序列建模核心模型诞生核心诉求:逐个拆解「解决的核心问题」
以下按模型演进顺序 梳理,从基础RNN到前沿预训练模型,每个模型/模型组只聚焦最核心的待解痛点 (抛弃冗余细节,直击设计初衷),同时标注痛点来源(前序模型缺陷/场景新需求),让你一眼看懂每类模型的诞生意义:
基础循环类:解决「序列时序依赖」和「长距离记忆」核心问题
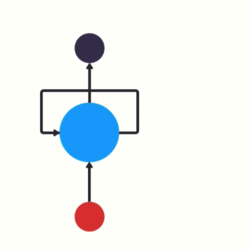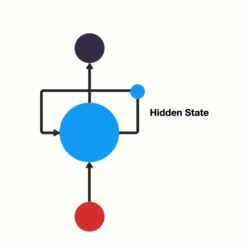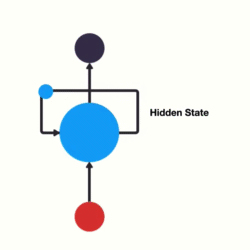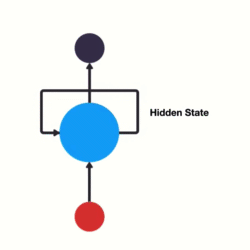
1. RNN(循环神经网络)
核心解决问题 :传统全连接/CNN模型处理序列数据时,完全忽略时序依赖 ,将有序的文本/语音/时序数据拆成独立样本,无法利用前文信息理解当前内容。
痛点来源:非序列建模模型的天然缺陷,无历史模型参考。
2. LSTM(长短期记忆网络)
核心解决问题 :RNN的长期依赖消失/梯度爆炸 问题,只能捕捉短序列的近邻依赖,长序列中早期信息会完全丢失,无法处理长文本、长语音等实际场景。
痛点来源:RNN反向传播时梯度随序列长度连乘,导致梯度趋近于0或无穷大。
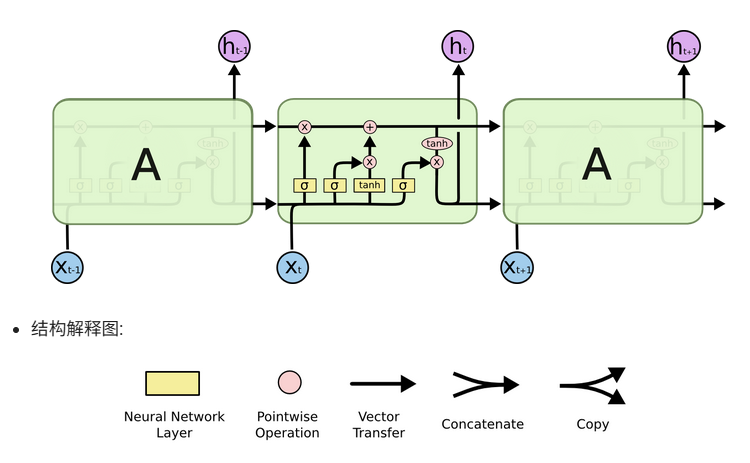
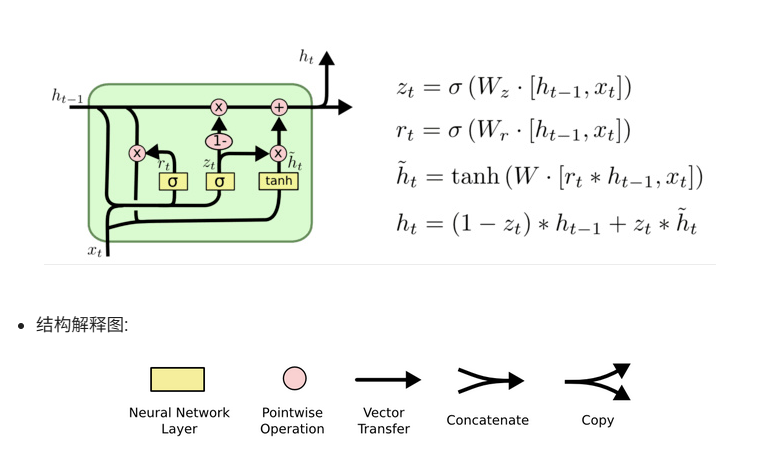
3. GRU(门控循环单元)
核心解决问题 :LSTM结构复杂、参数量大、计算效率低 ,训练和推理耗时,算力有限场景(如边缘设备)难以落地,且部分门控设计存在冗余。
痛点来源:LSTM的工程落地缺陷,3个门控+独立记忆单元导致参数冗余。
循环改进类:解决「基础循环模型的场景适配」问题
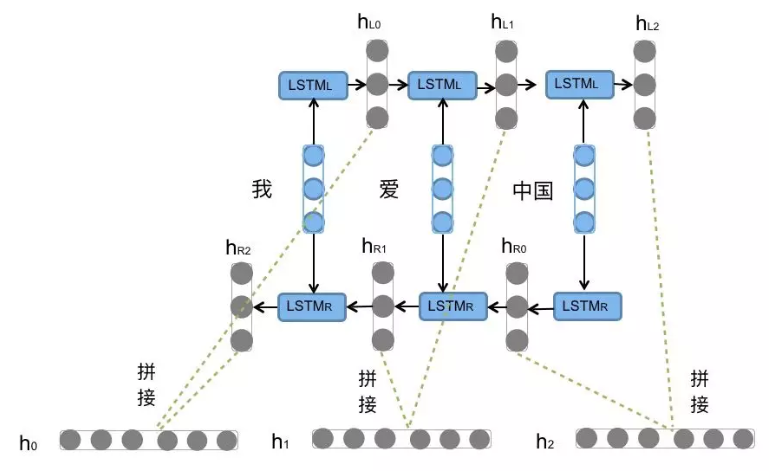
4. Bi-LSTM / Bi-GRU(双向LSTM/GRU)
核心解决问题 :基础LSTM/GRU仅能单向捕捉时序依赖 (从左到右/从前到后),无法利用后文/后序信息理解前文,比如理解语义、做命名实体识别时需要上下文双向信息。
痛点来源 :基础LSTM/GRU的单向设计缺陷,无法适配需要上下文双向依赖的NLP核心任务。
5. SRU(简单循环单元)
核心解决问题 :LSTM/GRU仍无法并行计算 ,且门控计算仍有冗余,进一步精简结构、提升计算效率 ,同时实现部分并行化 ,适配算力有限的边缘设备和流式数据场景。
痛点来源:LSTM/GRU的效率仍未满足轻量级、实时性场景的需求。
跨架构替代类:解决「循环模型的串行计算」核心缺陷
6. TCN(时间卷积网络)
核心解决问题 :RNN/LSTM/GRU全为串行计算 ,无法利用GPU并行算力,训练大批次序列数据时效率极低;同时纯CNN无法捕捉长时序依赖,TCN让CNN具备长距离时序建模能力。
痛点来源:循环模型的串行天然缺陷,以及纯CNN的时序建模短板。
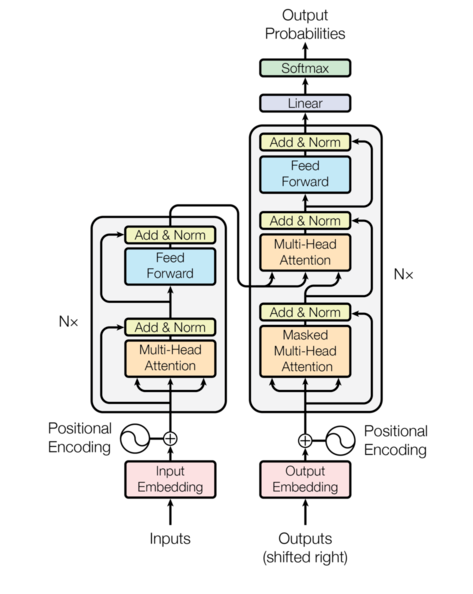
7. Transformer(自注意力核心架构)
核心解决问题 :彻底解决循环模型串行计算、长依赖捕捉能力有限 的核心痛点,通过自注意力机制 实现全序列并行计算 ,且能捕捉任意位置的全局依赖 (长序列中任意两个位置信息可直接交互)。
痛点来源:循环模型的底层架构缺陷,无法满足大规模、长序列的高效建模需求。
进阶优化类:解决「Transformer的短板」和「标注数据成本」问题
8. Transformer-XL
核心解决问题 :原版Transformer处理超长篇序列时,采用固定窗口截断 ,导致片段间依赖丢失 ,无法捕捉跨片段的长距离依赖,且存在重复计算问题。
痛点来源:原版Transformer的长序列处理缺陷,无法适配万级长度的超长篇文本/时序数据。
9. BERT(基于Transformer的预训练模型)
核心解决问题 :原版Transformer需要大量人工标注数据 才能训练,标注成本极高;通过海量无标注数据做预训练+小样本微调 ,大幅降低下游任务的标注成本,同时引入双向自注意力 ,提升语义理解能力。
痛点来源:原版Transformer的训练数据依赖缺陷,以及单向自注意力的语义理解短板。
一句话总结整体演进的核心逻辑
从RNN→LSTM→GRU→Bi-LSTM/SRU ,都是在循环架构内做优化 :先解决「能不能记长信息」,再解决「能不能算得快」,最后解决「能不能适配双向场景」;
从TCN→Transformer→Transformer-XL→BERT ,是跳出循环架构做颠覆:先解决「能不能并行计算」,再解决「能不能捕捉全局长依赖」,最后解决「能不能少标注数据、适配超长篇场景」。
所有模型的诞生,最终都围绕一个核心目标:让序列建模更高效、更能适配实际场景、更低成本。
序列建模核心模型 | 核心解决问题-适用场景 极简对比表
|----------------|-------------------------------------------------|-------------------------------------------|
| 模型/模型组 | 核心解决的核心问题 | 核心适用场景 |
| RNN | 传统全连接/CNN忽略序列时序依赖,无法利用前文信息处理当前内容 | 极短序列简单任务(现已基本淘汰,仅作理论基础) |
| LSTM | RNN的长期依赖消失/梯度爆炸,无法捕捉长序列的远距离信息 | 长序列建模、对记忆能力要求高的场景(如长文本理解、金融长时序预测) |
| GRU | LSTM结构复杂、参数多、计算效率低,工程落地算力成本高 | 绝大多数常规序列任务,追求效率与效果平衡(工业界主流循环模型) |
| Bi-LSTM/Bi-GRU | 基础LSTM/GRU仅能单向捕捉时序依赖,无法利用后文/后序的上下文信息 | NLP核心任务(命名实体识别、词性标注、文本分类)、语音识别 |
| SRU | LSTM/GRU仍串行计算、门控冗余,进一步精简结构+部分并行,提升极致效率 | 算力有限场景(边缘设备/嵌入式)、实时流式数据处理(实时语音/传感器数据) |
| TCN | 循环模型串行计算效率低,纯CNN无法捕捉长时序依赖,让CNN具备长距离时序建模能力 | 时间序列预测(气象/电力/金融)、视频帧分析,需并行计算的中长序列任务 |
| Transformer | 彻底解决循环模型串行计算+长依赖捕捉有限,实现全序列并行+全局依赖捕捉 | 所有大规模序列任务(大语言模型、机器翻译、文本生成),大模型核心基础架构 |
| Transformer-XL | 原版Transformer固定窗口截断,丢失跨片段长依赖,无法处理超长篇序列 | 万级长度超长篇序列(论文摘要、小说分析、超长时间序列预测) |
| BERT | 原版Transformer需大量人工标注数据,标注成本高;提升语义理解的双向注意力能力 | 所有NLP理解类任务(文本分类、相似度计算、问答系统),NLP工程化标配预训练模型 |