文章目录
-
- 一、词嵌入
-
- [1.1 词嵌入的原理](#1.1 词嵌入的原理)
- [1.2 使用词嵌入](#1.2 使用词嵌入)
- [1.3 词嵌入如何帮助推理类比](#1.3 词嵌入如何帮助推理类比)
- [1.4 矩阵嵌入](#1.4 矩阵嵌入)
- [1.5 学习词嵌入](#1.5 学习词嵌入)
-
- [1.5.1 学习嵌入矩阵](#1.5.1 学习嵌入矩阵)
- [1.5.2 Word2 VEC模型](#1.5.2 Word2 VEC模型)
-
- [1.5.2.1 skip-gram模型](#1.5.2.1 skip-gram模型)
- [1.5.2.2 负采样法](#1.5.2.2 负采样法)
- [1.5.3 GloVe(用于词汇表征的全局矢量)算法](#1.5.3 GloVe(用于词汇表征的全局矢量)算法)
- [1.6 词嵌入除偏](#1.6 词嵌入除偏)
- 二、情感分类
一、词嵌入
1.1 词嵌入的原理
词嵌入能够自动进行类比。
我们可以使用独热编码来表示每一个单词,每一个单词对应一个向量。这种表示方法的缺点是只考虑了单个词在向量中的作用,没有包括词与词之间的关系。

我们可以使用词的一些特征化表示,学习每一个词的特征和数值。通过标记词的某些特征来进行学习,于是我们可以用特征数量大小的向量去表示一个词,每一个数值代表该词在该特征上的数值。这种方式能够更好地去表示词与词之间地关系。

上述方式也存在一个问题:我们需要选取地特征具有不确定性,同时对词的表示也具有干扰性。
有一种算法叫做t-SNE,所有的词就会被映射到一个二维的空间中去,我们能够很清晰地看出哪些词可能会被划分到一个组中去。
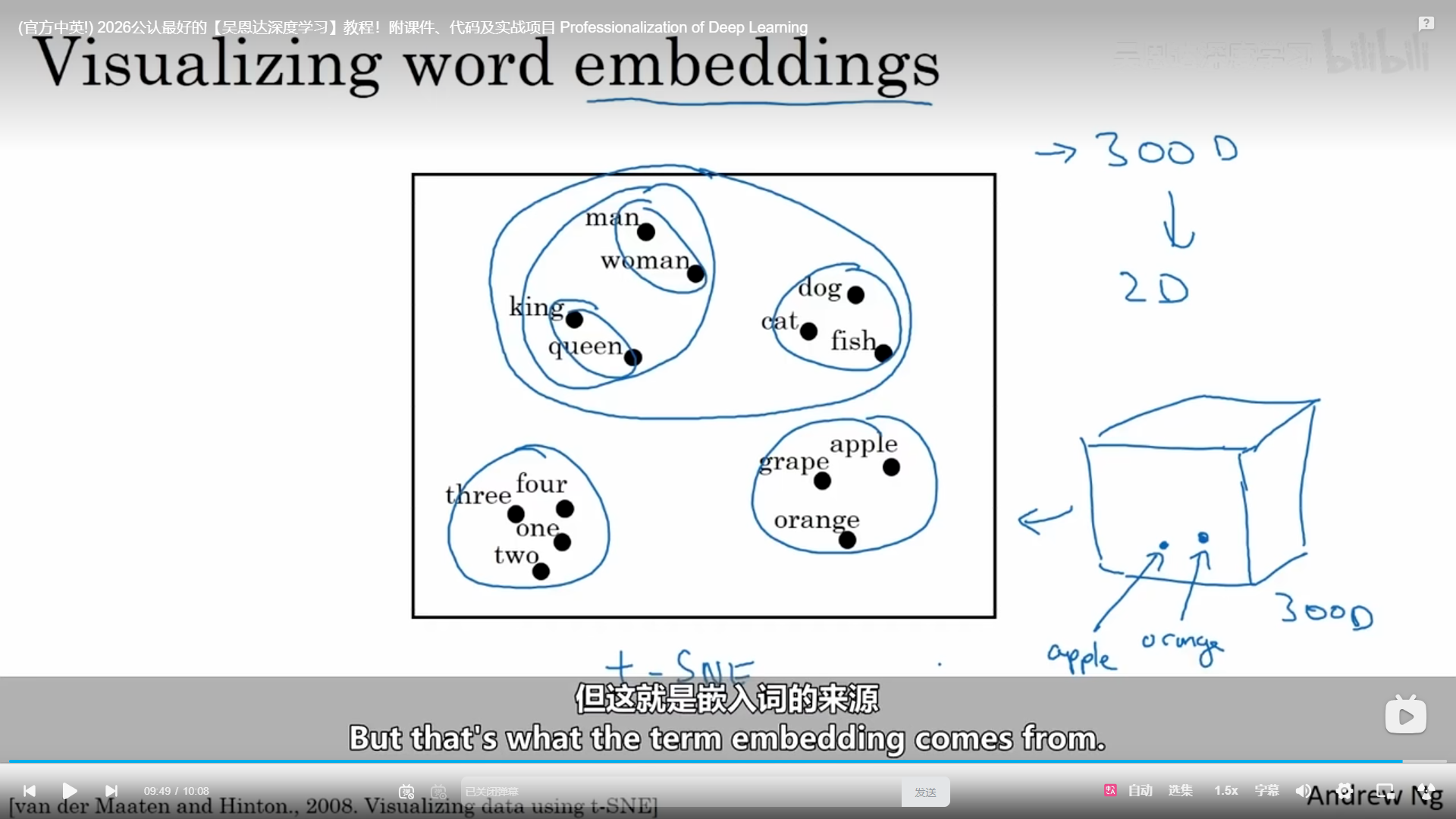
更加直观的理解如下:

1.2 使用词嵌入
第一步:首先是从大量文本语料库学习单词嵌入,或者从网上下载已经训练好的单词嵌入。
第二步:将获得的单词嵌入迁移到有着更小标记训练集的任务上。然后用这个300维的词嵌入来代表单词。
第三步:当你在新任务上训练模型时,可以选择性地去微调参数。继续用新数据调整单词嵌入。

单词嵌入与人脸编码有所关联:人脸识别是需要将人的脸部学习成一个能够代表它的编码,而词嵌入也是学习单词的编码,有着异曲同工之妙。
1.3 词嵌入如何帮助推理类比
词嵌入能够帮我们找到某一个单词可以类比为其他的某一个单词。这里假设我们使用的是4维嵌入:如果算法询问男性对应女性,则国王对应什么?这个算法要做的就是计算出男性和女性编码的差值,然后尝试找到一个向量使得男性和女性的编码差值接近国王和新值差值的向量。

可以将上述过程形式化表示为:
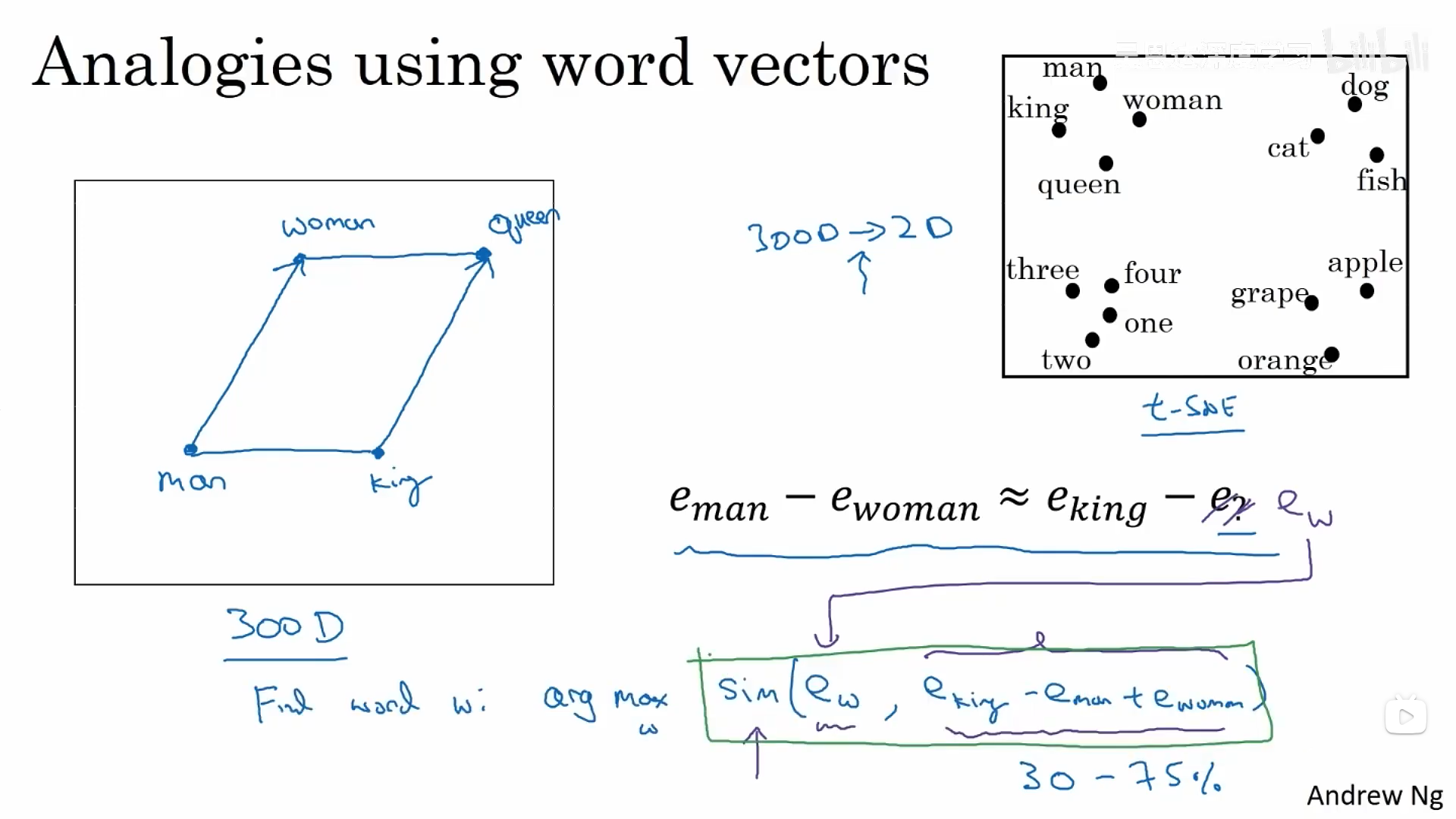
如何计算两者之间的相似度呢?最常用的相似函数为余弦相似度。它实际上是在计算两者之间夹角的余弦值。

当两者之间的夹角为0时,余弦值为1;为90度时,余弦值为0;为180度时,余弦值为-1。

plain
def complete_analogy(word_a, word_b, word_c, word_to_vec_map):
"""
Performs the word analogy task as explained above: a is to b as c is to ____.
"""
# convert words to lower case
word_a, word_b, word_c = word_a.lower(), word_b.lower(), word_c.lower()
### START CODE HERE ###
# 从词向量字典中取出对应的词向量
v_a = word_to_vec_map[word_a] # 获取 word_a 的词向量
v_b = word_to_vec_map[word_b] # 获取 word_b 的词向量
v_c = word_to_vec_map[word_c] # 获取 word_c 的词向量
# 计算类比目标向量:v_b - v_a + v_c
combined_vector = v_b - v_a + v_c # 构造"c 对应的 b"
### END CODE HERE ###
words = word_to_vec_map.keys()
max_cosine_sim = -100
best_word = None
# loop over the whole word vector set
for w in words:
# to avoid best_word being one of the input words, pass on them.
if w in [word_a, word_b, word_c]:
continue
### START CODE HERE ###
# 计算 combined_vector 与当前词向量之间的余弦相似度
cosine_sim = cosine_similarity(combined_vector, word_to_vec_map[w])
# 如果当前相似度大于目前记录的最大相似度
if cosine_sim > max_cosine_sim:
max_cosine_sim = cosine_sim # 更新最大余弦相似度
best_word = w # 更新最优词
### END CODE HERE ###
return best_word1.4 矩阵嵌入
我们可以使用整个单词表的词嵌入矩阵和某一个词的独热编码来进行计算这个词的词嵌入编码。
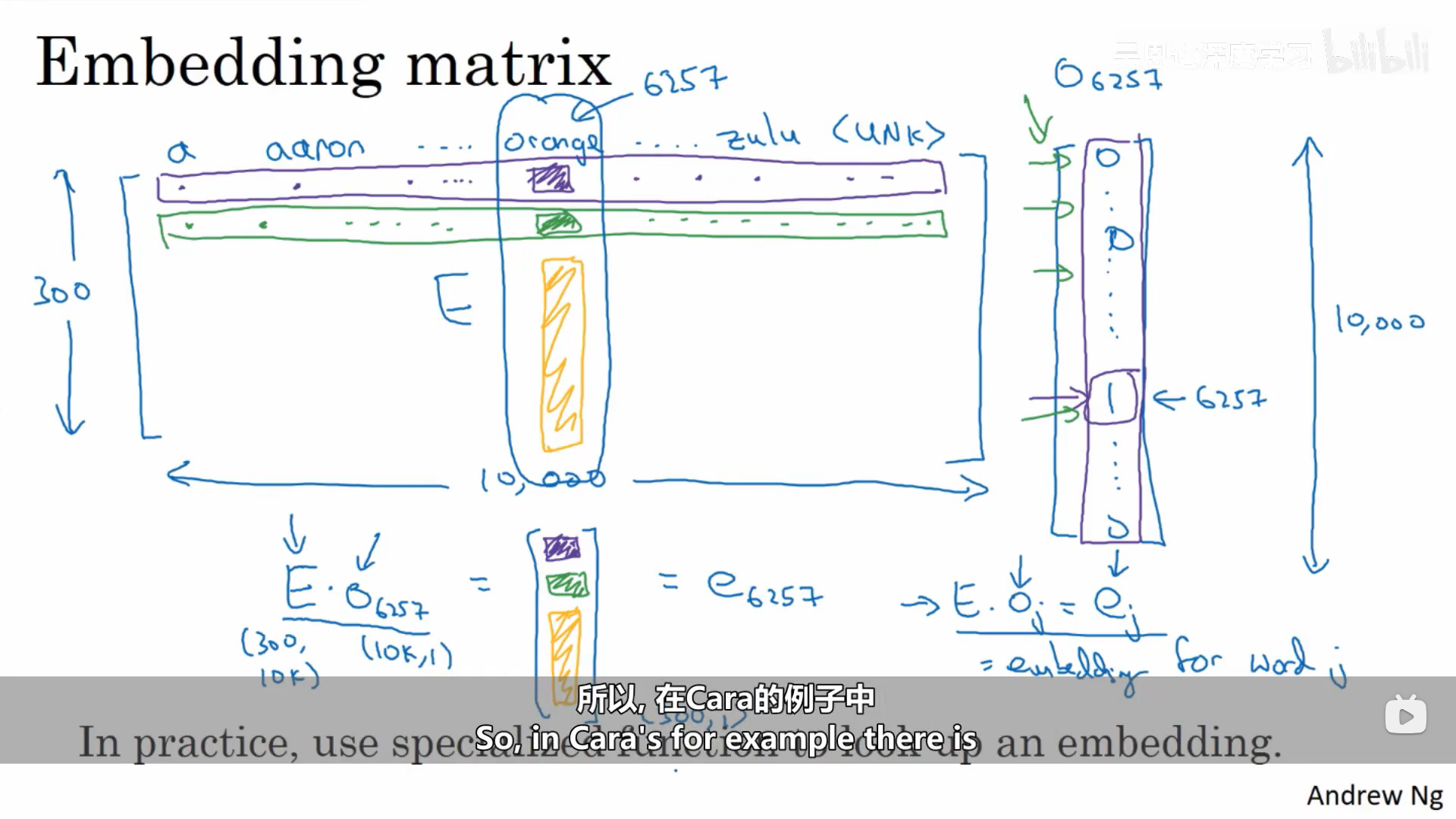
1.5 学习词嵌入
1.5.1 学习嵌入矩阵
构建神经网络语言模型是学习嵌入集合的一个小巧的方式。
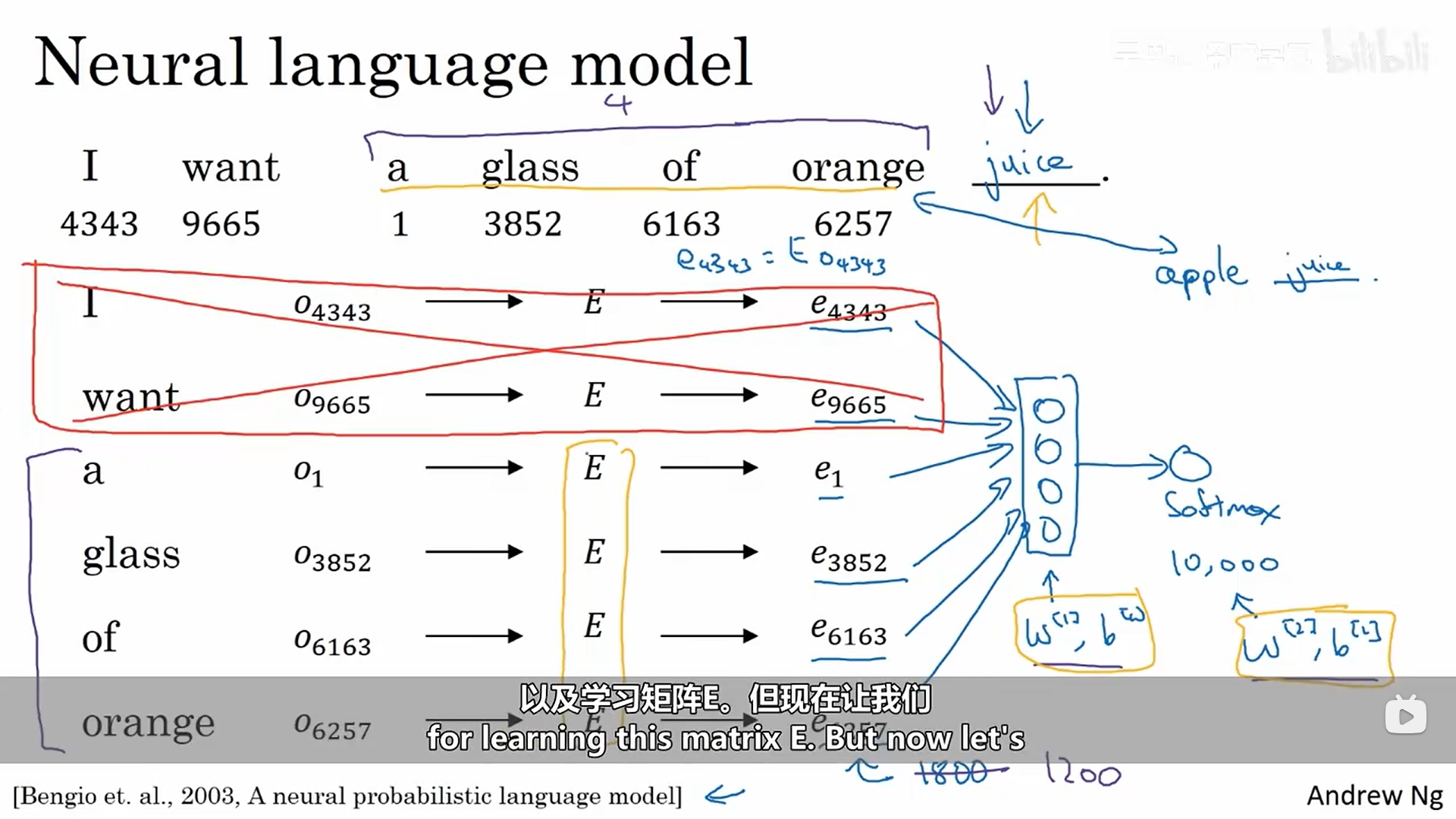
这个算法的参数就是矩阵E。下面有一个更加具体的示例:我们想要预测单词juice,它是我们的目标词,并且给定了一些上下文也就是最后四个单词。目标是学习嵌入。这里学习的上下文我们可以自行设置。但我们真正想要学习一个语言模型时,我们可以使用想要预测的词的后面几个词作为我们的上下文,当我们需要学习嵌入时,则上下文的取值有多种方式。

1.5.2 Word2 VEC模型
1.5.2.1 skip-gram模型
假设训练集给了这样一个示例,在这个模型中,我们要做的就是找出一些语境词到目标词的配对,从而建立监督式学习的问题,随机选一个词作为语境词,然后需要在某个窗口中随意挑选出另外一个单词,选择它作为我们的目标词。 模型具体如下:

这个模型在进行预测,也就是计算预测结果的概率时,并不是一下子就预测出所有的类别,而是像一个树一样的分类器,它的计算花销是按照对数倍增长的,因为损失的分母是需要整合整个词汇库。但是我们有很多方式去构建这棵树,可以加快softmax的分类速度。
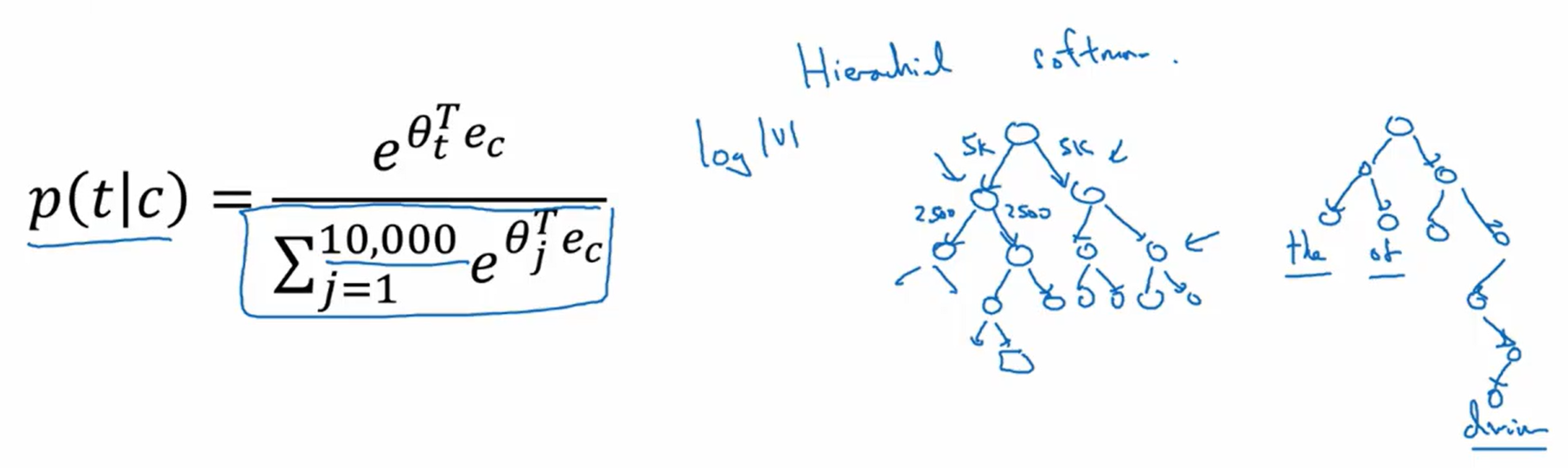
其中模型的训练是需要我们去对c(原始输入的单词)和t(目标单词)进行取样的,我们应该如何取样呢?
在实际应用中,文字的分布P(c)并不全是从训练集中随机均匀采样的,有不同的启发式被使用去平衡常见词汇和罕见词汇。
1.5.2.2 负采样法
负采样法能够达到和skip-gram模型类似的效果,但是采用一种更有效的学习算法。在这个方法中,我们建立一个新的监督学习问题,给定一对单词,我们需要去预测这是否是一对上下文和目标词语。生成数据集的过程:选择一个上下文词语、选择一个目标词语,这个示例就会被标记为1,然后对于某个次数k,我们选取同样的上下文词语,然后从字典中随机抽取词语,得到我们的负样本。然后建立监督式学习,输入就是一对词语,输出则是1或者0的预测。如何选择k值,对于小的数据集,k大概介于5-20之间,如果是很大的数据集,则选取较小的k。
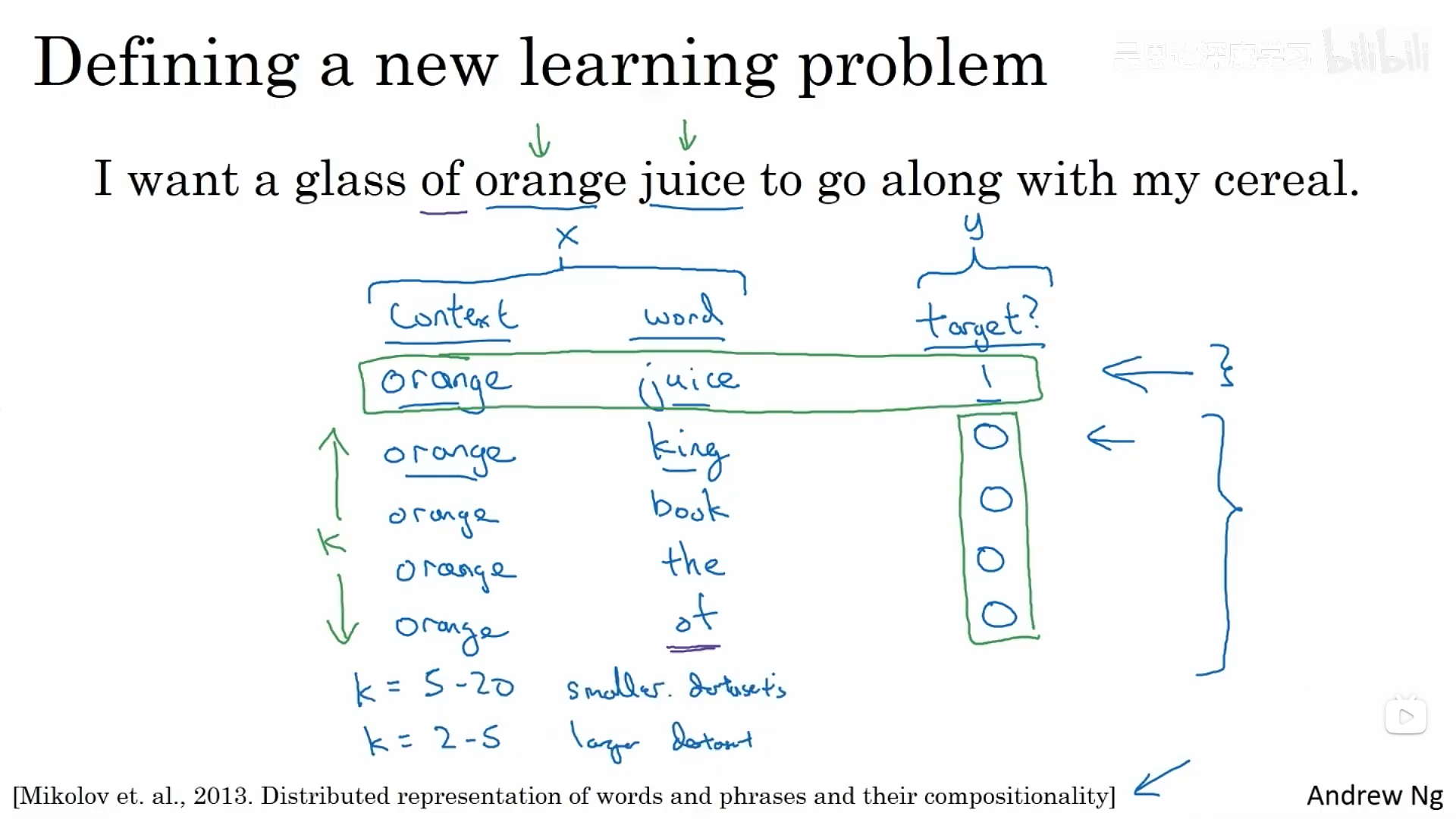
接下来具体描述一下这个算法:这里使用逻辑回归来计算预测结果的概率,转换成神经网络,这里我们不训练有词典大小个分类器,而是只训练k+1个。计算成本大大降低。

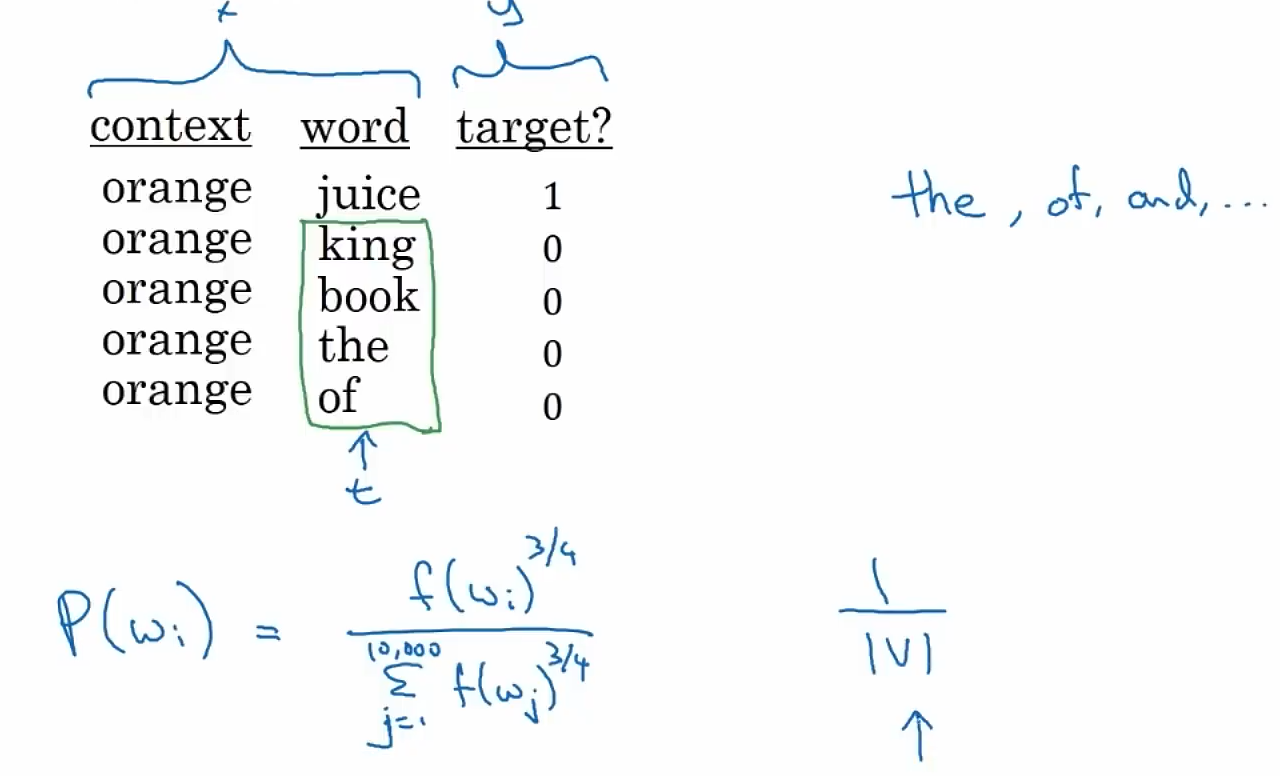
如何选取这些负样本呢?我们可以根据词语出现的频率来进行抽样。也可以根据词频的3/4次幂来抽样。
1.5.3 GloVe(用于词汇表征的全局矢量)算法

模型的目标是最小化下面这个公式,使得它们的内积能够更好地预测两个词语同时出现的频率。

最后一点需要注意的是:我们无法保证用来表示特征的那些坐标(即我们学习到的单词的嵌入编码)可以轻易地和人类容易理解的特征坐标关联起来。
1.6 词嵌入除偏
无论是深度学习还是机器学习,我们都希望我们的算法中没有我们不希望看到的偏见,如性别偏见、种族偏见等。
下面是词嵌入中消除性别偏见的一种方式:身份偏差定义+中性化+均匀化:

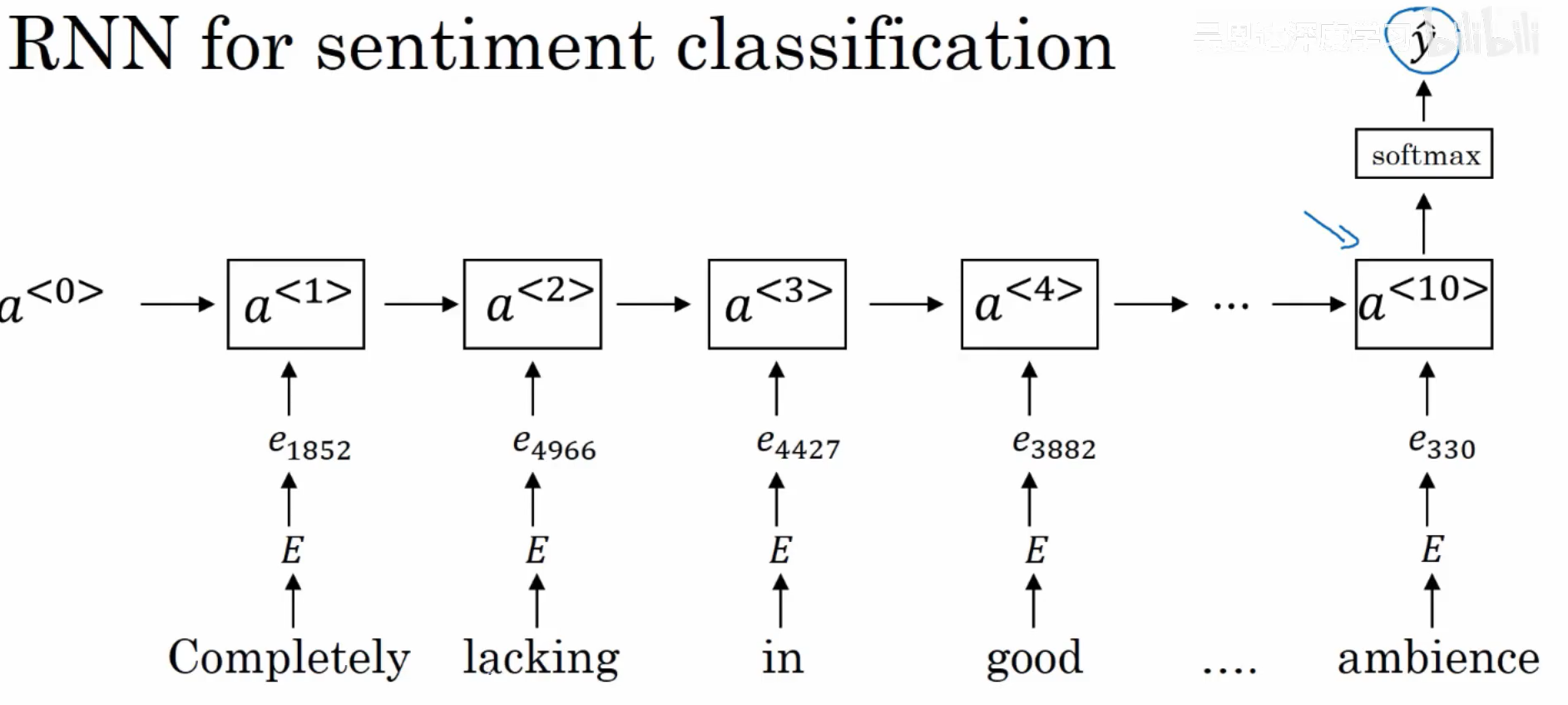
二、情感分类
情感分类示例:

情感分类的问题可能是标签数据集不是很大,而词嵌入能够更好地帮我们了解数据集小的时候的情况。
其中一个简单的预测方式如下图:

同时,我们也可以使用RNN来进行预测: