整体架构
| 组件 | 原始模型 | 升级后模型 | 优势 |
|---|---|---|---|
| 开集检测 | 通用目标检测模型 | DINO | 更强的开放世界检测能力,无需预定义类别 |
| CLIP 模型 | 英文 CLIP | 达摩院 Chinese-CLIP | 支持中文语义,适配本地化查询 |
🛠️ 二、关键组件详解
1. 📸 前视广角图片
- 来源:车载摄像头(ADAS 系统)
- 特点:视野宽、包含多个物体(车、人、路牌等),但无标注
2. 🔍 DINO 模型(用于开集检测)
是什么?
- DINO(DETR with No Object Queries )是 Meta 提出的一种基于 Transformer 的 自监督学习框架
- 实际应用中常指 DINOv2 或 DINOv2-Huge,具有强大的图像特征提取能力
- 可用于:
- 无监督目标分割
- 零样本分类
- 开放词汇检测
如何用在本项目中?
✅ 使用 DINO 的 视觉编码器(ViT-Huge) 提取图像特征,再配合 Open-Vocabulary Detection 方法实现"开集检测"
推荐方式:
-
使用 DINOv2 + Open-Vocabulary Detector (如 Grounding DINO)
-
输入一张广角图 → 输出所有检测框及其描述性标签(如:"红色SUV"、"骑电动车的人")
from groundingdino.models import build_model
from groundingdino.util.sliding_window import sliding_window_inferencemodel = build_model(args)
outputs = model(image, text_prompts=["car", "pedestrian", "traffic sign"])
⭐ 优点:可检测未见过的类别;输出带语义信息的目标区域
3. 🖼️ 目标物级别图片
- 从 DINO 输出的每个检测框中裁剪出独立图像
- 示例:每辆车、每个人、每个标志都变成单独的小图
- 存储格式:
(bbox, image_crop)对
4. 🧠 达摩院 CLIP 模型(damo/chinese-clip)
官方名称:
damo/chinese-clip-vit-base-patch16- 在 ModelScope 上开源,支持中文文本和图像编码
功能:
- 将图像或文本转换为 512 维 embedding 向量
- 图像和文本共享同一语义空间,便于计算相似度
使用示例:
from modelscope.pipelines import pipeline
clip_pipeline = pipeline(
task='multi_modal_embedding',
model='damo/chinese-clip-vit-base-patch16'
)
# 编码图像
img_emb = clip_pipeline({'image': 'car.jpg'})['image_embedding']
# 编码文本
text_emb = clip_pipeline({'text': '一辆黑色奥迪轿车'})['text_embedding']5. 💾 向量数据库
-
推荐工具:FAISS 、Milvus 、Pinecone 、Weaviate
-
存储结构:
{ "id": "001", "embedding": [0.1, 0.2, ..., 0.9], "metadata": { "timestamp": "2025-04-05T10:00:00Z", "camera_id": "cam_01", "bbox": [x1,y1,x2,y2], "description": "黑色奥迪" } }
6. 🔎 数据向量搜索(双通道输入)
支持两种查询方式:
表格
| 查询类型 | 流程 |
|---|---|
| 文本查询 | 用户输入中文 → CLIP 编码 → 查找最相似 embedding |
| 图片查询 | 用户上传图片 → CLIP 编码 → 查找匹配项 |
最终步骤:向量相似度 rerank
# 1. 初步召回 Top-K 结果(ANN 搜索)
candidates = vector_db.search(query_embedding, k=100)
# 2. 对候选结果重新计算余弦相似度
scores = []
for cand in candidates:
score = cosine_sim(query_embedding, cand.embedding)
scores.append(score)
# 3. 按分数排序,返回 top-N
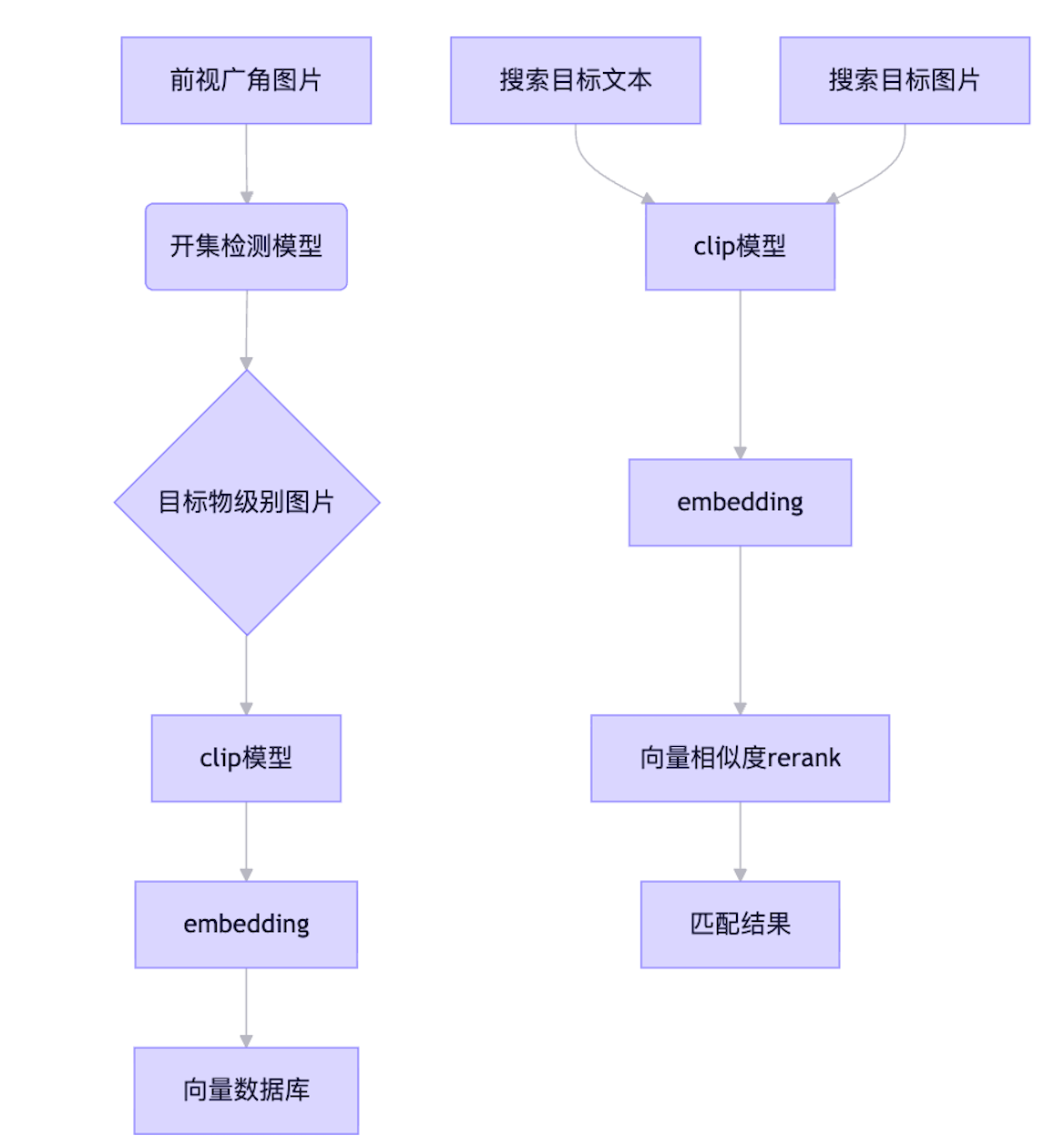
results = sorted(zip(candidates, scores), key=lambda x: x[1], reverse=True)[:10]🚀 三、完整流程图更新版
┌──────────────────────────────────────┐
│ 数据向量化入库 │
├──────────────────────────────────────┤
│ 前视广角图片 ──→ DINO 模型 ──→ 目标物级别图片 ──→ 达摩院 CLIP ──→ embedding ──→ 向量数据库
└──────────────────────────────────────┘
↑
│
┌──────────────────────────────────────┐
│ 数据向量搜索 │
├──────────────────────────────────────┤
│ 搜索目标文本 ──→ 达摩院 CLIP ──→ embedding ──┐
│ 搜索目标图片 ──→ 达摩院 CLIP ──→ embedding ──┤
│ ↓
│ 向量相似度rerank
│ ↓
│ 匹配结果
└──────────────────────────────────────┘