本系列主要旨在帮助初学者学习和巩固Linux系统。也是笔者自己学习Linux的心得体会。

个人主页: 爱装代码的小瓶子
文章系列: Linux
2. C++
文章目录
- 1.知识回顾和新的内容介绍:
- [2. 缓冲区的概念和作用](#2. 缓冲区的概念和作用)
-
- [2-1 缓冲区的概念:](#2-1 缓冲区的概念:)
- [2-2 缓冲区的作用:](#2-2 缓冲区的作用:)
- [3 尝试自己实现fwrite:](#3 尝试自己实现fwrite:)
-
- [3-1: 头文件:`MyStudio.h`](#3-1: 头文件:
MyStudio.h) - [3-2具体实现: `MyStudio.c`](#3-2具体实现:
MyStudio.c)
- [3-1: 头文件:`MyStudio.h`](#3-1: 头文件:
- 总结
1.知识回顾和新的内容介绍:
在上一篇文章中【c++与Linux基础】文件篇(4)虚拟文件系统VFS我们详细的谈了内存中的文件是如何操作的,这篇文章将会用到前面的知识,我们将自己实现用系统的接口封装一个fread和fwrite的接口。
在完成这个任务,之前我们必须要好好讲解两个缓冲区,一个系统的缓冲区,一个是语言比如C语言的缓冲区。只有这样,我们才能理解什么后面是如何封装的。
我们接下来会从下面几个点来完成今天的内容:
- 什么是缓冲区?
- 为什么要引入缓冲区
- 实现fwrite 和 fopen
2. 缓冲区的概念和作用
2-1 缓冲区的概念:
我们不得不说明,缓冲区的本质其实很简单:就是一块在堆上(或栈上)动态开辟的、用于暂存数据的内存空间,其底层实现通常是一个字符数组(char数组)。
缓冲区是内存中预留的一部分空间,用于临时存储输入或输出的数据,以协调不同速度的设备或操作之间的数据流。在计算机系统中,缓冲区常见于文件 I/O、网络通信等场景。
它只是一个用来临时存贮数据的地方,有它自己的刷新方式,在后面我们会讲他是行刷新还是满了才刷新进入文件中。
2-2 缓冲区的作用:
在深入之前,我们回顾一下 Linux 是如何通过系统接口打开文件的。
当我们的程序跑起来时,内核创建了一个进程控制块(PCB),也就是 task_struct。在这个巨大的结构体中,有一个极其关键的指针 struct files_struct *files。这个指针指向了一张文件描述符表 。
我们可以把这张表想象成一个指针数组 (fd_array),数组的下标就是我们常说的文件描述符(fd) 。而数组的内容,则是指向 打开文件结构体(struct file) 的指针。(默认情况下,进程启动时已经填充了前三个位置(0, 1, 2),分别对应标准输入、标准输出和标准错误)
当我们调用 write 接口时,内核通过 fd 索引找到对应的 struct file,进而通过它找到文件对应的 inode(索引节点),从而定位到文件在磁盘上的位置。
但是!这里有一个关键点: 如果我们每次调用 write 都直接把数据往慢速的磁盘上刻,那系统的效率将惨不忍睹。因此,Linux 引入了 页缓存(Page Cache) 。我们的 write 操作通常只是将数据从用户态拷贝到了内核态的内存(Cache)中就直接返回了,真正的"落盘"操作则由操作系统在后台择机完成。这才是 Linux 高效 IO 的秘
简答来说,就是为了满足cpu和磁盘速度不匹配而导致的效率问题。
总结一下就是:引入缓冲区的主要原因包括:
- 减少系统调用开销:每次直接读写磁盘或外设都需要通过系统调用,导致 CPU 在用户态和内核态之间切换,消耗资源。缓冲区可以累积多次操作的数据,一次性进行系统调用,从而降低切换频率,提升效率。
- 平衡速度差异:CPU 处理速度远高于磁盘、打印机等 I/O 设备。缓冲区作为中间层,允许 CPU 快速将数据暂存后继续执行其他任务,而 I/O 设备可以慢慢处理数据,避免 CPU 等待。
- 优化数据组织:例如行缓冲区(用于终端输入输出)可以在遇到换行符时刷新,提升交互体验;全缓冲区(用于磁盘文件)则填满后才写入,减少磁盘访问次数。
C语言在封装
FILE这个结构体的时候其实也给了缓冲区,你知道是为什么吗?C 语言缓冲区的目的,不是为了减少磁盘 IO (那是内核 Page Cache 的工作),而是为了减少系统调用 的次数。因为调用系统调用的"价格"实在是太昂贵了。每次调用都要向内核反映问题。相当于每次过高速路都要收取高速费用。
为了解决这个问题,我们不得不一起打包好,在一起送到系统的调用中。这就是为什么我们在写高性能 C/C++ 服务时,有时候甚至觉得 C 库的 buffer 都不够好,还要自己在业务层再写一个 Buffer(比如 Log 系统里的双缓冲区),目的都是一样的:尽可能在用户态把事情搞定,别老去骚扰内核
3 尝试自己实现fwrite:
3-1: 头文件:MyStudio.h
在这个头文件中,我们需要定义我们自己的文件结构体,类似于C语言中的FILE,在这里我们需要为他装上一个缓冲区。主要还要包含下面的:
cpp
struct IO_file {
int fileno;//fd
int flag;//是行还是满刷新
char outbuff[MAX];//缓冲区
char flush_flag;
int bufflen;
};有了这个IO_file我们可以不暴露里面的fd,还可以设置我们自己的缓冲区。接下来中就是定义一些全局变量和刷新格式了:
cpp
#pragma once
#include <stdio.h>
#define NONE_FLUSH 1
#define LINE_FLUSH 2
#define FULL_FLUSH 3
#define MAX 2048接下来完成自己的函数声明:
cpp
typedef struct IO_file my_file;
my_file* my_fopen(char* filename,char* mode);
int my_fwrite(my_file* ,void* str,int len);
void my_close(my_file*);
void my_flush(my_file* file);接下来,我们之需要在自己实现这些接口。
3-2具体实现: MyStudio.c
我们先实现open 函数,主要是打开文件,我们其实还是系统调用去打开这个函数:为了完成这个,我们还需要实现BuyFile 这个函数,这个也是创建my_file的函数:
cpp
my_file* Buyfile(int fd,int flag){
my_file* f = (my_file*)malloc(sizeof(my_file));
f->fileno = fd;
f->flag = flag;
f->flush_flag = LINE_FLUSH;
f->bufflen = 0;
memset(f->outbuff,0,sizeof(f->outbuff));
//把这些这么多全部设置为0。
return f;
}我们实现这个创建一个文件,并且设置好他的刷新格式。随后我们可以尝试完成open函数:
cpp
my_file* my_fopen(char* filename,char* mode){
int fd = -1;
int flag = 0;
if(strcmp(mode,"r") == 0){
flag = O_RDONLY;
fd = open(filename,flag);
}
else if(strcmp(mode,"w") == 0){
flag = O_WRONLY | O_CREAT | O_TRUNC;
fd = open(filename,flag,0666);
}
else if(strcmp(mode,"a") == 0){
flag = O_WRONLY | O_CREAT | O_APPEND;
fd = open(filename,flag,0666);
}
if(fd < 0){
perror("open error");
return NULL;
}
return Buyfile(fd,flag);
}我们在之前的文章,我们已经讲过了为什么这些模式的对应关系。我们只需要比较,打开就行了
随后就是完成刷新函数和关闭函数:
cpp
void my_flush(my_file* file){
int fd = file->fileno;
ssize_t ret = write(fd,file->outbuff,file->bufflen);
if(ret < 0){
perror("write error");
exit(2);
}
//其实写进去系统的缓冲区,我们就可以将:
file->bufflen = 0;
}我们注意,一旦释放指针,记得置为空。
cpp
void my_fclose(my_file * file){
if(file->fileno < 0) return;
my_flush(file);
close(file->fileno);
free(file);
file = NULL;
}最后,完成最难的write函数:
cpp
int my_fwrite(my_file* file,void* str,int len){
//先把str写到缓冲区中。
if(len + file->bufflen > MAX){
my_flush(file);
file->bufflen = 0;
//如果位置不够进行先给的文件刷新,并让bufflen = 0
}
if(len > MAX){
//如果比缓冲区都要大,那么就直接写进系统的缓冲区,放回len的长度
ssize_t ret = write(file->fileno,str,len);
if(ret < 0){
perror("write fail");
exit(2);
}
return len;
}
memcpy(file->outbuff + file->bufflen,str,len);
file->bufflen += len;
//我们已经把str ,写进去了my_file的长度中了,这次写成了,看看要不要刷新:
if(file->outbuff[file->bufflen - 1] == '\n' && file->flush_flag == LINE_FLUSH){
//如果遇到了\n并且刷新模式行刷新
my_flush(file);
}
return len;
}这样我们就完成本次代码的实现。开始调用:
cpp
#include "MyStudio.h"
#include <stdlib.h>
#include <time.h>
#include <unistd.h>
#include <string.h>
int main()
{
char * msg = "hello new world\n";
my_file* fp = my_fopen("log.txt","w");
if(fp == NULL){
perror("open error");
exit(3);
}
int cnt = 10;
while(cnt--){
my_fwrite(fp,msg,strlen(msg));
my_flush(fp);
//保证每次写进去.
printf("buffer: %s", fp->outbuff);
sleep(1);
}
return 0;
}开始运行,会像屏幕打印hello,world ,由于printf里面还是带了一个\n,会出现两次换行,这是正常的。
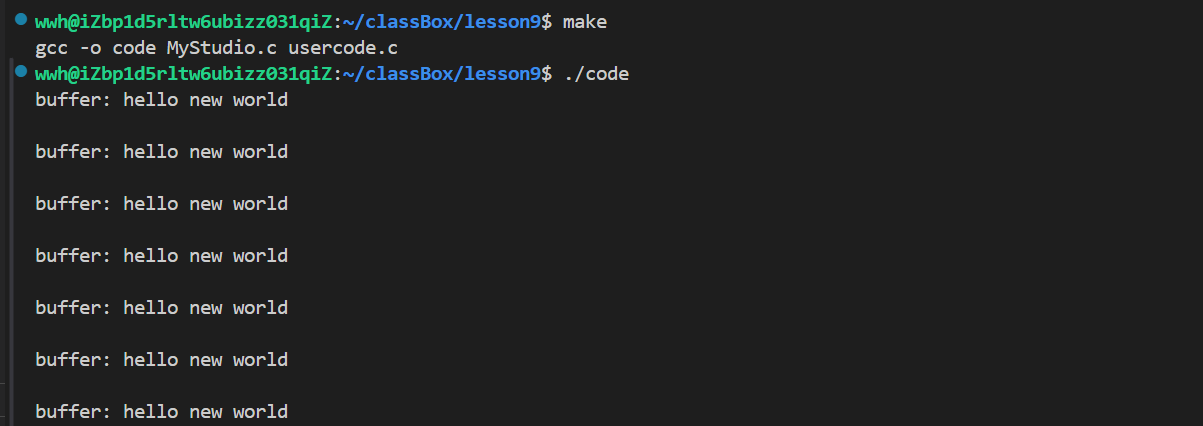
查看log.txt文件是不是正常的!
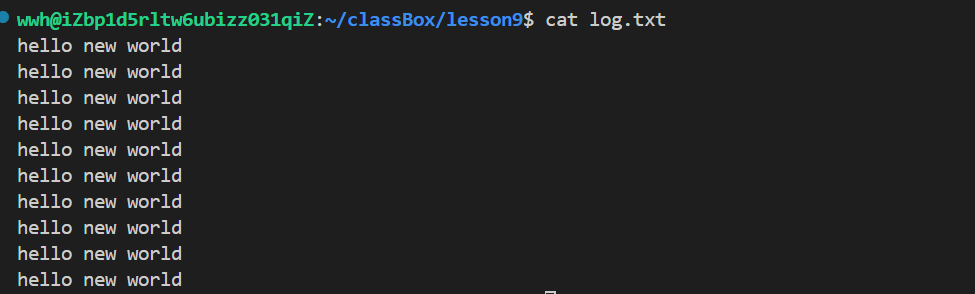
发现一切正常。
总结
这篇文章从缓冲区的基本概念入手,系统性地讲解了在Linux环境下实现文件操作接口fread和fwrite所需的核心知识。首先回顾了虚拟文件系统(VFS)的背景,然后深入探讨了缓冲区的定义、引入原因及其不同类型(如系统缓冲区与C语言缓冲区),最后通过实际代码演示如何基于系统调用封装这两个关键的文件读写函数,从而帮助读者理解从底层机制到上层封装的完整技术链路。
感谢各位对本篇文章的支持。谢谢各位点个三连吧!

