05_数据太多怎么吃?Mini-batch训练的设计模式
本章目标:解决"数据量太大,显存放不下"的问题。从全量训练 (Batch) 进化到分批训练 (Mini-batch)。
📖 目录
- [Epoch, Batch, Iteration](#Epoch, Batch, Iteration)
- [DataLoader 流水线](#DataLoader 流水线)
- [实战:自定义 Dataset](#实战:自定义 Dataset)
- [实战:使用 DataLoader](#实战:使用 DataLoader)
1. Epoch, Batch, Iteration
- Epoch: 所有样本训练一次。
- Batch Size: 每次喂给模型多少个样本。
- Iteration: 更新一次参数。
2. DataLoader 流水线
PyTorch 的数据加载是多线程的。
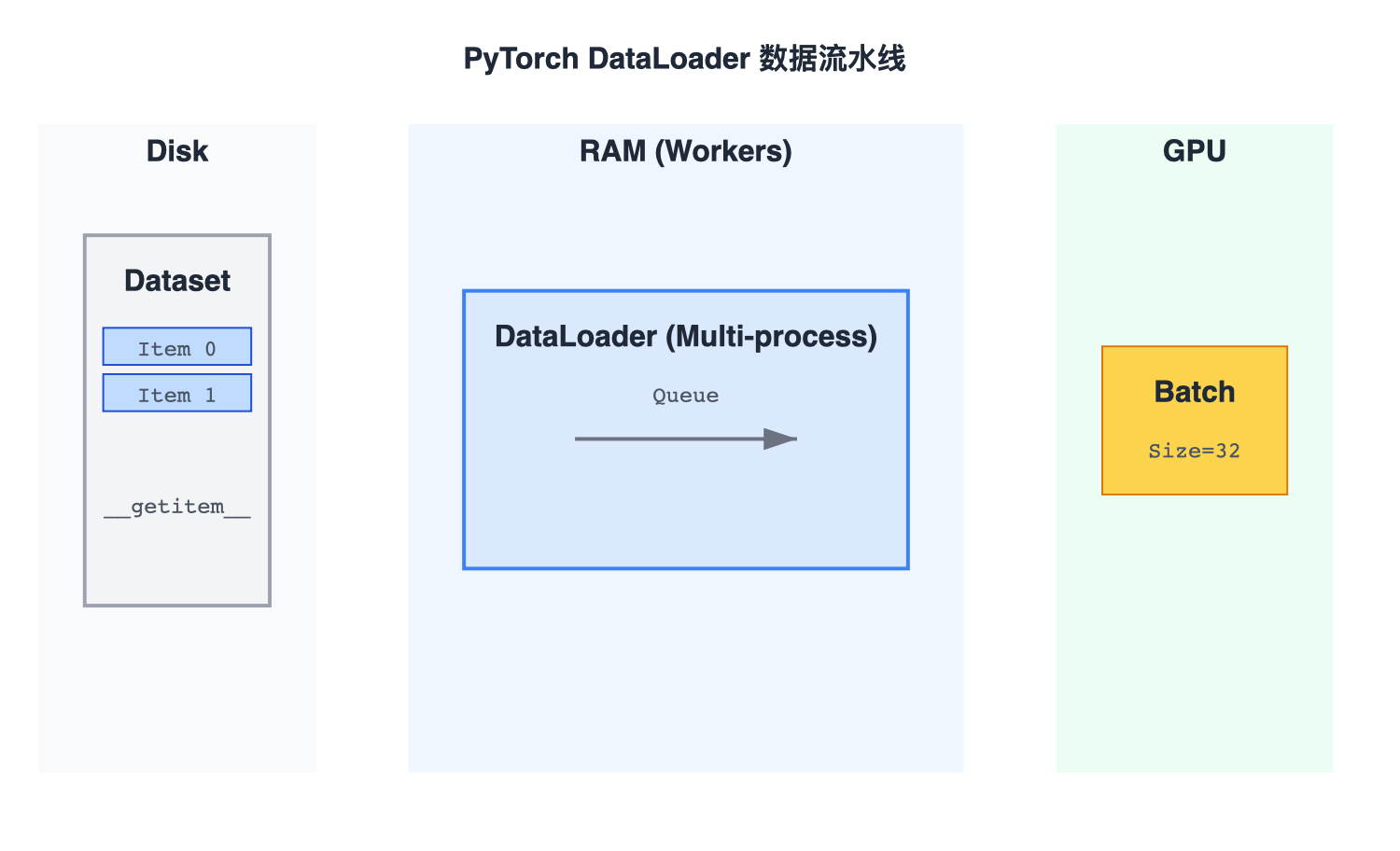
- Disk: 数据在硬盘。
- Workers:多进程读取。
- Queue: 放入内存队列。
- Collate: 拼成 Batch Tensor。
- GPU: 模型计算。
3. 实战:自定义 Dataset
python
from torch.utils.data import Dataset, DataLoader
import torch
import numpy as np
class DiabetesDataset(Dataset):
def __init__(self, filepath):
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
dataset = DiabetesDataset('diabetes.csv.gz')
train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=2)4. 实战:使用 DataLoader
python
for epoch in range(100):
for i, data in enumerate(train_loader, 0):
# 1. Prepare data
inputs, labels = data
# 2. Forward
y_pred = model(inputs)
loss = criterion(y_pred, labels)
# 3. Backward
optimizer.zero_grad()
loss.backward()
# 4. Update
optimizer.step()