视频嵌入表示是将视频内容包括视觉、音频、时序信息映射到一个稠密、低维向量空间的过程。
这个向量能表征视频的语义信息,是视频理解、生成、检索等任务的基础。
这里探索视频嵌入表示的多种生成方案。
1 视频-语言模型的编码
在巨量视频-文本对上进行对比学习,使编码器能将视频和文本映射到同一语义空间。
可用于文本匹配视频,作为特征输入给特定任务模型。
具体模型比如CLIP4Clip、VideoCoCa。
1.1 CLIP4Clip
CLIP4Clip架构示例如下所示
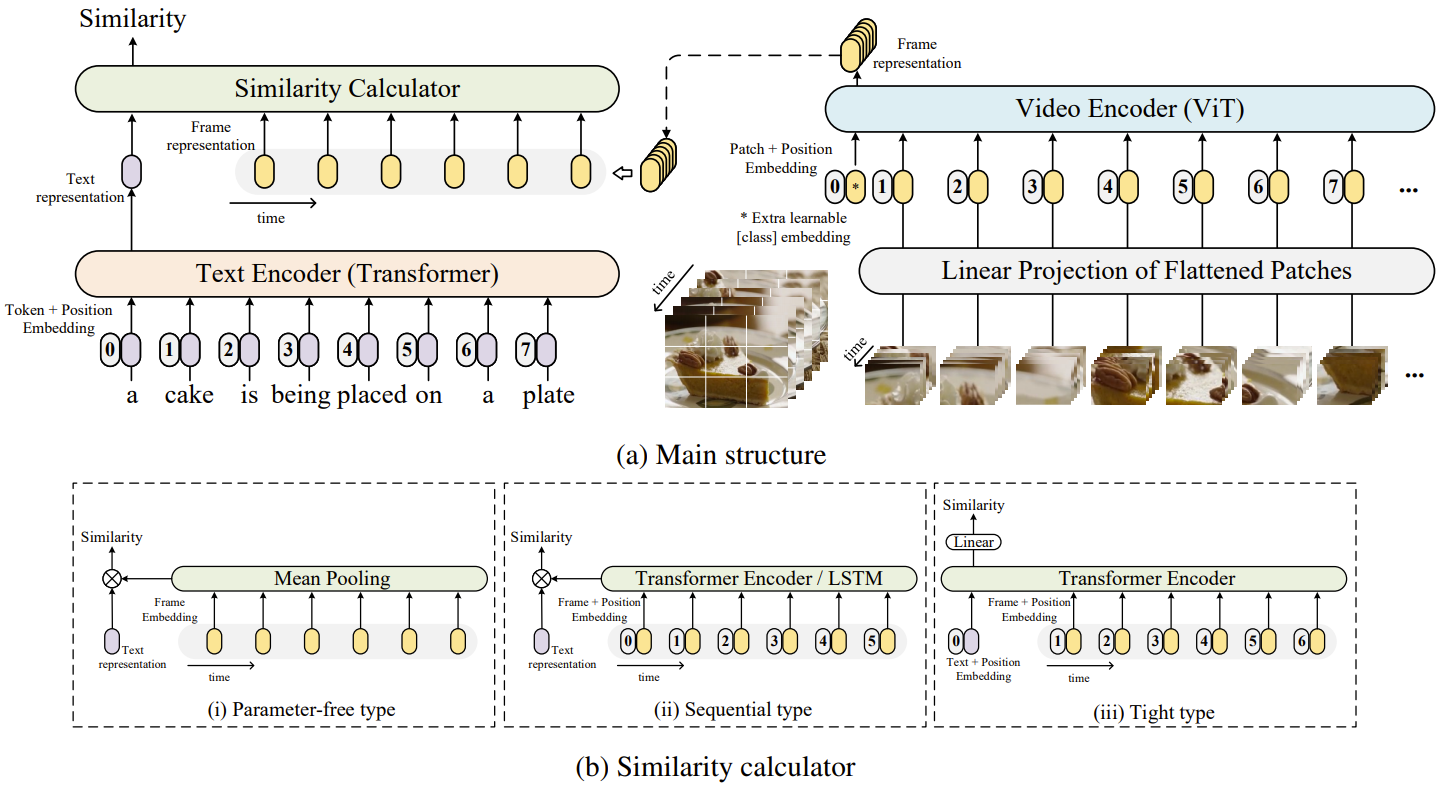
https://github.com/ArrowLuo/CLIP4Clip
1.2 VideoCoCa
VideoCoCa的核心架构示例如下
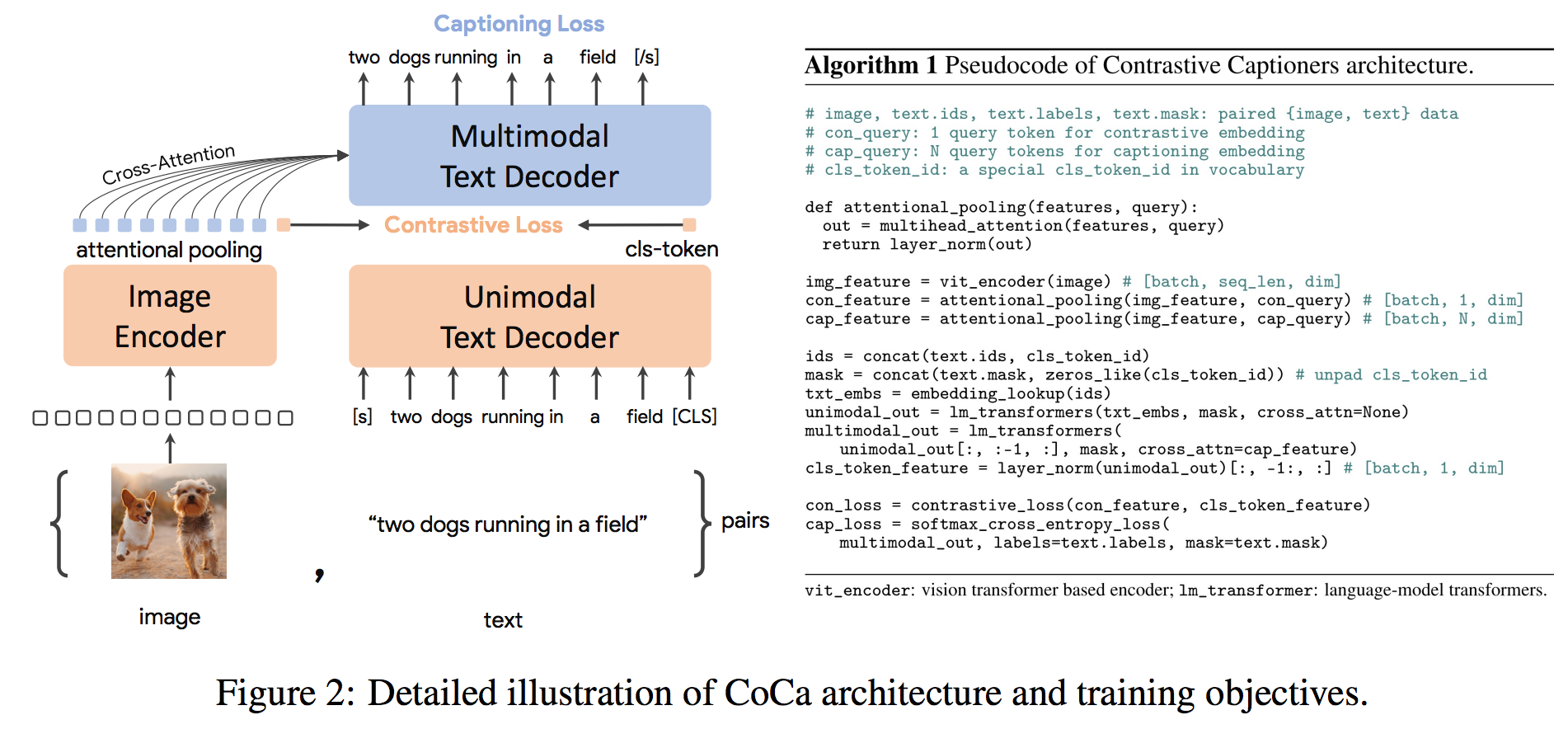
https://github.com/lucidrains/CoCa-pytorch
2 去噪网络的隐式表示
Sora、Veo、Lumiere 等扩散模型,核心是一个去噪网络。
这个网络将视频压缩到低维潜空间后,分解为时空块碎片,将不同时长、分辨率、长宽比的视频统一表示为"碎片"序列,类似于大语言模型中的Token。
在时空碎片构成的潜空间中,通过去噪过程学习并提取碎片间的动态关联。模型的目标不仅是生成像素,更是学习并模拟视频背后隐含的物理世界动态规律(如对象持久性、三维一致性)。
文本、图像或已有视频片段均可被编码为时空碎片,作为条件引导生成。这种统一表示使得视频扩展、静态图动画、视频连接与编辑等复杂任务成为可能。
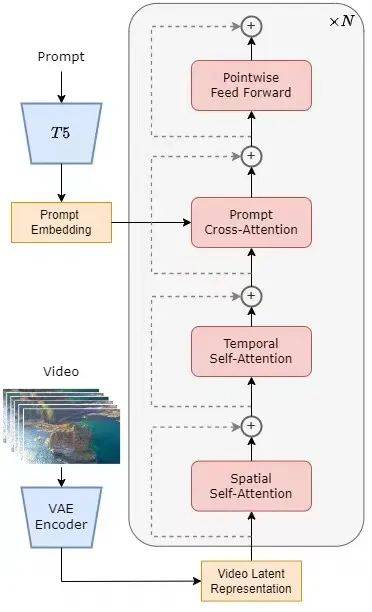
2.1 Open-Sora
以下是Open-SoRA的架构示例图。Video通过VAE Encode编码为Video Latent Reprsentation,然后在prompt嵌入作为条件,使用逐步去噪的方式训练模型,学习并提取碎片间的动态关联。
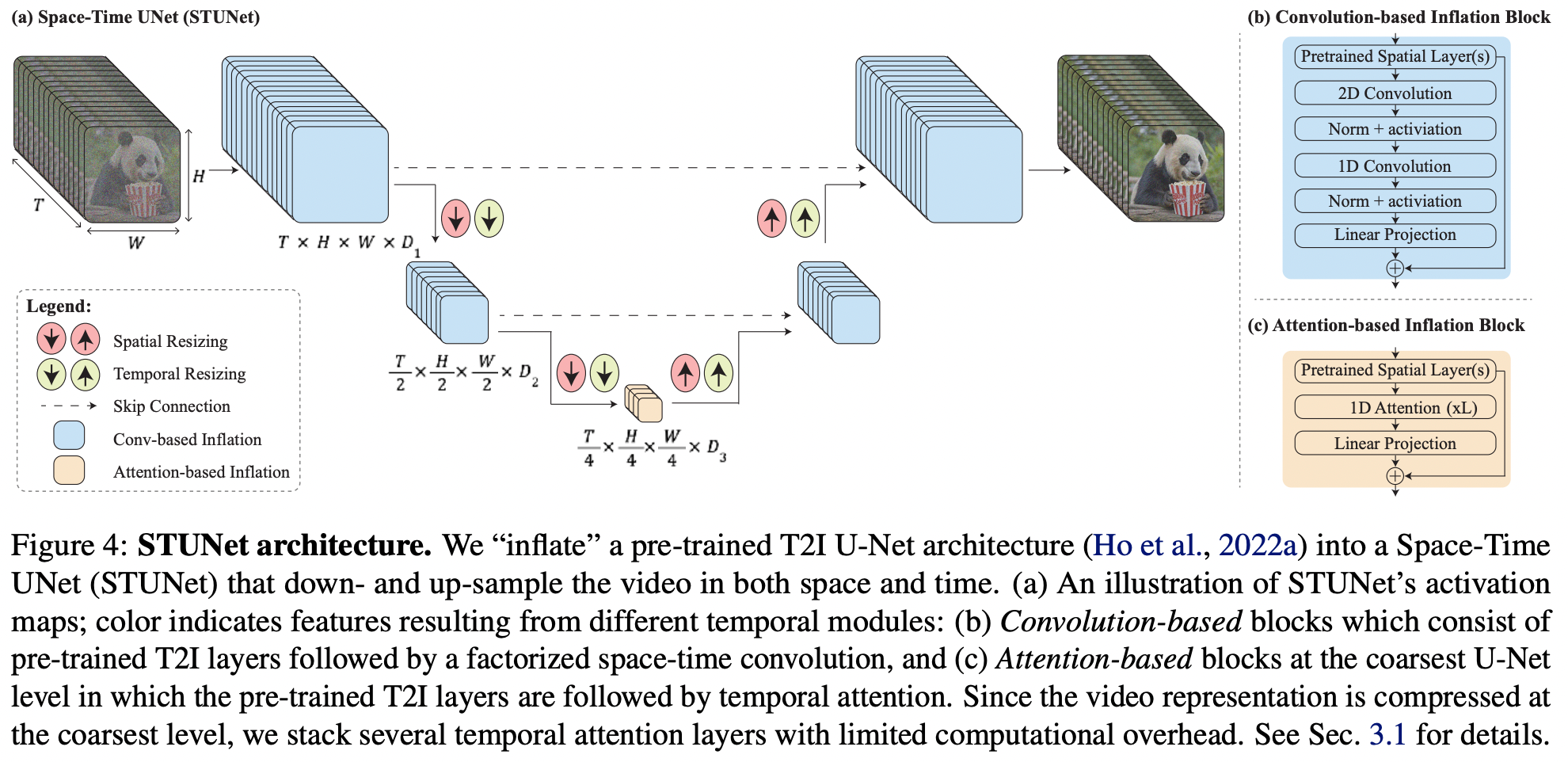
2.2 Lumiere
以下是Lumiere的架构图示例。
2.3 Wan2.2
以下是视频生成模型Wan的架构示例。
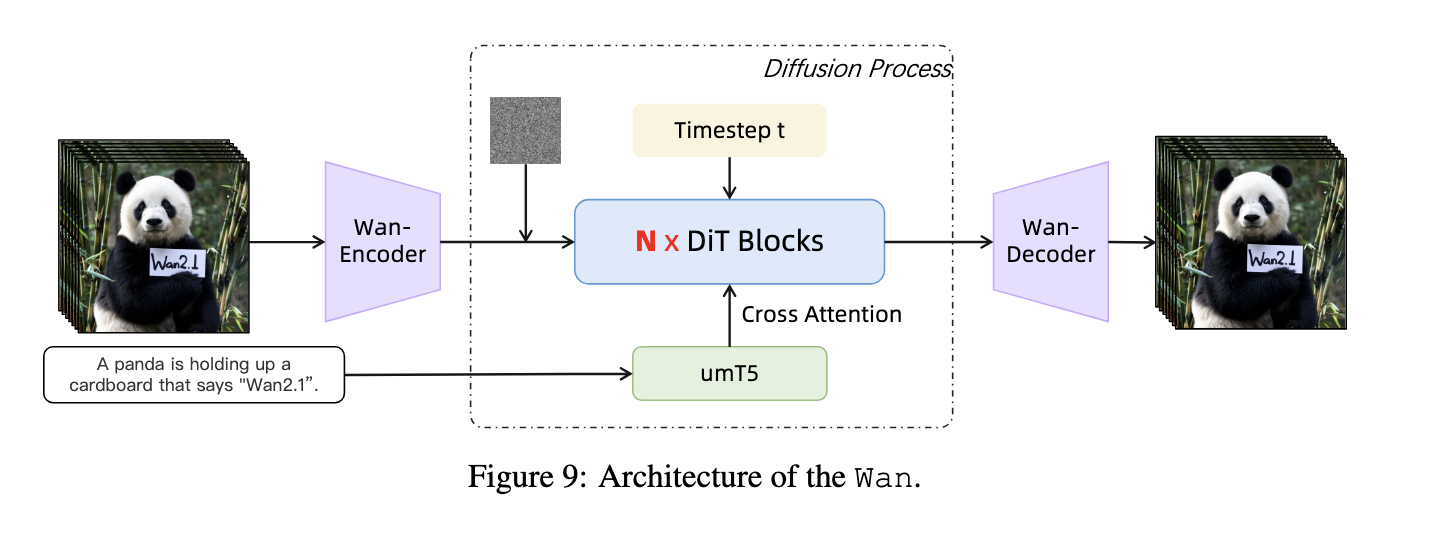
https://github.com/Wan-Video/Wan2.2
3 前沿视角演进探索
当前研究正将视频嵌入的边界从生成推向更深刻的理解与重建。
作为视频思考的推理工具,研究提出与视频共思范式,将Sora等模型视为统一的多模态理解与生成模型,能处理需要时空推理的任务(如解谜题、物理问题)。
用于重建4D世界,研究探索利用视频扩散模型中丰富的时空先验知识,从单目视频中直接推断出动态3D场景(4D几何),实现场景重建,比如SV4D。
应用深化,新一代模型在可控性上显著增强。其客串插入功能,实质是对特定对象(如人像)的身份表示进行高保真提取和跨场景一致合成。这需要精细的参考图像、场景元数据(光照、镜头)和负面提示约束。
reference
CLIP4Clip
https://github.com/ArrowLuo/CLIP4Clip
Open-Sora
https://github.com/hpcaitech/Open-Sora
Open-Sora 2.0: Training a Commercial-Level Video Generation Model in $200k
https://arxiv.org/pdf/2503.09642v1
Wan: Open and Advanced Large-Scale Video Generative Models
https://arxiv.org/abs/2503.20314
Video Production for All
https://arxiv.org/html/2412.20404v1
stabilityai/sv4d2.0
https://huggingface.co/stabilityai/sv4d2.0
generative-models
https://github.com/Stability-AI/generative-models
SV4D: Dynamic 3D Content Generation with Multi-Frame and Multi-View Consistency
veo-3
https://github.com/veo-3/veo-3
lumiere-pytorch
https://github.com/lucidrains/lumiere-pytorch
Wan2.2