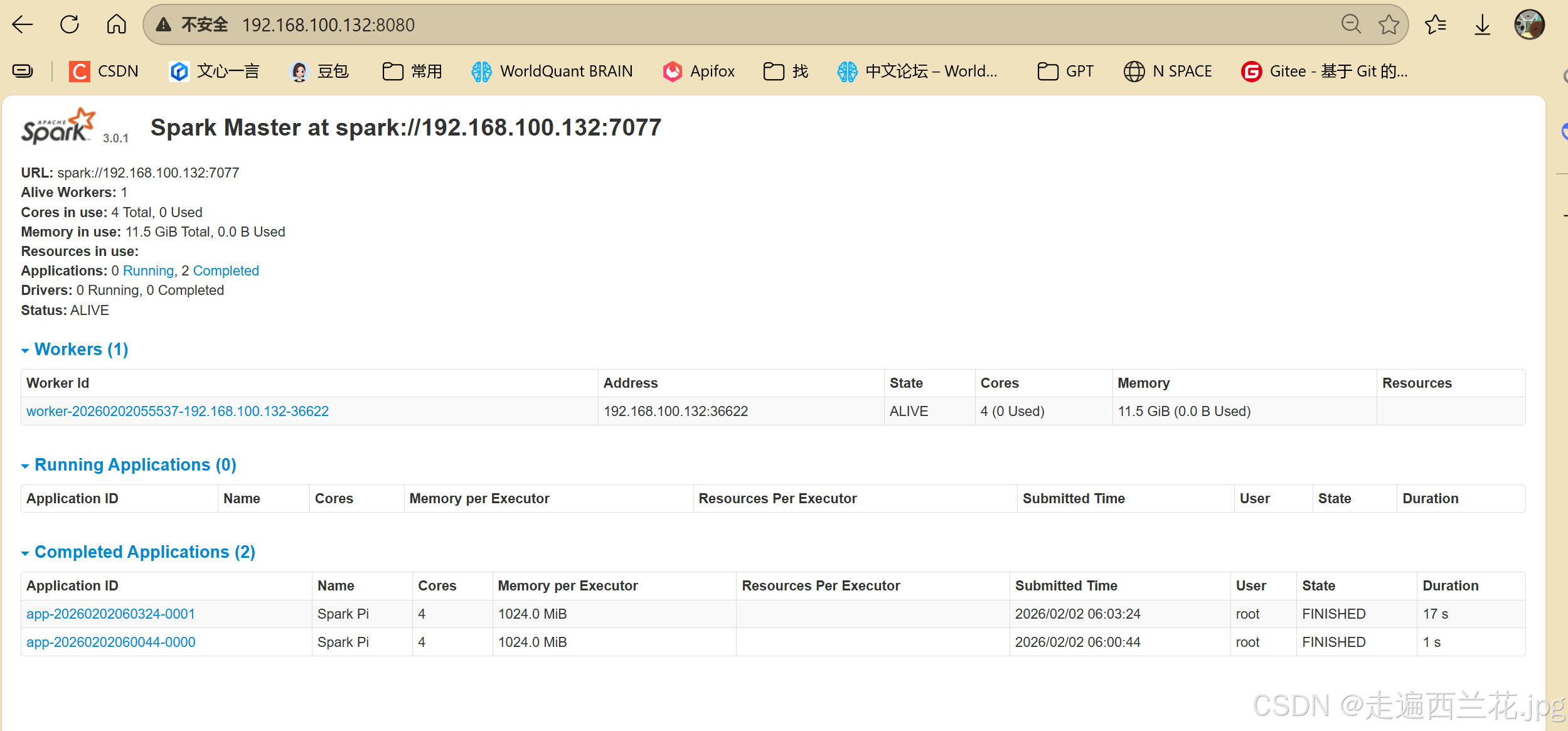
12、执行一条指令试一下
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://192.168.100.132:7077 \
./examples/jars/spark-examples_2.12-3.0.1.jar \
10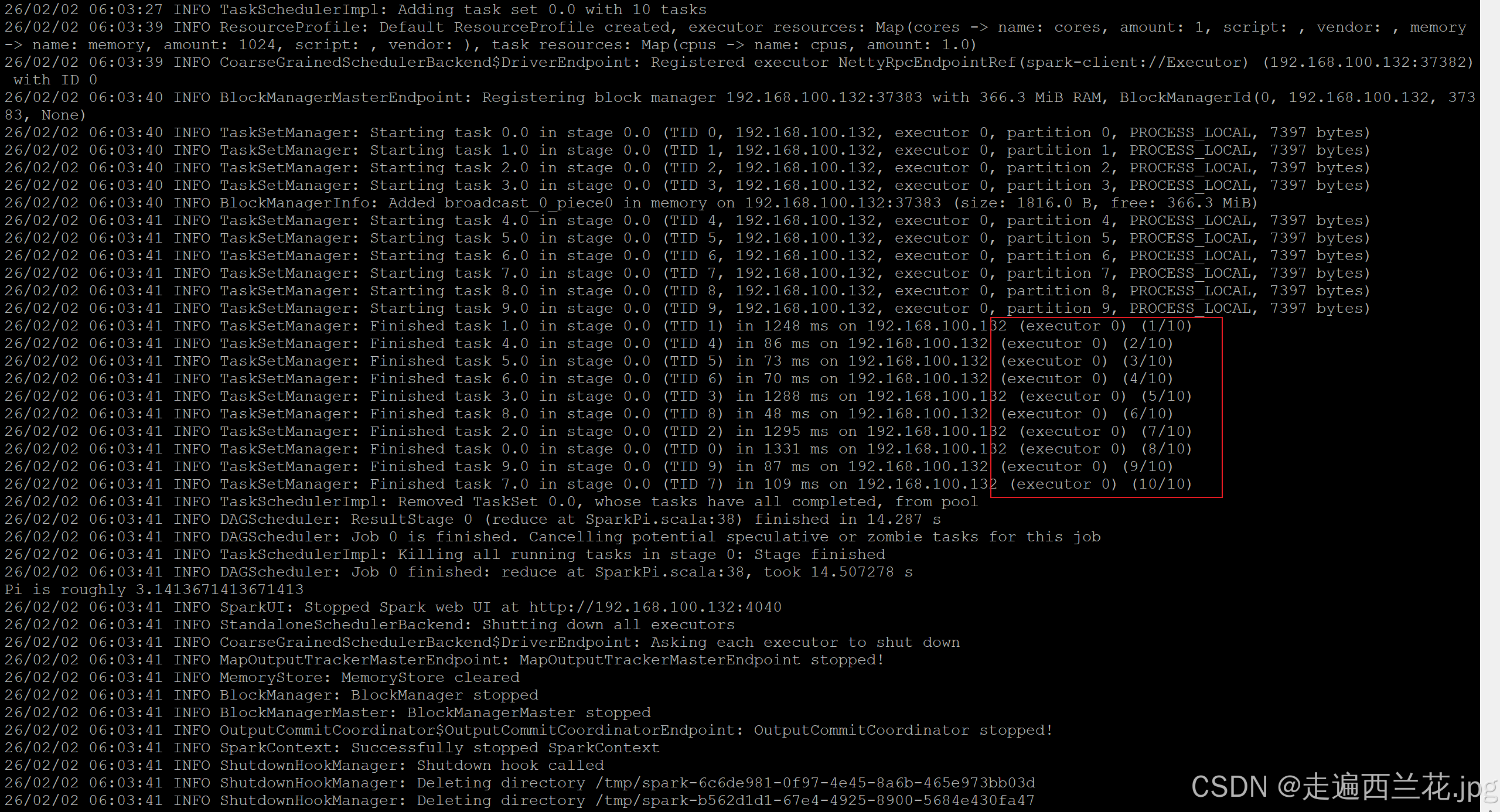
三、部署历史服务
1、进入/root/spark-standalone/conf
cd /root/spark-standalone/conf2、修改 spark-defaults.conf.template 文件名为 spark-defaults.conf
mv spark-defaults.conf.template spark-defaults.conf3、 修改 spark-default.conf 文件,配置日志存储路径
vim spark-defaults.conf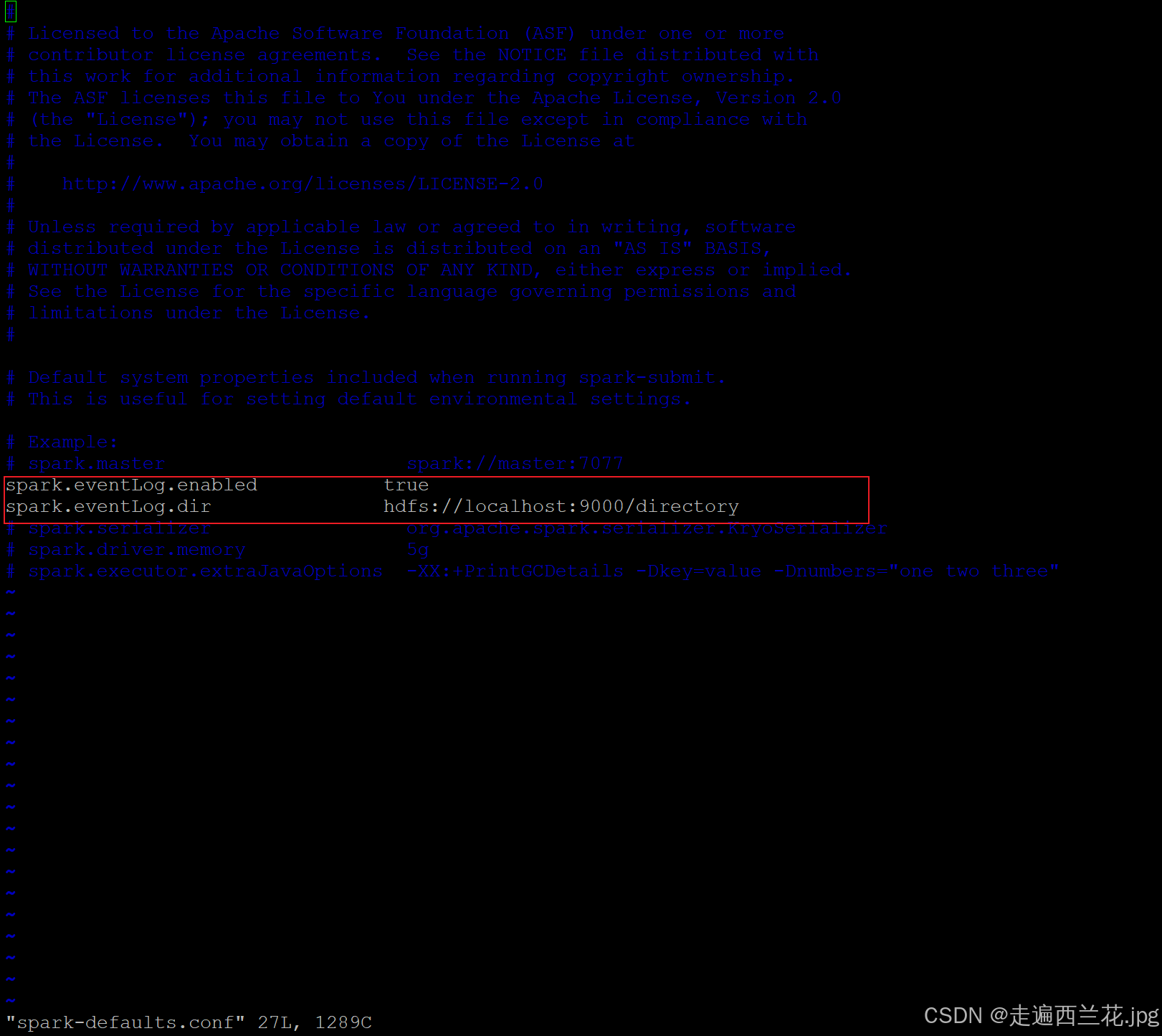
注意:需要启动 hadoop 集群,HDFS 上的 directory 目录需要提前存在。
hdfs dfs -mkdir /directory4、修改 spark-env.sh 文件, 添加日志配置
vim spark-env.sh
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://localhost:9000/directory
-Dspark.history.retainedApplications=30"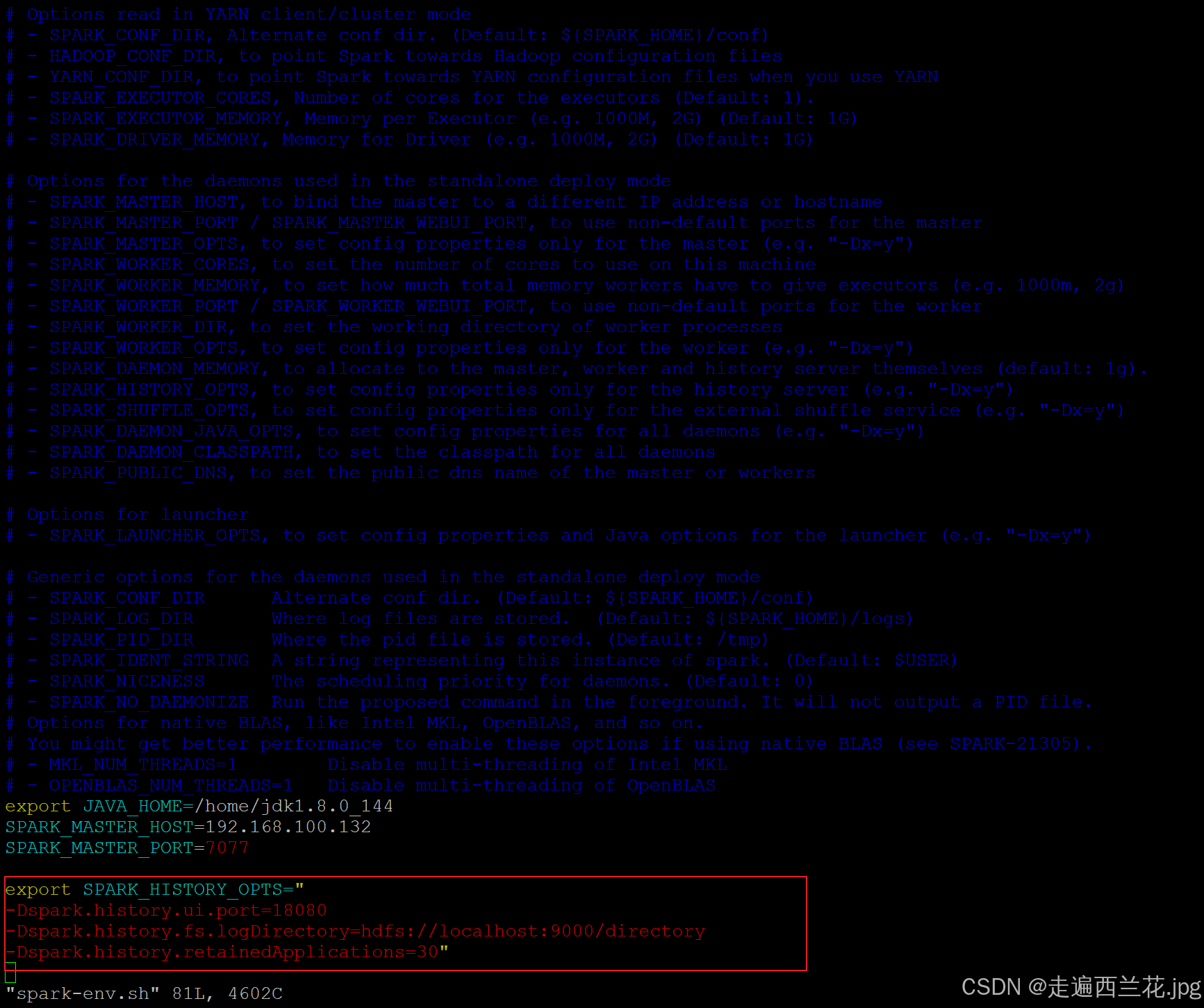
5、重新启动集群和历史服务
cd /root/spark-standalone
sbin/stop-all.sh
sbin/start-all.sh
sbin/start-history-server.sh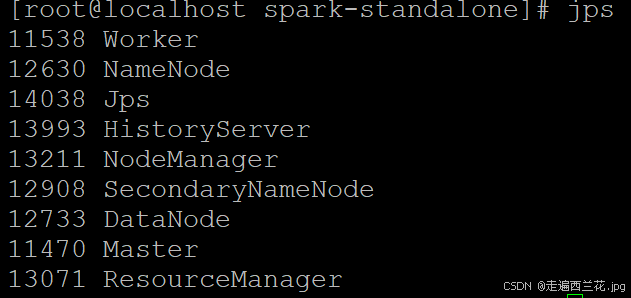
6、重新执行任务
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://192.168.100.132:7077 \
./examples/jars/spark-examples_2.12-3.0.1.jar \
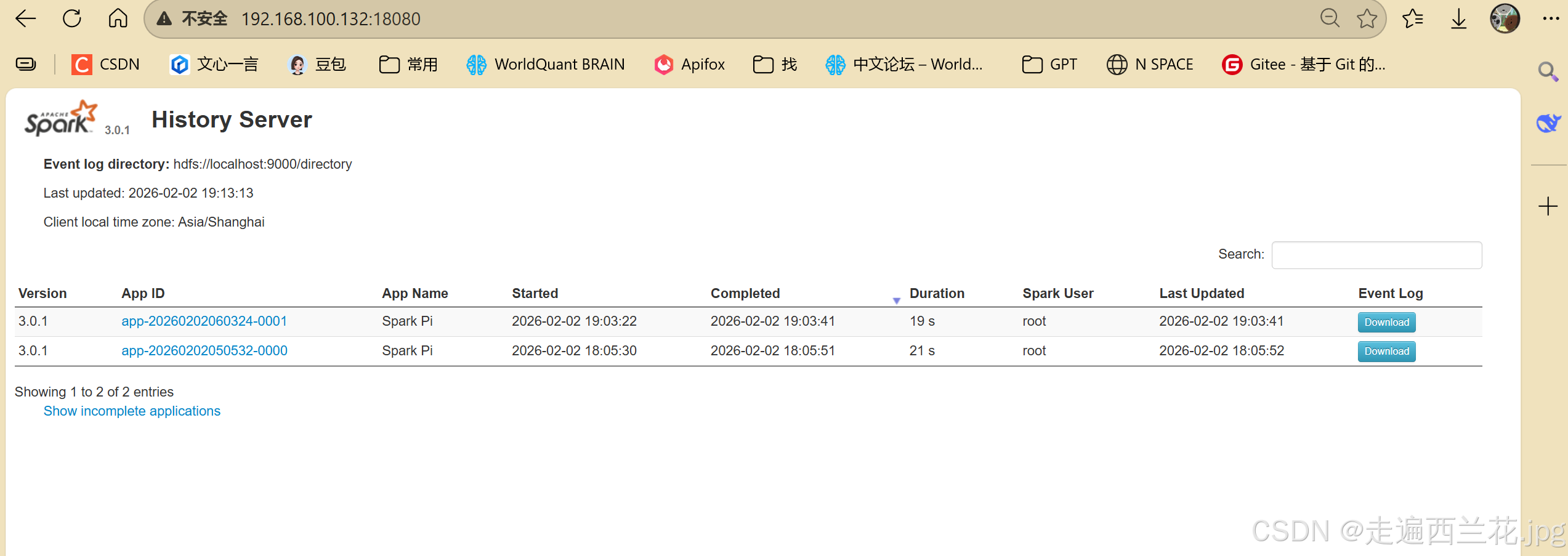
107、查看历史服务:http://192.168.100.132:18080
四、Yarn模式
1、还是之前的文件spark-3.0.1-bin-hadoop2.7.tgz解压到root下
tar -zxvf spark-3.0.1-bin-hadoop2.7.tgz -C /root2、进入root下,将spark-3.0.1-bin-hadoop2.7名字改为spark-yarn
mv spark-3.0.1-bin-hadoop2.7 spark-yarn3、修改hadoop配置文件/home/hadoop-2.8.2/etc/hadoop/hadoop/yarn-site.xml, 并分发
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>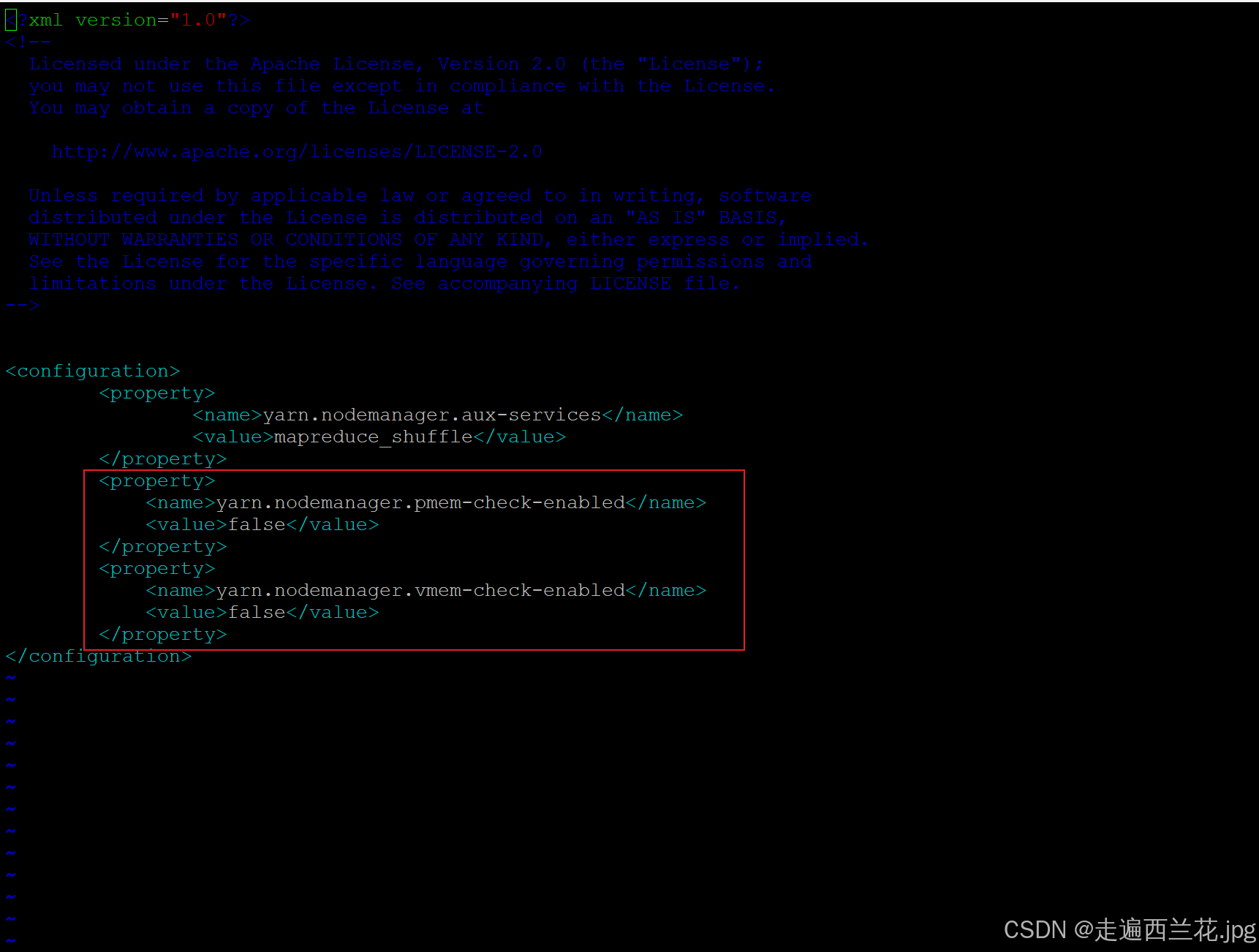
4、修改conf/spark-env.sh,添加 JAVA_HOME 和YARN_CONF_DIR配置
cd /root/spark-yarn/conf
mv spark-env.sh.template spark-env.sh
vim spark-env.sh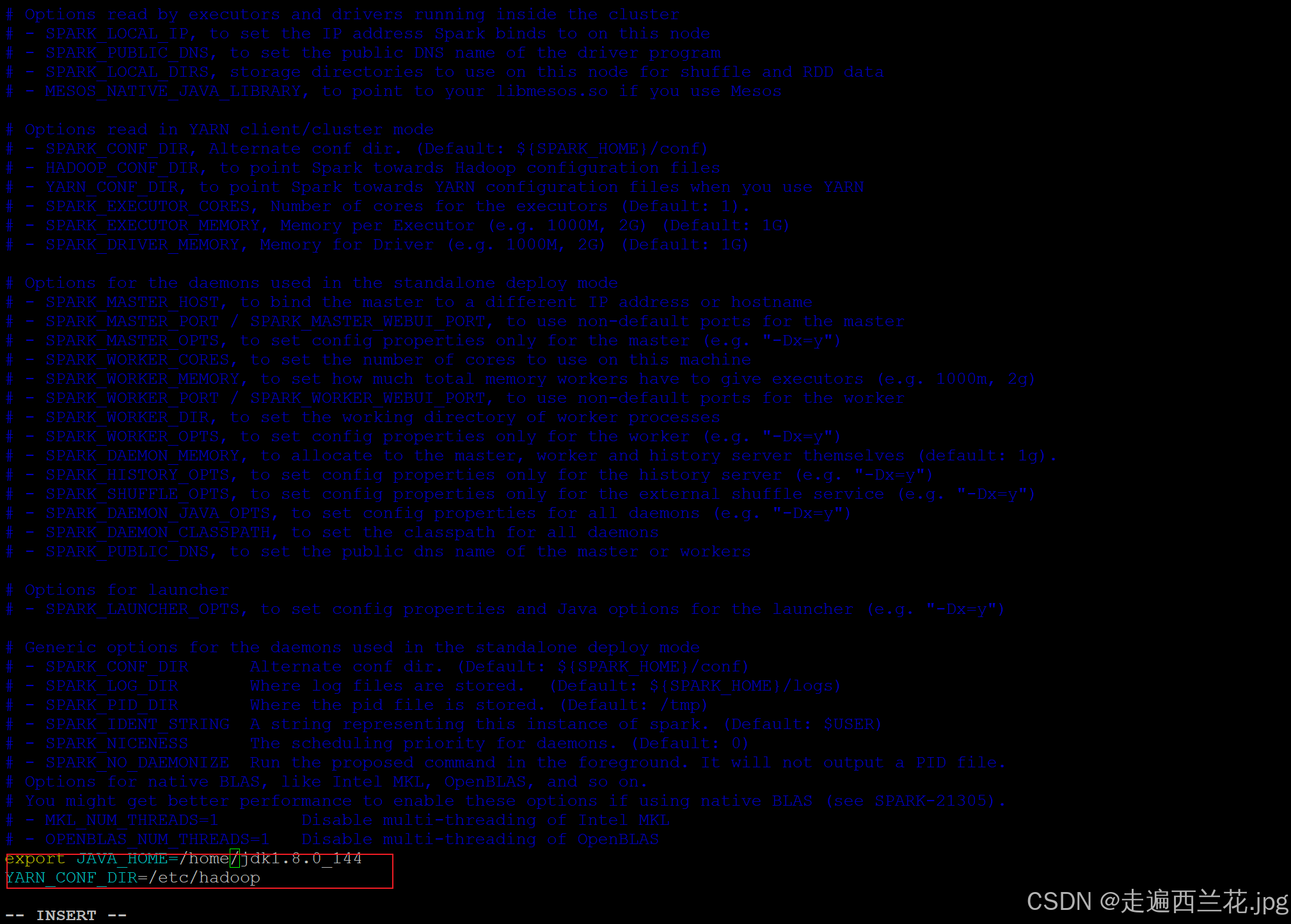
5、启动HDFS 以及YARN集群
start-all.sh
start-yarn.sh6、提交应用
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.12-3.0.1.jar \
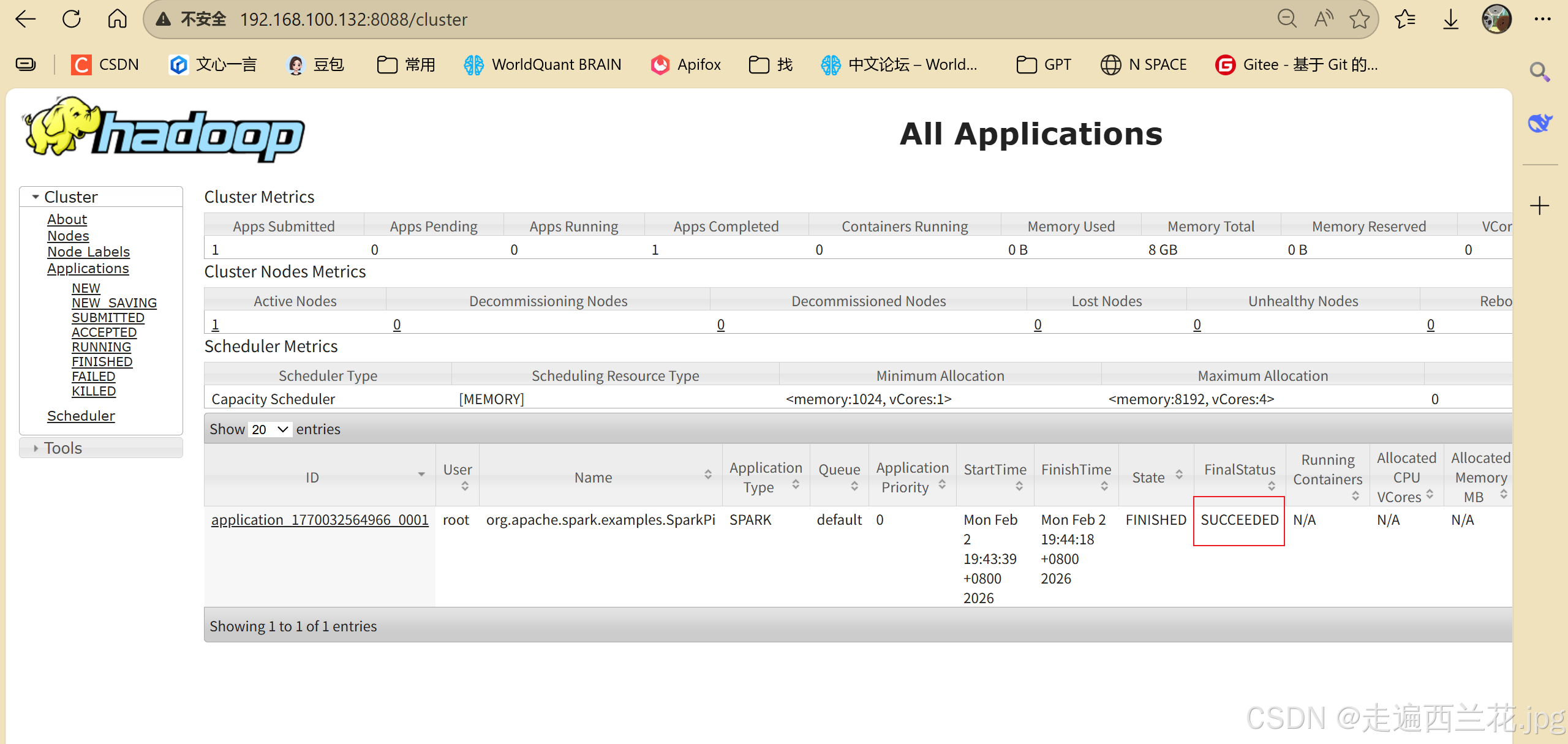
107、进入http://192.168.100.132:8088