1.项目简介
本案例 ,通过skill赋予大模型摘要生成能力
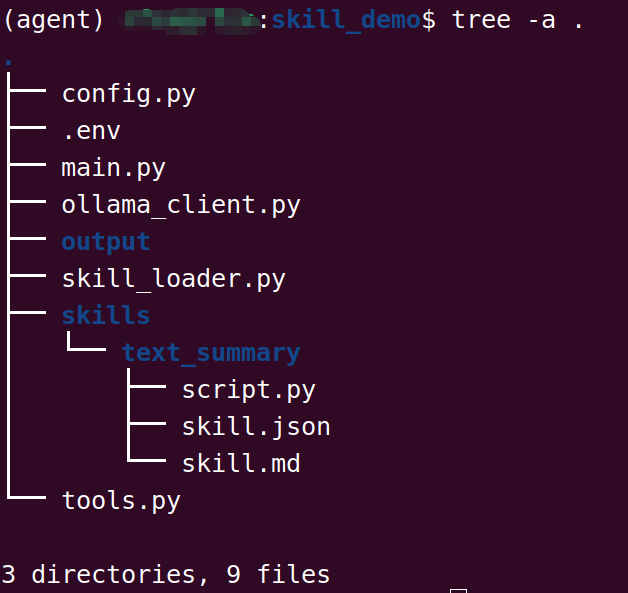
2.skill目录结构
3.项目实践
.env
bash
# Ollama 配置
OLLAMA_HOST=localhost
OLLAMA_PORT=11434
OLLAMA_MODEL=deepseek-r1:latest
# 项目配置
PROJECT_ROOT=./skill_demo
OUTPUT_DIR=./output/summaries
LOG_DIR=./logs
# 模型参数
MAX_TOKENS=4096
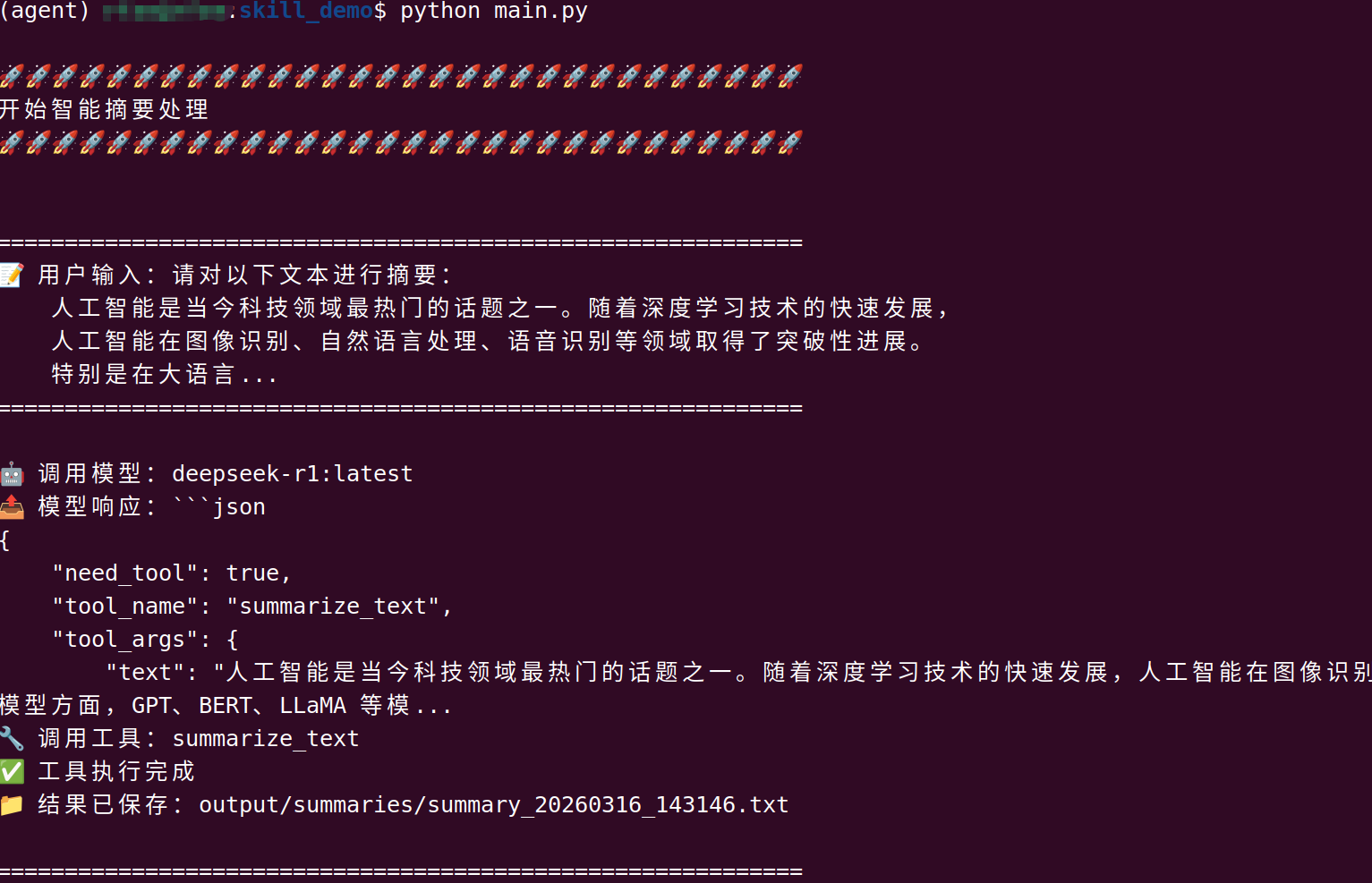
TEMPERATURE=0.7注释:本地运行ollama服务,查询效果如下

python
# -*- coding:utf-8 -*-
import json
import ollama
from datetime import datetime
from pathlib import Path
from config import config
from tools import ToolRegistry
from skill_loader import SkillLoader
class IntelligentSummarizer:
def __init__(self):
self.model = config.OLLAMA_MODEL
self.skill_loader = SkillLoader()
self.conversation_history = []
def _build_system_prompt(self):
tools_info = json.dumps(ToolRegistry.get_tools_schema(), ensure_ascii=False, indent=2)
skills_info = "\n".join([
f"- {skill['name']}: {skill['description']}"
for skill in self.skill_loader.list_skills()
])
return f"""你是一个智能摘要助手,运行在本地环境中。
## 可用工具
{tools_info}
## 可用技能
{skills_info}
## 决策规则
1. 分析用户输入,判断是否需要摘要
2. 如果需要摘要,自主决定调用 summarize_text 工具
3. 如果需要关键词,自主决定调用 extract_keywords 工具
4. 如果不需要工具,直接回答
## 输出格式
当需要调用工具时,返回 JSON 格式:
{{
"need_tool": true,
"tool_name": "工具名称",
"tool_args": {{ "参数": "值" }},
"reason": "调用原因"
}}
当不需要工具时,返回 JSON 格式:
{{
"need_tool": false,
"response": "直接回复内容"
}}
请始终以 JSON 格式回复。"""
def _parse_model_response(self, response):
try:
# 清理可能的 markdown 标记
response = response.strip()
if response.startswith("```json"):
response = response[7:]
if response.endswith("```"):
response = response[:-3]
return json.loads(response.strip())
except json.JSONDecodeError as e:
return {
"need_tool": False,
"response": f"解析响应失败:{str(e)}\n原始响应:{response}"
}
def _call_tool(self, tool_name, **kwargs):
print(f"🔧 调用工具:{tool_name}")
result = ToolRegistry.execute(tool_name, **kwargs)
print(f"✅ 工具执行完成")
return result
def _save_result(self, content, filename=None):
"""保存结果到文件"""
if filename is None:
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = f"summary_{timestamp}.txt"
output_path = config.OUTPUT_DIR / filename
with open(output_path, 'w', encoding='utf-8') as f:
f.write(content)
print(f"📁 结果已保存:{output_path}")
return output_path
def process(self, user_input, save_result=True):
print(f"\n{'='*60}")
print(f"📝 用户输入:{user_input[:100]}{'...' if len(user_input) > 100 else ''}")
print(f"{'='*60}\n")
# 构建消息
messages = [
{"role": "system", "content": self._build_system_prompt()},
{"role": "user", "content": user_input}
]
# 调用本地模型
print(f"🤖 调用模型:{self.model}")
response = ollama.chat(
model=self.model,
messages=messages,
options={
"temperature": config.TEMPERATURE,
"num_predict": config.MAX_TOKENS
}
)
model_response = response["message"]["content"]
print(f"📤 模型响应:{model_response[:200]}...")
# 解析响应
decision = self._parse_model_response(model_response)
# 执行决策
if decision.get("need_tool", False):
tool_name = decision.get("tool_name")
tool_args = decision.get("tool_args", {})
if tool_name:
tool_result = self._call_tool(tool_name, **tool_args)
# 生成最终回复
final_response = {
"tool_called": tool_name,
"tool_result": tool_result,
"user_input": user_input[:500]
}
if save_result:
self._save_result(json.dumps(final_response, ensure_ascii=False, indent=2))
return final_response
else:
final_response = {
"tool_called": None,
"response": decision.get("response", "无响应")
}
if save_result:
self._save_result(final_response["response"])
return final_response
def main():
"""主函数"""
summarizer = IntelligentSummarizer()
# 示例 1:长文本摘要
long_text = """
人工智能是当今科技领域最热门的话题之一。随着深度学习技术的快速发展,
人工智能在图像识别、自然语言处理、语音识别等领域取得了突破性进展。
特别是在大语言模型方面,GPT、BERT、LLaMA 等模型的出现,使得机器能够
更好地理解和生成人类语言。这些技术正在改变我们的工作方式、生活方式,
甚至思维方式。然而,人工智能的发展也带来了一些挑战,包括就业问题、
隐私保护、算法偏见等。我们需要在推动技术进步的同时,也要关注这些
社会问题,确保人工智能的发展能够造福全人类。未来,人工智能将与
各行各业深度融合,创造更多的价值和可能性。
""" * 3 # 重复以增加长度
print("\n" + "🚀" * 30)
print("开始智能摘要处理")
print("🚀" * 30 + "\n")
result = summarizer.process(
user_input=f"请对以下文本进行摘要:{long_text}",
save_result=True
)
print("\n" + "="*60)
print("📊 最终结果")
print("="*60)
print(json.dumps(result, ensure_ascii=False, indent=2))
if __name__ == "__main__":
main()ollama_client.py
python
import os
import json
import requests
class OllamaClient:
def __init__(self, host=None, model=None):
self.host = host or os.getenv("OLLAMA_HOST", "http://127.0.0.1:11434")
self.model = model or os.getenv("OLLAMA_MODEL", "deepseek-r1:latest")
self.timeout = 120
def chat(self, messages, tools=None, temperature=0.3):
url = f"{self.host}/api/chat"
payload = {
"model": self.model,
"messages": messages,
"stream": False,
"options": {"temperature": temperature}
}
if tools:
payload["tools"] = tools
try:
response = requests.post(url, json=payload, timeout=self.timeout)
response.raise_for_status()
data = response.json()
# 返回统一格式
return {
"message": data.get("message", {}),
"done": data.get("done", True)
}
except Exception as e:
return {"error": f"Ollama请求失败:{str(e)}"}
def check_health(self):
try:
r = requests.get(f"{self.host}/api/tags", timeout=5)
return r.status_code == 200
except:
return False
python
import os
from dotenv import load_dotenv
from pathlib import Path
load_dotenv()
class Config:
# Ollama 配置
OLLAMA_HOST = os.getenv("OLLAMA_HOST", "localhost")
OLLAMA_PORT = os.getenv("OLLAMA_PORT", "11434")
OLLAMA_MODEL = os.getenv("OLLAMA_MODEL", "deepseek-r1:latest")
OLLAMA_BASE_URL = f"http://{OLLAMA_HOST}:{OLLAMA_PORT}"
# 目录配置
PROJECT_ROOT = Path(os.getenv("PROJECT_ROOT", "./skill_demo"))
OUTPUT_DIR = Path(os.getenv("OUTPUT_DIR", "./output/summaries"))
LOG_DIR = Path(os.getenv("LOG_DIR", "./logs"))
# 模型参数
MAX_TOKENS = int(os.getenv("MAX_TOKENS", "4096"))
TEMPERATURE = float(os.getenv("TEMPERATURE", "0.7"))
@classmethod
def init_dirs(cls):
"""初始化必要目录"""
cls.OUTPUT_DIR.mkdir(parents=True, exist_ok=True)
cls.LOG_DIR.mkdir(parents=True, exist_ok=True)
config = Config()
Config.init_dirs()skill_loader.py
python
import json
import os
from pathlib import Path
from config import config
class SkillLoader:
def __init__(self, skills_dir = None):
self.skills_dir = skills_dir or config.PROJECT_ROOT / "skills"
self.skills = {}
self._load_all_skills()
def _load_all_skills(self):
"""加载所有可用的 Skills"""
if not self.skills_dir.exists():
return
for skill_dir in self.skills_dir.iterdir():
if skill_dir.is_dir():
skill_config = skill_dir / "skill.json"
if skill_config.exists():
self._load_skill(skill_dir, skill_config)
def _load_skill(self, skill_dir, config_file):
with open(config_file, 'r', encoding='utf-8') as f:
skill_data = json.load(f)
skill_name = skill_dir.name
self.skills[skill_name] = {
"name": skill_data.get("name", skill_name),
"description": skill_data.get("description", ""),
"version": skill_data.get("version", "1.0.0"),
"tools": skill_data.get("tools", []),
"script_path": skill_dir / "script.py",
"doc_path": skill_dir / "skill.md"
}
def get_skill(self, name):
return self.skills.get(name)
def list_skills(self):
return list(self.skills.values())
def get_available_tools(self):
tools = []
for skill in self.skills.values():
tools.extend(skill.get("tools", []))
return tools
python
import json
import requests
from config import config
class ToolRegistry:
_tools = {}
@classmethod
def register(cls, name, description):
def decorator(func):
cls._tools[name] = {
"name": name,
"description": description,
"function": func
}
return func
return decorator
@classmethod
def get_tools_schema(cls):
return [
{
"type": "function",
"function": {
"name": tool["name"],
"description": tool["description"],
"parameters": {
"type": "object",
"properties": {
"text": {
"type": "string",
"description": "需要处理的文本内容"
},
"max_length": {
"type": "integer",
"description": "摘要最大长度(字数)",
"default": 200
}
},
"required": ["text"]
}
}
}
for tool in cls._tools.values()
]
@classmethod
def execute(cls, name, **kwargs):
if name not in cls._tools:
raise ValueError(f"工具 {name} 未注册")
return cls._tools[name]["function"](**kwargs)
@ToolRegistry.register(
name="summarize_text",
description="对给定文本进行摘要提取,返回简洁的摘要内容"
)
def summarize_text(text, max_length = 200):
"""文本摘要工具"""
from skills.text_summary.script import TextSummarizer
summarizer = TextSummarizer()
result = summarizer.summarize(text, max_length)
return {
"success": True,
"summary": result["summary"],
"original_length": result["original_length"],
"summary_length": result["summary_length"],
"compression_rate": result["compression_rate"]
}
@ToolRegistry.register(
name="extract_keywords",
description="从文本中提取关键词"
)
def extract_keywords(text, top_k=5):
import re
from collections import Counter
words = re.findall(r'[\u4e00-\u9fa5a-zA-Z]+', text)
keywords = Counter(words).most_common(top_k)
return {
"success": True,
"keywords": [kw[0] for kw in keywords]
}skills/text_summary/script.py
python
import re
class TextSummarizer:
"""文本摘要处理器"""
def __init__(self):
self.min_sentence_length = 10
self.default_max_length = 200
def _split_sentences(self, text):
"""分割句子"""
# 中文句号、英文句号、感叹号、问号
separators = r'[。!?.!?]'
sentences = re.split(separators, text)
return [s.strip() for s in sentences if len(s.strip()) > self.min_sentence_length]
def _score_sentence(self, sentence, all_sentences):
"""句子重要性评分"""
score = 0
length = len(sentence)
if 20 <= length <= 100:
score += 2
if sentence in all_sentences[:3]:
score += 3
if sentence in all_sentences[-3:]:
score += 2
keywords = ['重要', '关键', '主要', '首先', '其次', '最后', '总结', '因此', '所以']
for kw in keywords:
if kw in sentence:
score += 1
return score
def summarize(self, text: str, max_length: int = None):
if max_length is None:
max_length = self.default_max_length
original_length = len(text)
if original_length <= max_length:
return {
"summary": text,
"original_length": original_length,
"summary_length": original_length,
"compression_rate": 1.0
}
sentences = self._split_sentences(text)
if not sentences:
return {
"summary": text[:max_length],
"original_length": original_length,
"summary_length": max_length,
"compression_rate": max_length / original_length
}
scored = [(s, self._score_sentence(s, sentences)) for s in sentences]
scored.sort(key=lambda x: x[1], reverse=True)
summary_sentences = []
current_length = 0
for sentence, score in scored:
if current_length + len(sentence) <= max_length:
summary_sentences.append(sentence)
current_length += len(sentence)
else:
break
summary_sentences = [
s for s in sentences
if s in summary_sentences
]
summary = '。'.join(summary_sentences)
if summary and not summary.endswith('。'):
summary += '。'
return {
"summary": summary,
"original_length": original_length,
"summary_length": len(summary),
"compression_rate": round(len(summary) / original_length, 2)
}skills/text_summary/skill.md
python
<pre># Text Summarizer Skill
## 功能描述
自动对输入文本进行智能摘要提取,支持中英文文本。
## 使用方式
模型会自动判断是否需要调用此技能:
- 当用户请求摘要/总结时
- 当输入文本超过一定长度时
## 输出格式
- 摘要内容
- 原文长度
- 摘要长度
- 压缩率
- 关键词
## 示例
输入:一篇长文章
输出:简洁的摘要 + 关键信息
</pre>skills/text_summary/skill.json
python
{
"name": "text_summarizer",
"description": "文本摘要提取技能,可自动识别长文本并生成简洁摘要",
"version": "1.0.0",
"author": "skill_demo",
"tools": [
"summarize_text",
"extract_keywords"
],
"triggers": [
"摘要",
"总结",
"概括",
"summarize",
"summary"
],
"auto_detect": true,
"min_text_length": 100
}运行效果: