目录
[4.1知识补充 :](#4.1知识补充 :)
一、进程
进程 : 一个己经加载到内存中的程序/正在运行的程序,叫做进程
我们在windows下打开任务管理器,就可以看到当前我们的进程
也可以在Linux下查看进程
bash
[txf@VM-4-5-centos ~]$ ps axj显示系统中所有进程的详细信息 。
其中 a 代表所有与终端相关的进程,j 代表显示作业(Job)信息(包含父进程PID等),x 代表显示所有进程(包括无终端的进程)
小编写一个程序,运行一下
cpp
1 #include<stdio.h>
2 #include<unistd.h>
3 int main()
4 {
5 while(1)
6 {
7 printf("我是一个进程啦\n");
8 sleep(1);
9 }
10 return 0;
11 } 
ps ajx : 查看所有的进程
开机时,最主要的工作是将操作系统从外设加载到内存中(启动操作系统),进程也一样
操作系统是怎样管理进程的:
一个操作系统,不仅仅只能运行一个进程,可以同时运行多个进程 ,操作系统必须的将进程管理起来!如何管理进程呢?? - - - - - - - - - - - - - - - 先描述,再组织
进程是怎样被管理的:
任何一个进程,在加载到内存的时候,形成真正的进程时,操作系统,要先创建描述进程的结构体对象---PCB(process ctrl block) --------------进程控制块(进程属性的集合)
在操作系统当中,要描述进程,本质就是创建一个操作系统内定义的一个 struct 结构体类型,进程中应该有哪些属性呢?
- 进程编号
- 进程的状态
- 优先级
- ............
描述完后,根据进程的PCB类型,操作系统为该进程创建对应的PCB对象(描述进程的结构体对象),并且把属性做初始化,我们还要把该进程的代码和数据加载到内存中,操作系统创建进程时,不仅仅是把你的代码和数据加载到内存,他还要多做一件事情,叫做创建进程的PCB对象,PCB结构体,和该进程对应的代码和数据合起来才叫做进程,其中PCB是由操作系统内部自己维护的,代码和数据由我们对应的程序员自己写。当你要加载进程的时候,本质上不仅仅是把对应的代码和数据加载到内存。操作系统还根据进程控制块,为你当前的进程创建对应的PCB,填充该进程的相关属性、编号、状态和优先级值,初始化形成一个PCB,结构体对象、结构体变量由操作系统自己形成,所以什么叫做进程:
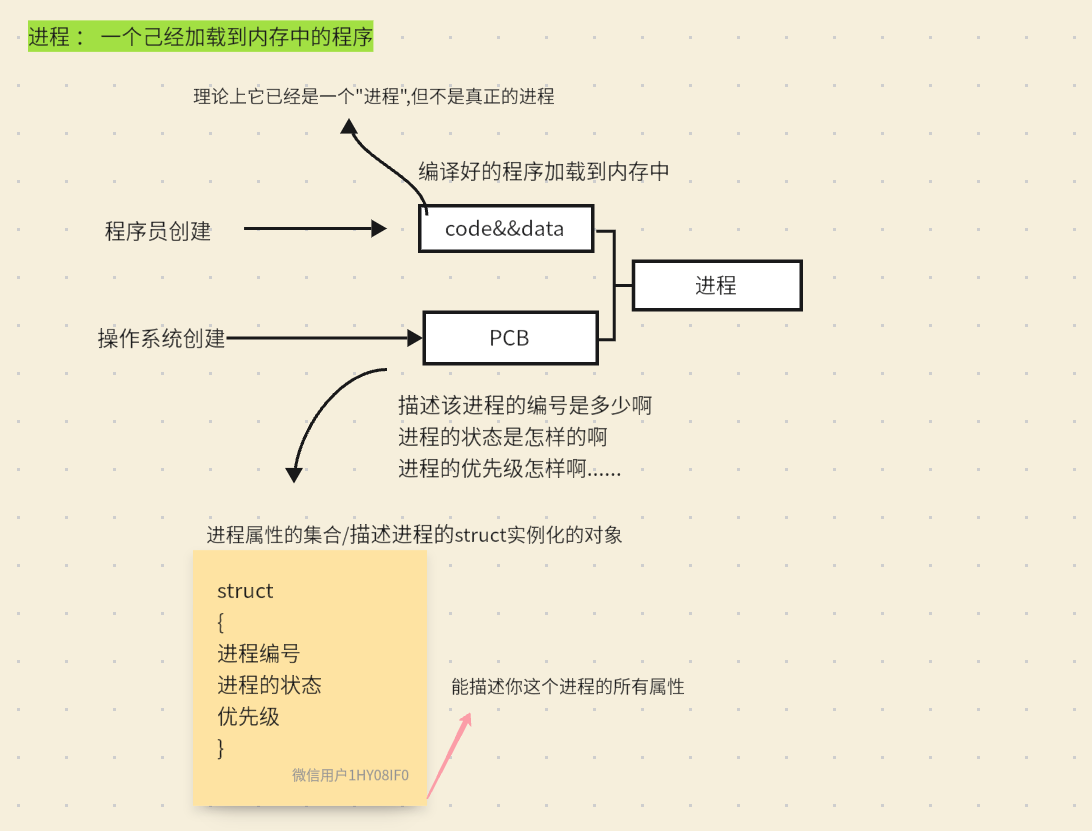
操作系统从此往后管理进程,根本不看你自己对应的代码和数据(code&&data) 。操作系统要管理,你只需要对PCB结构的对象做管理,操作系统能管理进程,所以所谓的对进程管理,本质是对内核PCB数据结构对象做管理。
那怎么对PCB做管理
PCB就是属性集合,里面包含描述进程的结构体。我可不可以在结构体里再加struct 比如struct PCB* next,加指针字段,将所有进程,我们只把PCB关联起来 ,在操作系统中,对进程进行管理,变成了对单链表进行增删查改
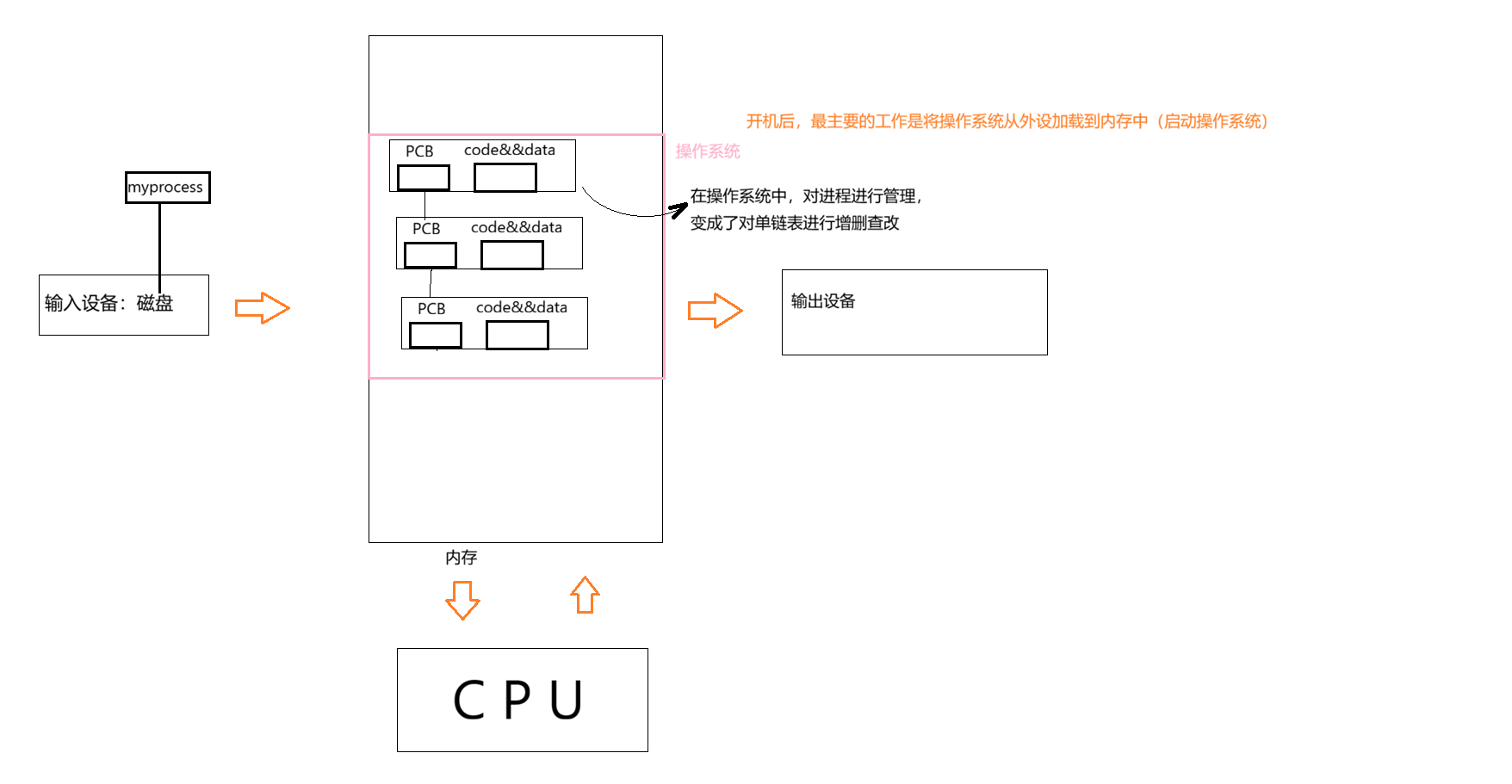
当我们问"进程在哪"时,其实它存在于两个层面:一个是它在内存里的家 (地址空间),另一个是操作系统用来管理它的小本本(内核数据结构)
它的"家":虚拟地址空间(内存大楼)
你可以把进程想象成一个租客 ,它住在操作系统分配的一栋虚拟大楼里。
- 位置 :这栋大楼在内存中(物理内存或磁盘交换区)。
- 布局 :这栋大楼里包含了我们刚才聊过的所有东西:
- 代码段(.text):存放你的程序代码(二进制指令)。
- 数据段(.data/.bss):存放全局变量。
- 堆(Heap):动态分配的内存。
- 栈(Stack):函数调用和局部变量。
- 共享库/命令行参数:等等。
它的"档案":内核中的数据结构(管理信息)
光有家还不够,操作系统需要知道这个进程的各种信息(比如它是谁、状态如何、分配了多少资源)。这些信息存放在内核空间(Kernel Space)。
- 位置 :内核空间(通常在内存的高地址区域,普通程序访问不到)。
- 核心结构 :
- PCB (进程控制块) :这是进程的"身份证"和"档案袋"。在 Linux 中,它具体表现为一个叫
task_struct的结构体。 - 进程地址空间 (mm_struct):这是描述那栋"虚拟大楼"布局的"设计图纸"。它记录了代码在哪、堆在哪、栈在哪。
- PCB (进程控制块) :这是进程的"身份证"和"档案袋"。在 Linux 中,它具体表现为一个叫
形象总结 :
如果把进程 比作一个正在办公的员工:
- 他在哪?
- 他的工位 (堆、栈、数据)在公司的大办公室(内存)里。
- 他的员工档案 (PID、状态、权限)在人事部(内核)的文件柜里。
- 他正在使用的电脑(CPU)上处理工作。
所以,进程既在内存里 (它的数据和代码),也在内核里 (它的管理和控制信息),同时还在CPU上(当它被调度执行时
二、Linux下的PCB
PCB是操作系统创建的
Linux操作系统具体PCB是什么样子?PCB是操作系统的概念,在Linux、Windows、macOS上,在手机上所有进程的控制块,我们都叫做PCB,在不同平台的PCB实现方案有差别。具体有哪些差别呢?
PCB,叫做进程的属性信息,被放在一个叫做进程控制块的结构体当中,可以理解为进程属性的结合。课本上把它叫做PCB,Linux操作系统中PCB,具体叫做task struct,是一个大型结构体,它里面包含了Linux内核中描述进程的所有属性,进程的属性非常多,这上面就是一个PCB。好同学们,其中关键的点是PCB和task struct 两者之间什么关系呢?task struct 是PCB的具体一种,在Windows中必须存在PCB ,macOS上也必须存在。Linux上具体的PCD叫做task struct,为什么叫task struct呢?因为我们把进程,也有的教材喜欢叫它任务,任务的英文叫做task,而struct叫做结构。所以Task struct就叫做任务结构体,用它描述进程的结构体,就叫做Linux中的PCB
taskstruct 作为 Linux操作系统内核的一种数据结构,会装载到内存中,并包含技术信息。下面我来说一下这句话,翻译过来就是Task strcut 是Linux内核中的一种数据类型。学C语言,我们平时用的int,那么double ,float就是内置类型,也就是C语言自带的。在C++当中,你自己定义的结构体,你定义的类,这些玩意儿最终都叫做类型啊,这种类型呢,我们一般称之为自定义类型。你平时在写代码时,你自己封装struct ,就是在定义自定义类型,也叫聚合类型。它里面包含你要描述的对象的所有属性,因为人认识世界是用属性来认识的,所以struct里面包含的所有属性表示具体的对象。这就叫做面向对象,我们前半部分说明它是一种内核的数据结构,其实就是操作系统内的数据类型。第二个是会被装载进信息的过程,根据task struct 来实例化进程对象,创建一个具体的PCB对象,最后再组织,那么所有进程的PCB对象组织起来,task叫做进程内部的所有属性,它内部有哪些常见属性呢?那么它内部的属性包含我们下面所罗列的,(进程的task结构体非常大):
- 状示符: 描述本进程的唯⼀标⽰符,用来区别其他进程。
- 状态: 任务状态,退出代码,退出信号等。
- 优先级: 相对于其他进程的优先级。
- 程序计数器: 程序中即将被执⾏的下⼀条指令的地址。
- 内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
- 上下⽂数据: 进程执⾏时处理器的寄存器中的数据休学例⼦,要加图CPU,寄存器。
- I∕O状态信息: 包括显⽰的I/O请求,分配给进程的I∕O设备和被进程使⽤的⽂件列表。
- 记账信息: 可能包括处理器时间总和,使⽤的时钟数总和,时间限制,记账号等。
- 其他信息:具体详细信息后续会介绍
在Linux内核中,最基本的组织进程task_struct 的方式,是采用双向链表组织的
实际上在操作系统内部一个PCB进程控制块里面,它除了把自己的PCB链到双链表里,还里面还有其他链式属性,同时可能会把自己放在一个队列里,或者其他节点当中,其他的数据结构中,PCB的task struct 就如我们当年学数据结构时,我们创建出来的列表节点一样,只不过这个链表节点可能既属于双链表,又属于二叉树中的某个节点,或者属于某个队列中的某个节点,这种做法并不难,无非在结构体属性的字段里。除了添加指针struct PCB* next,还可以添加对应的 struct PCB* queue,struct PCB* ...............等等 。可以添加更多指针字段,用这个指针来帮我们列入链表,用这个指针帮我们列入队列
Linux内核中的链表结构设计,和我们平常所学到的主结构设计,是有一点点差别的,我们对应对未来的所有task_struct进行管理,你的本质想做哪方面的管理,就是把PCB放到某某组织的数据结构当中。你想让进程在等待队列里等待,把PCB放到等待队列里。想让进程在运行队列里等待,把进程列入到PCB和运行队列就可以了。所以对进程的所有管理工作,取决于最终把它放在哪个数据结构中,因为数据结构背后是配套的算法,配套的算法背后是具体的应用场景
三、进程属性
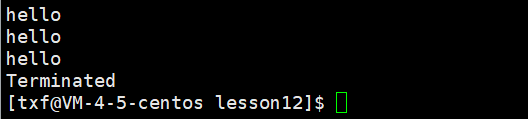
查看进程的相关常见属性 :ps ajx | head -1 && ps ajx | grep myprocess
ps的本质是在遍历双链表 ,然后在 task_struct 中拿出相关属性,然后可视化打应出来
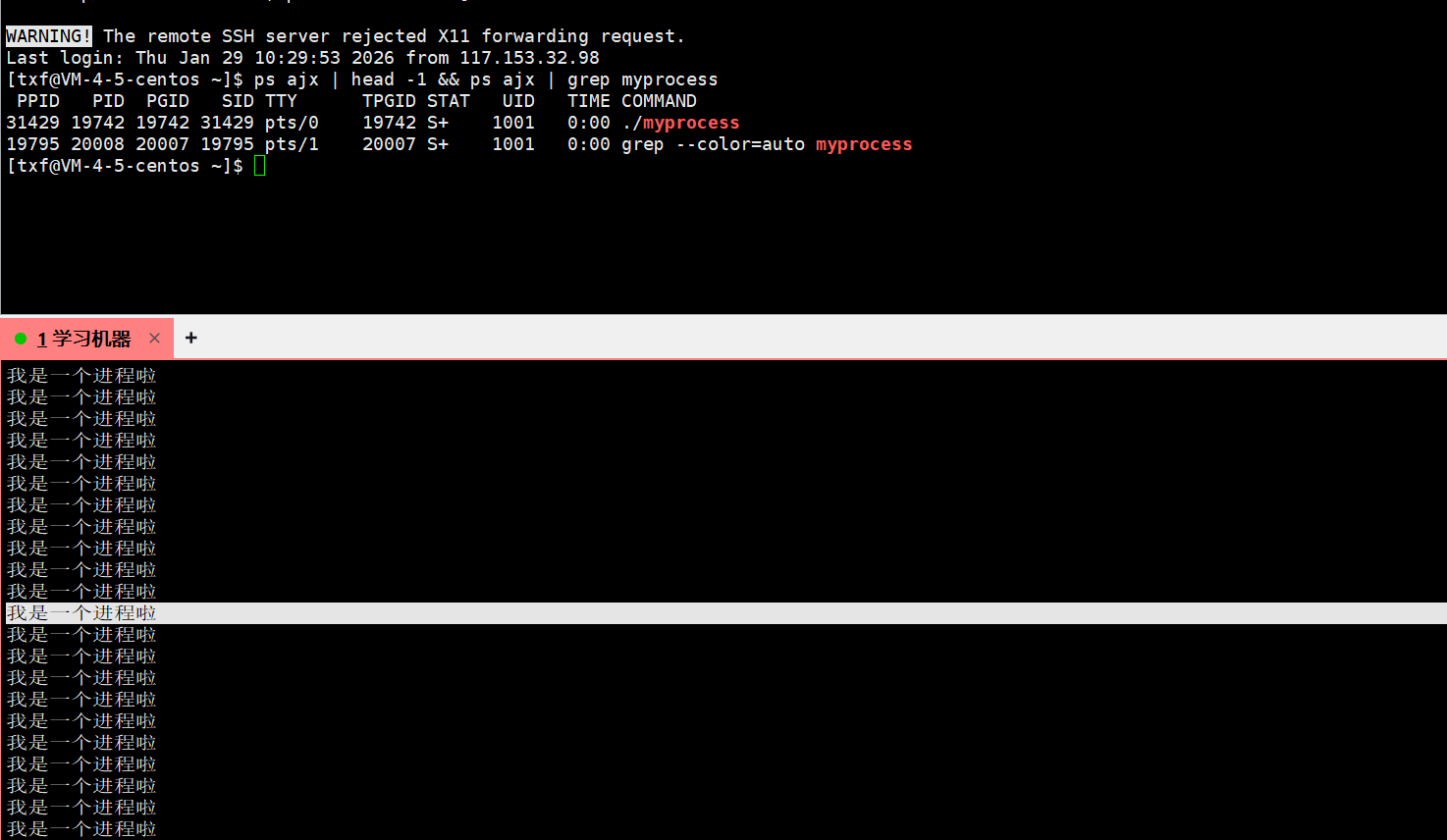
底下的程序一直再跑,
bash
[txf@VM-4-5-centos ~]$ ps ajx | head -1 && ps ajx | grep myprocess
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
31429 19742 19742 31429 pts/0 19742 S+ 1001 0:00 ./myprocess
19795 20008 20007 19795 pts/1 20007 S+ 1001 0:00 grep --color=auto myprocess
[txf@VM-4-5-centos ~]$ 这时候就有人要问了,此时不是就只有一个程序在跑吗?那么grep --color=auto myprocess是啥?
这个东西就是grep命令的进程,有人说怎么不见前面的呢,命令的关键字也有myprocess,所以当他在执行过滤系统的进程时:
首先它得把自己先变成进程。
然后自己才能被CPU调度,执行过滤代码。当他在过滤时,最终也会把自己带上 ,再说一遍,你现在通过这样的管道,把对应的程序跑起来,最后你是不是要跑grep命令?我们今天都知道了,平时运行LSPWD、PS、top所有指令都在Linux系统中,全部变成了进程,因为这些指令最终要被加载到内存,以进程方式运行,运行很快,完了直接被调度结束。而grep也是一个进程,用来进行关键词过滤,我们讲过,你要进行关键字过滤,前提条件是得先跑起来,所以你把自己跑起来,再执行代码进行关键字过滤,你就变成进程,很尴尬的是你自己的关键字里本来就有myprocess,所以在整个过滤系统中所有进程的时候,你把自己也带上了
还有一种冷门方式查看进程:
bash
[txf@VM-4-5-centos ~]$ ls /proc:查看我们当前的所有进程

这个process/proc目录其实是Linux文件系统当中比较奇怪的,比较重要的一个目录结构,在你关机之后,上面的所有数据就全没了,开机的时候,操作系统会自动创建对应的目录或文件,因为这上面的所有信息是Linux操作系统用文件系统的方式。那么把内存中的文件,包括进程信息,给我们可视化出来了,它上面的数据都是内存级的
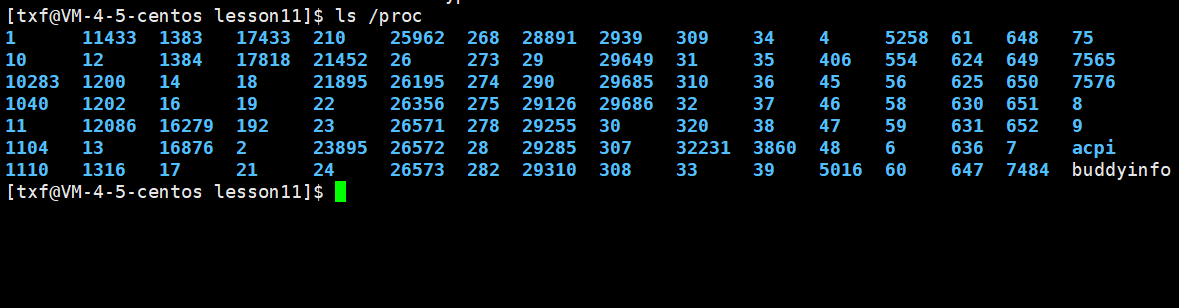
以上这些蓝色的都是目录 ,而第一行的数字都是它们的PID
(每个进程在系统运行期间终止了,重新启动后,操作系统分配的PID标识符大概率会变化,几乎不会出现上一次是什么PID的情况)
在系统中启动的所有进程默认在PROC目录里面,会在PROC目录创建一个以该进程PD命名的文件夹或目录,它这个目录保存了该进程的大部分属性
我们可以通过PID查找到一个进程相关的属性 :ls /proc/ PID

在这些属性中 exe : 我们代码和数据的指针
lrwxrwxrwx 1 txf txf 0 Jan 29 22:10 exe -> /home/txf/Linux_test/lesson11/myprocess把我们的指针字段给我们,
把我们对应的PCB中的内存指针指向自己,将程序信息可视化出来
(ps : 相当于
- 内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针)
cwd : 记录当前路径(在当前进程启动的目录)
pgrep : 查找进程的PID : " pgrep + 进程名称 "

kill 指令 : 命令是 Linux 和 Unix 系统中用于终止进程的工具。简单来说,它的作用就是告诉某个正在运行的程序:"请停止运行"。
bash
kill [信号选项] PID
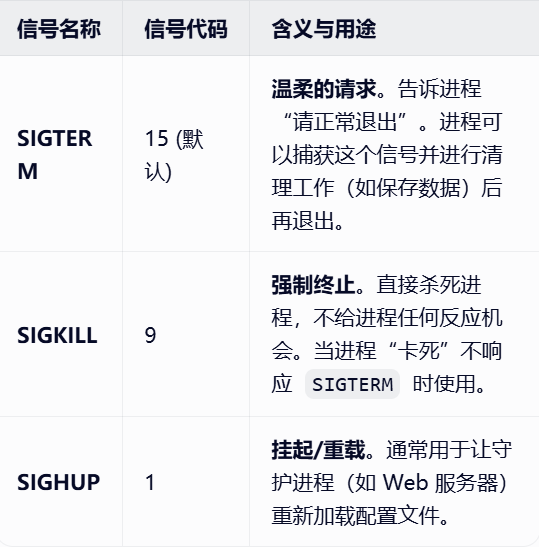
为什么有时候要加 -9?
- 不加 -9 (
kill PID):相当于礼貌地敲门说:"先生,请出门。" 进程如果还在忙(比如正在写文件),它可能会等忙完再走,或者根本听不见(无响应)。 - 加 -9 (
kill -9 PID):相当于直接把进程从窗户扔出去。它会立即死亡,但可能导致数据丢失(比如文件没保存完)。
ps ajx 的本质是在遍历双链表 ,然后在 task_struct 中拿出相关属性,然后可视化打应出来
而拿出相关属性只能是通过系统调用接口来拿属性,所以肯定有一个系统调用接口是来提供属性,
所以想得到PID 操作系统会有一个接口 getpid() : 获取我自己的PID
四、自己创建进程
在命令行解释器中输入命令或者执行程序,这些都由Bash来为它们创建进程,也就是说它们的父进程都是Bash,而它们都是Bash的子进程
如 : [txf@VM-4-5-centos lesson12] $ 是 Bash 显示给你的提示信息 ,专业术语叫 PS1 (Prompt String 1)。
你可以把它理解为:Bash 正在拿着一个话筒(光标)问你:"你想让我做什么?"
虽然你看不到它,但它正在后台运行。
- 当你打开终端时 :操作系统会创建一个终端进程,然后终端进程会启动 Bash 这个程序。
- Bash 的工作状态 :它会先显示上面那行提示符
[txf@VM-4-5-centos lesson12] $,然后停下来,等待你输入命令。 - 当你输入命令后 :Bash 会读取你输入的内容,进行解释和执行(比如创建子进程去运行
ls),执行完后再显示一遍提示符,等待下一次输入。
- Bash 是那个看不见的"大脑"(命令解释器)。
[txf@VM-4-5-centos lesson12] $是 Bash 给你显示的**"对话框"**。
++(当然Bash是终端的子进程)++
虽然 Bash 是终端的子进程,但它们在功能上是紧密协作的:
- 终端(Terminal) :它负责提供**"窗口"**(界面)。它管理着屏幕的显示、键盘的输入。它就像一个"电话线路"或"信使"。
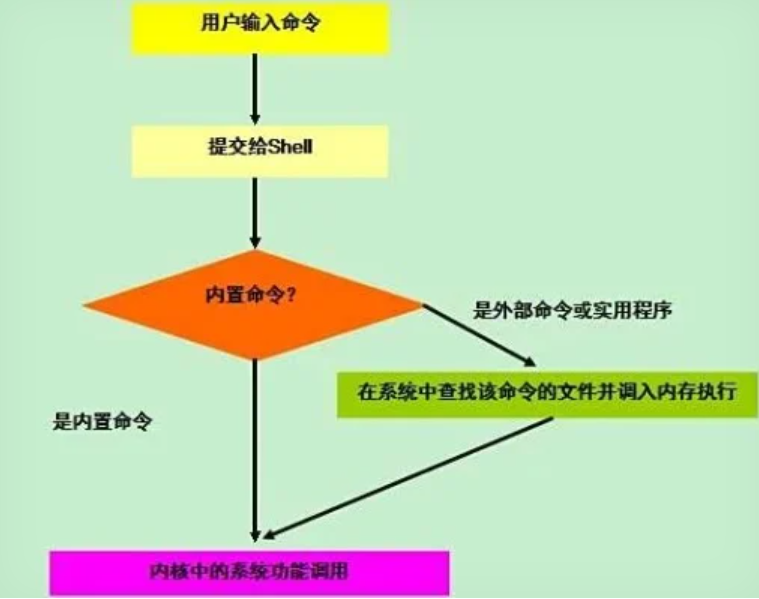
- Bash(Shell) :它负责**"思考"** (逻辑)。它接收通过终端传来的键盘输入,解析命令(比如
ls -l),然后决定是自己直接执行(内置命令),还是再创建一个新的子进程
4.1知识补充 :
1、Shell
Bash 就是 Shell 的一种具体实现 。简单来说:Shell 就是"命令解释器" 。它是你(用户)和操作系统内核(Kernel)之间的一个接口程序。
计算机的内核(大脑)只懂非常底层的机器语言,而我们人类很难直接写机器语言。
- 你的操作 :你在终端里输入
ls或dir想看文件列表。 - Shell 的工作 :它接收你的输入,把它翻译成内核能听懂的语言,然后调用内核的功能去读取文件夹。
- 结果:内核把文件列表返回给 Shell,Shell 再把它显示在你的屏幕上。
想象一下,操作系统内核(Kernel)就像是一个只会说机器语言(二进制)的超级专家 ,它负责管理 CPU、内存、硬盘等核心硬件。
而你,作为用户,只会说人类语言(比如输入 ls 看文件)。
- Shell 的角色 :它站在你和内核之间。你把需求告诉 Shell(输入命令),Shell负责把你的"人类语言"翻译成"机器语言"告诉内核;内核干完活后,把结果告诉 Shell,Shell 再把结果翻译成人话显示给你看。
- Shell 是统称:就像"手机"是一个统称。
- Bash 是具体种类:就像"iPhone"或"华为"。它是目前 Linux 和 macOS 系统中最主流、最常用的 Shell。
Shell 是操作系统的一部分,更准确地说,它是操作系统内核与用户之间的一个关键接口组件,用户直接操作的是 Shell,而 Shell 负责将用户的命令(如文件操作、进程管理等)翻译成内核能够理解的指令,从而让操作系统完成相应的工作
2、终端
最常见的现代含义:命令行界面 (CLI)
这是你作为用户最可能接触到的含义。它指的是一种应用程序 ,让你可以通过输入文本命令来与操作系统进行通信,而不是使用鼠标点击图形界面。
- 作用:执行各种任务,如管理文件、运行程序、配置系统等。它为高级用户和开发者提供了比图形界面更底层、更精细的控制能力。
- 例子 :
- 在 macOS 系统中,这个应用就叫"终端" (Terminal)。
- 在 Windows 系统中,有"命令提示符 " (cmd)、"PowerShell "以及更现代的"Windows 终端"。
- 在 Linux 系统中,也有各种终端模拟器。
windows 的终端 :

3、为什么父进程要创建子进程
1. 并发处理任务(分身术)
这是最常见的原因。父进程创建子进程,是为了让子进程分担工作,从而实现"同时"处理多件事情。
- 场景 :比如你打开的终端 (Terminal) 。当你输入一个命令(如
sleep 10)时,终端程序(父进程)会创建一个子进程去执行这个命令。 - 好处:如果没有子进程,终端就会卡住 10 秒,无法响应你的其他输入。有了子进程,父进程(终端)在创建完子进程后,可以立刻回去继续接收你的新命令,而子进程在后台慢慢执行任务。
2. 执行全新的程序(变身术)
很多时候,父进程创建子进程并不是为了让它干一样的活,而是为了让它去执行一个完全不同的程序。
- 机制 :这通常结合
fork()和exec()使用。父进程先fork出子进程,然后子进程立即调用exec,把自己的内存和代码替换掉,变成一个全新的程序(比如从 shell 变成了ls或vim)。 - 好处:这是操作系统启动应用程序的基本方式。父进程(如 shell)负责统筹管理,子进程负责具体干活。
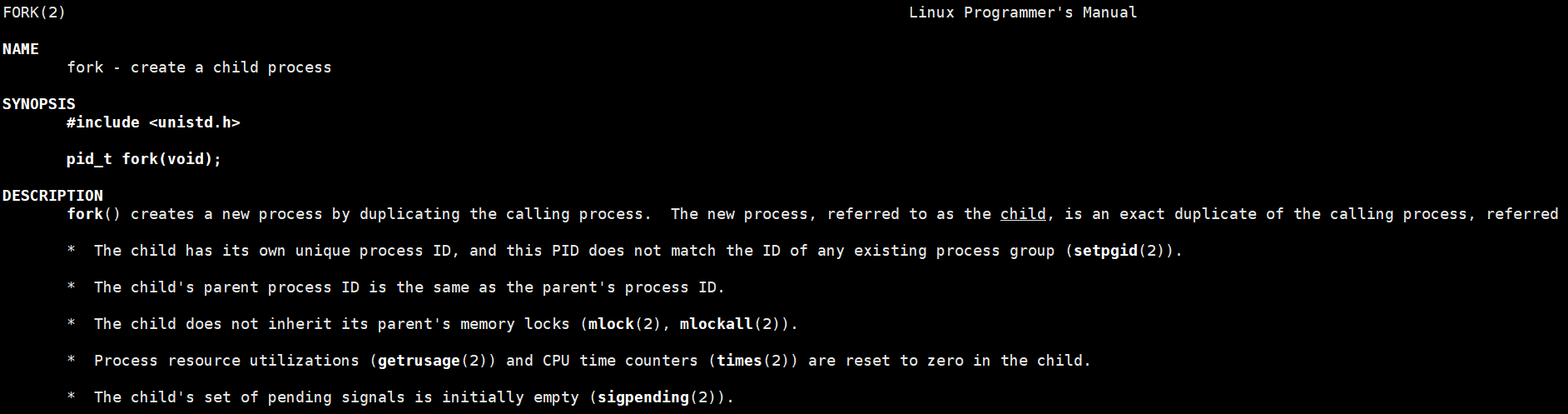
fork 函数 : 创建一个子进程
fork是一个在操作系统中用于创建新进程的系统调用,广泛应用于类Unix系统。调用fork后,系统**会复制当前进程(父进程)的地址空间,生成一个与父进程几乎完全相同的子进程,两者独立运行,共享代码段但拥有各自独立的数据、堆和栈空间。fork调用一次返回两次:在父进程中返回子进程的进程ID(正值),在子进程中返回0,若失败则返回负值。**该机制支持并发执行,是多进程编程的基础。
系统调用
定义:
fork系统调用用于创建一个新进程,称为子进程,与调用进程(父进程)同时运行。子进程是父进程的副本,拥有相同的程序计数器、CPU寄存器状态以及所有打开的文件描述符。调用后,父子进程从fork(之后的下一条指令开始执行。
执行机制:
fork 调用一次但返回两次,这是其核心特性。由于复制了父进程的堆栈段,两个进程均停留在 fork 函数中等待返回。子进程获得父进程地址空间的副本,包括数据、堆和栈,但代码段为共享。父子进程的执行顺序由操作系统调度决定,不可预测,因此代码移植时不应依赖执行顺序
形象点 :
如果把进程 比作一个正在办公的员工:
- 他在哪?
- 他的工位 (堆、栈、数据)在公司的大办公室(内存)里。
- 他的员工档案 (PID、状态、权限)在人事部(内核)的文件柜里。
- 他正在使用的电脑(CPU)上处理工作。
fork()时发生了什么?- 系统不仅给他复制了一个一模一样的工位(虚拟地址空间),还去人事部给他注册了一个新的工号(PID),生成了一份新的档案(PCB)。
父进程和子进程是并发运行的。
在 fork() 调用成功后,原来的进程(父进程)和新创建的进程(子进程)会同时存在,并由操作系统的调度器来决定谁先占用 CPU 执行。
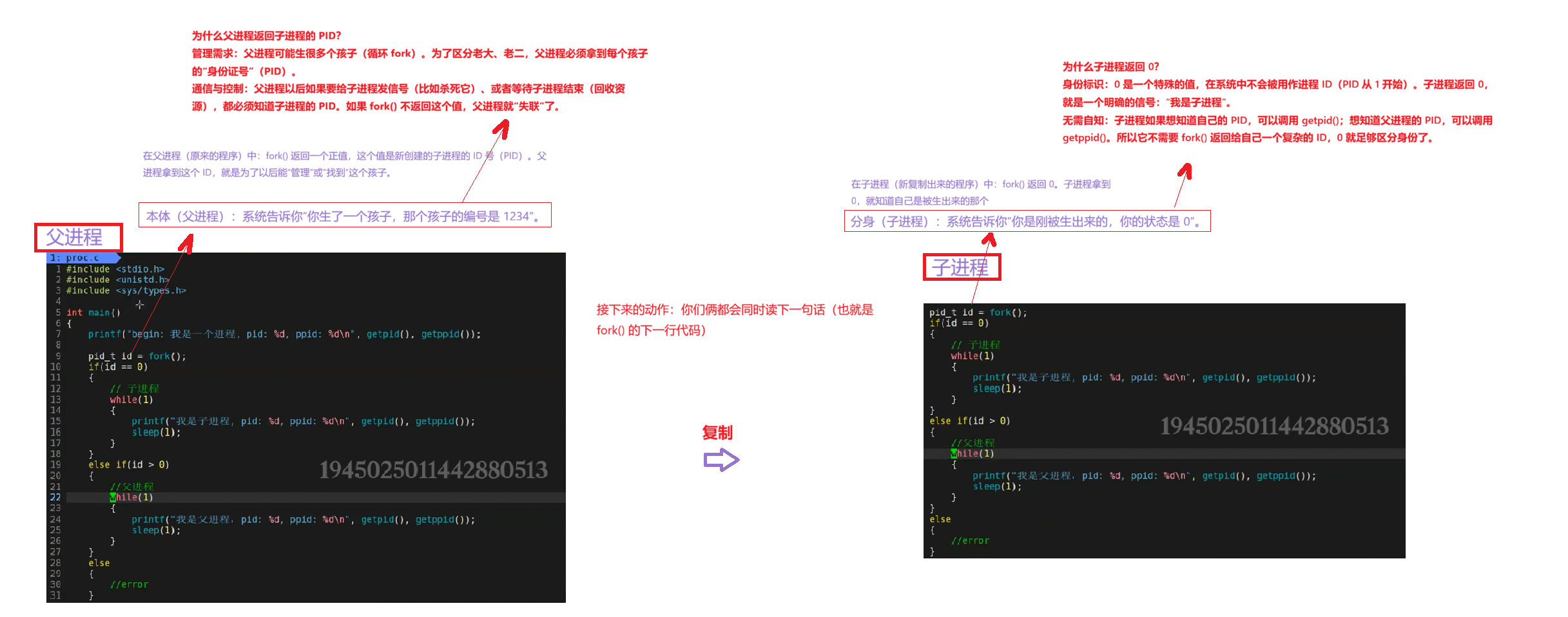
怎么做到返回两个值
- 调用 :父进程执行到
fork()语句,陷入内核。 - 复制:内核创建子进程,复制父进程的资源(代码、数据、堆栈等)。
- 设值 :内核为父进程 准备返回值(子进程 PID),为子进程准备返回值(0)。
- 返回 :内核调度器选择一个进程(可能是父也可能是子)先执行。被选中的进程从
fork()函数返回,带着那个特定的返回值(PID 或 0)。 - 分流 :父子进程都从
fork()的下一行代码开始执行。因为它们拿到的返回值不同,通过if (pid == 0)这种判断,它们就会走进不同的代码分支,做不同的事。

写实拷贝
在子进程中返回fork函数值,本质是写入,原本父进程和子进程的页表都指向同一个物理内存页。
操作系统把这个物理页标记为**"只读"** (Read-Only)。当子进程想要尝试修改时,CPU 发现这个内存页是"只读"的,但你现在想"写",于是 CPU 立刻触发一个硬件异常 (缺页异常)操作系统内核捕获到这个异常,它知道:"哦,这是 fork() 后的写时拷贝触发了。"
- 内核立刻做三件事:
- 分配 :给子进程在物理内存中分配一块新的空白页(用多少开多少)。
- 复制:把旧页的数据复制到新页。
- 修改 :把子进程的页表指向这个新页,并把新页的权限改为"可读写"。
最后,子进程的写操作继续执行,把新页里的数据重新写入
最终结果:
- 子进程:pid ,ppid..用的是新内存。
- 父进程:pid ,ppid ...还在原来的内存页里,完全不受影响。
写时拷贝的本质就是:
读取时共享,写入时分离。
- 不写不复制:只要父子进程都不修改某块数据,它们就一直愉快地共享同一块物理内存,省时省空间。
- 一写就复制:一旦某一方(比如子进程)想修改某个内存页,内核就立刻给它单独分配一块新内存,让它自己去改,不再和另一方共享这块数据了。
五、进程状态
在运行队列(runqueue) 中的状态叫做运行态(r)(一个CPU一个运行队列)
在等待队列(waitqueue) 中的状态叫做阻塞态 (ps : cin输入,键盘输入的黑框框)
有很多种等待队列,比如进程 A 在等键盘输入,进程 B 在等磁盘读数据,它们就会被放入对应的等待队列。而一个CPU只有一个运行队列
挂起状态 :
如果在等待队列中,操作系统内部的内存资源严重不足,操作系统在保证正常运行的情况下,省出来内存资源,操作系统把"空闲"进程的PCB保留,把数据和代码保存到外设中如: 磁盘。++(ps : 在办事(CPU) 处,一群人(进程)都在排队,人太多了,办事大厅站不下了(内存资源严重不足,没运行的进程占着内存资源),怎么办?把在排队的一些人用小牌子代替(保存PCB),代替他们排队 ,把那些人(代码和数据)请到休息区(磁盘)等待 (这个过程叫做挂起状态),等到排到他们了(内存够了),则把人(把代码和数据重新放进来,这叫做:换出和换入)叫过来办事,)++
补充
库函数和系统调用的关系
我们的库函数中有任何一个,只要尝试访问操作系统或软硬件上的资源,就没有意外,百分之百所有接口底层必须封装操作系统,因为软硬件资源的管理者是操作系统。而我们的上层语言不能绕过操作系统去直接对内部资源进行管理,进行访问的,对操作系统内的数据代码和相关硬件资源访问,你不能绕过操作系统,也做不到,因为操作系统是软件资源的真正管理者,所以库函数和系统调用的本质是上下层的调用关系,不一定所有库函数都会调系统调用,但只要库函数访问了软硬件资源,100%定要包含其中系统调用