目录
[Redis + Caffeine多级缓存架构查数据的过程:](#Redis + Caffeine多级缓存架构查数据的过程:)
[为什么要用Redis + Caffeine 多级缓存架构?](#为什么要用Redis + Caffeine 多级缓存架构?)
[一、核心原因:单缓存方案的 "致命短板"](#一、核心原因:单缓存方案的 “致命短板”)
[只用 Caffeine(本地缓存)的痛点](#只用 Caffeine(本地缓存)的痛点)
[只用 Redis(分布式缓存)的痛点](#只用 Redis(分布式缓存)的痛点)
[二、多级缓存架构的 "核心价值"](#二、多级缓存架构的 “核心价值”)
[数据一致性:兼顾 "快" 和 "准"](#数据一致性:兼顾 “快” 和 “准”)
[4. 成本优化:资源利用更高效](#4. 成本优化:资源利用更高效)
[Caffeine 本地缓存配置类:](#Caffeine 本地缓存配置类:)
前言:
在高并发场景下,缓存是提升系统性能的核心手段,但单一缓存往往难以兼顾"速度"与"一致性"。Redis 作为分布式缓存的标杆,Caffeine 作为 JVM 本地缓存的性能王者,两者组合的多级缓存架构,已成为电商、直播等高频访问场景的最优解。本文将拆解这一架构的核心逻辑、落地方式,帮你快速掌握高并发系统的缓存优化技巧。
Redis + Caffeine多级缓存架构查数据的过程:
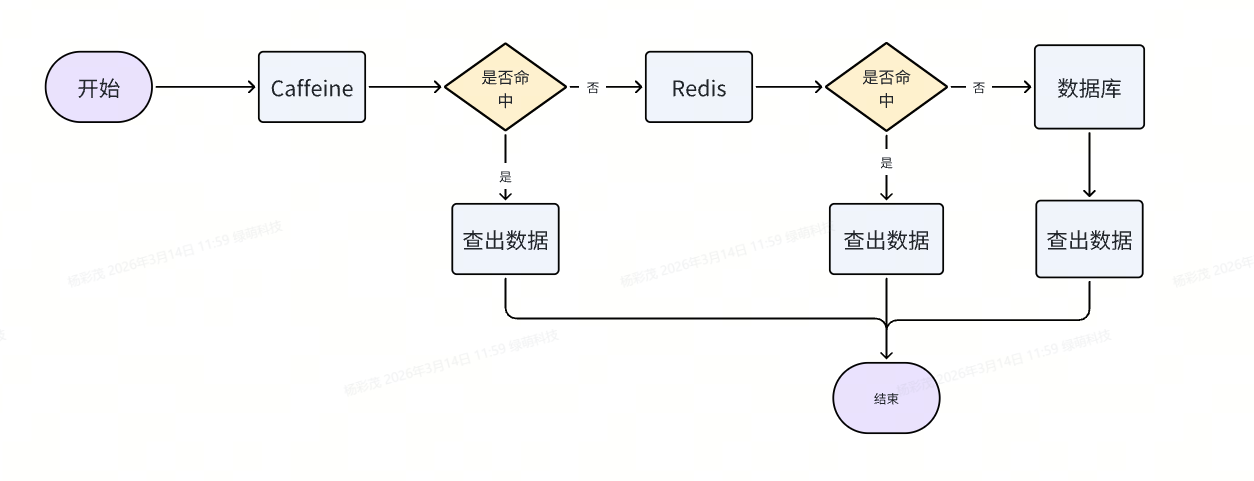
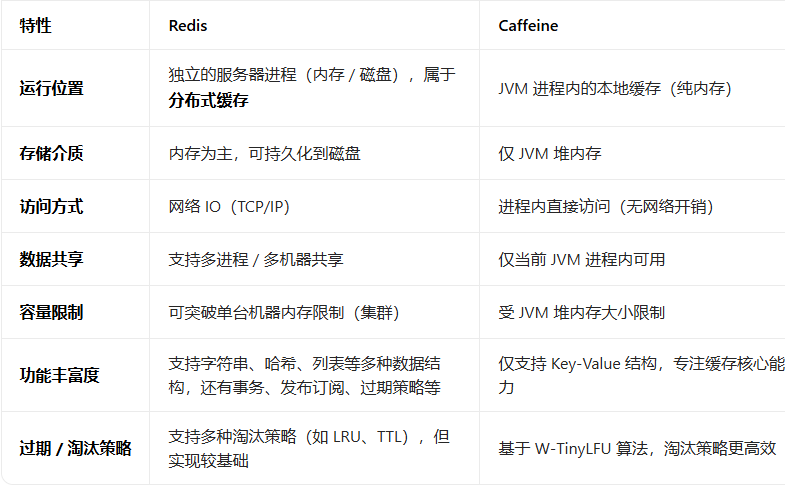
Redis与Caffeine的核心区别:
为什么要用Redis + Caffeine 多级缓存架构?
一、核心原因:单缓存方案的 "致命短板"
先看只用其中一种缓存的问题,就能理解多级缓存的必要性:
只用 Caffeine(本地缓存)的痛点
数据不一致:每个 JVM 实例都有独立的本地缓存,多服务节点间数据无法同步(比如 A 节点更新了数据,B 节点缓存还是旧的);
内存上限:受 JVM 堆内存限制,缓存数据量不能太大,否则会引发频繁 GC 甚至 OOM;
无持久化:JVM 进程重启后,本地缓存数据全部丢失,会导致 "缓存雪崩"(所有请求瞬间打到数据库)。
只用 Redis(分布式缓存)的痛点
性能瓶颈 :每次访问都要走网络 IO(TCP 连接、协议解析),即使是本地 Redis,单次操作也在毫秒级,高频访问场景下(比如每秒百万次请求),网络开销会被放大,成为性能瓶颈;
网络风险:Redis 节点故障、网络抖动会导致缓存不可用,直接影响业务;
资源浪费:把所有高频热点数据都放到 Redis,会增加 Redis 的压力(内存、CPU、网络),提升运维成本。
二、多级缓存架构的 "核心价值"
Redis + Caffeine 组合后,形成 "本地缓存(Caffeine)做第一层,分布式缓存(Redis)做第二层" 的架构,完美解决单缓存的问题,核心收益有 4 点:
极致的性能:降低时延,提升吞吐量
热点数据本地化 :把访问频率最高的 "热点数据"(比如占请求量 80% 的 20% 数据)放到 Caffeine 中,进程内直接访问,时延从 Redis 的毫秒级 降到微秒 / 纳秒级;
减轻 Redis 压力:Caffeine 拦截了大部分高频请求,Redis 只处理 "冷数据" 或 "首次请求",Redis 的 QPS 压力能降低 50% 以上,避免 Redis 成为瓶颈。
高可用性:容错能力更强
Redis 故障兜底:如果 Redis 集群宕机,Caffeine 中的热点数据还能正常提供服务,不会导致所有请求直接打到数据库,降低 "缓存击穿 / 雪崩" 的风险
Caffeine 失效不影响:单个 JVM 实例的 Caffeine 缓存失效(比如重启),只是该实例的请求会走到 Redis,整体业务不受影响。
数据一致性:兼顾 "快" 和 "准"
Redis 作为 "缓存唯一数据源":所有缓存的写入 / 更新 / 删除,都以 Redis 为准;
Caffeine 作为 "临时副本":Caffeine 只缓存 Redis 的数据副本,且设置较短的过期时间(比如 5 分钟),既保证了大部分请求的速度,又能通过 Redis 保证多节点的数据一致性。
4. 成本优化:资源利用更高效
本地缓存(Caffeine)使用 JVM 闲置内存,几乎无额外成本;
Redis 只需存储全量缓存数据,无需为 "热点数据" 过度扩容,降低 Redis 集群的硬件成本。
Caffeine 本地缓存配置类:
核心参数:
- 默认缓存最大数量
- 默认过期时间,单位秒
**Spring Cache 的具体实现 :**将 Caffeine 高性能本地缓存集成到 Spring 的缓存抽象中
CaffeineCache的特点:
|--------|---------------------------------|
| 本地内存缓存 | 数据存储在应用进程的内存中 |
| 有界缓存 | 可以设置最大容量和过期时 |
| 线程安全 | 底层使用 ConcurrentHashMap 和 CAS 操作 |
java
package com.rmcloud.common.caffeine;
import java.util.ArrayList;
import java.util.concurrent.TimeUnit;
import org.springframework.cache.CacheManager;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.cache.caffeine.CaffeineCache;
import org.springframework.cache.support.SimpleCacheManager;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import com.github.benmanes.caffeine.cache.Caffeine;
import lombok.AllArgsConstructor;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.extern.slf4j.Slf4j;
/**
* Caffeine缓存配置类
*/
@Configuration
@Slf4j
@EnableCaching
public class CaffeineCacheConfig {
// 默认缓存最大数量
private static final int DEFAULT_MAXSIZE = 100;
// 默认过期时间,单位秒
private static final int DEFAULT_TTL = 1800;
@Bean
public CacheManager createCacheManager() {
log.info("cache manager init...");
SimpleCacheManager cacheManager = new SimpleCacheManager();
ArrayList<CaffeineCache> caches = new ArrayList<>();
for (HadesInsightCache c : HadesInsightCache.values()) {
caches.add(new CaffeineCache(c.name(),
Caffeine.newBuilder().expireAfterWrite(c.getTtl(), TimeUnit.SECONDS).maximumSize(c.getMaxSize()).build()));
}
cacheManager.setCaches(caches);
return cacheManager;
}
@Getter
@AllArgsConstructor
@NoArgsConstructor
public enum HadesInsightCache {
// 将缓存的key值注册进来
// 第三方应用订阅事件缓存 key:eventId
COMPANY_APP_SUB_EVENT_CACHE_EVENT_ID(600, 10800),
// 第三方应用事件配置 key:appId
COMPANY_EVENT_CONFIG_APP_ID(600, 10800),
// 第三方应用订阅事件缓存 key:eventId+companyId
COMPANY_APP_SUB_EVENT_CACHE_EVENT_COMPANY_ID(600, 10800),
// 菜单权限表 key:companyId
SYS_MENU_COMPANY_ID(1000, 5),
// 事件 key:eventCode
EVENT_FOR_COMPANY_EVENT_CODE(100, 43200),
// 加工工艺缓存 key:id
PROCESS_TECHNOLOGY_CACHE_ID(600, 43200),
// 省份信息缓存 key:provinceCode
PROVINCE_DATA_CACHE_CODE(200, 259200),
// 市区信息缓存 key:cityCode
CITY_DATA_CACHE_CODE(500, 259200),
// 地区信息缓存 key:areaCode
AREA_DATA_CACHE_CODE(4000, 259200),
// 省市区信息缓存 key:unionCode
PCA_DATA_CACHE_CODE(4000, 259200),
// 国内省份信息缓存 key:DOMESTIC_PROVINCE_DATA
DOMESTIC_PROVINCE_DATA_CACHE(50, 259200),;
/**
* 最大数量
*/
private int maxSize = DEFAULT_MAXSIZE;
/**
* 过期时间,单位秒
*/
private int ttl = DEFAULT_TTL;
}
}结尾
综上,Redis + Caffeine 多级缓存架构的核心,是用 Caffeine 突破性能瓶颈、用 Redis 保障数据一致,既规避了单缓存的短板,又实现了性能、可用性与成本的平衡。对于高并发系统而言,这不仅是一种缓存方案,更是一套经过实践验证的性能优化思路,落地后能显著降低请求时延、减轻数据库与 Redis 压力,值得每一位后端开发者掌握与应用。