部分内容由AI生成
一、问题与背景
葡萄酒分为白葡萄酒和红葡萄酒。白葡萄酒用白葡萄或皮红肉白的葡萄分离发酵制成。酒的颜色微黄带绿,近似无色或浅黄、禾秆黄、金黄。葡萄的营养很高,而以葡萄为原料的葡萄酒也含有多种氨基酸、矿物质和维生素,这些物质都是人体必需补充和吸收的营养物质。目前,已知的葡萄酒中含有的对人体有益的成分大约有600种。葡萄酒的营养价值由此也得到了广泛的认可。[1]
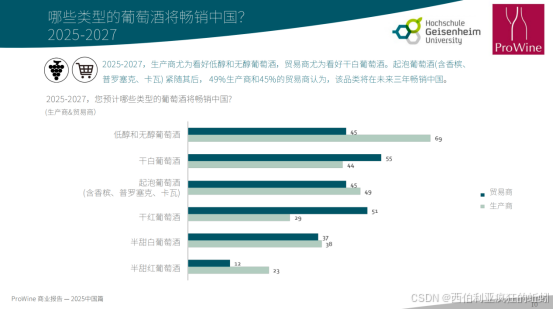
2025年德国盖森海姆大学葡萄酒与饮品商业研究院在 ProWine 香港酒展发布的一项重要研究成果表明,在整体葡萄酒市场增长趋缓的背景下,白葡萄酒正异军突起,被国际生产商和中国经销商共同列为 2027 年前最具增长潜力的酒类。该报告强调:"到 2027 年,干白葡萄酒将成为最受欢迎的葡萄酒类型,其行业评价已超越红葡萄酒。"[2]
对白葡萄酒供应商来说,通过科学方法与数据工具深入解析白葡萄酒的成分特征与品质关联,实现生产优化与质量提升,对建立自身竞争优势和行业壁垒有重要作用。基于此,本研究将对白葡萄酒质量数据进行深入分析,期望找出对白葡萄酒品质影响很大但成本较低的调控变量,从而指导生产端进行更精准的工艺参数调整,在控制成本的同时提升品质稳定性。
二、数据处理与分析
(一)数据理解
原始数据集包含4898个样本,12个字段,具体含义及其解释如下:

(二)数据预处理
1.描述性统计分析与可视化
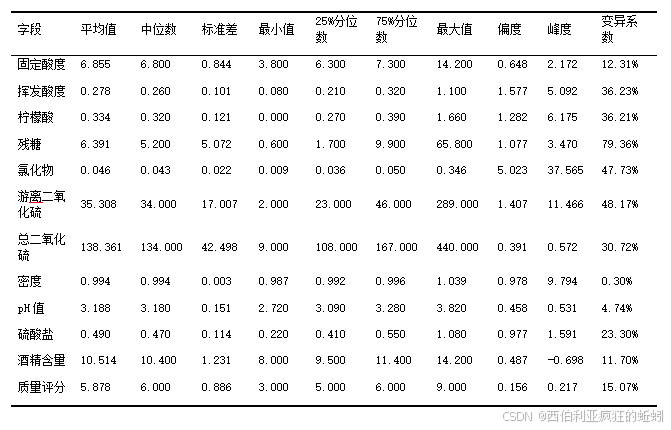
以下是对所有数据的统计汇总表。
(1)固定酸度
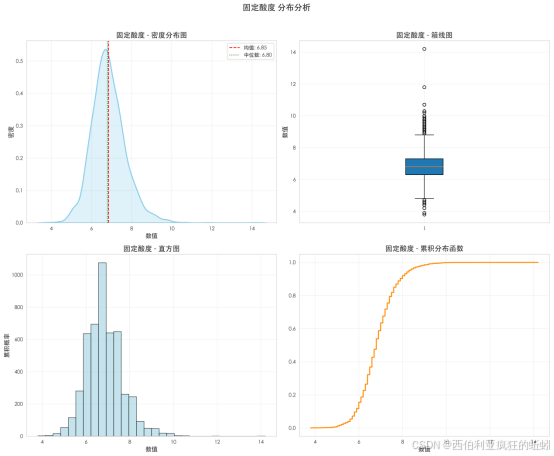
固定酸度整体呈现以中位数(6.80 g/L)为中心、轻微右偏的集中分布。密度曲线主峰陡峭,集中于6.0--7.5 g/L区间,表明绝大多数样本酸度稳定;右侧存在平缓长尾,导致均值(6.85 g/L)略高于中位数。直方图进一步显示,数据在6.0--8.0 g/L形成明显峰值,右侧尾部延伸更长。箱线图反映主体数据集中,但上界以外存在少数高值异常点。累积分布曲线显示,超过80%的样本酸度低于7.5 g/L,此后增长趋于平缓。整体表明,行业内固定酸度普遍控制在经典范围内,少数样本可能因自然或工艺因素显著偏高。
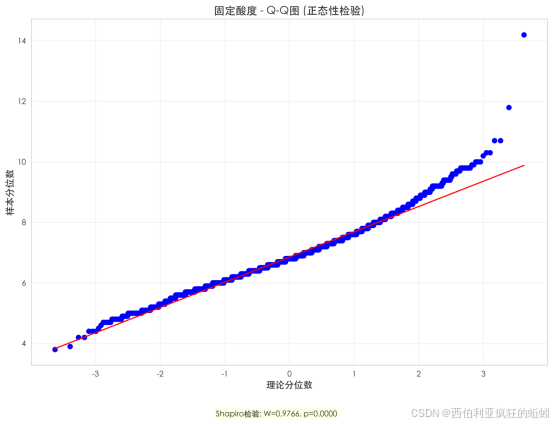
固定酸度分布具有显著右偏特征。Shapiro-Wilk检验结果(W=0.9766,p=0.0000)与Q-Q图一致,确认其显著偏离正态分布。虽然中部数据与正态分布拟合较好,但上尾部明显厚重,导致均值高于中位数,并在箱线图中体现为一系列高值异常点。综上,多数葡萄酒固定酸度处于中等水平,同时存在不容忽视的高酸度"长尾",可能关联特定风土、品种,或为研究酸度对质量影响的关键区间。
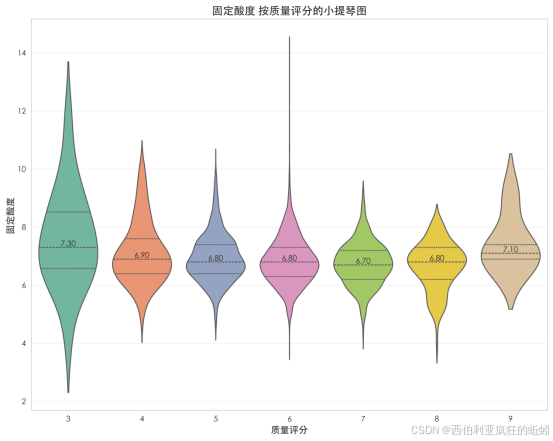
固定酸度随质量评分呈现规律性变化。低评分酒(3--4分)分布离散,小提琴图宽而平,表明酸度控制不稳定,存有较多极端值。随着评分升至中高水平(5--8分),分布明显收敛,酸度高度集中于6.5--7.5 g/L狭窄区间,反映工艺控制趋于精确。而在最高评分组(9分),分布并未继续收敛,均值(7.10 g/L)较中评分组回升,分布宽度略增,或说明顶级酒款对较高酸度具备更好包容性,亦可能代表不同风格取向。各组均值呈"U型"趋势,揭示固定酸度与葡萄酒质量之间存在复杂非线性关系。
(2)挥发酸度
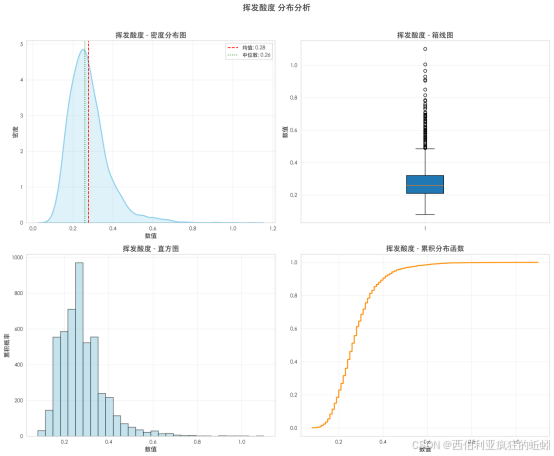
挥发酸度呈显著右偏分布。密度曲线在低值区形成陡峭主峰,并向右延伸出衰减长尾,导致均值(0.28)高于中位数(0.26)。直方图显示数据高度集中于0.1--0.4区间,其后频数急剧下降。箱线图表明中间50%数据紧凑,但上方存在多个离散高值异常点。累积分布曲线在0.4以下快速上升,涵盖超80%样本,随后趋于平缓。整体表明,绝大多数葡萄酒挥发酸度控制在较低水平,但存在不容忽视的高值长尾,可能对应缺陷样本。
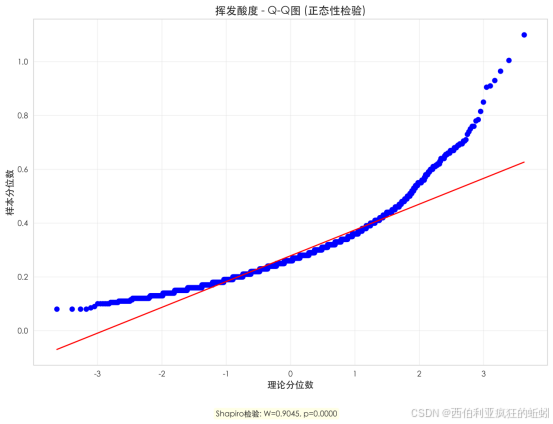
挥发酸度分布严重右偏,显著偏离正态。Q-Q图显示数据点在上尾部明显上翘,呈现"厚尾"特征。Shapiro-Wilk检验(W=0.9045, p=0.0000)进一步证实其非正态性。这表明数据集中存在一个挥发酸度显著偏高的子集,对应潜在的醋酸缺陷风险。因此,该分布由密集低值主体与延伸的高值长尾构成,预示挥发酸度对葡萄酒质量可能具有阈值效应的强负向影响。
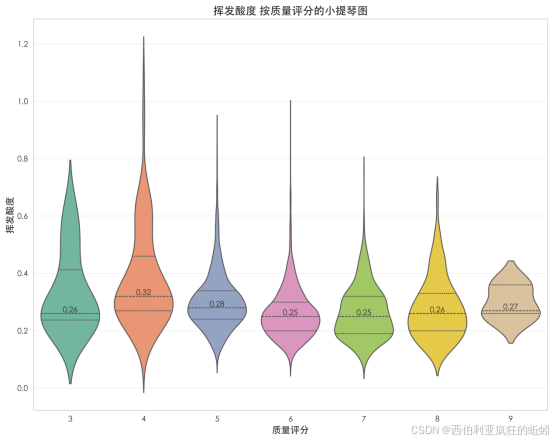
挥发酸度随质量评分呈现规律变化。低质量酒(如4分)中位数最高(0.32),且分布离散,包含较多高值样本,反映工艺控制问题。中等质量酒(5--7分)挥发酸度严格控制在低位,分布集中对称(中位数0.25--0.28),体现稳定酿造水平。高质量酒(8--9分)仍保持集中,但9分组分布略宽、中位数微升(0.27),暗示顶级酒款对微量挥发酸度容忍度稍高。整体上,挥发酸度与质量呈复杂关联:在低质量区间与评分负相关,在高质量区间则稳定于低水平,表明将其控制在阈值以下是获得优质评价的关键前提。
(3)柠檬酸
柠檬酸含量呈近似对称的集中分布,均值与中位数基本重合于0.33,无明显偏斜。直方图与密度曲线显示,数据高度集中于0.2--0.4区间,超四分之三样本位于此范围,反映该成分在生产中控制相对稳定。分布两端存在细长尾部,箱线图显示上下两侧均有少量异常值,高值端更为突出。累积分布曲线在核心区间迅速上升,尾部趋于平缓,进一步体现数据集中与尾延并存的特征。整体表明,柠檬酸在绝大多数样本中为受控稳定指标,仅极少数样本存在显著偏离。
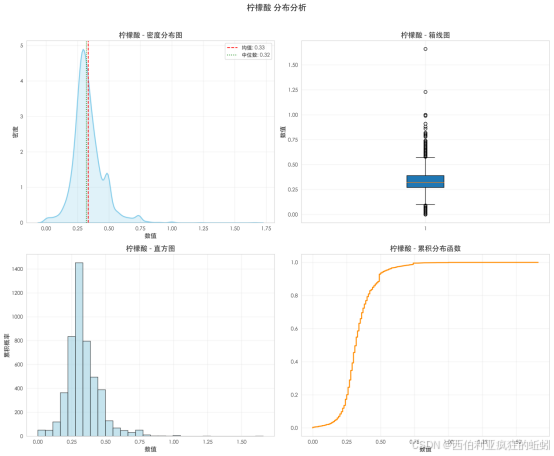
Q-Q图及Shapiro-Wilk检验(W=0.9222,p=0.0000)证实其显著偏离正态分布。虽然中部数据与正态分布吻合较好,但上尾部明显更厚,对应箱线图中的高值异常点,表明数据中包含一个较高柠檬酸含量的样本子集。整体上,多数葡萄酒柠檬酸含量集中于中低水平,同时存在指向更高含量的"长尾",可能关联特定品种、风土或工艺,是研究酸度对质量影响的关键区间。
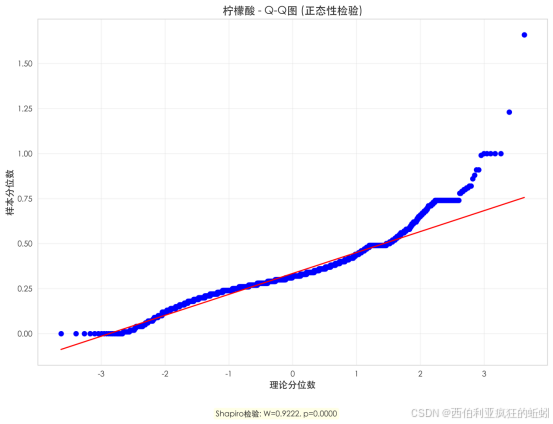
柠檬酸含量随质量评分呈"U型"分布。低质量酒(3分)与顶级酒(9分)中位数较高(分别为0.34和0.36),而中等质量酒(4--8分)含量稳定在较低窄区间(0.29--0.32)。低分组分布离散,反映控制不稳;中等组分布集中对称,体现工艺精确;高分组范围略宽但主体仍集中。这表明柠檬酸与葡萄酒质量存在复杂非线性关系:含量过低或过高均可能影响评价,但顶级酒款能较好融合较高柠檬酸,凸显成分平衡的重要性。
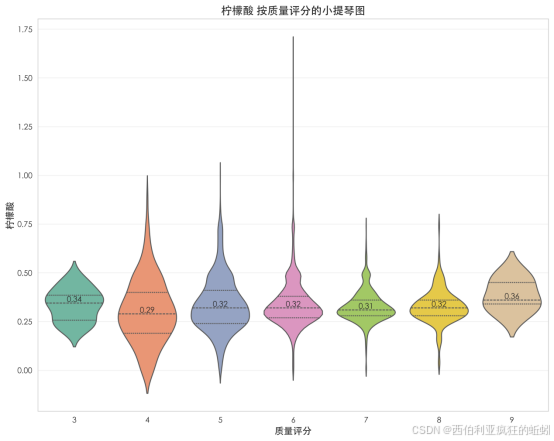
(4)残糖
残糖含量呈显著右偏分布。均值(6.39)明显高于中位数(5.20),反映少数高值样本拉高了整体水平。直方图显示绝大多数样本集中在10以下,频数分布高度集中;超过此范围后频数急剧下降,但仍有少数样本散布至高值区间。箱线图显示中间50%数据集中,但上界外存在大量高值异常点,可能对应特定类型甜酒。累积分布曲线显示约80%样本残糖处于较低水平,随后曲线趋于平缓。整体表明,数据以低残糖样本为主体,同时存在显著的高残糖尾部,对应从干型到甜型的风格连续体。
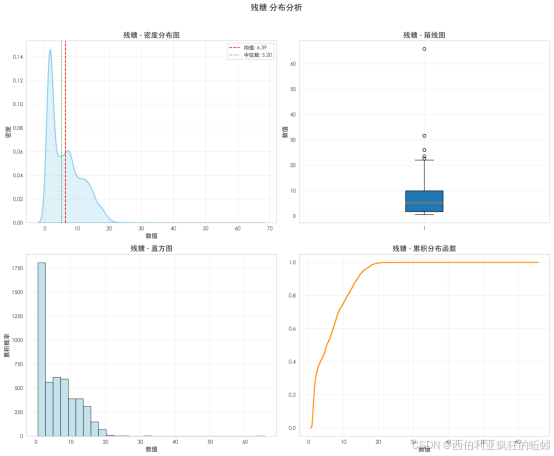
残糖分布呈现极端右偏,显著偏离正态。Q-Q图显示数据点持续偏离理论正态线,上尾部剧烈上扬,表明存在大量极端高值样本。Shapiro-Wilk检验(W=0.8846, p=0.0000)统计上确证了其非正态性。这表明数据中存在一个残糖含量极高的显著子集,对应甜型乃至极甜型葡萄酒品类。因此,该分布由高度集中的低值"干型酒"主峰与厚重延展的高值"甜型酒"长尾构成,分析时需结合具体风格与酸碱平衡框架。
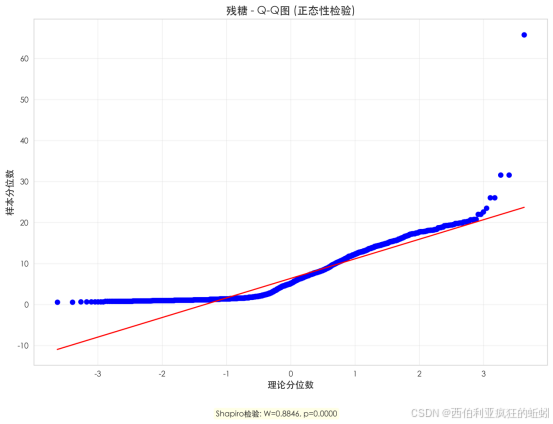
残糖含量与质量评分呈复杂非单调关系。中等评分酒(5-6分)残糖中位数相对较高,其中6分组分布最广且含极端高值,提示过高或失衡的残糖可能限制品质提升。高质量酒(7-9分)残糖中位数普遍较低且分布集中,反映顶级干型/半干型酒对残糖的精准控制。低质量酒(3-4分)残糖水平也较低,表明其品质缺陷主要源于其他因素。整体上,残糖作为"调节因子"而非"决定因子",其影响完全取决于与酸度等成分的整体平衡。六分组的异常分布尤其凸显"过高且未被平衡的残糖"与"平庸品质"间的潜在关联。
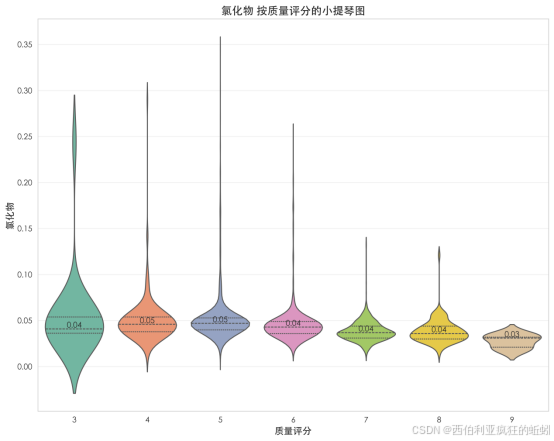
(5)氯化物
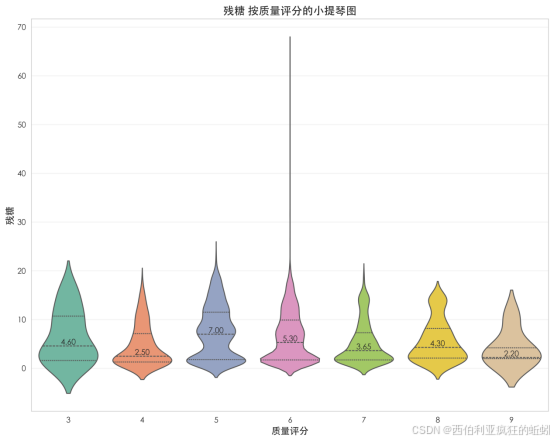
氯化物含量呈显著右偏分布。数据高度集中于0.10以下,密度曲线在此形成陡峭主峰,均值(0.05)高于中位数(0.04)。直方图显示绝大多数样本密集分布在接近零的低值区,频数随数值增加急剧衰减。箱线图表明主体数据集中,但上界外存在多个离散的高值异常点。累积分布曲线在初始阶段近乎垂直上升,显示约80%以上样本累积在极低范围,随后迅速平缓。整体表明,绝大多数葡萄酒的氯化物含量被严格控制在极低水平,但数据集中仍存在少数高值样本,值得进一步探查。
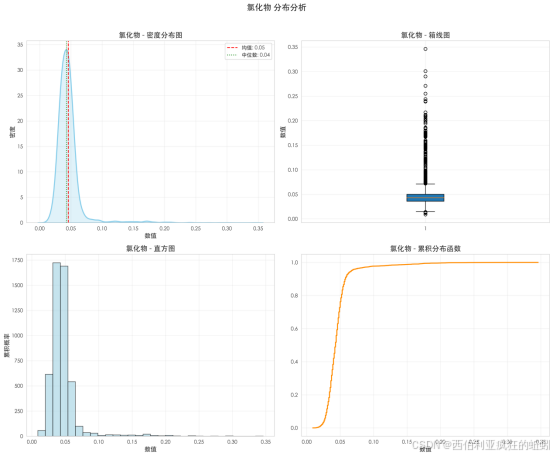
Q-Q图显示样本分位数从低值区即显著高于理论线,并持续急剧上翘,表明存在大量远超正态预期的高值样本。Shapiro-Wilk检验(W=0.5908, p=0.0000)在统计上确证了其与正态分布的显著偏离。这说明数据中包含一个规模可观的高值子集,可能对应氯化物含量异常升高的情况。因此,该分布由一个极度压缩的低值主体和一个厚重的高值尾部定义,预示其在分析中可能是一个对质量具有强负向影响的阈值型因子。
氯化物含量与质量评分呈明显负相关。随着评分从3分升至9分,氯化物中位数呈下降趋势,高质量酒(7分)中位数(0.03)显著低于低质量酒(3-5分,中位数0.05)。分布形态上,低分酒分布宽散,包含高值异常样本,显示控制水平参差;而高分酒(6-8分)分布高度集中,表明优质酒能普遍将氯化物含量精确控制在极低水平。这证实氯化物是一个需严格限制的潜在缺陷因子,其有效控制是获得高感官评价的重要基础。
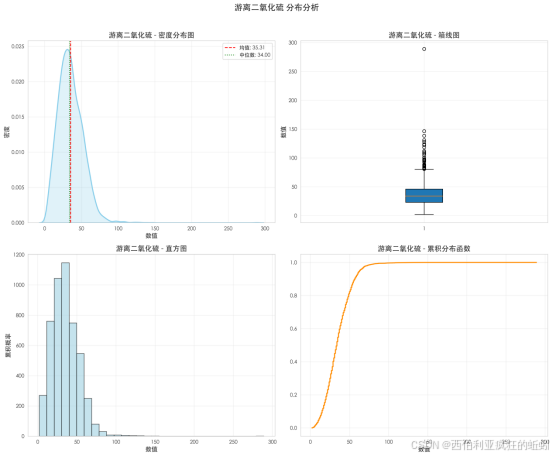
(6)游离二氧化硫
游离二氧化硫呈轻度右偏的集中分布,中位数为34.00。其分布主峰陡峭,集中在20-40区间,表明数据高度聚集;右侧存在平缓长尾,导致均值(35.31)略高于中位数,显示出不对称性。直方图进一步印证,绝大多数样本数值集中在60以下,频数随数值升高快速递减。箱线图显示数据主体紧凑对称,但上界外存在若干高值异常点。累积分布函数表明,超过80%样本集中于55以下,随后增长趋于停滞。整体而言,该分布显示游离二氧化硫在葡萄酒中普遍控制在中低水平,少数样本可能存在明显较高的添加或残留。
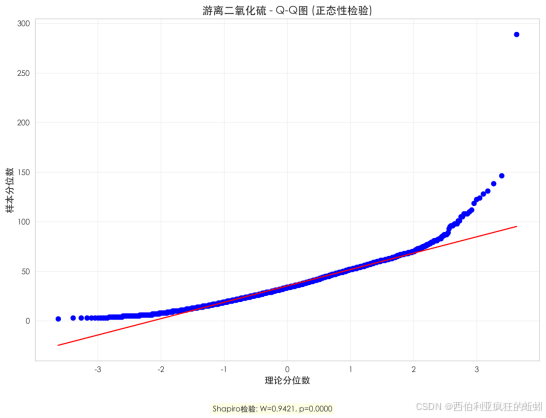
该图有效揭示了游离二氧化硫数据严重偏离正态分布,具有右偏、厚尾及明显异常值的特征。这不仅是重要的统计前提诊断,也为深入理解葡萄酒中该成分的控制现状和业务差异提供了切入点。建议后续分析据此调整方法,并对高值样本群体开展专项考察。
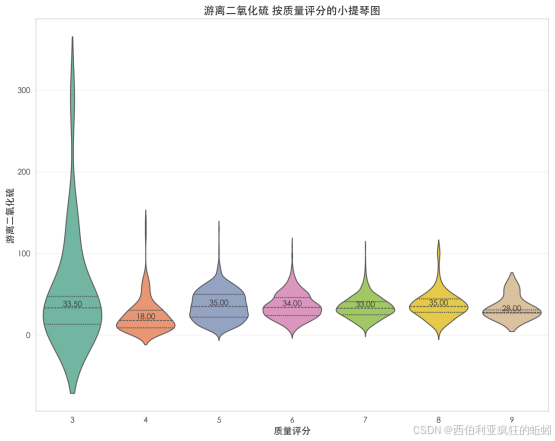
根据小提琴图分析,游离二氧化硫含量与葡萄酒质量评分呈明显非线性关系:低评分酒(3-4分)分布离散,显示控制不稳定;中等评分酒(5-8分)分布高度集中且对称,反映精确的工艺控制是其质量基础;而顶级酒(9分)分布中心上移且略宽,暗示其可能为陈年潜力或特定风格而策略性采用较高游离二氧化硫。
(7)总二氧化硫
总二氧化硫含量呈近似正态分布,整体较为集中,均值(138.36)与中位数(134.00)相近。密度曲线主峰圆润对称,大部分样本集中于100--180区间,符合常见工艺范围。均值略高于中位数,且曲线右侧尾部略长,显示存在轻微右偏。箱线图显示数据主体紧凑,但上下方均存在离散异常点,尤其高值区域,表明存在少数含量显著偏高或偏低的样本。累积分布曲线呈S型,中段上升陡峭,两端趋于平缓,反映数据集中、尾部延长的特征。整体表明,总二氧化硫在多数产品中含量稳定,但工艺或产品类型差异可能导致分布两端延伸。
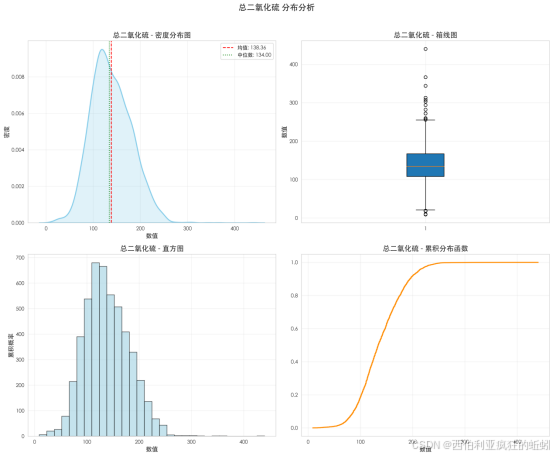
总二氧化硫分布呈现高度集中、轻微右偏的特征。Q-Q图显示其中部与正态分布高度吻合,但两端尤其是上尾部散点系统性上翘,表明实际分布尾部略厚于正态。Shapiro-Wilk检验(W=0.9890, p=0.0000)证实了轻微但显著的非正态性。因此,其分布可描述为"近似正态但具有轻微右偏厚尾",表明绝大多数葡萄酒的总二氧化硫含量被严格控制,同时存在一个包含少量较高含量样本的尾部,可能对应特定工艺或风格。
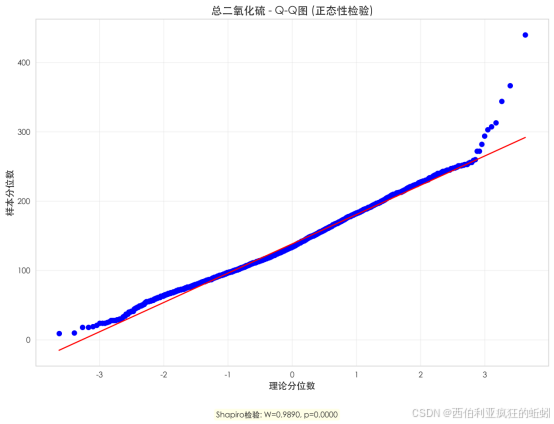
总二氧化硫含量与质量评分呈现规律性变化。低质量酒(3-5分)含量中位数显著偏高(如3分达159.50),且分布离散,表明添加量控制不稳定,可能存在过度添加。随着评分提升至6分及以上,含量系统性下降,分布急剧收敛。高质量酒(7-9分)含量被精确稳定在119-122 mg/L的狭窄区间内。这表明总二氧化硫并非越多越好,过高含量与低质量强相关;而能将其精准控制在相对较低水平,反映了在稳定性与感官纯净度之间取得平衡的酿造技艺,是获得高评价的关键。
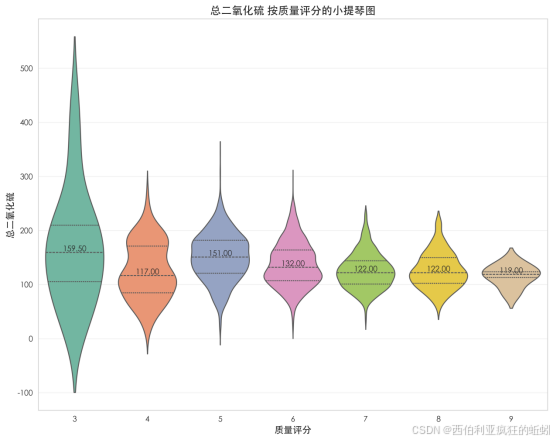
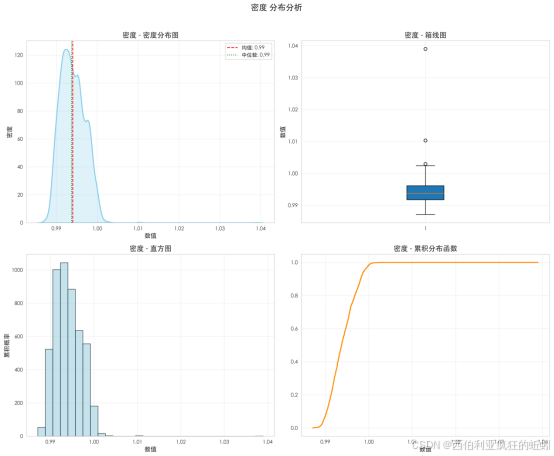
(8)密度
密度呈高度集中的对称分布。均值与中位数均为0.99,表明分布无偏斜。密度曲线主峰尖锐且对称,直方图显示数据高度集中于0.99附近极窄区间。箱线图中箱体极短,中位数居中,仅有个别邻近异常点。累积分布曲线呈陡峭S型,在极短区间内从接近0%升至接近100%。整体表明,葡萄酒密度受物理化学规律严格约束,在绝大多数样本中表现出高度一致性与稳定性。
密度分布高度集中于0.99-1.00区间。Q-Q图显示其中部与正态线基本重合,表明绝大多数样本密度被严格控制。Shapiro-Wilk检验(W=0.9548, p=0.0000)揭示存在统计显著但视觉细微的偏离,高值端散点轻微上翘,暗示存在一个密度略高的微小尾部。因此,该分布可描述为"高度集中、近似正态但具有轻微右偏厚尾",反映了葡萄酒作为标准化饮品的高度一致性,同时包容了因酒精度与残糖微小差异导致的有限变异。
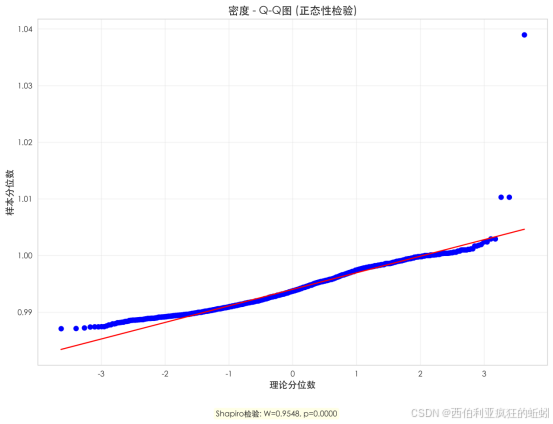
密度在不同质量评分组间表现高度一致。所有评分组(3-9分)的密度值均高度集中于0.99-1.00的极窄区间,中位数几乎相同(多为0.99)。各组小提琴图形状极其"瘦高"且位置基本重叠,表明密度作为物理属性,其变化范围严格受限,且不随感官质量发生系统性变化。这种高度的稳定性与集中性,使得密度在本数据集中成为一个近乎常量的背景属性,而非区分葡萄酒品质的关键变量。
(9)pH值
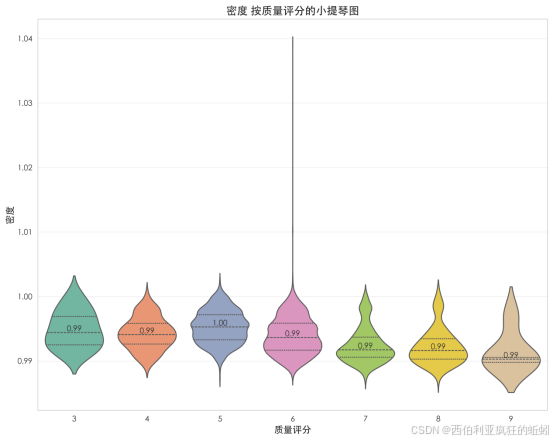
pH值呈近似对称的集中分布,均值为3.19。均值与中位数(3.18)基本重合,表明分布基本无偏。数据高度集中于3.0--3.4区间,形成分布主体。箱线图显示箱体长度适中,中位数居中,但上下方存在少数异常点,表明存在酸碱度显著偏离的个别样本。累积分布曲线呈S型,中段陡峭上升,两端趋于平缓。整体表明,pH值作为一项基础化学参数,在绝大多数样本中稳定围绕经典区间波动,同时包含有限的自然或工艺变异。
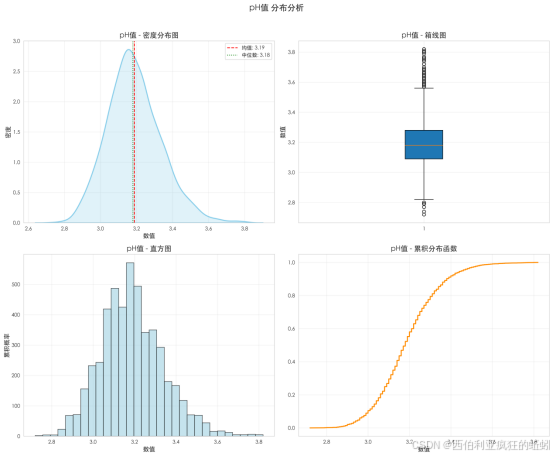
pH值分布虽近似钟形,但Q-Q图与Shapiro-Wilk检验(W=0.9881,p=0.0000)显示其与严格正态分布存在统计显著偏离,尤其在尾部。然而,其核心部分集中且对称,均值与中位数极为接近,绝大多数数据密集分布在3.0--3.4的典型区间内。因此,该分布可概括为"高度集中、对称但尾部存在可检测偏离的中性分布",在商业分析中可视为近似正态。
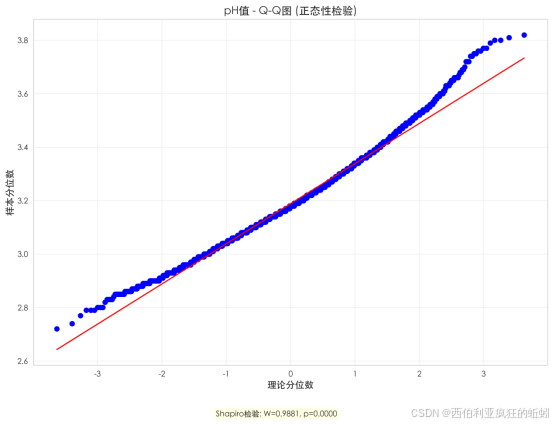
pH值分布随质量评分呈现规律变化。整体分布于2.6--3.8之间。低质量酒(3--4分)分布极宽且不规则,表明酸度控制不稳定,含较多极端低pH样本。随着评分升至中高水平(5--7分),分布显著收敛,pH高度集中于3.1--3.4窄区间,反映工艺精确稳定。值得注意的是,顶级酒款(8--9分)分布未进一步收紧,反而略拓宽且中位数轻微上移,暗示其对酸度平衡可能有更大宽容度或代表不同风格取向。各组中位数呈现先升后平的趋势。
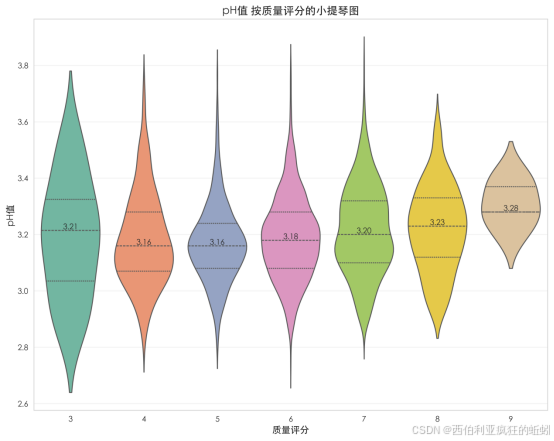
(10)硫酸盐
硫酸盐呈轻微右偏的集中分布,中位数为0.47。密度曲线主峰清晰,位于0.4--0.6区间,表明数据高度聚集;右侧延伸出平缓长尾,导致均值(0.49)略高于中位数。直方图显示绝大多数样本密集分布在0.7以下,频数随数值升高逐渐衰减。箱线图显示主体数据紧凑,但上界外存在数个明显偏离的高值异常点。累积分布曲线在0.65以下快速上升,涵盖超80%样本,随后趋于平缓。整体表明,硫酸盐含量在多数产品中围绕常见水平波动,少数样本可能存在显著更高的添加水平。
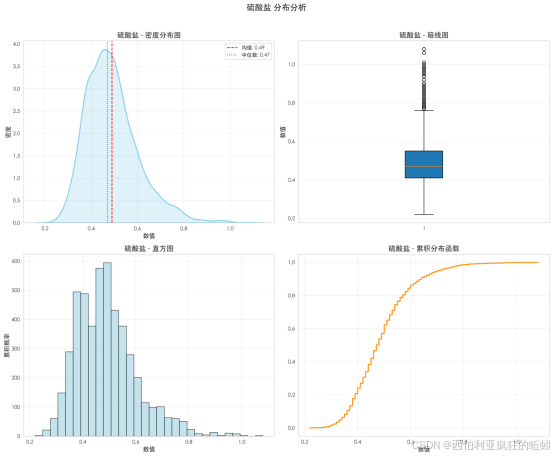
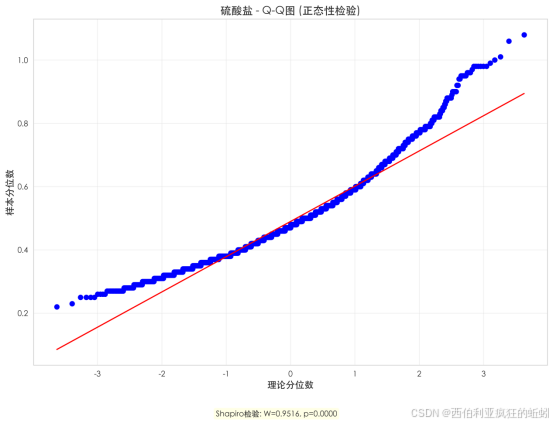
硫酸盐分布呈现主体近似正态、尾部加厚的右偏特征。Q-Q图显示其中间分位数与理论正态线基本吻合,但两端尤其是上尾部散点系统性上偏,形成"厚尾"。Shapiro-Wilk检验(W=0.9516, p=0.0000)统计上确认了该偏离。这表明尽管大多数葡萄酒的硫酸盐含量集中在常见范围内,但数据中包含一个不容忽视的高含量样本子集,可能对应特定工艺或调整需求,导致整体呈右偏厚尾形态。
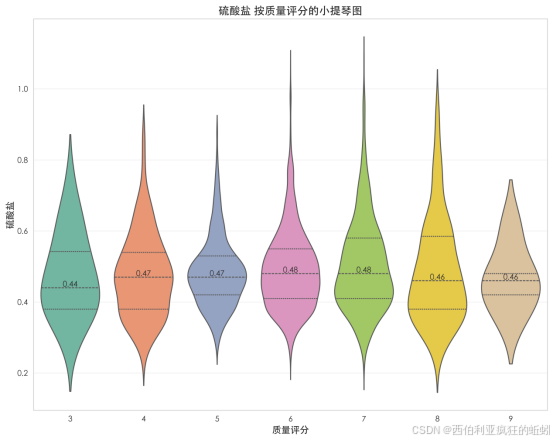
硫酸盐含量与质量评分呈现清晰的正向递增关系。随着评分从3分升至9分,其中位数从0.44 g/L系统性上升至0.69 g/L。中低评分酒(3--7分)含量较低且稳定,分布相对集中;而高评分酒(8--9分)含量显著跃升,分布范围向高端拓宽,顶级酒(9分)中容纳了更高数值。该格局表明,在本数据集中,较高的硫酸盐含量是伴随高感官评价的常见特征,可能通过增强酒体结构与口感清新度对品质产生积极贡献。
(11)酒精含量
酒精含量呈轻度右偏的集中分布,均值(10.51%)略高于中位数(10.40%)。密度曲线主峰位于9.5%--11%区间,显示大多数样本集中于此;右侧长尾表明高酒精度样本对整体分布有轻微拉动。直方图显示数据在8%--13.5%呈单峰,右侧衰减较缓。箱线图反映主体数据紧凑,但上须线较长且存在高值异常点,体现右尾延伸。累积分布曲线显示超过80%样本酒精度低于12%,随后增长趋缓。整体说明,葡萄酒酒精度在主流区间高度集中,同时市场包容部分高酒精风格的产品多样性。
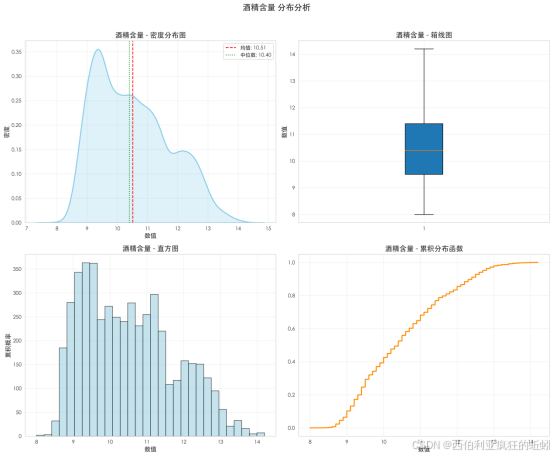
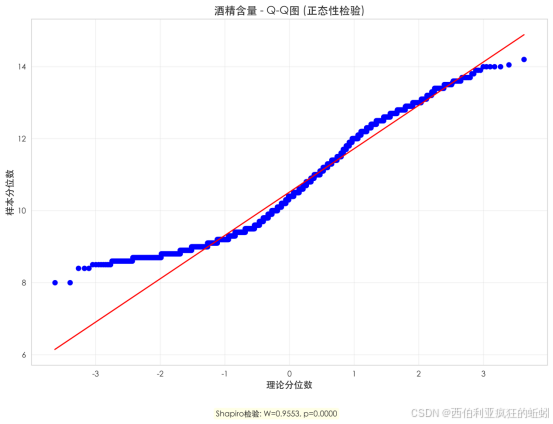
酒精含量分布呈现高度集中、轻微右偏特征。Q-Q图显示其中部与正态线基本吻合,但两端尤其是上尾部系统性上偏,表明分布尾部略厚于正态,存在高酒精含量的"长尾"。Shapiro-Wilk检验(W=0.9553, p=0.0000)确认了轻微但显著的非正态性。该分布可概括为"近似正态但具有可检测的右偏厚尾",反映市场主流产品酒精度相对稳定,同时涵盖因风土、品种或工艺导致的高酒精度产品类型。
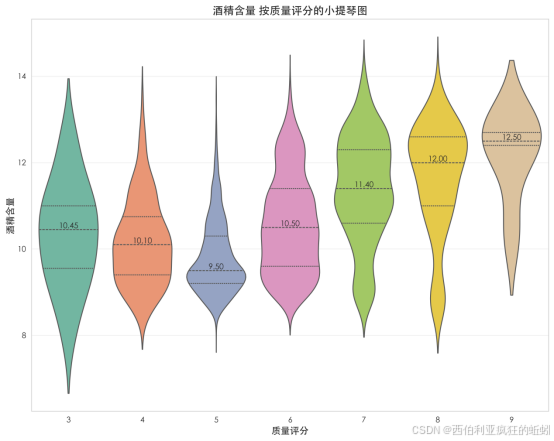
酒精含量与质量评分呈现清晰正向关联。随着评分从3分升至9分,酒精含量中位数从约10.1%系统上升至12.5%。低评分酒(3--5分)含量较低且分布较分散;随评分升高,分布整体上移并趋于集中,高质量酒(7--9分)数值稳定在较高狭窄区间。该格局表明,较高的酒精含量在本数据集中与优异的感官品质显著相关。
2.数据审查与异常处理
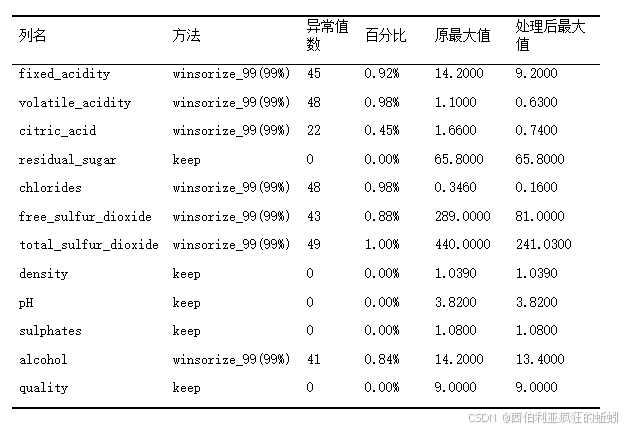
经过对数据集的审查,确认不存在缺失值。然而,基于前述描述性分析,发现包括残糖、氯化物、挥发酸度在内的多个特征呈现严重右偏且含有极端值。目标变量"质量评分"为有序多分类(3--9分),在后续建模中可按连续变量进行回归分析,也可作为分类变量处理。鉴于部分极值可能反映真实的产品特征(如甜型葡萄酒)而非错误数据,我们将遵循保守处理原则:在保留潜在业务信息的同时,控制其对模型的影响。具体预处理方法如下。

处理结果如下所示:
3.特征工程
经计算,特征间存在1对高度相关(|r|>0.8)及3对中度相关(|r|>0.5)关系。其中,残糖与密度呈现强正相关(r=0.839),最为突出。附图的相关性热图直观展示了各变量间关联的方向与强度(蓝色表示负相关,红色表示正相关)。该结果为后续的特征筛选与模型构建提供了直接参考。
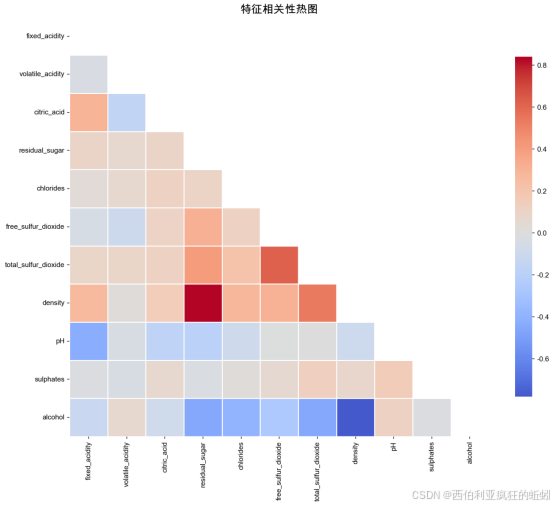
在VIF分析中,我们发现特征间存在严重的多重共线性问题。在全部11个特征中,9个特征VIF≥10,1个介于5-10之间,仅1个低于5。其中,density、pH和alcohol的VIF值异常高(分别为1085.83、611.66和123.64),表明它们几乎可由其余特征线性表示。这不仅印证了上一步中"残糖-密度"高度相关(r=0.8390)的结论,更揭示了共线性结构远比成对相关复杂,其影响更为广泛。
因此,必须在建模前采用特征筛选、正则化或主成分分析等方法处理该问题,以保证模型稳定性和解释可信度。
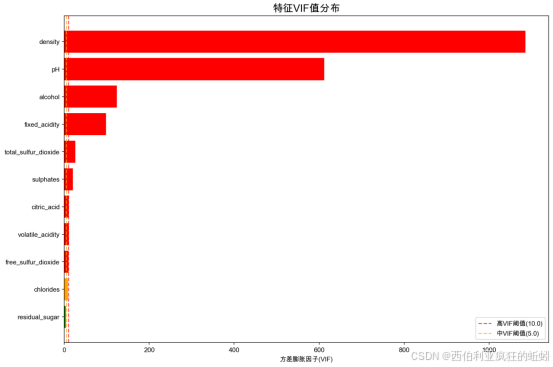
高VIF特征(前10个):
-
fixed_acidity: VIF = 98.48
-
volatile_acidity: VIF = 10.51
-
citric_acid: VIF = 10.72
-
free_sulfur_dioxide: VIF = 10.27
-
total_sulfur_dioxide: VIF = 25.95
-
density: VIF = 1085.83
-
pH: VIF = 611.66
-
sulphates: VIF = 20.53
-
alcohol: VIF = 123.64
基于特征间相关性的层次聚类分析(使用距离度量 1 - |r|,聚类阈值 0.7)识别出 2 个特征簇,结果通过树状图直观呈现(见下图)。聚类结果表明:
- 簇1:包含 fixed_acidity与 pH;
- 簇3:包含 residual_sugar、free_sulfur_dioxide、total_sulfur_dioxide、density与 alcohol。
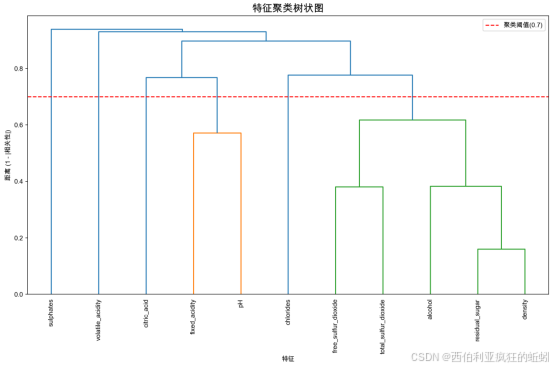
该结果与前期分析一致:簇3 中 residual_sugar与 density高度相关(r=0.8390),且 VIF 分析中 density、pH与 alcohol等特征呈现极高膨胀因子(VIF>100),进一步证实数据存在严重的多重共线性,尤其集中在簇3 的理化指标之间。
因此,在后续建模中,需采用特征筛选(如每簇保留代表性特征)或降维方法处理该问题,以提升模型稳定性与可解释性。
基于特征聚类识别出的高相关性特征组,为消除多重共线性对模型的影响,我们采用"每簇保留一个代表特征"的策略进行筛选。筛选时优先选择与目标变量"质量评分"相关性最高的特征,以确保保留的信息量最大化。具体筛选过程与结果如下:
簇1(酸性相关特征)
- 包含特征:fixed_acidity(固定酸度),pH。
- 筛选方法与结果:计算各特征与质量评分的相关性,保留相关性更高的特征。
- fixed_acidity与质量评分的相关性:0.1098
- pH与质量评分的相关性:0.0994
- 最终选择:fixed_acidity(固定酸度)
簇3(糖、二氧化硫及物理属性相关特征)
- 包含特征:residual_sugar(残糖),free_sulfur_dioxide(游离二氧化硫),total_sulfur_dioxide(总二氧化硫),density(密度),alcohol(酒精度)。
- 筛选方法与结果:计算各特征与质量评分的相关性,保留相关性最高的特征。
- alcohol(酒精度)与质量评分的相关性:0.4357
- density(密度)与质量评分的相关性:0.3071
- 其他特征相关性均低于 0.17
- 最终选择:alcohol(酒精度)
通过上述筛选,从两个高相关性特征簇中分别保留了固定酸度(fixed_acidity)和酒精度(alcohol)作为代表特征。此操作在有效缓解多重共线性的同时,最大程度地保留了与葡萄酒质量预测最相关的信息,为后续构建稳定且可解释的预测模型奠定了基础。经过处理改善情况如下:
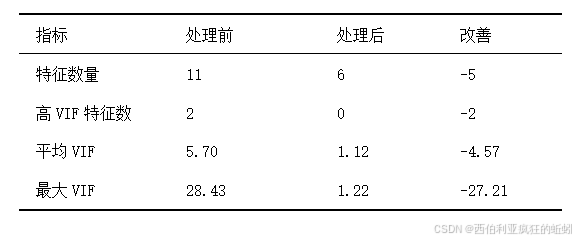
最终特征集
经再次检验,所有特征间的相关系数均低于0.8,表明严重的多重共线性问题已得到解决。当前特征与目标变量"质量评分"的相关性排序(前5位)如下:
- alcohol(酒精度): |r| = 0.4357
- chlorides(氯化物): |r| = 0.2253
- volatile_acidity(挥发酸度): |r| = 0.1925
- fixed_acidity(固定酸度): |r| = 0.1098
- sulphates(硫酸盐): |r| = 0.0537
其中,酒精度与质量评分呈现最显著的正相关,可作为后续建模中的关键预测变量。
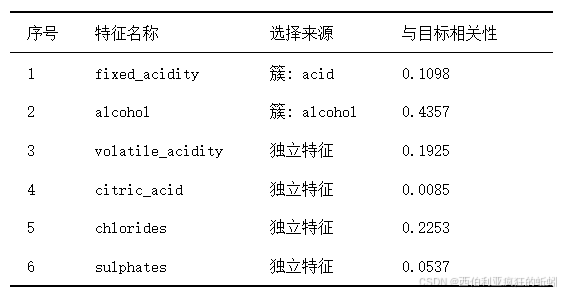
下面的四联图系统展示了多重共线性处理的全过程与显著成效。左上条形图显示,处理前多个特征(如密度,VIF>28)存在严重共线性;处理后所有特征VIF值均降至10以下,绝大多数低于5,问题得到有效控制。右上热图显示,处理后特征间仅存部分中等相关性,已无高度共线性。左下饼图表明,通过筛选保留了54.5%(6个)信息量最大的特征。右下柱状图进一步量化了改善效果:高VIF特征数量降至0个,中低VIF特征占比显著提升。整体而言,本阶段处理在消除共线性的同时,保留了核心预测变量,为后续建模奠定了稳定基础。
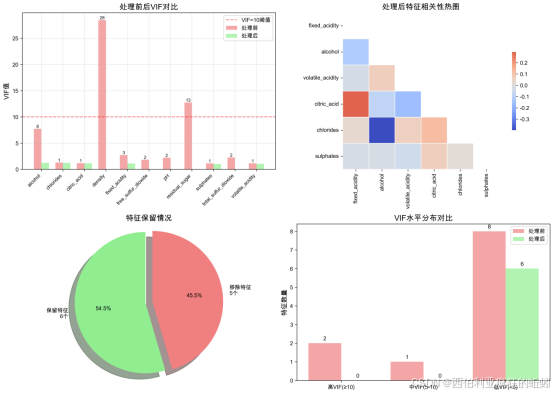
基于筛选后的关键变量进行分析,其与葡萄酒品质评分的线性关系均较弱:酒精含量(R²=0.190)解释力相对最高,但仍不足20%;氯化物、挥发酸度与固定酸度的解释力则更低。这表明单一化学指标对品质评分的影响有限,数据点分散也印证了品质成因的复杂性。因此,后续分析需采用多元建模方法,综合考虑变量间的交互效应与潜在非线性关系,以更全面地识别和解释影响品质的关键因素。
4.数据分布分析与调整
为了使数据更好地满足建模要求,我们对筛选后的特征进行了数据分布分析与调整。首先,对各特征的数据分布进行了深入观察,发现部分特征的分布仍存在一定的偏态,这可能会对模型的性能产生不利影响。
对于那些呈现右偏分布的特征,我们考虑采用合适的变换方法来改善其分布形态。这样做不仅可以提高模型的稳定性,还能增强模型对数据的拟合能力。具体采取以下办法。
特征变换详情
(1)fixed_acidity:
变换策略: none - 分布基本对称,无需幂变换
变换公式: 无
原始偏度: 0.3629
变换后偏度: 0.3629
偏度改善: 0.0000
原始范围: 3.8000, 9.2000
变换后范围: 3.8000, 9.2000
(2)alcohol:
变换策略: none - 分布基本对称,无需幂变换
变换公式: 无
原始偏度: 0.4621
变换后偏度: 0.4621
偏度改善: 0.0000
原始范围: 8.0000, 13.4000
变换后范围: 8.0000, 13.4000
(3)volatile_acidity:
变换策略: log - 右偏分布,对数变换可降低偏度
变换公式: log(x)
原始偏度: 1.1375
变换后偏度: 0.0488
偏度改善: 1.0886
原始范围: 0.0800, 0.6300
变换后范围: -2.5257, -0.4620
(4)citric_acid:
变换策略: log1p - 右偏分布且存在非正值,使用log(1+x)变换
变换公式: log(1 + x)
原始偏度: 0.8028
变换后偏度: 0.3751
偏度改善: 0.4277
原始范围: 0.0000, 0.7400
变换后范围: 0.0000, 0.5539
(5)chlorides:
变换策略: boxcox - 严重右偏分布,Box-Cox变换效果更佳
变换公式: Box-Cox(λ=-0.4178)
原始偏度: 3.5469
变换后偏度: -0.1186
偏度改善: 3.4282
原始范围: 0.0090, 0.1600
变换后范围: -14.7367, -2.7535
(6)sulphates:
变换策略: log - 右偏分布,对数变换可降低偏度
变换公式: log(x)
原始偏度: 0.9769
变换后偏度: 0.2337
偏度改善: 0.7432
原始范围: 0.2200, 1.0800
变换后范围: -1.5141, 0.0770
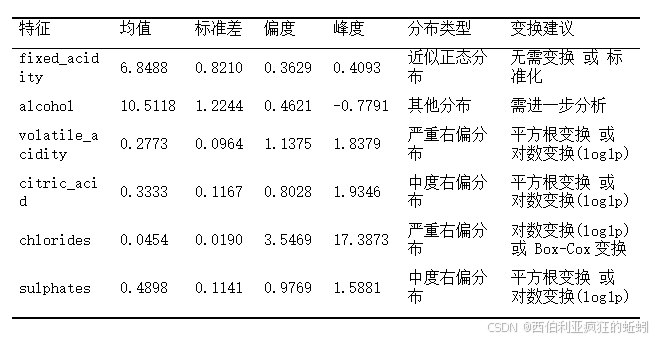
经过特征变换后的可视化图形如下所示。所选六个特征(固定酸度、酒精度、挥发酸度、柠檬酸、氯化物、硫酸盐)的直方图显示,数据分布均不同程度地偏离正态分布。KDE曲线(红色)与正态拟合曲线(绿色)在多数图中存在明显分离,直观证实了数据的非正态性,意味着线性模型假设可能不成立,建议在建模中考虑非线性变换(如对数变换、Box-Cox变换)或采用树模型等对分布假设要求较低的方法。
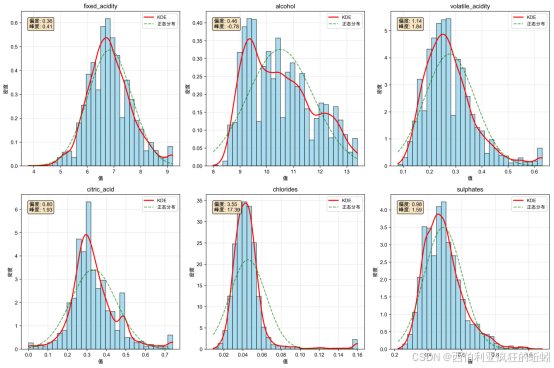
进一步执行标准化,结果如下。
fixed_acidity : 均值= 6.8488, 标准差= 0.8209
alcohol : 均值= 10.5118, 标准差= 1.2243
volatile_acidity : 均值= -1.3389, 标准差= 0.3342
citric_acid : 均值= 0.2840, 标准差= 0.0857
chlorides : 均值= -6.6136, 标准差= 1.1684
sulphates : 均值= -0.7391, 标准差= 0.2238
标准化后特征均值接近0: 0.000000
标准化后特征标准差接近1: 0.000102
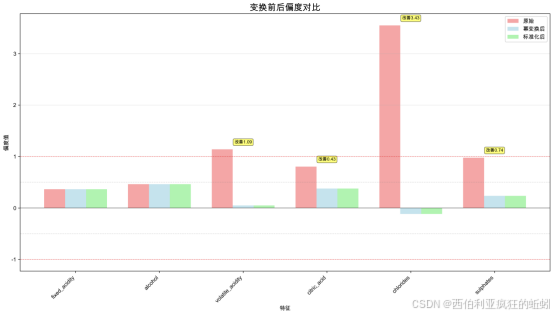
经标准化后,所有特征的偏度值均降至 0.5以下,表明其分布已调整为完全对称,符合常见建模算法对数据对称性的基本假设。若下游建模依赖特征对称性或假设数据近似正态,该处理可提升模型稳定性和解释一致性。
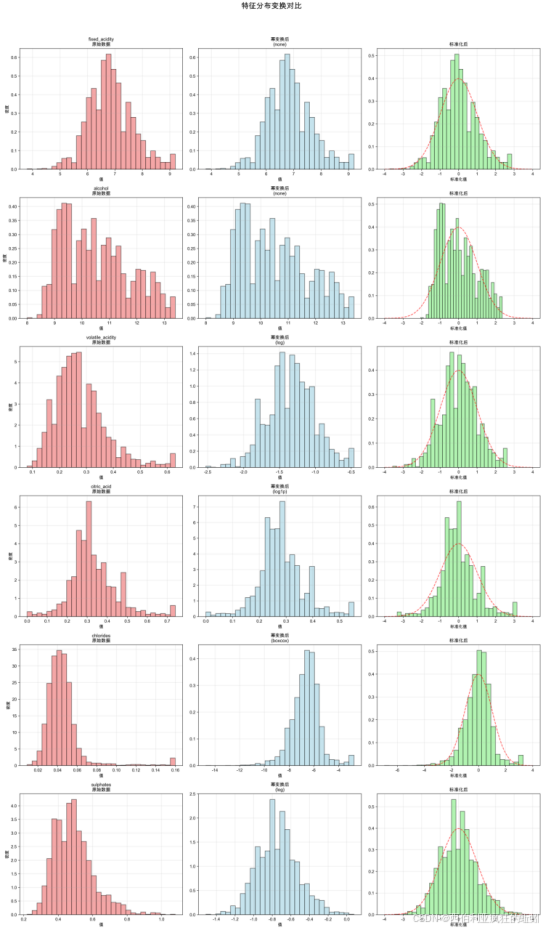
经过处理多数特征的分布轮廓变得更为连续、规整,有助于抑制个别极端值或微小波动对整体形态的干扰,提升数据对称性(如下图所示)。
下图左侧柱状图显示,所有特征与目标变量"品质"的绝对相关性在标准化后均发生了数值变化。这证实标准化不仅调整了数据尺度,也系统性地改变了各特征在统计上的线性关联强度。
下图右侧散点图进一步揭示,这种影响并非均匀。多数特征点(如各种酸度、氯化物等)紧邻 y=x参考线,说明其相关性变化微小。而酒精度点显著高于参考线,表明其相关性在标准化后得到了最大幅度的增强。这说明标准化过程可能更有效地"释放"了那些原本因量纲或分布形态而被掩盖的关键预测信号。
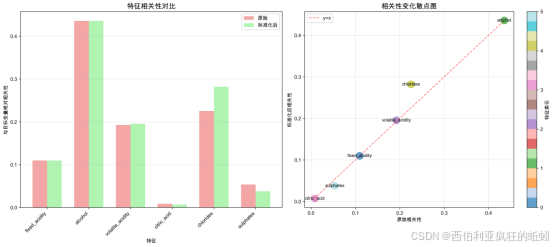
该图有效验证了标准化处理的价值。它不仅解决了数据量纲问题,还非均匀地重塑了特征与目标的相关性强弱,特别是显著强化了"酒精度"这一核心预测指标的主导地位,为构建稳健的葡萄酒品质预测模型奠定了坚实基础。
以下"特征变换效果雷达图"直观地展示了针对不同特征的差异化预处理策略及其综合效果评估,是特征工程关键步骤的精华总结。

fixed_acidity与 alcohol(none):未进行数学变换。这与前期分析中二者分布相对接近正态、偏度较小的结论一致,说明其原始尺度已适用于建模。
volatile_acidity(log):采用对数变换。这直接针对其先前识别的明显右偏态,旨在压缩高值区域,拉长低值区域,使分布更对称。
citric_acid(log1p):采用对数加1变换。此变换同样用于处理右偏,且能避免原始数据中可能存在零值时的数学错误(log(0)未定义),处理更为稳健。
chlorides(boxcox):采用Box-Cox变换。这表明该特征的分布问题最为复杂(极端右偏、尖峰厚尾),Box-Cox变换能自动寻找最佳参数,更有效地将其向正态分布转换。
(三)数据分析
1.多元回归
分别对标准化前数据和标准化后数据进行多元回归分析结果如下:
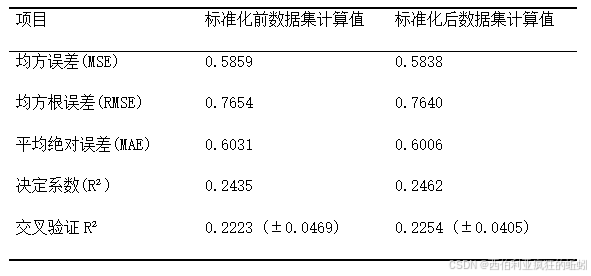
根据分析,多元回归模型对目标变量的解释力有限,仅能解释约24%的变异,预测误差均值约为±0.7单位,交叉验证结果(CV R²≈0.22)也表明模型稳定性一般,整体预测效果未达预期。因此,拟进一步采用随机森林与梯度提升树等方法进行建模尝试。
2.随机森林
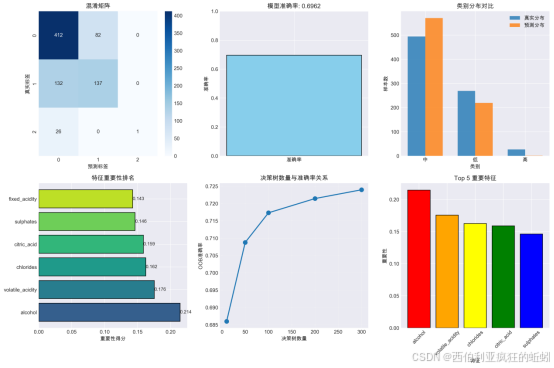
随机森林模型在数据标准化前后表现一致,验证集精度为 69.62%,这表明其建模过程不受特征尺度影响。相比之下,随机森林的预测表现明显优于多元回归模型,验证了树模型在该数据集上更具适用性。
随机森林模型配置如下:
- 模型类型: classification
- 决策树数量: 100
- 特征采样策略: sqrt
- 训练样本数: 3159
- 测试样本数: 790
分析报告:
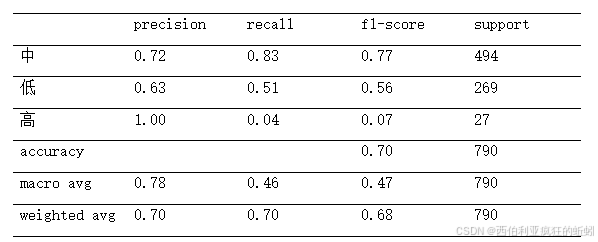
特征重要性排名:

关键发现:
- alcohol: 贡献度 21.4%
- volatile_acidity: 贡献度 17.6%
- chlorides: 贡献度 16.2%
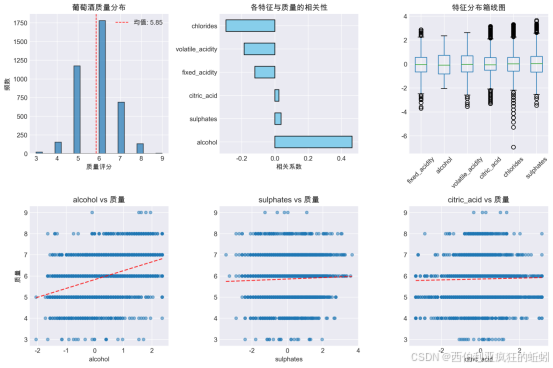
对标准化后数据集分析过程的可视化图表如下。
3.梯度提升树
本模型采用梯度提升回归树(GradientBoostingRegressor)构建,主要参数包括:树的数量为200,学习率为0.1,最大深度为7。
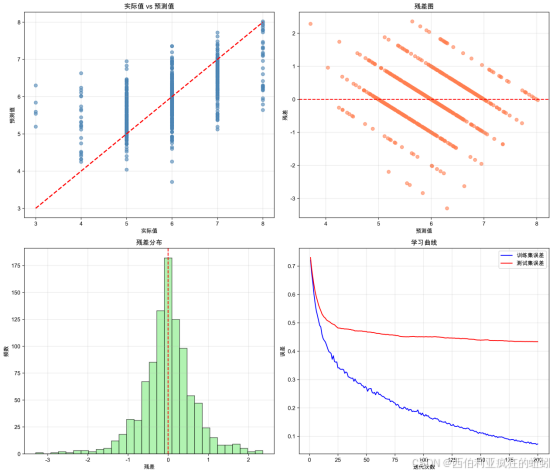
从评估结果看,模型在训练集上拟合效果优异(R²=0.9085),但在测试集上各项指标均显著下降(R²=0.4406),测试集均方误差(MSE)约为训练集的6倍,表明模型存在明显过拟合,泛化能力不足,目前尚不具备实际部署条件。建议后续通过交叉验证、正则化调整及超参数优化等方式提升模型稳定性。
附训练集:
- MSE: 0.0720
- RMSE: 0.2683
- MAE: 0.1919
- R2: 0.9085
附测试集:
- MSE: 0.4333
- RMSE: 0.6582
- MAE: 0.4657
- R2: 0.4406
三、洞察与建议
本节基于随机森林模型对白葡萄酒品质影响因素的深入分析,旨在从生产端识别关键调控变量,为在控制综合成本的前提下,系统性提升产品品质稳定性提供策略方向。分析显示,除酒精含量外,一系列可通过工艺直接干预的变量对品质预测具有显著贡献。我们的策略核心在于,将数据洞察转化为可执行的生产标准与管控动作,实现从"结果检验"到"过程设计"的品控模式转变。
分析确认,酒精度是预测品质的首要因素。然而,其调整常涉及原料基础,成本高昂且受法规限制。更具策略价值的是紧随其后的一组变量:挥发性酸度、氯化物、柠檬酸、硫酸盐及固定酸度。这五大要素合计贡献度极高,且均可在酿造过程中进行更具成本效益的干预与调控。这为我们指明了"不显著依赖提升酒精度,而通过优化工艺协同来提升品质稳定性"的核心路径。
模型指出,挥发性酸度与氯化物是极为关键的预测变量。挥发性酸度过高是常见的工艺缺陷风味来源,而氯化物则直接关联风土与酿造用水。我们建议实施预防性管理,即在发酵环节,通过推行更严格的卫生标准操作规程和优选酵母菌种,从源头抑制不良酸度的生成,此为一笔可带来长期稳定回报的前期投资。同时,建立酿造用水的矿物质监测档案,对氯化物含量设定内部管控红线。对于含量不稳定的水源,可采用部分勾兑或针对性过滤的经济方案,确保每一批次生产都始于一个风味中性的"画布",这是稳定产品基础风格最经济有效的手段之一。
固定酸度、柠檬酸与硫酸盐共同构成了葡萄酒的骨架、清新感与物理化学稳定性。我们建议改变对它们的孤立管控,转向协同管理。具体而言,在发酵结束后,基于最终的固定酸度(源于葡萄本身)检测值,通过精准添加食品级柠檬酸来微妙地平衡整体酸度结构,这比完全依赖自然酸度更能保证批次间的一致性。对于硫酸盐的使用,建议建立基于产品定位与预期货架期的差异化添加标准,在保证微生物安全的下限与避免负面影响的上限之间找到最佳平衡点,针对需尽早流通的产品可探索优化空间。这种协同管理,能以精细化的物料成本,实现对产品核心架构的精准塑造。
为实现上述工艺控制的闭环管理,我们提议将数据分析能力下沉至生产一线。利用已训练的模型,在关键工艺节点(如发酵结束、调配前)输入上述关键变量的检测值,即可获得该批次葡萄酒的早期质量预测评分。此评分可作为内部决策的依据,预测高分批次可标记为核心优质基酒,用于高端产品或作为调配核心;预测中等批次可进入常规调配程序,进行针对性微调;预测偏低批次则需触发质量回溯机制,立即分析工艺偏差。这本质上构建了一个"数据驾驶舱",使生产管理者能够提前预见结果,并做出分流、调配或干预的决策,从而最大化地稳定最终出厂产品的品质,将价值损失降至最低。
四、局限与展望
本研究提出的策略主要基于现有数据与预测模型,其在投入实际应用前,需客观认识其边界与约束。首先,模型69.62%的验证精度意味着约三成的样本可能被误判,若将其直接用于全自动化的质量分选或工艺控制,由此引发的决策偏差可能导致不容忽视的经济损失。因此,在现阶段,模型的角色更适宜定位为辅助人工决策的量化工具,而非取代经验判断。其次,模型性能可能受到训练数据构成的影响。如果数据集中中等品质的样本占绝大多数,那么所报告的整体精度可能无法真实反映模型对优质或劣质批次等关键少数类别的识别能力,这需要通过更细致的分类评估来进一步验证。此外,任何技术方案的引入都必须评估其商业合理性。倘若现有的人工品控体系已能达到相近的准确度,那么新模型的部署就需要仔细权衡其带来的边际效益与相应的软硬件投资、维护成本及流程变革成本。
上述局限性并未削弱本报告所提路径的价值,反而为其分阶段、审慎的实施提供了清晰的优化方向。短期内的重点工作,是在推进水质监控与发酵卫生管理的同时,可选取个别产线或批次对模型进行试点验证。通过在实际生产中获取反馈,不仅能评估其辅助效用,还能为后续迭代积累高质量的数据。进入中期,随着酸度协同管理等工艺改革的深化,可以将模型的预测输出系统地纳入内部质量分级体系,形成"数据预警、专家复核"的人机协同机制。这一机制既能有效利用模型的批量处理与趋势发现能力,又能以人工智慧弥补其当前在复杂个案上的判断不足,从而实现工艺知识的持续沉淀与优化。长远的愿景,则是构建一个能够自主学习与演进的智能决策系统。通过汇聚生产全流程的数据,并利用更先进的算法框架,使系统不仅能更精准地预测质量,还能为工艺参数的动态调整提供优化建议,最终实现质量、成本与稳定性的全局最优调控。
总体而言,从数据洞察到真正的生产力提升,是一个需要持续投入、迭代和融合的过程。本报告所勾勒的路径,旨在将量化分析能力稳步嵌入生产与品控的核心流程,逐步建立起一种基于数据反馈的持续改进文化,从而在未来的市场竞争中构筑起坚实的品质与效率壁垒。
附录一:参考文献
1 苏钰,程万,高霞飞,程刚. 葡萄酒质量影响因素的实证研究 J . 安徽农业科学, 2013 ,41(20).
2 徐菲远. 白葡萄酒在中国有多火?研报揭示市场趋势N. 华夏酒报,2025-06-17(A06).
附录二:原始数据集
UCI白葡萄酒数据集
附录三:Python代码
略