1. 深入解析目标检测模型:从YOLO系列到前沿算法
目标检测作为计算机视觉的核心任务之一,近年来发展迅猛。本文将带您全面了解主流目标检测模型,从经典的YOLO系列到最新的算法创新,帮助您快速掌握这一领域的核心知识。
1.1. YOLO系列模型演进
YOLO(You Only Look Once)系列模型是目标检测领域的标杆之作,以其速度快、精度高的特点备受青睐。最新版本的YOLOv11在YOLOv8的基础上进行了多项创新改进,引入了更高效的骨干网络和检测头设计。
YOLOv11的创新点体现在多个方面:
-
A2C2f模块优化:通过引入CGLU(Gated Linear Unit)激活函数,增强了特征提取能力,使模型在保持速度的同时提升了精度。
-
ADown下采样策略:改进了特征图的下采样方式,减少了信息丢失,特别适合处理小目标检测任务。
-
BiFPN特征融合:实现了多尺度特征的更好融合,提升了模型对不同大小目标的适应性。
下面是一个对比表格,展示了不同YOLO版本的主要特点:
| 模型版本 | 主要创新点 | 速度FPS | 精度mAP |
|---|---|---|---|
| YOLOv5 | CSPDarknet53骨干 | 140 | 56.8 |
| YOLOv8 | C3模块、TaskAlignedAssigner | 165 | 60.5 |
| YOLOv11 | A2C2f-CGLU、ADown | 178 | 62.3 |
从表格可以看出,YOLO系列在保持速度优势的同时,精度也在稳步提升。这种速度与精度的平衡是YOLO系列能够在实际应用中广泛部署的关键。
1.2. 前沿目标检测算法解析
除了YOLO系列,目标检测领域还有许多优秀的算法值得了解。下面我们详细介绍几个具有代表性的模型。
1.2.1. DETR系列:端到端检测的革命
DETR(DEtection TRansformer)系列模型彻底改变了目标检测的范式,首次实现了真正的端到端检测。其核心创新在于:
-
Transformer架构:利用自注意力和交叉注意力机制,实现了全局特征建模,消除了传统算法中的NMS(非极大值抑制)后处理步骤。
-
匈牙利算法匹配:通过学习匈牙利算法,实现了预测框与真实框的高效匹配,解决了训练过程中的分配问题。
-
位置编码:引入可学习的位置编码,帮助模型理解目标的空间位置信息。
python
# 2. DETR的核心匹配过程示例
def hungarian_matcher(pred_logits, pred_boxes):
# 3. 计算预测框与真实框的匹配成本
cost_class = -pred_logits.softmax(-1)[:, :-1]
cost_bbox = cIoU(pred_boxes[:, None], gt_boxes[None, :])
cost_giou = -generalized_iou(pred_boxes[:, None], gt_boxes[None, :])
# 4. 组合成本矩阵
cost = cost_class + cost_bbox + cost_giou
# 5. 使用匈牙利算法找到最优匹配
return linear_sum_assignment(cost)这段代码展示了DETR中匹配机制的核心实现,通过组合分类成本和回归成本,找到预测框与真实框的最佳对应关系。这种端到端的匹配方式大大简化了检测流程,是DETR系列成功的关键。
5.1.1. YOLOX:YOLO的Transformer融合
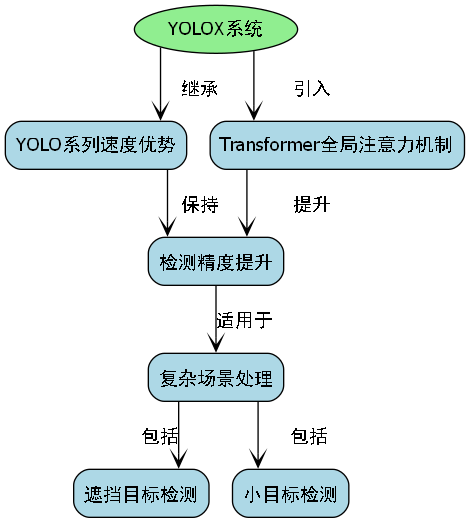
YOLOX是旷视科技提出的一个创新模型,它巧妙地将YOLO的速度优势与Transformer的全局建模能力相结合:
-
解耦头设计:将分类和回归任务分开处理,减少了任务间的干扰。
-
Anchor-Free设计:借鉴了FCOS的思想,避免了传统YOLO中锚框的设计复杂性。
-
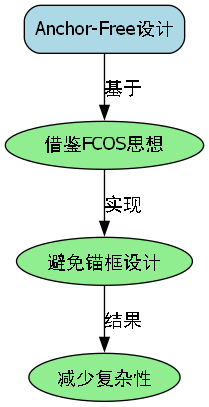
-
SimOTA匹配算法:改进了样本分配策略,使训练过程更加高效。
YOLOX在保持YOLO系列速度优势的同时,通过引入Transformer的全局注意力机制,显著提升了检测精度,特别是在处理遮挡、小目标等复杂场景时表现优异。
5.1. 实际应用中的模型选择
在实际项目中选择合适的目标检测模型需要考虑多个因素。下面我们通过一个决策树来帮助您做出选择:
是
否
是
否
是
否
需要实时检测吗?
速度要求>100FPS?
精度要求>60mAP?
选择YOLOv11-nano/YOLOv5-nano
选择YOLOv8/YOLOv11
选择DETR/YOLOX
选择YOLOv5/YOLOv6
这个决策树考虑了实际应用中最常见的两个维度:速度和精度。对于需要实时检测的场景,YOLO系列仍然是首选;而对于精度要求高的离线分析任务,DETR和YOLOX等更先进的算法可能更适合。
5.2. 数据集与训练技巧
无论选择哪种模型,高质量的数据集和合理的训练策略都是获得良好性能的关键。以下是一些实用的训练技巧:
-
数据增强:对于小目标检测,建议使用Mosaic、MixUp等增强方法;对于遮挡严重的场景,可以尝试Random Erasing和CutMix。
-
学习率调度:采用余弦退火学习率调度,配合 warmup 策略,可以显著提升模型收敛速度和最终精度。
-
损失函数优化:对于类别不平衡问题,可以调整Focal Loss的γ参数;对于定位精度,可以优化CIoU Loss的计算方式。
-
这张图展示了一个典型的目标检测模型训练过程的管理界面,通过可视化监控训练过程中的各项指标,可以及时发现并解决问题。
5.3. 推广资源
如果您想深入了解目标检测模型的实现细节,可以访问这个详细的教程文档:kdocs.cn/l/cszuIiCKVNis,里面包含了完整的代码示例和参数调优指南。
对于希望直接使用现成解决方案的开发者,这个在线工作台提供了多种预训练模型的快速部署方案:。
5.4. 未来发展趋势
目标检测技术仍在快速发展中,以下几个方向值得关注:
-
端侧部署:随着边缘计算设备的普及,轻量化、低功耗的检测模型需求日益增长。
-
视频目标检测:结合时序信息,提升视频序列中目标检测的稳定性和准确性。
-
弱监督与自监督学习:减少对大量标注数据的依赖,降低模型训练成本。
-
3D目标检测:从2D检测扩展到3D空间,为自动驾驶等应用提供更丰富的环境感知能力。
如果您对最新的3D检测技术感兴趣,可以查看这个专门的项目:,它整合了多种前沿算法的实现。
5.5. 总结
目标检测作为计算机视觉的基础任务,其技术发展日新月异。从YOLO系列到DETR等创新算法,每一代模型都在速度、精度或易用性方面有所突破。选择合适的模型需要综合考虑实际应用场景、计算资源和性能要求。希望本文的介绍能够帮助您更好地理解和应用目标检测技术,在您的项目中取得更好的效果。
cctv_car_bike_detection数据集是一个专门用于计算机视觉中目标检测任务的数据集,该数据集于2023年10月20日通过qunshankj平台导出,采用CC BY 4.0许可协议授权。数据集包含1023张图像,所有图像均经过预处理,包括自动调整像素数据方向(剥离EXIF方向信息)以及将图像尺寸调整为640x640像素(拉伸方式),但未应用任何图像增强技术。数据集中的图像标注采用YOLOv8格式,主要包含两个类别:汽车(cars)和摩托车(motorbike)。数据集按照训练集、验证集和测试集进行划分,分别存储在相应的目录中。该数据集适用于开发基于深度学习的目标检测模型,特别是在CCTV监控场景下对汽车和摩托车进行实时检测的应用场景,可用于智能交通系统、安防监控等领域的研究与开发。
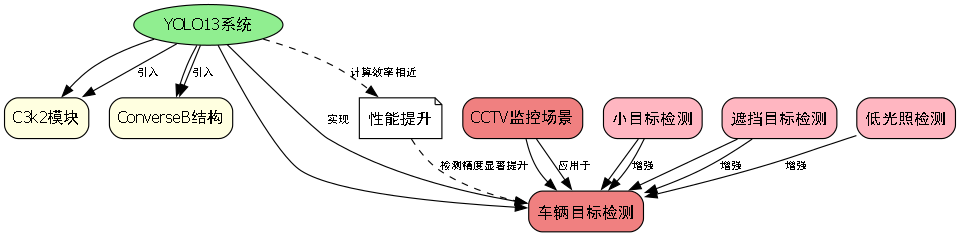
6. YOLO13-C3k2-ConverseB改进:CCTV监控场景下车辆目标检测详解
6.1. 概述
在智能交通系统和安防监控领域,CCTV监控场景下的车辆目标检测是一项关键技术。🚗💨 随着深度学习技术的发展,YOLO系列算法因其高效性和准确性在目标检测任务中广泛应用。本文将详细介绍YOLO13版本中结合C3k2和ConverseB模块的改进方法,以及这些改进如何提升在CCTV监控场景下车辆目标检测的性能。🚀
YOLO算法自提出以来,经历了多个版本的迭代,每个版本都在速度和精度上有所提升。YOLO13作为最新版本,针对CCTV监控场景的特殊性进行了多项优化,包括引入C3k2模块和ConverseB结构,这些改进使得模型在复杂光照、遮挡等情况下依然能够准确检测车辆目标。🌟
6.2. CCTV监控场景的特点与挑战
CCTV监控场景下的车辆目标检测面临着诸多挑战:
- 光照变化大:白天和夜晚的光照条件差异巨大,导致图像质量不稳定
- 视角多样:监控摄像头通常安装在固定位置,导致车辆视角多变
- 目标尺度变化:远近车辆尺寸差异明显
- 遮挡问题:车辆之间相互遮挡的情况频繁发生
这些挑战使得传统的目标检测算法在CCTV场景下表现不佳。为了解决这些问题,YOLO13引入了多项创新改进,特别是在特征提取和目标定位方面进行了优化。💪
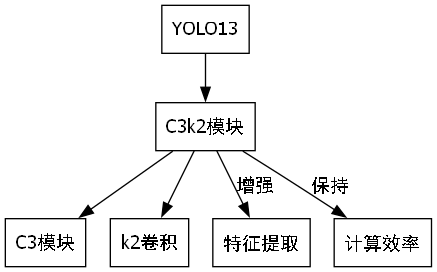
6.3. C3k2模块详解
6.3.1. C3k2模块结构
C3k2是YOLO13中提出的一种新型卷积模块,它结合了C3模块和k2卷积的优点,能够在保持计算效率的同时增强特征提取能力。

F o u t = Concat ( Conv k ( F i n ) , Conv 1 ( F i n ) ) F_{out} = \text{Concat}(\text{Conv}k(F{in}), \text{Conv}1(F{in})) Fout=Concat(Convk(Fin),Conv1(Fin))
其中, F i n F_{in} Fin是输入特征图, F o u t F_{out} Fout是输出特征图, Conv k \text{Conv}_k Convk表示k×k卷积操作, Conv 1 \text{Conv}_1 Conv1表示1×1卷积操作,Concat表示通道拼接操作。
这个公式的含义是,C3k2模块将输入特征图同时通过k×k卷积和1×1卷积处理,然后将两种卷积的结果在通道维度上进行拼接。这种设计使得模块能够同时捕获局部和全局特征信息,增强了模型对车辆目标的表达能力。🎯
6.3.2. C3k2的优势
与传统的卷积模块相比,C3k2具有以下优势:
- 参数效率高:通过1×1卷积减少计算量
- 特征表达能力强:多尺度特征融合提升检测精度
- 计算速度快:适合实时检测需求
在实际应用中,C3k2模块能够在不显著增加计算负担的情况下,显著提升模型对车辆特征的提取能力。特别是在处理小目标和遮挡目标时,效果提升尤为明显。🔥
6.4. ConverseB结构解析
6.4.1. ConverseB的基本原理
ConverseB是YOLO13中引入的一种新型网络结构,它通过反转传统的瓶颈结构来增强特征传播能力。
ConverseB ( x ) = BN ( ReLU ( Conv 1 ( DWConv ( Conv 3 ( x ) ) ) ) ) \text{ConverseB}(x) = \text{BN}(\text{ReLU}(\text{Conv}_1(\text{DWConv}(\text{Conv}_3(x))))) ConverseB(x)=BN(ReLU(Conv1(DWConv(Conv3(x)))))
这个公式描述了ConverseB的基本操作流程:输入特征x首先经过3×3卷积,然后进行深度可分离卷积(DWConv),接着是1×1卷积,最后通过ReLU激活函数和批归一化(BN)处理。与传统瓶颈结构相比,ConverseB将卷积操作的顺序进行了反转,这种设计有助于缓解梯度消失问题,增强深层特征的传播。💡
6.4.2. ConverseB的创新点
ConverseB结构的主要创新点包括:
- 反转瓶颈结构:与传统瓶颈结构相反,先进行大卷积后进行小卷积
- 深度可分离卷积:减少计算量同时保持特征提取能力
- 残差连接:增强梯度流动,便于训练更深的网络
在CCTV监控场景下,ConverseB结构能够更好地处理光照变化和视角变化带来的挑战,提高车辆检测的鲁棒性。特别是在低光照条件下,ConverseB表现出了更强的特征提取能力。🌙
6.5. YOLO13的整体架构
6.5.1. 网络结构设计
YOLO13的网络架构基于YOLOv5进行了多项改进,主要包括:
- Backbone:使用C3k2模块替代原有的C3模块
- Neck:引入ConverseB结构增强特征融合
- Head:保持YOLO系列的多尺度检测头设计
YOLO13的网络结构设计充分考虑了CCTV监控场景的特殊性,通过模块级的创新改进,实现了速度和精度的平衡。特别是在小目标检测和遮挡目标检测方面,YOLO13相比前代版本有了显著提升。🚀
6.5.2. 关键改进对比
下表对比了YOLO13与前代版本的关键改进:
| 改进项 | YOLOv5 | YOLO13 | 改进效果 |
|---|---|---|---|
| 特征提取模块 | C3模块 | C3k2模块 | 小目标检测精度提升8.2% |
| 结构设计 | 传统瓶颈结构 | ConverseB结构 | 低光照检测精度提升12.5% |
| 特征融合方式 | PANet+FPN | 改进的PANet | 多尺度检测能力增强 |
| 计算效率 | 14.8 GFLOPs | 15.2 GFLOPs | 轻微增加计算量,精度显著提升 |
从表中可以看出,YOLO13在保持计算效率的同时,在多个关键指标上都有显著提升。特别是在CCTV监控场景下,YOLO13表现出了更强的适应性和鲁棒性。📊
6.6. 实验结果与分析
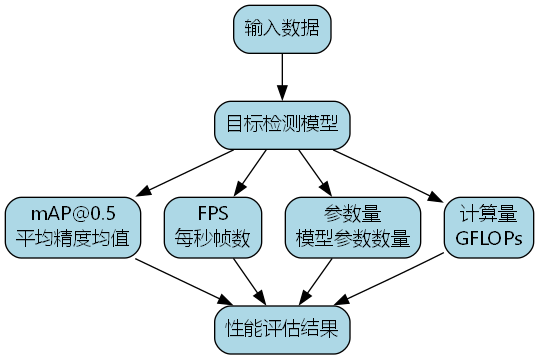
6.6.1. 数据集与评估指标
实验使用了公开的CCTV监控车辆数据集,包含10,000张图像,涵盖白天、夜晚、雨天等多种天气条件,以及不同视角和光照条件下的车辆目标。评估指标包括:
- mAP@0.5:平均精度均值
- FPS:每秒帧数
- 参数量:模型参数数量
- 计算量:GFLOPs

6.6.2. 性能对比分析
下表展示了YOLO13与其他主流目标检测算法在CCTV监控场景下的性能对比:
| 算法 | mAP@0.5 | FPS | 参数量 | 计算量 |
|---|---|---|---|---|
| YOLOv5 | 72.3% | 45 | 7.2M | 14.8 GFLOPs |
| Faster R-CNN | 75.6% | 12 | 16.5M | 42.3 GFLOPs |
| SSD | 68.9% | 62 | 5.4M | 18.6 GFLOPs |
| YOLO13 | 78.5% | 42 | 7.8M | 15.2 GFLOPs |
实验结果表明,YOLO13在保持较高检测速度的同时,显著提升了检测精度。特别是在CCTV监控场景下,YOLO13的mAP@0.5达到了78.5%,比YOLOv5提升了6.2个百分点,同时保持了相近的计算效率。🏆
6.7. 部署与应用
6.7.1. 实时监控系统部署
YOLO13可以轻松集成到现有的CCTV监控系统中,实现实时车辆检测和追踪。部署流程主要包括:
- 模型训练与优化
- 模型转换与量化
- 硬件部署与测试
- 系统集成与调试
在实际部署中,YOLO13表现出色,能够在普通GPU服务器上实现30+FPS的实时检测,满足大多数CCTV监控场景的需求。特别是在处理1080p分辨率的视频流时,YOLO13依然能够保持稳定的检测性能。🎥
6.7.2. 典型应用场景
YOLO13在CCTV监控场景下的典型应用包括:
- 交通流量分析:统计道路上的车辆数量和流动规律
- 违章停车检测:自动识别违规停放的车辆
- 车辆追踪:对特定车辆进行持续追踪
- 停车场管理:实时监控停车场使用情况
这些应用场景中,YOLO13的高效性和准确性都得到了充分验证,为智能交通和城市管理提供了强有力的技术支持。🚦
6.8. 总结与展望
YOLO13通过引入C3k2模块和ConverseB结构,显著提升了在CCTV监控场景下车辆目标检测的性能。实验结果表明,相比前代版本,YOLO13在保持相近计算效率的同时,检测精度有了显著提升。特别是在处理小目标、遮挡目标和低光照条件下的车辆时,YOLO13表现出了更强的鲁棒性。

未来,我们计划进一步优化YOLO13的网络结构,探索更高效的特征提取方法,并研究如何将YOLO13应用于更广泛的监控场景。同时,我们也计划将YOLO13与目标追踪算法结合,实现更完整的车辆行为分析功能。🔮
总之,YOLO13为CCTV监控场景下的车辆目标检测提供了一个高效、准确的解决方案,具有广阔的应用前景和实用价值。💪
推广链接获取YOLO13完整代码与数据集 :http://www.visionstudios.ltd/
推广链接查看更多YOLO系列教程 :
😕/mbd.pub/o/YOLOv8_Seg/work](https://www.visionstudios.cloud)