导读:在环境建模与水文分析中,数据质量往往决定了模型的上限。本文作为系列首篇,将聚焦于最核心的基础输入------历史气象数据,分享如何利用 Python 和开放 API 高效获取全球任意位置的逐小时气象资料。
一、引言
在环境领域的分析与建模中,业内有一句名言:"Garbage in, Garbage out"。无论是进行水文模拟、洪涝风险评估,还是城市微气候研究,模型逻辑再精妙,若缺乏高质量的基础数据支撑,结果也难具说服力。
在实际工作中,我们通常需要以下几类基础数据:
-
历史气象数据:降雨、气温、风速、辐射、湿度等。
-
下垫面数据:土地利用/覆盖(LULC)。
-
地形地貌数据:数字高程模型(DEM)。
-
观测与统计数据:土壤参数、水文站流量、社会经济数据。
然而,现实痛点在于:这些数据往往分散在不同的官方平台,获取门槛高、格式不统一、自动化程度低。为此,我计划通过一个系列文章,系统介绍这些环境数据的获取途径、接口调用及建模应用。
本篇我们从最基础、也是最常用的历史气象数据讲起。
二、为什么历史气象数据是"刚需"?
在环境机理建模中,历史气象数据不仅是驱动力,更是校准基准:
-
驱动模型:作为水文水动力模型的核心输入。
-
极端事件回溯:分析特定场次暴雨、干旱或高温热浪的演变过程。
-
基准值计算:计算多年平均降雨量、蒸散发量等气候统计特征。
-
模型校准:利用历史实测气象驱动模型,对比观测流量或水位以调整参数。
其中,降雨数据几乎是所有环境水文分析中波动最大、敏感度最高的变量。
三、历史气象数据的三大来源
目前,获取历史气象数据的途径主要分为三类:
-
地面气象站观测
-
优点:精度最高,是公认的"真值"。
-
缺点:站点稀疏,空间代表性有限;通常有严格的使用限制,获取流程繁琐。
-
-
再分析数据集(Reanalysis)
-
代表:欧洲中心的 ERA 5、NASA 的 MERRA-2。
-
优点:全球覆盖,时空连续性好。
-
缺点:数据量极大(通常为 PB 级),处理门槛高(需处理 NetCDF 格式)。
-
-
开放气象 API / 插值产品
-
代表:Open-Meteo, Visual Crossing。
-
优点 :易获取、自动化友好、无需处理原始大文件。
-
适用场景:快速建模、科研原型开发、区域性趋势分析。
-
对于大多数开发者和研究者来说,开放 API 是平衡精度与效率的最佳选择。
四、实战:使用 Open-Meteo 获取逐小时降雨
Open-Meteo 是一个对开发者极其友好的气象平台。它整合了 ERA 5 等权威再分析数据,并提供了极简的 API 接口。
核心优势:
-
✅ 无需注册/无 API Key(针对非商业用途)。
-
✅ 覆盖全球:基于经纬度定位。
-
✅ 高时间分辨率:支持逐小时(Hourly)数据。
-
✅ 格式友好:直接返回 JSON,易于 Python 解析。
示例:获取福州 2023--2024 年逐小时降雨数据
以下 Python 代码展示了如何自动化获取数据并转换为 Pandas DataFrame:
python
import requests
import pandas as pd
# 1. 配置参数
params = {
"latitude": 26.08, # 福州纬度
"longitude": 119.3, # 福州经度
"start_date": "2023-01-01",
"end_date": "2024-12-31",
"hourly": "precipitation", # 请求变量:降雨量
"timezone": "Asia/Shanghai"
}
# 2. 调用 Open-Meteo 历史数据接口 (Archive API)
url = "https://archive-api.open-meteo.com/v1/archive"
response = requests.get(url, params=params)
if response.status_code == 200:
data = response.json()
# 3. 解析数据并构建 DataFrame
df = pd.DataFrame({
"time": pd.to_datetime(data["hourly"]["time"]),
"precip_mm": data["hourly"]["precipitation"]
})
# 4. 简单处理:保存并查看前几行
df.to_csv("fuzhou_rainfall_hourly.csv", index=False)
print("数据获取成功!前五行如下:")
print(df.head())
else:
print(f"请求失败,状态码:{response.status_code}")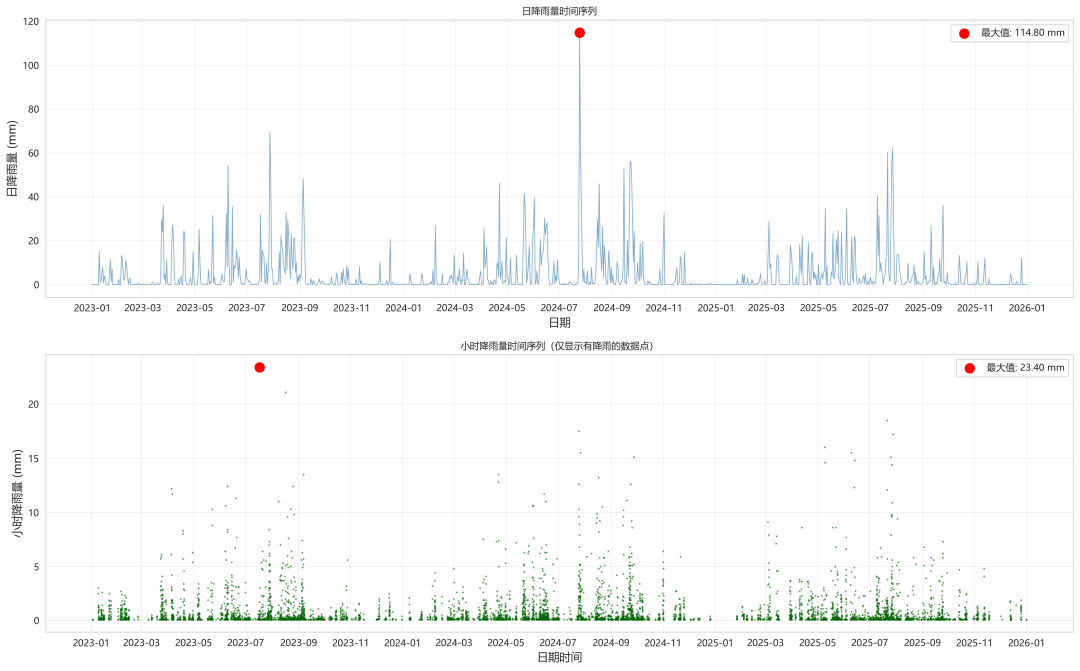
五、数据深加工:从原始数据到建模输入
获取到逐小时数据后,我们通常需要根据建模需求进行二次加工:
1. 尺度转换(重采样)
如果你的模型只需要日尺度数据,可以利用 Pandas 快速聚合:
# 将逐小时数据聚合为日总降雨量df_daily = df.set_index("time").resample("D").sum()2. 特征提取
-
计算最大 1 h 降雨量:识别短历时强降雨。
-
识别降雨场次:根据无雨间隔(IETD)划分独立的降雨事件。
-
计算降雨历时:分析单次降雨持续的时间分布。
六、避坑指南:使用插值数据需注意什么?
虽然 API 获取数据非常方便,但在严谨的机理建模中,必须注意以下几点:
-
非实测属性:这类数据多基于格点插值或模式模拟,对于局地性极强的强对流天气(如夏季午后的雷阵雨),可能会有平滑效应(低估峰值)。
-
空间分辨率:Open-Meteo 的历史数据通常基于 0.1° 或 0.25° 的格点,对于极小尺度的排水管网建模,可能需要结合本地雨量站进行校正。
-
单位检查 :调用不同 API 时,务必确认降雨单位是
mm还是inch,气温是℃还是℉。
七、结语与预告
获取历史气象数据只是环境建模的第一步。有了"历史",我们往往还想预测"未来"。
在下一篇文章中,我将分享:👉 《环境建模中的基础数据获取(二):天气预报数据的自动抓取与滚动更新》
我们将探讨如何获取预报数据,并将其接入自动化预警模型中。