前言
在数据库性能优化这块,SQL 调优绝对是提升系统响应速度、降低资源消耗的核心操作!KingbaseES 作为能兼容 Oracle 的企业级数据库,把从 SQL 语句改写、执行计划干预到结果集缓存的优化全给覆盖到了,一套高级调优工具直接拉满。今天就带大家手把手拆解 Query Mapping、物化视图、并行查询、函数结果集缓存这些关键调优手段,再配上实打实的实战代码,不管你是数据库管理员还是开发同学,都能快速上手这些高性能优化技巧!

一、Query Mapping:不用改代码的 SQL"智能替换"神器
Query Mapping 绝对是 KingbaseES 里灵活性拉满的调优工具!简单说就是提前定义好"源 SQL"和"目标 SQL"的对应关系,你输入的 SQL 只要和源 SQL 匹配,就会自动换成目标 SQL 执行,不用动一行应用代码就能完成性能优化,简直不要太方便!
核心特性与适用场景
- 支持两种匹配级别:TEXT 级会保留原始语法,连注释都不会丢,还能搭配 HINT 一起用;SEMANTICS 级会做语法语义校验,严谨度直接拉满。
- 常见用法:把写得不够高效的 SQL 改成等价的高效语句、异构数据库迁移时做语法转换、批量调整查询条件(比如把过滤条件下推,减少中间数据量)。
实战代码示例
1. 先把功能开起来
要想用这个功能,得先在 kingbase.conf 里配置一下,开启后重启数据库就行:
sql
enable_query_rule = on2. 优化过滤条件,少返回点数据
比如原本查询 id<10,想改成 id<5 来减少结果集大小,直接创建映射规则就行:
sql
-- 创建映射规则:qm1 是规则名,TEXT 级别匹配
SELECT create_query_rule(
'qm1',
'select id,val from t1 where id<$1', -- 源 SQL(带变量$1)
'select id from t1 where id<($1-5)', -- 目标 SQL(对变量做运算)
true, -- 规则启用
'text' -- 匹配级别
);
-- 执行源 SQL,会自动触发替换
select id,val from t1 where id<10;
-- 实际执行的是:select id from t1 where id<5,返回 id=1-4 的数据,少传不少数据!3. UNION 转 UNION ALL,告别多余去重
如果数据本身不会重复,用 UNION 会多做一次去重操作,特别耗时。用 Query Mapping 自动转换成 UNION ALL,效率直接翻倍:
sql
-- 创建映射规则
SELECT create_query_rule(
'union_opt',
'select * from t1 union select * from t2',
'select * from t1 union all select * from t2',
true,
'semantics'
);
-- 执行查询,自动用 UNION ALL 执行,不用再做无用的去重了
select * from t1 union select * from t2;4. 条件下推,优化 UNION 子查询
有时候 UNION 子查询外面还有连接条件,把条件下推到子查询里,能少传很多中间数据,效率提升超明显:
sql
SELECT create_query_rule(
'push_down',
'SELECT count(0) FROM t1, (select * from t2 where val>$1 union select * from t1 where val<$2) as v where t1.id=v.id',
'SELECT count(0) FROM t1, lateral(select * from t2 where val>$1 and t1.id=t2.id union select * from t1 t where t.val<$2 and t.id=t1.id) as v',
true,
'text'
);
-- 执行优化后的查询,中间结果集小了,速度自然快了
SELECT count(0) FROM t1, (select * from t2 where val>5 union select * from t1 where val<20) as v where t1.id=v.id;5. 变量交换与多表关联优化(新增实用示例)
如果想交换查询条件里的变量顺序,或者给多表关联加个精准过滤,也能通过映射规则实现:
sql
-- 变量交换:把 t2.id<$1 和 t2.val=$2 的条件交换变量
SELECT create_query_rule(
'var_swap',
'select * from t2 where t2.id<$1 and t2.val=$2',
'select * from t2 where t2.id<$2 and t2.val=$1',
true,
'text'
);
-- 执行查询,自动交换变量条件,不用改业务代码
select * from t2 where t2.id<50 and t2.val=5;
-- 多表关联过滤优化:增加 t2.id=$2 条件,精准过滤无用数据
SELECT create_query_rule(
'join_filter',
'select * from t1, t2 where t1.id=t2.id and t1.id<$1 and t2.val=$2',
'select * from t1, t2 where t1.id=t2.id and t1.id<$1 and t2.val=$2 and t2.id=$2',
true,
'text'
);
-- 执行多表查询,自动添加过滤条件,返回结果更精准
select * from t1, t2 where t1.id=t2.id and t1.id<30 and t2.val=5;常用操作函数
| 函数名 | 功能描述 |
|---|---|
| create_query_rule(规则名, 源SQL, 目标SQL, 启用状态, 级别) | 创建映射规则 |
| drop_query_rule(规则名) | 删除指定规则 |
| enable/disable_query_rule(规则名) | 启用/禁用规则 |
二、物化视图:高频复杂查询的"预计算缓存"
物化视图会把查询结果集实实在在存起来------数据量小就放内存,大了就存磁盘,不用每次查询都重复执行耗时的表连接、聚集操作。特别适合基表数据更新不频繁,但查询又特别频繁的场景,比如统计报表,查一次能快好几倍!
核心原理与限制
- 存储方式:数据落地存储,支持手动全量刷新或增量刷新,不过 KingbaseES 目前还不支持自动刷新,基表数据变了记得手动刷一下。
- 适用场景:统计报表查询、多表关联查询、外部表数据缓存(把外部表数据存下来,不用每次都远程读取,省不少时间)。
实战代码示例
1. 创建物化视图(多表关联场景)
先准备两张基表,再创建物化视图存储按区域统计的订单数据,后续查询直接读视图就行:
sql
-- 基表准备
create table order_info(order_id int primary key, user_id int, amount numeric, create_time timestamp);
create table user_info(user_id int primary key, user_name text, region text);
-- 插入测试数据
insert into user_info select generate_series(1,1000), 'user_'||generate_series(1,1000), 'region_'||(generate_series(1,1000)%10);
insert into order_info select generate_series(1,10000), (random()*1000)::int+1, random()*1000, now()- (random()*30)::interval;
-- 创建物化视图:按区域统计订单数量和总金额,预计算好结果
create materialized view region_order_stats as
select u.region, count(o.order_id) as order_count, sum(o.amount) as total_amount
from user_info u
join order_info o on u.user_id = o.user_id
group by u.region;2. 刷新物化视图(数据更新后)
基表数据变了之后,得刷新物化视图才能拿到最新数据,两种刷新方式按需选:
sql
-- 全量刷新(数据变动大时用,直接重新计算所有数据)
refresh materialized view region_order_stats;
-- 增量刷新(只更改变动的数据,效率更高,不用等太久)
refresh materialized view concurrently region_order_stats;3. 物化视图加索引,查询更快
为了让物化视图的查询速度再提一档,可以给它创建索引,针对性优化查询条件:
sql
-- 给物化视图的 region 列创建索引,按区域查询时直接走索引
create index idx_region_order_stats_region on region_order_stats(region);
-- 查询时会自动使用索引,毫秒级就能返回结果
select * from region_order_stats where region='region_0';4. 性能对比:物化视图 vs 原始查询
直观感受下优化效果,差距真的很明显:
sql
-- 直接查询物化视图(毫秒级响应,预计算的结果直接用)
select * from region_order_stats where region='region_0';
-- 对比原始查询(需要实时关联两张表计算,耗时直接翻倍)
select u.region, count(o.order_id), sum(o.amount)
from user_info u
join order_info o on u.user_id = o.user_id
where u.region='region_0'
group by u.region;三、并行查询:用多核 CPU 给 SQL 加速
KingbaseES 支持把单个 SQL 语句分给多个 Worker 进程并行执行,能把多核 CPU 的性能充分利用起来。像大表扫描、哈希连接、聚集这些耗时操作,用并行查询能明显提速,有时候甚至能快好几倍!
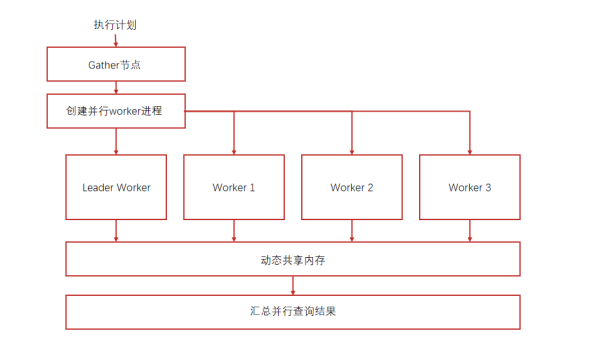
核心配置与参数
要开启并行查询,先在 kingbase.conf 里配置好这些参数,根据自己的服务器配置调整:
sql
max_worker_processes = 16 -- 最大后台进程数
max_parallel_workers = 8 -- 最大并行 Worker 数
max_parallel_workers_per_gather = 4 -- 每个查询最多能用的并行 Worker 数
min_parallel_table_scan_size = 8MB -- 表至少这么大才会触发并行实战代码示例
1. 并行全表扫描(大表必备)
创建一张 1000 万行的大表,用并行查询加速扫描,不用等半天:
sql
-- 创建大表(1000万行,模拟真实大表场景)
create table big_table(id int primary key, content text, create_time timestamp);
insert into big_table select generate_series(1,10000000), md5(random()::text), now()- (random()*100)::interval;
analyze big_table; -- 更新统计信息,让优化器知道表有多大
-- 用 HINT 指定 4 个 Worker 并行查询,效率直接拉满
explain analyze select /*+Parallel(big_table 4)*/ * from big_table where create_time > '2024-01-01';2. 并行哈希连接(大表+小表组合)
大表和小表连接时,用并行哈希连接效率更高,不用串行等一个进程处理:
sql
-- 创建小表
create table small_table(id int primary key, category text);
insert into small_table select generate_series(1,1000), 'cat_'||(generate_series(1,1000)%20);
-- 并行哈希连接查询,大表并行扫描,小表做哈希,连接速度飞快
explain analyze select /*+Parallel(big_table 2)*/ b.*, s.category
from big_table b
join small_table s on b.id = s.id
where b.create_time > '2024-01-01';3. 并行聚集计算(统计数据必备)
统计订单总金额这种操作,用并行聚集能省不少时间,不用单个进程慢慢算:
sql
-- 并行统计 2024 年 1-4 月的订单总金额,多个 Worker 一起算
explain analyze select /*+Parallel(order_info 3)*/ sum(amount) as total
from order_info
where create_time between '2024-01-01' and '2024-04-01';关键注意事项
- Worker 进程数不是越多越好:太多进程会互相抢资源、增加通信开销,比如 8 核 CPU 设 4-6 个就差不多了,多了反而变慢。
- 小结果集别用并行:如果查询返回的数据占表总量 50% 以上,优化器可能会直接选全表扫描,比并行更高效,不用强行开并行。
四、函数结果集缓存:重复调用的函数不用再重复执行
如果函数是 immutable(结果永远不变)或 stable(同一事务中结果不变)类型,KingbaseES 会把它的执行结果缓存起来。同一 SQL 中多次调用相同参数的函数,会直接复用缓存结果,不用重复执行,能省不少 CPU 资源!
核心条件与配置
-
缓存条件:函数属性是 immutable 或 stable、返回单个值、入参不超过 16 个,满足这些就能缓存。
-
控制参数:
sqlfunction_result_cache = on -- 启用函数缓存 function_cache_number = 1000 -- 最多缓存 1000 个结果
实战代码示例
1. 创建可缓存函数
先创建一个根据用户 ID 获取区域的 stable 类型函数,满足缓存条件:
sql
create or replace function get_user_region(user_id int) returns text as $$
select region from user_info where user_id = $1;
$$ language sql stable;
-- 开启函数缓存,让配置生效
set function_result_cache = on;2. 复用缓存结果(同一 SQL 多次调用)
同一 SQL 中多次调用相同参数的函数,第二次直接用缓存,不用再查数据库:
sql
-- 同一 SQL 中两次调用 get_user_region,参数相同,第二次复用缓存
select
order_id,
get_user_region(user_id) as region1,
get_user_region(user_id) as region2 -- 复用缓存,不重复执行函数
from order_info where order_id < 100;3. 验证缓存效果(看执行次数就知道)
通过系统表查看函数执行次数,缓存命中后次数不会增加,一眼就能验证效果:
sql
-- 先执行几次查询,触发函数调用
select get_user_region(1) from order_info where order_id < 10;
select get_user_region(1) from order_info where order_id < 20;
-- 查看函数执行统计,calls 列是执行次数,缓存命中后次数不会变
select funcname, calls from sys_stat_user_functions where funcname='get_user_region';4. 临时禁用函数缓存(特殊场景用)
如果某些场景不想用缓存,也能临时禁用,灵活调整:
sql
-- 禁用函数缓存
set function_result_cache = off;
-- 再次执行查询,函数会重复执行,不会复用之前的缓存
select get_user_region(1) from order_info where order_id < 10;五、其他高级调优手段补充
1. 分区表执行计划优化
如果分区表的子表数量很多,生成执行计划会变慢,用这个参数控制一下,快速生成计划:
sql
-- 子表数超过 30 时,启用快速生成执行计划,不用等太久
set partition_table_limit = 30;2. 逻辑优化规则(kdb_rbo 插件)
启用 kdb_rbo 插件,能自动优化 count(distinct)、合并子查询公共表达式,不用手动改 SQL:
sql
-- kingbase.conf 配置,添加插件(需要重启数据库)
shared_preload_libraries = 'kdb_rbo'
-- 启用 count(distinct) 优化(阈值 0.1,根据实际情况调整)
set kdb_rbo.attribute_distinct_value_threshold = 0.1;
-- 启用子查询公共表达式合并,减少重复计算
set kdb_rbo.enable_merge_comm_expr = on;3. SQL 监控与调优报告
通过 sys_sqltune 插件,能自动生成 SQL 调优建议报告,不用手动分析,省心又高效:
sql
-- 创建插件
create extension sys_sqltune;
-- 生成指定 SQL 的调优报告,直接给出优化建议
select PERF.QUICK_TUNE_BY_SQL('select * from big_table where create_time > ''2024-01-01''');
-- 把报告保存到文件,方便后续查看
select PERF.QUICK_TUNE_BY_SQL_TO_FILE('select * from big_table where create_time > ''2024-01-01''', 'TEXT', '/tmp/sql_tune_report.txt');六、调优手段选型指南
| 调优手段 | 核心优势 | 适用场景 |
|---|---|---|
| Query Mapping | 不用改应用代码,替换灵活 | SQL 语法转换、批量优化低效语句 |
| 物化视图 | 预计算缓存,查询速度极快 | 静态报表、高频复杂查询、外部表缓存 |
| 并行查询 | 利用多核 CPU,加速大数据处理 | 大表扫描、哈希连接、聚集计算 |
| 函数结果集缓存 | 复用计算结果,减少 CPU 消耗 | 高频调用的 immutable/stable 函数 |
总结
KingbaseES 这些高级 SQL 调优手段,从语句改写、结果缓存到硬件资源利用,全链路都覆盖到了。实际优化的时候,建议先通过 SQL 监控找到性能瓶颈,再根据数据特征选对应的工具------比如静态报表用物化视图,动态查询用 Query Mapping,大数据量处理用并行查询。把这些手段合理组合起来,数据库的吞吐量和响应速度肯定能明显提升!
-
金仓官方网址:https://www.kingbase.com.cn
-
金仓社区链接:https://bbs.kingbase.com.cn/