一、引入包
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
<version>4.0.2</version>
</dependency>二、yml配置
spring:
elasticsearch:
uris: http://192.168.1.123:9200三、索引创建与删除
java
@Data
@Document(indexName = "stu-info")
public class Stu {
@Id
private Long stuId;
@Field
private String name;
@Field
private Integer age;
@Field
private float money;
@Field
private String description;
}1.创建索引
java
@GetMapping(value = "/createIndex")
public AjaxResult createIndex(HttpServletRequest req) {
esRestTemplate.indexOps(Stu.class).create();
return AjaxResult.success("创建成功");
}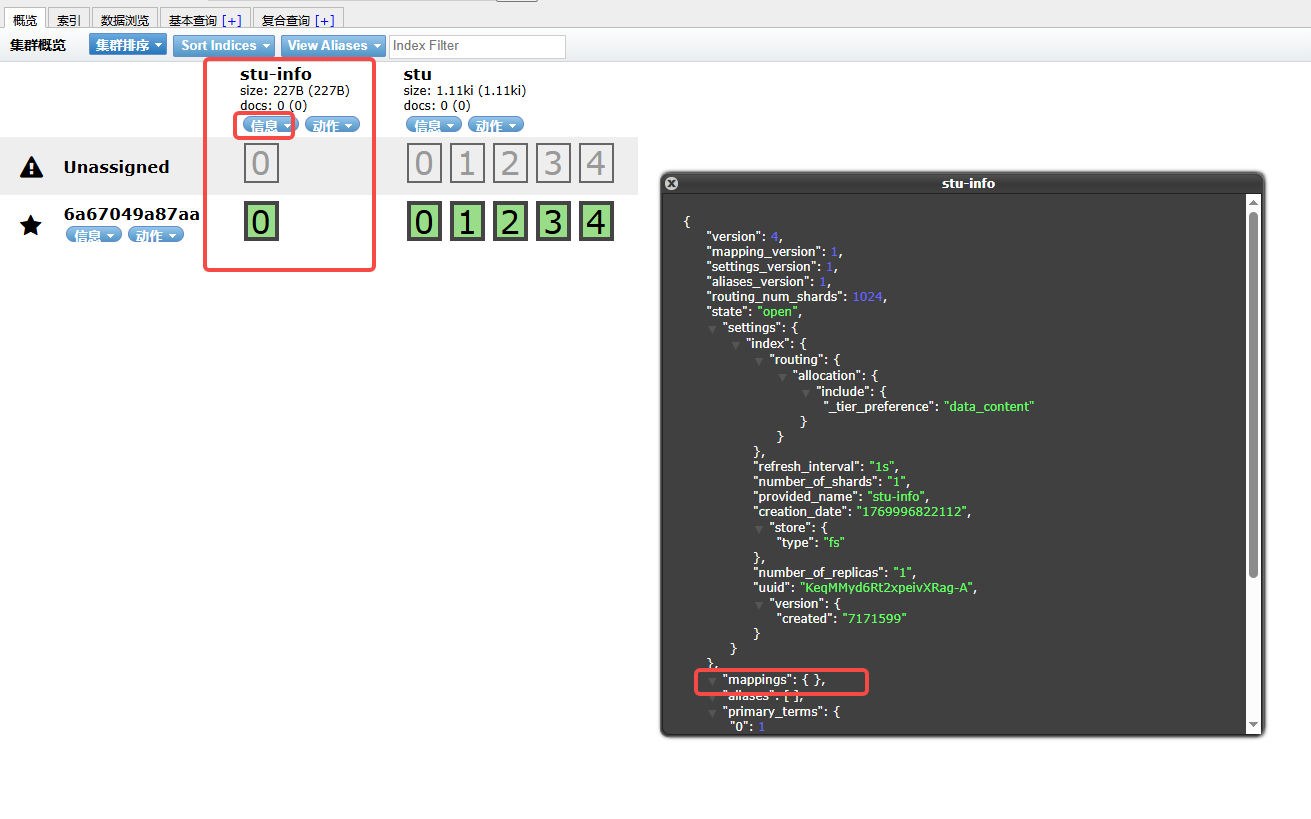
但是一般来说,一般来说为了规范,我们都是通过手动来创建索引的,因为索引一旦创建就无法修改,除非删除,连field的类型是什么也不能修改,所以往往都是在初期规划好的。那么在这里我们就通过手动的方式来创建。
2.删除索引
java
@GetMapping("deleteIndex")
public Object deleteIndex() {
esRestTemplate.indexOps(Stu.class).delete();
return AjaxResult.success("删除成功");
}3.新增文档数据
java
@GetMapping("save")
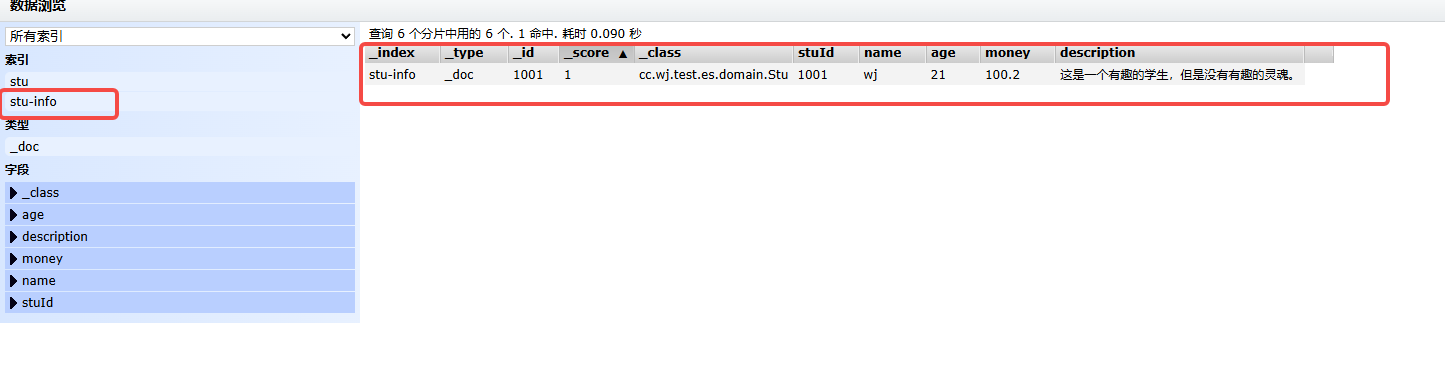
public Object save() {
Stu stu = new Stu();
stu.setStuId(1001L);
stu.setName("wj");
stu.setAge(21);
stu.setDescription("这是一个有趣的学生,但是没有有趣的灵魂。");
stu.setMoney(100.2f);
IndexQuery iq = new IndexQueryBuilder().withObject(stu).build();
IndexCoordinates ic = IndexCoordinates.of("stu-info");
esRestTemplate.index(iq, ic);
return AjaxResult.success();
}
4.为索引创建mapping
(1)接口方式
java
POST /stu/_doc/_mapping?include_type_name=true
{
"properties": {
"stuId": {
"type": "long"
},
"name": {
"type": "text",
"analyzer": "ik_max_word"
},
"age": {
"type": "integer"
},
"money": {
"type": "float"
},
"desc": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}(2)配置方式
java
package cc.wj.test.es.domain;
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import java.util.List;
/**
* @author wj
* @version 1.0
* @date 2026/2/2 9:16
*/
@Data
@Document(indexName = "stu-info")
public class Stu {
@Id
@Field(type = FieldType.Keyword)
private Long stuId;
@Field(type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String name;
@Field(type = FieldType.Integer)
private Integer age;
@Field(type = FieldType.Float)
private float money;
@Field(type = FieldType.Keyword)
private String description;
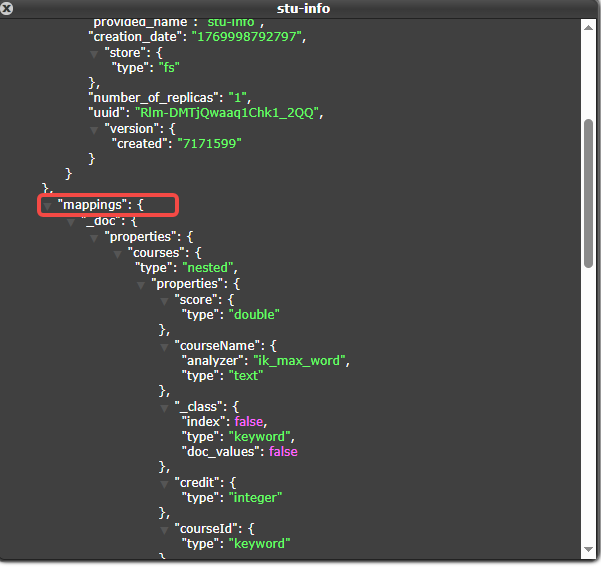
@Field(type = FieldType.Object)
private Address address;
@Field(type = FieldType.Nested)
private List<Course> courses;
@Data
public static class Course {
@Field(type = FieldType.Keyword)
private String courseId;
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String courseName;
@Field(type = FieldType.Double)
private Double score;
@Field(type = FieldType.Integer)
private Integer credit;
}
@Data
public static class Address {
@Field(type = FieldType.Text)
private String province;
@Field(type = FieldType.Text)
private String city;
@Field(type = FieldType.Text)
private String detail;
}
}
java
@GetMapping(value = "/createIndex")
public AjaxResult createIndex(HttpServletRequest req) {
esRestTemplate.indexOps(Stu.class).createWithMapping();
return AjaxResult.success("创建成功");
}
java
@GetMapping("save")
public Object save() {
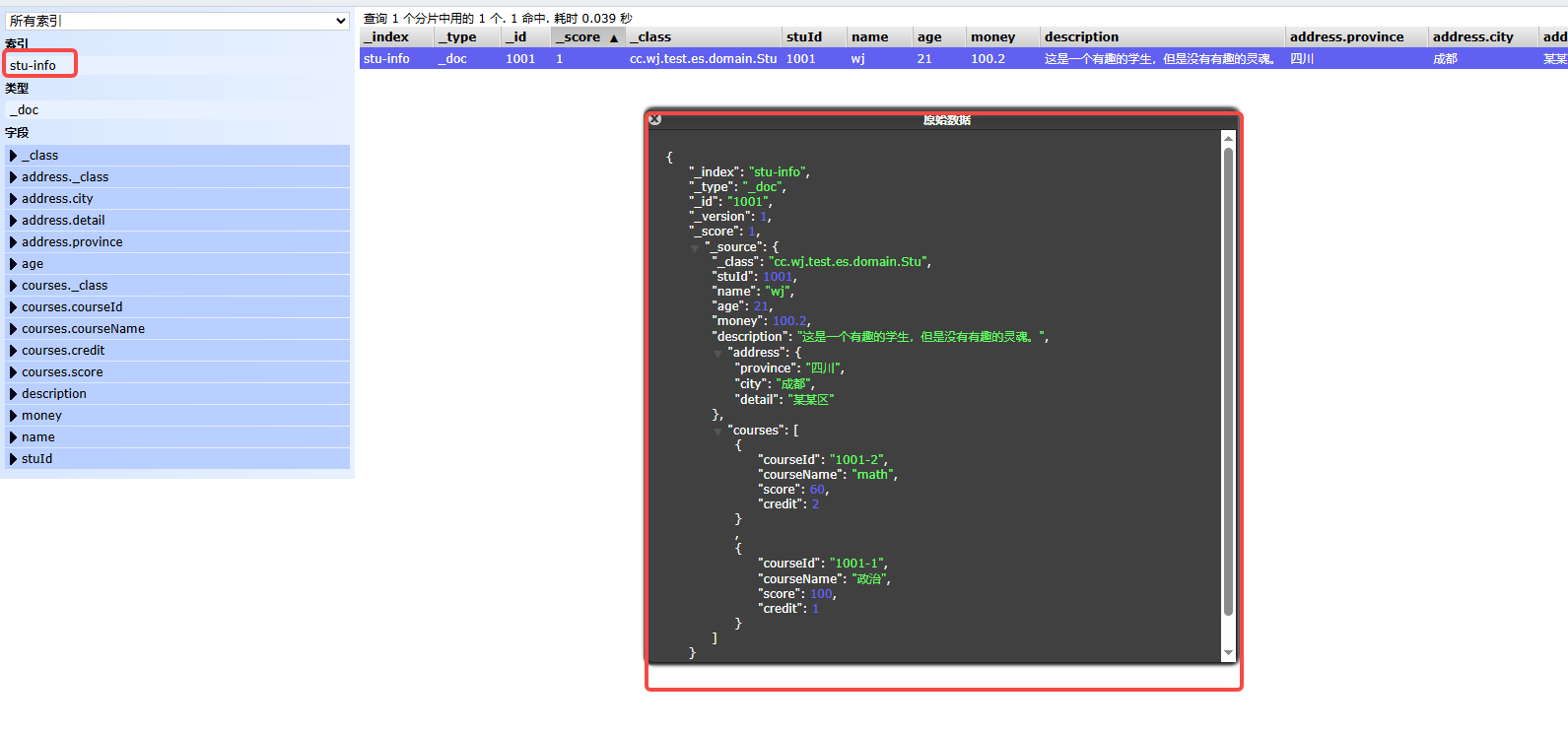
Stu stu = new Stu();
stu.setStuId(1001L);
stu.setName("wj");
stu.setAge(21);
stu.setDescription("这是一个有趣的学生,但是没有有趣的灵魂。");
stu.setMoney(100.2f);
Stu.Address address=new Stu.Address();
address.setCity("成都");
address.setProvince("四川");
address.setDetail("某某区");
stu.setAddress(address);
Stu.Course course1=new Stu.Course();
course1.setCourseId("1001-1");
course1.setCourseName("政治");
course1.setCredit(1);
course1.setScore(100D);
Stu.Course course2=new Stu.Course();
course2.setCourseId("1001-2");
course2.setCourseName("math");
course2.setCredit(2);
course2.setScore(60D);
List<Stu.Course> courses=new ArrayList<>();
courses.add(course2);
courses.add(course1);
stu.setCourses(courses);
IndexQuery iq = new IndexQueryBuilder().withObject(stu).build();
IndexCoordinates ic = IndexCoordinates.of("stu-info");
esRestTemplate.index(iq, ic);
return AjaxResult.success();
}
5.修改文档数据
java
@GetMapping("update")
public Object update() {
Stu stu = new Stu();
stu.setStuId(1001L);
stu.setName("wj");
stu.setAge(21);
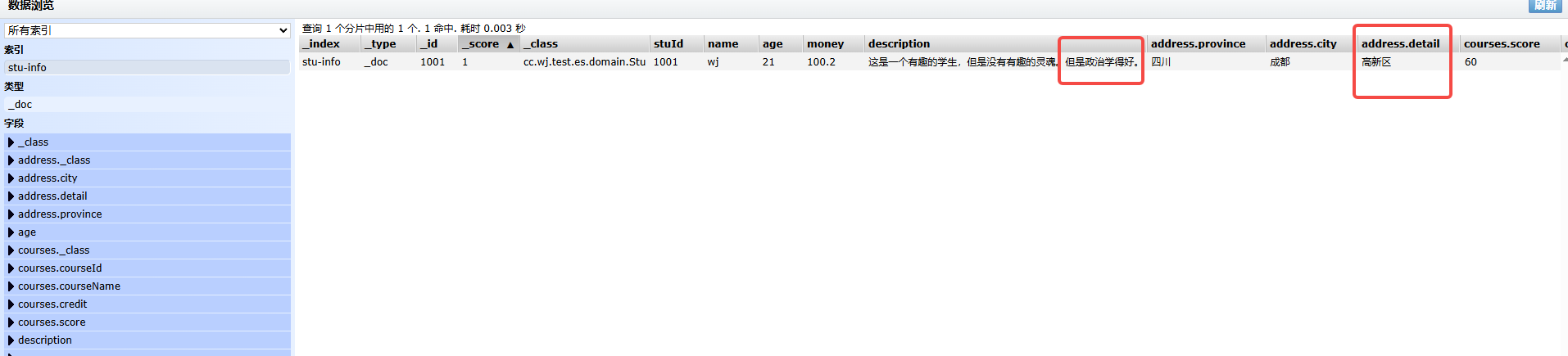
stu.setDescription("这是一个有趣的学生,但是没有有趣的灵魂。但是政治学得好。");
stu.setMoney(100.2f);
Stu.Address address = new Stu.Address();
address.setCity("成都");
address.setProvince("四川");
address.setDetail("高新区");
stu.setAddress(address);
Stu.Course course1 = new Stu.Course();
course1.setCourseId("1001-1");
course1.setCourseName("思想品德与政治");
course1.setCredit(1);
course1.setScore(100D);
Stu.Course course2 = new Stu.Course();
course2.setCourseId("1001-2");
course2.setCourseName("数学");
course2.setCredit(2);
course2.setScore(60D);
List<Stu.Course> courses = new ArrayList<>();
courses.add(course2);
courses.add(course1);
stu.setCourses(courses);
UpdateQuery updateQuery = UpdateQuery.builder("1001")
.withDocument(esRestTemplate.getElasticsearchConverter()
.mapObject(stu))
.withDocAsUpsert(true) // 如果不存在则插入
.build();
IndexCoordinates ic = IndexCoordinates.of("stu-info");
esRestTemplate.update(updateQuery, ic);
return AjaxResult.success();
}
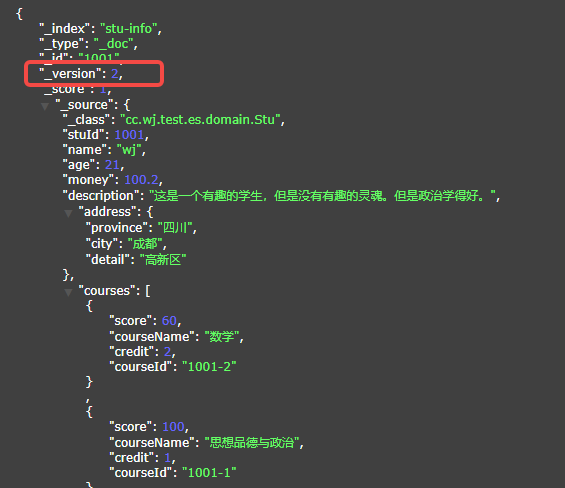
6.文档数据查询
java
@GetMapping("get")
public Object get() {
// Criteria criteria = new Criteria().and("stuId").is(1001L);
// Query query = new CriteriaQuery(criteria);
// Stu s = esRestTemplate.searchOne(query, Stu.class).getContent();
Criteria criteria1 = new Criteria("age").is("21").
and("money").greaterThan(60);
Query query1 = new CriteriaQuery(criteria1);
SearchHits<Stu> mapSearchHits = esRestTemplate.search(query1, Stu.class, IndexCoordinates.of("stu-info"));
List<SearchHit<Stu>> searchHits = mapSearchHits.getSearchHits();
for (SearchHit<Stu> searchHit : searchHits) {
Stu student = searchHit.getContent();
System.out.println(student);
}
return AjaxResult.success(searchHits);
}7.删除文档数据
java
@GetMapping("delDoc")
public Object detDoc(String id) {
esRestTemplate.delete("1001", IndexCoordinates.of("stu-info"));
return AjaxResult.success();
}四、Springboot集成ES重点架构问题
上面是基础的使用,但是接下来就有很多需要思考的问题了:
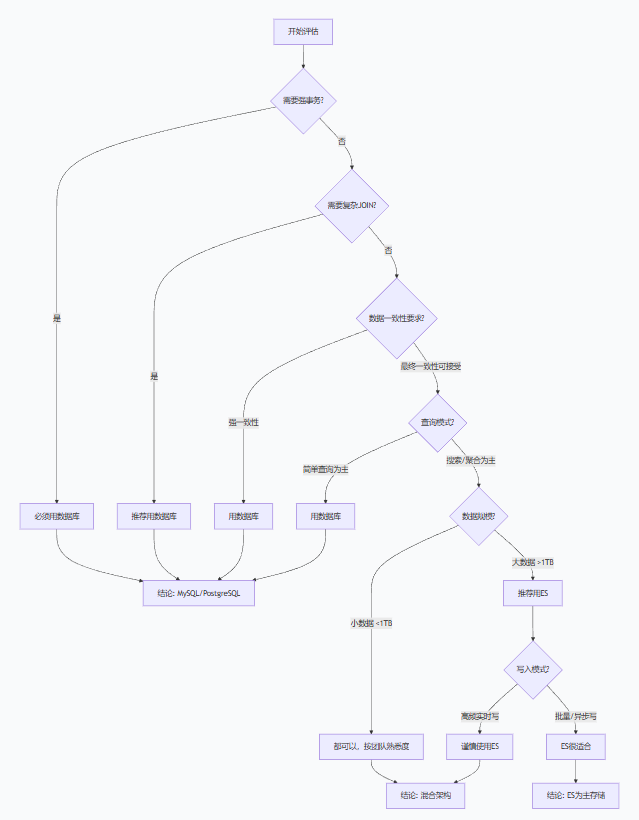
1.ES大数据量查询基本是要取代mysql查询的,那这些数据的新增、修改、删除呢?换言之,ES可以取代mysql吗?
不能完全取代,但在特定场景下可以部分取代。
| 特性 | Elasticsearch | 传统数据库 (MySQL/PostgreSQL) | 适合场景 |
|---|---|---|---|
| 数据一致性 | 最终一致性(默认1秒) | 强一致性(ACID) | 数据库胜出 |
| 事务支持 | 单文档"伪事务" | 完整事务(跨文档/跨表) | 数据库胜出 |
| 查询语言 | DSL/Query DSL | 标准SQL | 数据库胜出 |
| 关联查询 | 有限(父子文档/嵌套) | 完整JOIN支持 | 数据库胜出 |
| 写入性能 | 批量写入快 | 单条写入快 | 各有优势 |
| 读取性能 | 搜索/聚合极快 | 简单查询快 | ES胜出搜索 |
| 数据安全 | 较弱 | 完整备份恢复机制 | 数据库胜出 |
| 数据规模 | TB-PB级 | GB-TB级 | ES胜出大数据 |
因为Mysql可以实现事务保障、强一致性、支持复杂join、高频写入。可以根据数据量来考虑,具体如下:
-
小数据量:可以直接双写
-
大数据量:推荐 CDC + 异步同步
-
关键业务:必须保留MySQL作为主存储
ES作为主存储的风险和挑战:数据丢失风险( ES:快照备份+副本机制+没有完整事务日志;Mysql具备完整备份恢复机制)、数据一致性风险(ES:默认1秒刷新,可能丢失数据)等等。
2.哪些数据可以存储在ES?
适合的数据:
搜索分析数据 - Elasticsearch(按需)
* - 全文搜索内容
* - 日志数据分析
* - 用户行为分析
* - 时序数据(比如高频查询场景)
* - 实时统计
适合数据特征:
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1. 半结构化或非结构化 * 支持 JSON 文档存储,字段可动态扩展 * 无需预定义严格 schema(但建议定义映射模板) 2. 高写入吞吐量 * 适合持续写入的场景(如日志流) * 通过分片(Shard)实现水平扩展 3. 实时性要求高 * 数据写入后 1 秒内可被检索 * 适用于监控告警等场景 4. 数据量较大 * 支持 PB 级数据存储(需合理设计分片和索引生命周期) 5. 频繁聚合分析 * 支持 Bucket/Metric 聚合(如统计、分组、百分比) * 适合生成仪表盘(Kibana) |
不适合的数据:
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1. 强事务数据 * 如订单支付、账户余额(需用关系型数据库) * Elasticsearch 不支持 ACID 事务 2. 频繁更新的数据 * 每次更新实质是"删除+重建",影响性能 * 适合追加式写入(如日志) 3. 高度关联的数据 * Join 查询性能较差,需通过嵌套或父子文档处理 * 复杂关联查询建议结合关系型数据库使用 4. 精确去重计数 * Cardinality 聚合存在误差(精度与内存权衡) * 精确统计需借助其他方案(如 HBase+Spark) |
3.ES与mysql数据如何同步?(解决数据一致性问题)
A. 同步双写
场景:适用于对数据实时性要求极高,且业务逻辑简单的场景,如金融交易记录同步。
痛点:
- 硬编码侵入:所有涉及写操作的地方均需添加ES写入逻辑。
- 性能瓶颈:双写操作导致事务时间延长,TPS下降30%以上。
- 数据一致性风险:若ES写入失败,需引入补偿机制(如本地事务表+定时重试)。
B.异步双写
场景:电商订单状态更新后需同步至ES供客服系统检索。
优势:
- 吞吐量提升:通过MQ削峰填谷,可承载万级QPS。
- 故障隔离:ES宕机不影响主业务链路。
缺陷:
- 消息堆积:突发流量可能导致消费延迟(需监控Lag值)。
- 顺序性问题:需通过分区键保证同一数据的顺序消费。
C.Logstash定时拉取
场景:用户行为日志的T+1分析场景。该方案低侵入但高延迟。
适用性分析:
- 优点:零代码改造,适合历史数据迁移。
- 致命伤 :
- 分钟级延迟(无法满足实时搜索)
- 全表扫描压力大(需优化增量字段索引)
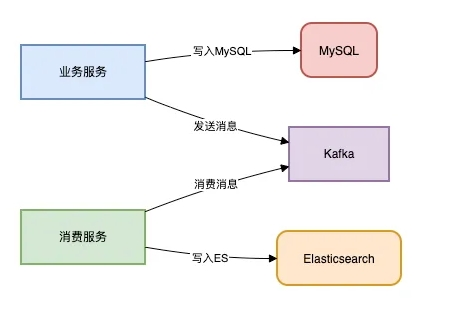
D.Canal监听Binlog
场景:社交平台动态实时搜索(如微博热搜更新)。
技术栈:Canal + RocketMQ + ES
该方案高实时,并且低侵入。
架构流程如下:
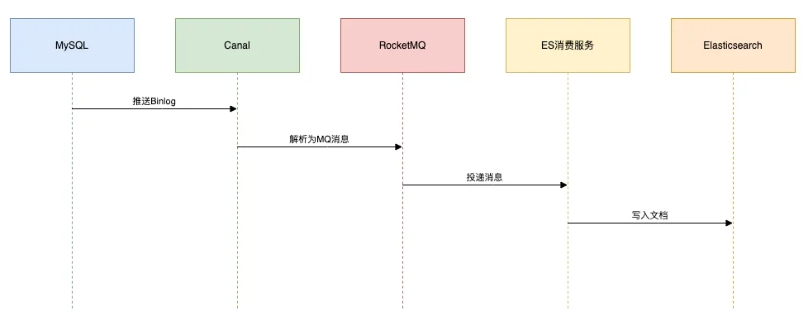
避坑指南:
- 数据漂移:需处理DDL变更(通过Schema Registry管理映射)。
- 幂等消费 :通过
_id唯一键避免重复写入。
E.DataX批量同步
场景:将历史数据从分库分表MySQL迁移至ES。该方案是大数据迁移的首选。
性能调优:
- 调整
channel数提升并发(建议与分片数对齐) - 启用
limit分批查询避免OOM
F.Flink流处理
场景:该方案适合于复杂的ETL场景。
优势:
- 状态管理:精准处理乱序事件(Watermark机制)
- 维表关联:通过Broadcast State实现实时画像关联
同步方案汇总
| 方案 | 实时性 | 侵入性 | 复杂度 | 适用阶段 |
|---|---|---|---|---|
| 同步双写 | 秒级 | 高 | 低 | 小型单体项目 |
| MQ异步 | 秒级 | 中 | 中 | 中型分布式系统 |
| Logstash | 分钟级 | 无 | 低 | 离线分析 |
| Canal | 毫秒级 | 无 | 高 | 高并发生产环境 |
| DataX | 小时级 | 无 | 中 | 历史数据迁移 |
| Flink | 毫秒级 | 低 | 极高 | 实时数仓 |
4.索引设计问题
- 整个项目索引我应该如何规划?
- 每天几百 GB 增量实时数据的TB级甚至PB级别的大索引如何设计?
- 分片数和副本数大小如何设计,才能提升 ES 集群的性能?
- ES 的 Mapping 该如何设计,才能保证检索的高效?
- 检索类型 term/match/matchphrase/querystring /match_phrase _prefix /fuzzy 那么多,设计阶段如何选型呢?
- 分词该如何设计,才能满足复杂业务场景需求?
- 传统数据库中的多表关联在 ES 中如何设计?
https://developer.aliyun.com/article/801913
5.索引规划原则
(1)时间序列 vs 业务实体
# 时间序列数据(适合按时间滚动)
- 日志、指标、监控数据
- 策略:按时间分索引(如 logs-2024.01.01)
- 优点:易于老化、清理、性能稳定
# 业务实体数据(按业务分索引)
- 商品、用户、文章
- 策略:按业务逻辑分索引(如 products、users)
- 优点:数据结构稳定,生命周期长关于时序索引问题:https://www.cnblogs.com/xguo/p/10558828.html
(2)索引生命周期策略
热阶段(Hot):7天,SSD,3副本,频繁查询
温阶段(Warm):30天,HDD,1副本,较少查询
冷阶段(Cold):90天,归档存储,只读
删除阶段(Delete):180天后自动删除**比如日志系统(ELK Stack):**保留策略:热数据7天 → 温数据30天 → 冷数据90天
6.ES宕机怎么办?
监控告警配置+灾备等等。
里面有好多问题需要考虑,毕竟刚开始就不想这么多了,遇到问题再说。
五、ES分片、副本、文档
1.分片:
分片是Elasticsearch中存储数据的基本单位。一个索引可以由多个分片组成,每个分片都是一个独立的Lucene索引,索引的文档上限是2,147,483,519(2³¹ - 129) 个文档。通过分片,Elasticsearch可以将数据分布到多个节点上,从而实现数据的分布式存储和并行处理。
A.优势:
- 水平扩展:通过增加分片数量,可以水平扩展索引的存储容量和处理能力。
- 并行处理:分片可以分布在不同的节点上,允许多个节点并行处理查询和索引请求,提高系统的性能和吞吐量。
- 数据分布:分片机制使数据可以分布在集群的多个节点上,减少单点故障的风险,提高数据的可用性和可靠性。
B.分片类型
Elasticsearch中的分片分为两种类型:
- 主分片(Primary Shard) :主分片是原始的数据分片,所有的写操作(如索引和删除)都首先作用于主分片。
- 副本分片(Replica Shard) :副本分片是主分片的复制品,用于提高数据的可用性和查询性能。副本分片接收来自主分片的数据更新,并在主分片不可用时提供冗余。
C.分片的分配
Elasticsearch在创建索引时,用户可以指定索引的分片数量。默认情况下,一个索引包含5个主分片。分片的数量一旦设置,主分片的数量是无法更改的 (除非重新创建索引)。然而,副本分片的数量可以在索引创建后动态调整。每个文档属于且仅属于一个主分片
2.副本
副本是主分片的完整复制品,它用于提高系统的容错能力和查询性能。每个主分片可以有多个副本分片,这些副本分片分布在集群的不同节点上。
A.副本的重要性
副本机制带来了以下好处:
- 高可用性:副本分片提供了数据冗余,当主分片所在节点出现故障时,副本分片可以提升为主分片,保证数据的可用性。
- 负载均衡:副本分片可以分担查询负载,减少主分片的压力,提高系统的查询性能和响应速度。
- 数据恢复:当节点发生故障时,副本分片可以用于快速恢复数据,减少系统的停机时间。
B. 副本的分配
副本分片的数量可以在索引创建时指定,默认情况下,每个主分片有一个副本分片。与主分片不同,副本分片的数量可以在索引创建后动态调整。Elasticsearch会自动管理分片和副本的分配,确保它们分布在集群的不同节点上,以最大限度地提高系统的容错能力和性能。
3.分片和副本的机制
3.1 分片的创建和分配
当创建一个新索引时,Elasticsearch会根据用户指定的分片数量创建主分片,并将这些分片分配到集群中的不同节点上。分片的分配过程如下:
- 分片创建:Elasticsearch根据索引的分片设置,创建指定数量的主分片。
- 分片分配:Elasticsearch将主分片分配到集群中的不同节点上,确保分片均匀分布。
- 副本创建:Elasticsearch根据索引的副本设置,为每个主分片创建副本分片。
- 副本分配:Elasticsearch将副本分片分配到与主分片不同的节点上,确保数据冗余。
3.2 数据写入过程
在Elasticsearch中,数据的写入过程包括以下步骤:
- 写请求发送到主分片:所有的写操作(如索引和删除)首先发送到主分片。
- 主分片处理写请求:主分片处理写请求,将数据写入到分片中。
- 写请求同步到副本分片:主分片将写操作同步到所有的副本分片,确保数据的一致性。
- 写操作完成:当所有副本分片确认写操作后,Elasticsearch返回写操作的结果。
3.3 数据读取过程
在Elasticsearch中,数据的读取过程包括以下步骤:
- 读请求发送到协调节点:客户端将查询请求发送到Elasticsearch集群中的任意节点,该节点作为协调节点处理请求。
- 协调节点 路由 请求:协调节点将查询请求路由到相关的主分片和副本分片。
- 分片并行处理查询:主分片和副本分片并行处理查询请求,返回查询结果。
- 协调节点汇总结果:协调节点汇总所有分片的查询结果,并返回给客户端。
4.文档如何到分片
当一个文档写入索引时:
java
文档写入请求 → 提取路由值 → 哈希计算分片号A.提取路由值:三种路由策略:
1. 默认路由:使用文档ID作为路由值
PUT /index/_doc/123 # 路由值 = "123"
2. 显式路由:指定自定义路由值
PUT /index/_doc/123?routing=user_456 # 路由值 = "user_456"
3. 时间路由:基于时间戳的路由(用于时序数据)B.哈希计算分片
计算公式:shard_num = hash(_routing) % number_of_primary_shards
-
_routing默认等于文档ID -
计算结果决定文档存储在哪个主分片
比如假如hash计算值16,分片5,16%5=1,那么分配到主分片1.
java
1. 客户端发送:PUT /products/_doc/1001
2. 协调节点计算:hash("1001") % 3 = 1
3. 确定分片:分片1(在节点B上)
4. 转发请求:发送到节点B的主分片1
5. 副本同步:同时发送到节点C的副本分片1
6. 确认返回:多数副本确认后返回成功5.分片数量设置如何合理?
A.数据量驱动法
(1)如何预估数据量
从四个维度存储空间、文档数量、业务增长、查询性能来评估。
基础存储计算:
java
# 单文档存储估算
文档原始大小 = sum(所有字段的原始数据大小)
# Elasticsearch存储开销系数
存储系数 = 索引开销 + 倒排索引 + DocValues + _source存储
# 典型系数参考
普通文本字段:原始大小 × 2.0-3.0倍
数值字段:原始大小 × 1.2-1.5倍
keyword字段:原始大小 × 1.5-2.0倍
嵌套对象:额外增加30-50%开销分场景存储系数表:
| 场景 | 压缩前系数 | 启用压缩后系数 | 说明 |
|---|---|---|---|
| 日志全文检索 | 3.0-4.0倍 | 2.0-2.5倍 | 文本多,索引开销大 |
| 指标监控 | 1.5-2.0倍 | 1.2-1.5倍 | 数值为主,开销小 |
| 商品目录 | 2.0-2.5倍 | 1.5-2.0倍 | 混合类型 |
| 用户画像 | 2.5-3.5倍 | 2.0-2.5倍 | 稀疏字段多 |
案例如下:
增长模式识别:
java
# 线性增长模型
每日新增文档数 = 基准数 × (1 + 日增长率)^天数
# 季节性调整
节假日系数 = 1.5-3.0倍
促销期系数 = 5.0-10.0倍
# 业务事件影响
新功能上线:可能带来2-10倍增长
市场扩张:按新市场比例计算增长率分析:
| 业务阶段 | 年增长率 | 数据量翻倍周期 |
|---|---|---|
| 初创期 | 200-500% | 3-6个月 |
| 成长期 | 50-150% | 8-18个月 |
| 成熟期 | 10-30% | 2-5年 |
| 衰退期 | -5-10% | N/A |
索引开销细分:
java
1.典型分布(文本密集型):
_source存储: 40-60%
倒排索引: 25-35%
DocValues: 10-20%
其他开销: 5-10%
2.# 可优化的存储项
if 字段仅用于过滤:
可禁用 norms: 节省 1字节/文档/字段
可禁用 index_options: 节省 2-4字节/词项
if 字段仅用于展示:
可禁用索引: store_only = true
if 历史数据:
可启用更高压缩级别(2)根据数据量预估分片数
| 数据量 | 推荐分片数 | 说明 |
|---|---|---|
| < 10GB | 1-2个 | 避免过度分片 |
| 10-100GB | 2-5个 | 平衡并行度和开销 |
| 100GB-1TB | 5-20个 | 根据查询复杂度调整 |
| 1-10TB | 20-100个 | 需要仔细规划 |
| > 10TB | 100+个 | 分索引+分片组合策略 |
B.查询性能方式
(1)查询类型影响:
-
简单查询:较少分片(减少协调开销)
-
复杂聚合:较多分片(并行计算优势)
-
高并发点查:中等分片(负载均衡)
(2)并行度公式:
java
理想并行度 = min(CPU核心数 × 0.75, 数据分片数)
# 建议:每个查询能利用2-8个分片并行处理C.写入吞吐量方式
写入场景:
-
高吞吐写入:较多分片(并行写入)
-
低频写入:较少分片(减少管理开销)
-
时序数据:按时间分片(如每天一个分片)
高吞吐 指的是系统在单位时间内 能够处理的最大工作量。
D.案例:一个中型电商平台,需要将订单数据存入Elasticsearch用于实时搜索和分析
|-------|------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 评估 步骤 | 步骤名称 | 示例 |
| 1 | 数据特征分析 | 单订单文档结构: - 订单基础信息:200字节 - 商品信息(平均3个商品):3 × 150字节 = 450字节 - 用户信息:100字节 - 支付物流信息:150字节 - 总原始大小:约 900 字节 ≈ 0.9KB |
| 2 | 业务规模评估 | 日订单量:10,000单 数据保留期:2年(730天) 日增长率:保守估计 10%/月 |
| 3 | 计算 | # 基础数据量 年订单量 = 10,000单/天 × 365天 = 365万单 # Elasticsearch存储系数(含索引开销) 存储系数 = 2.0 # 中等文本和数值混合 # 存储计算 原始数据年总量 = 365万 × 0.9KB ≈ 3.2TB ES存储年总量 = 3.2TB × 2.0 = 6.4TB |
| 4 | 增长模型 | # 考虑每月10%增长 第1个月:10,000单/天 第12个月:10,000 × (1.1)^11 ≈ 28,500单/天 第24个月:28,500 × (1.1)^12 ≈ 89,500单/天 # 2年总数据量估算 总订单数 ≈ 约 5,000万单 总ES存储 ≈ 5,000万 × 0.9KB × 2.0 ≈ 90TB |
| 5 | 分片规划 | # 目标:每个分片30GB 总数据量 = 90TB 总分片数 = 90TB ÷ 30GB/分片 = 3,000个分片 # 实际建议: 1. 按时间分索引(每月一个索引) 2. 每月索引数据量 ≈ 90TB ÷ 24 ≈ 3.75TB 3. 每月分片数 = 3.75TB ÷ 30GB ≈ 125个分片 4. 初始配置:每月索引设置 10个分片(支持后期扩容) |
| 6 | 硬件需求 | 基于2年90TB数据规划: - 节点数:至少10个数据节点 - 单节点存储:90TB ÷ 10 ÷ 副本数2 ≈ 4.5TB/节点 - 实际配置:每个节点配6TB SSD(预留30%缓冲) - 内存:每个节点32GB(堆内存16GB) - 总分片数:每月10分片 × 24月 = 240个活跃分片 - 分片/节点:240 ÷ 10 = 24个分片/节点(合理) |
仅代表个人想法,若有不对,欢迎指正。
六、解决报错
1.报错信息
java
{
"msg": "Index [stuInfo] not found.; nested exception is [stuInfo] ElasticsearchStatusException[Elasticsearch exception [type=invalid_index_name_exception, reason=Invalid index name [stuInfo], must be lowercase]]",
"code": 500
}-
根本原因 :Elasticsearch 索引名必须是全小写
-
直接表现:Elasticsearch 不支持大写字母的索引名
部分内容引用