前言(废话,不看也行哦)
其实我没有系统的, 抽出一大段时间, 就像学Web时一样完整的学习Redis, 都是通过项目, 像外卖项目中的菜品的缓存, 以及点评项目中优惠券的缓存查询抢购, 包括最近尝试着投简历遇到的一些问题, 来学习Redis的一些知识, 在这里来做一个总结.
目录
- 前言(废话,不看也行哦)
- Redis
-
- 📚Redis基本概念
-
- 🌟Redis的存储
- 🔍Redis常用命令(注:不区分大小写)
-
- [Redis 字符串类型常用命令:](#Redis 字符串类型常用命令:)
- [Redis 哈希操作命令:](#Redis 哈希操作命令:)
- [Redis 列表操作命令:](#Redis 列表操作命令:)
- Redis集合操作命令
- Redis有序集合操作命令
- Redis的通用命令:
- Java中操作Redis(入门)
-
- [1. 导入Maven坐标](#1. 导入Maven坐标)
- [2. 配置Redis数据源](#2. 配置Redis数据源)
- [3. 编写配置类](#3. 编写配置类)
- [4. 通过Redis Templet 操作对象操作Redis](#4. 通过Redis Templet 操作对象操作Redis)
- [Redis 常见面试题](#Redis 常见面试题)
-
- 1.Redis的使用场景
- [2. 什么是缓存穿透?怎么解决?](#2. 什么是缓存穿透?怎么解决?)
- 3.介绍一下布隆过滤器
- [4. 什么是缓存击穿?怎么解决?](#4. 什么是缓存击穿?怎么解决?)
- [5. 什么是缓存雪崩? 怎么解决?](#5. 什么是缓存雪崩? 怎么解决?)
- [redis做为缓存, MySQL的数据如何与redis进行同步呢?(双写一致性)](#redis做为缓存, MySQL的数据如何与redis进行同步呢?(双写一致性))
- [那这个排他锁是如何保证读写, 读读互斥的呢?](#那这个排他锁是如何保证读写, 读读互斥的呢?)
- 你听说过延时双删吗?
- [那你来介绍一下异步的方案( 你来介绍一下redisson读写锁的这种方案 )?](#那你来介绍一下异步的方案( 你来介绍一下redisson读写锁的这种方案 )?)
- 在Redis中提供了两种数据持久化是怎么做的?
- [假如redis的key过期之后, 会立即删除吗?](#假如redis的key过期之后, 会立即删除吗?)
- [假如缓存过多, 内存是有限的, 内存被占满怎么办?(redis的数据淘汰策略)](#假如缓存过多, 内存是有限的, 内存被占满怎么办?(redis的数据淘汰策略))
-
- Redis的数据淘汰策略有哪些?
- [数据库中有1000万条数据, Redis只能缓存20W数据, 如何保证Redis中的数据都是热点数据?](#数据库中有1000万条数据, Redis只能缓存20W数据, 如何保证Redis中的数据都是热点数据?)
- Redis的分布式锁怎么实现?
- 那如何控制Redis实现分布式锁有效时长?
- redission实现的分布式锁是可重入的吗?
- redission实现的分布式锁能解决主从一致性的问题吗?
Redis
📚Redis基本概念
Redis 是一个开源的、基于内存的数据结构存储系统,它可以用作数据库(这个和Mysql差不多,存储的信息少些)、缓存和消息中间件。(🙌可以把它理解成一个"超级快的临时记事本"。它把数据存在内存里,所以读写速度非常快,常用于做缓存、排行榜,验证码存储等需要快速访问的场景。)
🌟Redis的存储
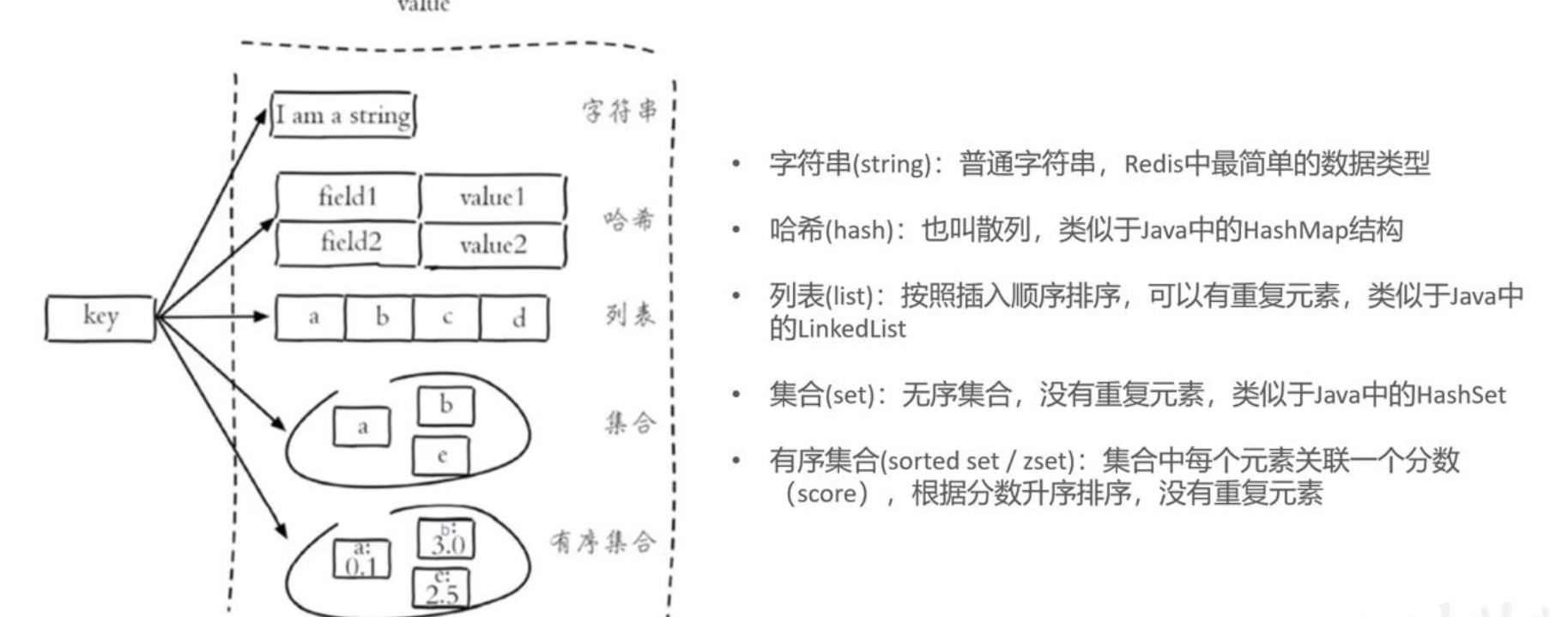
Redis存储是Key-value结构的数据,其中key是字符串类型,value有5中常用的数据类型:
- 字符串(String):就是普通字符串,(比如:用户登录后的 token、用户的昵称、访问次数(计数器)等)。
- 哈希(Hash):类似于对象,适合保存一个用户的多个信息(类似于Java中的HashMap结构,(比如:保存用户的信息(id、姓名、年龄等)在一个 key 里)。
- 列表(List):就是一个有序的字符串集合,可以在头尾添加/删除,(比如:消息队列、最近浏览记录)。
- 集合(Set):不重复的字符串集合,没有顺序,(抽奖活动中的唯一中奖用户、标签系统)。
- 有序集合(Sorted Set / ZSet):带分数排序的集合,可以按分数排名,(比如:游戏排行榜、热度榜单)。
我在黑马程序员讲义里截了张图,会更有助于理解这几种数据类型的存储结构
🔍Redis常用命令(注:不区分大小写)
Redis 字符串类型常用命令:
-
SET key value 设置指定key的值
-
Get Key 获取指定key的值
-
SETEX key seconds value 设置key的值,并把时间设置为seconds秒
-
SETNX key value key 不存在时设置key的值
Redis 哈希操作命令:
HASET key field value 将哈希表key 中的字段field的值设为value
HGET key field 获取存储在哈希表中指定字段的值
HDEL key field 删除存储在哈希表中指定字段
HKEYS key 获取哈希表中所有字段
HVALS key 获取哈希表中所有值
Redis 列表操作命令:
LPUSH key value1 value2 将一个或多个值插入到列表头部
LRANGE key start stop 获取列表指定范围内的元素
RPOP key 移除并获取列表最后一个元素
LLEN key 获取列表长度
Redis集合操作命令
SADD key member1 member2 向集合添加一个或者多个成员
SMENMBER key 返回集合中的所有成员
SCARD key 获取集合的成员数
SINTER key1 key2 返回给定所有集合的交集
SUNION key1 key2 返回所有给定集合的并集
SREM key member1 member2 删除集合中一个或多个成员
Redis有序集合操作命令
ZADD key score1 member1 score2 member2 向有序集合添加一个或多个成员
ZRANGE key start stop WITHSCORES 通过索引区间返回有序集合中指定区间内的成员
ZINCRBY key increment member 有序集合中对指定成员分数加上增量 increment
ZREM key member member ... 移除有序集合中的一个或多个成员
Redis的通用命令:
KEYS pattern 查找所有符合给定模式的key
EXISTS key 检查给定key 是否存在
TYPE key 返回key所储存的值的类型
DEL key 该命令用于在key存在时删除key
✨后面我们的项目都是用Java写的,通过一个Java测试类,来看这些语句转成Java中怎么配置使用的(功能都是一样的,都是将数据储存在Redis中):
Java中操作Redis(入门)
1. 导入Maven坐标
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>2. 配置Redis数据源
在application-dev.yml配置
xml
spring:
redis:
host: localhost
port: 6379
database: 0在application.yml中配置引用
java
redis:
host: ${sky.redis.host}
port: ${sky.redis.port}
password: ${sky.redis.password}
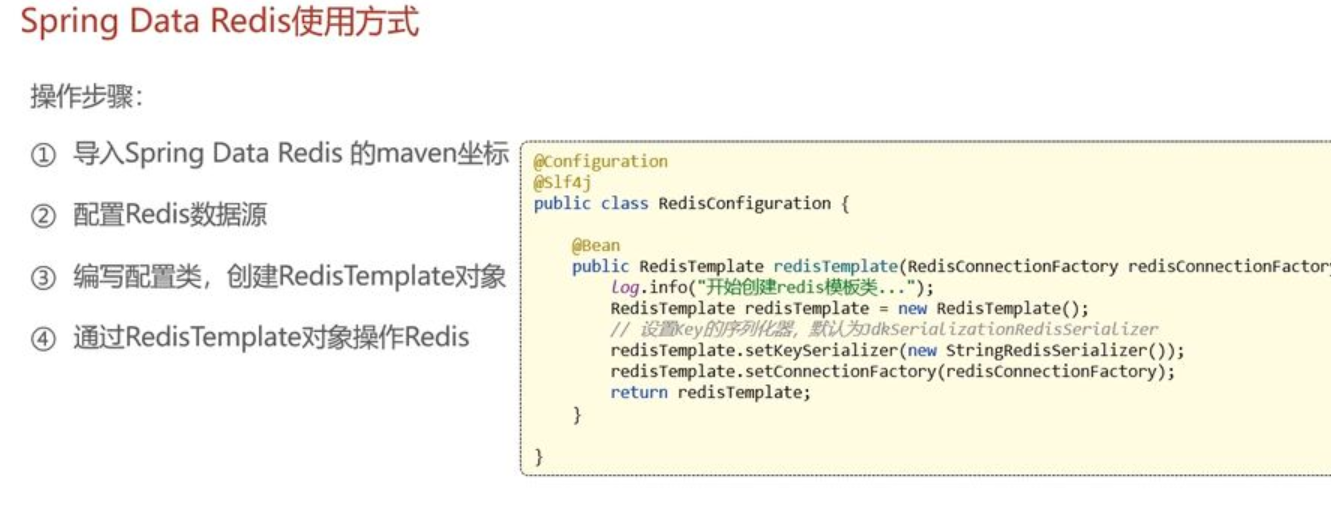
database: ${sky.redis.database}3. 编写配置类
config包下创建RedisConfiguration类
java
package com.sky.config;
import ...
@Configuration
@Slf4j
public class RedisConfiguration {
@Bean
public RedisTemplate redisTemplate(RedisConnectionFactory redisConnectionFactory){
log.info("开始创建RedisTemplate对象...");
RedisTemplate redisTemplate = new RedisTemplate();
//设置Redis连接工厂对象
redisTemplate.setConnectionFactory(redisConnectionFactory);
//设置Redis key的序列化器
redisTemplate.setKeySerializer(new StringRedisSerializer());
return redisTemplate;
}
}4. 通过Redis Templet 操作对象操作Redis
java
@SpringBootTest
public class SpringDataRedisTest {
@Autowired
private RedisTemplate redisTemplate;
@Test
public void testRedisTemplate() {
System.out.println(redisTemplate);
ValueOperations valueOperations = redisTemplate.opsForValue();
HashOperations hashOperations = redisTemplate.opsForHash();
ListOperations listOperations =redisTemplate.opsForList();
SetOperations setOperations = redisTemplate.opsForSet();
ZSetOperations zSetOperations = redisTemplate.opsForZSet();
}
/**
* 操作字符串类型的数据
*/
@Test
public void testString() {
// set get setex setnx
redisTemplate.opsForValue().set("city", "北京");
//Get Key 获取指定key的值
String city = (String) redisTemplate.opsForValue().get("city");
System.out.println(city);
//SETEX key seconds value 设置key的值,并把时间设置为seconds秒
redisTemplate.opsForValue().set("code", "1234", 3, TimeUnit.MINUTES);
//SETNX key value key 不存在时设置key的值
redisTemplate.opsForValue().setIfAbsent("lock", "1");
redisTemplate.opsForValue().setIfAbsent("lock", "2");
}
}将代码运行,通过Redis图形化界面,可以清楚的看到数据在Redis中的存储状态

哈希数据
java
@Test
public void testHash () {
HashOperations hashOperations = redisTemplate.opsForHash();
//HASET key field value 将哈希表key 中的字段field的值设为value
hashOperation.put("100", "name","hhhhh");
//HGET key field 获取存储在哈希表中指定字段的值
String name = (String)hashOperations.get("100","name");
System.out.prnntln(name);
//HKEYS key 获取哈希表中所有字段
Set keys = hashOperations.kets("100");
System.out.println("100");
// HVALS key 获取哈希表中所有值
List values = hashOperations.value("100");
System.out.printfln(values);
//HDEL key field 删除存储在哈希表中指定字段
hashOperations.delete("100", "name");
}列表类数据:
java
@Test
public void testList () {
ListOperations listOperations = redisTemplate.opsForList();
//LPUSH key value1 [value2] 将一个或多个值插入到列表头部
listOperations.leftPushAll("mylist","a","b","c");
listOperations.leftPush("mylist","d");
//LRANGE key start stop 获取列表指定范围内的元素
List mylist = listOperations.range("mylist",0m-1);
//RPOP key 移除并获取列表最后一个元素
listOperations.rightPop("mylist");
//LLEN key 获取列表长度
Long size = listOperations.size("mylist");
System.out.println(size);
}集合:
java
@Test
public void testList () {
SetOperations setOperations = redisTemplate.opsForSet();
//SADD key member1 [member2] 向集合添加一个或者多个成员
setOperations.add("set1","a","b","c","d");
setOPerations.add("set2","a","b","e","f");
//SMENMBER key 返回集合中的所有成员
Set members = setOperations.members("set1");
System.out.println(members);
//SCARD key 获取集合的成员数
Long size = setOperations.size("set1");
System.out.println(size);
//SINTER key1 [key2] 返回给定所有集合的交集
Set intersect = setOperations.intersect("set1","set2");
System.out.println(intersect);
//SUNION key1 [key2] 返回所有给定集合的并集
Set union = setOperations.union("set1","set2");
System.out.println(union);
//SREM key member1 [member2] 删除集合中一个或多个成员
setOperations.remove("set1","a","b");
}有序集合类:
java
@Test
public void testZset() {
ZSetOperations zSetOperations = redisTemplate.opsForZSet();
//ZADD key score1 member1 [score2 member2] 向有序集合添加一个或多个成员
zSetOperations.add("zset1","a",10);
zSetOperations.add("zset2","b",12);
zSetOperations.add("zset1","c",9);
//ZRANGE key start stop [WITHSCORES] 通过索引区间返回有序集合中指定区间内的成员
Set zset1 = zSetOperations.range("zset1",0,-1); //zrange
System.out.println(zset1);
//ZINCRBY key increment member 有序集合中对指定成员分数加上增量 increment
zSetOperations.incrementScore("zset1","c",10);
//ZREM key member [member ...] 移除有序集合中的一个或多个成员
zSetOperations.remove("zset1","a","b");
} Redis 常见面试题
先来通过一张图来总体看一下面试时,Redis常问什么?
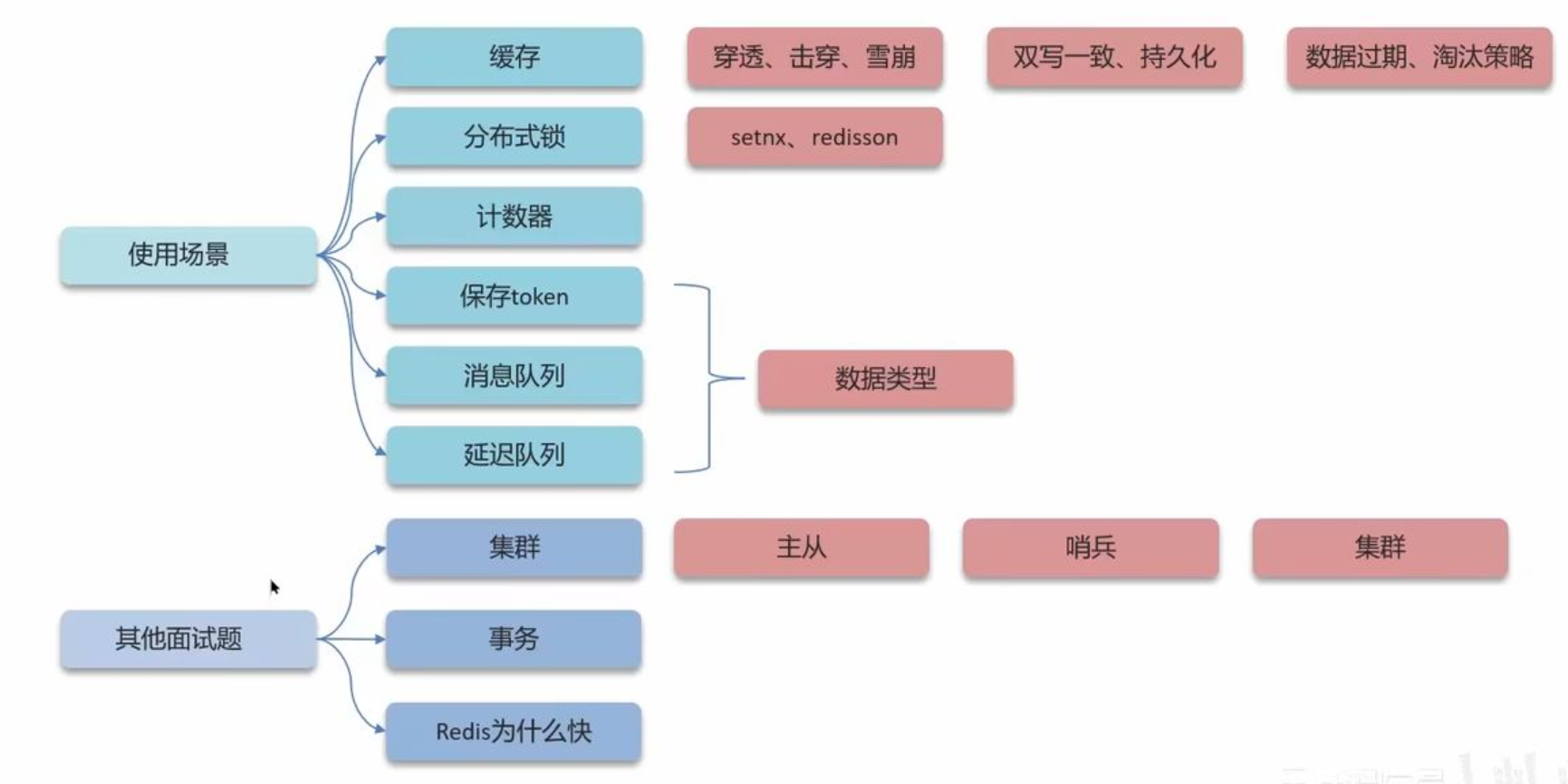
1.Redis的使用场景
- 这里一定要结合自己的项目来说
- 缓存: 穿透, 击穿, 雪崩, 双写一致, 持久化, 数据过期, 淘汰策略.
- 分布式锁 setnx, redisson
2. 什么是缓存穿透?怎么解决?
缓存穿透是指查询一个一定不存在 的数据, 如果从存储层查不到数据则不写入缓存, 这将导致这个不存在的数据每次请求都要到数据库去查询, 可能导致数据库挂掉, 这种情况大概率遭到了攻击.
通常通过缓存空数据 和布隆过滤器来解决.
3.介绍一下布隆过滤器
布隆过滤器主要是用于检索一个元素是否在一个集合中, 我们当时使用的是redission实现的布隆过滤器.
他的底层主要是先去初始化一个比较大的数组, 里面存放的二进制的0或1. 在一开始都是0, 当一个key来了之后经过3次hash计算,模于数组长度找到数据的下标然后把数组中原来的0改为1, 这样的话, 三个数组的位置就能标明一个key的存在. 查找过程也是一样的.
当然是有缺点的, 布隆过滤器有可能会产生一定的误判, 我们一般设置这个误判率,大概不会超过5%,其实这个误判率是必然存在的, 要不就是增加数组长度, 其实已经算是很划算了,5%以内的误判率一般项目也能接受, 不至于高并发下压倒数据库.
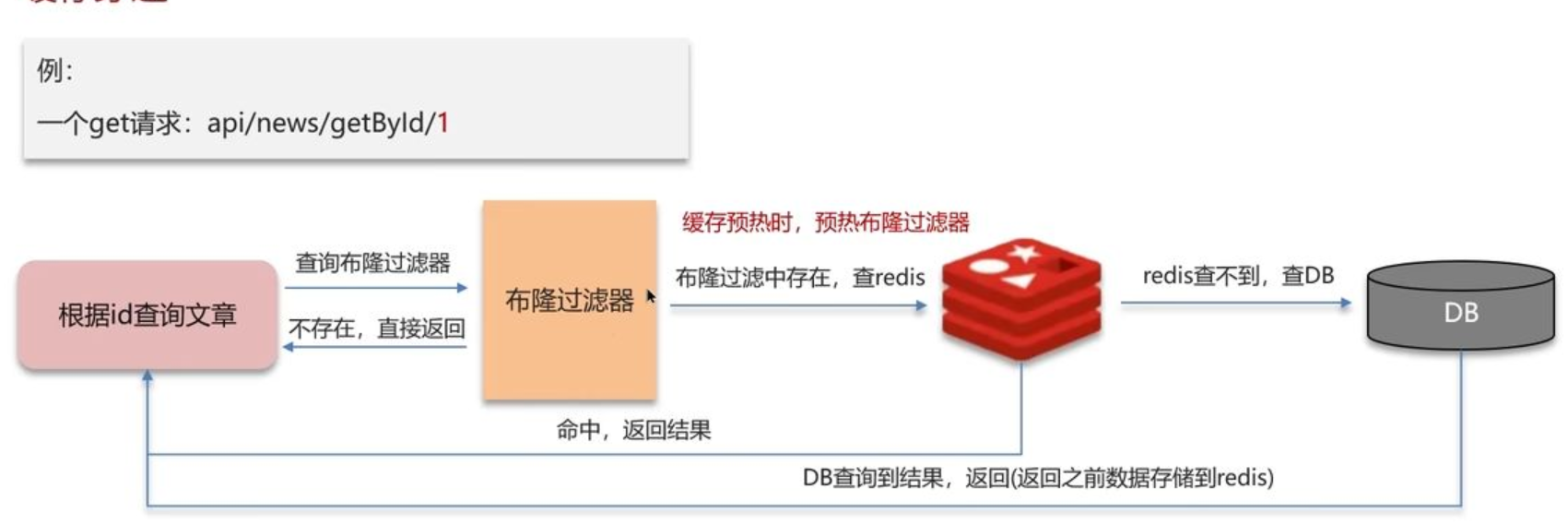

4. 什么是缓存击穿?怎么解决?
缓存击穿 是对于设置了过期时间的key , 缓存在某个时间点过期的时候, 恰好这个时间点对这个key有大量的并发请求过来, 这些请求发现缓存过期一般都会从后端数据库
- 解决方案一: 互斥锁, 强一致性, 性能差
当缓存失效时, 不立即去Load db, 先使用Redis的setnx去设置一个互斥锁, 当操作成功返回时再进行load db的操作并回设缓存, 否则重试get缓存的方法.
- 解决方案二: 逻辑过期, 高可用, 性能优, 不能保证数据绝对一致
- 在设置key的时候, 设置一个过期时间字段一块存入缓存中, 不给当前key设置过期时间
- 当查询的时候, 从redis取出数据后判断时间是否过期
- 如果过期则开通另外一个线程进行数据同步, 当前线程正常返回数据,这个数据不是最新的
当然两种方法各有利弊:
如果选择数据的强一致性,建议使用分布式锁, 性能上可能没那么高,锁需要等,也可能要产生死锁.
如果选择可以的逻辑删除, 则优先考虑高可用性,和性能, 但是数据同步不能保证
5. 什么是缓存雪崩? 怎么解决?
缓存雪崩是指在同一时间段大量的缓存key同时失效或者Redis服务宕机, 导致大量的请求到达数据库, 带来压力.
解决方案:
- 给不同的Key的TTL添加随机值
- 利用Redis集群提高服务的看可用性
- 给缓存业务添加降级限流策略
- 给业务添加多级缓存
redis做为缓存, MySQL的数据如何与redis进行同步呢?(双写一致性)
双写一致: 当修改了数据库的数据也要同时更新缓存的数据, 缓存和数据库的数据要保持一致
读操作: 缓存命中, 直接返回; 缓存未命中查询数据库, 写入换存, 设定超时时间
写操作: 延时双删
- 介绍自己简历上的业务, 我们当时是把文章的热点数据存入到了缓存中, 虽然是热点数据, 但是实时要求行没有那么高,所以, 我们当时采用的是异步的方案同步的数据
- 我们当时是把抢券的库存存入到了缓存中, 这个需要实时的进行数据同步, 为了保存数据的强一致, 我们当时采用的是redisson提供的读写锁来保证数据的同步.
例: 嗯! 就说我最近的项目, 里面有...的功能, 需要让数据库与redis高度保持一致, 因为要求时效性比较高, 我们当时采用的读写锁保证强一致性.
我们采用的是redisson实现的读写锁, 在读的时候填加共享锁, 可以保证读读不互斥, 读写互斥, 当我们更新数据时, 添加排他锁, 他是读写, 读读都互斥, 这就保证在写数据的同时是不会让其它线程读数据的, 避免脏数据, 这里面需要注意的是都方法和写方法上需要使用同一把锁.
那这个排他锁是如何保证读写, 读读互斥的呢?
其实怕他锁底层使用也是setnx, 保证了同时只能有一个线程操作锁方法 .
你听说过延时双删吗?
延时双删, 如果是写操作, 我们先把缓存中的数据删除, 然后更新数据库, 最后再延时删除缓存中的数据, 其中这个延时多久不好确定, 在延时的过程中, 可能会出现脏数据, 并不能保证强一致性, 所以并没有使用它.
那你来介绍一下异步的方案( 你来介绍一下redisson读写锁的这种方案 )?
- 允许延时一致的业务, 采用异步通知
- 使用MQ中间中间件, 更新数据之后, 通知缓存删除
- 利用canal中间件, 不需要修改业务代码, 伪装为MySQL的一个从节点, canal通过读取binlog数据更新缓存
- 强一致性的, 采用Redisson提供的读写锁
- 共享锁: 读锁readLock, 加锁之后, 其他线程可以共享读操作
- 排他锁: 独占锁writeLock也叫, 加锁之后, 阻塞其他线程读写操作
例: 嗯! 就说我最近的项目, 里面有...的功能,数据同步可以有一定的延时.
我们当时采用的阿里canal 组件实现数据同步, 不需要更改业务代码, 部署一个canal服务, canal服务把自己伪装成MySQL的一个从节点, 当MySQL数据更新以后, canal会读binlog数据, 然后再通过canal的客户端获取数据, 更新缓存即可.
在Redis中提供了两种数据持久化是怎么做的?
在Redis中提供了两种数据持久化的方式:
- RDB
RDB全程Redis Datebase file (Redis数据备份文件) , 也叫做Redis数据快照, 简单来说就是把内存中的所有数据都记录到磁盘上, 当Redis示例故障重启后, 从磁盘读取快照文件,恢复数据.
- AOF
假如redis的key过期之后, 会立即删除吗?
Redis对数据设置数据有效时间, 数据过期以后, 就需要将数据从内存中删掉. 可以按照不同的规则进行删除, 这种删除有两种:
-
惰性删除:
设置该key过期时间后, 我们不去管他, 当需要该key时, 我们在检查其是否过期, 如果过期, 我们就删除掉它, 反之返回改key
-
定期删除:
每隔一段时间, 我们就对一些key进行检查, 删除里面过期的key( 从一定数量的数据库中取一定数量的随机key进行检查, 并删除其中的过期key )
定期清理有两种模式:
- SLOW模式是定时任务, 执行频率默认为10hz, 每次不超过25ms, 已通过修改配置文件redis.conf的hz选项来调整这个次数
- FAST模式执行频率不固定, 每次事件循环会尝试执行, 但两次的间隔不低于2ms, 每次耗时不超过1ms
假如缓存过多, 内存是有限的, 内存被占满怎么办?(redis的数据淘汰策略)
Redis的数据淘汰策略有哪些?
嗯, 这个redis中提供了很多种, 默认是noeviction, 不删除任何数据, 内部不足直接报错是可以在Redis的配置文件中进行设置的, 里面有两个非常重要的概念, 一个是LRU, 另一个是LFU, LRU的意思是最少最近使用, 用当前时间减去最后一次访问时间, 这个值越大则越先淘汰.LFU的意思是最少频率使用. 会统计每个key的访问频率, 值越小淘汰优先级越高
我们在项目中使用的是alkeys-lru, 挑选最近最少使用的数据淘汰, 把一些经常访问的key留在redis中
数据库中有1000万条数据, Redis只能缓存20W数据, 如何保证Redis中的数据都是热点数据?
可以使用alkeys-lru( 挑选最近最少使用的数据淘汰 ) 淘汰策略, 那留下来的都是经常访问的热点数据
Redis的分布式锁怎么实现?
嗯, 在redis中提供了一个命令setnx(SET if not exists) 由于redis的单线程的, 用于命令之后, 只能有一个客户端对某一个key设置值, 在没有过期或删除key的时候是其他客户端是不能设置这个key的
那如何控制Redis实现分布式锁有效时长?
嗯,的确,redis的setnx指令不好控制这个问题, 我们当时的采用redis的一个框架rediission实现的.
在redission中需要手动加锁, 并且可以控制锁的失效失效和等待时间, 当锁住的一个业务还没有执行完成的时候, 在redission中引入了一个看门狗机制, 就是说每隔一段时间就检查当时业务是否还持有锁, 如果持有就增加加锁的持有时间, 当业务执行完成后需要使用释放锁就可以了.
还有一个好处就是, 在高并发下, 一个业务有可能会执行很快, 先客户1持有锁的时候, 客户2来了以后并不会马上拒绝, 它会自选不断尝试获取锁, 如果客户1释放之后,客户2就可以马上持有锁, 性能得到了提升
redission实现的分布式锁是可重入的吗?
嗯, 是可以重入的, 这样做是为了避免死锁的产生. 这个重入其实在内容就是判断是否是当前线程持有的锁, 如果是当前线程持有的锁就会计数, 如果释放锁就会在计算上减一. 在存储数据的时候采用的hash结构, 大key可以按照自己的业务进行定制, 其中小key是当前线程的唯一标识, value是当前线程重入的次数.
redission实现的分布式锁能解决主从一致性的问题吗?
这个是不能的, 比如, 当线程1加锁成功后, master节点数据会异步复制到slave节点, 当时当前持有Redis锁的master节点宕机, slave节点被提升为新的master节点, 假如现在来了一个线程2.
小白啊!!!写的不好轻喷啊🤯如果觉得写的不好,点个赞吧🤪(批评是我写作的动力)
。。。。。。。。。。。。。。
。。。。。。。。。。。。。。。