03_计算图是什么?PyTorch动态图机制解密
本章目标 :告别手算梯度!引入 PyTorch 的核心神经 ------ Autograd (自动微分) 系统。我们将看到 Tensor 如何自动记录历史,并一键计算所有梯度。
📖 目录
- 从手动挡到自动挡
- Tensor:不只是数组
- 动态图机制 (Dynamic Computational Graph)
- [实战:用 PyTorch 重写线性回归](#实战:用 PyTorch 重写线性回归)
- [关键细节:zero_grad 的必要性](#关键细节:zero_grad 的必要性)
1. 从手动挡到自动挡
在上一章,我们手动推导了 L o s s = ( x ⋅ w − y ) 2 Loss = (x \cdot w - y)^2 Loss=(x⋅w−y)2 的梯度公式。
PyTorch 的出现,就是为了把我们带入**"自动挡"**时代。你只管写前向传播(怎么算 Loss),PyTorch 自动帮你算反向传播(怎么求梯度)。
2. Tensor:不只是数组
PyTorch 的核心数据结构是 Tensor。它看起来像 NumPy 的数组,但它多带了三个关键"挂件":
data: 存储具体的数值。grad: 存储计算出来的梯度。grad_fn: 记录 "我是怎么来的" (比如通过乘法算出来的,记为MulBackward)。
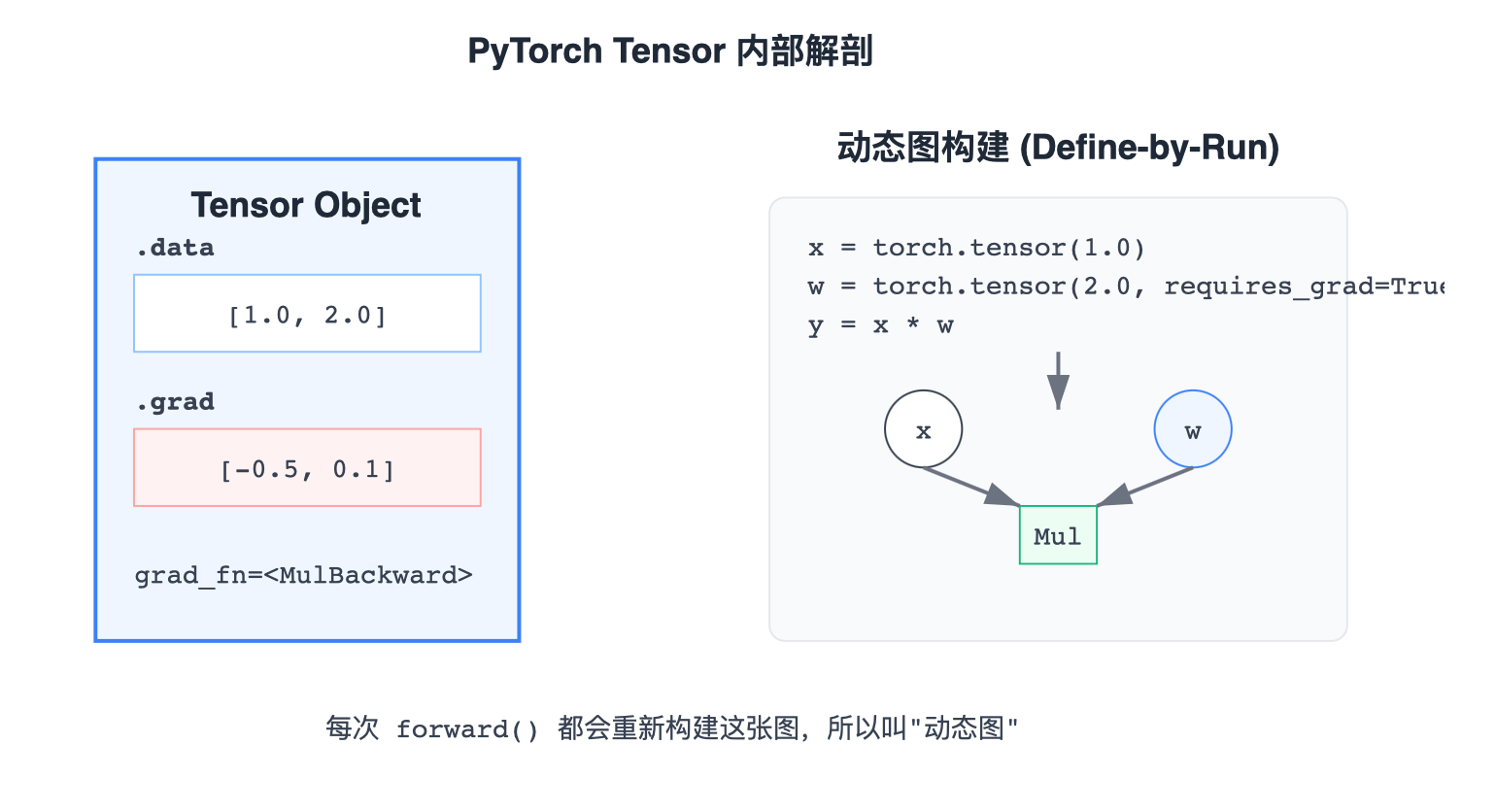
3. 动态图机制 (Dynamic Computational Graph)
PyTorch 采用的是 动态图 (Define-by-Run) 机制。
这意味着计算图不是预先定义好的(像 TensorFlow 1.x),而是在你运行代码的那一刻动态构建的。
这意味着 :你可以用 Python 的 if、for 循环任意控制网络结构,PyTorch 都能照单全收。
4. 实战:用 PyTorch 重写线性回归
让我们把第1章的代码用 PyTorch 重写一遍。注意观察代码量的急剧减少。
python
import torch
# 1. 准备数据
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
# 2. 初始化权重 (这就是我们的 Model)
# 只要是模型参数,都需要 requires_grad=True
w = torch.tensor([1.0], requires_grad=True)
# 3. 前向传播函数
def forward(x):
return x * w # 这里的 * 是 Tensor 乘法,会自动构建计算图
# 4. 损失函数
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
# 5. 训练循环
print("Predict (before training)", 4, forward(4).item())
for epoch in range(100):
for x, y in zip(x_data, y_data):
# A. 前向计算 Loss
l = loss(x, y)
# B. 【魔法步骤】反向传播
l.backward() # 自动计算梯度存入 w.grad
print(f"\tgrad: {x}, {y}, {w.grad.item():.2f}")
# C. 更新权重
# w.data 也就是只修改数值,不影响计算图
w.data = w.data - 0.01 * w.grad.data
# D. 【重要】清空梯度
w.grad.data.zero_()
print(f"Epoch: {epoch}, w={w.item():.3f}, loss={l.item():.3f}")
print("Predict (after training)", 4, forward(4).item())5. 关键细节:zero_grad 的必要性
很多初学者容易栽在这里:为什么要 w.grad.data.zero_()?
因为在 PyTorch 的设计中,.backward() 计算出的梯度是累加 (+=) 到 .grad 里的,而不是覆盖。
- 这在 RNN 或者多任务学习中非常有用。
- 但在普通的梯度下降中,我们需要的是"这一轮的梯度",所以必须把"上一轮的梯度"清零,否则
w会跑飞。