一、 站在十字路口:老旧系统的"AI 焦虑"
在很多企业中,支撑核心业务的往往是那些运行了 5 年、10 年甚至更久的"老系统"。它们可能是一套复杂的 ERP、一套功能臃肿的 OA,或者是一套堆满了业务逻辑的进销存软件。
作为这些系统的开发者或维护者,你是否面临以下困境:
- 报表地狱:老板想要一个新的统计维度,你需要改 SQL、加 Controller、画前端图表,忙活三天,结果老板只看了一眼。
- 数据孤岛:系统里存了成千上万份 PDF 合同和 Word 文档,除了占用磁盘,毫无价值,想查某个条款只能靠肉眼翻。
- 决策盲区:系统只负责记录"发生了什么",却无法告诉你"该做什么"。库存缺了、价格异常了,只能靠人工盯着。
现在,大模型(LLM)给了我们一个低成本、高回报的"翻新"机会。 本系列合集将带你深入实战,不讲虚头巴脑的理论,直接基于本地部署的 DeepSeek-R1 大模型,手把手教你如何在一套传统 Spring Boot 架构上,"插"入一颗 AI 核心,让它从一个"打字机"进化为能思考、能审计、能分析的"数字员工"。
二、 旁路式架构:老系统集成 AI 的最优解
在对生产系统进行改造时,最忌讳的是"推倒重来"或"强侵入改造"。我们要像安装外挂模块一样,采用旁路式扩展架构。
1. 技术选型:私有化是唯一底线
对于企业级系统,数据安全高于一切。我们拒绝使用任何公有云商业 API,所有示例均基于:
- Ollama:作为本地大模型运行环境。
- DeepSeek-R1 (7B/14B):作为核心推理大脑。
- Spring AI:作为 Java 后端与模型交互的标准适配层。
2. 核心基础设施:审计日志设计
AI 的输出具有随机性,因此在老系统集成 AI 的第一步,不是写 Prompt,而是建立审计体系。我们需要记录每一次 AI 调用的"思考过程"(Thinking Process)、耗时以及 Token 消耗。
代码示例:通用 AI 审计模型(脱敏重构)
java
/**
* 为什么需要审计日志?
* 1. 监控 AI 是否在瞎说(幻觉)。
* 2. 推理模型(如 DeepSeek-R1)的 thinking 过程是优化 Prompt 的核心依据。
* 3. 统计本地资源的消耗情况。
*/
@Data
@TableName("infra_ai_audit")
public class AiAuditLog {
@TableId
private Long id;
// 业务场景:如"合同问答"、"智能补货"
private String scene;
// 用户输入的原始问题
private String userPrompt;
// AI 的思考过程(针对推理模型)
private String aiThinking;
// AI 的最终回答内容
private String aiResponse;
// 消耗时间(毫秒)
private Long durationMs;
// 状态:0-成功,1-异常
private Integer status;
private LocalDateTime createTime;
}三、 实战预览:我们将如何改造你的系统?
在本合集的后续篇章中,我们将深入以下核心业务场景:
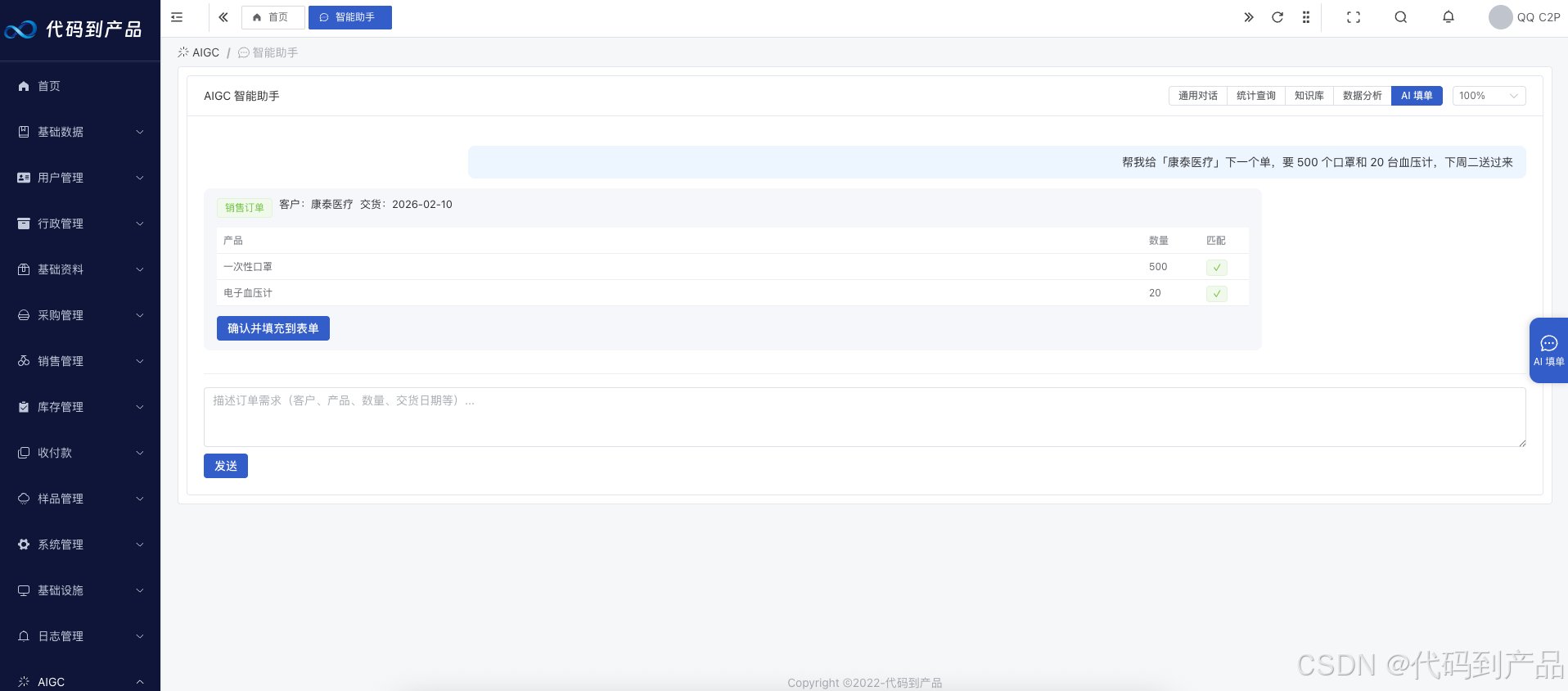
1. 赋予系统"语义检索"能力 (RAG)
我们将把系统里沉睡的 PDF 附件提取出来,切片存入向量数据库(MySQL 扩展或 pgvector)。
效果:用户问:"公司去年跟康泰医疗签的补充协议里,违约金是怎么定的?" AI 直接翻出合同并回答。
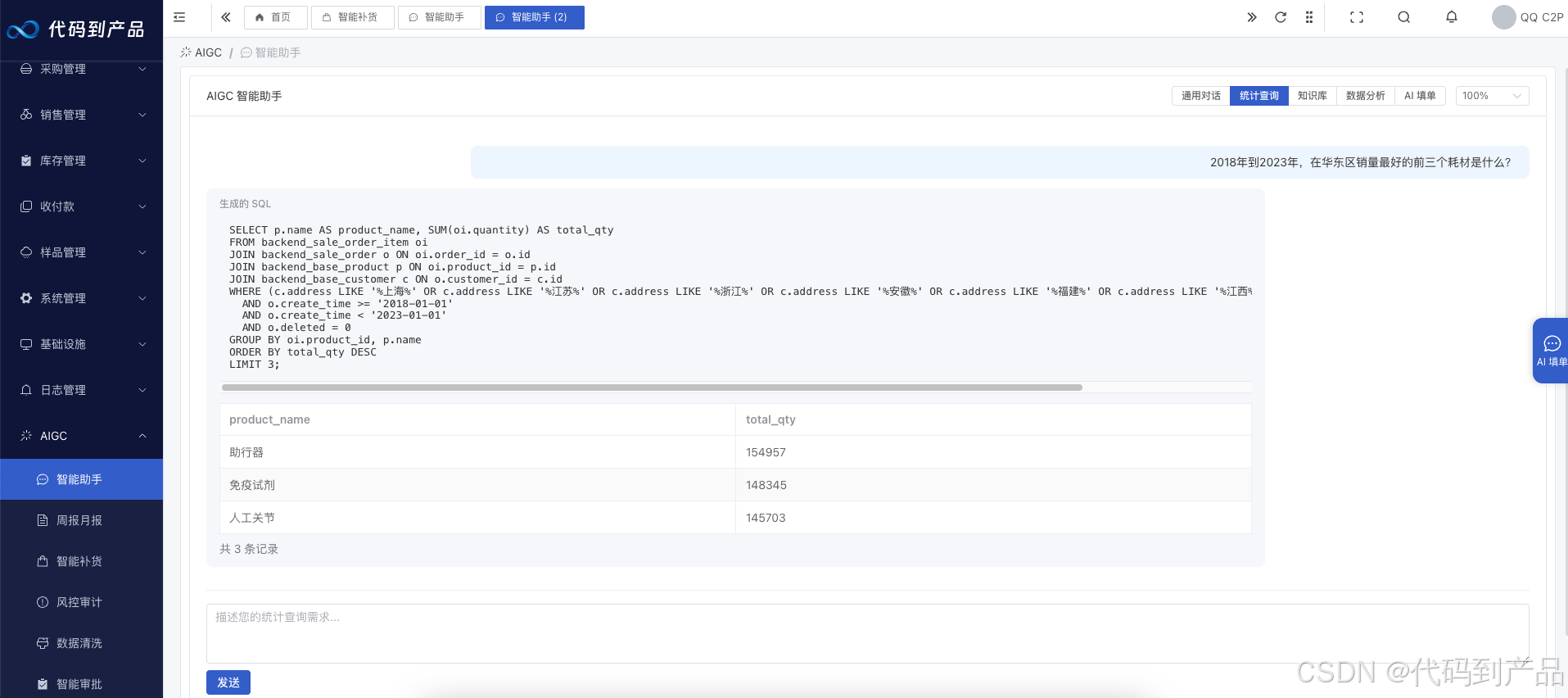
2. 让财务和销售"问"出报表 (Text-to-SQL)
通过 Schema Linking 技术,让 AI 理解你的数据库结构。
示例代码:防止 AI 删库的 SQL 校验器思路
java
/**
* 生产级安全:防止 AI 执行 DDL 或 DML 语句
*/
public class SqlSafetyChecker {
public static void checkSelectOnly(String generatedSql) {
// 使用 JSQLParser 解析 SQL
Statement statement = CCJSqlParserUtil.parse(generatedSql);
if (!(statement instanceof Select)) {
throw new SecurityException("危险操作!AI 试图执行非查询指令。");
}
log.info("SQL 安全校验通过,准备执行查询...");
}
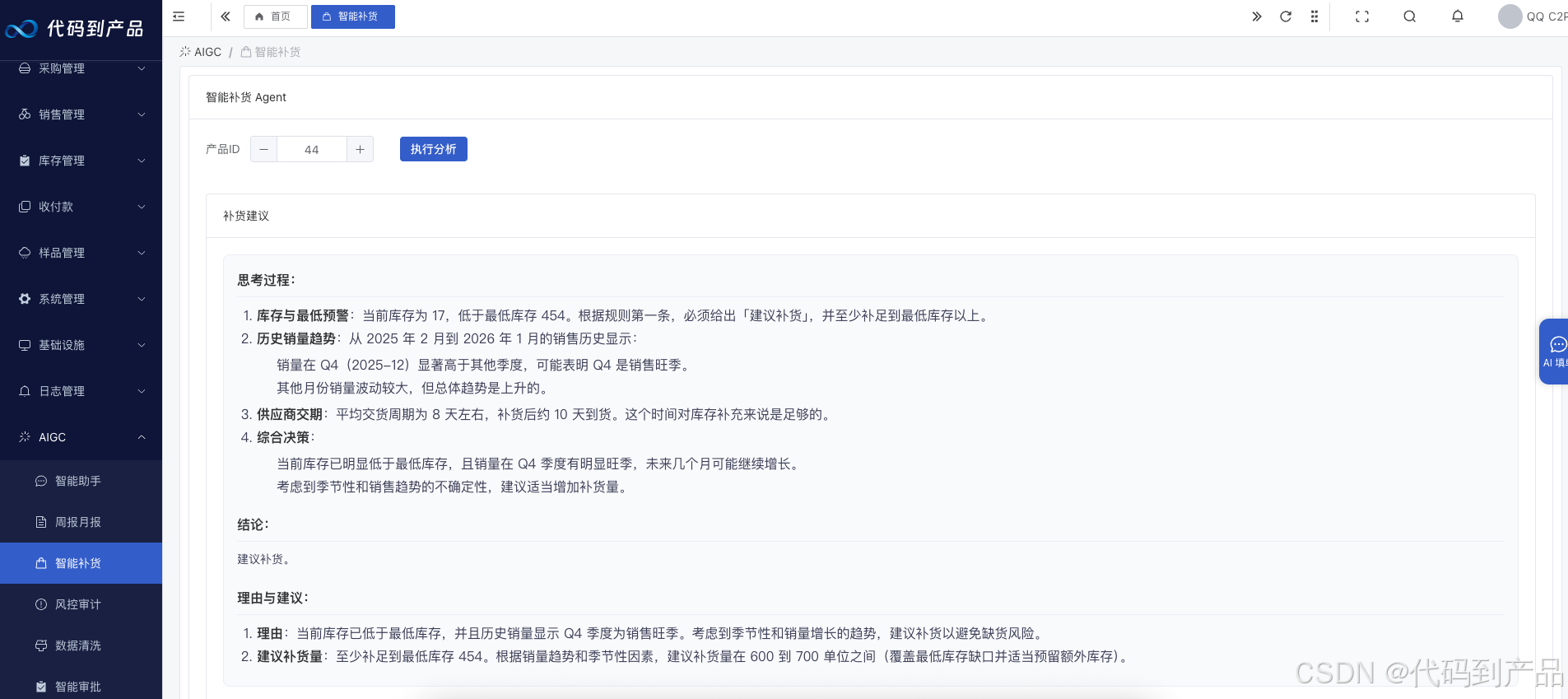
}3. 打造能自我修正的"数字专家" (Agent)
利用 ReAct(Reasoning and Acting)模型,给 AI 装备"工具箱"。
场景:AI 发现库存低于阈值 -> 自动调用查询接口看历史销量 -> 发现下周有大促 -> 自动生成一份补货申请单草稿发送给采购员。
四、 为什么这套课程值得你关注?
- 纯本地环境:不用梯子,不用买 Key,一台 16G 内存的笔记本就能跑通全流程。
- 生产级代码:拒绝 Hello World。我会教你如何处理长文本截断、如何防止 AI 幻觉、如何实现多租户数据隔离。
- 循序渐进:从最简单的 Chat 接口讲起,一直到复杂的 Agent 编排。
五、 系统样例
该合集文章更新于:知识星球 代码到产品之Java