问题:先更新库还是先删缓存?
1、双写一致性,是 Redis 作为缓存时最核心的面试考点之一,本质是解决「MySQL 数据库」和「Redis 缓存」之间的数据同步问题,确保两者的数据始终匹配。
1)读操作:读操作时因为对redis和mysql都是没有影响的,所以这个动作本身不会导致出错; 数据不一致的根源一定是「写操作」的并发处理不当。
2)写操作:而因为写操作究其目的我们需要写缓存和数据库;而又不能直接更新于缓存上;而是删除缓存,然后其他线程发现缓存中没有数据的时候,在读数据库的时候同步更新给缓存。
2、这就导致了一个问题:
假设我们要把数据库和缓存中的数据10更新为20
1)先更数据库:如果线程1先更数据库,缓存还没被删除的时候,线程2就会读到缓存中的脏数据10;这就错误了! (而后线程1才重建缓存为20。)
初始状态:MySQL=10,Redis=10(要更新为20)
1. 线程1:更新MySQL为20(此时Redis还是10)
2. 线程2:读取Redis,直接拿到旧值10(脏数据)
3. 线程1:删除Redis缓存(但线程2已经拿到脏数据了)
4. 后续线程:读Redis空 → 读MySQL=20 → 写回Redis=20(但线程2已经出错)2)先删缓存:如果线程1先删除缓存,线程2发现缓存中没数据,就会去数据库中读到旧数据(10)并重建给缓存;这就错误了!(而后线程1才去将更新数据库为20并重建缓存)
初始状态:MySQL=10,Redis=10(要更新为20)
1. 线程1:删除Redis缓存(此时Redis空,MySQL还是10)
2. 线程2:读Redis空 → 读MySQL=10 → 写回Redis=10(脏数据)
3. 线程1:更新MySQL为20(此时Redis=10,MySQL=20,数据不一致)
4. 后续线程:读Redis=10(脏数据),直到缓存过期/被再次删除讨论:
1、写操作不能直接更新缓存(比如直接set key 20),原因是什么?
==》如果高并发下多个线程同时更新缓存,会出现 "覆盖问题"(比如线程 A 和 B 都要更 20,但 A 先更、B 后更,看似没问题;但如果是 "库存扣减" 这类累加操作,直接更缓存会导致库存计算错误)。
所以行业最佳实践是:写操作只更新数据库,然后删除缓存;后续读操作发现缓存空了,会自动从数据库读新值并写回缓存(这个过程叫「缓存重建」)。
2、总结:
无论是先删缓存还是先更新数据库,都会导致某个线程读到脏数据;本质是「读写操作的并发时序问题」。即 只要读和写是两个独立的操作,且没有加锁 / 限流等控制,就可能出现时序错乱。 这也是为什么我们需要「延迟双删、读写锁、MQ/Canal 异步」这些解决方案; 而接下来我就会为大家介绍这些个方案; 没有银弹,只看业务场景取舍(强一致用锁,最终一致用异步)。
解决方案
方案 1:延迟双删(解决基础并发问题)
这是最基础的优化方案,针对 "先删缓存→更数据库" 的缺陷做补充:
1、执行流程:
先删除 Redis 中对应的缓存 Key;
更新 MySQL 数据库的数据;
延迟一小段时间(比如 500ms),再次删除该缓存 Key;
2、核心原理:
延迟删除的目的是 "覆盖" 并发场景下,其他线程在步骤 1-2 之间写入的脏数据;
延迟时间要大于 "读请求从查库到写缓存" 的耗时(一般 500ms~1s 足够);
3、举例:
Redis = 10 MySQL = 10 目标:改成 20 执行
时序:
线程 1:删除 Redis 缓存 → Redis 空了
线程 2:查询缓存,没命中 → 去 MySQL 查旧值 10,并重建redis为10
线程 1:更新 MySQL 为 20
关键来了:线程 1:等待 500ms(保证线程 2 的逻辑已经全部执行完)
线程 1:再次 del Redis(key),
延迟是为了 "等脏缓存写完,我再一锅端删掉"。
优缺点:
✅ 实现简单,无额外组件依赖;
❌ 只能降低脏数据概率,无法 100% 保证强一致;适合「并发量不高、能接受短暂不一致」的场景。
方案 2:Redisson 读写锁(强一致性场景)
1、原理:Redisson 读写锁就是通过严格的锁机制,让读写操作互斥,从而从根源上保证缓存和数据库的强一致性。
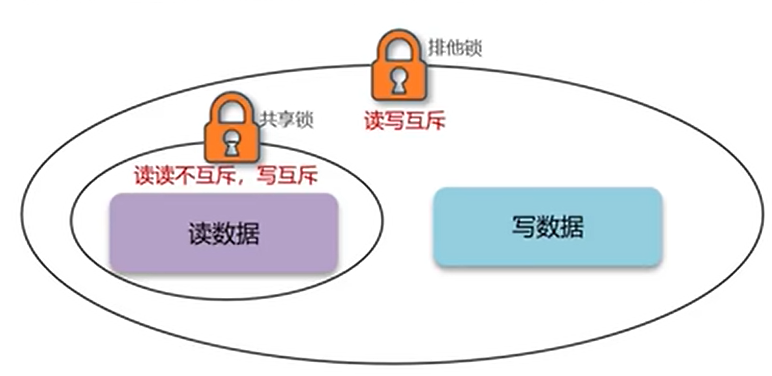
2、锁的介绍
利用 Redisson 的RReadWriteLock(读写锁),区分 "读操作" 和 "写操作",保证「读写互斥、写写互斥、读读共享」:
读锁(ReadLock):共享锁,多个线程可以同时加读锁查数据,不阻塞;
写锁(WriteLock):排他锁,加写锁后,阻塞所有读 / 写操作,直到写锁释放;
3、 读操作和写操作的过程
读操作:线程1要读数据的时候,需要获取读锁,从而完成缓存有,则读;缓存没有,则"读数据库并重建缓存"的整个操作;(读的时候不能写)
写操作:线程2要写数据的时候,需要获取写锁,从而完成"更新数据库,删除缓存"整个操作;
从而当我们要写数据前和写数据后,缓存和数据库永远都是一致的;
优点**:保证了数据的**强一致性,适合库存、交易金额等对数据准确性要求极高的场景。
缺点是:性能低(写锁会阻塞所有操作);有点为了强一致性而牺牲高并发的意味了 。适合「写少读多、一致性要求极高」的场景(比如库存、订单金额)。
java
// 读操作(查数据):加读锁,保证读的时候不会有写操作修改数据
public Item getItemById(Integer id) {
RReadWriteLock rwLock = redissonClient.getReadWriteLock("ITEM_LOCK_" + id);
RLock readLock = rwLock.readLock();
try {
readLock.lock(); // 加读锁
// 1. 先查缓存
Item item = redisTemplate.opsForValue().get("item:" + id);
if (item != null) return item;
// 2. 缓存空则查库,写回缓存
item = itemMapper.selectById(id);
redisTemplate.opsForValue().set("item:" + id, item, 30, TimeUnit.MINUTES);
return item;
} finally {
readLock.unlock(); // 释放读锁
}
}
// 写操作(改数据):加写锁,保证写的时候没有读操作查旧数据
public void updateItem(Item item) {
RReadWriteLock rwLock = redissonClient.getReadWriteLock("ITEM_LOCK_" + id);
RLock writeLock = rwLock.writeLock();
try {
writeLock.lock(); // 加写锁(阻塞所有读/写)
// 1. 更新数据库
itemMapper.updateById(item);
// 2. 删除缓存(避免脏数据)
redisTemplate.delete("item:" + item.getId());
} finally {
writeLock.unlock(); // 释放写锁
}
}
方案 3:异步通知(最终一致性场景)
如果业务能接受「短暂的数据不一致」(比如商品详情、文章内容),优先用这种高性能方案,核心是 "异步更新缓存":
子方案 3.1:基于 MQ 的异步通知
流程:更新数据库 → 发送 "缓存删除" 消息到 MQ → 消费 MQ 消息 → 删除 / 更新缓存;
核心:利用 MQ 的可靠性,保证缓存最终会被更新,业务代码无阻塞;
它的运行流程可以分为两大步骤:
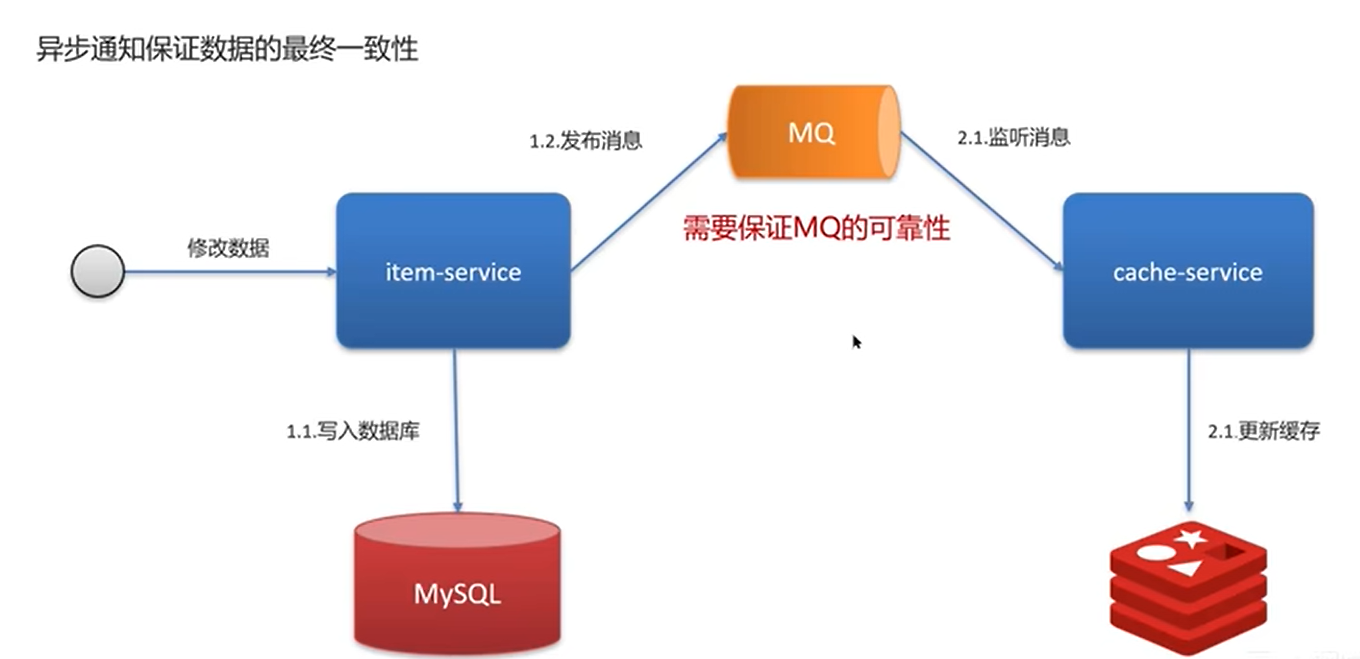
1、写数据时:业务服务(item-service)负责写库并发送消息
java
用户发起修改请求 → item-service 接收到请求
→ 1.1 先将数据写入 MySQL 数据库(确保数据持久化成功)
→ 1.2 向 MQ 发送一条「缓存更新/删除」的消息
→ 立即返回给用户"操作成功"关键特点:业务服务不直接操作缓存,发送消息后就立即返回,性能非常高,用户无感知延迟
2、异步更新缓存:缓存服务(cache-service)负责消费消息并更新缓存
bash
cache-service 持续监听 MQ
→ 2.1 一旦收到「缓存更新/删除」的消息
→ 2.2 执行缓存更新/删除操作(通常是删除缓存,让后续读请求自动重建)- 关键特点:缓存更新是异步、后台执行的,不影响主业务流程。
基于 MQ 的异步通知,就是用 "先保证数据库正确,再用 MQ 异步修正缓存" 的方式,换取了极致的性能和系统解耦,同时接受数据在短时间内的不一致,最终达到一致状态。
子方案 3.2:基于 Canal 的异步同步
一、原理:Canal 是一个基于 MySQL 主从同步机制开发的中间件,它的核心是伪装成 MySQL 的一个从节点,实时监听并解析 MySQL 的二进制日志(binlog),然后将数据变更事件发送给下游的缓存服务(如 Redis),从而实现数据库和缓存的异步同步,保证最终一致性。
二、它和 MQ 异步通知的核心区别是:
-
MQ 方案需要业务代码主动发送消息。
-
Canal 方案对业务代码完全无侵入,无需任何修改,通过监听数据库日志自动完成。
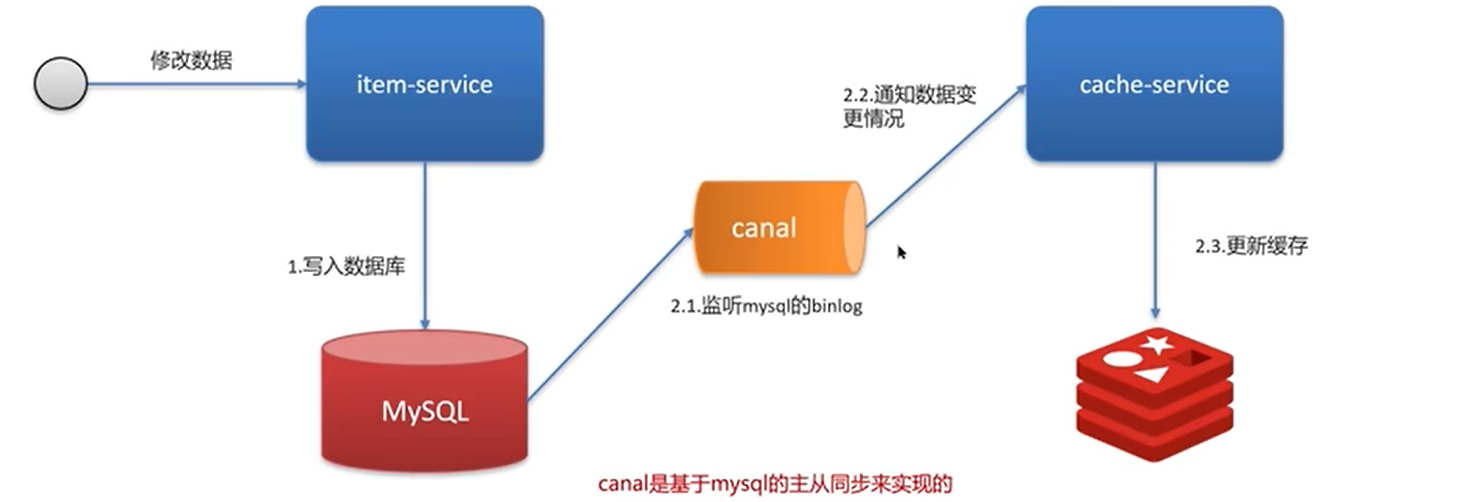
三、工作过程
-
业务系统正常写库
用户发起修改请求 → item-service 接收到请求
→ 1. 将数据写入 MySQL 数据库
MySQL 会把这次修改操作记录到自己的二进制日志(binlog)里。
-
Canal 监听并解析 binlog Canal
伪装成 MySQL 的从节点,持续向主节点发送 dump 请求
→ 实时监听并拉取 MySQL 的 binlog
→ 解析 binlog,提取出数据变更的具体内容(比如哪张表、哪个 ID、更新了什么值)
-
Canal 通知缓存服务更新
Canal 解析到数据变更后
→将变更事件发送给缓存服务(cache-service)
这里的 "发送" 可以是直接调用接口,也可以是通过 MQ 来解耦。 缓存服务收到通知后,就知道哪些数据需要更新了。 -
缓存服务更新
Redis cache-service 收到变更通知
→ 2.3 执行缓存更新/删除操作(通常是删除缓存,让后续读请求自动重建)
四、优缺点
优点: 对业务完全无侵入 可靠性极高:基于 MySQL 主从同步的协议,只要数据库的 binlog 不丢,Canal 就能保证数据不丢。
缺点: 部署复杂度高:需要额外部署和维护 Canal 服务,对运维能力有一定要求。 有一定延迟:从数据库变更到缓存更新,中间有解析和传输的时间,通常在毫秒级别。
Canal 非常适合大型、复杂、对业务代码无侵入性要求高的系统
讨论:
1、用户发起写请求,会先更新数据库,然后发送 MQ 消息 → 立即返回用户。缓存更新是在另一个线程 / 服务里异步完成的,主业务线程完全不阻塞。 这就区别于传统的更新数据库然后马上重建缓存; 用户发起读请求,先去查找缓存;使用mq不可避免的,可能缓存中查找到的是旧值(脏数据) 这正是 "最终一致性" 的含义:短暂不一致,但最终会一致。
2、mq异步通知解决方案和延迟双删相比有什么优势,延迟双删的缺点也是得让系统能接受短暂不一致才行,这个基于mq的异步通知也是啊,难道是并发性有区别?
===》
1、在高并发写场景下,MQ 方案的性能优势是碾压性的。
1)延迟双删:写操作的主业务线程需要等待两次删除缓存的操作(尤其是第二次延迟删除),这会增加写操作的响应时间,对高并发写场景不够友好。
2)MQ 异步通知:写操作的主业务线程只需要完成 "写库 + 发消息",这两步都是非常快的 IO 操作,几乎不增加延迟。缓存更新的开销完全转嫁到了异步线程,主业务的并发能力得到了极大提升。
2、系统解耦性
1)延迟双删:业务代码和缓存操作紧耦合,所有逻辑都在一个服务里完成。
2)MQ 异步通知:业务服务(item-service)和缓存服务(cache-service)通过 MQ 解耦,各自独立演化。比如,你可以单独扩容缓存服务,或者更换缓存技术,都不会影响业务服务。
拓展
最终一致性
最终一致性是分布式系统中的一个核心概念,它指的是: 不要求数据在任何时刻都完全一致,但会保证在经过一段短暂的时间后,所有副本的数据都会达到一致的状态。 简单来说,就是允许数据在短时间内存在不一致,但最终会被修正。 典型场景:商品详情页、文章内容、用户资料等。这些场景对数据实时性要求不高,用户能接受 "刷新一下就看到最新内容" 的体验。
总结:
1、双写一致性的核心是解决「Redis 缓存」和「MySQL 数据库」的数据同步问题,避免脏数据;
强一致性场景(库存 / 交易)用「Redisson 读写锁」,最终一致性场景(资讯 / 商品)用「MQ/Canal 异步通知」;
延迟双删是基础优化,能降低脏数据概率,但无法替代上述核心方案。
2、本文介绍了 Redis 作为缓存时双写一致性问题;讨论了写操作时是先更新库还是先删缓存的问题?(交代了行业最佳实践是:写操作只更新数据库,然后删除缓存而不直接于缓存上更新的原因)。并揭示了无论哪个原因都会让某个线程读到脏数据。从而提出了「延迟双删、读写锁、MQ/Canal 异步」这些解决方案;并交代了强一致性场景(库存 / 交易)用「Redisson 读写锁」,最终一致性场景(资讯 / 商品)用「MQ/Canal 异步通知」;