文章目录
- [1. 基本概念补充](#1. 基本概念补充)
-
- [1. Pad, Bump,以及芯片封装过程中Pad、Bump 与基板的连接步骤](#1. Pad, Bump,以及芯片封装过程中Pad、Bump 与基板的连接步骤)
- [2. 基板和 PDB板](#2. 基板和 PDB板)
- [3、UCIE 中的 x8, x16, x32, x64](#3、UCIE 中的 x8, x16, x32, x64)
- [4. UCIE 中的 Link Training](#4. UCIE 中的 Link Training)
1. 基本概念补充
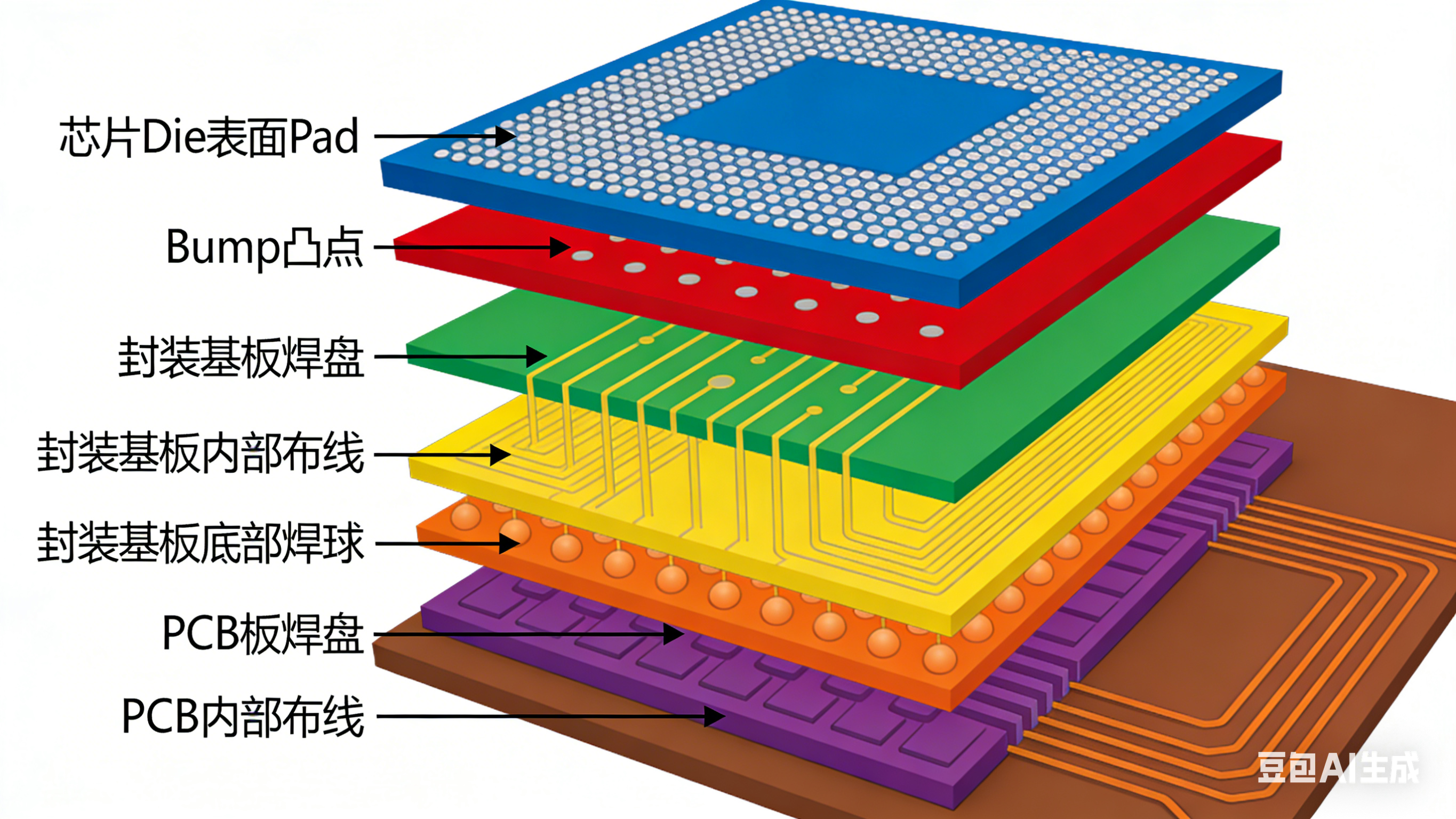
1. Pad, Bump,以及芯片封装过程中Pad、Bump 与基板的连接步骤
(1)芯片表面 Pad 金属化处理 :在晶圆切割后的裸芯片(Die) 表面,通过溅射或者电镀工艺形成金属焊盘(Pad), 材质通常为铝或铜,作为芯片内部电路与外部连接的接口
(2)在 Pad 上制作Bump 凸点 :采用焊膏印刷、电镀或蒸发工艺,在 Pad 表面生成金属凸点(Bump),常见材料为锡铅合金或无铅焊料,高度约为 20~ 100um,用于后续与基板的机械或电气连接
(3)Bump 与基板焊盘对准 :通过高精度贴片机将芯片翻转,使 Bump 抄下,与有机基板(Substrate)表面的对应焊盘精准对齐,误差控制在 ±5um 内,确保互连可靠性
(4)回流焊完成连接 :将组件放入回流焊炉,通过升温使Bump 焊料熔化,冷却后形成固定焊点,实现芯片Pad 与基板的永久电气连接,同时完成机械固定
2. 基板和 PDB板
在芯片封装与电子系统中,封装基板(Substrate) 和PCB 板(印刷电路板) 是两个核心互连载体,二者虽均为 "板级互连",但定位、工艺、性能、应用场景完全不同,且封装基板是芯片与 PCB 之间的核心桥接层 ,尤其在先进封装(如 UCIe、2.5D/3D)中是关键部件。
一、核心对比表(最易区分)
| 对比维度 | 封装基板(Substrate) | PCB 板(Printed Circuit Board) |
|---|---|---|
| 定位 | 芯片级互连,直接与芯片 Die 的 bump 连接 | 系统级互连,连接封装好的芯片、元器件、模组 |
| 连接对象 | 芯片 Die(bump)、其他芯粒、PCB 板 | 封装件(如 SOC、Chiplet 模组)、电阻 / 电容 / 连接器 |
| 工艺精度 | 极高,线宽 / 线距(L/S)2-10μm(先进款<2μm) | 常规,L/S 50-100μm(高精度 PCB 约 20μm) |
| 布线层数 | 薄而密,2-20 层,核心是微过孔 / 埋孔 | 灵活,1-100 + 层,以通孔 / 盲埋孔为主 |
| 材料 | 陶瓷、BT 树脂、硅基、玻璃基(先进封装) | FR-4(主流)、铝基、聚酰亚胺(柔性 FPC) |
| 互连方式 | 上接芯片bump(回流焊 / 混合键合),下接 PCB 的焊盘 / 引脚 | 上接封装件的引脚 / 焊球,下接其他元器件 / 外部接口 |
| 核心作用 | 芯片信号扇出、阻抗匹配、散热、供电分配 | 系统信号传输、电源分配、元器件物理固定 |
| 应用场景 | 芯片封装(倒装焊、UCIe、2.5D/3D、SiP) | 主板、显卡、工控板、消费电子主板等系统级产品 |
| 成本 | 单位面积极高(精密工艺) | 单位面积低(成熟量产工艺) |
二、关键概念深度解析
- 封装基板(Substrate)------ 芯片的 "专属贴身互连层"
- 芯片 pad→bump→基板连接,这里的基板就是封装基板,是芯片封装的核心组成部分(没有封装基板,芯片 Die 无法直接连 PCB)。
- 核心功能:芯片 Die 的 bump 间距极小(如 UCIe 先进封装 25-55μm),PCB 无法直接匹配该精度,封装基板通过 "扇出工艺" 将微小的 bump 引脚间距放大,转换成 PCB 能匹配的引脚 / 焊盘间距,同时完成高频信号的阻抗控制、芯片散热、稳定供电。
- 典型形态:尺寸很小(如手机 SOC 的封装基板仅数平方毫米),表面有与芯片 bump 对应的基板焊盘,底部有与 PCB 连接的焊球 / 引脚。
- 先进款:硅基基板(Si-Substrate)、玻璃基基板是 2.5D/3D 封装、UCIe Chiplet 互连的核心,可实现芯粒间的高密度 Die2Die 连接。
- PCB 板 ------ 电子系统的 "通用互连平台"
- PCB 是系统级的 "骨架",所有封装好的芯片、电阻、电容、连接器都焊接在 PCB 上,实现整个电子系统的信号、电源、地的互连。
- 核心功能:把不同封装件的引脚按系统设计要求 "布线连接",同时提供元器件的物理固定和一定的散热能力。
- 典型形态:尺寸大(如电脑主板、手机主板),表面有大量元器件焊盘,板上有通孔、走线、电源层 / 地层。
- 与封装基板的配合:封装基板(带芯片)通过底部焊球焊接在 PCB 的对应焊盘上,完成 "芯片→封装基板→PCB" 的互连链路。
三、结合封装流程的完整互连链路
从芯片 Die 到电子系统,完整的连接顺序是:
芯片 Die 内部电路 → 芯片表面 Pad(焊盘) → Pad 上制作 Bump(凸块) → 封装基板的基板焊盘(回流焊连接 bump)→ 封装基板内部微布线(扇出 + 阻抗匹配)→ 封装基板底部焊球 / 引脚 → PCB 板的元器件焊盘 → PCB 板内部布线 → 其他元器件 / 外部接口
四、一句话总结
封装基板是芯片的 "贴身转换器",解决芯片高精度互连与板级互连的匹配问题;PCB 是系统的 "通用接线板",实现所有元器件的系统级连接,二者是 "芯片封装→电子系统" 链路中上下游互补的核心部件,缺一不可。
3、UCIE 中的 x8, x16, x32, x64
x8, x16 ... 指的是芯粒(Chiplet) 间UCIE链路的单向数据通道(Lane) 总宽度,即单方向的并行数据lane 数量。
- 决定芯粒间的带宽上限与配置灵活性,标准封装常用 x8/x16, 先进封装以 x32/x64 为主,适配不同场景的性能与成本需求
xN = N 条单向数据 Lane: N 指单方向(发送或接收) 的物理数据通道数,每条 Lane 独立传输数据,链路为全双工,双向各有 xN Lane ( 如 x16 表示发送 16 Lane + 接收16 Lane)
典型配置与应用场景
| 配置 | 单向 Lane 数 | 典型封装类型 | 核心应用 | 关键特性 |
|---|---|---|---|---|
| x8 | 8 | 标准封装(UCIe‑S) | 低带宽芯粒(如 IO、控制芯粒)、故障降级 | 可从 x16 拆分,容错性强 |
| x16 | 16 | 标准封装(UCIe‑S) | 通用芯粒(如 CPU 小核、中端 IP) | 标准封装基础模块,成本与性能平衡 |
| x32 | 32 | 先进封装(UCIe‑A) | 中高带宽芯粒(如 GPU、AI 计算芯粒) | 由 2 个 x16 模块聚合,带宽翻倍 |
| x64 | 64 | 先进封装(UCIe‑A) | 超高带宽芯粒(如 HBM 控制器、高端 SoC) | 先进封装基础模块,含 4 条冗余 lane,支持修复 |
4. UCIE 中的 Link Training
Link Training(链路训练):两个芯粒(Chiplet) 上电/复位后,在正式传输数据前,通过一系列协商与校准步骤,让物理层(PHY) 和数据链路层(DLL) 达成一致,建立稳定可靠连接的初始化过程
- 握手 + 校准 + 协商,确保链路能跑、跑对、跑稳
4.1. Link Training 核心:
-
- 链路协商
- 确定链路宽度:x8/x16/x32/x64
- 确定速率:16/24/32 GT/s 等
- 确定工作模式:Flit 模式 / Raw 模式
- 确定协议:PCIe6.0 / CXL 2.0/3.0 / 自定义协议
-
- 物理层校准(PHY Calibration)
- Lane 极性校正(Tx/Rx 正负极是否接反)
- Lane 映射与 Lane 排序(lane swap)
- 时钟恢复与 CDR锁定
- 均衡(FFE/CTLE/DFE) 参数训练
- 时延补偿(skew 校准)
- 信号眼图优化
-
- 链路层同步与可靠性建立
- Flit 边界对齐
- CRC 与 重传机制协商
- 流量控制信用初始化
- 链路状态进入 L0 (正常工作)
4.2 UCIe Link Training 典型流程
UCIe 训练流程与 PCIe/CXL 类似,但是更适配 Chiplet 短距高密度场景,典型阶段如下:
-
- 复位与初始状态(Detect/Reset)
- 两端进入复位,Tx 发送默认电平/训练序列
- 检测对方存在,进入训练
-
- 链路宽度与 Lane 识别(Polling/Lane Identification)
- 发送已知训练序列(TS1/TS2 或 UCIe 专用序列)
- 识别有效 Lane, 确定链路宽度(x8/x16/x32/x64)
- 纠正 Lane 交换(lane swap)、极性反转
-
- 速率协商与均衡训练(Configuration)
- 从低速到高速逐级尝试
- 对每 Lane 做 FFE/CTLE/DFE 系数训练
- 优化信号质量,达到误码率要求
-
- 同步与对齐(Alignment)
- Lane-to-Lane skew 补偿
- Flit 边界对齐
- 链路层状态机同步
-
- 进入正常工作(L0)
- 训练完成,开始正常 Flit 传输
- 后续可进入低功耗状态(L1/L2),唤醒时可做快速重训练
4.3. 为什么必须做 Link Training
-
- Chiplet 物理差异大
- 不同工艺、不同封装、不同位置,信号衰减、串扰、skew 都不同
- 必须 "现场校准",不能出厂固定参数
-
- 高速 SerDes 依赖自适应均衡
- 16/24/32 GT/s PAM4 对信道非常敏感
- 必须通过训练找到最优 FFE/CTLE/DFE 才能开眼
-
- 保证互操作性
- 不同厂商芯粒必须按同一训练流程协商
- 否则无法互通,UCIe 生态就不成立
-
- 提高良率与可靠性
- 训练中可检测坏 Lane,做 Lane 降级(如 x16 → x8)
- 保证即使部分 Lane 异常,链路仍可用
4.4、关联(Flit /xN/ Bump)
Link Training 成功后,才会进入 Flit 模式
训练确定的 链路宽度(x8/x16/x32/x64) 决定 Flit 如何映射到 Lane
训练确定的 速率 决定 Flit 传输周期与带宽
训练完成后,物理层才会把 Bump 上的差分信号稳定转换成可靠的 Flit 流