1. 模型微调的基本概念与流程
微调是指在预训练模型的基础上,通过进一步的训练来适应特定的下游任务。BERT 模型通过预训练来学习语言的通用模式,然后通过微调来适应特定任务,如情感分析、命名实体识别等。微调过程中,通常冻结 BERT 的预训练层,只训练与下游任务相关的层。本课件将介绍如何使用 BERT 模型进行情感分析任务的微调训练。
1.1 ai开发的流程

其中,数据集是比较重要的,从用户获得原始数据,对数据的清洗,往往会影响模型的训练结果
1.2 训练过程 的三个状态
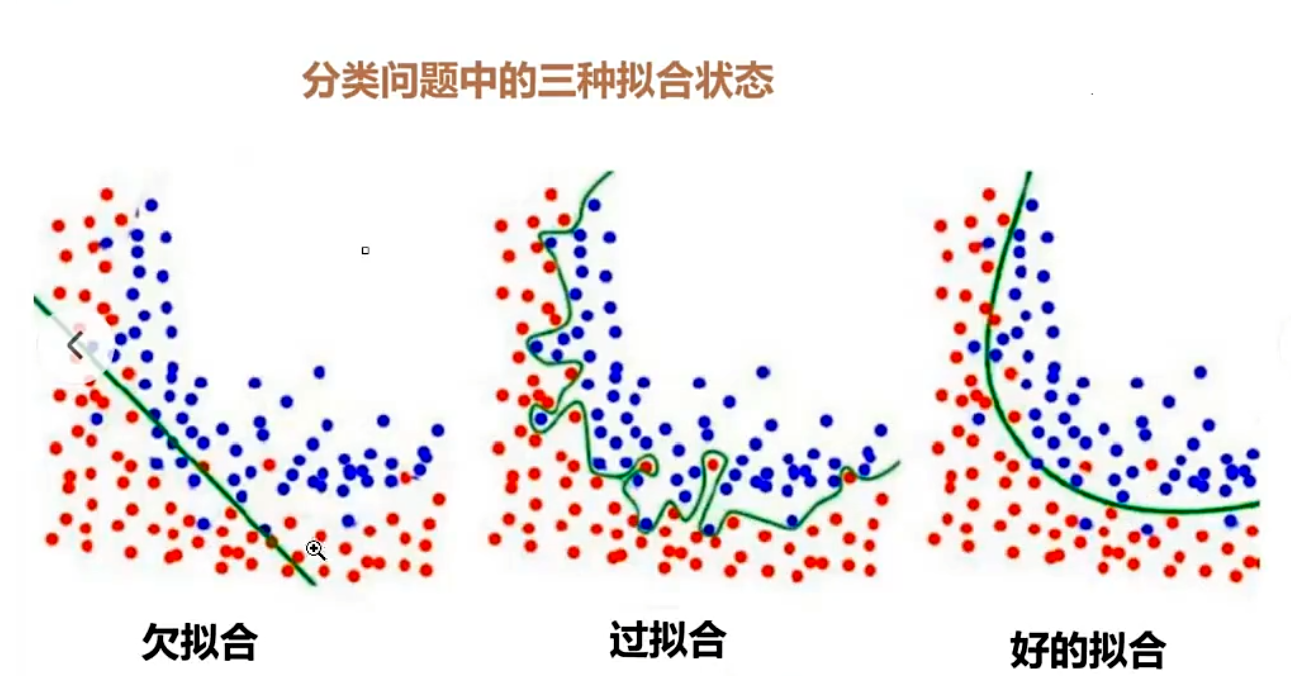
过拟合状态,会丧失模型的泛华能力
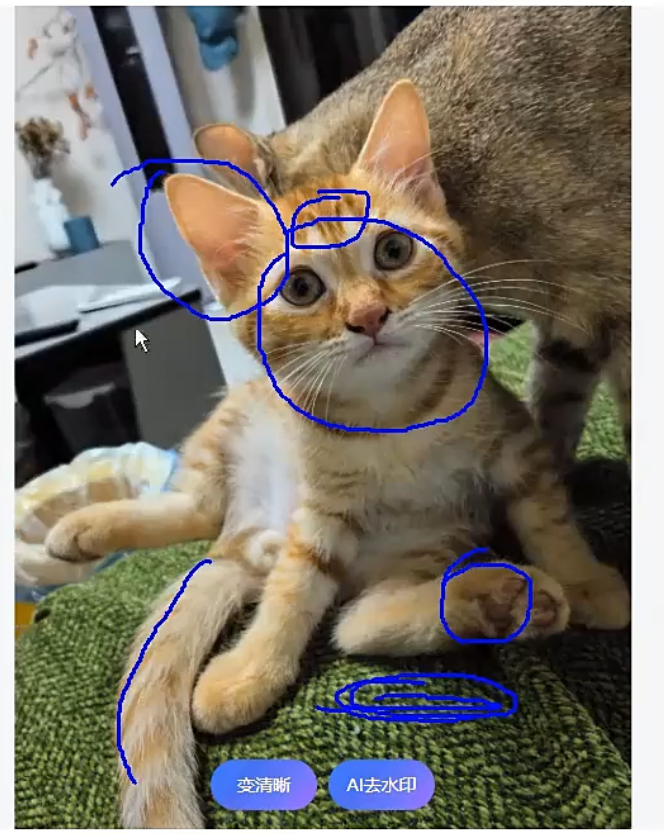
好的拟合:描述尾巴长长的,花色、大小、脚印的形状
过拟合:xxxx...会将绿色的毛毯也认为是猫的特征
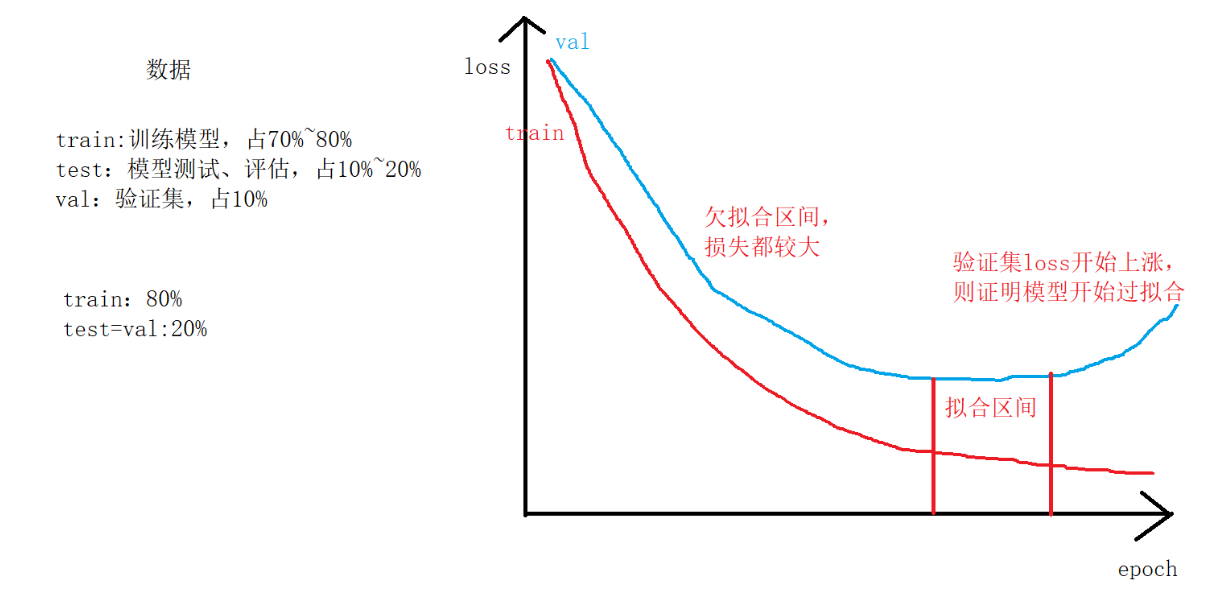
怎么判断是否是一个好的拟合状态?
观察测试的loss的情况
2. 加载数据集
情感分析任务的数据通常包括文本及其对应的情感标签。使用 Hugging Face 的 datasets 库可以轻松地加载和处理数据集。
python
from datasets import load_dataset,load_from_disk
#在线加载数据
# dataset = load_dataset(path="NousResearch/hermes-function-calling-v1",cache_dir="data/")
# print(dataset)
#转为csv格式
# dataset.to_csv(path_or_buf=r"D:\PycharmProjects\demo_02\data\ChnSentiCorp.csv")
# 加载缓存数据
data_path = r"F:\26_01\第六期\python\L2_study\L2\day04-基于BERT模型的自定义微调训练\demo_04\data\ChnSentiCorp"
datasets = load_from_disk(data_path)
print(datasets)
train_data = datasets["test"]
for data in train_data:
print(data)
# 扩展:加载CSV格式数据
# dataset = load_dataset(path="csv",data_files=data_path)
# print(dataset)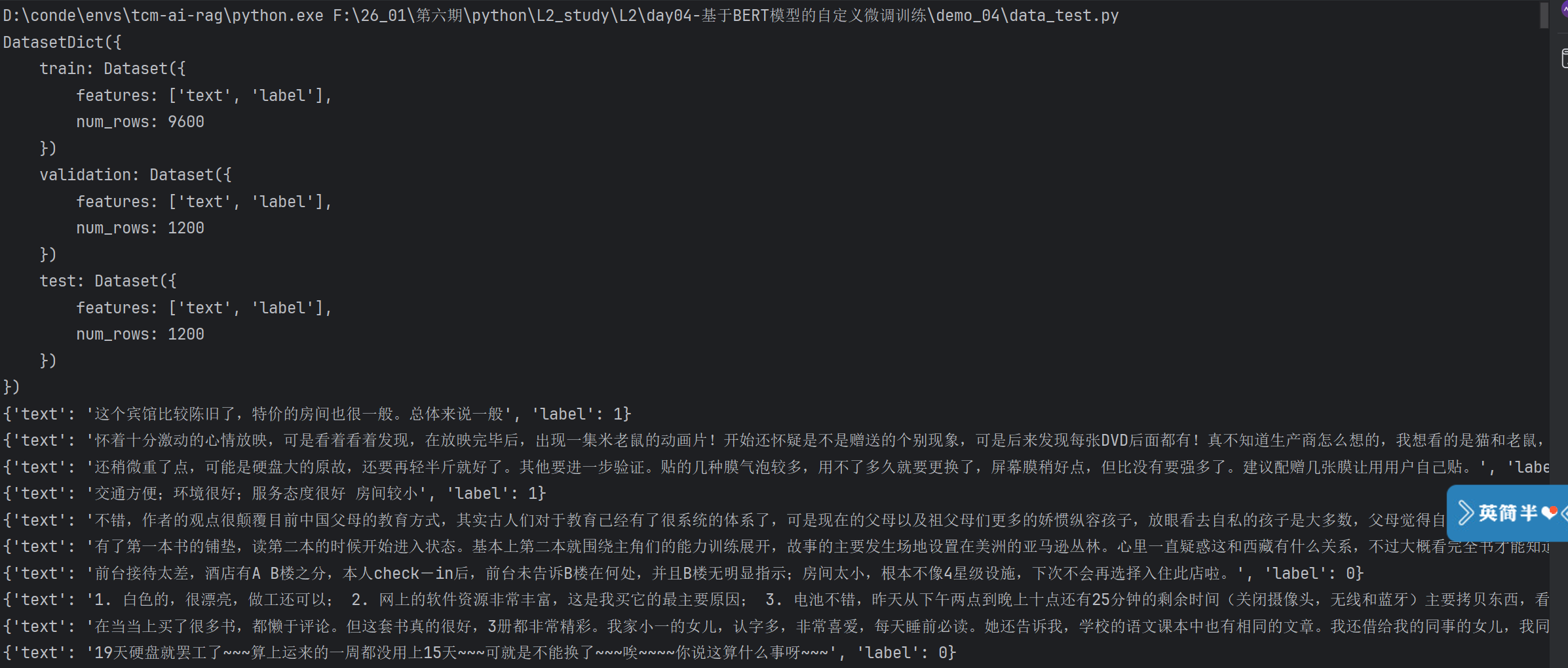
魔搭社区下载+环境配置
采用魔搭社区下载数据集
pythonpip install oss2 addict #升级 pip install --upgrade datasets pip install --upgrade modelscope
python#数据集下载 from modelscope.msdatasets import MsDataset #需要下载的绝对目录 cache_dir = r"F:\26_01\第六期\python\L2_study\L2\day04-基于BERT模型的自定义微调训练\demo_04\data" ds = MsDataset.load('AiNiklaus/ChnSentiCorp', subset_name='default', split='train', cache_dir=cache_dir) #您可按需配置 subset_name、split,参照"快速使用"示例代码
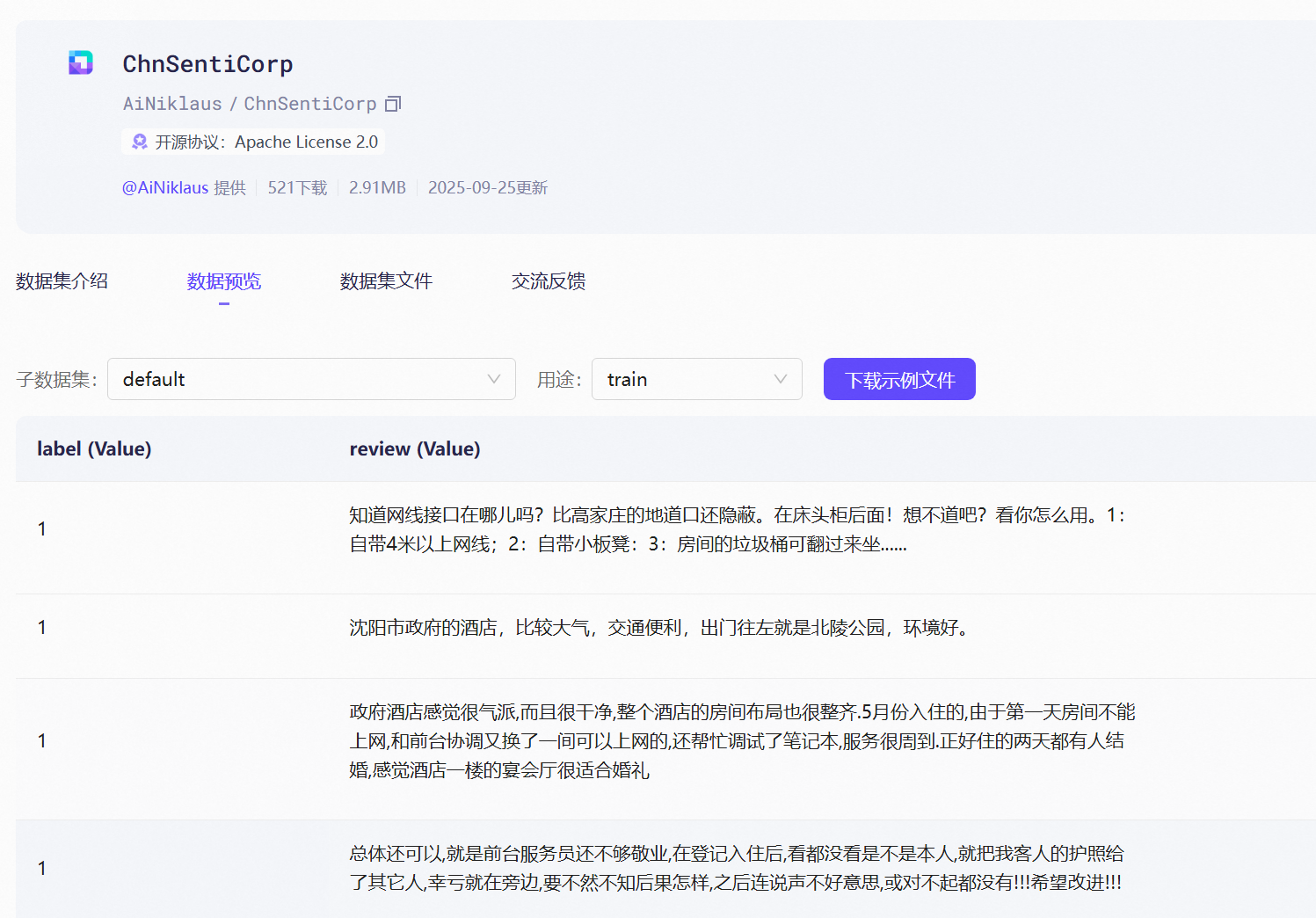
2.1 数据集格式
Hugging Face 的 datasets 库支持多种数据集格式,如 CSV、JSON、TFRecord 等。在本案例中,使用CSV 格式,CSV 文件应包含两列:一列是文本数据,另一列是情感标签。
2.2 数据集信息
加载数据集后,可以查看数据集的基本信息,如数据集大小、字段名称等。这有助于我们了解数据的分布情况,并在后续步骤中进行适当的处理。
3. 制作 Dataset
加载数据集后,需要对其进行处理以适应模型的输入格式。这包括数据清洗、格式转换等操作。
python
from datasets import Dataset
# 制作 Dataset
dataset = Dataset.from_dict({
'text': ['位置尚可,但距离海边的位置比预期的要差的多','5月8日付款成功,当当网显示5月10日发货,可是至今还没看到货物,也没收到任何通知,简不知怎么说好!!!','整体来说,本书还是不错的。至少在书中描述了许多现实中存在的司法系统方面的问题,这是值得每个法律工作者去思考的。尤其是让那些涉世不深的想加入到律师队伍中的年青人,看到了社会特别是中国司法界真实的一面。缺点是:书中引用了大量的法律条文和司法解释,对于已经是律师或有一定工作经验的法律工作者来说有点多余,而且所占的篇幅不少,有凑字数的嫌疑。整体来说还是不错的。不要对一本书提太高的要求。'],
'label': [0, 1, 1] # 0 表示负向评价,1 表示正向评价
})
# 查看数据集信息
print(dataset)介绍AI模型是如何处理字符数据的
图中对应着模型字典的顺序

python
"""
本节小结核心介绍AI模型是如何处理字符数据的
"""
from transformers import BertTokenizer
#加载字典和分词器
token = BertTokenizer.from_pretrained(r"F:\26_01\第六期\python\L2_study\L2\day04-基于BERT模型的自定义微调训练\demo_04\model\bert-base-chinese\models--bert-base-chinese\snapshots\c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f")
# print(token)
#准备要编码的文本数据
sents = ["白日依山尽,",
"价格在这个地段属于适中, 附近有早餐店,小饭店, 比较方便,无早也无所"]
#批量编码句子
out = token.batch_encode_plus(
batch_text_or_text_pairs=[sents[0],sents[1]],
add_special_tokens=True,
#当句子长度大于max_length(上限是model_max_length)时,截断
truncation=True,
max_length=15,
#一律补0到max_length
padding="max_length",
#可取值为tf,pt,np,默认为list
return_tensors=None,
return_attention_mask=True,
return_token_type_ids=True,
return_special_tokens_mask=True,
#返回序列长度
return_length=True
)
#input_ids 就是编码后的词
#token_type_ids第一个句子和特殊符号的位置是0,第二个句子的位置1()只针对于上下文编码
#special_tokens_mask 特殊符号的位置是1,其他位置是0
#length 编码之后的序列长度
for k,v in out.items():
print(k,":",v)
#解码文本数据
print(token.decode(out["input_ids"][0]),token.decode(out["input_ids"][1]))3.1 数据集字段
在制作 Dataset 时,需定义数据集的字段。在本案例中,定义了两个字段:text(文本)和label (情感标签)。每个字段都需要与模型的输入和输出匹配。
3.2 数据集信息
制作 Dataset 后,可以通过 dataset.info 等方法查看其大小、字段名称等信息,以确保数据集的正确性和完整性。
4. vocab 字典操作
在微调 BERT 模型之前,需要将模型的词汇表(vocab)与数据集中的文本匹配。这一步骤确保输入的文本能够被正确转换为模型的输入格式。
python
from transformers import BertTokenizer
# 加载 BERT 模型的 vocab 字典
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
# 将数据集中的文本转换为 BERT 模型所需的输入格式
dataset = dataset.map(lambda x: tokenizer(x['text'], return_tensors="pt"),
batched=True)
# 查看数据集信息
print(dataset)4.1 词汇表(vocab)
BERT 模型使用词汇表(vocab)将文本转换为模型可以理解的输入格式。词汇表包含所有模型已知的单词及其对应的索引。确保数据集中的所有文本都能找到对应的词汇索引是至关重要的。
4.2 文本转换
使用 tokenizer 将文本分割成词汇表中的单词,并转换为相应的索引。此步骤需要确保文本长度、特殊字符处理等都与 BERT 模型的预训练设置相一致。
5. 下游任务模型设计
在微调 BERT 模型之前,需要设计一个适应情感分析任务的下游模型结构。通常包括一个或多个全连接层,用于将 BERT 输出的特征向量转换为分类结果。
python
from transformers import BertModel
import torch.nn as nn
class SentimentAnalysisModel(nn.Module):
def __init__(self):
super().__init__()
self.bert = BertModel.from_pretrained('bert-base-chinese')
self.drop_out = nn.Dropout(0.3)
self.linear = nn.Linear(768, 2) # 假设情感分类为二分类
def forward(self, input_ids, attention_mask):
_, pooled_output = self.bert(
input_ids=input_ids,
attention_mask=attention_mask,
return_dict=False
)
output = self.drop_out(pooled_output)
return self.linear(output)5.1 模型结构
下游任务模型通常包括以下几个部分:
BERT 模型:用于生成文本的上下文特征向量。
Dropout 层:用于防止过拟合,通过随机丢弃一部分神经元来提高模型的泛化能力。
全连接层:用于将 BERT 的输出特征向量映射到具体的分类任务上。
5.2 模型初始化
使用 BertModel.from_pretrained() 方法加载预训练的 BERT 模型,同时也可以初始化自定义的全连接层。初始化时,需要根据下游任务的需求,定义合适的输出维度。
6. 自定义模型训练
模型设计完成后,进入训练阶段。通过数据加载器(DataLoader)高效地批量处理数据,并使用优化器更新模型参数。
python
from torch.utils.data import DataLoader
from transformers import AdamW
# 实例化 DataLoader
data_loader = DataLoader(dataset, batch_size=16, shuffle=True)
# 初始化模型和优化器
model = SentimentAnalysisModel()
optimizer = AdamW(model.parameters(), lr=5e-5)
# 训练循环
for epoch in range(3): # 假设训练 3 个 epoch
model.train()
for batch in data_loader:
optimizer.zero_grad()
outputs = model(input_ids=batch['input_ids'],
attention_mask=batch['attention_mask'])
loss = nn.CrossEntropyLoss()(outputs, batch['labels'])
loss.backward()
optimizer.step()6.1 数据加载
使用 DataLoader 实现批量数据加载。DataLoader 自动处理数据的批处理和随机打乱,确保训练的高效性和数据的多样性。
6.2 AdamW 优化器
AdamW 是一种适用于 BERT 模型的优化器,结合了 Adam 和权重衰减的特点,能够有效地防止过拟合。
6.3 训练循环
训练循环包含前向传播(forward pass)、损失计算(loss calculation)、 反向传播(backwardpass)、参数更新(parameter update)等步骤。每个 epoch 都会对整个数据集进行一次遍历,更新模型参数。通常训练过程中会跟踪损失值的变化,以判断模型的收敛情况。
6.4 保存参数
在保存参数的方法中,要确保目录存在,pytorch保存不会自己创建目录
python# #每训练完一轮,保存一次参数 # torch.save(model.state_dict(),f"params/{epoch}_bert.pth") # print(epoch,"参数保存成功!") #根据验证准确率保存最优参数 if val_acc > best_val_acc: best_val_acc = val_acc torch.save(model.state_dict(),"params/best_bert.pth") print(f"EPOCH:{epoch}:保存最优参数:acc{best_val_acc}") #保存最后一轮参数 torch.save(model.state_dict(), "params/last_bert.pth") print(f"EPOCH:{epoch}:最后一轮参数保存成功!")
6.5 训练批次设置
根据gpu显存占用,选择合适的大小批次
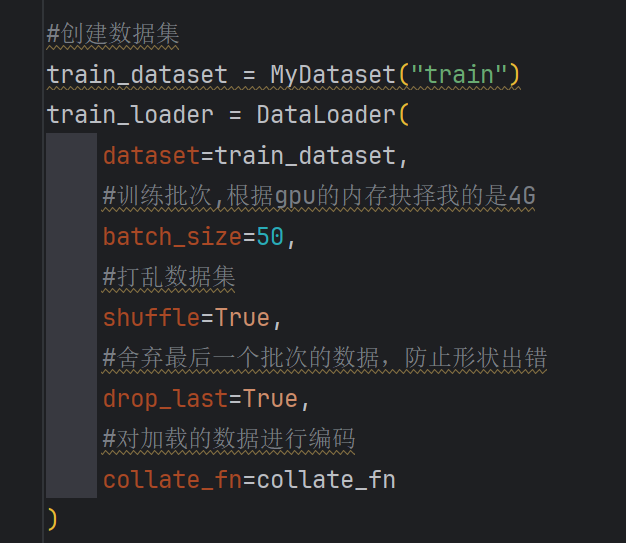
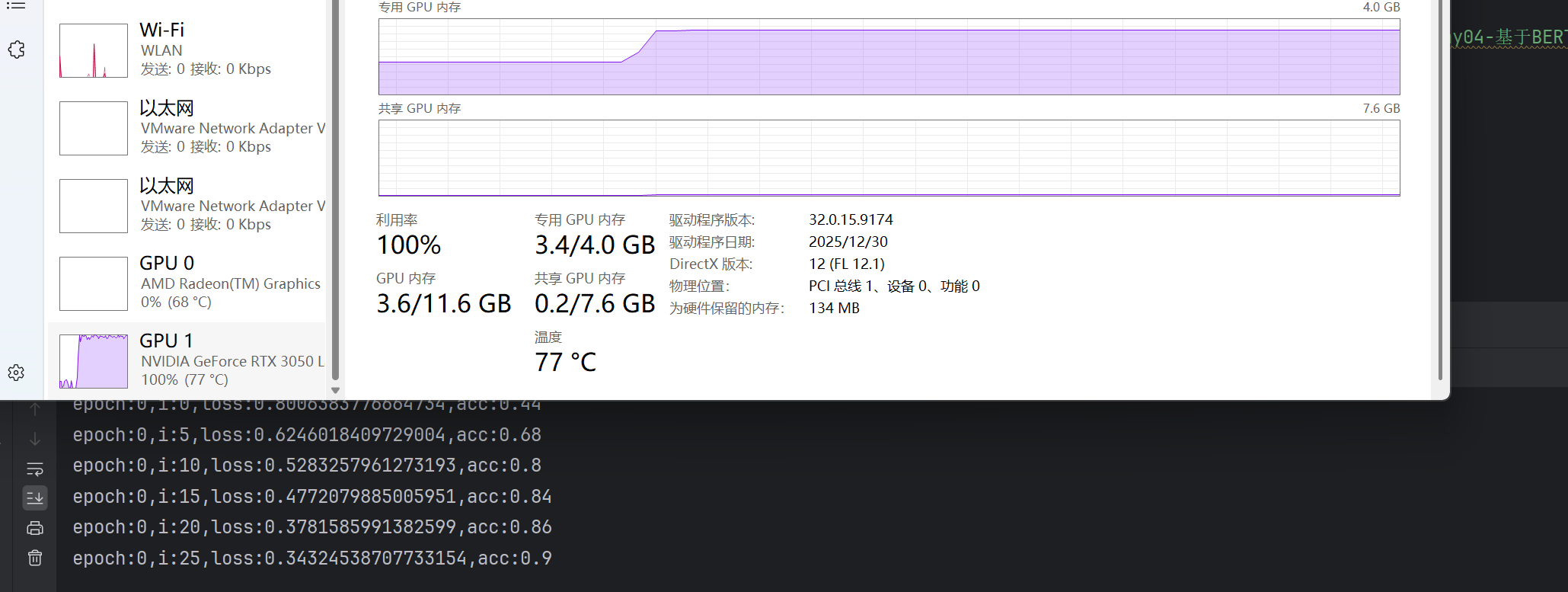
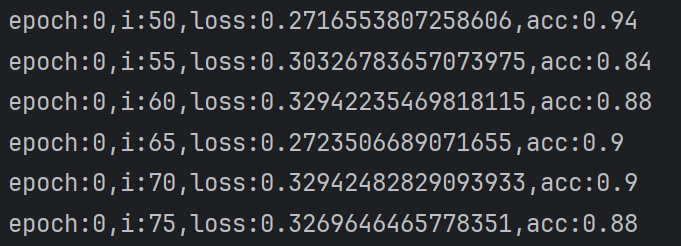
6.6 训练效果判断
acc在0.91左右就好,因为模型比较小
正在训练
7. 最终效果评估与测试
在模型训练完成后,需要评估其在测试集上的性能。通常使用准确率、精确率、召回率和 F1 分数等指标来衡量模型的效果。
7.1 准确率(Accuracy)
准确率是衡量分类模型整体性能的基本指标,计算公式为正确分类的样本数量除以总样本数量。
python
from sklearn.metrics import accuracy_score
# 假设有一个测试集 `test_dataset`,并且已经经过与训练集相同的预处理
test_loader = DataLoader(test_dataset, batch_size=16, shuffle=False)
# 评估模型在测试集上的性能
model.eval()
predictions, true_labels = [], []
with torch.no_grad():
for batch in test_loader:
outputs = model(input_ids=batch['input_ids'],
attention_mask=batch['attention_mask'])
_, preds = torch.max(outputs, dim=1)
predictions.extend(preds.cpu().numpy())
true_labels.extend(batch['labels'].cpu().numpy())
accuracy = accuracy_score(true_labels, predictions)
print(f"Accuracy: {accuracy:.4f}") 7.2 精确率、召回率和 F1 分数
精确率(Precision)和召回率(Recall)是分类模型的另两个重要指标,分别反映模型在正例预测上的精确性和召回能力。F1 分数是精确率和召回率的调和平均数,通常用于不均衡数据集的评估。
python
from sklearn.metrics import precision_score, recall_score, f1_score
precision = precision_score(true_labels, predictions, average='weighted')
recall = recall_score(true_labels, predictions, average='weighted')
f1 = f1_score(true_labels, predictions, average='weighted')
print(f"Precision: {precision:.4f}")
print(f"Recall: {recall:.4f}")
print(f"F1 Score: {f1:.4f}") 7.3 结果分析与模型优化
通过分析测试集上的结果,可以发现模型的强项和弱项。例如,如果 F1 分数较低,可能是由于数据集不平衡,导致模型在某些类别上表现不佳。通过调整超参数、改进数据预处理步骤,或使用更复杂的模型结构,可以进一步提高模型性能。
7.4 保存与加载模型
为了在未来使用训练好的模型,可以将其保存为文件,之后再加载进行推理或进一步的微调。
python
# 保存模型
torch.save(model.state_dict(), 'sentiment_analysis_model.pth')
# 加载模型
model = SentimentAnalysisModel()
model.load_state_dict(torch.load('sentiment_analysis_model.pth', model.eval())8. 完整代码
整体流程
第一步:准备数据。加载文本数据,用BERT分词器编码成模型可处理的数字格式(input_ids, attention_mask等),并打包成批次。
第二步:定义模型。加载预训练BERT模型,冻结其参数,然后添加一个全连接层(768维输入,2维输出)作为分类头。
第三步:配置训练环境。设置计算设备(GPU/CPU)、优化器(AdamW)、损失函数(交叉熵损失),并初始化跟踪最佳验证准确率的变量。
第四步:执行训练循环。
每个训练批次中:将数据输入模型,计算预测结果和损失,执行反向传播更新分类头参数。
每隔几个批次打印训练损失和准确率。
每个训练轮次(epoch)结束后,切换到评估模式,在整个验证集上计算损失和准确率。
第五步:保存模型 。根据验证集准确率保存性能最佳的模型参数(
best_bert.pth),并在每轮结束后也保存最新参数(last_bert.pth)。
train_val.py
python
#模型训练
import torch
from torch.optim import AdamW
from MyData import MyDataset
from torch.utils.data import DataLoader
from net import Model
from transformers import BertTokenizer
#定义设备信息
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#定义训练的轮次(将整个数据集训练完一次为一轮)
EPOCH = 30000
#加载字典和分词器
token = BertTokenizer.from_pretrained(r"F:\26_01\第六期\python\L2_study\L2\day04-基于BERT模型的自定义微调训练\demo_04\model\bert-base-chinese\models--bert-base-chinese\snapshots\c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f")
#将传入的字符串进行编码
def collate_fn(data):
sents = [i[0]for i in data]
label = [i[1] for i in data]
#编码
data = token.batch_encode_plus(
batch_text_or_text_pairs=sents,
# 当句子长度大于max_length(上限是model_max_length)时,截断
truncation=True,
max_length=512,
# 一律补0到max_length
padding="max_length",
# 可取值为tf,pt,np,默认为list
return_tensors="pt",
# 返回序列长度
return_length=True
)
input_ids = data["input_ids"]
attention_mask = data["attention_mask"]
token_type_ids = data["token_type_ids"]
label = torch.LongTensor(label)
return input_ids,attention_mask,token_type_ids,label
#创建数据集
train_dataset = MyDataset("train")
train_loader = DataLoader(
dataset=train_dataset,
#训练批次,根据gpu的内存抉择我的是4G
batch_size=50,
#打乱数据集
shuffle=True,
#舍弃最后一个批次的数据,防止形状出错
drop_last=True,
#对加载的数据进行编码
collate_fn=collate_fn
)
#创建验证数据集
val_dataset = MyDataset("validation")
val_loader = DataLoader(
dataset=val_dataset,
#训练批次
batch_size=40,
#打乱数据集
shuffle=True,
#舍弃最后一个批次的数据,防止形状出错
drop_last=True,
#对加载的数据进行编码
collate_fn=collate_fn
)
if __name__ == '__main__':
#开始训练
print(DEVICE)
model = Model().to(DEVICE)
#定义优化器
optimizer = AdamW(model.parameters())
#定义损失函数
loss_func = torch.nn.CrossEntropyLoss()
#初始化验证最佳准确率
best_val_acc = 0.0
for epoch in range(EPOCH):
for i,(input_ids,attention_mask,token_type_ids,label) in enumerate(train_loader):
#将数据放到DVEVICE上面
input_ids, attention_mask, token_type_ids, label = input_ids.to(DEVICE),attention_mask.to(DEVICE),token_type_ids.to(DEVICE),label.to(DEVICE)
#前向计算(将数据输入模型得到输出)
out = model(input_ids,attention_mask,token_type_ids)
#根据输出计算损失
loss = loss_func(out,label)
#根据误差优化参数
optimizer.zero_grad()
loss.backward()
optimizer.step()
#每隔5个批次输出训练信息
if i%5 ==0:
out = out.argmax(dim=1)
#计算训练精度
acc = (out==label).sum().item()/len(label)
print(f"epoch:{epoch},i:{i},loss:{loss.item()},acc:{acc}")
#验证模型(判断模型是否过拟合)
#设置为评估模型
model.eval()
#不需要模型参与训练
with torch.no_grad():
val_acc = 0.0
val_loss = 0.0
for i, (input_ids, attention_mask, token_type_ids, label) in enumerate(val_loader):
# 将数据放到DVEVICE上面
input_ids, attention_mask, token_type_ids, label = input_ids.to(DEVICE), attention_mask.to(
DEVICE), token_type_ids.to(DEVICE), label.to(DEVICE)
# 前向计算(将数据输入模型得到输出)
out = model(input_ids, attention_mask, token_type_ids)
# 根据输出计算损失
val_loss += loss_func(out, label)
#根据数据,计算验证精度
out = out.argmax(dim=1)
val_acc+=(out==label).sum().item()
val_loss/=len(val_loader)
val_acc/=len(val_loader)
print(f"验证集:loss:{val_loss},acc:{val_acc}")
# #每训练完一轮,保存一次参数
# torch.save(model.state_dict(),f"params/{epoch}_bert.pth")
# print(epoch,"参数保存成功!")
#根据验证准确率保存最优参数
if val_acc > best_val_acc:
best_val_acc = val_acc
torch.save(model.state_dict(),"params/best_bert.pth")
print(f"EPOCH:{epoch}:保存最优参数:acc{best_val_acc}")
#保存最后一轮参数
torch.save(model.state_dict(), "params/last_bert.pth")
print(f"EPOCH:{epoch}:最后一轮参数保存成功!")MyData
python
from torch.utils.data import Dataset
from datasets import load_from_disk
class MyDataset(Dataset):
#初始化数据集
def __init__(self,split):
#从磁盘加载数据
# self.dataset = load_from_disk( r"F:\26_01\第六期\python\L2_study\L2\day04-基于BERT模型的自定义微调训练\demo_04\model\bert-base-chinese\models--bert-base-chinese\snapshots")
# 修改 MyData.py 第 8 行
self.dataset = load_from_disk(
r"F:\26_01\第六期\python\L2_study\L2\day04-基于BERT模型的自定义微调训练\demo_04\data\ChnSentiCorp")
if split == "train":
self.dataset = self.dataset["train"]
elif split == "test":
self.dataset = self.dataset["test"]
elif split == "validation":
self.dataset = self.dataset["validation"]
else:
print("数据名错误!")
#返回数据集长度
def __len__(self):
return len(self.dataset)
#对每条数据单独做处理
def __getitem__(self, item):
text = self.dataset[item]["text"]
label = self.dataset[item]["label"]
return text,label
if __name__ == '__main__':
dataset = MyDataset("train")
for data in dataset:
print(data)net
python
import torch
from transformers import BertModel
#定义设备信息
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(DEVICE)
#加载预训练模型
pretrained = BertModel.from_pretrained(r"F:\26_01\第六期\python\L2_study\L2\day04-基于BERT模型的自定义微调训练\demo_04\model\bert-base-chinese\models--bert-base-chinese\snapshots\c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f").to(DEVICE)
print(pretrained)
#定义下游任务(增量模型)
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
#设计全连接网络,实现二分类任务
self.fc = torch.nn.Linear(768,2)
#使用模型处理数据(执行前向计算)
def forward(self,input_ids,attention_mask,token_type_ids):
#冻结Bert模型的参数,让其不参与训练
with torch.no_grad():
out = pretrained(input_ids=input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids)
#增量模型参与训练
out = self.fc(out.last_hidden_state[:,0])
return out