导言:在工作中,您是否遇到过这些困扰:
(1)好不容易拿到一份数据报告,却发现它反映的是几个小时甚至一天前的"旧闻",无法支撑您此刻需要做出的紧急决策;
(2)想针对线上正在发生的情况(比如某个直播间的突发流量)立刻进行分析和调整,却发现技术流程复杂、响应缓慢,只能眼睁睁看着机会溜走。
AllData数据中台集成的开源项目StreamPark作为实时开发平台,您可以理解为一个"数据流水线的智能工厂"。实时开发平台最大的优势,就是让业务人员也能轻松搭建起处理实时数据流的通道,将"等待数据"变为"同步获取洞察"。
您无需深究复杂的编程和分布式系统原理,通过可视化的方式,就能将来自网站、APP、物联网设备的实时信息,快速转换成可供决策的图表、警报或看板。
简单来说,能让实时反应变得像查看监控摄像头一样简单直接,帮助您和您的团队在业务竞争中,始终快人一步。

实时开发平台(StreamPark)集成了Flink与Spark两大流行计算引擎,通过开箱即用的组件和可视化的操作界面,大幅降低了实时应用开发的门槛与周期。
同时,实时开发平台提供从开发、调试、部署到监控、告警的全生命周期管理,确保您的实时数据流稳定、7x24小时可靠运行,真正释放数据的实时潜能。
一、【实时开发平台】功能架构
实时开发平台是基于开源项目StreamPark构建,提供从可视化开发到智能运维全生命周期管理的一站式实时与批处理作业工厂。
1、统一的应用开发框架:
为Flink和Spark流批处理应用提供标准的开发、部署和管理框架,将分散的工具链整合为统一平台。
2、全生命周期的运维管控:
覆盖实时作业的开发、部署、监控、告警、容错恢复到下线整个生命周期,实现集约化管理。
3、异构引擎与资源调度:
无缝支持Flink(流处理)和Spark(批处理),并能实现跨多集群的动态资源分配与统一调度。
4、企业级协同与治理底座:
提供团队协作、版本控制、任务血缘、高可用等能力,支撑多人协作与生产环境的稳定合规。

二、【核心能力演示】这位 "全能工具箱" 能应对什么场景?
下面以实时开发平台结合咱们常见的工作场景,一一为您介绍:
🔹项目地址:https://github.com/apache/streampark
🔹文档地址:https://streampark.apache.org/docs/get-started/quick-start
1、"搭积木"式开发:所见即所得,告别深奥代码
这是平台最颠覆性的特点。把原本需要编写大量复杂程序代码才能完成的实时计算任务(比如"实时统计每秒的销售额"),变成了在网页上拖拽组件、连线、填参数的可视化操作。您不需要是Flink专家,只需要理清业务逻辑。
✅ 测试时:仅用5分钟就搭建了一个"实时读取Kafka订单流,并统计每5秒销售总额"的流程。整个过程就像画流程图,拖入"Kafka源"、"时间窗口"、"聚合计算"、"结果输出"几个模块并连线配置,点击"发布"就直接跑起来了。效率大大提高了。
2、"自动驾驶"式运维:全天候值守,故障自愈
实时应用需要7x24小时运行,最怕半夜出问题。平台内置了智能的监控和恢复机制。可以为任务设置"健康指标"(比如处理速度不能低于每秒1000条),一旦异常,系统会自动报警,并尝试自己重启恢复,如同给系统配备了全年无休的"自动驾驶"程序。
✅ 测试时:我模拟了计算节点故障。平台几乎在瞬间就发出钉钉告警,并在无需我任何干预的情况下,自动在另一个健康节点上重新启动作业,并从之前保存的"检查点"恢复数据,确保数据一分不差。这种安心感,对于生产系统至关重要。
3、"弹性伸缩"的资源管家:要多少给多少,不浪费
实时数据流量常有高峰低谷(如早晚高峰),平台能自动感知任务压力,在流量高峰时默默增加计算资源保证速度,在低谷时自动释放资源节省成本。您不需要手动预估和申请资源。
✅ 测试时:我配置了一个处理日志的作业。当模拟的日志量突然激增3倍时,在平台的监控图上可以清晰看到,它自动向底层的YARN集群申请了更多的计算容器(Container),处理延迟始终保持平稳。流量回落,容器数也随即下降。
4、"时光机"与"溯源图":一切变化有据可查,问题根因一目了然
版本控制和任务血缘这两个功能解决了团队协作和排查故障两大难题。
- 版本控制像"时光机"对作业做的每次修改(哪怕只是改个参数)都会被平台记录。
- 可以随时对比不同版本,或一键回退到昨天稳定运行的状态,彻底告别"改完怎么不行了"的恐惧。
- 任务血缘像"溯源图"平台能自动画出数据流的完整路径图:最终报表里的数字,是由哪个任务、处理了哪些源表、经过哪些计算步骤得来的。
✅ 测试时:在一次团队协作测试中,我和同事分别修改了同一个作业的不同部分,平台清晰记录了每个人的更改。后来发现一个计算错误,通过"血缘图"迅速定位是上游某个数据源的字段格式变了,而不是我们的逻辑问题,排查效率极高。
三、【实时开发平台】功能能力演示
1、Apache Flink
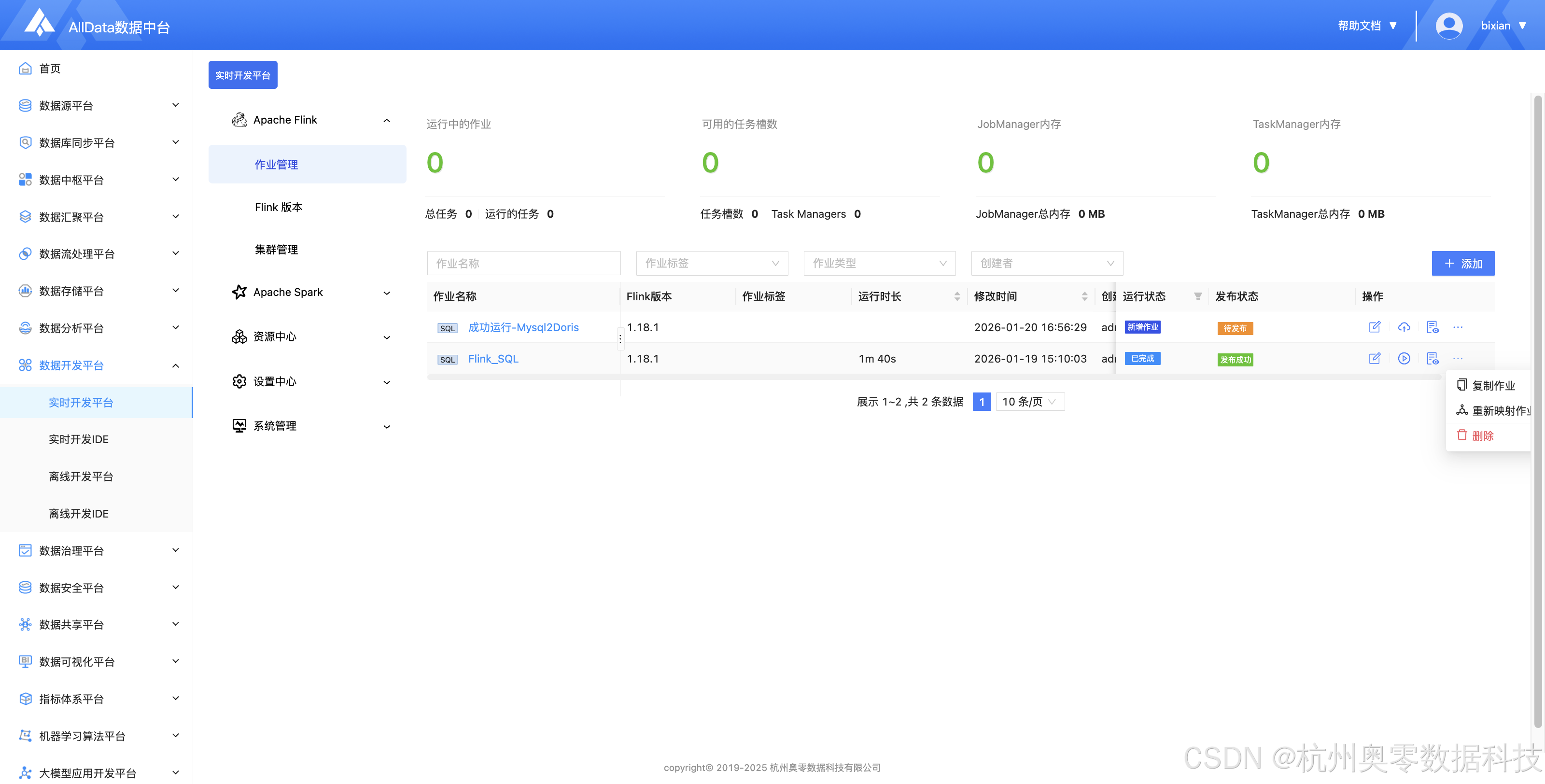
✅ 作业管理(Flink作业管理实现作业提交、调度、监控与动态资源分配,保障实时计算高效稳定)
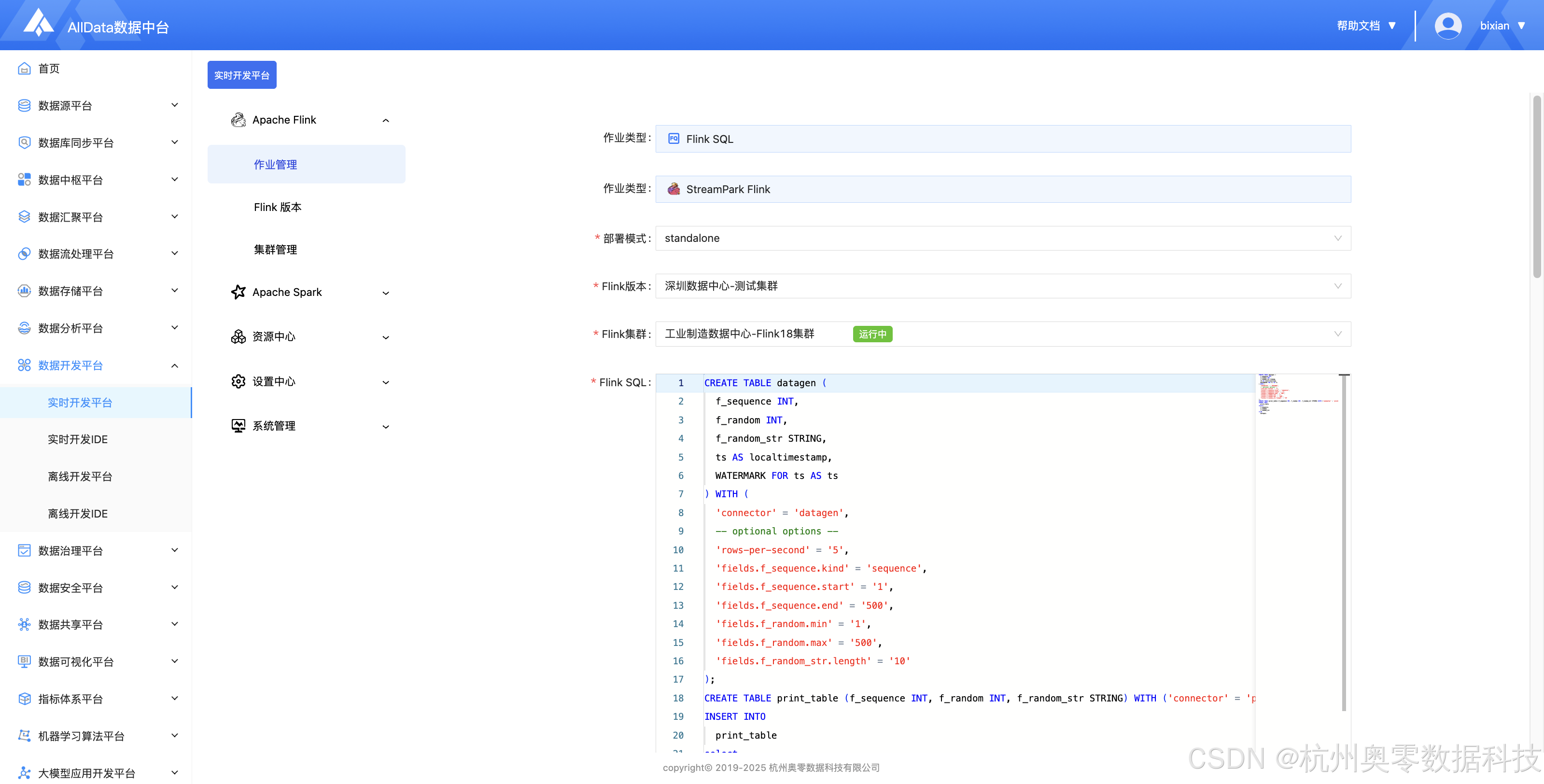
✅ 编辑作业
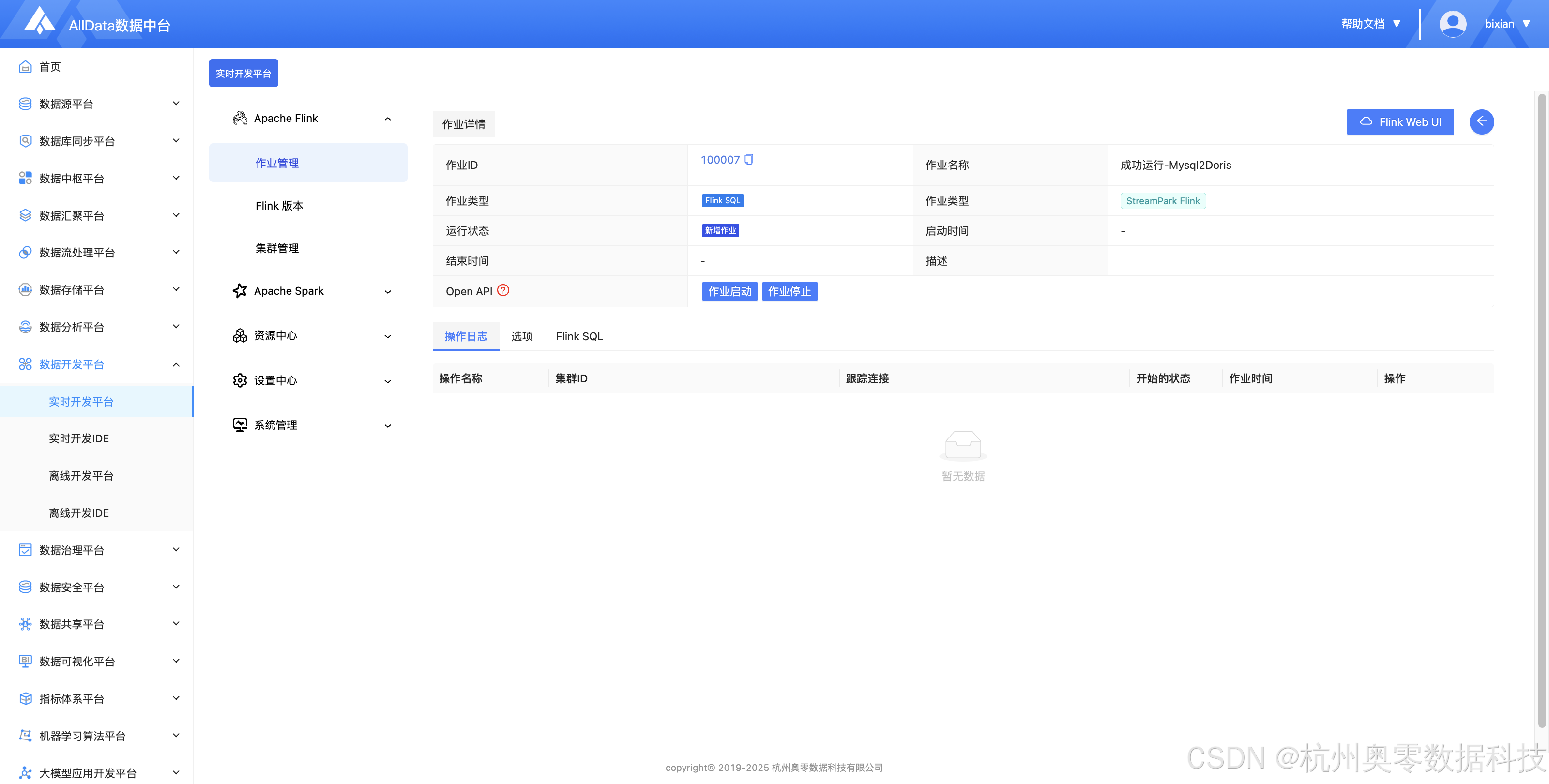
✅ Flink作业详情
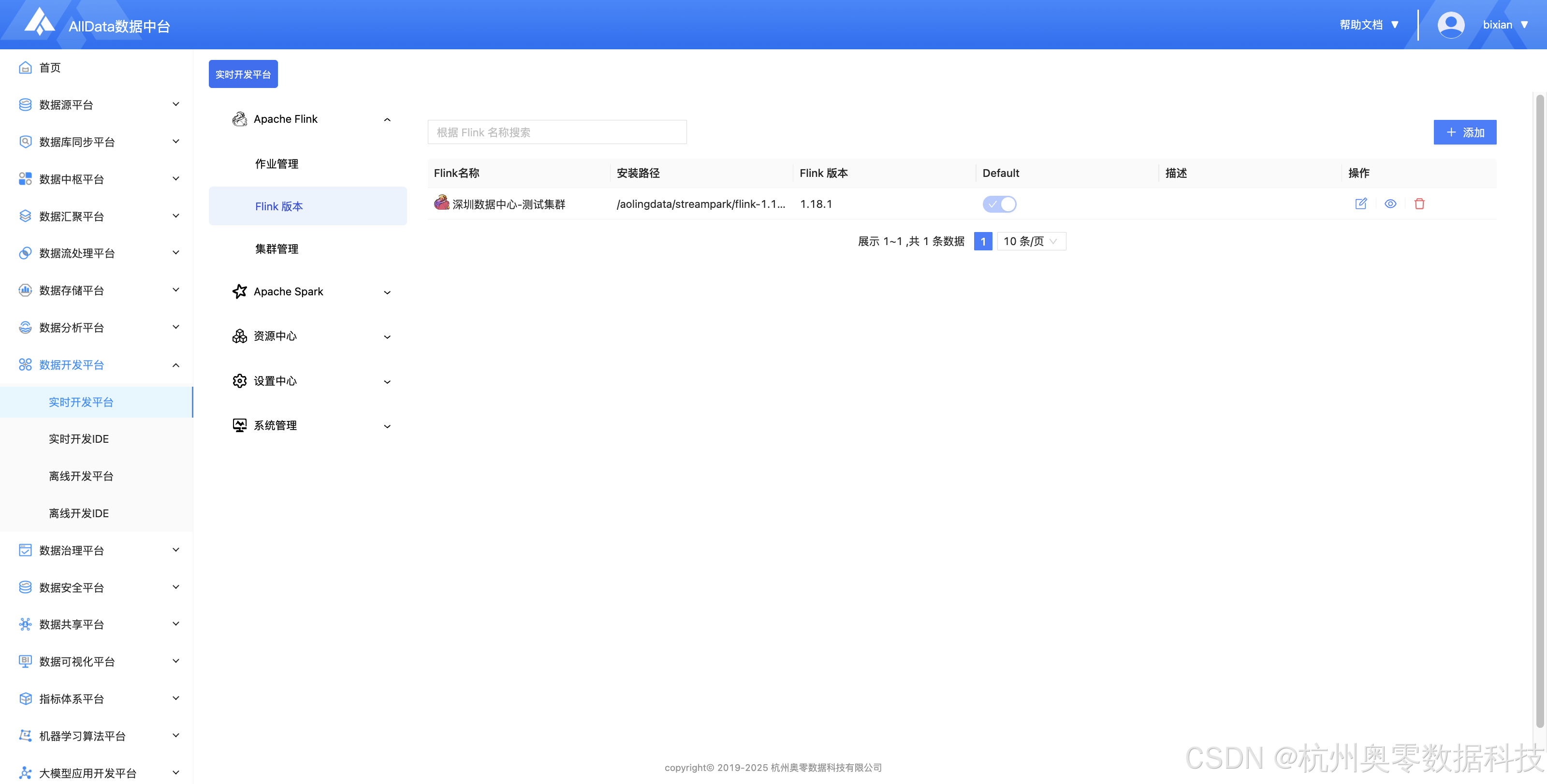
2、Flink版本 (提供一站式Flink作业管理,支持多版本兼容,具备作业提交、调度、监控及故障自愈能力,保障实时计算高效稳定运行)
3、添加Flink版本
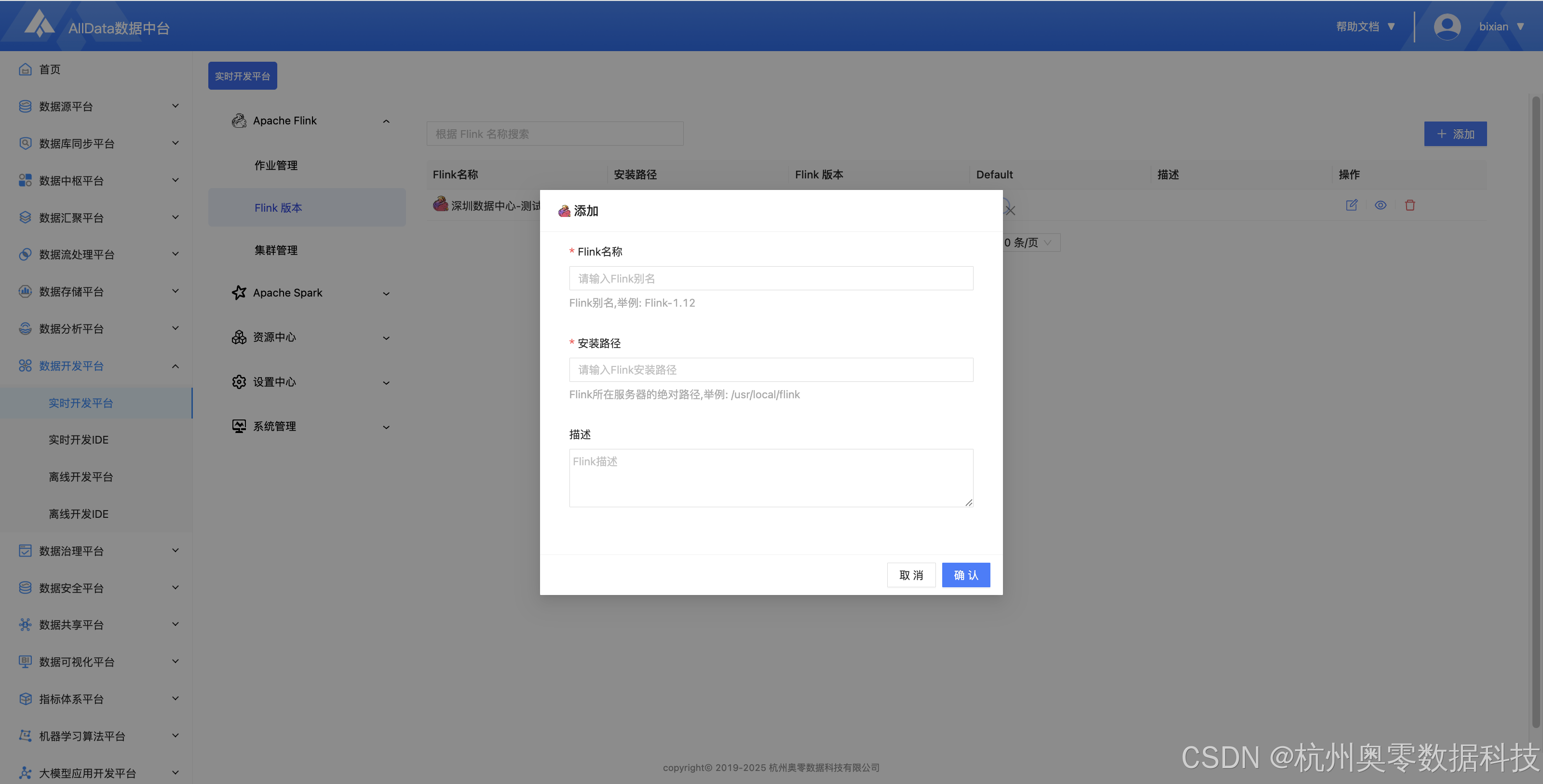
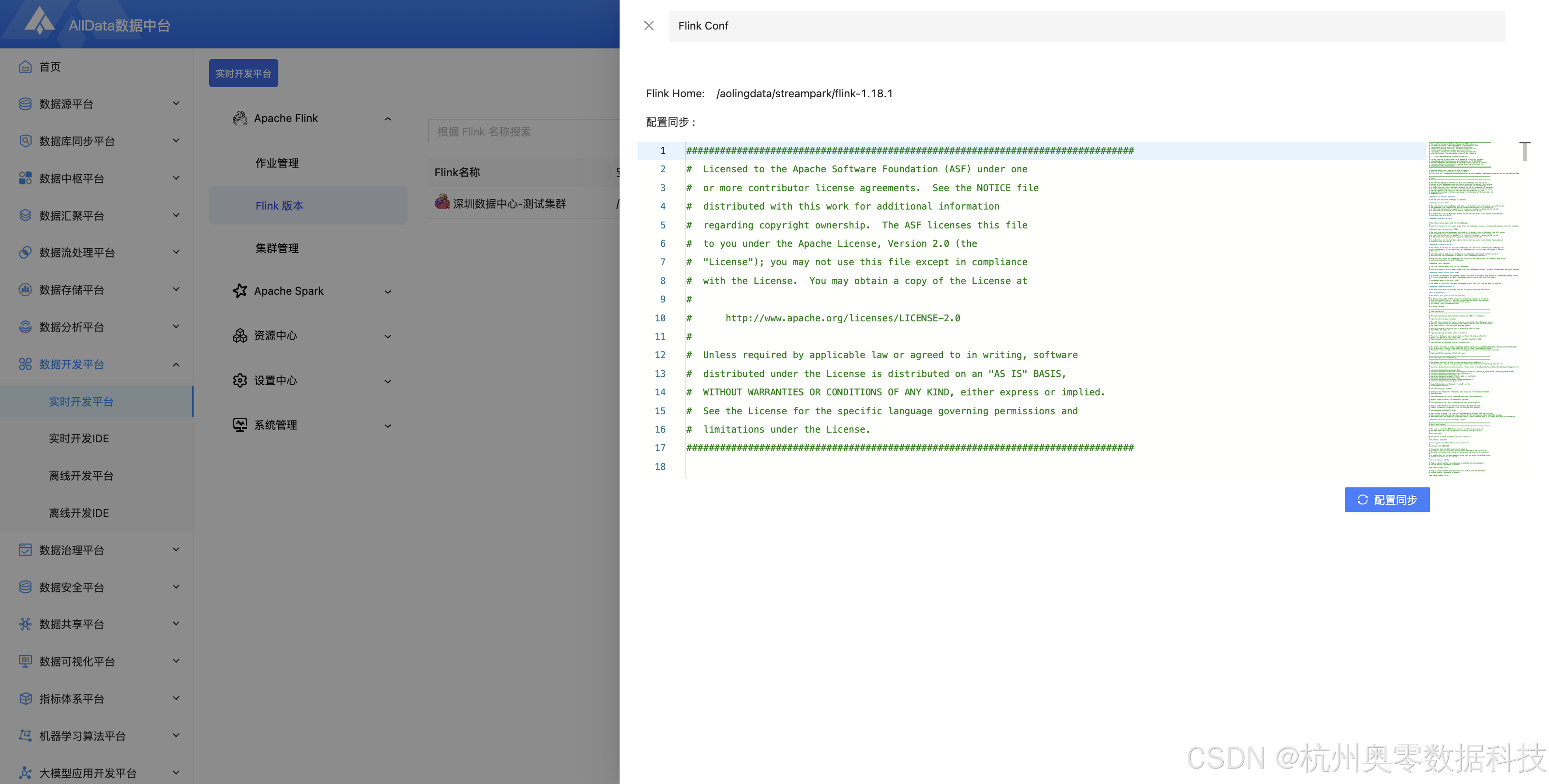
4、查看Flink版本配置
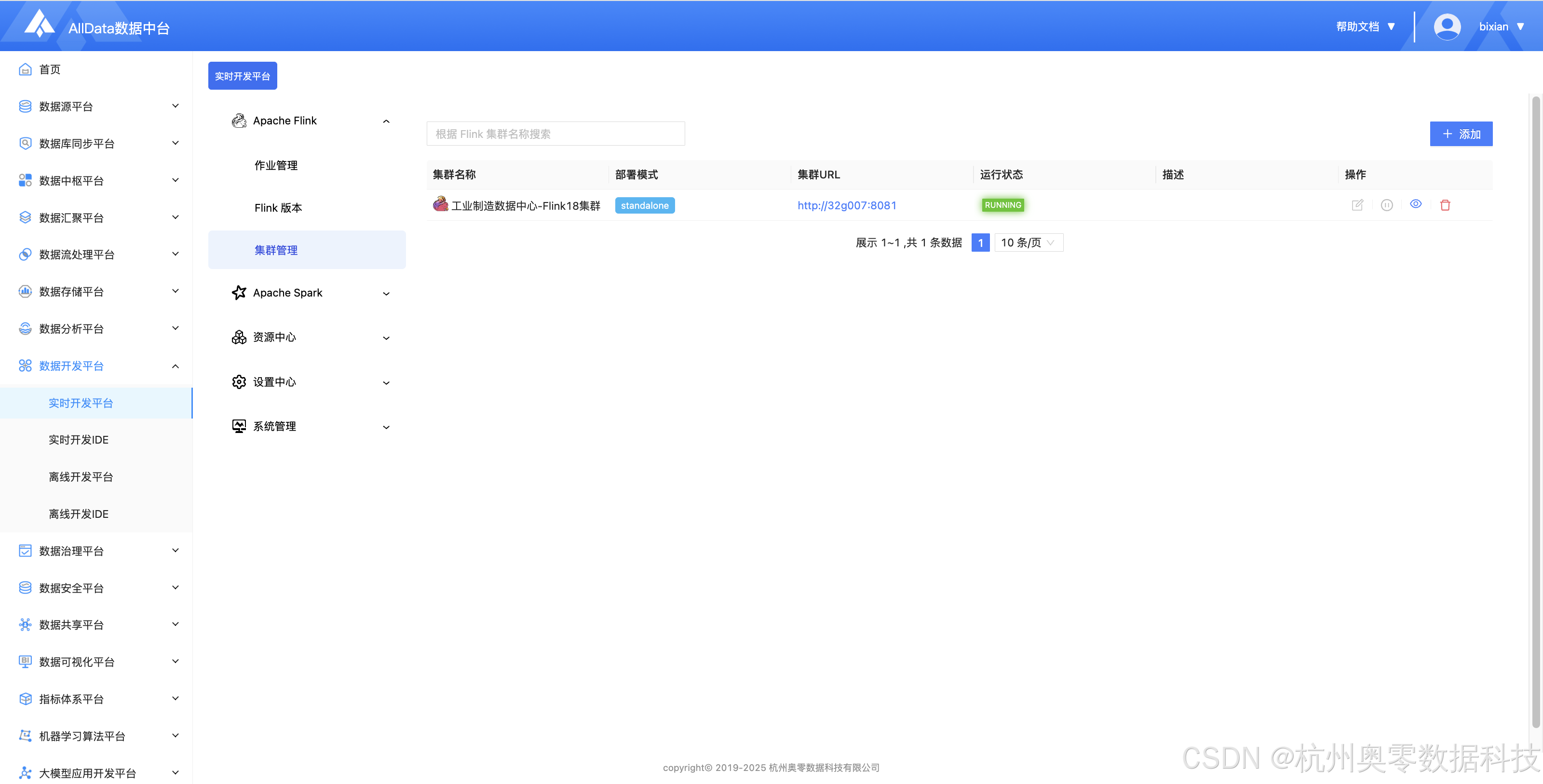
5、集群管理 (提供多集群统一纳管与资源动态调度,支持Flink作业跨集群分发、资源配额隔离、健康度监控及故障自愈,保障实时计算集群高可用与弹性伸缩)
6、Apache Spark
✅ 作业管理(支持Spark任务全周期管控,涵盖提交、监控及故障自愈,保障任务稳定运行)
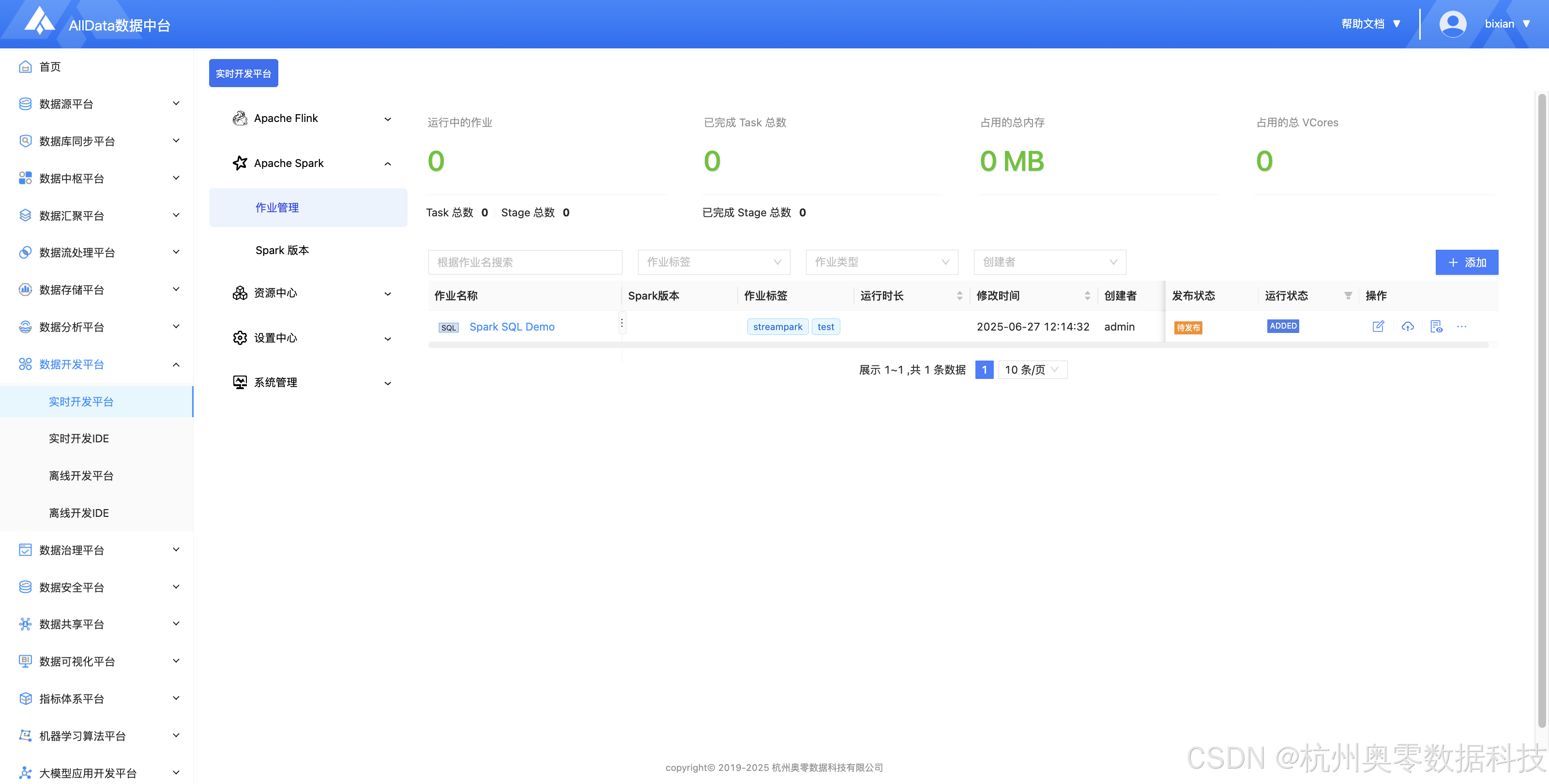
✅ 编辑Spark作业
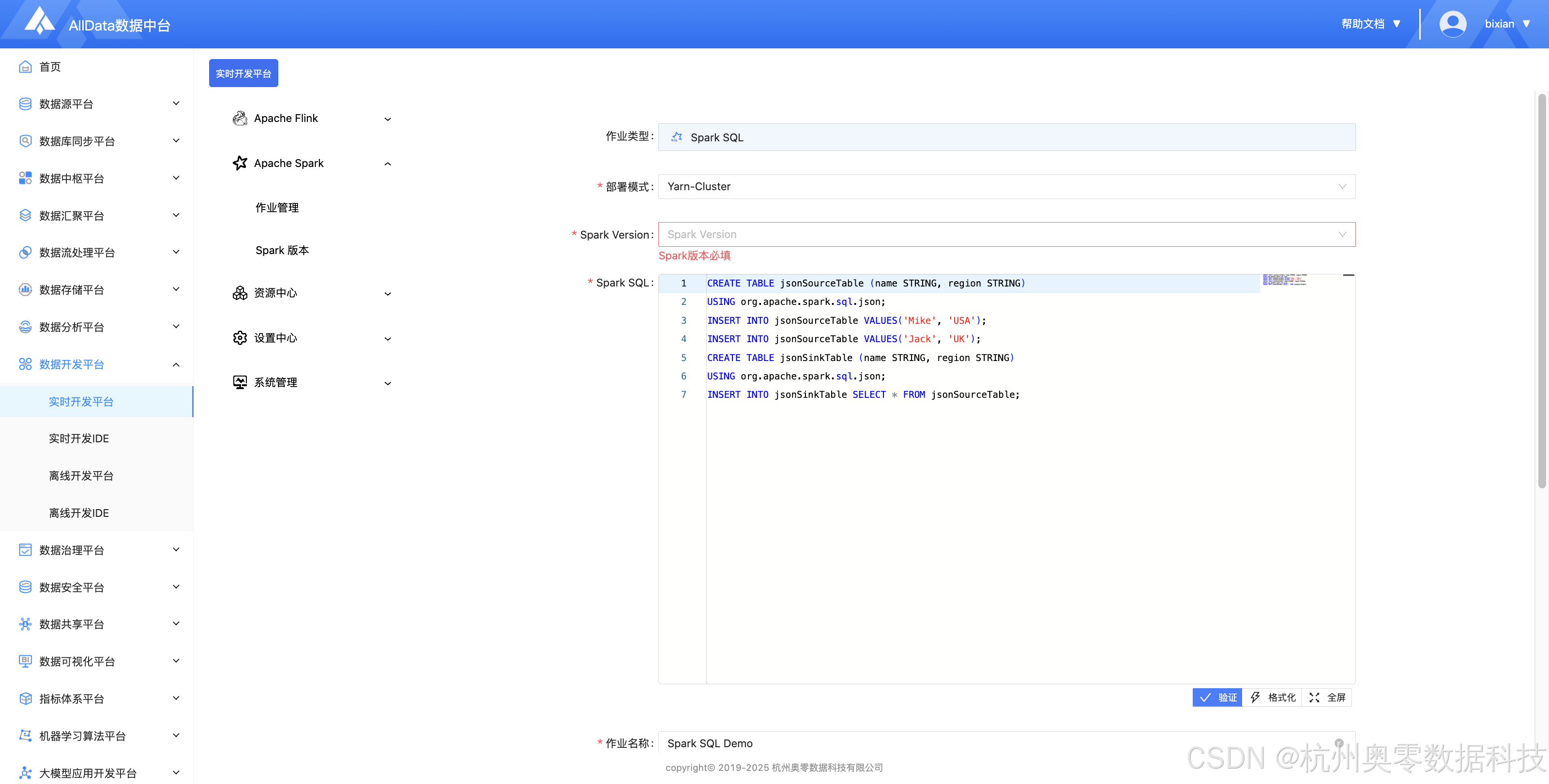
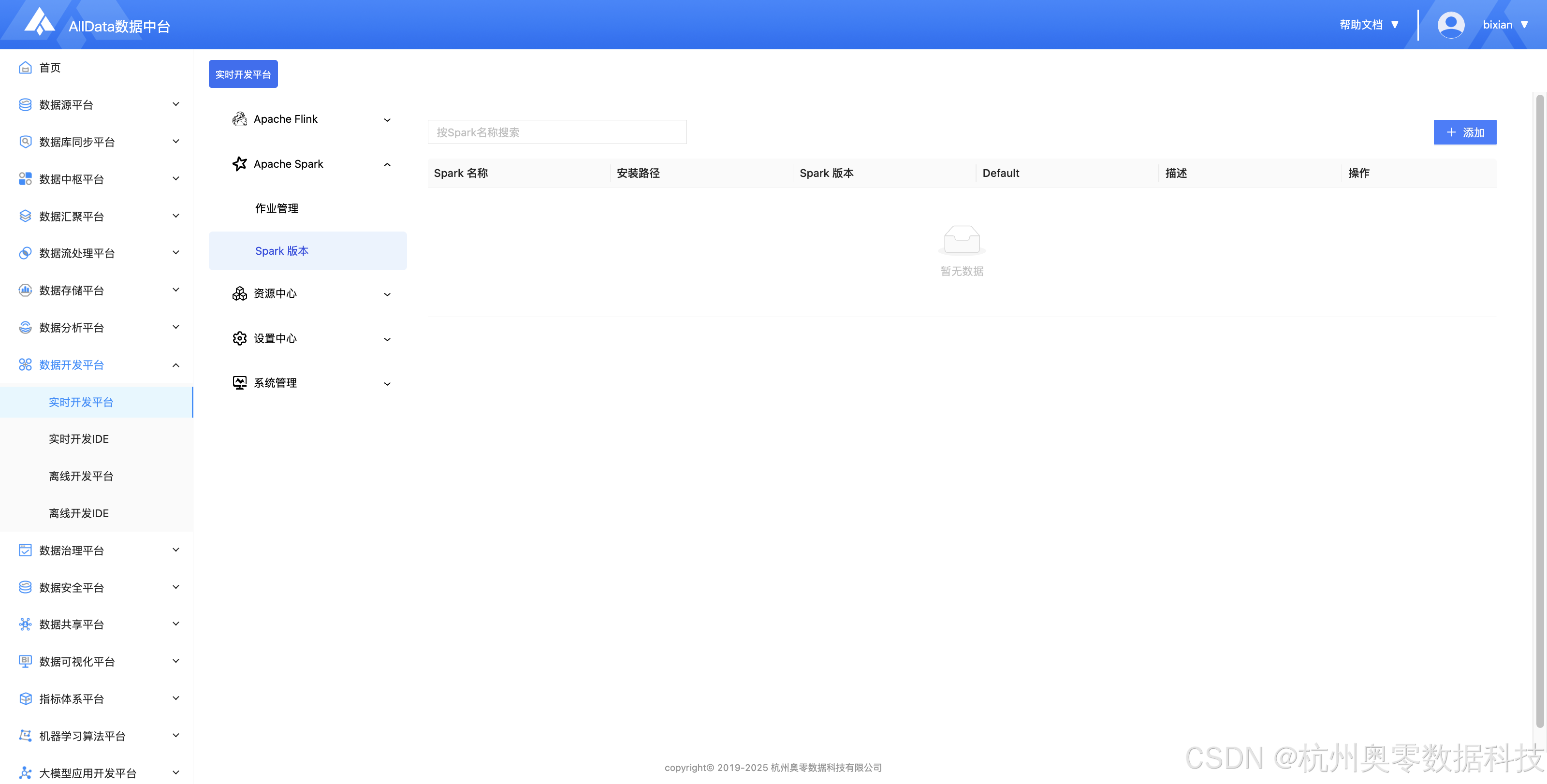
7、Spark版本 (支持多版本Spar管理,提供版本配置、依赖隔离与集群适配,保障Spark作业稳定运行与跨环境兼容性)
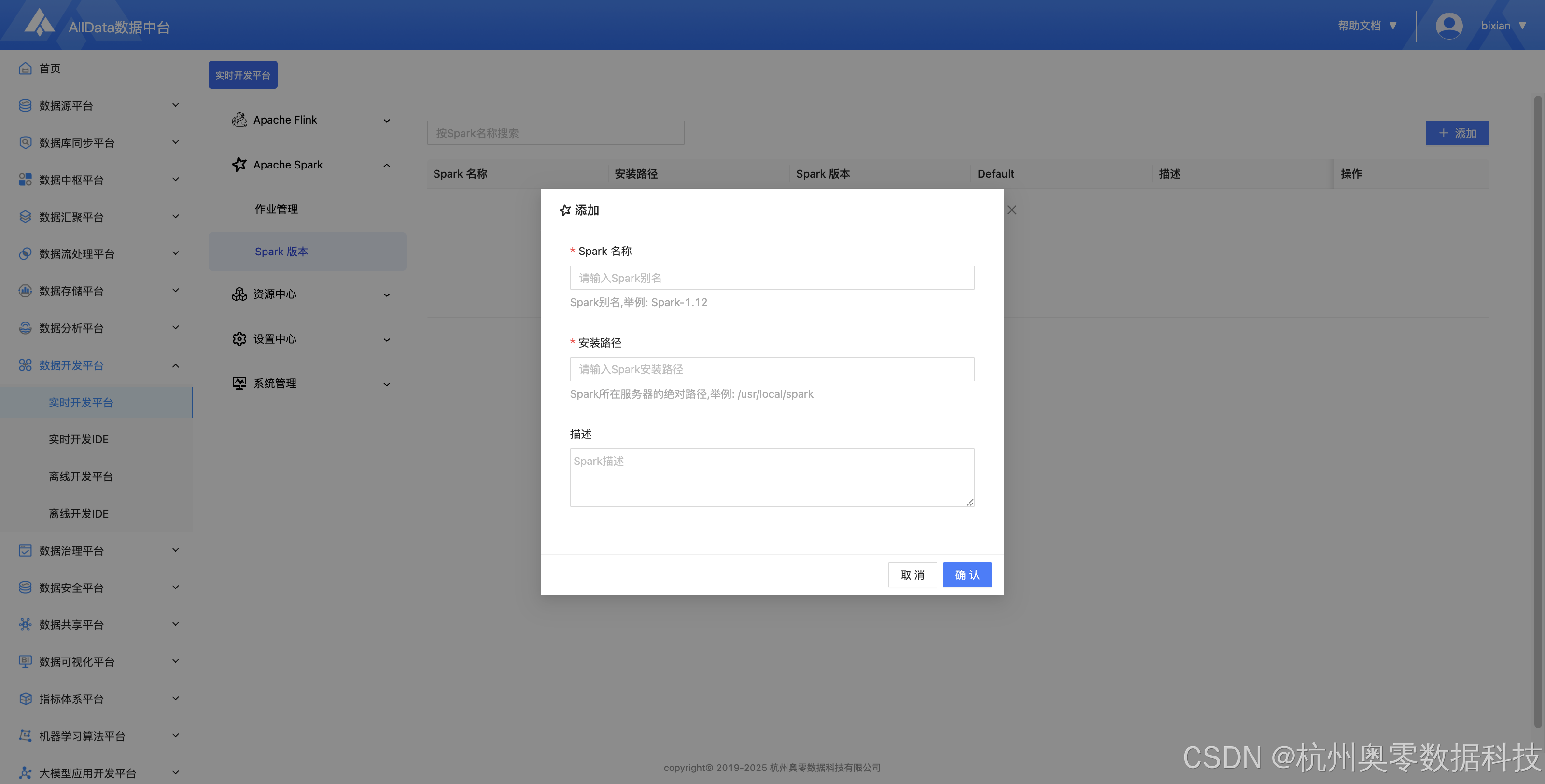
8、新建Spark版本
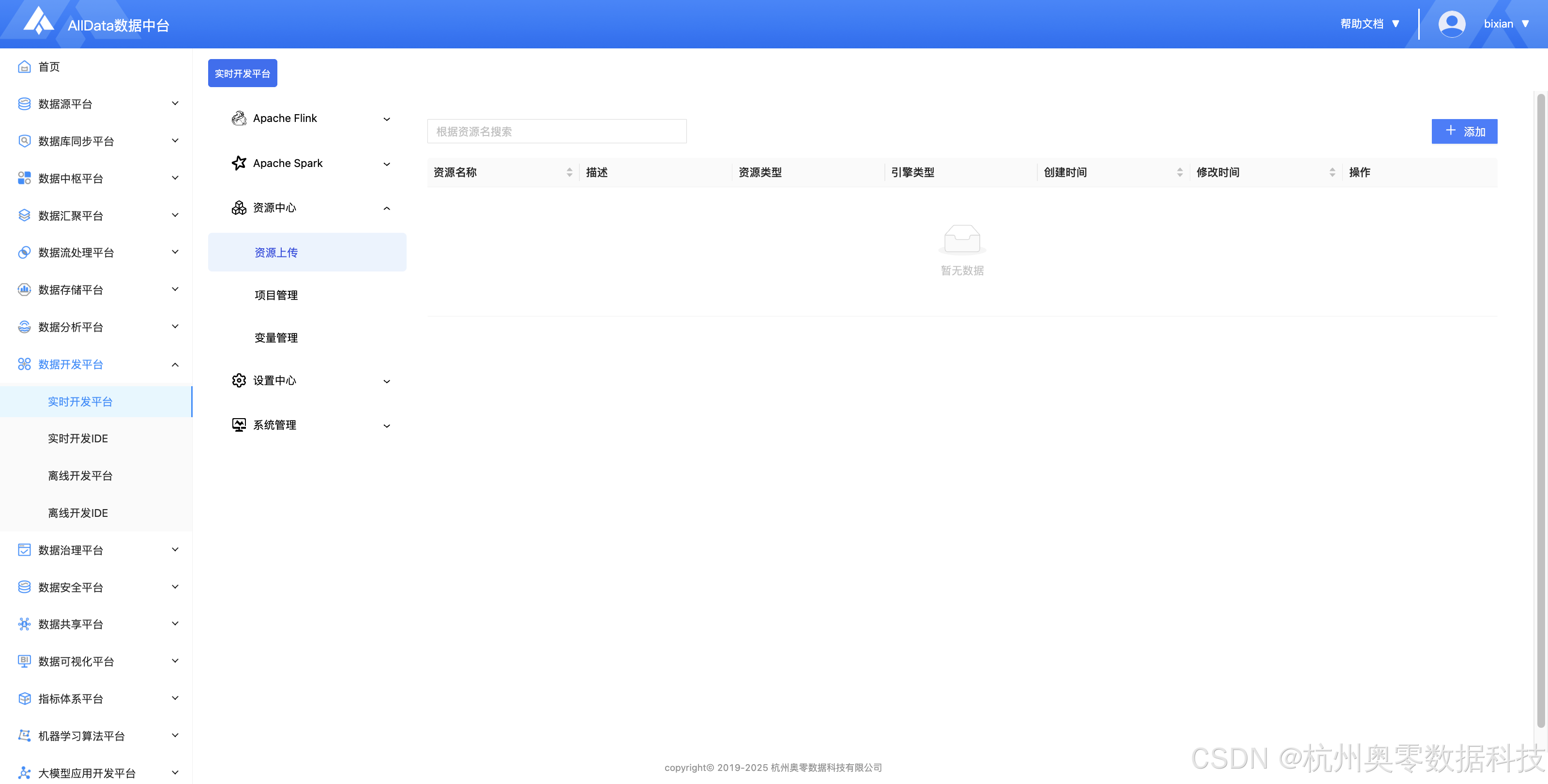
9、资源中心
✅ 资源上传(支持多格式资源一键上传)
10、新建资源
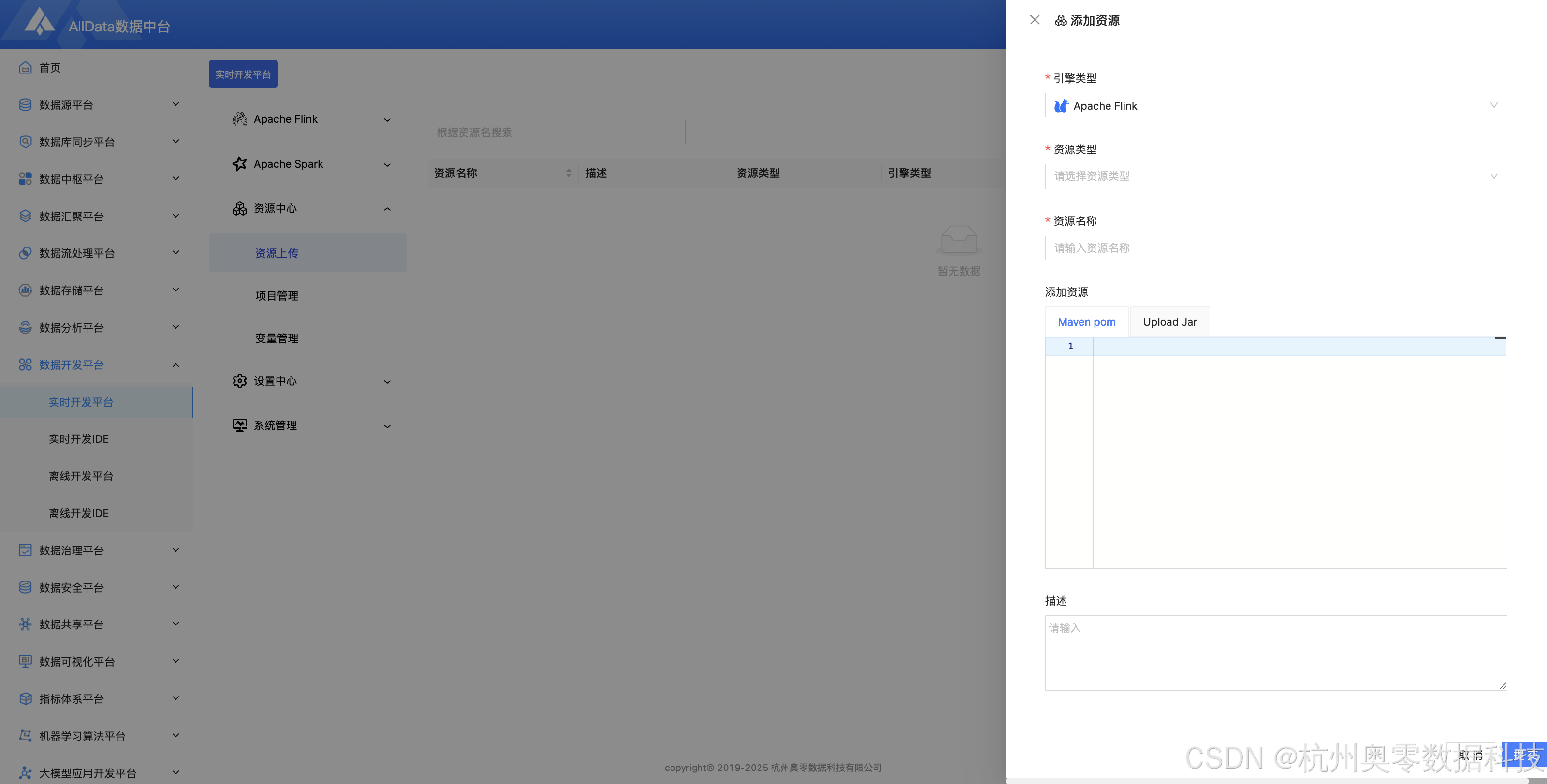
11、项目管理 (支持资源分库分类、权限隔离与版本追溯,实现多项目资源独立管控,避免跨团队协作冲突与资源误用)
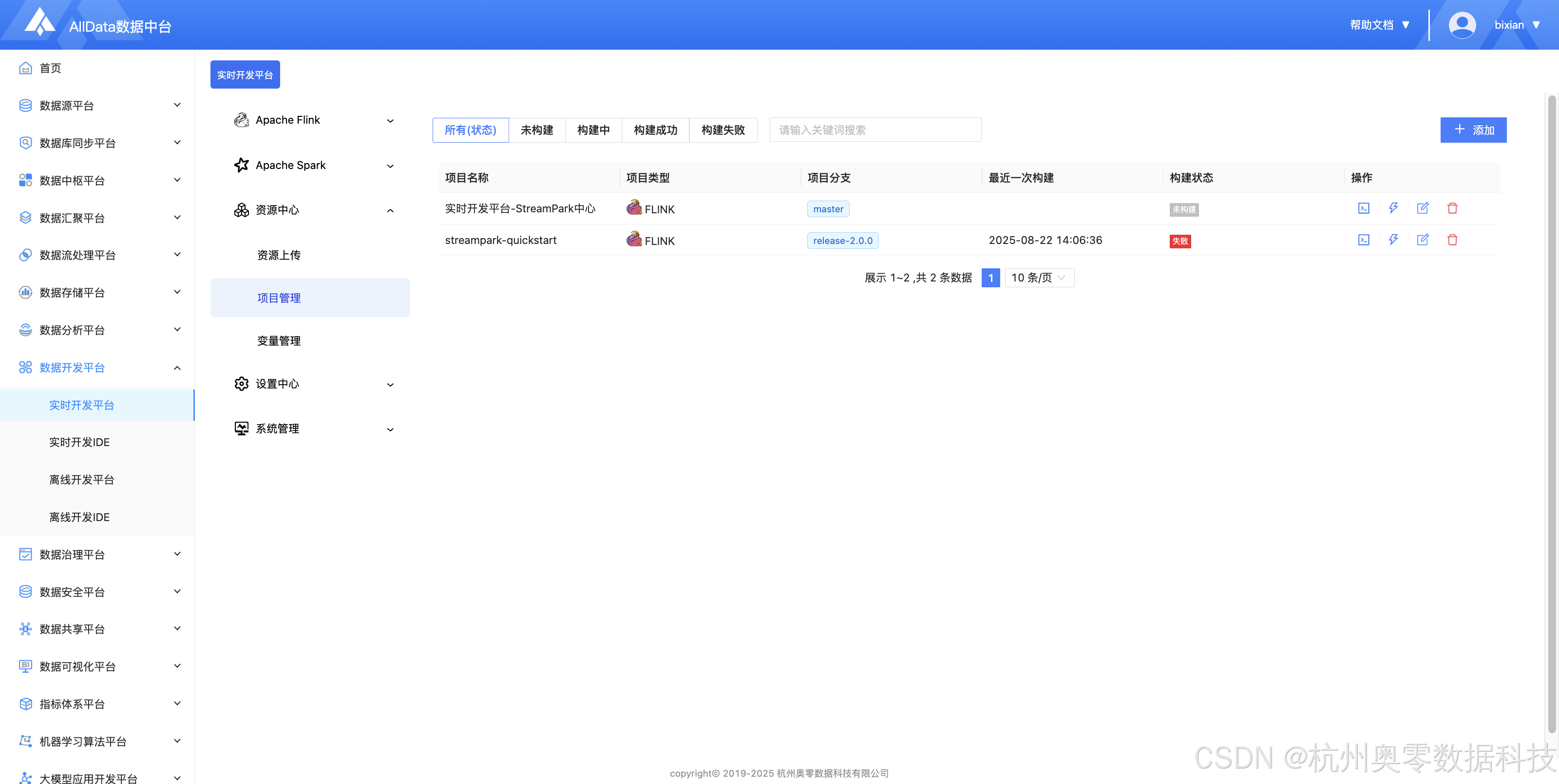
12、新建项目
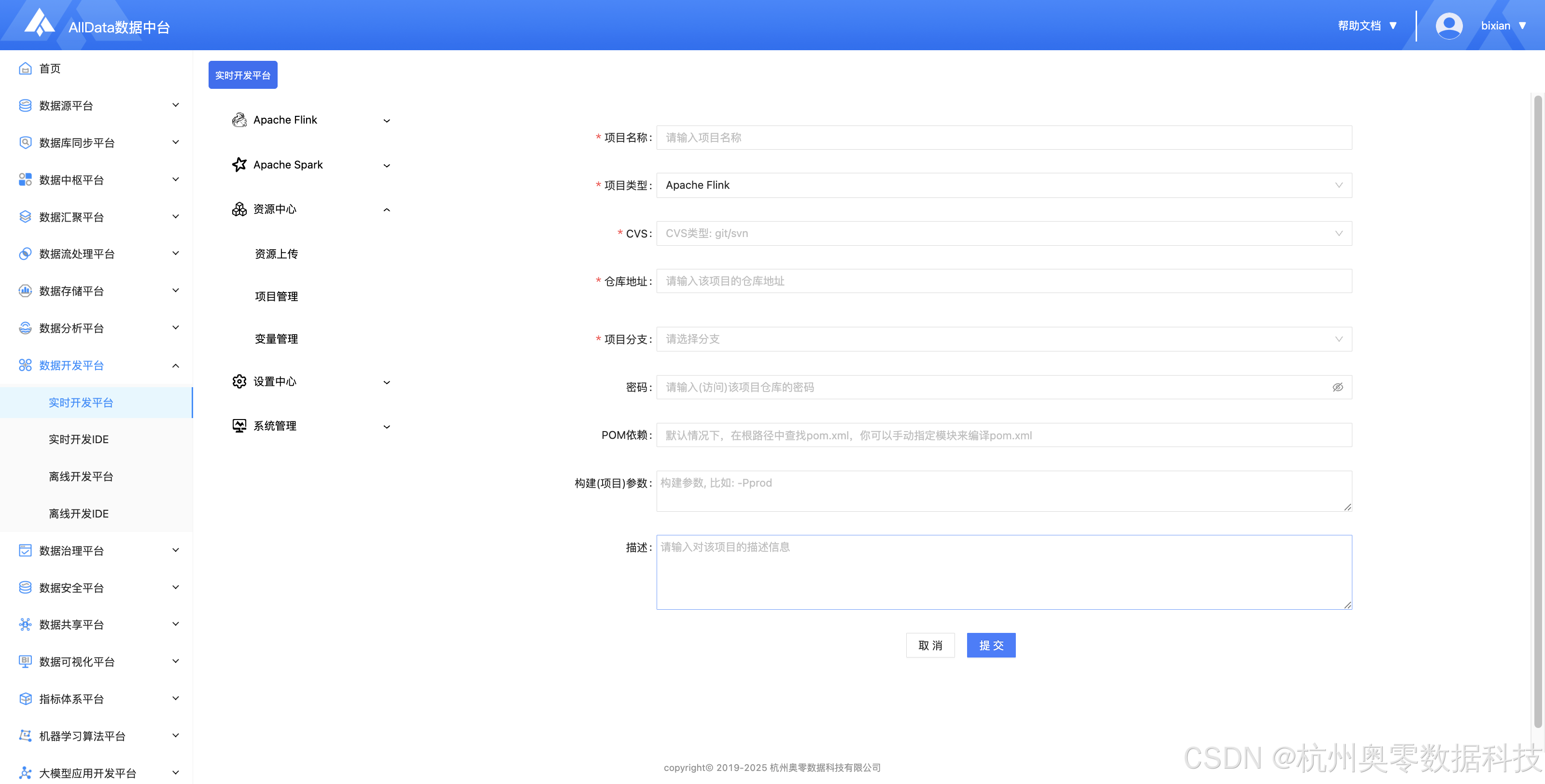
13、查看构建项目日志
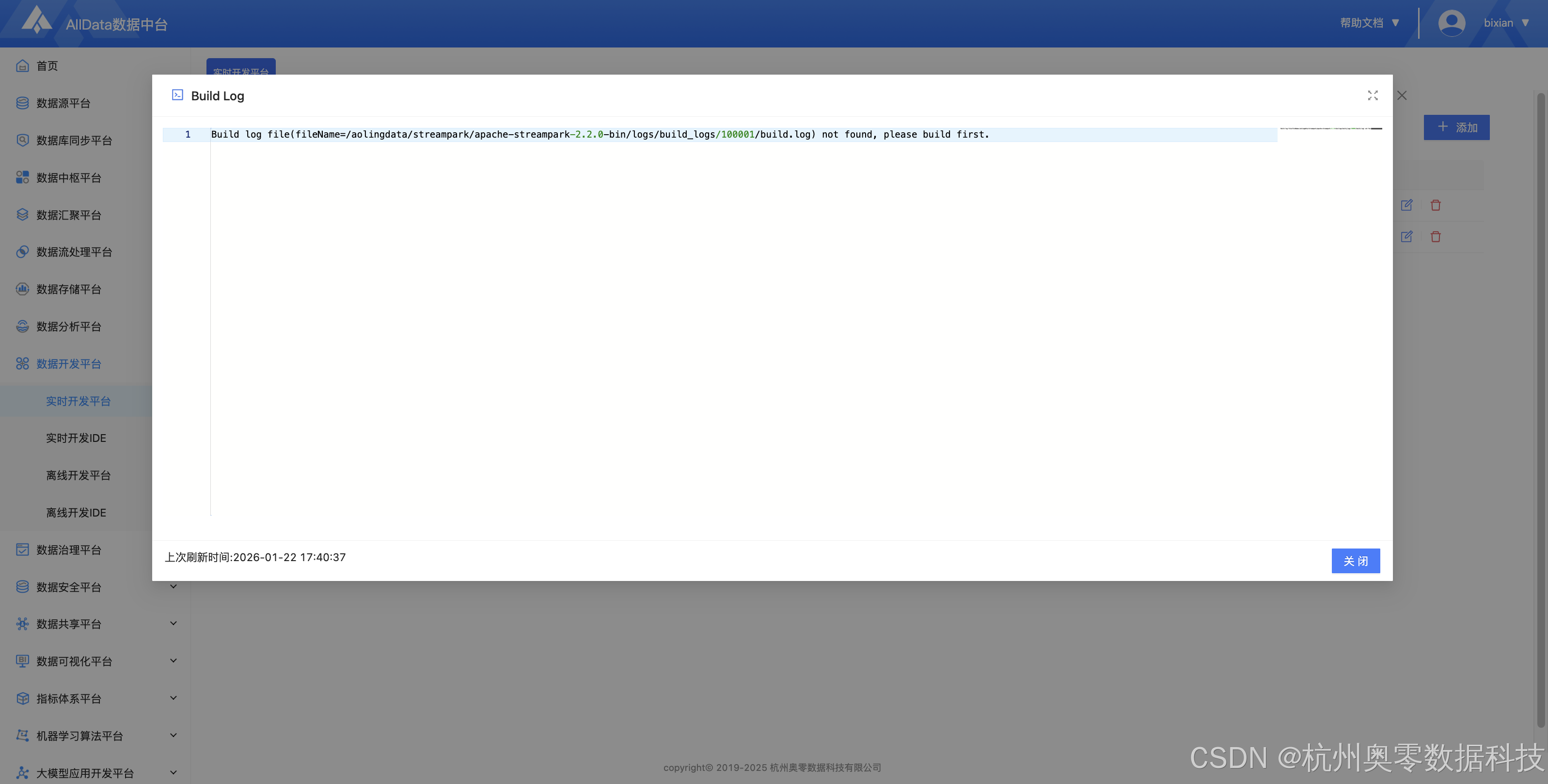
14、变量管理 (支持全局/项目级变量配置、多环境动态替换与版本追踪,实现资源参数与代码解耦,保障跨环境部署一致性)
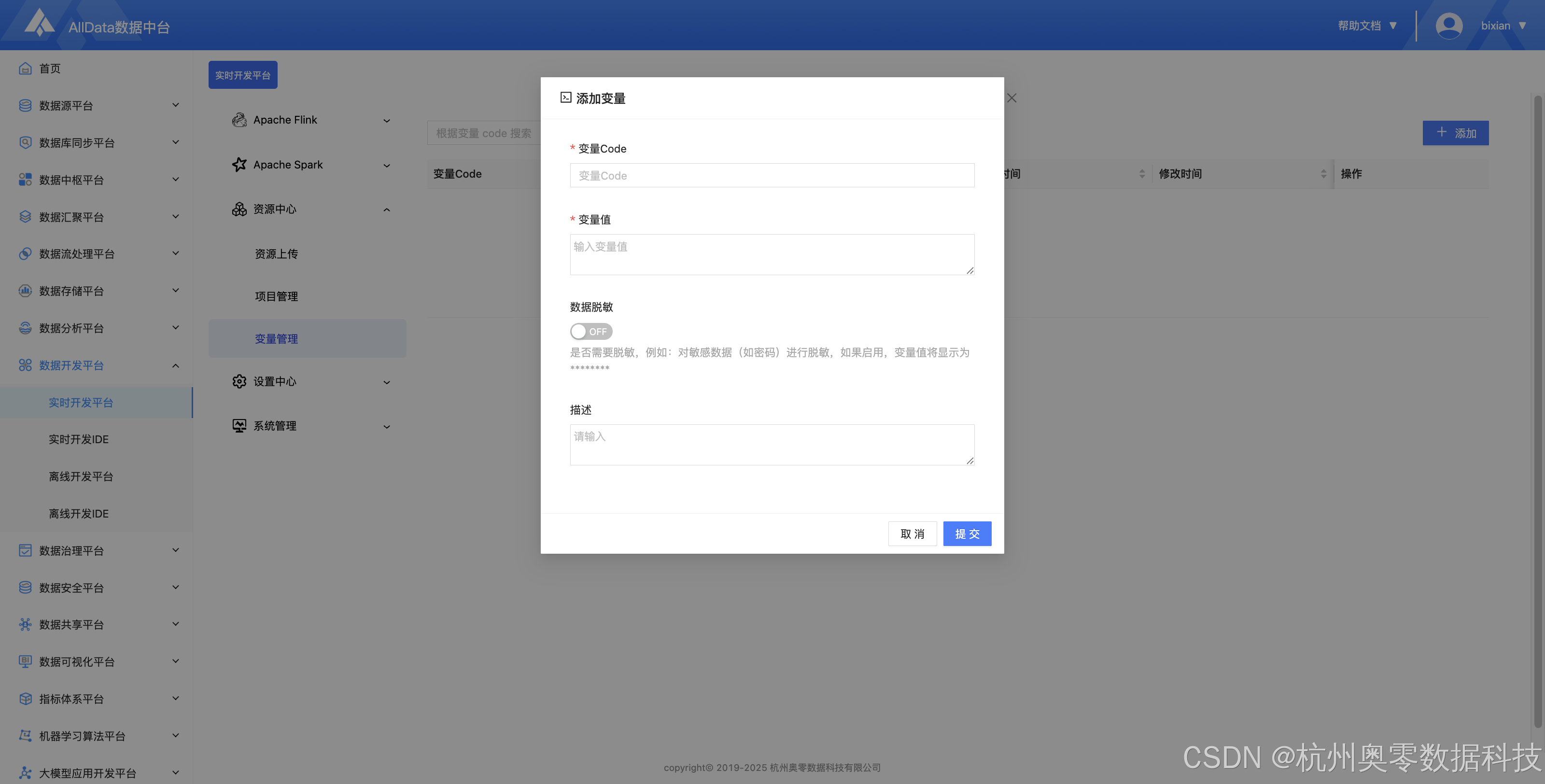
15、新建变量
16、设置中心
✅ 编辑环境设置(支持多环境参数隔离、集群动态绑定与资源变量联动)
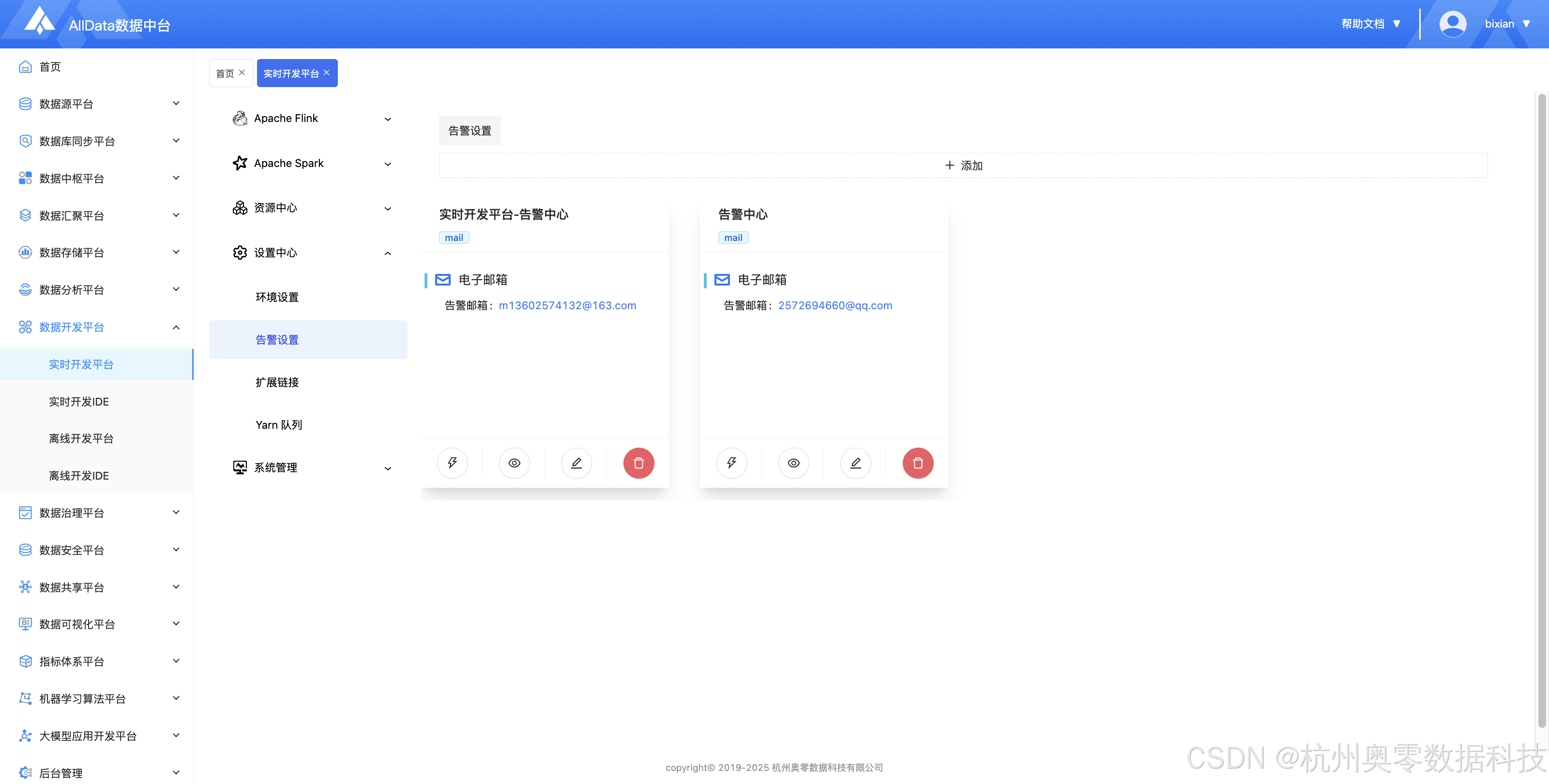
✅ 告警设置(多维度阈值配置、多渠道通知(邮件/短信)与告警策略自定义)
✅ 新建告警设置
17、扩展链接
18、Yarn队列 (自支持按业务分域配置资源池,动态分配核数/内存配额,绑定优先级与用户组,保障实时作业资源强隔离)
19、系统管理
✅ 密钥管理
✅ 新建密钥令牌
20、用户管理 (支持跨部门资源隔离、权限组批量分配与协作审计,实现实时开发团队与业务场景的动态映射,保障多项目资源安全协同)
21、新建用户
22、角色管理
23、编辑角色
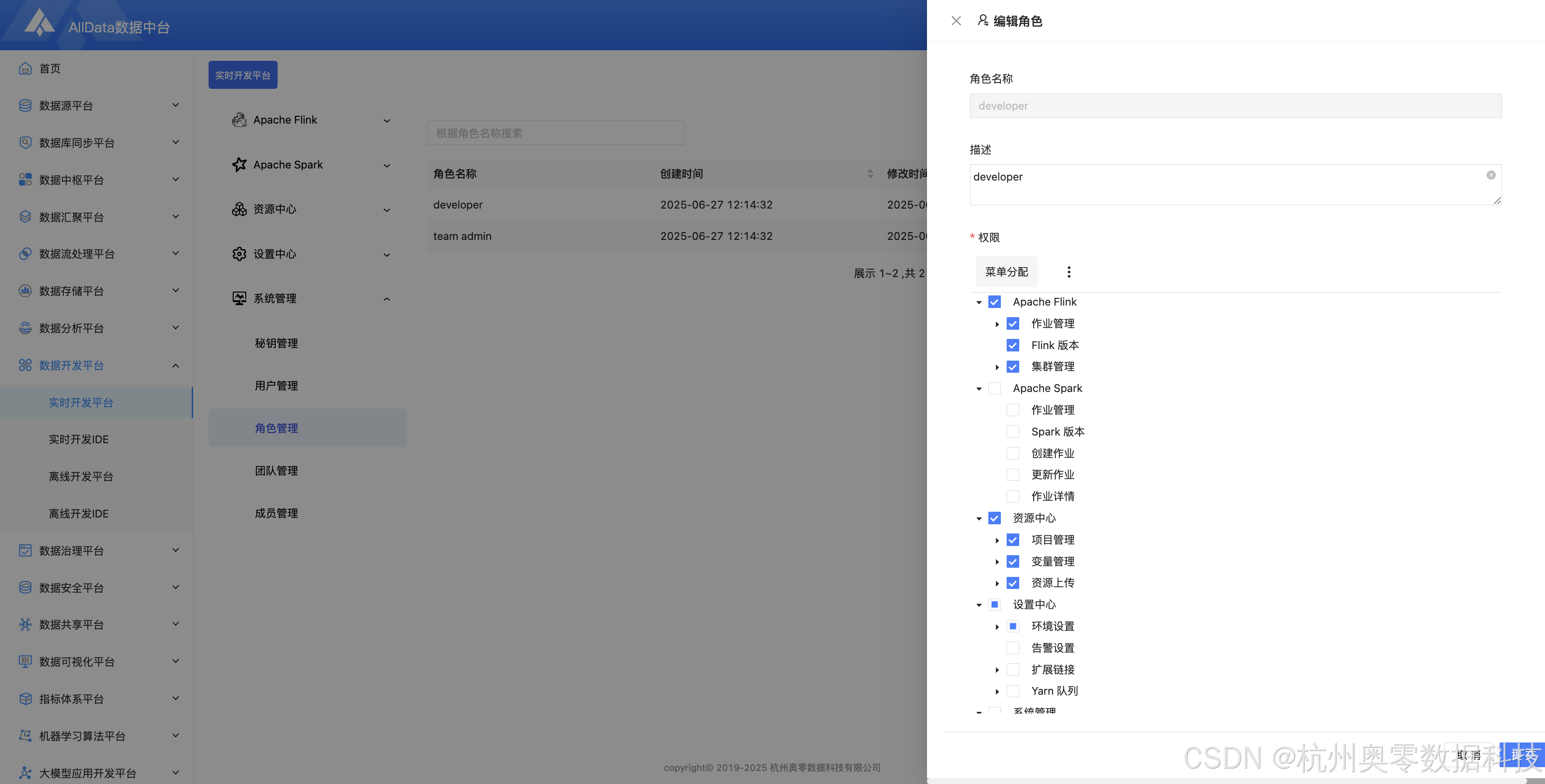
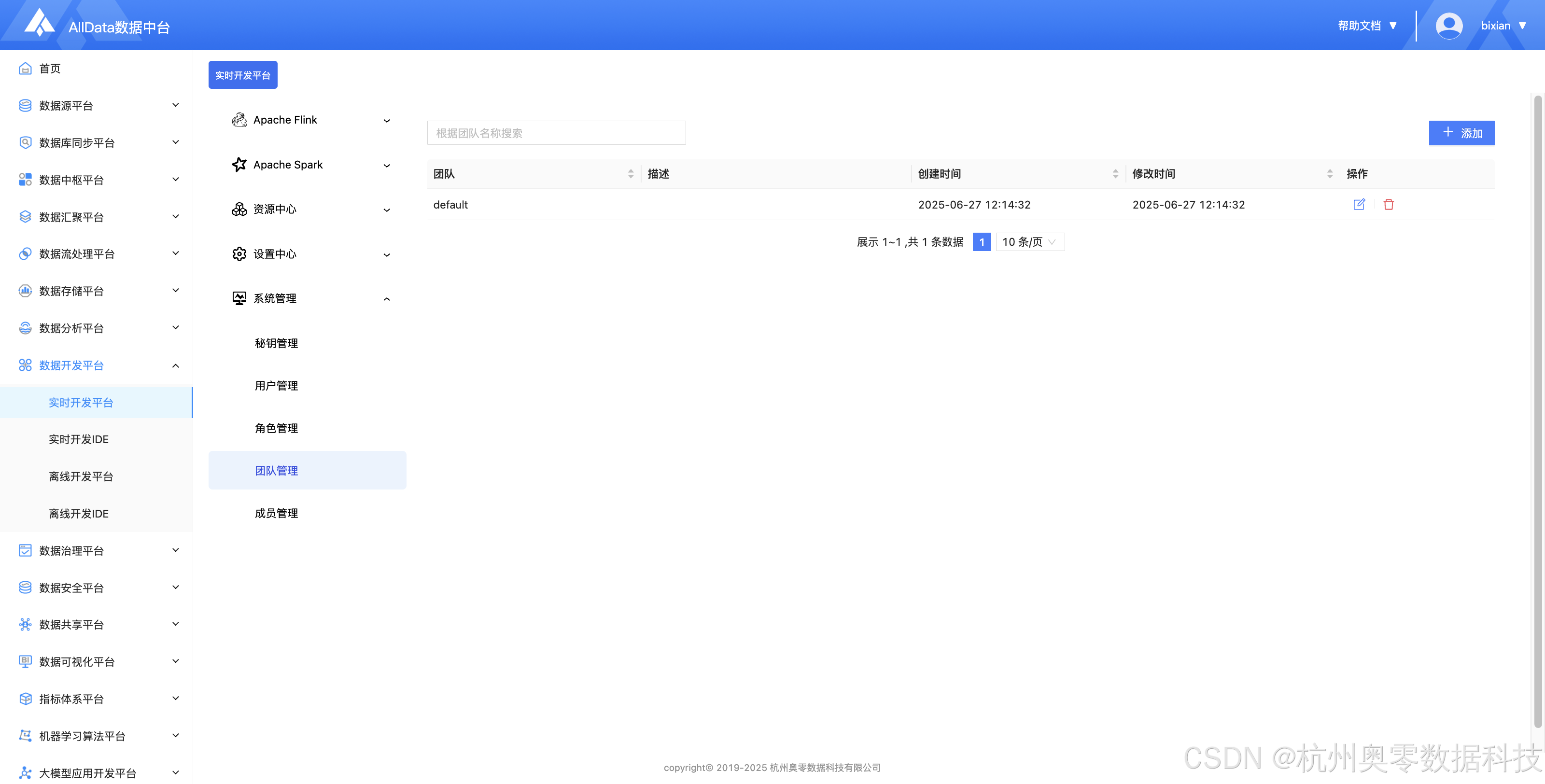
24、团队管理 (支持跨部门资源隔离、权限组批量分配与协作审计,实现实时开发团队与业务场景的动态映射,保障多项目资源安全协同)
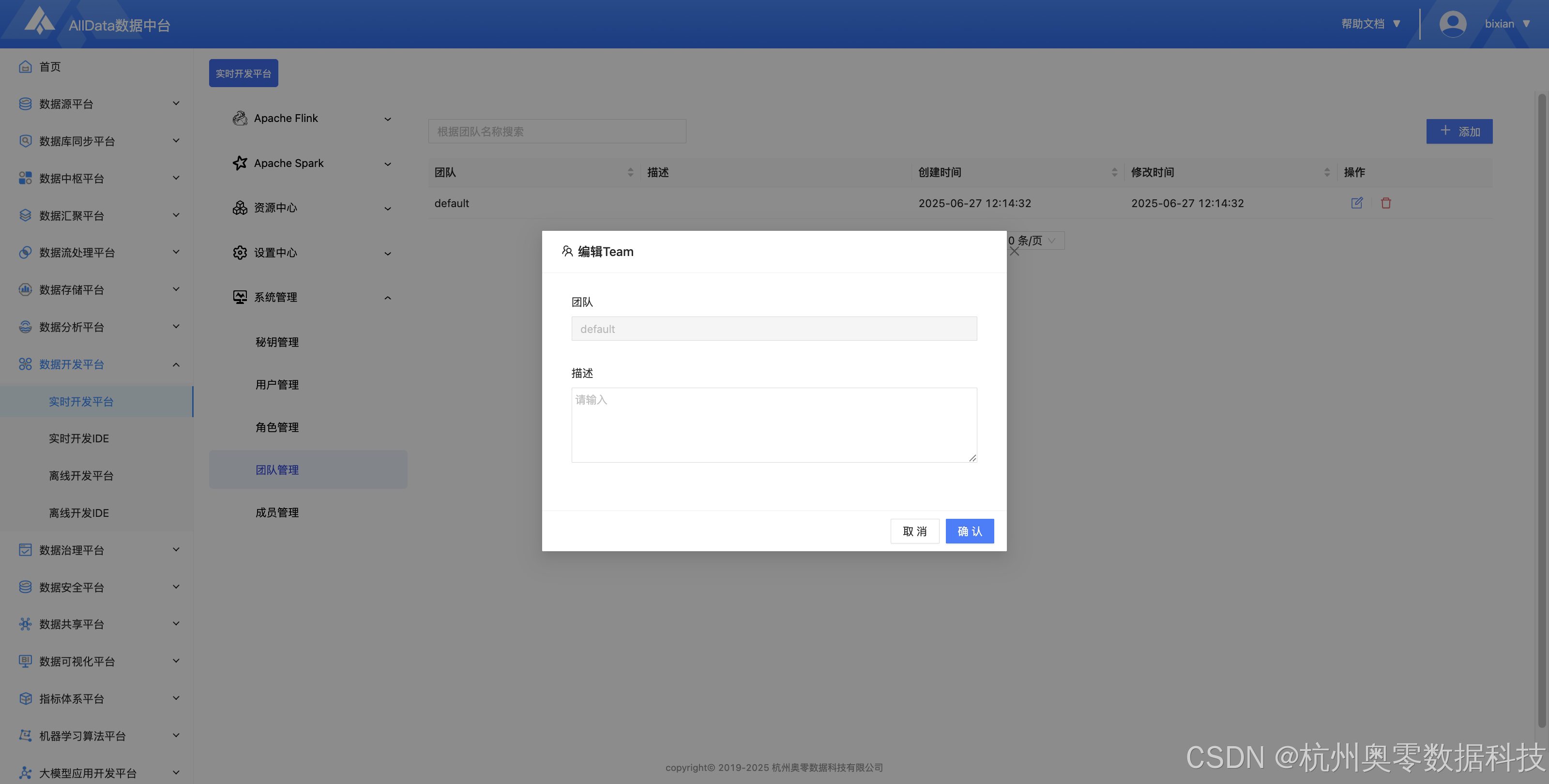
25、编辑团队
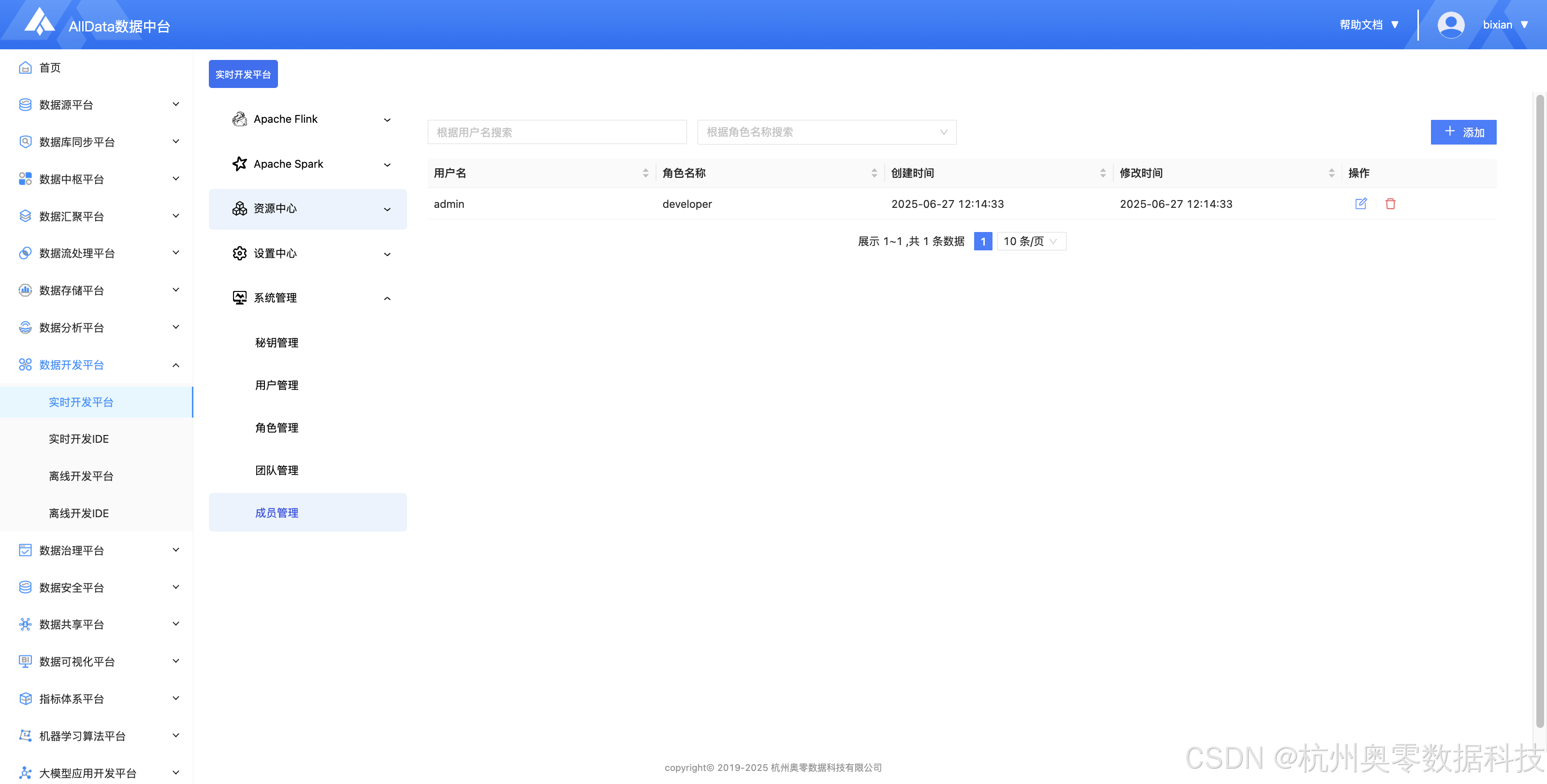
26、成员管理 (支持跨团队账号聚合、权限动态调整与操作行为溯源,实现企业级用户资源精细化管控,保障实时开发协作安全合规)
27、编辑成员
四、【实操演示】配置一个 "促销活动实时监控" 任务
✅ 作为业务负责人,您也可以通过清晰的界面和配置,主导一个实时数据任务的资源准备、上线部署和监控告警全流程,并与团队成员安全协作。

实时开发平台(StreamPark)不仅仅是工具,当"实时"成为一种普适、易用的能力,企业便能在数据的流动中,捕捉到每一个转瞬即逝的商机与风险。这正是这个时代,数据技术赋予业务的终极竞争力。
对企业而言,意味着构建了"统一的实时数据生产力" ,通过标准化、可视化的平台,降低了技术门槛和协作成本,使得"数据实时化"能够规模化地在全企业推广,成为业务创新的基础标配。
五、【相关资源】
✅ AllData开源项目:https://github.com/alldatacenter/alldata
✅ AllData官方手册:https://www.yuque.com/aolingdata/product
✅ 杭州奥零数据科技官网:http://www.aolingdata.com