文章目录
-
- [1. 为什么我们不总是追求"最新版本"?------ 技术的成熟度曲线](#1. 为什么我们不总是追求“最新版本”?—— 技术的成熟度曲线)
- [2. 开发者必备的"内功"基础](#2. 开发者必备的“内功”基础)
- [3. 智能、机器学习与深度学习的关系](#3. 智能、机器学习与深度学习的关系)
-
- [(1) 智能的本质:推理与预测](#(1) 智能的本质:推理与预测)
- [(2) 机器学习 (ML) 的引出](#(2) 机器学习 (ML) 的引出)
- [(3) 三者的包含关系](#(3) 三者的包含关系)
- [**4. 人工智能的方法论演进(为什么需要深度学习?)**](#4. 人工智能的方法论演进(为什么需要深度学习?))
- [**5. 深度学习的里程碑与现状**](#5. 深度学习的里程碑与现状)
- [6. 生物启发与分层感知](#6. 生物启发与分层感知)
- [7. 反向传播 (BP) 与计算图:神经网络的"学习"之魂](#7. 反向传播 (BP) 与计算图:神经网络的“学习”之魂)
- [8. 各种架构](#8. 各种架构)
- [9. 为什么选择 PyTorch 框架?](#9. 为什么选择 PyTorch 框架?)
-
- [关键技术差异:静态图 vs 动态图](#关键技术差异:静态图 vs 动态图)
- [核心差异:静态图 vs 动态图](#核心差异:静态图 vs 动态图)
- [10. 环境安装与验证](#10. 环境安装与验证)
1. 为什么我们不总是追求"最新版本"?------ 技术的成熟度曲线
在学习之初,刘二大人解释了课程使用 PyTorch 0.4 版本(虽然官网已更新至 1.x 及以上)的原因。这背后蕴含着**技术成熟度曲线(Gartner Hype Cycle)**的深刻逻辑:
- 技术发展期(Innovation Trigger):新技术出现,热度急剧上升,技术迭代快。
- 泡沫巅峰期(Peak of Inflated Expectations):由于媒体和企业的过度关注,技术达到热度顶点。
- 下降期/冰河期(Trough of Disillusionment):缺陷被发现,热度骤降。许多技术在此阶段夭折。
- 应用期(Slope of Enlightenment & Plateau of Productivity) :技术解决自身缺陷后进入平稳应用阶段,适配工作上的技术。如 C、Java 等成熟语言。
核心能力培养 :在技术迭代极快的环境下,学会阅读文档 和理解基础架构 的"泛化能力"远比死记硬背 API 更重要。
2. 开发者必备的"内功"基础
正式进入代码实践前,建议具备以下知识储备:
- 数学基础 :
- 线性代数:理解矩阵作为"空间变换函数"的本质。
- 概率论与数理统计 :重点理解随机变量 与概率分布(如高斯分布),这是理解模型处理噪声和不确定性的关键。
- 编程基础 :
- 精通 Python,特别是面向对象编程(OOP)。
- 掌握魔法方法 ,如
__call__(使对象像函数一样可调用,这是 PyTorch 模型调用的底层逻辑)。
3. 智能、机器学习与深度学习的关系
(1) 智能的本质:推理与预测
- 推理 (Reasoning):根据已知信息和约束做出决策。例如根据余额和偏好通过算法决定中午吃什么。
- 预测 (Prediction):将现实世界的实体(如图像、声音)转化为抽象概念的过程(如识别图中是"猫"还是"数字2")。
(2) 机器学习 (ML) 的引出
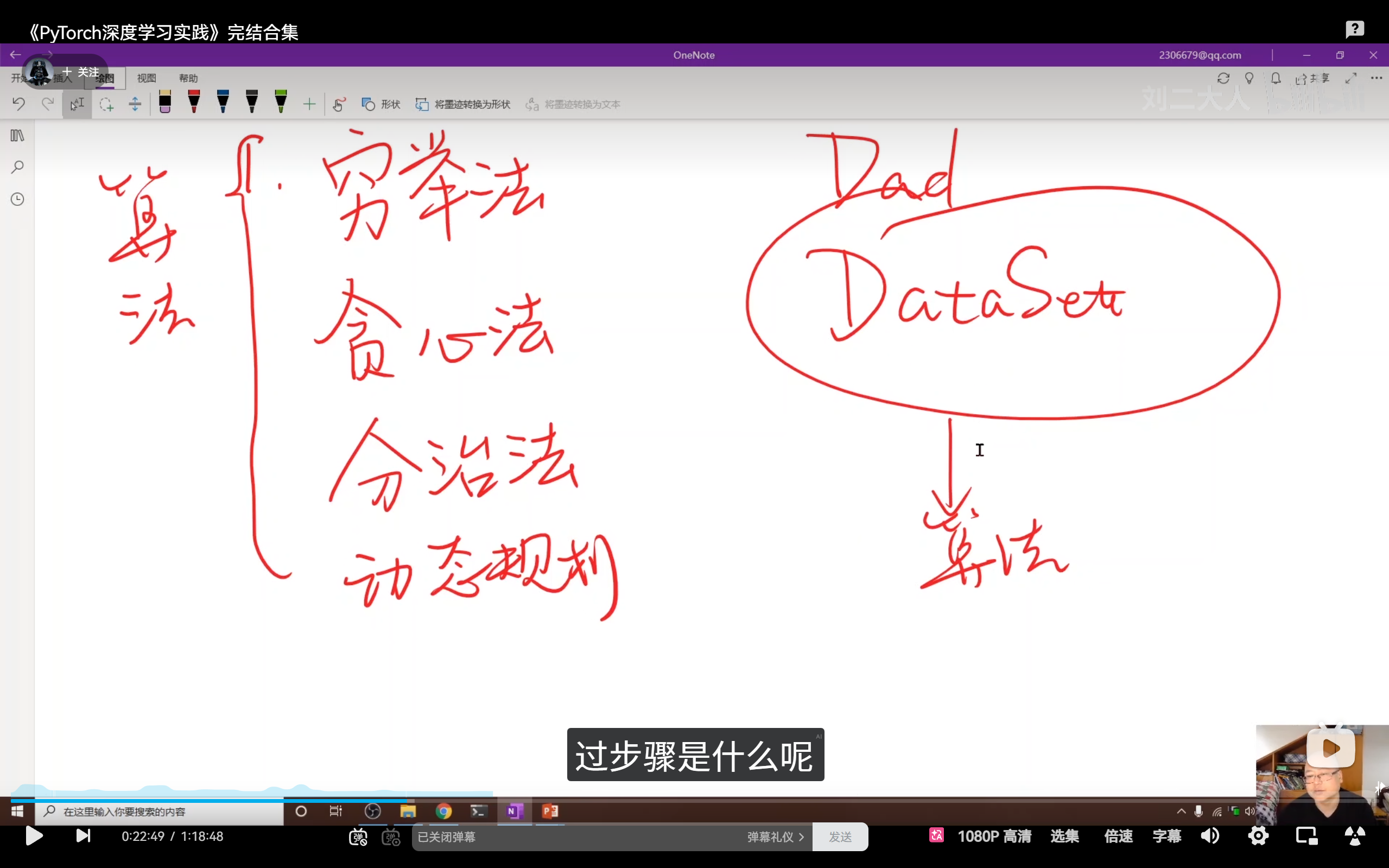
刘二大人通过对比传统算法课程揭示了 ML 的核心:
- 传统算法(人工设计) :人类利用穷举、贪心、分治或动态规划等思维,人工设计出一套具体的计算过程。
- 机器学习(数据驱动) :算法不再是由人手写的规则,而是从数据集 (Data) 中通过训练模型**自动"挖掘"**出来的计算逻辑。
(3) 三者的包含关系
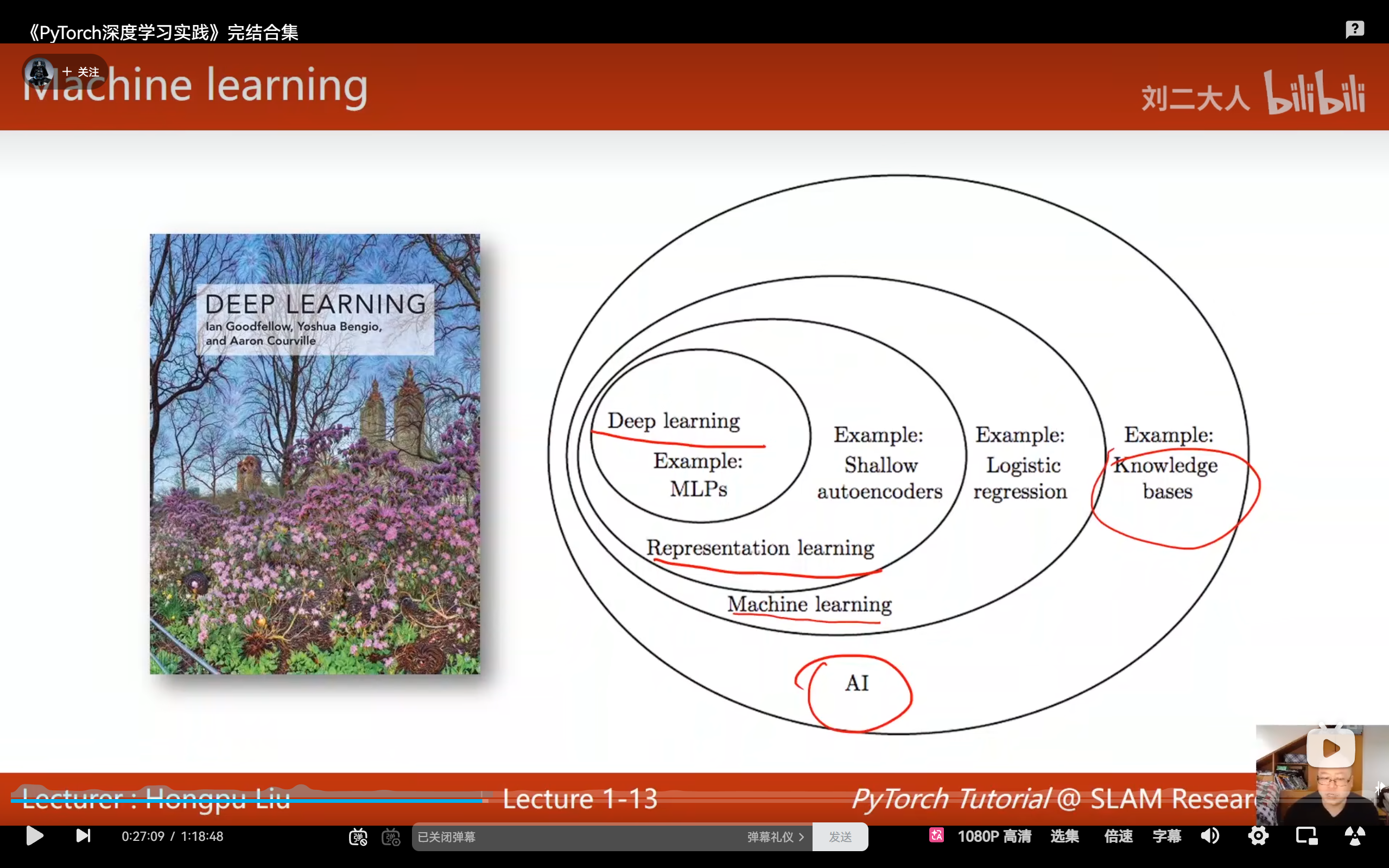
• 人工智能 (AI):作为最广泛的领域,不仅涵盖机器学习,还包括知识库系统、专家系统、计算机视觉、自然语言处理以及因果推理等多个分支。
• 机器学习 (ML):属于AI的核心子领域,其本质是通过数据驱动的方式自动学习算法,而非依赖人工设计。主要运用统计学方法(如最大似然估计)来优化模型参数。
• 深度学习 (DL):作为机器学习的重要分支,专注于使用深度神经网络架构(包括MLP、CNN、RNN等)构建高性能模型。
三者呈现明确的层级关系:AI ⊃ ML ⊃ DL 。其中深度学习是机器学习中专门采用深度神经网络解决复杂问题的方法论。
4. 人工智能的方法论演进(为什么需要深度学习?)
视频中通过对比三种系统,解释了为什么深度学习能脱颖而出:
-
基于规则的系统 (Rule-based Systems):
- 原理:由人类专家根据背景知识手动编写复杂的逻辑和规则。
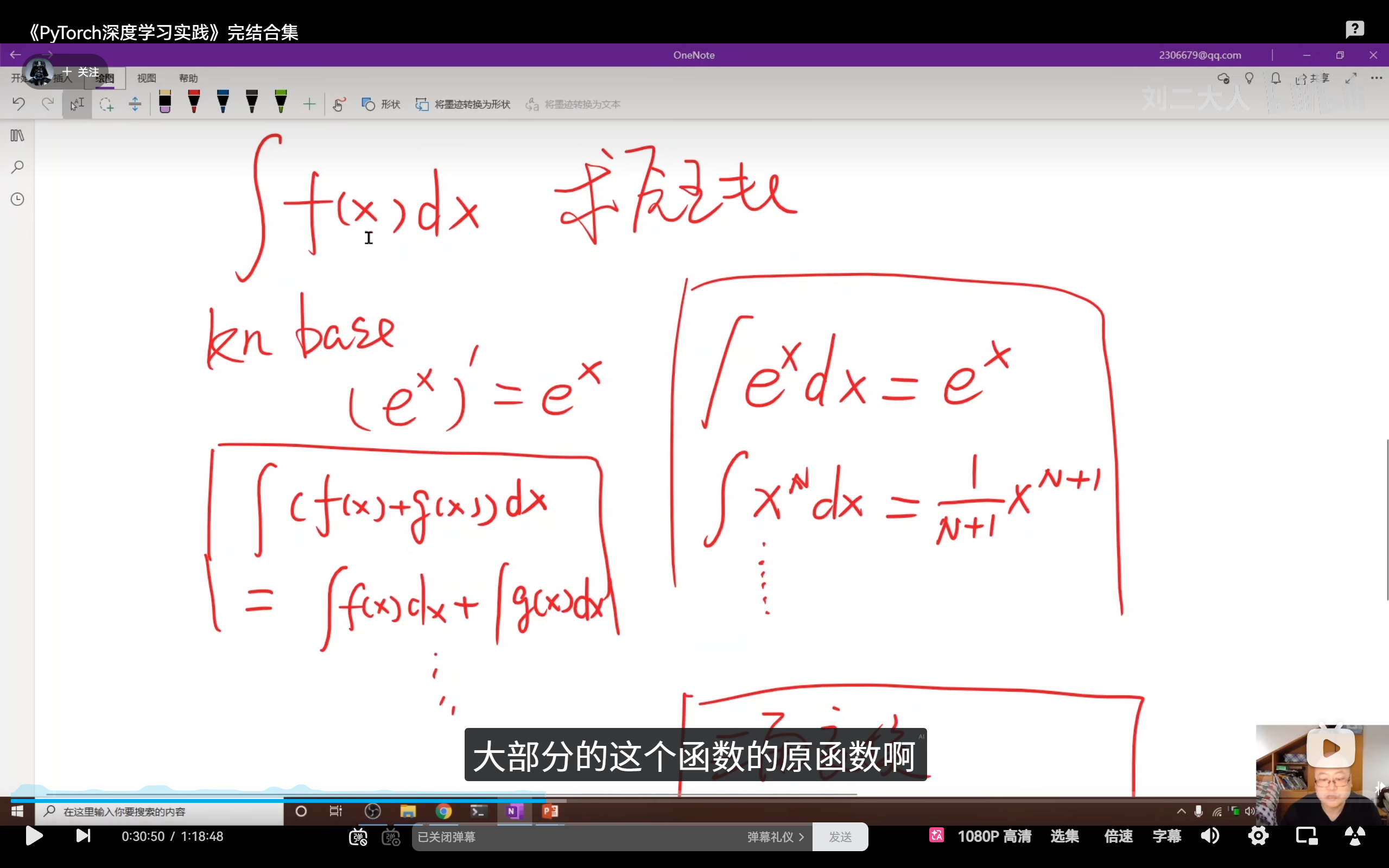
- 例子:早期自动求解微积分原函数的程序,需要预设大量原子公式和等价变形规则。
- 瓶颈 :面对复杂问题(如图像识别),规则库会变得庞大到人类无法维护,且由于规则不全会导致算法存在严重缺陷。简单说,要解决无限个复杂问题,就要开发无限个规则去解决,很麻烦,也不实用。
-
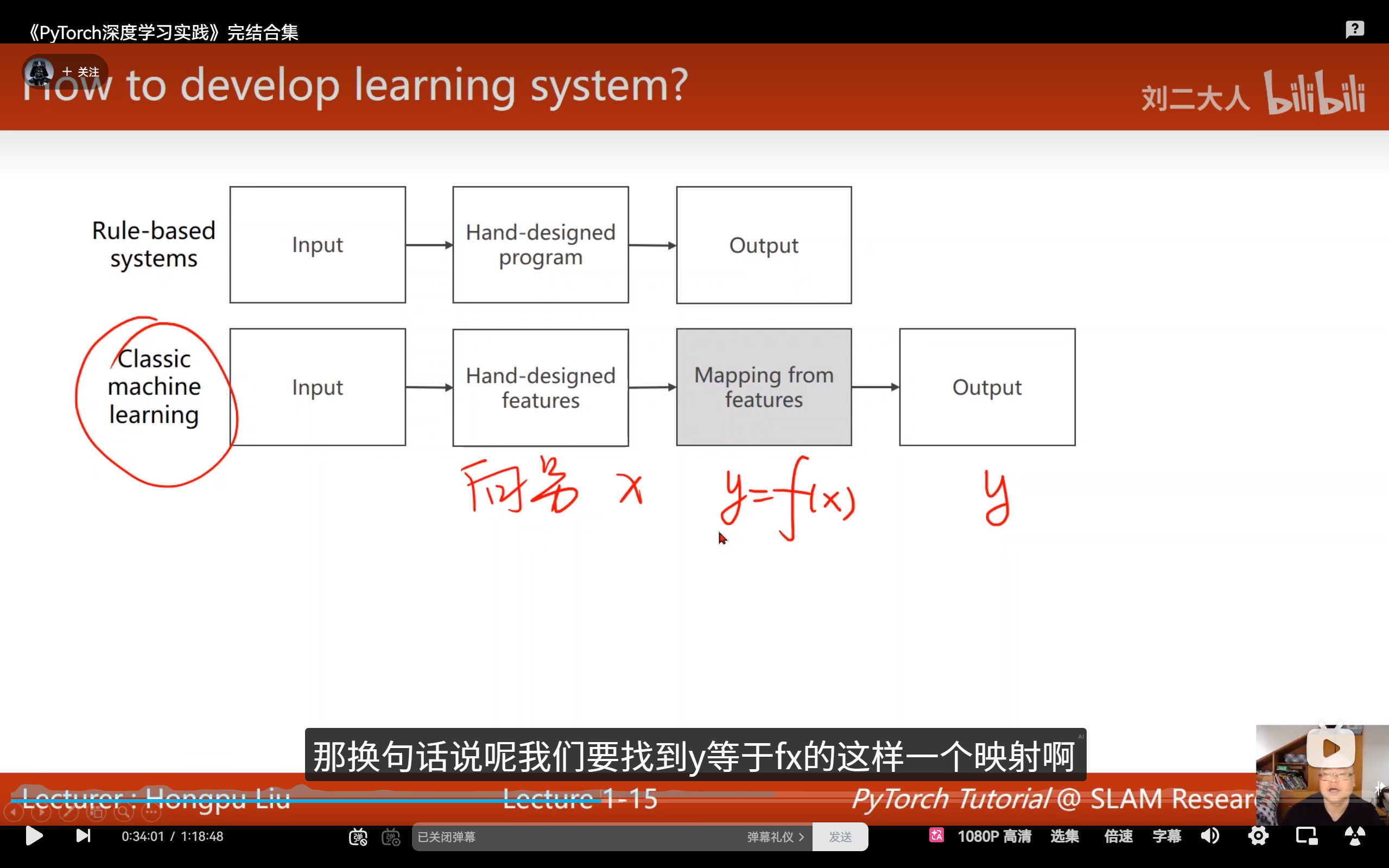
经典机器学习 (Classic Machine Learning):
- 原理 :采用特征提取器的设计思路。通过人工统计方法手动构建特征(例如将图像特定区域转换为固定长度的向量),然后基于输出结果寻找映射函数(如线性回归、支持向量机或逻辑回归等算法)。
- 挑战(维度灾难) :当特征维度 n n n 增加时,所需样本量呈指数级 x n x^n xn 增长(单特征需10个样本,双特征需10×10,三特征则需10×10×10)。同时,人工设计的特征往往难以有效捕捉数据中潜在的复杂模式。
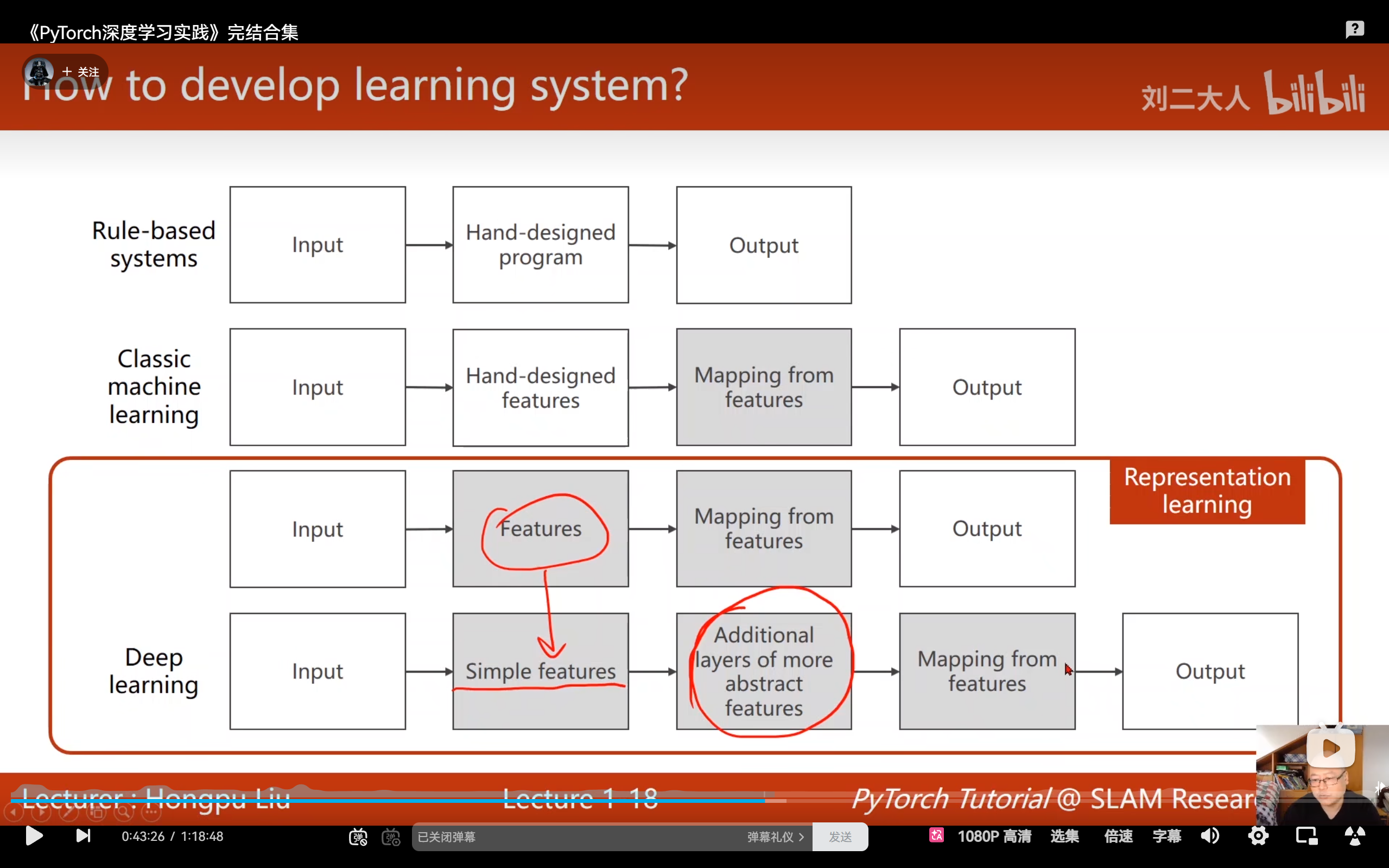
- 深度学习 (Deep Learning) :
- 革命性变化 :实现了端到端 (End-to-End) 的训练过程。
- 原理 :模型直接输入原始数据(如像素点、语音波形),自动学习如何提取特征并输出结论。
- 表征学习:旨在实现特征的自动学习。特征提取作为独立步骤,通过特定算法将复杂的非结构化输入数据转换为向量表示,该向量可输入到特征映射模型中。特征提取采用无监督学习方法(无需标签),而特征映射模型则使用有监督学习(需要标签),因此需要分别训练。
- 流形假设 (Manifold Hypothesis) :深度学习通过多层非线性变换,将高维空间的数据压缩映射到低维曲面(流形)上,从而绕过了维度的诅咒,抓住了数据的本质规律。
5. 深度学习的里程碑与现状
-
性能跨越 :在 ILSVRC 图像识别竞赛中,2012 年 AlexNet 的出现让错误率大幅下降(从 25.8% 降至 16.4%);到 2015 年,ResNet 的错误率降至 3.57%,历史上首次超过了人类的识别精度(人类约为 5%)。
-
地位评价:尽管深度学习存在"可解释性较差"等缺陷,但它是目前在业界落地的最主流、最有效的 AI 技术。

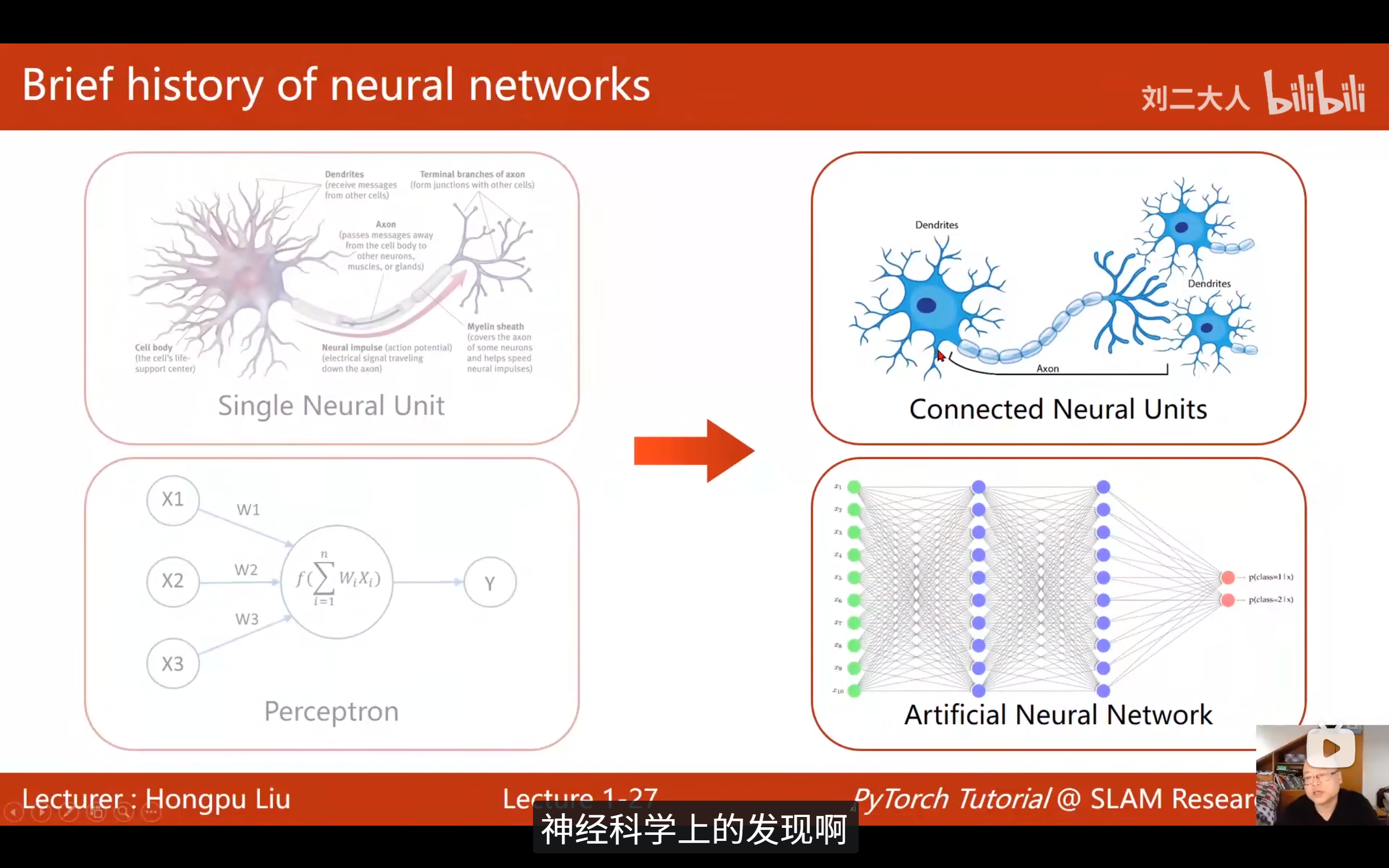
6. 生物启发与分层感知
1959 年对猫视觉系统的著名实验证明:哺乳动物大脑处理信息是分层的:
- 底层神经元:负责检测简单的线条、边缘、色块。
- 高层神经元 :组合底层特征,提取高层抽象概念(如识别猫、狗、人脸)。
这一发现直接启发了现代深度神经网络的架构设计。
7. 反向传播 (BP) 与计算图:神经网络的"学习"之魂
神经网络如何"自动"调整权重?
-
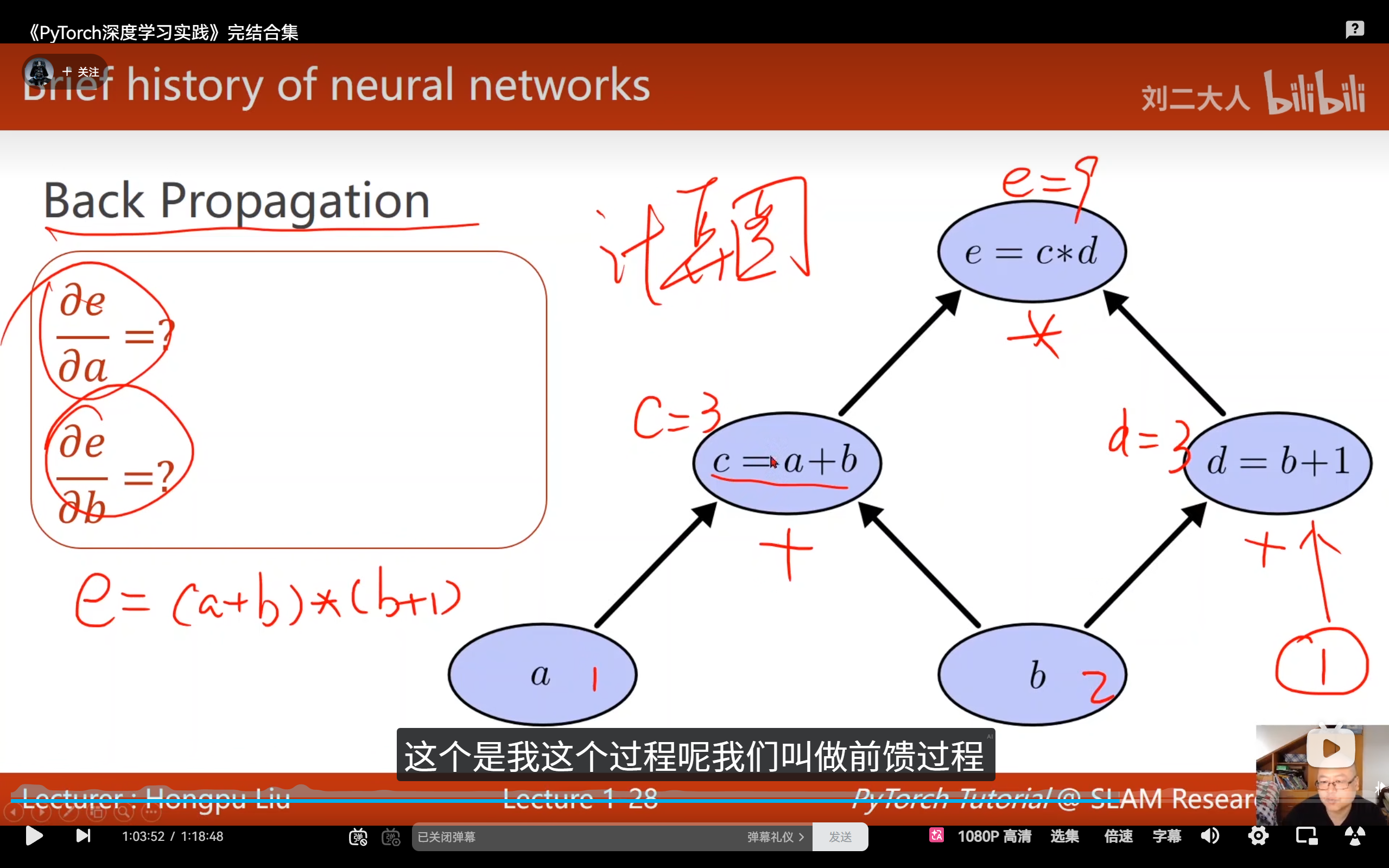
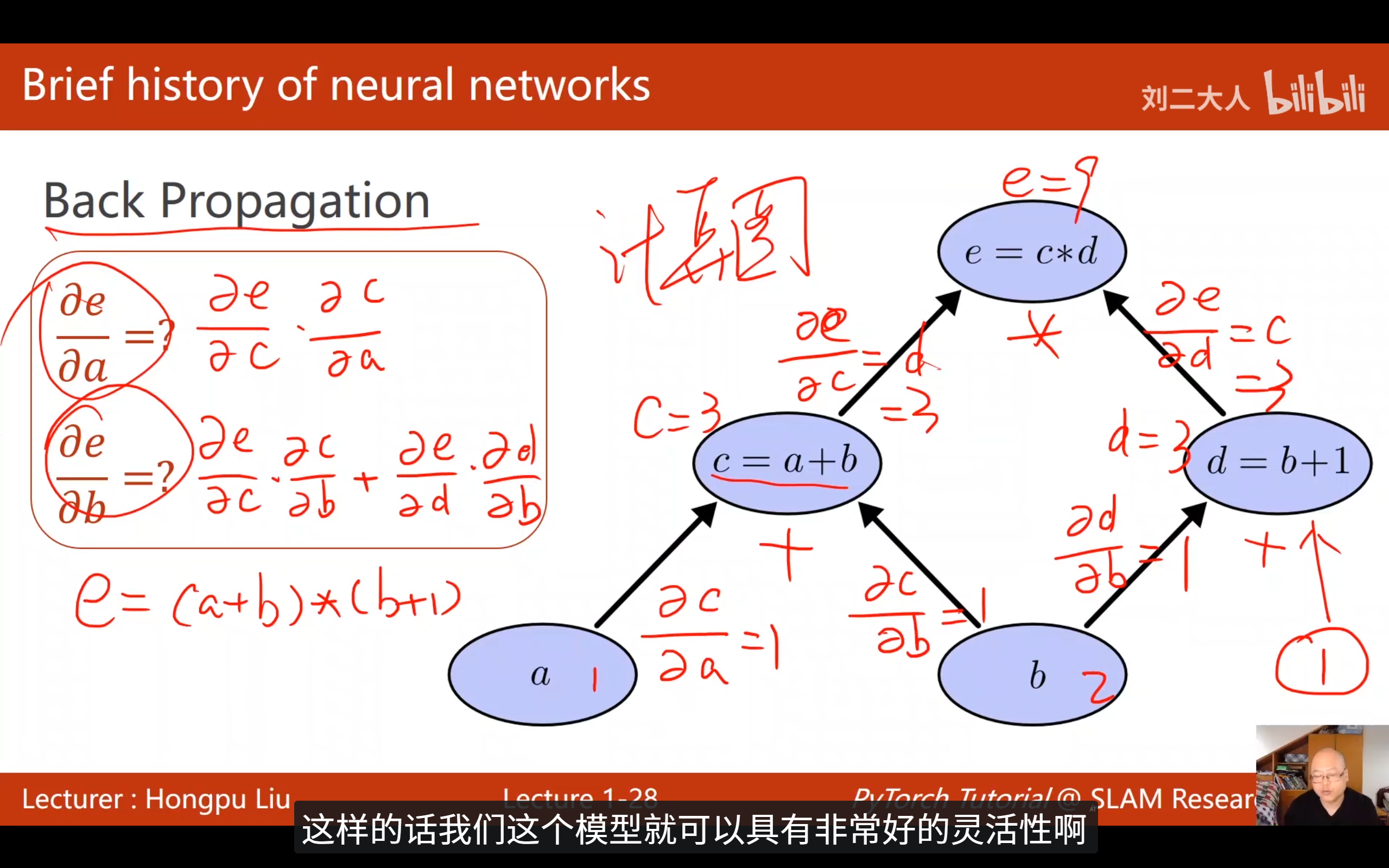
计算图 (Computation Graph) :将复杂的数学运算分解为原子计算(如加法、乘法节点)构成的图。
-
前馈 (Forward) :数据通过图流向输出,计算损失(Loss)。
-
反馈 (Backward) :利用链式法则 (Chain Rule) 沿图反向传播偏导数。无需手动推导复杂的导数解析式,即可求得每个权重对 Loss 的贡献。
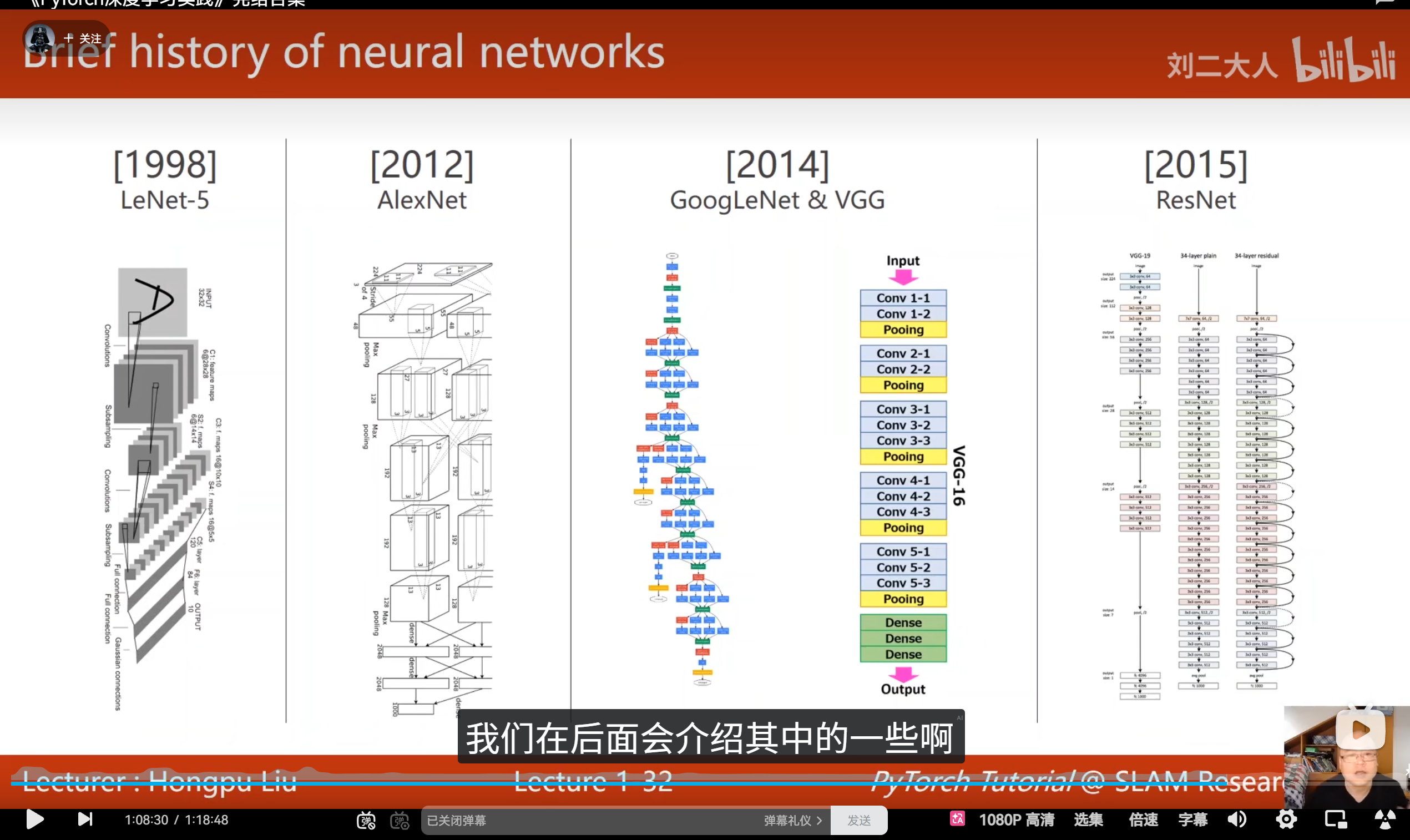
8. 各种架构
与其学会所有的架构,不如学会每一个架构的基本组成结构
9. 为什么选择 PyTorch 框架?
在主流深度学习框架(如 TensorFlow、Caffe)中,PyTorch 凭借以下核心优势脱颖而出:
- 动态计算图:支持实时构建和自动释放计算图,可直接使用 Python 原生控制流(如 for 循环)实现复杂网络结构
- Pythonic 设计:完全遵循 Python 编程范式,大幅提升开发效率和调试便利性
- 完备的工具链:提供丰富的神经网络基础模块(包括卷积层、池化层、优化器等),并内置 GPU 加速支持,无需处理底层 CUDA 接口
关键技术差异:静态图 vs 动态图
- TensorFlow(早期版本) :静态图机制
- 需预先定义完整计算图结构
- 运行时无法调整网络架构,灵活性受限
- PyTorch :动态图机制
- 实时构建并自动释放计算图
- 支持迭代过程中动态调整网络结构,灵活度极高
动态图带来极佳的调试体验:
- 可直接插入 print 语句
- 可使用 pdb 等标准调试工具
- 可实时查看中间张量数值
- 便于快速定位问题
静态图调试相对复杂:
- 需通过 tf.Print 等特殊操作
- 必须将待检查节点作为 fetches 传入 sess.run()
- 无法直接获取中间结果
- 调试流程繁琐## 9. 为什么首选 PyTorch 框架?
在众多深度学习框架(如 TensorFlow、Caffe)中,PyTorch 凭借以下优势成为首选:
- 动态计算图:实时构建计算图,运算完成后自动释放。支持使用常规 Python 控制流(如 for 循环)构建复杂网络结构。
- 原生 Python 风格:采用符合 Python 习惯的编程范式,大幅简化调试过程。
- 完善的组件库:内置丰富的神经网络基础模块(卷积层、池化层、优化器等),并原生支持 GPU 加速,无需直接操作 CUDA 接口。
核心差异:静态图 vs 动态图
- TensorFlow(早期版本) :基于静态图机制
- 需要预先定义完整的计算图结构
- 运行时无法修改图结构,灵活性受限
- PyTorch :采用动态图机制
- 实时构建计算图,运算后自动释放
- 支持每次迭代构建不同的图结构,灵活性极强
动态图的调试体验近乎完美。你可以随意在代码中插入 print语句,或使用 pdb等标准 Python 调试器设置断点,逐行查看中间张量的值,快速定位问题,这为研究和实验提供了巨大便利。
静态图的调试则比较曲折。因为你只是在构建一个计算"蓝图",在 Session.run()之前,数据并未流动。你无法直接打印中间结果,必须借助 tf.Print这类特殊的操作,并将需要查看的节点作为 fetches传入 sess.run(),流程上麻烦很多
10. 环境安装与验证
-
无显卡方案:安装 CPU 版本即可满足本课程实验,几分钟内即可出结果。
-
GPU 方案 :若有 NVIDIA 显卡,需先安装 CUDA 驱动。注意安装时如遇冲突可选择自定义安装并取消 VS 支持。
-
验证成功 :
pythonimport torch print(torch.__version__) # 打印版本号确认安装