目录
[1. 核心思想](#1. 核心思想)
[2. 性能表现](#2. 性能表现)
[3. MoE vs 稠密模型](#3. MoE vs 稠密模型)
[1. Skill Neuron(能力神经元)](#1. Skill Neuron(能力神经元))
[2. 语言神经元](#2. 语言神经元)
[3. 情感神经元](#3. 情感神经元)
[1. ReLU vs Swish](#1. ReLU vs Swish)
[1. PowerInfer 混合推理](#1. PowerInfer 混合推理)
[2. PowerInfer2 进阶优化](#2. PowerInfer2 进阶优化)
[1. 投机采样](#1. 投机采样)
[2. Medusa 解码](#2. Medusa 解码)
[3. 高速树状投机(EAGLE)](#3. 高速树状投机(EAGLE))
[1. 分块计算](#1. 分块计算)
[2. 丢弃词元](#2. 丢弃词元)
[3. 算子优化](#3. 算子优化)
[混合专家模型 MoE](#混合专家模型 MoE)
[1. Token 负载均衡](#1. Token 负载均衡)
[2. 计算负载均衡](#2. 计算负载均衡)
[3. 专家并行通信](#3. 专家并行通信)
[Block FFN](#Block FFN)
本文深入解析大模型架构的最新进展,揭示稀疏激活、MoE 架构,再到极致量化技术,全面展现大模型效率优化的技术路径。
通用智能时代的三大支柱
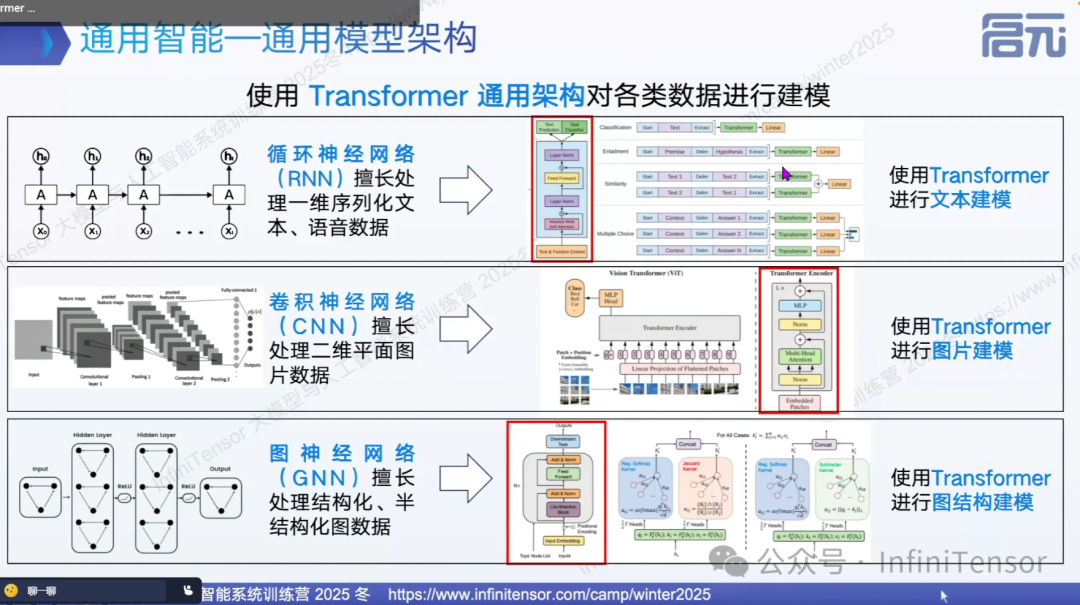
架构统一
Transformer 架构的出现实现了 AI 模型架构的统一:
-
• 文本处理:将文本转换为 token 序列
-
• 图像处理:将图像分割为 patch 序列
-
• 图结构:对节点和连接关系进行编码
这种统一架构使得单一模型能够处理多模态任务,奠定了通用智能的基础。
学习方法统一
通过"预测下一个 token"的自回归方式,各类 NLP 任务均可转化为序列生成问题:
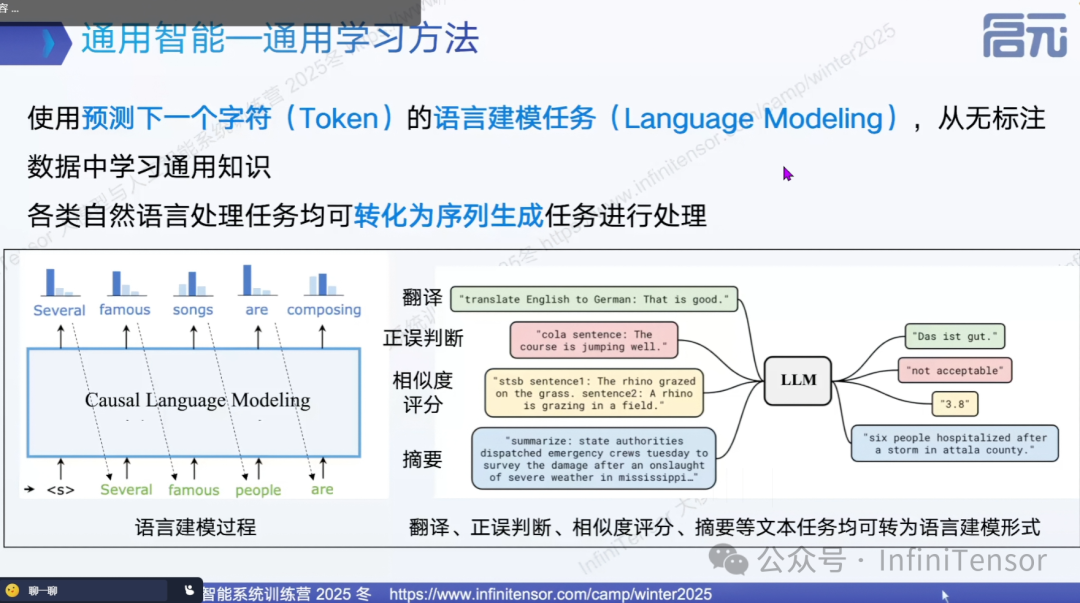
这种统一的学习范式使得模型能够进行多任务联合训练,获得通用能力。
通用模型能力
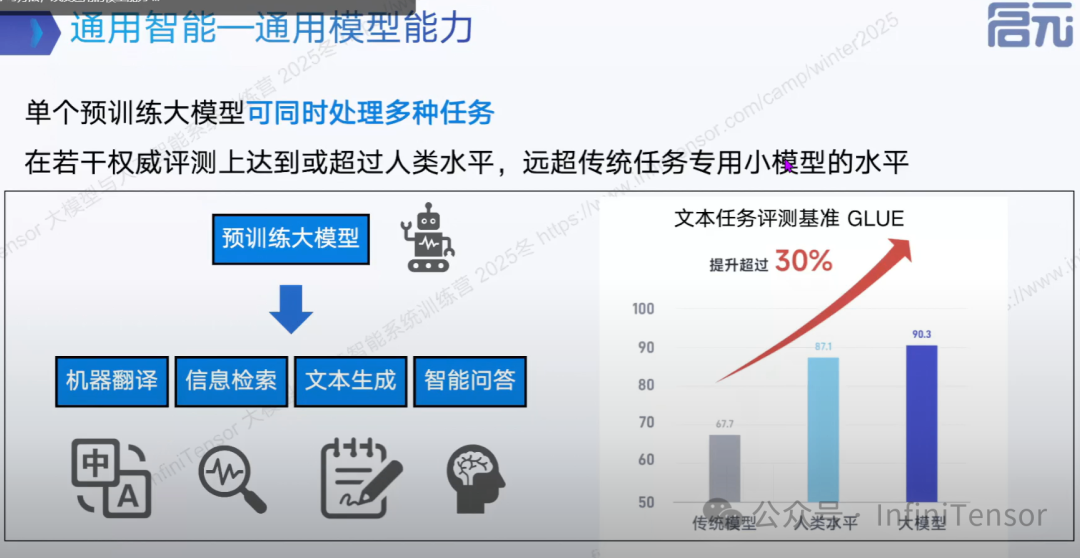
大模型结构高效
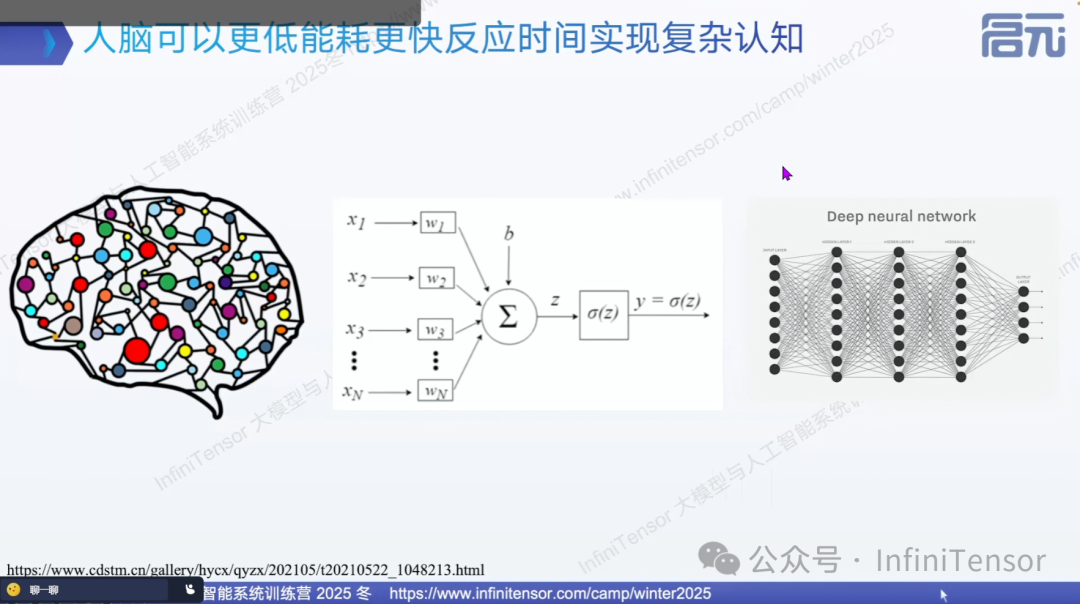
人脑 vs 大模型
-
• 神经元规模:人脑约数百亿级别神经元,GPT-3 约 1750 亿参数,规模相当
-
• 能耗对比:GPT-3 单次推理 400 瓦,人脑不到 15 瓦
-
• 响应时间:GPT-3 约 2000 毫秒,人脑不到 100 毫秒
-
• 关键差异:人脑神经元激活比例不到 5%,而大模型接近 100%
稀疏激活现象
研究发现大模型具有自发的稀疏激活特性:

混合专家(MoE)架构
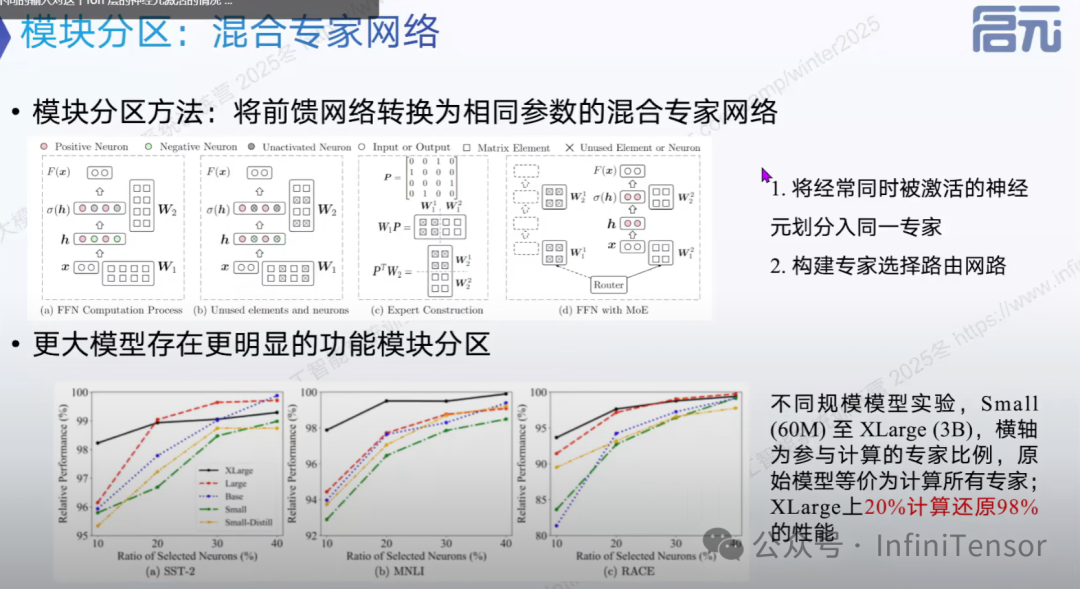
1. 核心思想
将稠密前馈网络(FFN)转换为混合专家网络:
-
• 专家划分:将经常同时激活的神经元分组为专家
-
• 路由机制:根据输入选择最相关的专家进行计算
-
• 稀疏激活:每次只激活部分专家,大幅减少计算量
2. 性能表现
-
• 3B 模型:20% 的计算量可还原 98% 的性能
-
• 模型规模效应:更大的模型具有更明显的功能模块分区
3. MoE vs 稠密模型
实验表明,MoE 架构能更好地刻画模型的模块化性质,功能神经元在专家中的比例更高。
功能神经元
1. Skill Neuron(能力神经元)
特定神经元对任务标签具有高度预测性:
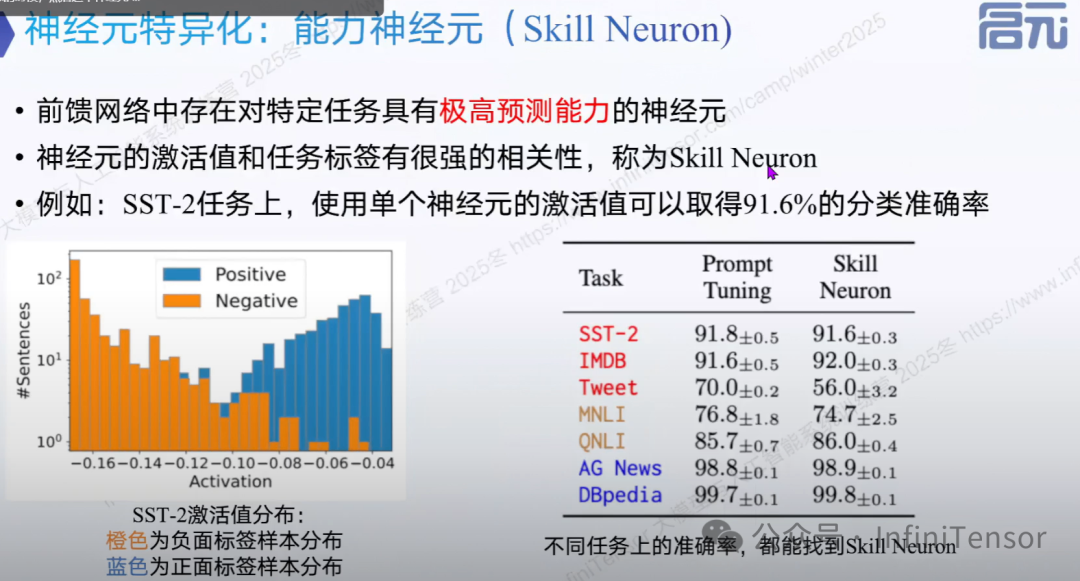
2. 语言神经元
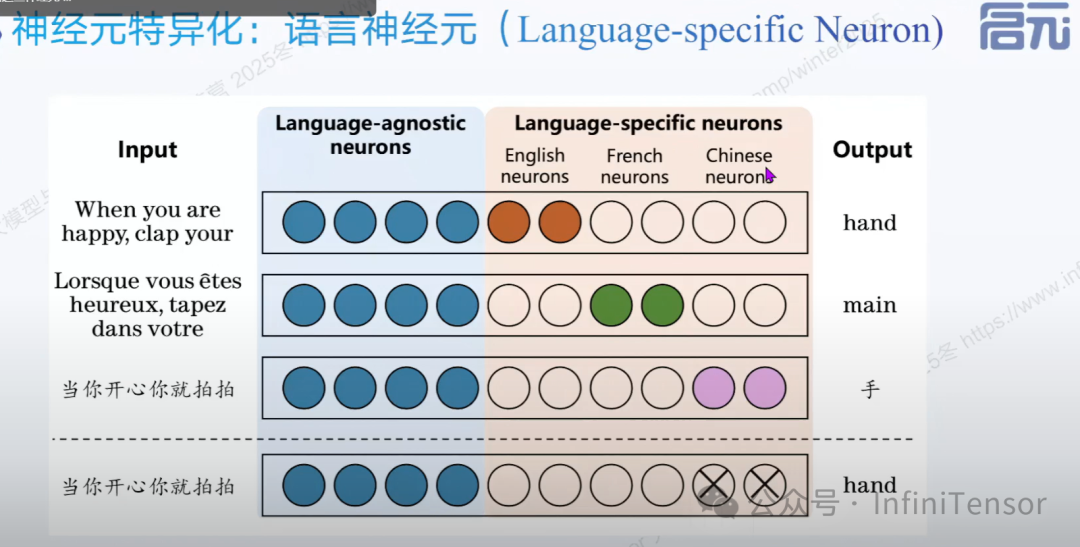
3. 情感神经元
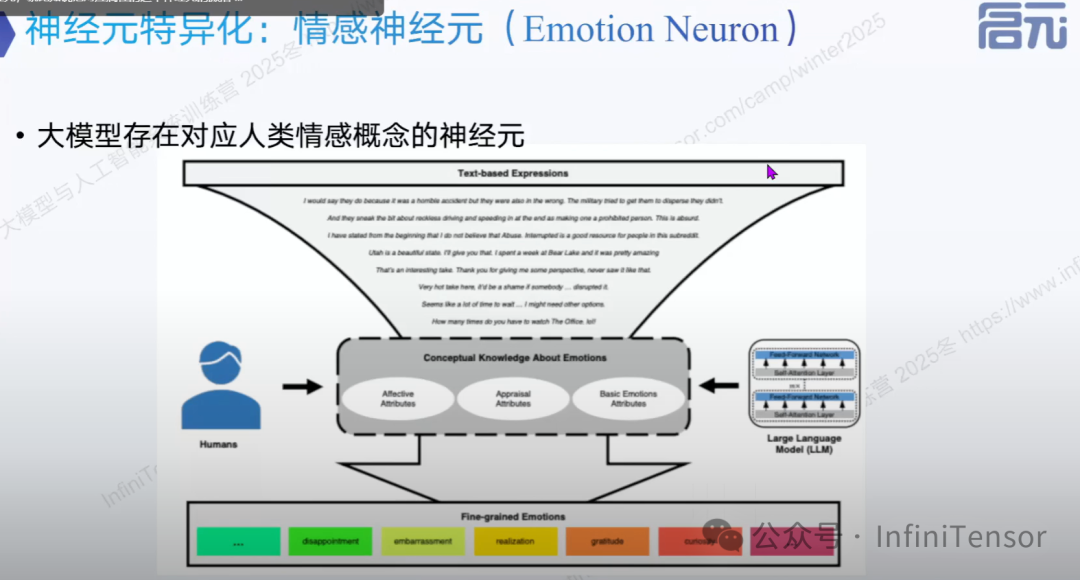
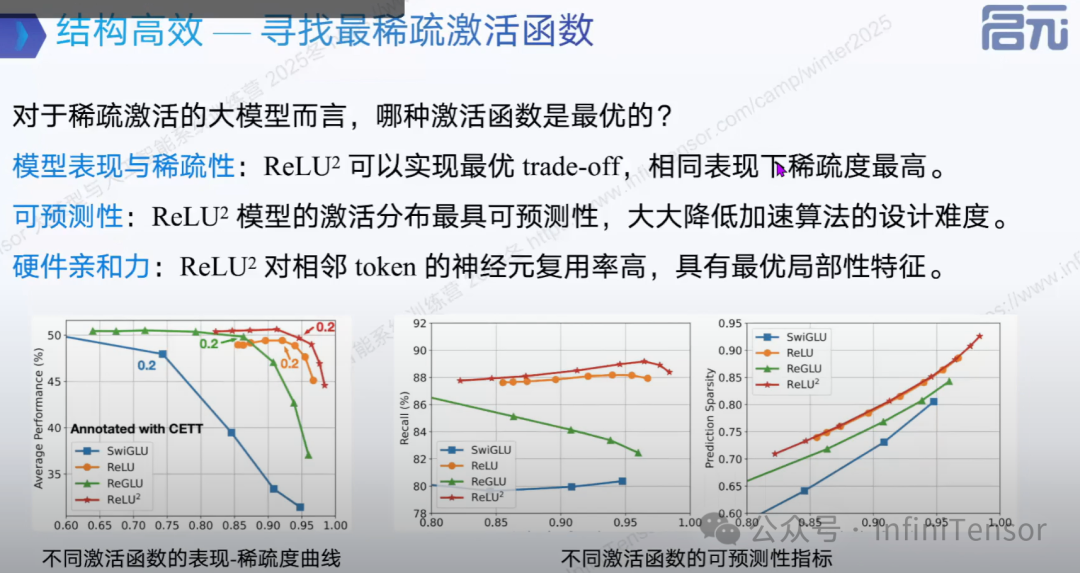
稀疏激活函数
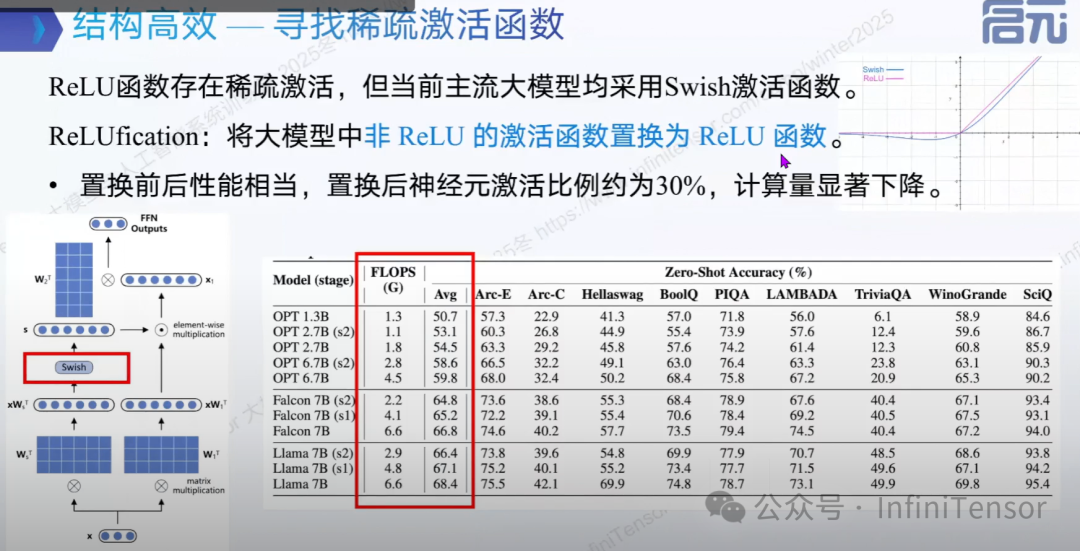
1. ReLU vs Swish
-
• ReLU:将负数直接置零,产生稀疏激活
-
• Swish:平滑处理所有输入值,保持参数吸收性但降低稀疏性
大模型计算高效
低位宽优化
- • 通过降低参数精度提升效率:
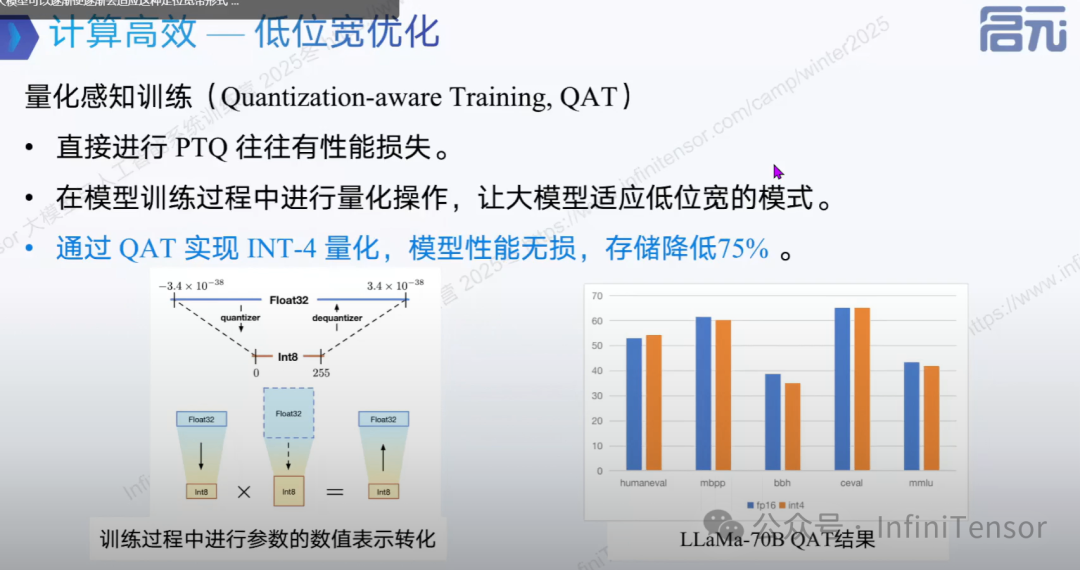
- • 效果:减少带宽需求,提升训练/推理速度
标量与向量量化的统一
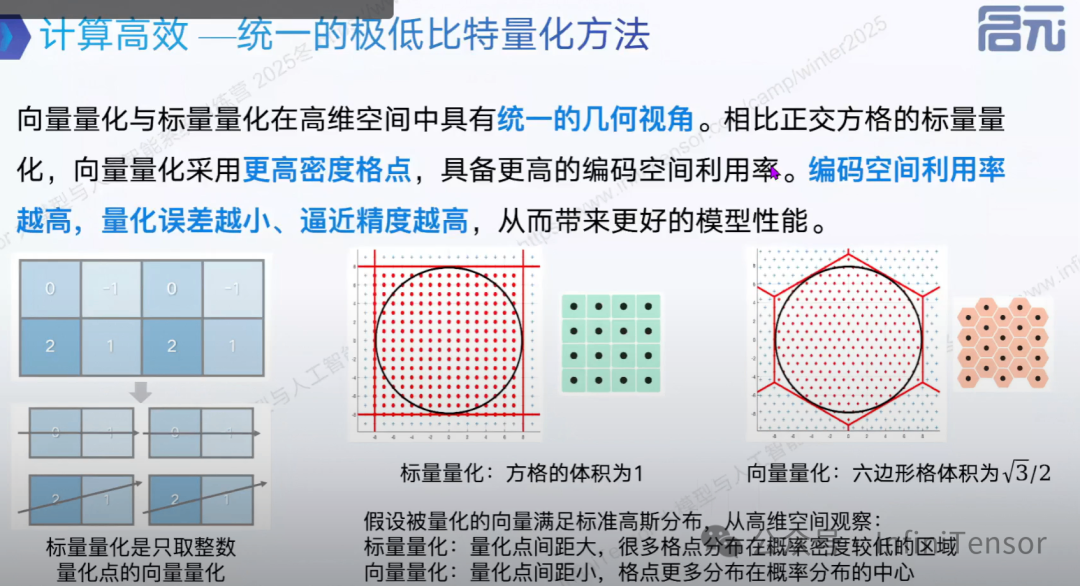
稀疏优化
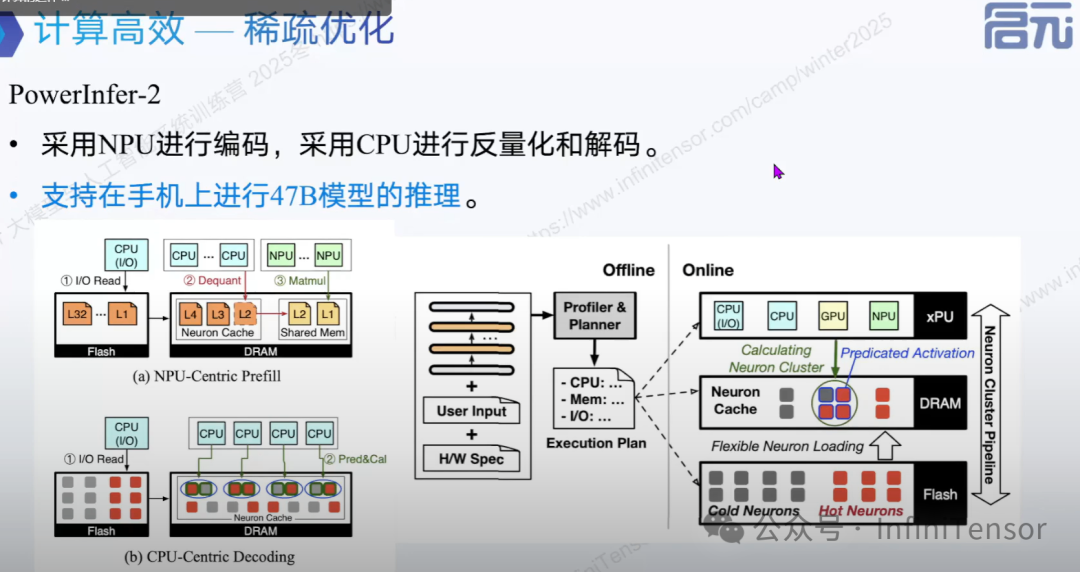
1. PowerInfer 混合推理

2. PowerInfer2 进阶优化
高效解码技术
1. 投机采样
大小模型协同解码:
-
• 草稿模型:小模型为大模型打草稿
-
• 并行验证:大模型同时验证多个 token
-
• 加速效果:推理速度提升 1.6-2 倍
2. Medusa 解码
-
• 轻量解码头:可并行训练的预测头
-
• 树状注意力:同时验证多条候选路径
-
• 加速效果:约 2 倍推理加速
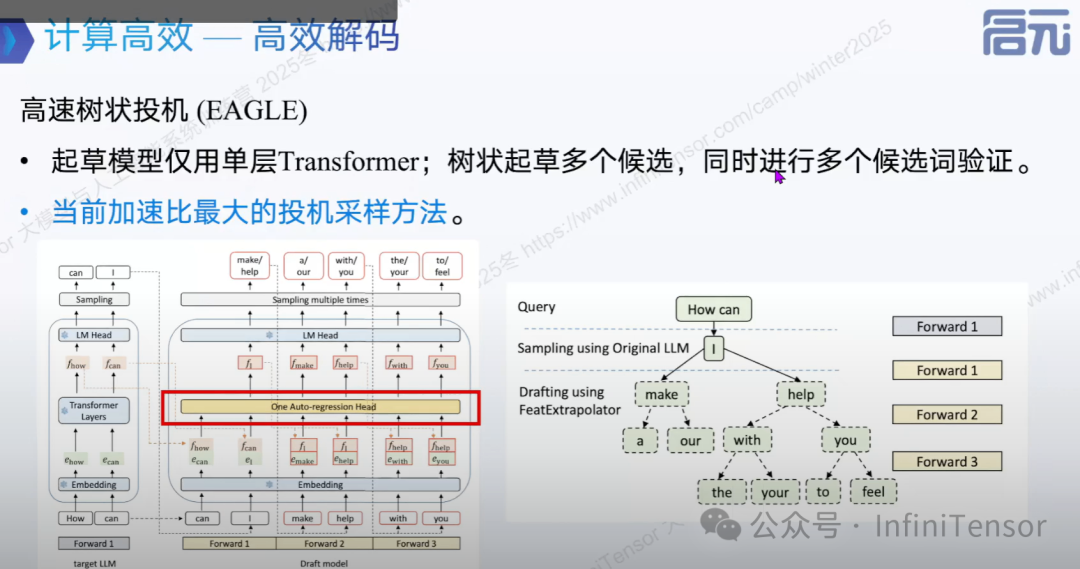
3. 高速树状投机(EAGLE)
-
• 极简起草:仅用一层全连接层起草
-
• 特征复用:利用倒数第二层特征消除随机性
-
• 加速效果:比 Medusa 再快 1-1.6 倍
大词表优化
针对 10 万+词表的起草瓶颈:
-
• 长尾分布:75% 的词出现频率总和小于 5%
-
• 高频词起草:仅预测前 32K 高频词
-
• 加速效果:A100 上额外带来 1.1-1.8 倍加速,3090 上达 1.2-5.2 倍
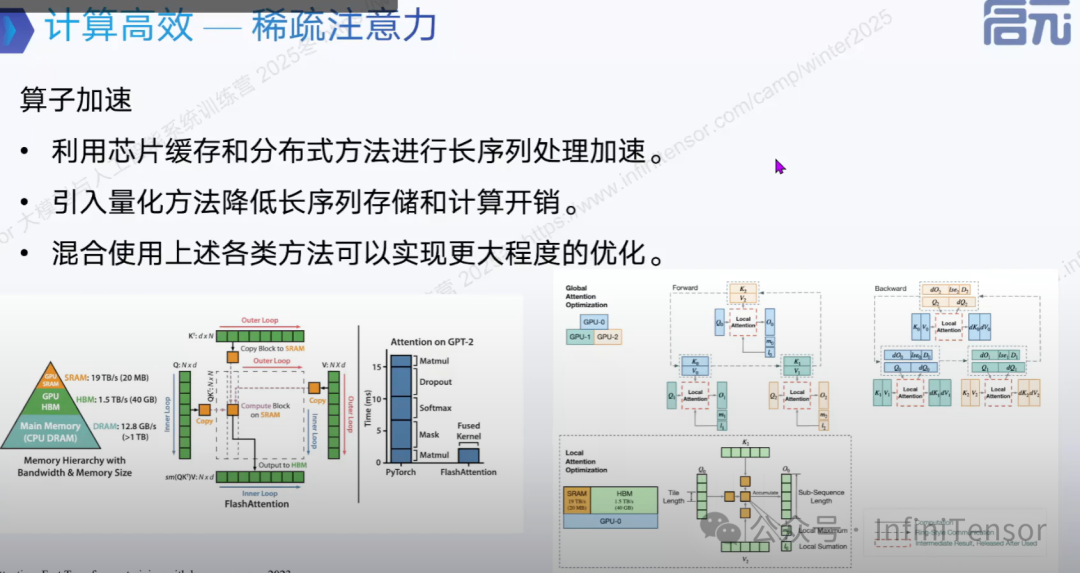
注意力机制优化
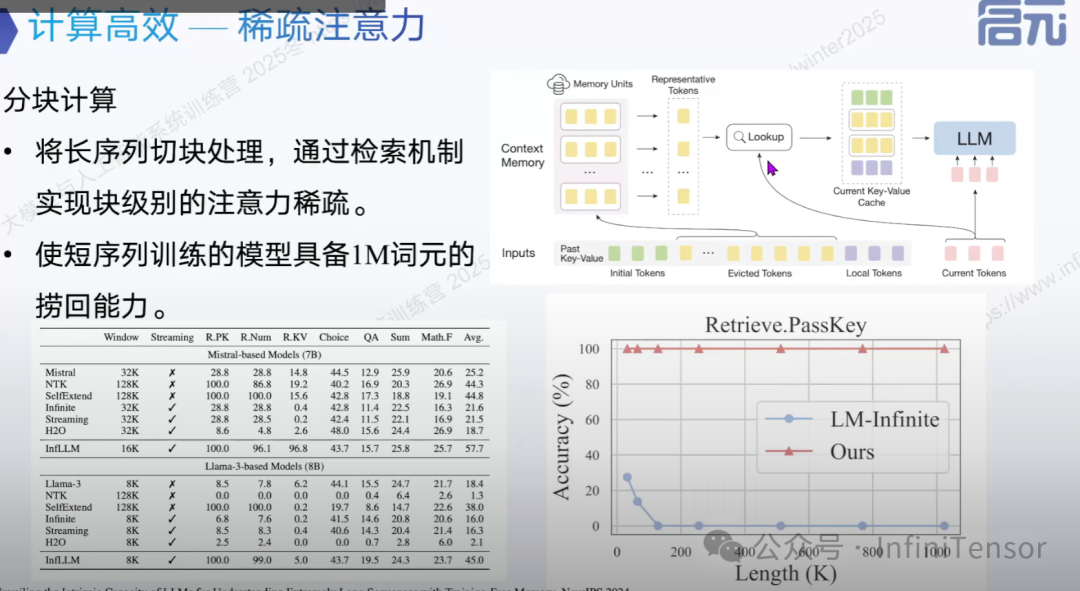
1. 分块计算
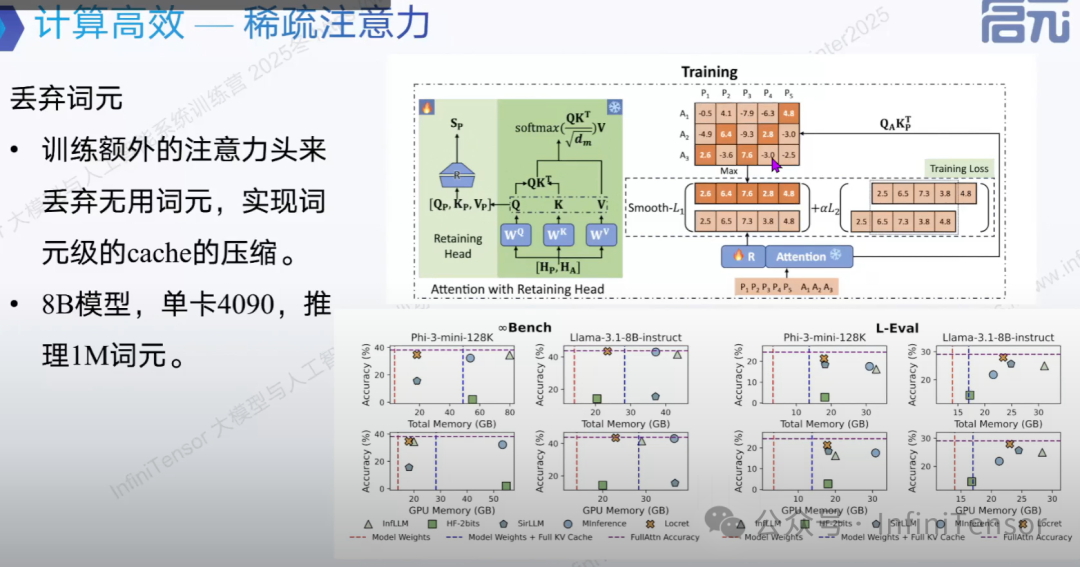
2. 丢弃词元
3. 算子优化
混合专家模型与大模型稀疏化
混合专家模型 MoE
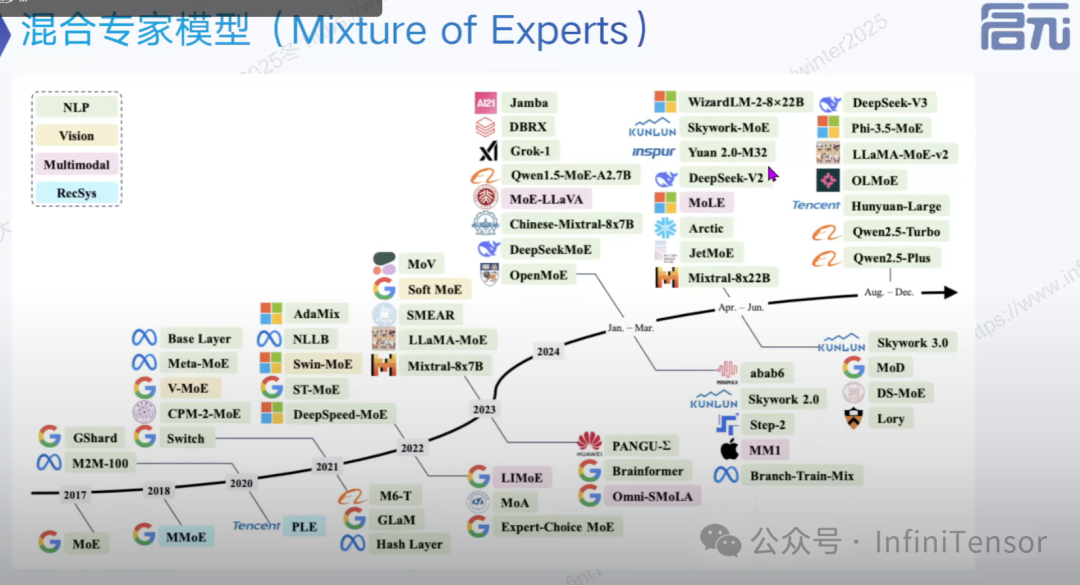

核心挑战
1. Token 负载均衡
-
• 问题:Token 倾向于发送到少数受欢迎的专家
-
• 解决方案:
-
• 辅助损失:确保每个专家有相同重要性
-
• 随机路由:TOP2 中第二个专家按权重随机选择
-
2. 计算负载均衡
-
• 问题:不同专家处理的 token 数量不均,导致计算不平衡
-
• 解决方案:Megablocks 方法支持块稀疏矩阵乘法,灵活适应不均衡分配
3. 专家并行通信
-
• 架构:路由网络复制到每个计算单元,专家网络独立部署
-
• 通信模式:Token 智能路由到对应专家节点,结果返回原节点
-
• 扩展性:专家数量与 GPU 数量正相关
创新方向
ReMoE
-
• 可微路由:用 ReLU 激活替代 TOPK + Softmax
-
• 优势:更好的专家数量可扩展性
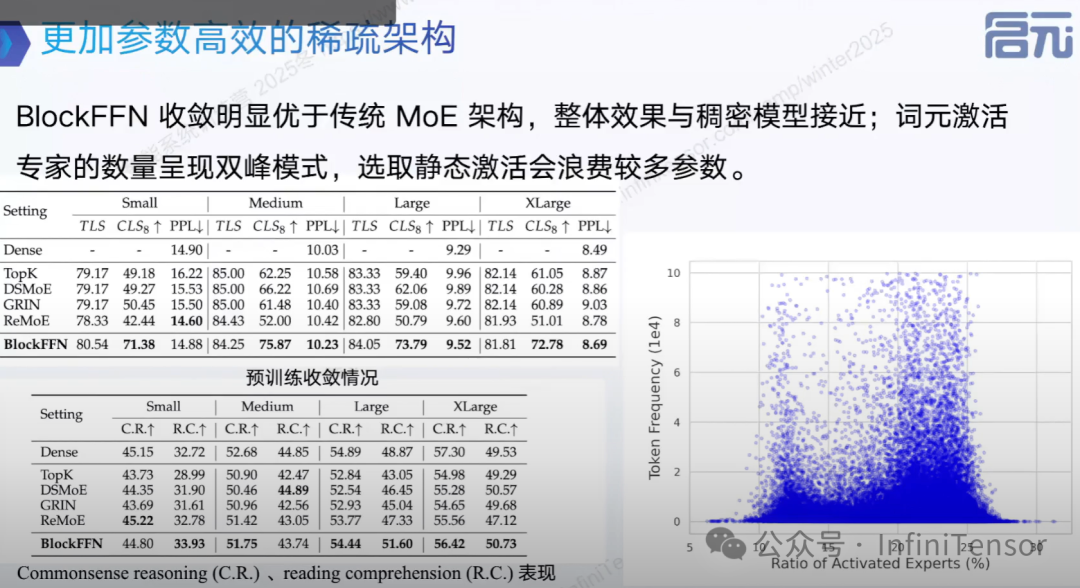
Block FFN
-
• LoRA启发:将 FFN 分解为类似 LoRA 的模块
-
• 动态路由:激活数量完全由稀疏激活函数决定
-
• 优势:兼顾稀疏动态性和结构性,访存模式更集中
总结
大模型架构正从单纯的规模扩张转向效率优先的精细化设计。通过稀疏激活 、MoE架构 、量化技术 和推理优化的协同创新,业界正在构建更加高效、可持续的大模型生态系统。
这些技术不仅解决了当前的计算和能耗瓶颈,更为未来更大规模、更复杂任务的 AI 系统奠定了基础。在通用智能的道路上,效率与能力的平衡将成为持续探索的重要方向。