连接是 SQL 中最重要的的概念之一,要有效地使用它们,你需要具备关系数据库设计的基本知识,本文解释了从数据冗余的"宽表"向规范化"关系表"演进的核心思路,并演示连接的基本用法。
文章目录
- 一、理解关系:表的设计
-
- [1.1 现实世界的挑战:原始的宽表](#1.1 现实世界的挑战:原始的宽表)
- [1.2 解决方案:关系化拆分](#1.2 解决方案:关系化拆分)
- [1.3 优劣势分析](#1.3 优劣势分析)
-
- [1.3.1 优势](#1.3.1 优势)
- [1.3.2 劣势](#1.3.2 劣势)
- [二、 创建连接](#二、 创建连接)
-
- [2.1 基础连接语法](#2.1 基础连接语法)
- [2.2 笛卡尔积 (Cartesian Product)](#2.2 笛卡尔积 (Cartesian Product))
- [2.3 内连接 (Inner Join) 写法](#2.3 内连接 (Inner Join) 写法)
- [2.4 哪种写法更好?](#2.4 哪种写法更好?)
一、理解关系:表的设计
1.1 现实世界的挑战:原始的宽表
我们要设计一个电商数据库,如果把所有信息都堆在一张表(例如 Orders)里,数据看起来会是这样的(注意客户信息、客户地址、客户电话在每条记录里都有):
| 订单号 | 下单日期 | 客户名称 | 客户地址 | 客户电话 | 商品名称 | 金额 |
|---|---|---|---|---|---|---|
| 2026001 | 2026-03-01 | 张三 | 上海市... | 138... | 机械键盘 | 599 |
| 2026005 | 2026-03-05 | 张三 | 上海市... | 138... | 电竞鼠标 | 299 |
| 2026010 | 2026-03-10 | 李四 | 北京市... | 139... | 4K显示器 | 2999 |
这种设计的缺陷:
- 空间浪费: 客户"张三"的信息在每条订单中都要重复录入。如果有 100 个订单,同样的地址和电话就要存储 100 次,极大地浪费了存储空间。
- 维护繁琐: 如果张三搬家了,你必须找出数据库中所有张三的订单,逐一修改地址,一旦漏掉一行,就会导致物流发错货。
- 一致性差: 手动输入或多次重复录入极易出错,可能出现在订单 A 中写的是"张三",在订单 B 中却变成了"章三",导致统计客户消费总额时数据错误。
1.2 解决方案:关系化拆分
在关系型数据库中,我们遵循 "一表一事" 的原则,将数据拆分为两个相互关联的表:
A. 客户表 (Customers)
职责: 仅存储客户的静态信息,每位客户拥有唯一的 客户ID。
| 客户ID | 姓名 | 电话 | 地址 |
|---|---|---|---|
| 1 | 张三 | 138... | 上海市... |
| 2 | 李四 | 139... | 北京市... |
B. 订单表 (Orders)
职责: 记录交易动态,不存储客户的姓名地址,而是通过 客户ID指向客户表。
| 订单号 | 下单日期 | 客户ID | 订单金额 |
|---|---|---|---|
| 2026001 | 2026-03-01 | 1 | 599 |
| 2026005 | 2026-03-05 | 1 | 299 |
| 2026010 | 2026-03-10 | 2 | 2999 |
1.3 优劣势分析
1.3.1 优势
- 高效存储: 客户信息只存一份,订单表只存一个客户编号,大幅缩减了数据体积。
- 一处修改,处处生效: 若客户更换电话,只需修改
Customers表中的一条记录。Orders表是通过 ID 引用该记录的,所有历史和未来订单都会自动关联到最新信息。 - 易扩展: 如果以后想增加客户的"生日"或"会员等级",只需修改
Customers一个表,而不需要动到成千上万条订单数据。
1.3.2 劣势
- 多表关联: 拆分后的劣势就是,当需要获取一份完整的数据时,无法从单张表中直接读取,必须将两张或多张表连接起来。在执行连接查询时,如果表的数据量达到千万级甚至亿级,且索引设计不当,连接操作可能会产生明显的查询延迟。
关系型数据库(如 MySQL, PostgreSQL, Oracle)在设计上就是专为高效处理"连接(join)"而生的。通过合理的优化,数据库可以以极快速度关联数据,这种成本在现代硬件性能下微乎其微。
二、 创建连接
我们用MySQL示例数据库Sakila作为演示,我们这里用到两张表,客户表 customer ,地址 address ,两张表通过address_id关联。
2.1 基础连接语法
创建连接的核心在于:指定要关联的表,并明确它们之间的连接条件。
示例:获取客户姓名及其对应的地址
sql
SELECT first_name, last_name, address
FROM customer, address
WHERE customer.address_id = address.address_id;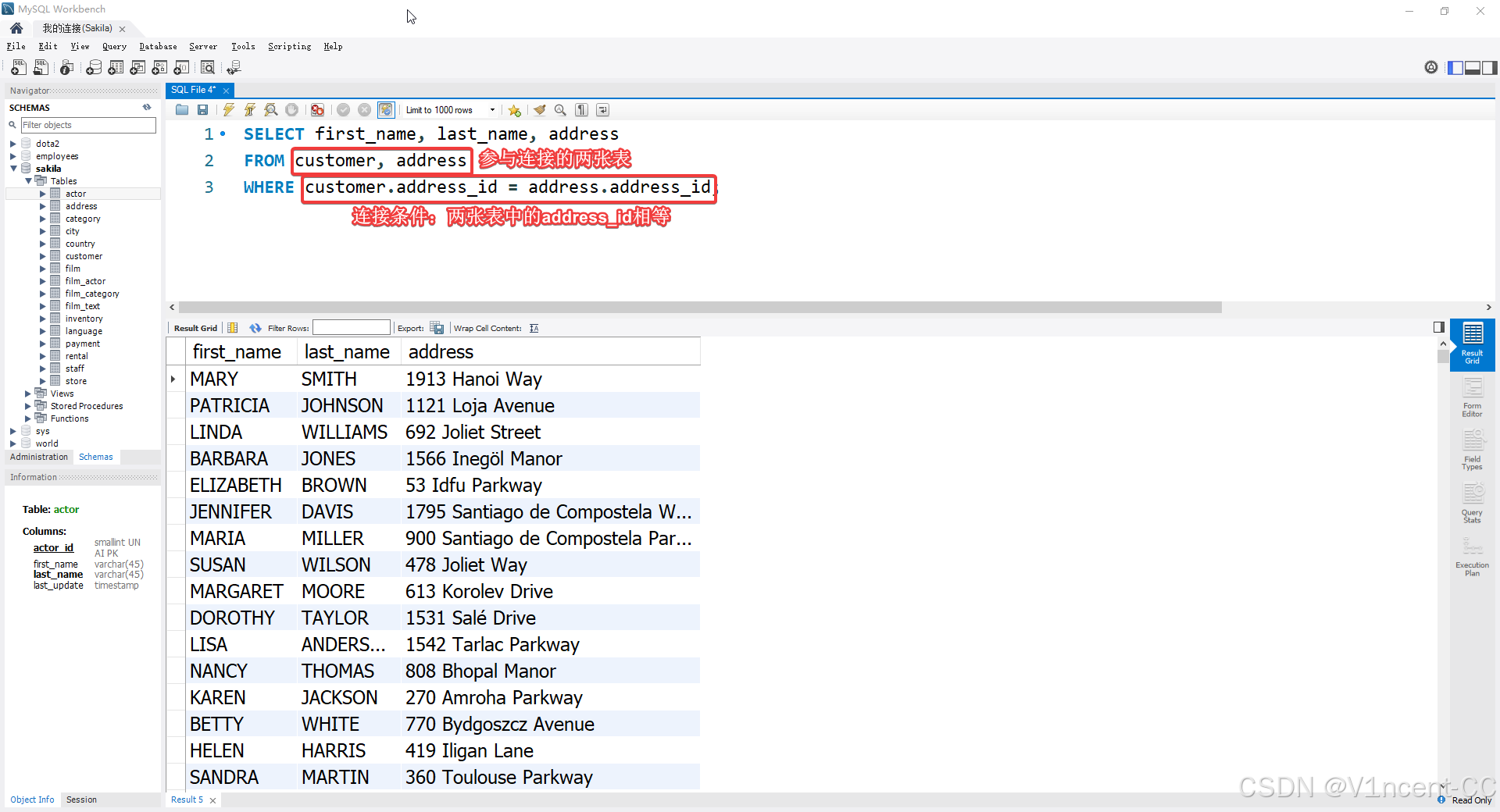
SQL解析:
-
SELECT 子句 :
first_name和last_name来自customer表,address来自address表。 -
FROM 子句 :与单表查询不同,这里列出了参与连接的两个表名:
customer和address。 -
WHERE 子句 :扮演了过滤器 ,只有当两个表的
address_id完全匹配时,才将这两行数据拼接在一起并返回。
注意 :当连接的表中存在同名字段时(例如两个表都有
address_id),必须使用表名.列名的格式。如果不使用完全限定名,MySQL 会抛出Column 'xxx' in field list is ambiguous(字段含义模糊)的错误。
2.2 笛卡尔积 (Cartesian Product)
如果你在连接两个表时漏掉了 WHERE 子句 ,就会产生笛卡尔积。第一个表的每一行都会与第二个表的每一行进行配对。若 A 表有 600 行,B 表有 600 行,结果将产生 600 × 600 = 360 , 000 600 \times 600 = 360,000 600×600=360,000 行数据,这通常不是你想要的结果。
示例:下面的SQL分别统计了两张表和笛卡尔积的行数
sql
SELECT 'customer 表行数' 说明, count(*) 结果集行数 FROM customer
union
SELECT 'address 表行数', count(*) FROM address
union
SELECT '笛卡尔积行数', count(*) FROM customer, address;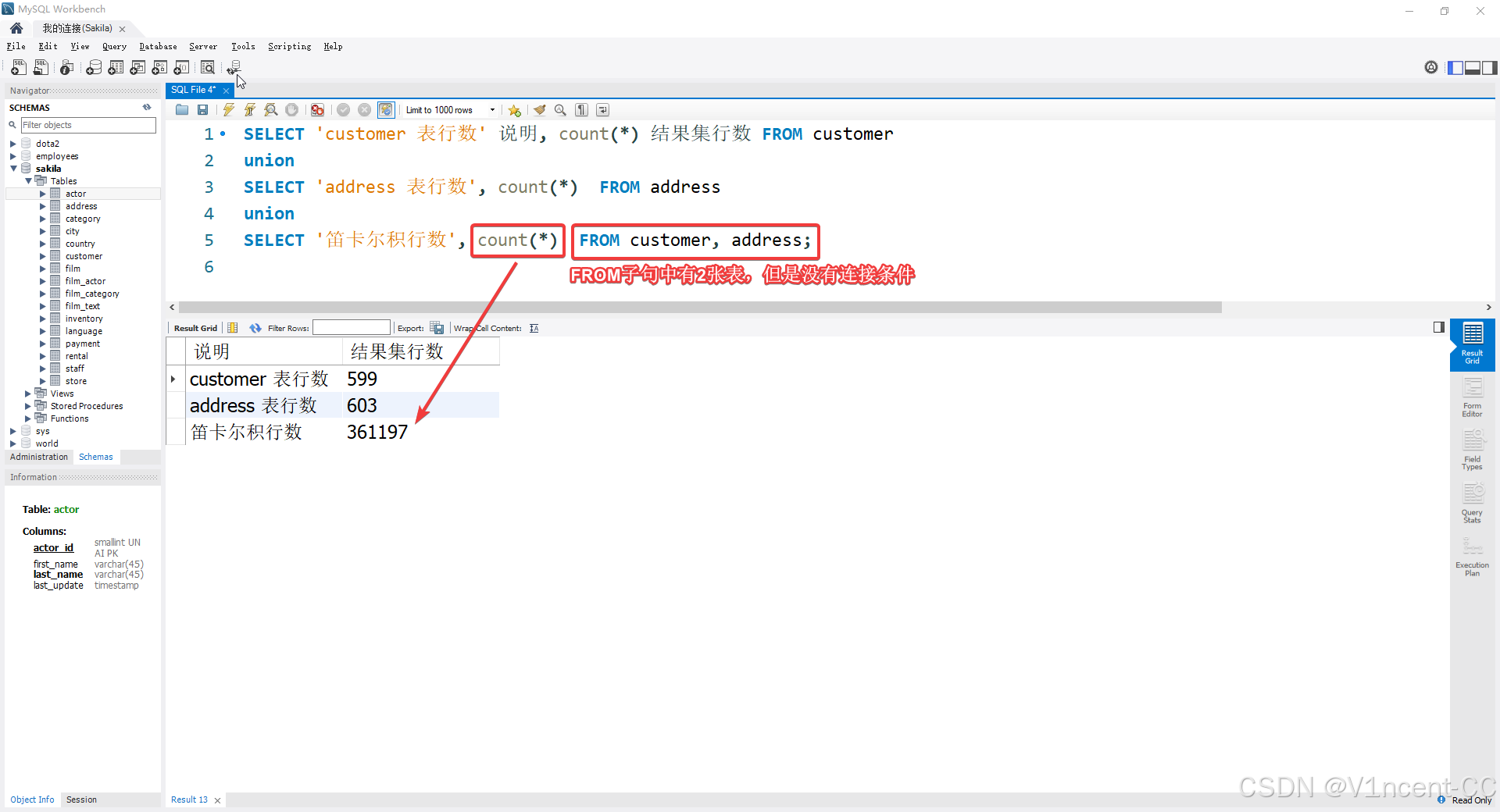
两张表笛卡尔积的记录数是 599 × 603 = 361197 599 \times 603=361197 599×603=361197 条,这还仅仅是两个百级别表。在生产环境中单表的数据可能是几万到几千万,缺少连接条件会导致查询极慢甚至撑爆内存,因此连接时千万不能忘记连接条件。
2.3 内连接 (Inner Join) 写法
我们之前使用的基于 WHERE 等值测试的连接称为等值连接 ,在 SQL 标准中官方名称为 内连接 (Inner Join)。
虽然 WHERE 子句写法更简洁,但 ANSI SQL 规范更推荐使用显式的 INNER JOIN 关键字,配合 ON 子句定义连接条件。
sql
-- 推荐的 ANSI 规范写法
SELECT c.first_name, c.last_name, a.address
FROM customer c
INNER JOIN address a ON c.address_id = a.address_id;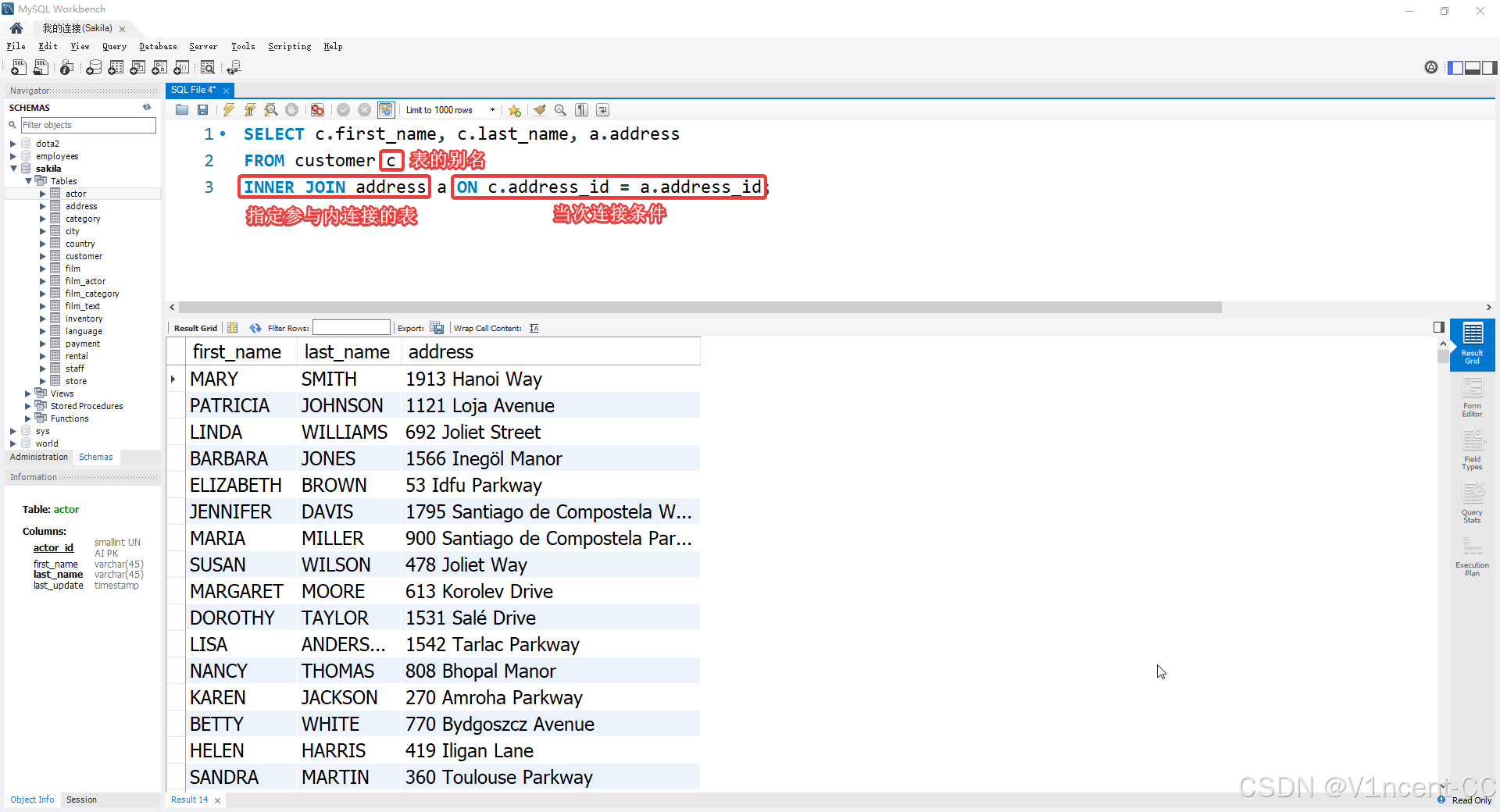
如果有3张及以上表参与连接,只需要重复叠加 INNER JOIN 子句即可。
2.4 哪种写法更好?
上面介绍的两种等值连接写法,更推荐显式的 INNER JOIN 写法,它有如下优点:
- 语义清晰 :
INNER JOIN明确这是"内连接",而WHERE用于"过滤条件"(如amount > 100)。 - 避免遗漏 :使用
ON子句可以强迫你思考连接逻辑,减少意外产生笛卡尔积的风险。 - 易于维护:当连接的表增加到 3 个或更多时,显式语法能让代码层级更加分明(连接条件紧跟表后),你不用在一堆where条件中找连接条件。