引言
循环神经网络(RNN)通常被视为处理序列数据的利器,如自然语言处理或时间序列预测。但你是否想过,RNN 也能胜任图像分类任务?本文将介绍如何使用 PyTorch 构建一个基于 LSTM 的模型来处理经典的 MNIST 手写数字识别任务,灵感来源于 TensorFlow Keras 的官方 RNN 示例 。
为什么用 RNN 做图像分类?
MNIST 数据集中的图像是 28×28 的灰度图。传统上,我们会使用 CNN 来提取空间特征。但换个角度:如果将每一行(或列)像素视为一个时间步,整张图片就变成了一个序列------28 个时间步,每个时间步包含 28 个特征。这种视角让 RNN 有了用武之地,同时也展示了 RNN 处理非传统序列数据的能力。
模型架构解析
核心思路是用 LSTM 逐行"阅读"图像,就像阅读文本一样:
python
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.rnn = nn.LSTM(input_size=28, hidden_size=64, batch_first=True)
self.batchnorm = nn.BatchNorm1d(64)
self.dropout1 = nn.Dropout2d(0.25)
self.dropout2 = nn.Dropout2d(0.5)
self.fc1 = nn.Linear(64, 32)
self.fc2 = nn.Linear(32, 10)
def forward(self, input):
# 将 (batch, 1, 28, 28) 重塑为 (batch, 28, 28) 以适应 RNN
input = input.reshape(-1, 28, 28)
output, hidden = self.rnn(input)
# 取序列最后一个时间步的输出
output = output[:, -1, :]
output = self.batchnorm(output)
output = self.dropout1(output)
output = self.fc1(output)
output = F.relu(output)
output = self.dropout2(output)
output = self.fc2(output)
return F.log_softmax(output, dim=1)关键设计点:
-
LSTM 层:输入维度 28(每行像素数),隐藏层 64,自动学习行与行之间的时序依赖
-
取最后时刻 :
output[:, -1, :]获取最后行的隐藏状态,聚合了整图信息 -
正则化:BatchNorm + Dropout 防止过拟合
-
分类头:两层全连接将 64 维特征映射到 10 个数字类别
数据预处理
python
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])使用 MNIST 数据集的标准归一化参数,将像素值缩放到适合神经网络的范围。
训练配置与技巧
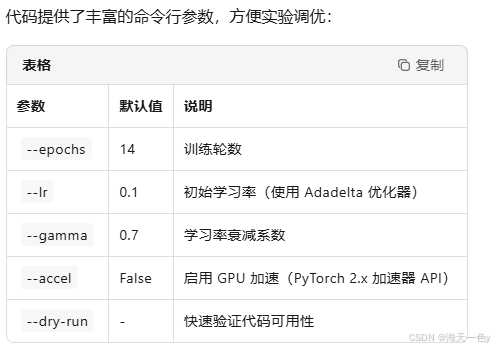
优化策略:
-
使用 Adadelta 替代 SGD,自适应学习率减少调参负担
-
StepLR 调度器每轮衰减学习率,帮助收敛
运行方式
bash
# 安装依赖
pip install torch torchvision
# CPU 训练
python main.py
# GPU 加速训练
python main.py --accel
# 快速验证(仅跑一个 batch)
python main.py --dry-run
# 保存训练好的模型
python main.py --save-modelPyTorch 的实现更灵活:
-
显式控制:前向传播、损失计算、反向传播步骤清晰可见
-
动态图:调试方便,可在 forward 中打断点检查张量形状
-
设备管理 :手动控制
device对象,更透明地管理 CPU/GPU 切换
总结与扩展
这个示例虽小,却展示了 RNN 的灵活性。你可以尝试:
-
双向 LSTM (
bidirectional=True) 同时捕捉上下行信息 -
Attention 机制 替代简单的取最后时刻
-
GRU 替代 LSTM 减少参数量
-
应用到其他序列化图像数据(如文档扫描件)
完整代码:
python
from __future__ import print_function
import argparse
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.optim.lr_scheduler import StepLR
from torchvision import datasets, transforms
from tqdm import tqdm # 导入 tqdm
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.rnn = nn.LSTM(input_size=28, hidden_size=64, batch_first=True)
self.batchnorm = nn.BatchNorm1d(64)
self.dropout1 = nn.Dropout2d(0.25)
self.dropout2 = nn.Dropout2d(0.5)
self.fc1 = nn.Linear(64, 32)
self.fc2 = nn.Linear(32, 10)
def forward(self, input):
# Shape of input is (batch_size,1, 28, 28)
# converting shape of input to (batch_size, 28, 28)
# as required by RNN when batch_first is set True
input = input.reshape(-1, 28, 28)
output, hidden = self.rnn(input)
# RNN output shape is (seq_len, batch, input_size)
# Get last output of RNN
output = output[:, -1, :]
output = self.batchnorm(output)
output = self.dropout1(output)
output = self.fc1(output)
output = F.relu(output)
output = self.dropout2(output)
output = self.fc2(output)
output = F.log_softmax(output, dim=1)
return output
def train(args, model, device, train_loader, optimizer, epoch):
model.train()
# 使用 tqdm 包装 train_loader,添加动态信息显示
pbar = tqdm(enumerate(train_loader), total=len(train_loader),
desc=f'Epoch {epoch}/{args.epochs}', ncols=100)
for batch_idx, (data, target) in pbar:
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
# 更新 tqdm 的后缀显示当前 loss 和进度
pbar.set_postfix({
'loss': f'{loss.item():.6f}',
'batch': f'{batch_idx}/{len(train_loader)}'
})
if args.dry_run:
break
pbar.close()
def test(args, model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
# 使用 tqdm 包装 test_loader
pbar = tqdm(test_loader, desc='Testing', ncols=100, leave=False)
with torch.no_grad():
for data, target in pbar:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
# 实时更新准确率
current_acc = 100. * correct / len(test_loader.dataset)
pbar.set_postfix({'acc': f'{current_acc:.2f}%'})
if args.dry_run:
break
pbar.close()
test_loss /= len(test_loader.dataset)
accuracy = 100. * correct / len(test_loader.dataset)
print(f'\nTest set: Average loss: {test_loss:.4f}, '
f'Accuracy: {correct}/{len(test_loader.dataset)} ({accuracy:.0f}%)\n')
def main():
# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example using RNN')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=14, metavar='N',
help='number of epochs to train (default: 14)')
parser.add_argument('--lr', type=float, default=0.1, metavar='LR',
help='learning rate (default: 0.1)')
parser.add_argument('--gamma', type=float, default=0.7, metavar='M',
help='learning rate step gamma (default: 0.7)')
parser.add_argument('--accel', action='store_true',
help='enables accelerator')
parser.add_argument('--dry-run', action='store_true',
help='quickly check a single pass')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--save-model', action='store_true',
help='for Saving the current Model')
args = parser.parse_args()
if args.accel:
device = torch.accelerator.current_accelerator()
else:
device = torch.device("cpu")
torch.manual_seed(args.seed)
kwargs = {'num_workers': 1, 'pin_memory': True} if args.accel else {}
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=args.batch_size, shuffle=True, **kwargs)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=args.test_batch_size, shuffle=True, **kwargs)
model = Net().to(device)
optimizer = optim.Adadelta(model.parameters(), lr=args.lr)
scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma)
# 添加总体进度条显示 epoch 进度
epoch_pbar = tqdm(range(1, args.epochs + 1), desc='Overall Progress',
position=0, ncols=100)
for epoch in epoch_pbar:
epoch_pbar.set_postfix({'lr': f'{scheduler.get_last_lr()[0]:.6f}'})
train(args, model, device, train_loader, optimizer, epoch)
test(args, model, device, test_loader)
scheduler.step()
epoch_pbar.close()
if args.save_model:
torch.save(model.state_dict(), "mnist_rnn.pt")
tqdm.write(f"Model saved to mnist_rnn.pt")
if __name__ == '__main__':
main()运行结果:
bash
Overall Progress: 0%| | 0/14 [00:00<?, ?it/s, lr=0.100000]/home/haichao/MLSTAT/anaconda/envs/mlstat/lib/python3.11/site-packages/torch/nn/functional.py:1538: UserWarning: dropout2d: Received a 2-D input to dropout2d, which is deprecated and will result in an error in a future release. To retain the behavior and silence this warning, please use dropout instead. Note that dropout2d exists to provide channel-wise dropout on inputs with 2 spatial dimensions, a channel dimension, and an optional batch dimension (i.e. 3D or 4D inputs).
warnings.warn(warn_msg)
Epoch 1/14: 100%|███████████████████| 938/938 [00:12<00:00, 75.10it/s, loss=1.013126, batch=937/938]
Epoch 1/14: 99%|██████████████████▉| 932/938 [00:12<00:00, 89.55it/s, loss=1.013126, batch=937/938]
Test set: Average loss: 0.7654, Accuracy: 7548/10000 (75%)
Epoch 2/14: 100%|███████████████████| 938/938 [00:11<00:00, 84.62it/s, loss=0.579384, batch=937/938]
Epoch 2/14: 99%|██████████████████▉| 933/938 [00:11<00:00, 93.70it/s, loss=0.579384, batch=937/938]
Test set: Average loss: 0.4426, Accuracy: 8544/10000 (85%)
Epoch 3/14: 100%|███████████████████| 938/938 [00:10<00:00, 89.23it/s, loss=0.406930, batch=937/938]
Epoch 3/14: 99%|██████████████████▉| 932/938 [00:10<00:00, 91.98it/s, loss=0.406930, batch=937/938]
Test set: Average loss: 0.3288, Accuracy: 9025/10000 (90%)
Epoch 4/14: 100%|███████████████████| 938/938 [00:10<00:00, 88.78it/s, loss=0.716000, batch=937/938]
Epoch 4/14: 100%|██████████████████▉| 934/938 [00:10<00:00, 92.20it/s, loss=0.716000, batch=937/938]
Test set: Average loss: 0.2768, Accuracy: 9193/10000 (92%)
Epoch 5/14: 100%|███████████████████| 938/938 [00:10<00:00, 88.77it/s, loss=0.157785, batch=937/938]
Epoch 5/14: 100%|██████████████████▉| 934/938 [00:10<00:00, 94.86it/s, loss=0.157785, batch=937/938]
Test set: Average loss: 0.2519, Accuracy: 9251/10000 (93%)
Epoch 6/14: 100%|███████████████████| 938/938 [00:10<00:00, 89.81it/s, loss=0.524307, batch=937/938]
Epoch 6/14: 99%|██████████████████▉| 932/938 [00:10<00:00, 80.61it/s, loss=0.524307, batch=937/938]
Test set: Average loss: 0.2388, Accuracy: 9282/10000 (93%)
Epoch 7/14: 100%|███████████████████| 938/938 [00:10<00:00, 86.33it/s, loss=0.347808, batch=937/938]
Epoch 7/14: 100%|██████████████████▉| 937/938 [00:10<00:00, 80.96it/s, loss=0.347808, batch=937/938]
Test set: Average loss: 0.2286, Accuracy: 9318/10000 (93%)
Epoch 8/14: 100%|███████████████████| 938/938 [00:10<00:00, 87.81it/s, loss=0.483327, batch=937/938]
Epoch 8/14: 99%|██████████████████▊| 930/938 [00:10<00:00, 83.26it/s, loss=0.483327, batch=937/938]
Test set: Average loss: 0.2213, Accuracy: 9335/10000 (93%)
Epoch 9/14: 100%|███████████████████| 938/938 [00:10<00:00, 86.23it/s, loss=0.582588, batch=937/938]
Epoch 9/14: 99%|██████████████████▊| 930/938 [00:10<00:00, 93.04it/s, loss=0.582588, batch=937/938]
Test set: Average loss: 0.2159, Accuracy: 9344/10000 (93%)
Epoch 10/14: 100%|██████████████████| 938/938 [00:10<00:00, 86.33it/s, loss=0.278955, batch=937/938]
Epoch 10/14: 100%|██████████████████| 938/938 [00:10<00:00, 90.55it/s, loss=0.278955, batch=937/938]
Test set: Average loss: 0.2131, Accuracy: 9359/10000 (94%)
Epoch 11/14: 100%|██████████████████| 938/938 [00:10<00:00, 86.26it/s, loss=0.404683, batch=937/938]
Epoch 11/14: 100%|█████████████████▉| 935/938 [00:10<00:00, 79.48it/s, loss=0.404683, batch=937/938]
Test set: Average loss: 0.2110, Accuracy: 9363/10000 (94%)
Epoch 12/14: 100%|██████████████████| 938/938 [00:11<00:00, 79.80it/s, loss=0.250124, batch=937/938]
Epoch 12/14: 99%|█████████████████▉| 932/938 [00:11<00:00, 91.28it/s, loss=0.250124, batch=937/938]
Test set: Average loss: 0.2106, Accuracy: 9359/10000 (94%)
Epoch 13/14: 100%|██████████████████| 938/938 [00:11<00:00, 85.16it/s, loss=0.278060, batch=937/938]
Epoch 13/14: 99%|█████████████████▊| 929/938 [00:11<00:00, 92.83it/s, loss=0.278060, batch=937/938]
Test set: Average loss: 0.2091, Accuracy: 9354/10000 (94%)
Epoch 14/14: 100%|██████████████████| 938/938 [00:10<00:00, 91.87it/s, loss=0.448233, batch=937/938]
Epoch 14/14: 99%|█████████████████▉| 932/938 [00:10<00:00, 94.04it/s, loss=0.448233, batch=937/938]
Test set: Average loss: 0.2083, Accuracy: 9368/10000 (94%)
Overall Progress: 100%|████████████████████████████████| 14/14 [02:42<00:00, 11.63s/it, lr=0.000969]